- HSQLDB 教程
- HSQLDB - 首頁
- HSQLDB - 簡介
- HSQLDB - 安裝
- HSQLDB - 連線
- HSQLDB - 資料型別
- HSQLDB - 建立表
- HSQLDB - 刪除表
- HSQLDB - 插入查詢
- HSQLDB - 選擇查詢
- HSQLDB - WHERE 子句
- HSQLDB - 更新查詢
- HSQLDB - DELETE 子句
- HSQLDB - LIKE 子句
- HSQLDB - 排序結果
- HSQLDB - 連線
- HSQLDB - 空值
- HSQLDB - 正則表示式
- HSQLDB - 事務
- HSQLDB - ALTER 命令
- HSQLDB - 索引
- HSQLDB 有用資源
- HSQLDB 快速指南
- HSQLDB - 有用資源
- HSQLDB - 討論
HSQLDB 快速指南
HSQLDB - 簡介
HyperSQL 資料庫 (HSQLDB) 是一款現代的關係資料庫管理系統,嚴格遵循 SQL:2011 標準和 JDBC 4 規範。它支援所有核心功能和 RDBMS。HSQLDB 用於資料庫應用程式的開發、測試和部署。
HSQLDB 的主要和獨特功能是標準合規性。它可以在使用者應用程式程序內、應用程式伺服器內或作為單獨的伺服器程序提供資料庫訪問。
HSQLDB 的特性
HSQLDB 使用記憶體結構來對 DB 伺服器進行快速操作。它根據使用者靈活性的要求使用磁碟永續性,並具有可靠的崩潰恢復功能。
HSQLDB 也適用於商業智慧、ETL 和處理大型資料集的其他應用程式。
HSQLDB 擁有廣泛的企業部署選項,例如 XA 事務、連線池資料來源和遠端身份驗證。
HSQLDB 使用 Java 程式語言編寫,並在 Java 虛擬機器 (JVM) 中執行。它支援 JDBC 介面進行資料庫訪問。
HSQLDB 的元件
HSQLDB jar 包中有三個不同的元件。
HyperSQL RDBMS 引擎 (HSQLDB)
HyperSQL JDBC 驅動程式
資料庫管理器(帶 Swing 和 AWT 版本的 GUI 資料庫訪問工具)
HyperSQL RDBMS 和 JDBC 驅動程式提供核心功能。資料庫管理器是通用資料庫訪問工具,可用於任何具有 JDBC 驅動程式的資料庫引擎。
一個名為 sqltool.jar 的附加 jar 包含 Sql 工具,這是一個命令列資料庫訪問工具。這是一個通用的命令。行資料庫訪問工具,也可用於其他資料庫引擎。
HSQlDB - 安裝
HSQLDB 是一個用純 Java 實現的關係資料庫管理系統。您可以使用 JDBC 將此資料庫輕鬆嵌入到您的應用程式中。或者您可以單獨使用這些操作。
先決條件
請按照 HSQLDB 的先決條件軟體安裝步驟進行操作。
驗證 Java 安裝
由於 HSQLDB 是一個用純 Java 實現的關係資料庫管理系統,因此在安裝 HSQLDB 之前必須安裝 JDK(Java 開發工具包)軟體。如果您的系統中已安裝 JDK,請嘗試使用以下命令驗證 Java 版本。
java –version
如果 JDK 成功安裝在您的系統中,您將獲得以下輸出。
java version "1.8.0_91" Java(TM) SE Runtime Environment (build 1.8.0_91-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
如果您的系統中未安裝 JDK,請訪問以下連結以 安裝 JDK。
HSQLDB 安裝
以下是安裝 HSQLDB 的步驟。
步驟 1 - 下載 HSQLDB 捆綁包
從以下連結下載最新版本的 HSQLDB 資料庫 https://sourceforge.net/projects/hsqldb/files/. 單擊連結後,您將看到以下螢幕截圖。
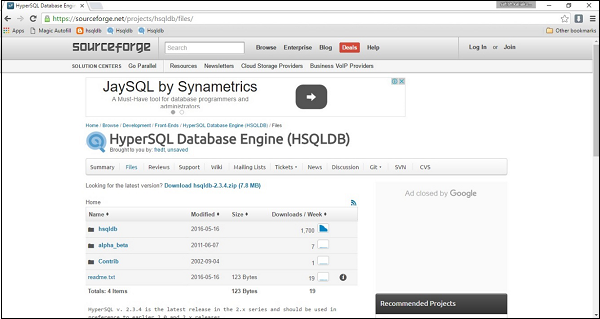
單擊 HSQLDB,下載將立即開始。最後,您將獲得名為 hsqldb-2.3.4.zip 的 zip 檔案。
步驟 2 - 解壓縮 HSQLDB zip 檔案
解壓縮 zip 檔案並將其放置到 C:\ 目錄中。解壓縮後,您將獲得以下螢幕截圖所示的檔案結構。
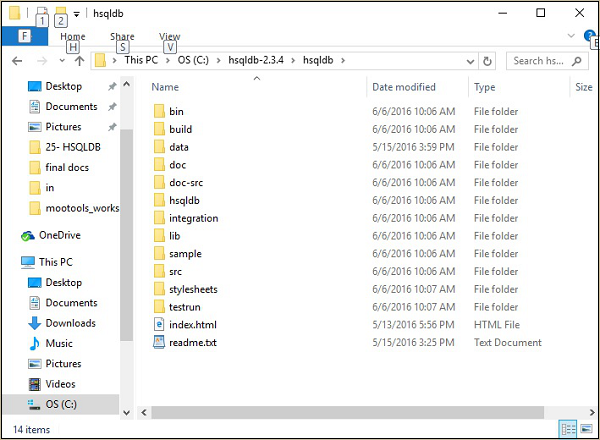
步驟 3 - 建立預設資料庫
HSQLDB 沒有預設資料庫,因此您需要為 HSQLDB 建立一個數據庫。讓我們建立一個名為 server.properties 的屬性檔案,該檔案定義一個名為 demodb 的新資料庫。請檢視以下資料庫伺服器屬性。
server.database.0 = file:hsqldb/demodb server.dbname.0 = testdb
將此 server.properties 檔案放置到 HSQLDB 主目錄中,即 C:\hsqldb- 2.3.4\hsqldb\。
現在在命令提示符下執行以下命令。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server
執行上述命令後,您將收到以下螢幕截圖所示的伺服器狀態。
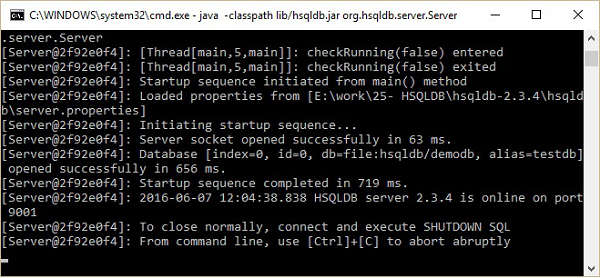
稍後,您將在 HSQLDB 主目錄(即 C:\hsqldb-2.3.4\hsqldb)中找到 hsqldb 目錄的以下資料夾結構。這些檔案是 HSQLDB 資料庫伺服器建立的 demodb 資料庫的臨時檔案、lck 檔案、日誌檔案、屬性檔案和指令碼檔案。
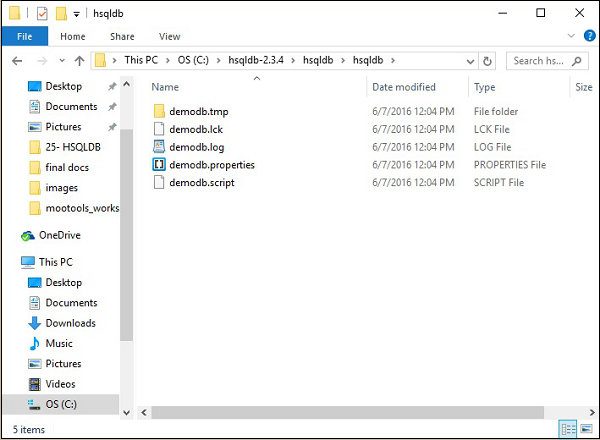
步驟 4 - 啟動資料庫伺服器
建立資料庫後,必須使用以下命令啟動資料庫。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
執行上述命令後,您將獲得以下狀態。
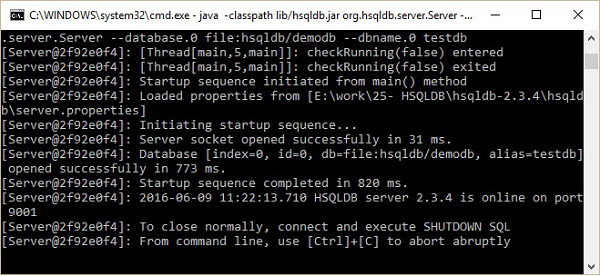
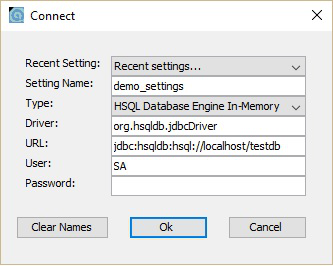
現在,您可以開啟資料庫主螢幕,即 C:\hsqldb-2.3.4\hsqldb\bin 位置中的 runManagerSwing.bat。此 bat 檔案將開啟 HSQLDB 資料庫的 GUI 檔案。在此之前,它將透過對話方塊詢問您資料庫設定。請檢視以下螢幕截圖。在此對話方塊中,輸入設定名稱,URL 如上所示,然後單擊確定。
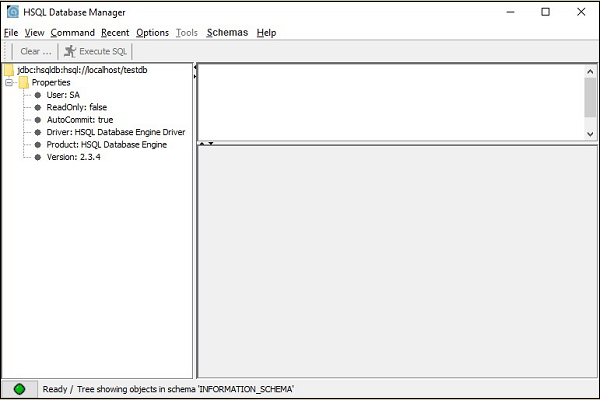
您將獲得 HSQLDB 資料庫的 GUI 螢幕,如以下螢幕截圖所示。
HSQlDB - 連線
在安裝章節中,我們討論瞭如何手動連線資料庫。在本節中,我們將討論如何以程式設計方式(使用 Java 程式設計)連線資料庫。
請檢視以下程式,它將啟動伺服器並在 Java 應用程式和資料庫之間建立連線。
示例
import java.sql.Connection;
import java.sql.DriverManager;
public class ConnectDatabase {
public static void main(String[] args) {
Connection con = null;
try {
//Registering the HSQLDB JDBC driver
Class.forName("org.hsqldb.jdbc.JDBCDriver");
//Creating the connection with HSQLDB
con = DriverManager.getConnection("jdbc:hsqldb:hsql:///testdb", "SA", "");
if (con!= null){
System.out.println("Connection created successfully");
}else{
System.out.println("Problem with creating connection");
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
將此程式碼儲存到 ConnectDatabase.java 檔案中。您將必須使用以下命令啟動資料庫。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
