- Hive 教程
- Hive - 首頁
- Hive - 簡介
- Hive - 安裝
- Hive - 資料型別
- Hive - 建立資料庫
- Hive - 刪除資料庫
- Hive - 建立表
- Hive - 修改表
- Hive - 刪除表
- Hive - 分割槽
- Hive - 內建運算子
- Hive - 內建函式
- Hive - 檢視和索引
- HiveQL
- HiveQL - Select Where
- HiveQL - Select Order By
- HiveQL - Select Group By
- HiveQL - Select Joins
- Hive 有用資源
- Hive - 問題與解答
- Hive 快速指南
- Hive - 有用資源
Hive 快速指南
Hive - 簡介
術語“大資料”用於指代包含海量資料、高速資料和種類繁多的資料集的集合,這些資料日益增多。使用傳統的資料管理系統很難處理大資料。因此,Apache 軟體基金會引入了一個名為 Hadoop 的框架來解決大資料管理和處理的挑戰。
Hadoop
Hadoop 是一個開源框架,用於在分散式環境中儲存和處理大資料。它包含兩個模組,一個是 MapReduce,另一個是 Hadoop 分散式檔案系統 (HDFS)。
MapReduce:它是一種並行程式設計模型,用於在大型商品硬體叢集上處理大量結構化、半結構化和非結構化資料。
HDFS:Hadoop 分散式檔案系統是 Hadoop 框架的一部分,用於儲存和處理資料集。它提供了一個容錯檔案系統,可在商品硬體上執行。
Hadoop 生態系統包含不同的子專案(工具),例如 Sqoop、Pig 和 Hive,這些工具用於幫助 Hadoop 模組。
Sqoop:它用於在 HDFS 和 RDBMS 之間匯入和匯出資料。
Pig:它是一個過程語言平臺,用於開發用於 MapReduce 操作的指令碼。
Hive:它是一個平臺,用於開發 SQL 型別指令碼以執行 MapReduce 操作。
注意:執行 MapReduce 操作有多種方法
- 使用 Java MapReduce 程式處理結構化、半結構化和非結構化資料的傳統方法。
- 使用 Pig 處理結構化和半結構化資料的 MapReduce 指令碼方法。
- 使用 Hive 處理結構化資料的 MapReduce 的 Hive 查詢語言 (HiveQL 或 HQL)。
什麼是 Hive
Hive 是一個數據倉庫基礎架構工具,用於處理 Hadoop 中的結構化資料。它位於 Hadoop 的頂部,用於彙總大資料,並簡化查詢和分析。
Hive 最初由 Facebook 開發,後來 Apache 軟體基金會接手並將其進一步開發為一個名為 Apache Hive 的開源專案。它被不同的公司使用。例如,亞馬遜在 Amazon Elastic MapReduce 中使用它。
Hive 不是
- 關係型資料庫
- 聯機事務處理 (OLTP) 的設計
- 用於即時查詢和行級更新的語言
Hive 的特性
- 它將模式儲存在資料庫中,並將處理後的資料儲存在 HDFS 中。
- 它專為 OLAP 設計。
- 它提供了一種名為 HiveQL 或 HQL 的 SQL 型別查詢語言。
- 它熟悉、快速、可擴充套件且可擴充套件。
Hive 的架構
以下元件圖描繪了 Hive 的架構
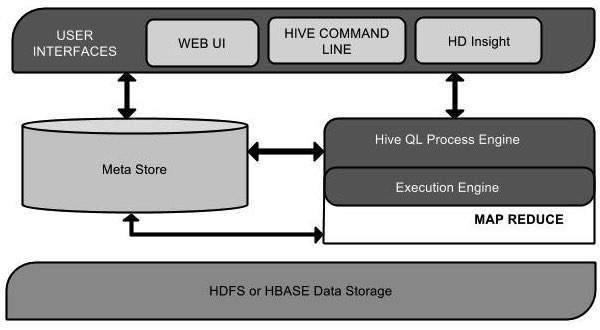
此元件圖包含不同的單元。下表描述了每個單元
| 單元名稱 | 操作 |
|---|---|
| 使用者介面 | Hive 是一種資料倉庫基礎架構軟體,可以建立使用者與 HDFS 之間的互動。Hive 支援的使用者介面包括 Hive Web UI、Hive 命令列和 Hive HD Insight(在 Windows 伺服器中)。 |
| 元資料儲存 | Hive 選擇相應的資料庫伺服器來儲存表的模式或元資料、資料庫、表中的列、它們的資料型別以及 HDFS 對映。 |
| HiveQL 處理引擎 | HiveQL 類似於 SQL,用於查詢元資料儲存上的模式資訊。它是傳統 MapReduce 程式方法的替代方法之一。我們可以編寫 MapReduce 作業的查詢並對其進行處理,而不是用 Java 編寫 MapReduce 程式。 |
| 執行引擎 | HiveQL 處理引擎和 MapReduce 的連線部分是 Hive 執行引擎。執行引擎處理查詢並生成與 MapReduce 結果相同的結果。它使用 MapReduce 的風格。 |
| HDFS 或 HBASE | Hadoop 分散式檔案系統或 HBASE 是將資料儲存到檔案系統中的資料儲存技術。 |
Hive 的工作原理
下圖描繪了 Hive 和 Hadoop 之間的工作流程。
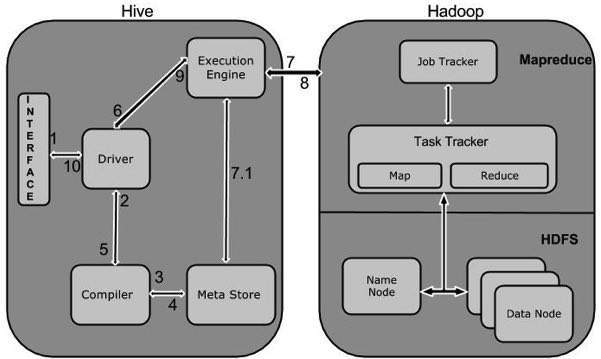
下表定義了 Hive 如何與 Hadoop 框架互動
| 步驟號 | 操作 |
|---|---|
| 1 | 執行查詢
Hive 介面(例如命令列或 Web UI)將查詢傳送到驅動程式(任何資料庫驅動程式,例如 JDBC、ODBC 等)以執行。 |
| 2 | 獲取計劃
驅動程式藉助查詢編譯器來解析查詢,以檢查語法和查詢計劃或查詢的要求。 |
| 3 | 獲取元資料
編譯器向元資料儲存(任何資料庫)傳送元資料請求。 |
| 4 | 傳送元資料
元資料儲存將元資料作為響應傳送到編譯器。 |
| 5 | 傳送計劃
編譯器檢查需求並將計劃重新發送到驅動程式。到此為止,查詢的解析和編譯已完成。 |
| 6 | 執行計劃
驅動程式將執行計劃傳送到執行引擎。 |
| 7 | 執行作業
在內部,執行作業的過程是一個 MapReduce 作業。執行引擎將作業傳送到 JobTracker(位於 Name 節點中),它將此作業分配給 TaskTracker(位於 Data 節點中)。在這裡,查詢執行 MapReduce 作業。 |
| 7.1 | 元資料操作
同時在執行過程中,執行引擎可以與元資料儲存執行元資料操作。 |
| 8 | 獲取結果
執行引擎從 Data 節點接收結果。 |
| 9 | 傳送結果
執行引擎將這些結果值傳送到驅動程式。 |
| 10 | 傳送結果
驅動程式將結果傳送到 Hive 介面。 |
Hive - 安裝
所有 Hadoop 子專案(如 Hive、Pig 和 HBase)都支援 Linux 作業系統。因此,您需要安裝任何 Linux 風格的作業系統。Hive 安裝執行以下簡單步驟
步驟 1:驗證 JAVA 安裝
在安裝 Hive 之前,必須在您的系統上安裝 Java。讓我們使用以下命令驗證 java 安裝
$ java –version
如果您的系統上已安裝 Java,您將看到以下響應
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果您的系統中未安裝 java,則按照以下步驟安裝 java。
安裝 Java
步驟 I
透過訪問以下連結下載 java(JDK <最新版本> - X64.tar.gz)http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html.
