
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何處理機器學習中的類別不平衡問題
在本教程中,我們將學習如何在 ML 中處理類別不平衡問題。
介紹
一般來說,機器學習中的類別不平衡是指一種型別或觀測值的類別數量高於另一種型別的情況。這是機器學習中的一個常見問題,涉及諸如欺詐檢測、廣告點選率預測、垃圾郵件檢測、客戶流失等任務。它對模型的準確性有很大影響。
類別不平衡的影響
在這種問題中,多數類在訓練模型時會掩蓋少數類。由於在這種情況下,與其他類別相比,一種類別的數量非常高(通常< 0.05%),因此訓練出的模型大多會預測多數類。這會對準確性產生不利影響,結果容易出錯。
那麼,我們如何解決這個問題呢?讓我們深入瞭解一些已被證明有效的技術。
如何處理類別不平衡
有 5 種方法可以用來處理類別不平衡問題。
1. 隨機欠取樣
在信用卡欺詐檢測系統中,我們經常面臨類別不平衡的問題,因為欺詐交易的數量非常低(有時不到 1%)。隨機欠取樣是一種簡單的處理此問題的技術。在這種方法中,從多數類中刪除大量資料點,以便平衡少數類。多數類和少數類的比例相當。
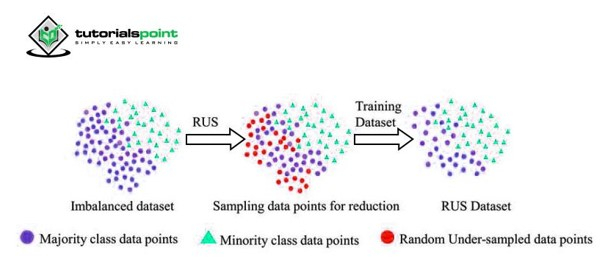
當我們有大量資料時,此方法非常有用。
此方法的一個缺點是它可能導致大量資訊丟失,並可能產生不太準確的模型。
2. 隨機過取樣
在這種方法中,少數類被複制多次(以固定的整數比例),以便平衡多數類。我們應該記住在過取樣之前使用 K 折交叉驗證,以便在資料中引入適當的隨機性以防止過擬合。
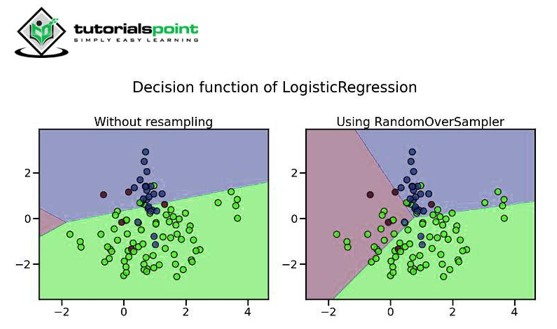
當我們只有少量資料時,此方法非常有用。
此方法的缺點是它可能導致過擬合,並且生成的模型不會很好地泛化。
3. 合成少數類過取樣技術 (SMOTE)
SMOTE 是一種統計技術,可以以平衡的方式增加少數類中的樣本。它從現有的少數類中生成新例項。它不會影響多數類。該演算法從目標類及其 k 個最近鄰中獲取樣本。然後,它透過結合目標類及其鄰居的特徵來建立樣本。
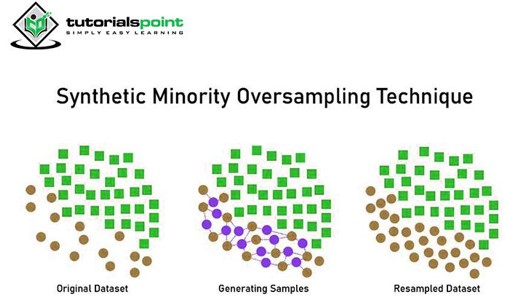
SMOTE 的優點是我們不僅僅是複製少數類,而是建立與原始樣本不同的合成數據點。
SMOTE 有幾個缺點:
很難確定最近鄰的數量,並且最近鄰的選擇並不準確。
它可能會對噪聲樣本進行過取樣。
4. 整合學習
在這種方法中,我們使用多個學習器或組合多個分類器的結果來產生所需的結果。事實證明,很多時候多個學習器比單個學習器產生更好的結果。
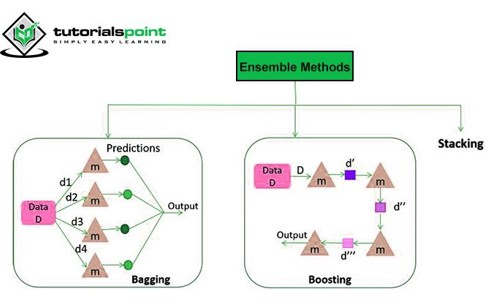
涉及的兩種方法是 Bagging 和 Boosting。
Bagging
Bagging 方法被稱為 Bootstrap 聚合。Bootstrap 是從總體中建立資料樣本以估計總體引數的方法。在 Bagging 中,小型分類器是在從具有替換的資料集中獲取的資料樣本上進行訓練的。然後聚合這些分類器的預測以產生最終結果。
Boosting
這是一種透過根據最近的分類調整觀測值的權重來減少預測誤差的方法。它傾向於增加錯誤分類觀測值的權重。此模型根據先前模型產生的錯誤進行訓練。這種迭代方法是高度並行的。
Bagging 的一個優點是它減少了模型的方差誤差。
Boosting 的一個優點是它減少了模型的偏差誤差。
選擇正確的評估指標。
對於類別不平衡的資料集,選擇準確性作為評估引數可能會適得其反。更好的指標是精確率或召回率或組合指標,如 F1 分數。雖然準確性指標似乎由於類別比例不當而受到不利影響,但精確率/召回率/F1 分數似乎能夠很好地處理這個問題,如下面的關係式所示:
$$\mathrm{精確率 \:=\: \frac{真陽性}{真陽性\:+\:假陽性}}$$ $$\mathrm{召回率 \:=\: \frac{真陽性}{真陽性\:+\:假陰性}}$$F1 分數考慮了進行了多少正確的分類。
$$\mathrm{F1\:分數 \:=\: \frac{2\:*\:精確率\:*\:召回率}{精確率\:+\:召回率}}$$結論
因此,我們看到了類別不平衡如何嚴重影響基於模型效能的預測。處理此類問題有時可能會很繁瑣,但正如我們在本文中所看到的,正確的技術結合適當的評估指標可以解決這個問題,從而提高模型預測的質量。

367 次檢視