您可以使用以下命令編譯和執行程式碼。
\>javac ConnectDatabase.java \>java ConnectDatabase
執行上述命令後,您將收到以下輸出 -
Connection created successfully
HSQLDB - 資料型別
本章介紹了 HSQLDB 的不同資料型別。HSQLDB 伺服器提供了六類資料型別。
精確數值資料型別
| 資料型別 | 從 | 到 |
|---|---|---|
| bigint | -9,223,372,036,854,775,808 | 9,223,372,036,854,775,807 |
| int | -2,147,483,648 | 2,147,483,647 |
| smallint | -32,768 | 32,767 |
| tinyint | 0 | 255 |
| bit | 0 | 1 |
| decimal | -10^38 +1 | 10^38 -1 |
| numeric | -10^38 +1 | 10^38 -1 |
| money | -922,337,203,685,477.5808 | +922,337,203,685,477.5807 |
| smallmoney | -214,748.3648 | +214,748.3647 |
近似數值資料型別
| 資料型別 | 從 | 到 |
|---|---|---|
| float | -1.79E + 308 | 1.79E + 308 |
| real | -3.40E + 38 | 3.40E + 38 |
日期和時間資料型別
| 資料型別 | 從 | 到 |
|---|---|---|
| datetime | 1753 年 1 月 1 日 | 9999 年 12 月 31 日 |
| smalldatetime | 1900 年 1 月 1 日 | 2079 年 6 月 6 日 |
| date | 儲存日期,例如 1991 年 6 月 30 日 | |
| time | 儲存一天中的時間,例如下午 12:30。 | |
注意 - 在這裡,datetime 的精度為 3.33 毫秒,而 small datetime 的精度為 1 分鐘。
字元字串資料型別
| 資料型別 | 描述 |
|---|---|
| char | 最大長度為 8,000 個字元(固定長度非 Unicode 字元) |
| varchar | 最大 8,000 個字元(可變長度非 Unicode 資料) |
| varchar(max) | 最大長度為 231 個字元,可變長度非 Unicode 資料(僅限 SQL Server 2005) |
| text | 可變長度非 Unicode 資料,最大長度為 2,147,483,647 個字元 |
Unicode 字串資料型別
| 資料型別 | 描述 |
|---|---|
| nchar | 最大長度為 4,000 個字元(固定長度 Unicode) |
| nvarchar | 最大長度為 4,000 個字元(可變長度 Unicode) |
| nvarchar(max) | 最大長度為 231 個字元(僅限 SQL Server 2005),(可變長度 Unicode) |
| ntext | 最大長度為 1,073,741,823 個字元(可變長度 Unicode) |
二進位制資料型別
| 資料型別 | 描述 |
|---|---|
| binary | 最大長度為 8,000 位元組(固定長度二進位制資料) |
| varbinary | 最大長度為 8,000 位元組(可變長度二進位制資料) |
| varbinary(max) | 最大長度為 231 位元組(僅限 SQL Server 2005),(可變長度二進位制資料) |
| image | 最大長度為 2,147,483,647 位元組(可變長度二進位制資料) |
其他資料型別
| 資料型別 | 描述 |
|---|---|
| sql_variant | 儲存各種 SQL Server 支援的資料型別的值,除了 text、ntext 和 timestamp |
| timestamp | 儲存資料庫範圍內的唯一編號,每次更新行時都會更新 |
| uniqueidentifier | 儲存全域性唯一識別符號 (GUID) |
| xml | 儲存 XML 資料。您可以將 xml 例項儲存在列或變數中(僅限 SQL Server 2005) |
| cursor | 對遊標物件的引用 |
| table | 儲存結果集以供以後處理 |
HSQLDB - 建立表
建立表的必要基本要求是表名、欄位名以及這些欄位的資料型別。可以選擇地,您還可以為表提供鍵約束。
語法
請檢視以下語法。
CREATE TABLE table_name (column_name column_type);
示例
讓我們建立一個名為 tutorials_tbl 的表,其欄位名稱為 id、title、author 和 submission_date。請檢視以下查詢。
CREATE TABLE tutorials_tbl ( id INT NOT NULL, title VARCHAR(50) NOT NULL, author VARCHAR(20) NOT NULL, submission_date DATE, PRIMARY KEY (id) );
執行上述查詢後,您將收到以下輸出 -
(0) rows effected
HSQLDB – JDBC 程式
以下是用於在 HSQLDB 資料庫中建立名為 tutorials_tbl 的表的 JDBC 程式。將程式儲存到 CreateTable.java 檔案中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class CreateTable {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection("jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate("CREATE TABLE tutorials_tbl (
id INT NOT NULL, title VARCHAR(50) NOT NULL,
author VARCHAR(20) NOT NULL, submission_date DATE,
PRIMARY KEY (id));
");
} catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println("Table created successfully");
}
}
您可以使用以下命令啟動資料庫。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令編譯並執行上述程式。
\>javac CreateTable.java \>java CreateTable
執行上述命令後,您將收到以下輸出 -
Table created successfully
HSQLDB - 刪除表
刪除現有的 HSQLDB 表非常容易。但是,在刪除任何現有表時,您需要非常小心,因為刪除表後,任何丟失的資料都將無法恢復。
語法
以下是刪除 HSQLDB 表的通用 SQL 語法。
DROP TABLE table_name;
示例
讓我們考慮一個從 HSQLDB 伺服器刪除名為 employee 的表的示例。以下是刪除名為 employee 的表的查詢。
DROP TABLE employee;
執行上述查詢後,您將收到以下輸出 -
(0) rows effected
HSQLDB – JDBC 程式
以下是用於從 HSQLDB 伺服器刪除 employee 表的 JDBC 程式。
將以下程式碼儲存到 DropTable.java 檔案中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class DropTable {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection("jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate("DROP TABLE employee");
}catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println("Table dropped successfully");
}
}
您可以使用以下命令啟動資料庫。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令編譯並執行上述程式。
\>javac DropTable.java \>java DropTable
執行上述命令後,您將收到以下輸出 -
Table dropped successfully
HSQLDB - 插入查詢
您可以透過使用 INSERT INTO 命令在 HSQLDB 中實現 Insert 查詢語句。您必須按照表中列欄位的順序提供使用者定義的資料。
語法
以下是INSERT 查詢的通用語法。
INSERT INTO table_name (field1, field2,...fieldN) VALUES (value1, value2,...valueN );
要將字串型別資料插入表中,您必須使用雙引號或單引號在插入查詢語句中提供字串值。
示例
讓我們考慮一個將記錄插入名為 tutorials_tbl 的表的示例,其值為 id = 100、title = Learn PHP、Author = John Poul,提交日期為當前日期。
以下是給定示例的查詢。
INSERT INTO tutorials_tbl VALUES (100,'Learn PHP', 'John Poul', NOW());
執行上述查詢後,您將收到以下輸出 -
1 row effected
HSQLDB – JDBC 程式
這是一個使用 JDBC 程式將記錄插入到表中的示例,給定的值包括:id=100,title=Learn PHP,Author=John Poul,提交日期為當前日期。請檢視以下程式,並將程式碼儲存到InserQuery.java檔案中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class InsertQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate("INSERT INTO tutorials_tbl
VALUES (100,'Learn PHP', 'John Poul', NOW())");
con.commit();
}catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println(result+" rows effected");
System.out.println("Rows inserted successfully");
}
}
您可以使用以下命令啟動資料庫。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令編譯並執行上述程式。
\>javac InsertQuery.java \>java InsertQuery
執行上述命令後,您將收到以下輸出 -
1 rows effected Rows inserted successfully
嘗試使用INSERT INTO命令將以下記錄插入到tutorials_tbl表中。
| Id | 標題 | 作者 | 提交日期 |
|---|---|---|---|
| 101 | Learn C | Yaswanth | Now() |
| 102 | Learn MySQL | Abdul S | Now() |
| 103 | Learn Excell | Bavya kanna | Now() |
| 104 | Learn JDB | Ajith kumar | Now() |
| 105 | Learn Junit | Sathya Murthi | Now() |
HSQLDB - 選擇查詢
SELECT 命令用於從 HSQLDB 資料庫中獲取記錄資料。在這裡,您需要在 Select 語句中指定所需的欄位列表。
語法
以下是 Select 查詢的通用語法。
SELECT field1, field2,...fieldN table_name1, table_name2... [WHERE Clause] [OFFSET M ][LIMIT N]
您可以在單個 SELECT 命令中獲取一個或多個欄位。
您可以使用星號 (*) 代替欄位。在這種情況下,SELECT 將返回所有欄位。
您可以使用 WHERE 子句指定任何條件。
您可以使用 OFFSET 指定 SELECT 從哪裡開始返回記錄的偏移量。預設情況下,偏移量為零。
您可以使用 LIMIT 屬性限制返回的數量。
示例
以下是一個從tutorials_tbl表中獲取所有記錄的 id、title 和 author 欄位的示例。我們可以使用 SELECT 語句實現這一點。以下是該示例的查詢。
SELECT id, title, author FROM tutorials_tbl
執行上述查詢後,您將收到以下輸出。
+------+----------------+-----------------+ | id | title | author | +------+----------------+-----------------+ | 100 | Learn PHP | John Poul | | 101 | Learn C | Yaswanth | | 102 | Learn MySQL | Abdul S | | 103 | Learn Excell | Bavya kanna | | 104 | Learn JDB | Ajith kumar | | 105 | Learn Junit | Sathya Murthi | +------+----------------+-----------------+
HSQLDB – JDBC 程式
以下是一個 JDBC 程式,它將從tutorials_tbl表中獲取所有記錄的 id、title 和 author 欄位。將以下程式碼儲存到SelectQuery.java檔案中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class SelectQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT id, title, author FROM tutorials_tbl");
while(result.next()){
System.out.println(result.getInt("id")+" | "+
result.getString("title")+" | "+
result.getString("author"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
您可以使用以下命令啟動資料庫。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令編譯並執行上述程式碼。
\>javac SelectQuery.java \>java SelectQuery
執行上述命令後,您將收到以下輸出 -
100 | Learn PHP | John Poul 101 | Learn C | Yaswanth 102 | Learn MySQL | Abdul S 103 | Learn Excell | Bavya Kanna 104 | Learn JDB | Ajith kumar 105 | Learn Junit | Sathya Murthi
HSQLDB - WHERE 子句
通常,我們使用 SELECT 命令從 HSQLDB 表中獲取資料。我們可以使用 WHERE 條件子句過濾結果資料。使用 WHERE,我們可以指定選擇條件來從表中選擇所需的記錄。
語法
以下是使用 SELECT 命令 WHERE 子句從 HSQLDB 表中獲取資料的語法。
SELECT field1, field2,...fieldN table_name1, table_name2... [WHERE condition1 [AND [OR]] condition2.....