然後 jdk-7u71-linux-x64.tar.gz 將下載到您的系統上。
步驟 II
通常您會在 Downloads 資料夾中找到下載的 java 檔案。驗證它並使用以下命令解壓縮 jdk-7u71-linux-x64.gz 檔案。
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
步驟 III
要使所有使用者都可以使用 java,您必須將其移動到“/usr/local/”位置。開啟 root,然後鍵入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
步驟 IV
要設定 PATH 和 JAVA_HOME 變數,請將以下命令新增到 ~/.bashrc 檔案中。
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH=PATH:$JAVA_HOME/bin
現在使用終端中說明的命令 java -version 驗證安裝。
步驟 2:驗證 Hadoop 安裝
在安裝 Hive 之前,必須在您的系統上安裝 Hadoop。讓我們使用以下命令驗證 Hadoop 安裝
$ hadoop version
如果您的系統上已安裝 Hadoop,則您將收到以下響應
Hadoop 2.4.1 Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
如果您的系統上未安裝 Hadoop,則繼續執行以下步驟
下載 Hadoop
使用以下命令從 Apache 軟體基金會下載並解壓縮 Hadoop 2.4.1。
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
以偽分散式模式安裝 Hadoop
以下步驟用於以偽分散式模式安裝 Hadoop 2.4.1。
步驟 I:設定 Hadoop
您可以透過將以下命令追加到~/.bashrc 檔案中來設定 Hadoop 環境變數。
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
現在將所有更改應用到當前執行的系統中。
$ source ~/.bashrc
步驟 II:Hadoop 配置
您可以在“$HADOOP_HOME/etc/hadoop”位置找到所有 Hadoop 配置檔案。您需要根據您的 Hadoop 基礎架構對這些配置檔案進行適當的更改。
$ cd $HADOOP_HOME/etc/hadoop
為了使用 java 開發 Hadoop 程式,您必須透過用系統中 java 的位置替換JAVA_HOME 值來重置hadoop-env.sh 檔案中的 java 環境變數。
export JAVA_HOME=/usr/local/jdk1.7.0_71
以下是您必須編輯以配置 Hadoop 的檔案列表。
core-site.xml
core-site.xml 檔案包含諸如 Hadoop 例項使用的埠號、分配給檔案系統的記憶體、儲存資料的記憶體限制以及讀/寫緩衝區大小等資訊。
開啟 core-site.xml,並在<configuration>和</configuration>標籤之間新增以下屬性。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://:9000</value>
</property>
</configuration>
hdfs-site.xml
hdfs-site.xml 檔案包含諸如複製資料的值、namenode 路徑以及本地檔案系統的 datanode 路徑等資訊。這意味著您要儲存 Hadoop 基礎架構的位置。
讓我們假設以下資料。
dfs.replication (data replication value) = 1 (In the following path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
開啟此檔案,並在該檔案的<configuration>、</configuration>標籤之間新增以下屬性。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value >
</property>
</configuration>
注意:在上面的檔案中,所有屬性值都是使用者定義的,您可以根據您的 Hadoop 基礎架構進行更改。
yarn-site.xml
此檔案用於將 yarn 配置到 Hadoop 中。開啟 yarn-site.xml 檔案,並在該檔案的<configuration>、</configuration>標籤之間新增以下屬性。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
此檔案用於指定我們正在使用的 MapReduce 框架。預設情況下,Hadoop 包含一個 yarn-site.xml 模板。首先,您需要使用以下命令將檔案從 mapred-site.xml.template 複製到 mapred-site.xml 檔案。
$ cp mapred-site.xml.template mapred-site.xml
開啟mapred-site.xml檔案,並在該檔案中的 <configuration>、</configuration> 標籤之間新增以下屬性。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
驗證 Hadoop 安裝
以下步驟用於驗證 Hadoop 安裝。
步驟一:Name Node 設定
使用命令“hdfs namenode -format”設定 namenode,如下所示。
$ cd ~ $ hdfs namenode -format
預期結果如下。
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
步驟二:驗證 Hadoop dfs
以下命令用於啟動 dfs。執行此命令將啟動您的 Hadoop 檔案系統。
$ start-dfs.sh
預期輸出如下
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
步驟三:驗證 Yarn 指令碼
以下命令用於啟動 yarn 指令碼。執行此命令將啟動您的 yarn 守護程序。
$ start-yarn.sh
預期輸出如下
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
步驟四:在瀏覽器中訪問 Hadoop
訪問 Hadoop 的預設埠號為 50070。使用以下 URL 在瀏覽器上獲取 Hadoop 服務。
https://:50070/

步驟五:驗證叢集的所有應用程式
訪問叢集所有應用程式的預設埠號為 8088。使用以下 URL 訪問此服務。
https://:8088/
步驟 3:下載 Hive
在本教程中,我們使用 hive-0.14.0。您可以透過訪問以下連結下載它 http://apache.petsads.us/hive/hive-0.14.0/. 假設它下載到 /Downloads 目錄。在這裡,我們為本教程下載名為“apache-hive-0.14.0-bin.tar.gz”的 Hive 歸檔檔案。以下命令用於驗證下載