您可以使用逗號分隔一個或多個表,以使用 WHERE 子句包含各種條件,但 WHERE 子句是 SELECT 命令的可選部分。
您可以使用 WHERE 子句指定任何條件。
您可以使用 AND 或 OR 運算子指定多個條件。
WHERE 子句也可以與 DELETE 或 UPDATE SQL 命令一起使用以指定條件。
我們可以使用條件過濾記錄資料。我們在條件 WHERE 子句中使用不同的運算子。以下是可與 WHERE 子句一起使用的運算子列表。
| 運算子 | 描述 | 示例 |
|---|---|---|
| = | 檢查兩個運算元的值是否相等,如果相等,則條件為真。 | (A = B) 不為真 |
| != | 檢查兩個運算元的值是否相等,如果值不相等,則條件為真。 | (A != B) 為真 |
| > | 檢查左運算元的值是否大於右運算元的值,如果大於,則條件為真。 | (A > B) 不為真 |
| < | 檢查左運算元的值是否小於右運算元的值,如果小於,則條件為真。 | (A < B) 為真 |
| >= | 檢查左運算元的值是否大於或等於右運算元的值,如果大於或等於,則條件為真。 | (A >= B) 不為真 |
| <= | 檢查左運算元的值是否小於或等於右運算元的值,如果小於或等於,則條件為真。 | (A <= B) 為真 |
示例
以下是一個檢索書籍標題為“Learn C”的詳細資訊(例如 id、title 和 author)的示例。這可以透過在 SELECT 命令中使用 WHERE 子句來實現。以下是相同的查詢。
SELECT id, title, author FROM tutorials_tbl WHERE title = 'Learn C';
執行上述查詢後,您將收到以下輸出。
+------+----------------+-----------------+ | id | title | author | +------+----------------+-----------------+ | 101 | Learn C | Yaswanth | +------+----------------+-----------------+
HSQLDB – JDBC 程式
以下是一個 JDBC 程式,它從名為 tutorials_tbl 的表中檢索標題為Learn C的記錄資料。將以下程式碼儲存到WhereClause.java中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class WhereClause {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT id, title, author FROM tutorials_tbl
WHERE title = 'Learn C'");
while(result.next()){
System.out.println(result.getInt("id")+" |
"+result.getString("title")+" |
"+result.getString("author"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
您可以使用以下命令啟動資料庫。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令編譯並執行上述程式碼。
\>javac WhereClause.java \>java WhereClause
執行上述命令後,您將收到以下輸出。
101 | Learn C | Yaswanth
HSQLDB - 更新查詢
每當您想要修改表的的值時,都可以使用 UPDATE 命令。這將修改任何 HSQLDB 表中的任何欄位值。
語法
以下是 UPDATE 命令的通用語法。
UPDATE table_name SET field1 = new-value1, field2 = new-value2 [WHERE Clause]
- 您可以同時更新一個或多個欄位。
- 您可以使用 WHERE 子句指定任何條件。
- 您可以一次更新單個表中的值。
示例
讓我們考慮一個將教程的標題從“Learn C”更新為“C and Data Structures”且 id 為“101”的示例。以下是更新查詢。
UPDATE tutorials_tbl SET title = 'C and Data Structures' WHERE id = 101;
執行上述查詢後,您將收到以下輸出。
(1) Rows effected
HSQLDB – JDBC 程式
以下是一個 JDBC 程式,它將 id 為101的教程標題從Learn C更新為C and Data Structures。將以下程式儲存到UpdateQuery.java檔案中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class UpdateQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate(
"UPDATE tutorials_tbl SET title = 'C and Data Structures' WHERE id = 101");
} catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println(result+" Rows effected");
}
}
您可以使用以下命令啟動資料庫。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令編譯並執行上述程式。
\>javac UpdateQuery.java \>java UpdateQuery
執行上述命令後,您將收到以下輸出 -
1 Rows effected
HSQLDB - DELETE 子句
每當您想要從任何 HSQLDB 表中刪除記錄時,都可以使用 DELETE FROM 命令。
語法
以下是用於從 HSQLDB 表中刪除資料的 DELETE 命令的通用語法。
DELETE FROM table_name [WHERE Clause]
如果未指定 WHERE 子句,則將從給定的 MySQL 表中刪除所有記錄。
您可以使用 WHERE 子句指定任何條件。
您可以一次刪除單個表中的記錄。
示例
讓我們考慮一個從名為tutorials_tbl的表中刪除 id 為105的記錄資料的示例。以下是實現給定示例的查詢。
DELETE FROM tutorials_tbl WHERE id = 105;
執行上述查詢後,您將收到以下輸出 -
(1) rows effected
HSQLDB – JDBC 程式
以下是一個實現給定示例的 JDBC 程式。將以下程式儲存到DeleteQuery.java中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class DeleteQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate(
"DELETE FROM tutorials_tbl WHERE id=105");
} catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println(result+" Rows effected");
}
}
您可以使用以下命令啟動資料庫。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令編譯並執行上述程式。
\>javac DeleteQuery.java \>java DeleteQuery
執行上述命令後,您將收到以下輸出 -
1 Rows effected
HSQLDB - LIKE 子句
RDBMS 結構中有一個 WHERE 子句。您可以將 WHERE 子句與等號 (=) 一起使用,在需要進行精確匹配時使用。但可能存在需要過濾所有作者姓名包含“john”的結果的情況。這可以使用 SQL LIKE 子句以及 WHERE 子句來處理。
如果 SQL LIKE 子句與 % 字元一起使用,那麼它在列出命令提示符下所有檔案或目錄時將類似於 UNIX 中的萬用字元 (*)。
語法
以下是 LIKE 子句的通用 SQL 語法。
SELECT field1, field2,...fieldN table_name1, table_name2... WHERE field1 LIKE condition1 [AND [OR]] filed2 = 'somevalue'
您可以使用 WHERE 子句指定任何條件。
您可以將 LIKE 子句與 WHERE 子句一起使用。
您可以將 LIKE 子句替換為等號。
當 LIKE 子句與 % 符號一起使用時,它將類似於元字元搜尋。
您可以使用 AND 或 OR 運算子指定多個條件。
WHERE...LIKE 子句可以與 DELETE 或 UPDATE SQL 命令一起使用以指定條件。
示例
讓我們考慮一個檢索作者姓名以John開頭的教程資料列表的示例。以下是給定示例的 HSQLDB 查詢。
SELECT * from tutorials_tbl WHERE author LIKE 'John%';
執行上述查詢後,您將收到以下輸出。
+-----+----------------+-----------+-----------------+ | id | title | author | submission_date | +-----+----------------+-----------+-----------------+ | 100 | Learn PHP | John Poul | 2016-06-20 | +-----+----------------+-----------+-----------------+
HSQLDB – JDBC 程式
以下是一個 JDBC 程式,它檢索作者姓名以John開頭的教程資料列表。將程式碼儲存到LikeClause.java中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class LikeClause {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT * from tutorials_tbl WHERE author LIKE 'John%';");
while(result.next()){
System.out.println(result.getInt("id")+" |
"+result.getString("title")+" |
"+result.getString("author")+" |
"+result.getDate("submission_date"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
您可以使用以下命令啟動資料庫。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令編譯並執行上述程式碼。
\>javac LikeClause.java \>java LikeClause
執行以下命令後,您將收到以下輸出。
100 | Learn PHP | John Poul | 2016-06-20
HSQLDB - 排序結果
每當需要按照特定順序檢索和顯示記錄時,SQL SELECT 命令都會從 HSQLDB 表中獲取資料。在這種情況下,我們可以使用ORDER BY子句。
語法
以下是使用 ORDER BY 子句對 HSQLDB 中的資料進行排序的 SELECT 命令的語法。
SELECT field1, field2,...fieldN table_name1, table_name2... ORDER BY field1, [field2...] [ASC [DESC]]
您可以對返回的結果中的任何欄位進行排序,前提是該欄位已列出。
您可以對多個欄位進行排序。
您可以使用關鍵字 ASC 或 DESC 以升序或降序獲取結果。預設情況下,它是升序。
您可以像往常一樣使用 WHERE...LIKE 子句來設定條件。
示例
讓我們考慮一個獲取並對tutorials_tbl表中的記錄進行排序的示例,方法是按升序對作者姓名進行排序。以下是相同的查詢。
SELECT id, title, author from tutorials_tbl ORDER BY author ASC;
執行上述查詢後,您將收到以下輸出。
+------+----------------+-----------------+ | id | title | author | +------+----------------+-----------------+ | 102 | Learn MySQL | Abdul S | | 104 | Learn JDB | Ajith kumar | | 103 | Learn Excell | Bavya kanna | | 100 | Learn PHP | John Poul | | 105 | Learn Junit | Sathya Murthi | | 101 | Learn C | Yaswanth | +------+----------------+-----------------+
HSQLDB – JDBC 程式
以下是一個 JDBC 程式,它獲取並對tutorials_tbl表中的記錄進行排序,方法是按升序對作者姓名進行排序。將以下程式儲存到OrderBy.java中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class OrderBy {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT id, title, author from tutorials_tbl
ORDER BY author ASC");
while(result.next()){
System.out.println(result.getInt("id")+" |
"+result.getString("title")+" |
"+result.getString("author"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
您可以使用以下命令啟動資料庫。
\>cd C:\hsqldb-2.3.4\hsqldb hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0 file:hsqldb/demodb --dbname.0 testdb
使用以下命令編譯並執行上述程式。
\>javac OrderBy.java \>java OrderBy
執行上述命令後,您將收到以下輸出。
102 | Learn MySQL | Abdul S 104 | Learn JDB | Ajith kumar 103 | Learn Excell | Bavya Kanna 100 | Learn PHP | John Poul 105 | Learn Junit | Sathya Murthi 101 | C and Data Structures | Yaswanth
HSQLDB - 連線
每當需要使用單個查詢從多個表中檢索資料時,您可以使用 RDBMS 中的連線。您可以在單個 SQL 查詢中使用多個表。HSQLDB 中的連線行為是指將兩個或多個表合併成一個表。
請考慮以下 Customers 和 Orders 表。
Customer: +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+ Orders: +-----+---------------------+-------------+--------+ |OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
現在,讓我們嘗試檢索客戶的資料以及相應客戶下的訂單金額。這意味著我們正在從 Customers 和 Orders 表中檢索記錄資料。我們可以透過在 HSQLDB 中使用連線的概念來實現這一點。以下是相同的連線查詢。
SELECT ID, NAME, AGE, AMOUNT FROM CUSTOMERS, ORDERS WHERE CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
執行上述查詢後,您將收到以下輸出。
+----+----------+-----+--------+ | ID | NAME | AGE | AMOUNT | +----+----------+-----+--------+ | 3 | kaushik | 23 | 3000 | | 3 | kaushik | 23 | 1500 | | 2 | Khilan | 25 | 1560 | | 4 | Chaitali | 25 | 2060 | +----+----------+-----+--------+
連線型別
HSQLDB 中有不同型別的連線可用。
INNER JOIN − 當兩個表中都存在匹配項時返回行。
LEFT JOIN − 返回左側表中的所有行,即使右側表中不存在匹配項。
RIGHT JOIN − 返回右側表中的所有行,即使左側表中不存在匹配項。
FULL JOIN − 當其中一個表中存在匹配項時返回行。
SELF JOIN − 用於將表自身連線起來,就像該表是兩個表一樣,在 SQL 語句中至少臨時重新命名一個表。
內部連線
連線中最常用和最重要的連線是 INNER JOIN。它也稱為 EQUIJOIN。
INNER JOIN 透過根據連線謂詞組合兩個表(table1 和 table2)的列值來建立一個新的結果表。查詢將 table1 的每一行與 table2 的每一行進行比較,以查詢滿足連線謂詞的所有行對。當連線謂詞滿足時,每個匹配的行對 A 和 B 的列值將組合到結果行中。
語法
INNER JOIN 的基本語法如下所示。
SELECT table1.column1, table2.column2... FROM table1 INNER JOIN table2 ON table1.common_field = table2.common_field;
示例
請考慮以下兩個表,一個名為 CUSTOMERS 表,另一個名為 ORDERS 表,如下所示 -
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
+-----+---------------------+-------------+--------+ | OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
現在,讓我們使用 INNER JOIN 查詢連線這兩個表,如下所示 -
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS INNER JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
執行上述查詢後,您將收到以下輸出。
+----+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +----+----------+--------+---------------------+ | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +----+----------+--------+---------------------+
左連線
HSQLDB LEFT JOIN 返回左側表中的所有行,即使右側表中不存在匹配項。這意味著,如果 ON 子句在右側表中匹配 0(零)條記錄,則連線仍將在結果中返回一行,但在右側表中的每一列中都為 NULL。
這意味著左連線返回左側表中的所有值,加上右側表中的匹配值,或者在沒有匹配連線謂詞的情況下返回 NULL。
語法
LEFT JOIN 的基本語法如下所示 -
SELECT table1.column1, table2.column2... FROM table1 LEFT JOIN table2 ON table1.common_field = table2.common_field;
這裡給定的條件可以是基於您的需求的任何給定表示式。
示例
請考慮以下兩個表,一個名為 CUSTOMERS 表,另一個名為 ORDERS 表,如下所示 -
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
+-----+---------------------+-------------+--------+ | OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
現在,讓我們使用 LEFT JOIN 查詢連線這兩個表,如下所示 -
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS LEFT JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
執行上述查詢後,您將收到以下輸出 -
+----+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +----+----------+--------+---------------------+ | 1 | Ramesh | NULL | NULL | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | | 5 | Hardik | NULL | NULL | | 6 | Komal | NULL | NULL | | 7 | Muffy | NULL | NULL | +----+----------+--------+---------------------+
右連線
HSQLDB RIGHT JOIN 返回右側表中的所有行,即使左側表中不存在匹配項。這意味著,如果 ON 子句在左側表中匹配 0(零)條記錄,則連線仍將在結果中返回一行,但在左側表中的每一列中都為 NULL。
這意味著右連線返回右側表中的所有值,加上左側表中的匹配值,或者在沒有匹配連線謂詞的情況下返回 NULL。
語法
RIGHT JOIN 的基本語法如下所示 -
SELECT table1.column1, table2.column2... FROM table1 RIGHT JOIN table2 ON table1.common_field = table2.common_field;
示例
請考慮以下兩個表,一個名為 CUSTOMERS 表,另一個名為 ORDERS 表,如下所示 -
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
+-----+---------------------+-------------+--------+ | OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
現在,讓我們使用 RIGHT JOIN 查詢連線這兩個表,如下所示 -
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS RIGHT JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
執行上述查詢後,您將收到以下結果。