$ cd Downloads $ ls
下載成功後,您將看到以下響應
apache-hive-0.14.0-bin.tar.gz
步驟 4:安裝 Hive
在您的系統上安裝 Hive 需要以下步驟。假設 Hive 歸檔檔案已下載到 /Downloads 目錄。
解壓縮和驗證 Hive 歸檔檔案
以下命令用於驗證下載並解壓縮 hive 歸檔檔案
$ tar zxvf apache-hive-0.14.0-bin.tar.gz $ ls
下載成功後,您將看到以下響應
apache-hive-0.14.0-bin apache-hive-0.14.0-bin.tar.gz
將檔案複製到 /usr/local/hive 目錄
我們需要從超級使用者“su -”複製檔案。以下命令用於將檔案從解壓縮的目錄複製到 /usr/local/hive”目錄。
$ su - passwd: # cd /home/user/Download # mv apache-hive-0.14.0-bin /usr/local/hive # exit
設定 Hive 的環境
您可以透過將以下行追加到~/.bashrc檔案來設定 Hive 環境
export HIVE_HOME=/usr/local/hive export PATH=$PATH:$HIVE_HOME/bin export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:. export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
以下命令用於執行 ~/.bashrc 檔案。
$ source ~/.bashrc
步驟 5:配置 Hive
要將 Hive 與 Hadoop 配合使用,您需要編輯hive-env.sh檔案,該檔案位於$HIVE_HOME/conf目錄中。以下命令重定向到 Hive config 資料夾並複製模板檔案
$ cd $HIVE_HOME/conf $ cp hive-env.sh.template hive-env.sh
透過追加以下行編輯hive-env.sh檔案
export HADOOP_HOME=/usr/local/hadoop
Hive 安裝已成功完成。現在您需要一個外部資料庫伺服器來配置元儲存。我們使用 Apache Derby 資料庫。
步驟 6:下載和安裝 Apache Derby
請按照以下步驟下載和安裝 Apache Derby
下載 Apache Derby
以下命令用於下載 Apache Derby。下載需要一些時間。
$ cd ~ $ wget http://archive.apache.org/dist/db/derby/db-derby-10.4.2.0/db-derby-10.4.2.0-bin.tar.gz
以下命令用於驗證下載
$ ls
下載成功後,您將看到以下響應
db-derby-10.4.2.0-bin.tar.gz
解壓縮和驗證 Derby 歸檔檔案
以下命令用於解壓縮和驗證 Derby 歸檔檔案
$ tar zxvf db-derby-10.4.2.0-bin.tar.gz $ ls
下載成功後,您將看到以下響應
db-derby-10.4.2.0-bin db-derby-10.4.2.0-bin.tar.gz
將檔案複製到 /usr/local/derby 目錄
我們需要從超級使用者“su -”複製。以下命令用於將檔案從解壓縮的目錄複製到 /usr/local/derby 目錄
$ su - passwd: # cd /home/user # mv db-derby-10.4.2.0-bin /usr/local/derby # exit
設定 Derby 的環境
您可以透過將以下行追加到~/.bashrc檔案來設定 Derby 環境
export DERBY_HOME=/usr/local/derby export PATH=$PATH:$DERBY_HOME/bin Apache Hive 18 export CLASSPATH=$CLASSPATH:$DERBY_HOME/lib/derby.jar:$DERBY_HOME/lib/derbytools.jar
以下命令用於執行~/.bashrc檔案
$ source ~/.bashrc
建立目錄以儲存元儲存
在 $DERBY_HOME 目錄中建立一個名為 data 的目錄以儲存元儲存資料。
$ mkdir $DERBY_HOME/data
Derby 安裝和環境設定現已完成。
步驟 7:配置 Hive 的元儲存
配置元儲存意味著向 Hive 指定資料庫儲存位置。您可以透過編輯 hive-site.xml 檔案來實現此目的,該檔案位於 $HIVE_HOME/conf 目錄中。首先,使用以下命令複製模板檔案
$ cd $HIVE_HOME/conf $ cp hive-default.xml.template hive-site.xml
編輯hive-site.xml並在 <configuration> 和 </configuration> 標籤之間追加以下行
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:derby://:1527/metastore_db;create=true </value> <description>JDBC connect string for a JDBC metastore </description> </property>
建立一個名為 jpox.properties 的檔案並在其中新增以下行
javax.jdo.PersistenceManagerFactoryClass = org.jpox.PersistenceManagerFactoryImpl org.jpox.autoCreateSchema = false org.jpox.validateTables = false org.jpox.validateColumns = false org.jpox.validateConstraints = false org.jpox.storeManagerType = rdbms org.jpox.autoCreateSchema = true org.jpox.autoStartMechanismMode = checked org.jpox.transactionIsolation = read_committed javax.jdo.option.DetachAllOnCommit = true javax.jdo.option.NontransactionalRead = true javax.jdo.option.ConnectionDriverName = org.apache.derby.jdbc.ClientDriver javax.jdo.option.ConnectionURL = jdbc:derby://hadoop1:1527/metastore_db;create = true javax.jdo.option.ConnectionUserName = APP javax.jdo.option.ConnectionPassword = mine
步驟 8:驗證 Hive 安裝
在執行 Hive 之前,您需要建立/tmp資料夾和 HDFS 中的單獨 Hive 資料夾。這裡,我們使用/user/hive/warehouse資料夾。您需要為這些新建立的資料夾設定寫入許可權,如下所示
chmod g+w
現在在驗證 Hive 之前在 HDFS 中設定它們。使用以下命令
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp $ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
以下命令用於驗證 Hive 安裝
$ cd $HIVE_HOME $ bin/hive
Hive 成功安裝後,您將看到以下響應
Logging initialized using configuration in jar:file:/home/hadoop/hive-0.9.0/lib/hive-common-0.9.0.jar!/hive-log4j.properties Hive history file=/tmp/hadoop/hive_job_log_hadoop_201312121621_1494929084.txt …………………. hive>
以下示例命令用於顯示所有表
hive> show tables; OK Time taken: 2.798 seconds hive>
Hive - 資料型別
本章將引導您瞭解 Hive 中的不同資料型別,這些資料型別參與表建立。Hive 中的所有資料型別分為四種類型,如下所示
- 列型別
- 文字
- 空值
- 複雜型別
列型別
列型別用作 Hive 的列資料型別。它們如下所示
整型
整數型別資料可以使用整型資料型別 INT 指定。當資料範圍超出 INT 的範圍時,您需要使用 BIGINT,如果資料範圍小於 INT,則使用 SMALLINT。TINYINT 小於 SMALLINT。
下表顯示了各種 INT 資料型別
| 型別 | 字尾 | 示例 |
|---|---|---|
| TINYINT | Y | 10Y |
| SMALLINT | S | 10S |
| INT | - | 10 |
| BIGINT | L | 10L |
字串型別
字串型別資料型別可以使用單引號 (' ') 或雙引號 (" ") 指定。它包含兩種資料型別:VARCHAR 和 CHAR。Hive 遵循 C 型別跳脫字元。
下表顯示了各種 CHAR 資料型別
| 資料型別 | 長度 |
|---|---|
| VARCHAR | 1 到 65355 |
| CHAR | 255 |
時間戳
它支援傳統 UNIX 時間戳,並具有可選的納秒精度。它支援 java.sql.Timestamp 格式“YYYY-MM-DD HH:MM:SS.fffffffff”和格式“yyyy-mm-dd hh:mm:ss.ffffffffff”。
日期
DATE 值以年/月/日格式表示,格式為 {{YYYY-MM-DD}}。
小數
Hive 中的 DECIMAL 型別與 Java 的 Big Decimal 格式相同。它用於表示不可變的任意精度。語法和示例如下
DECIMAL(precision, scale) decimal(10,0)
聯合型別
Union 是異構資料型別的集合。您可以使用create union建立例項。語法和示例如下
UNIONTYPE<int, double, array<string>, struct<a:int,b:string>>
{0:1}
{1:2.0}
{2:["three","four"]}
{3:{"a":5,"b":"five"}}
{2:["six","seven"]}
{3:{"a":8,"b":"eight"}}
{0:9}
{1:10.0}
文字
Hive 中使用以下文字
浮點型別
浮點型別不過是帶有小數點的數字。通常,此型別的資料由 DOUBLE 資料型別組成。
十進位制型別
十進位制型別資料不過是比 DOUBLE 資料類型範圍更大的浮點值。十進位制型別的範圍大約為 -10-308 到 10308。空值
缺失值由特殊值 NULL 表示。
複雜型別
Hive 複雜資料型別如下
陣列
Hive 中的陣列與在 Java 中的使用方式相同。
語法:ARRAY<data_type>
對映
Hive 中的對映類似於 Java 對映。
語法:MAP<primitive_type, data_type>
結構體
Hive 中的結構體類似於使用帶註釋的複雜資料。
語法:STRUCT<col_name : data_type [COMMENT col_comment], ...>
Hive - 建立資料庫
Hive 是一種資料庫技術,可以定義資料庫和表以分析結構化資料。結構化資料分析的主題是以表格方式儲存資料,並傳遞查詢以對其進行分析。本章說明如何建立 Hive 資料庫。Hive 包含一個名為default的預設資料庫。
建立資料庫語句
Create Database 是一個用於在 Hive 中建立資料庫的語句。Hive 中的資料庫是名稱空間或表的集合。此語句的語法如下
CREATE DATABASE|SCHEMA [IF NOT EXISTS] <database name>
這裡,IF NOT EXISTS 是一個可選子句,它通知使用者已經存在一個同名數據庫。我們可以在此命令中使用 SCHEMA 代替 DATABASE。以下查詢用於建立一個名為userdb的資料庫
hive> CREATE DATABASE [IF NOT EXISTS] userdb;
或
hive> CREATE SCHEMA userdb;
以下查詢用於驗證資料庫列表
hive> SHOW DATABASES; default userdb
JDBC 程式
建立資料庫的 JDBC 程式如下所示。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet; 4. CREATE DATABASE
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveCreateDb {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://:10000/default", "", "");
Statement stmt = con.createStatement();
stmt.executeQuery("CREATE DATABASE userdb");
System.out.println(“Database userdb created successfully.”);
con.close();
}
}
將程式儲存在名為 HiveCreateDb.java 的檔案中。以下命令用於編譯和執行此程式。
$ javac HiveCreateDb.java $ java HiveCreateDb
輸出
Database userdb created successfully.