+------+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +------+----------+--------+---------------------+ | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +------+----------+--------+---------------------+
全連線
HSQLDB FULL JOIN 組合了左右外連線的結果。
連線的表將包含兩個表中的所有記錄,並在任一側的缺失匹配項中填充 NULL。
語法
FULL JOIN 的基本語法如下所示 -
SELECT table1.column1, table2.column2... FROM table1 FULL JOIN table2 ON table1.common_field = table2.common_field;
這裡給定的條件可以是基於您的需求的任何給定表示式。
示例
請考慮以下兩個表,一個名為 CUSTOMERS 表,另一個名為 ORDERS 表,如下所示 -
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
+-----+---------------------+-------------+--------+ | OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
現在,讓我們使用以下 FULL JOIN 查詢將這兩個表連線起來:
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS FULL JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
執行上述查詢後,您將收到以下結果。
+------+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +------+----------+--------+---------------------+ | 1 | Ramesh | NULL | NULL | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | | 5 | Hardik | NULL | NULL | | 6 | Komal | NULL | NULL | | 7 | Muffy | NULL | NULL | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +------+----------+--------+---------------------+
自連線
SQL 自連線用於將表自身連線起來,就好像該表是兩個表一樣,在 SQL 語句中至少臨時重新命名一個表。
語法
自連線的基本語法如下:
SELECT a.column_name, b.column_name... FROM table1 a, table1 b WHERE a.common_field = b.common_field;
這裡,WHERE 子句可以是根據您的要求給出的任何表示式。
示例
請考慮以下兩個表,一個名為 CUSTOMERS 表,另一個名為 ORDERS 表,如下所示 -
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
現在,讓我們使用以下 SELF JOIN 查詢將此表連線起來:
SELECT a.ID, b.NAME, a.SALARY FROM CUSTOMERS a, CUSTOMERS b WHERE a.SALARY > b.SALARY;
執行上述查詢後,您將收到以下輸出 -
+----+----------+---------+ | ID | NAME | SALARY | +----+----------+---------+ | 2 | Ramesh | 1500.00 | | 2 | kaushik | 1500.00 | | 1 | Chaitali | 2000.00 | | 2 | Chaitali | 1500.00 | | 3 | Chaitali | 2000.00 | | 6 | Chaitali | 4500.00 | | 1 | Hardik | 2000.00 | | 2 | Hardik | 1500.00 | | 3 | Hardik | 2000.00 | | 4 | Hardik | 6500.00 | | 6 | Hardik | 4500.00 | | 1 | Komal | 2000.00 | | 2 | Komal | 1500.00 | | 3 | Komal | 2000.00 | | 1 | Muffy | 2000.00 | | 2 | Muffy | 1500.00 | | 3 | Muffy | 2000.00 | | 4 | Muffy | 6500.00 | | 5 | Muffy | 8500.00 | | 6 | Muffy | 4500.00 | +----+----------+---------+
HsqlDB - 空值
SQL NULL 是一個用於表示缺失值的術語。表中的 NULL 值是指欄位中看起來為空的值。每當我們嘗試給出比較欄位或列值與 NULL 的條件時,它都不能正常工作。
我們可以使用以下三種方法處理 NULL 值。
IS NULL - 如果列值為 NULL,則該運算子返回 true。
IS NOT NULL - 如果列值不為 NULL,則該運算子返回 true。
<=> - 該運算子比較值,即使對於兩個 NULL 值,它也返回 true(與 = 運算子不同)。
要查詢為 NULL 或不為 NULL 的列,請分別使用 IS NULL 或 IS NOT NULL。
示例
讓我們考慮一個示例,其中有一個名為 tcount_tbl 的表,其中包含兩列,作者和教程計數。我們可以為教程計數提供 NULL 值,表示作者甚至沒有釋出一篇教程。因此,相應作者的教程計數值為 NULL。
執行以下查詢。
create table tcount_tbl(author varchar(40) NOT NULL, tutorial_count INT);
INSERT INTO tcount_tbl values ('Abdul S', 20);
INSERT INTO tcount_tbl values ('Ajith kumar', 5);
INSERT INTO tcount_tbl values ('Jen', NULL);
INSERT INTO tcount_tbl values ('Bavya kanna', 8);
INSERT INTO tcount_tbl values ('mahran', NULL);
INSERT INTO tcount_tbl values ('John Poul', 10);
INSERT INTO tcount_tbl values ('Sathya Murthi', 6);
使用以下命令顯示 tcount_tbl 表中的所有記錄。
select * from tcount_tbl;
執行上述命令後,您將收到以下輸出。
+-----------------+----------------+ | author | tutorial_count | +-----------------+----------------+ | Abdul S | 20 | | Ajith kumar | 5 | | Jen | NULL | | Bavya kanna | 8 | | mahran | NULL | | John Poul | 10 | | Sathya Murthi | 6 | +-----------------+----------------+
要查詢教程計數列為 NULL 的記錄,以下是查詢。
SELECT * FROM tcount_tbl WHERE tutorial_count IS NULL;
查詢執行後,您將收到以下輸出。
+-----------------+----------------+ | author | tutorial_count | +-----------------+----------------+ | Jen | NULL | | mahran | NULL | +-----------------+----------------+
要查詢教程計數列不為 NULL 的記錄,以下是查詢。
SELECT * FROM tcount_tbl WHERE tutorial_count IS NOT NULL;
查詢執行後,您將收到以下輸出。
+-----------------+----------------+ | author | tutorial_count | +-----------------+----------------+ | Abdul S | 20 | | Ajith kumar | 5 | | Bavya kanna | 8 | | John Poul | 10 | | Sathya Murthi | 6 | +-----------------+----------------+
HSQLDB – JDBC 程式
這是一個 JDBC 程式,它分別從 tcount_tbl 表中檢索記錄,其中教程計數為 NULL 和教程計數不為 NULL。將以下程式儲存到 NullValues.java 中。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class NullValues {
public static void main(String[] args) {
Connection con = null;
Statement stmt_is_null = null;
Statement stmt_is_not_null = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql:///testdb", "SA", "");
stmt_is_null = con.createStatement();
stmt_is_not_null = con.createStatement();
result = stmt_is_null.executeQuery(
"SELECT * FROM tcount_tbl WHERE tutorial_count IS NULL;");
System.out.println("Records where the tutorial_count is NULL");
while(result.next()){
System.out.println(result.getString("author")+" |
"+result.getInt("tutorial_count"));
}
result = stmt_is_not_null.executeQuery(
"SELECT * FROM tcount_tbl WHERE tutorial_count IS NOT NULL;");
System.out.println("Records where the tutorial_count is NOT NULL");
while(result.next()){
System.out.println(result.getString("author")+" |
"+result.getInt("tutorial_count"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}
使用以下命令編譯並執行上述程式。
\>javac NullValues.java \>Java NullValues
執行上述命令後,您將收到以下輸出。
Records where the tutorial_count is NULL Jen | 0 mahran | 0 Records where the tutorial_count is NOT NULL Abdul S | 20 Ajith kumar | 5 Bavya kanna | 8 John Poul | 10 Sathya Murthi | 6