Hive - 刪除資料庫
本章介紹如何在 Hive 中刪除資料庫。SCHEMA 和 DATABASE 的用法相同。
刪除資料庫語句
Drop Database 是一個刪除所有表並刪除資料庫的語句。其語法如下
DROP DATABASE StatementDROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
以下查詢用於刪除資料庫。假設資料庫名為userdb。
hive> DROP DATABASE IF EXISTS userdb;
以下查詢使用CASCADE刪除資料庫。這意味著在刪除資料庫之前先刪除相應的表。
hive> DROP DATABASE IF EXISTS userdb CASCADE;
以下查詢使用SCHEMA刪除資料庫。
hive> DROP SCHEMA userdb;
此子句是在 Hive 0.6 中新增的。
JDBC 程式
刪除資料庫的 JDBC 程式如下所示。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager; 5. DROP DATABASE
public class HiveDropDb {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://:10000/default", "", "");
Statement stmt = con.createStatement();
stmt.executeQuery("DROP DATABASE userdb");
System.out.println(“Drop userdb database successful.”);
con.close();
}
}
將程式儲存在名為 HiveDropDb.java 的檔案中。以下是編譯和執行此程式的命令。
$ javac HiveDropDb.java $ java HiveDropDb
輸出
Drop userdb database successful.
Hive - 建立表
本章說明如何建立表以及如何向其中插入資料。在 HIVE 中建立表的約定與使用 SQL 建立表非常相似。
建立表語句
Create Table 是一個用於在 Hive 中建立表的語句。語法和示例如下
語法
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [ROW FORMAT row_format] [STORED AS file_format]
示例
假設您需要使用CREATE TABLE語句建立一個名為employee的表。下表列出了 employee 表中的欄位及其資料型別
| 序號 | 欄位名稱 | 資料型別 |
|---|---|---|
| 1 | Eid | int |
| 2 | Name | String |
| 3 | Salary | Float |
| 4 | Designation | string |
以下資料是註釋,行格式化欄位,如欄位分隔符、行分隔符和儲存的檔案型別。
COMMENT ‘Employee details’ FIELDS TERMINATED BY ‘\t’ LINES TERMINATED BY ‘\n’ STORED IN TEXT FILE
以下查詢使用上述資料建立一個名為employee的表。
hive> CREATE TABLE IF NOT EXISTS employee ( eid int, name String, > salary String, destination String) > COMMENT ‘Employee details’ > ROW FORMAT DELIMITED > FIELDS TERMINATED BY ‘\t’ > LINES TERMINATED BY ‘\n’ > STORED AS TEXTFILE;
如果您新增 IF NOT EXISTS 選項,則如果表已存在,Hive 將忽略該語句。
表建立成功後,您將看到以下響應
OK Time taken: 5.905 seconds hive>
JDBC 程式
建立表的 JDBC 程式示例。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveCreateTable {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("CREATE TABLE IF NOT EXISTS "
+" employee ( eid int, name String, "
+" salary String, destignation String)"
+" COMMENT ‘Employee details’"
+" ROW FORMAT DELIMITED"
+" FIELDS TERMINATED BY ‘\t’"
+" LINES TERMINATED BY ‘\n’"
+" STORED AS TEXTFILE;");
System.out.println(“ Table employee created.”);
con.close();
}
}
將程式儲存在名為 HiveCreateDb.java 的檔案中。以下命令用於編譯和執行此程式。
$ javac HiveCreateDb.java $ java HiveCreateDb
輸出
Table employee created.
載入資料語句
通常,在 SQL 中建立表後,我們可以使用 Insert 語句插入資料。但在 Hive 中,我們可以使用 LOAD DATA 語句插入資料。
在將資料插入 Hive 時,最好使用 LOAD DATA 儲存批次記錄。載入資料有兩種方法:一種是從本地檔案系統載入,另一種是從 Hadoop 檔案系統載入。
語法
載入資料的語法如下
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
- LOCAL 是用於指定本地路徑的識別符號。它是可選的。
- OVERWRITE 是可選的,用於覆蓋表中的資料。
- PARTITION 是可選的。
示例
我們將以下資料插入表中。它是一個名為sample.txt的文字檔案,位於/home/user目錄中。
1201 Gopal 45000 Technical manager 1202 Manisha 45000 Proof reader 1203 Masthanvali 40000 Technical writer 1204 Krian 40000 Hr Admin 1205 Kranthi 30000 Op Admin
以下查詢將給定的文字載入到表中。
hive> LOAD DATA LOCAL INPATH '/home/user/sample.txt' > OVERWRITE INTO TABLE employee;
下載成功後,您將看到以下響應
OK Time taken: 15.905 seconds hive>
JDBC 程式
以下是將給定資料載入到表的 JDBC 程式。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveLoadData {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("LOAD DATA LOCAL INPATH '/home/user/sample.txt'"
+"OVERWRITE INTO TABLE employee;");
System.out.println("Load Data into employee successful");
con.close();
}
}
將程式儲存在名為 HiveLoadData.java 的檔案中。使用以下命令編譯和執行此程式。
$ javac HiveLoadData.java $ java HiveLoadData
輸出
Load Data into employee successful
Hive - 修改表
本章說明如何更改表的屬性,例如更改表名、更改列名、新增列以及刪除或替換列。
更改表語句
它用於更改 Hive 中的表。
語法
根據我們希望修改表中的哪些屬性,該語句採用以下任何語法。
ALTER TABLE name RENAME TO new_name ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...]) ALTER TABLE name DROP [COLUMN] column_name ALTER TABLE name CHANGE column_name new_name new_type ALTER TABLE name REPLACE COLUMNS (col_spec[, col_spec ...])
重新命名為...語句
以下查詢將表從employee重新命名為emp。
hive> ALTER TABLE employee RENAME TO emp;
JDBC 程式
重命名錶的 JDBC 程式如下所示。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterRenameTo {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee RENAME TO emp;");
System.out.println("Table Renamed Successfully");
con.close();
}
}
將程式儲存到名為 HiveAlterRenameTo.java 的檔案中。使用以下命令編譯並執行此程式。
$ javac HiveAlterRenameTo.java $ java HiveAlterRenameTo
輸出
Table renamed successfully.
更改語句
下表包含 **employee** 表的欄位,並顯示要更改的欄位(以粗體顯示)。
| 欄位名稱 | 從資料型別轉換 | 更改欄位名稱 | 轉換為資料型別 |
|---|---|---|---|
| eid | int | eid | int |
| name | String | ename | String |
| salary | Float | salary | Double |
| designation | String | designation | String |
以下查詢使用上述資料重新命名列名和列資料型別
hive> ALTER TABLE employee CHANGE name ename String; hive> ALTER TABLE employee CHANGE salary salary Double;
JDBC 程式
下面是更改列的 JDBC 程式。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterChangeColumn {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee CHANGE name ename String;");
stmt.executeQuery("ALTER TABLE employee CHANGE salary salary Double;");
System.out.println("Change column successful.");
con.close();
}
}
將程式儲存到名為 HiveAlterChangeColumn.java 的檔案中。使用以下命令編譯並執行此程式。
$ javac HiveAlterChangeColumn.java $ java HiveAlterChangeColumn
輸出
Change column successful.
新增列語句
以下查詢向 employee 表中新增一個名為 dept 的列。
hive> ALTER TABLE employee ADD COLUMNS ( > dept STRING COMMENT 'Department name');
JDBC 程式
向表中新增列的 JDBC 程式如下所示。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterAddColumn {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee ADD COLUMNS "
+" (dept STRING COMMENT 'Department name');");
System.out.prinln("Add column successful.");
con.close();
}
}
將程式儲存到名為 HiveAlterAddColumn.java 的檔案中。使用以下命令編譯並執行此程式。
$ javac HiveAlterAddColumn.java $ java HiveAlterAddColumn
輸出
Add column successful.
替換語句
以下查詢刪除 **employee** 表中的所有列,並將其替換為 **emp** 和 **name** 列
hive> ALTER TABLE employee REPLACE COLUMNS ( > eid INT empid Int, > ename STRING name String);
JDBC 程式
下面是將 **eid** 列替換為 **empid** 和 **ename** 列替換為 **name** 的 JDBC 程式。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveAlterReplaceColumn {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("ALTER TABLE employee REPLACE COLUMNS "
+" (eid INT empid Int,"
+" ename STRING name String);");
System.out.println(" Replace column successful");
con.close();
}
}
將程式儲存到名為 HiveAlterReplaceColumn.java 的檔案中。使用以下命令編譯並執行此程式。
$ javac HiveAlterReplaceColumn.java $ java HiveAlterReplaceColumn
輸出
Replace column successful.
Hive - 刪除表
本章介紹如何在 Hive 中刪除表。當您從 Hive Metastore 中刪除表時,它會刪除表/列資料及其元資料。它可以是普通表(儲存在 Metastore 中)或外部表(儲存在本地檔案系統中);Hive 對兩者採用相同的方式處理,無論其型別如何。
刪除表語句
語法如下
DROP TABLE [IF EXISTS] table_name;
以下查詢刪除名為 **employee** 的表
hive> DROP TABLE IF EXISTS employee;
查詢成功執行後,您將看到以下響應
OK Time taken: 5.3 seconds hive>
JDBC 程式
以下 JDBC 程式刪除 employee 表。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveDropTable {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
stmt.executeQuery("DROP TABLE IF EXISTS employee;");
System.out.println("Drop table successful.");
con.close();
}
}
將程式儲存到名為 HiveDropTable.java 的檔案中。使用以下命令編譯並執行此程式。
$ javac HiveDropTable.java $ java HiveDropTable
輸出
Drop table successful
以下查詢用於驗證表列表
hive> SHOW TABLES; emp ok Time taken: 2.1 seconds hive>
Hive - 分割槽
Hive 將表組織成分割槽。它是根據分割槽列(如日期、城市和部門)的值將表劃分為相關部分的一種方式。使用分割槽,可以輕鬆查詢一部分資料。
表或分割槽細分為 **桶**,為資料提供額外的結構,可用於更有效的查詢。分桶基於表中某些列的雜湊函式的值。
例如,名為 **Tab1** 的表包含員工資料,例如 id、name、dept 和 yoj(即入職年份)。假設您需要檢索 2012 年入職的所有員工的詳細資訊。查詢會搜尋整個表以獲取所需的資訊。但是,如果您使用年份對員工資料進行分割槽並將其儲存在單獨的檔案中,則可以減少查詢處理時間。以下示例顯示瞭如何對檔案及其資料進行分割槽
以下檔案包含 employeedata 表。
/tab1/employeedata/file1
id, name, dept, yoj
1, gopal, TP, 2012
2, kiran, HR, 2012
3, kaleel,SC, 2013
4, Prasanth, SC, 2013
上述資料使用年份劃分為兩個檔案。
/tab1/employeedata/2012/file2
1, gopal, TP, 2012
2, kiran, HR, 2012
/tab1/employeedata/2013/file3
3, kaleel,SC, 2013
4, Prasanth, SC, 2013
新增分割槽
我們可以透過更改表來向表中新增分割槽。假設我們有一個名為 **employee** 的表,其欄位包括 Id、Name、Salary、Designation、Dept 和 yoj。
語法
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location1'] partition_spec [LOCATION 'location2'] ...; partition_spec: : (p_column = p_col_value, p_column = p_col_value, ...)