HSQLDB - 正則表示式
HSQLDB 支援一些基於正則表示式的模式匹配操作的特殊符號和 REGEXP 運算子。
以下是模式表,可與 REGEXP 運算子一起使用。
| 模式 | 模式匹配的內容 |
|---|---|
| ^ | 字串的開頭 |
| $ | 字串的結尾 |
| . | 任何單個字元 |
| [...] | 方括號之間列出的任何字元 |
| [^...] | 方括號之間未列出的任何字元 |
| p1|p2|p3 | 替換;匹配模式 p1、p2 或 p3 中的任何一個 |
| * | 前一個元素的零個或多個例項 |
| + | 前一個元素的一個或多個例項 |
| {n} | 前一個元素的 n 個例項 |
| {m,n} | 前一個元素的 m 到 n 個例項 |
示例
讓我們嘗試不同的示例查詢以滿足我們的需求。請檢視以下給定的查詢。
嘗試此查詢以查詢所有以 '^A' 開頭的作者姓名。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'^A.*');
執行上述查詢後,您將收到以下輸出。
+-----------------+ | author | +-----------------+ | Abdul S | | Ajith kumar | +-----------------+
嘗試此查詢以查詢所有以 'ul$' 結尾的作者姓名。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'.*ul$');
執行上述查詢後,您將收到以下輸出。
+-----------------+ | author | +-----------------+ | John Poul | +-----------------+
嘗試此查詢以查詢所有作者姓名中包含 'th' 的作者。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'.*th.*');
執行上述查詢後,您將收到以下輸出。
+-----------------+ | author | +-----------------+ | Ajith kumar | | Abdul S | +-----------------+
嘗試此查詢以查詢所有作者姓名以母音(a、e、i、o、u)開頭的作者。
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'^[AEIOU].*');
執行上述查詢後,您將收到以下輸出。
+-----------------+ | author | +-----------------+ | Abdul S | | Ajith kumar | +-----------------+
HSQLDB - 事務
事務是一組按順序執行的資料庫操作,這些操作被視為一個工作單元。換句話說,只有在所有操作都成功執行後,整個事務才算完成。如果事務中的任何操作失敗,則整個事務將失敗。
事務的屬性
基本上,事務支援 4 個標準屬性。它們可以被稱為 ACID 屬性。
原子性 - 事務中的所有操作都成功執行,否則事務將在失敗點中止,並且之前的操作將回滾到其先前的位置。
一致性 - 資料庫在成功提交的事務後會正確更改狀態。
隔離性 - 它使事務能夠獨立於彼此並對其透明地執行。
永續性 - 提交的事務的結果或影響在系統故障的情況下仍然存在。
提交、回滾和儲存點
這些關鍵字主要用於 HSQLDB 事務。
提交 - 成功的事務應始終透過執行 COMMIT 命令來完成。
回滾 - 如果事務中發生錯誤,則應執行 ROLLBACK 命令以將事務中引用的每個表返回到其先前狀態。
儲存點 - 在事務組中建立一個要回滾到的點。
示例
以下示例解釋了事務概念以及提交、回滾和儲存點。讓我們考慮一個名為 Customers 的表,其中包含 id、name、age、address 和 salary 列。
| Id | 姓名 | 年齡 | 地址 | 薪資 |
|---|---|---|---|---|
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Karun | 25 | Delhi | 1500.00 |
| 3 | Kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitanya | 25 | Mumbai | 6500.00 |
| 5 | Harish | 27 | Bhopal | 8500.00 |
| 6 | Kamesh | 22 | MP | 1500.00 |
| 7 | Murali | 24 | Indore | 10000.00 |
使用以下命令建立客戶表,並遵循上述資料。
CREATE TABLE Customer (id INT NOT NULL, name VARCHAR(100) NOT NULL, age INT NOT NULL, address VARCHAR(20), Salary INT, PRIMARY KEY (id)); Insert into Customer values (1, "Ramesh", 32, "Ahmedabad", 2000); Insert into Customer values (2, "Karun", 25, "Delhi", 1500); Insert into Customer values (3, "Kaushik", 23, "Kota", 2000); Insert into Customer values (4, "Chaitanya", 25, "Mumbai", 6500); Insert into Customer values (5, "Harish", 27, "Bhopal", 8500); Insert into Customer values (6, "Kamesh", 22, "MP", 1500); Insert into Customer values (7, "Murali", 24, "Indore", 10000);
COMMIT 示例
以下查詢從表中刪除年齡為 25 的行,並使用 COMMIT 命令將這些更改應用到資料庫中。
DELETE FROM CUSTOMERS WHERE AGE = 25; COMMIT;
執行上述查詢後,您將收到以下輸出。
2 rows effected
成功執行上述命令後,透過執行以下命令檢查客戶表的記錄。
Select * from Customer;
執行上述查詢後,您將收到以下輸出。
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000 | | 3 | kaushik | 23 | Kota | 2000 | | 5 | Harish | 27 | Bhopal | 8500 | | 6 | Kamesh | 22 | MP | 4500 | | 7 | Murali | 24 | Indore | 10000 | +----+----------+-----+-----------+----------+
回滾示例
讓我們考慮將相同的 Customer 表作為輸入。
| Id | 姓名 | 年齡 | 地址 | 薪資 |
|---|---|---|---|---|
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Karun | 25 | Delhi | 1500.00 |
| 3 | Kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitanya | 25 | Mumbai | 6500.00 |
| 5 | Harish | 27 | Bhopal | 8500.00 |
| 6 | Kamesh | 22 | MP | 1500.00 |
| 7 | Murali | 24 | Indore | 10000.00 |
這是一個示例查詢,它解釋了透過從表中刪除年齡為 25 的記錄,然後回滾資料庫中的更改來解釋回滾功能。
DELETE FROM CUSTOMERS WHERE AGE = 25; ROLLBACK;
成功執行上述兩個查詢後,您可以使用以下命令檢視 Customer 表中的記錄資料。
Select * from Customer;
執行上述命令後,您將收到以下輸出。
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000 | | 2 | Karun | 25 | Delhi | 1500 | | 3 | Kaushik | 23 | Kota | 2000 | | 4 | Chaitanya| 25 | Mumbai | 6500 | | 5 | Harish | 27 | Bhopal | 8500 | | 6 | Kamesh | 22 | MP | 4500 | | 7 | Murali | 24 | Indore | 10000 | +----+----------+-----+-----------+----------+
delete 查詢刪除了年齡為 25 的客戶的記錄資料。Rollback 命令將這些更改回滾到 Customer 表上。
儲存點示例
儲存點是在事務中可以將事務回滾到某個點而不回滾整個事務的點。
讓我們考慮將相同的 Customer 表作為輸入。
| Id | 姓名 | 年齡 | 地址 | 薪資 |
|---|---|---|---|---|
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Karun | 25 | Delhi | 1500.00 |
| 3 | Kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitanya | 25 | Mumbai | 6500.00 |
| 5 | Harish | 27 | Bhopal | 8500.00 |
| 6 | Kamesh | 22 | MP | 1500.00 |
| 7 | Murali | 24 | Indore | 10000.00 |
讓我們考慮在這個例子中,您計劃從 Customers 表中刪除三個不同的記錄。您希望在每次刪除之前建立一個儲存點,以便您可以隨時回滾到任何儲存點以將適當的資料返回到其原始狀態。
這是一系列操作。
SAVEPOINT SP1; DELETE FROM CUSTOMERS WHERE ID = 1; SAVEPOINT SP2; DELETE FROM CUSTOMERS WHERE ID = 2; SAVEPOINT SP3; DELETE FROM CUSTOMERS WHERE ID = 3;
現在,您已建立了三個儲存點並刪除了三個記錄。在這種情況下,如果您想回滾 ID 為 2 和 3 的記錄,請使用以下回滾命令。
ROLLBACK TO SP2;
請注意,由於您已回滾到 SP2,因此僅執行了第一次刪除。使用以下查詢顯示客戶的所有記錄。
Select * from Customer;
執行上述查詢後,您將收到以下輸出。
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 2 | Karun | 25 | Delhi | 1500 | | 3 | Kaushik | 23 | Kota | 2000 | | 4 | Chaitanya| 25 | Mumbai | 6500 | | 5 | Harish | 27 | Bhopal | 8500 | | 6 | Kamesh | 22 | MP | 4500 | | 7 | Murali | 24 | Indore | 10000 | +----+----------+-----+-----------+----------+