以下查詢用於向 employee 表中新增分割槽。
hive> ALTER TABLE employee > ADD PARTITION (year=’2012’) > location '/2012/part2012';
重新命名分割槽
此命令的語法如下。
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;
以下查詢用於重新命名分割槽
hive> ALTER TABLE employee PARTITION (year=’1203’) > RENAME TO PARTITION (Yoj=’1203’);
刪除分割槽
以下語法用於刪除分割槽
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec, PARTITION partition_spec,...;
以下查詢用於刪除分割槽
hive> ALTER TABLE employee DROP [IF EXISTS] > PARTITION (year=’1203’);
Hive - 內建運算子
本章介紹 Hive 的內建運算子。Hive 中有四種類型的運算子
- 關係運算符
- 算術運算子
- 邏輯運算子
- 複雜運算子
關係運算符
這些運算子用於比較兩個運算元。下表描述了 Hive 中可用的關係運算符
| 運算子 | 運算元 | 描述 |
|---|---|---|
| A = B | 所有基本型別 | 如果表示式 A 等於表示式 B,則為 TRUE,否則為 FALSE。 |
| A != B | 所有基本型別 | 如果表示式 A 不等於表示式 B,則為 TRUE,否則為 FALSE。 |
| A < B | 所有基本型別 | 如果表示式 A 小於表示式 B,則為 TRUE,否則為 FALSE。 |
| A <= B | 所有基本型別 | 如果表示式 A 小於或等於表示式 B,則為 TRUE,否則為 FALSE。 |
| A > B | 所有基本型別 | 如果表示式 A 大於表示式 B,則為 TRUE,否則為 FALSE。 |
| A >= B | 所有基本型別 | 如果表示式 A 大於或等於表示式 B,則為 TRUE,否則為 FALSE。 |
| A IS NULL | 所有型別 | 如果表示式 A 評估結果為 NULL,則為 TRUE,否則為 FALSE。 |
| A IS NOT NULL | 所有型別 | 如果表示式 A 評估結果為 NULL,則為 FALSE,否則為 TRUE。 |
| A LIKE B | 字串 | 如果字串模式 A 與 B 匹配,則為 TRUE,否則為 FALSE。 |
| A RLIKE B | 字串 | 如果 A 或 B 為 NULL,則為 NULL;如果 A 的任何子字串與 Java 正則表示式 B 匹配,則為 TRUE,否則為 FALSE。 |
| A REGEXP B | 字串 | 與 RLIKE 相同。 |
示例
假設 **employee** 表由名為 Id、Name、Salary、Designation 和 Dept 的欄位組成,如下所示。生成一個查詢以檢索 Id 為 1205 的員工詳細資訊。
+-----+--------------+--------+---------------------------+------+ | Id | Name | Salary | Designation | Dept | +-----+--------------+------------------------------------+------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | |1205 | Kranthi | 30000 | Op Admin | Admin| +-----+--------------+--------+---------------------------+------+
執行以下查詢以使用上表檢索員工詳細資訊
hive> SELECT * FROM employee WHERE Id=1205;
查詢成功執行後,您將看到以下響應
+-----+-----------+-----------+----------------------------------+ | ID | Name | Salary | Designation | Dept | +-----+---------------+-------+----------------------------------+ |1205 | Kranthi | 30000 | Op Admin | Admin | +-----+-----------+-----------+----------------------------------+
執行以下查詢以檢索薪水大於或等於 40000 元的員工詳細資訊。
hive> SELECT * FROM employee WHERE Salary>=40000;
查詢成功執行後,您將看到以下響應
+-----+------------+--------+----------------------------+------+ | ID | Name | Salary | Designation | Dept | +-----+------------+--------+----------------------------+------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali| 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | +-----+------------+--------+----------------------------+------+
算術運算子
這些運算子支援運算元上的各種常用算術運算。它們都返回數字型別。下表描述了 Hive 中可用的算術運算子
| 運算子 | 運算元 | 描述 |
|---|---|---|
| A + B | 所有數字型別 | 給出 A 和 B 相加的結果。 |
| A - B | 所有數字型別 | 給出從 A 中減去 B 的結果。 |
| A * B | 所有數字型別 | 給出 A 和 B 相乘的結果。 |
| A / B | 所有數字型別 | 給出從 A 中除以 B 的結果。 |
| A % B | 所有數字型別 | 給出 A 除以 B 產生的餘數。 |
| A & B | 所有數字型別 | 給出 A 和 B 按位與的結果。 |
| A | B | 所有數字型別 | 給出 A 和 B 按位或的結果。 |
| A ^ B | 所有數字型別 | 給出 A 和 B 按位異或的結果。 |
| ~A | 所有數字型別 | 給出 A 按位非的結果。 |
示例
以下查詢將兩個數字 20 和 30 相加。
hive> SELECT 20+30 ADD FROM temp;
查詢成功執行後,您將看到以下響應
+--------+ | ADD | +--------+ | 50 | +--------+
邏輯運算子
運算子是邏輯表示式。它們都返回 TRUE 或 FALSE。
| 運算子 | 運算元 | 描述 |
|---|---|---|
| A AND B | 布林值 | 如果 A 和 B 都為 TRUE,則為 TRUE,否則為 FALSE。 |
| A && B | 布林值 | 與 A AND B 相同。 |
| A OR B | 布林值 | 如果 A 或 B 或兩者都為 TRUE,則為 TRUE,否則為 FALSE。 |
| A || B | 布林值 | 與 A OR B 相同。 |
| NOT A | 布林值 | 如果 A 為 FALSE,則為 TRUE,否則為 FALSE。 |
| !A | 布林值 | 與 NOT A 相同。 |
示例
以下查詢用於檢索部門為 TP 且薪水超過 40000 元的員工詳細資訊。
hive> SELECT * FROM employee WHERE Salary>40000 && Dept=TP;
查詢成功執行後,您將看到以下響應
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | +------+--------------+-------------+-------------------+--------+
複雜運算子
這些運算子提供一個表示式來訪問複雜型別的元素。
| 運算子 | 運算元 | 描述 |
|---|---|---|
| A[n] | A 是一個數組,n 是一個整數 | 它返回陣列 A 中的第 n 個元素。第一個元素的索引為 0。 |
| M[key] | M 是一個 Map<K, V>,key 的型別為 K | 它返回對映中對應於鍵的值。 |
| S.x | S 是一個結構體 | 它返回 S 的 x 欄位。 |
Hiveql Select...Where
Hive 查詢語言 (HiveQL) 是 Hive 用於處理和分析元資料中結構化資料的查詢語言。本章介紹如何將 SELECT 語句與 WHERE 子句一起使用。
SELECT 語句用於從表中檢索資料。WHERE 子句的工作原理類似於條件。它使用條件過濾資料,併為您提供有限的結果。內建運算子和函式生成一個表示式,該表示式滿足條件。
語法
下面是 SELECT 查詢的語法
SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [HAVING having_condition] [CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]] [LIMIT number];
示例
讓我們以 SELECT…WHERE 子句為例。假設我們有如下所示的 employee 表,欄位名為 Id、Name、Salary、Designation 和 Dept。生成一個查詢以檢索薪水超過 30000 元的員工詳細資訊。
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | |1205 | Kranthi | 30000 | Op Admin | Admin | +------+--------------+-------------+-------------------+--------+
以下查詢使用上述場景檢索員工詳細資訊