釋放儲存點
我們可以使用 RELEASE 命令釋放儲存點。以下是通用語法。
RELEASE SAVEPOINT SAVEPOINT_NAME;
HsqlDB - ALTER 命令
每當需要更改表或欄位的名稱、更改欄位的順序、更改欄位的資料型別或任何表結構時,您都可以使用 ALTER 命令來實現。
示例
讓我們考慮一個使用不同場景解釋 ALTER 命令的示例。
使用以下查詢建立一個名為 testalter_tbl 的表,其中包含欄位 id 和 name。
//below given query is to create a table testalter_tbl table. create table testalter_tbl(id INT, name VARCHAR(10)); //below given query is to verify the table structure testalter_tbl. Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM = 'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';
執行上述查詢後,您將收到以下輸出。
+------------+-------------+------------+-----------+-----------+------------+ |TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE| +------------+-------------+------------+-----------+-----------+------------+ | PUBLIC |TESTALTER_TBL| ID | 4 | INTEGER | 4 | | PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 10 | +------------+-------------+------------+-----------+-----------+------------+
刪除或新增列
每當您想從 HSQLDB 表中刪除現有列時,您可以將 DROP 子句與 ALTER 命令一起使用。
使用以下查詢從 testalter_tbl 表中刪除列 (name)。
ALTER TABLE testalter_tbl DROP name;
成功執行上述查詢後,您可以使用以下命令瞭解 name 欄位是否已從 testalter_tbl 表中刪除。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM = 'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';
執行上述命令後,您將收到以下輸出。
+------------+-------------+------------+-----------+-----------+------------+ |TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE| +------------+-------------+------------+-----------+-----------+------------+ | PUBLIC |TESTALTER_TBL| ID | 4 | INTEGER | 4 | +------------+-------------+------------+-----------+-----------+------------+
每當您想向 HSQLDB 表中新增任何列時,您可以將 ADD 子句與 ALTER 命令一起使用。
使用以下查詢向 testalter_tbl 表新增一個名為 NAME 的列。
ALTER TABLE testalter_tbl ADD name VARCHAR(10);
成功執行上述查詢後,您可以使用以下命令瞭解 name 欄位是否已新增到 testalter_tbl 表中。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM = 'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';
執行上述查詢後,您將收到以下輸出。
+------------+-------------+------------+-----------+-----------+------------+ |TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE| +------------+-------------+------------+-----------+-----------+------------+ | PUBLIC |TESTALTER_TBL| ID | 4 | INTEGER | 4 | | PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 10 | +------------+-------------+------------+-----------+-----------+------------+
更改列定義或名稱
每當需要更改列定義時,請將 MODIFY 或 CHANGE 子句與 ALTER 命令一起使用。
讓我們考慮一個示例,它將說明如何使用 CHANGE 子句。testalter_tbl 表包含兩個欄位 - id 和 name - 它們的資料型別分別為 int 和 varchar。現在讓我們嘗試將 id 的資料型別從 INT 更改為 BIGINT。以下是進行更改的查詢。
ALTER TABLE testalter_tbl CHANGE id id BIGINT;
成功執行上述查詢後,可以使用以下命令驗證表結構。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM = 'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';
執行上述命令後,您將收到以下輸出。
+------------+-------------+------------+-----------+-----------+------------+ |TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE| +------------+-------------+------------+-----------+-----------+------------+ | PUBLIC |TESTALTER_TBL| ID | 4 | BIGINT | 4 | | PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 10 | +------------+-------------+------------+-----------+-----------+------------+
現在讓我們嘗試將 testalter_tbl 表中列 NAME 的大小從 10 增加到 20。以下是使用 MODIFY 子句以及 ALTER 命令實現此目的的查詢。
ALTER TABLE testalter_tbl MODIFY name VARCHAR(20);
成功執行上述查詢後,可以使用以下命令驗證表結構。
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM = 'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';
執行上述命令後,您將收到以下輸出。
+------------+-------------+------------+-----------+-----------+------------+ |TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE| +------------+-------------+------------+-----------+-----------+------------+ | PUBLIC |TESTALTER_TBL| ID | 4 | BIGINT | 4 | | PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 20 | +------------+-------------+------------+-----------+-----------+------------+
HSQLDB - 索引
資料庫索引是一種資料結構,可以提高表中操作的速度。可以使用一個或多個列建立索引,為快速隨機查詢和有效排序對記錄的訪問提供基礎。
建立索引時,應考慮哪些列將用於執行 SQL 查詢,並在這些列上建立一個或多個索引。
實際上,索引也是一種型別的表,它儲存主鍵或索引欄位以及指向實際表中每個記錄的指標。
使用者無法看到索引。它們僅用於加快查詢速度,並將由資料庫搜尋引擎用於快速定位記錄。
在具有索引的表上,INSERT 和 UPDATE 語句需要更多時間,而 SELECT 語句在這些表上執行速度更快。原因是在插入或更新時,資料庫也需要插入或更新索引值。
簡單索引和唯一索引
您可以在表上建立唯一索引。唯一索引表示兩行不能具有相同的索引值。以下是建立表索引的語法。
CREATE UNIQUE INDEX index_name ON table_name (column1, column2,...);
您可以使用一個或多個列來建立索引。例如,使用 tutorial_author 在 tutorials_tbl 上建立索引。
CREATE UNIQUE INDEX AUTHOR_INDEX ON tutorials_tbl (tutorial_author)
您可以在表上建立簡單索引。只需從查詢中省略 UNIQUE 關鍵字即可建立簡單索引。簡單索引允許表中存在重複值。
如果要以降序排列列中的值,可以在列名後新增保留字 DESC。
CREATE UNIQUE INDEX AUTHOR_INDEX ON tutorials_tbl (tutorial_author DESC)
ALTER 命令新增和刪除索引
有四種類型的語句用於向表中新增索引:
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list) - 此語句新增主鍵,這意味著索引值必須唯一且不能為 NULL。
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list) - 此語句建立一個索引,該索引的值必須唯一(除了 NULL 值,它可以多次出現)。
ALTER TABLE tbl_name ADD INDEX index_name (column_list) - 這將在其中任何值都可能出現多次的情況下新增普通索引。
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list) - 這將建立一個用於文字搜尋目的的特殊 FULLTEXT 索引。
以下是向現有表中新增索引的查詢。
ALTER TABLE testalter_tbl ADD INDEX (c);
您可以使用 DROP 子句以及 ALTER 命令刪除任何索引。以下是刪除上述建立的索引的查詢。
ALTER TABLE testalter_tbl DROP INDEX (c);
顯示索引資訊
您可以使用 SHOW INDEX 命令列出與表關聯的所有索引。對於此語句,垂直格式輸出(由 \G 指定)通常很有用,以避免長行換行。
以下是顯示錶索引資訊的通用語法。
SHOW INDEX FROM table_name\G