hive> SELECT * FROM employee WHERE salary>30000;
查詢成功執行後,您將看到以下響應
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | +------+--------------+-------------+-------------------+--------+
JDBC 程式
為給定示例應用 where 子句的 JDBC 程式如下所示。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveQLWhere {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
Resultset res = stmt.executeQuery("SELECT * FROM employee WHERE
salary>30000;");
System.out.println("Result:");
System.out.println(" ID \t Name \t Salary \t Designation \t Dept ");
while (res.next()) {
System.out.println(res.getInt(1)+" "+ res.getString(2)+" "+
res.getDouble(3)+" "+ res.getString(4)+" "+ res.getString(5));
}
con.close();
}
}
將程式儲存到名為 HiveQLWhere.java 的檔案中。使用以下命令編譯並執行此程式。
$ javac HiveQLWhere.java $ java HiveQLWhere
輸出
ID Name Salary Designation Dept 1201 Gopal 45000 Technical manager TP 1202 Manisha 45000 Proofreader PR 1203 Masthanvali 40000 Technical writer TP 1204 Krian 40000 Hr Admin HR
Hiveql Select...Order By
本章介紹如何在 SELECT 語句中使用 ORDER BY 子句。ORDER BY 子句用於根據一列檢索詳細資訊,並按升序或降序對結果集進行排序。
語法
下面是 ORDER BY 子句的語法
SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [HAVING having_condition] [ORDER BY col_list]] [LIMIT number];
示例
讓我們以 SELECT...ORDER BY 子句為例。假設 employee 表如下所示,欄位名為 Id、Name、Salary、Designation 和 Dept。生成一個查詢,以使用部門名稱按順序檢索員工詳細資訊。
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | |1205 | Kranthi | 30000 | Op Admin | Admin | +------+--------------+-------------+-------------------+--------+
以下查詢使用上述場景檢索員工詳細資訊
hive> SELECT Id, Name, Dept FROM employee ORDER BY DEPT;
查詢成功執行後,您將看到以下響應
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1205 | Kranthi | 30000 | Op Admin | Admin | |1204 | Krian | 40000 | Hr Admin | HR | |1202 | Manisha | 45000 | Proofreader | PR | |1201 | Gopal | 45000 | Technical manager | TP | |1203 | Masthanvali | 40000 | Technical writer | TP | +------+--------------+-------------+-------------------+--------+
JDBC 程式
以下是為給定示例應用 Order By 子句的 JDBC 程式。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveQLOrderBy {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
Resultset res = stmt.executeQuery("SELECT * FROM employee ORDER BY
DEPT;");
System.out.println(" ID \t Name \t Salary \t Designation \t Dept ");
while (res.next()) {
System.out.println(res.getInt(1)+" "+ res.getString(2)+" "+
res.getDouble(3)+" "+ res.getString(4)+" "+ res.getString(5));
}
con.close();
}
}
將程式儲存到名為 HiveQLOrderBy.java 的檔案中。使用以下命令編譯並執行此程式。
$ javac HiveQLOrderBy.java $ java HiveQLOrderBy
輸出
ID Name Salary Designation Dept 1205 Kranthi 30000 Op Admin Admin 1204 Krian 40000 Hr Admin HR 1202 Manisha 45000 Proofreader PR 1201 Gopal 45000 Technical manager TP 1203 Masthanvali 40000 Technical writer TP 1204 Krian 40000 Hr Admin HR
Hiveql Group By
本章詳細介紹了 SELECT 語句中 GROUP BY 子句的細節。GROUP BY 子句用於使用特定集合列對結果集中的所有記錄進行分組。它用於查詢一組記錄。
語法
GROUP BY 子句的語法如下
SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [HAVING having_condition] [ORDER BY col_list]] [LIMIT number];
示例
讓我們以 SELECT…GROUP BY 子句為例。假設 employee 表如下所示,欄位為 Id、Name、Salary、Designation 和 Dept。生成一個查詢以檢索每個部門的員工人數。
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 45000 | Proofreader | PR | |1205 | Kranthi | 30000 | Op Admin | Admin | +------+--------------+-------------+-------------------+--------+
以下查詢使用上述場景檢索員工詳細資訊。
hive> SELECT Dept,count(*) FROM employee GROUP BY DEPT;
查詢成功執行後,您將看到以下響應
+------+--------------+ | Dept | Count(*) | +------+--------------+ |Admin | 1 | |PR | 2 | |TP | 3 | +------+--------------+
JDBC 程式
下面是為給定示例應用 Group By 子句的 JDBC 程式。
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveQLGroupBy {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
Resultset res = stmt.executeQuery(“SELECT Dept,count(*) ”
+“FROM employee GROUP BY DEPT; ”);
System.out.println(" Dept \t count(*)");
while (res.next()) {
System.out.println(res.getString(1)+" "+ res.getInt(2));
}
con.close();
}
}
將程式儲存到名為 HiveQLGroupBy.java 的檔案中。使用以下命令編譯並執行此程式。
$ javac HiveQLGroupBy.java $ java HiveQLGroupBy
輸出
Dept Count(*) Admin 1 PR 2 TP 3
Hiveql Joins
JOINS 是一個用於透過使用每個表共有的值來組合來自兩個表的特定欄位的子句。它用於組合資料庫中兩個或多個表中的記錄。
語法
join_table:
table_reference JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference
join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference [join_condition]
示例
我們將在本章中使用以下兩個表。請考慮以下名為 CUSTOMERS 的表..
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
再考慮另一個名為 ORDERS 的表
+-----+---------------------+-------------+--------+ |OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
以下是不同型別的連線
- JOIN
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
JOIN
JOIN 子句用於組合和檢索來自多個表的記錄。JOIN 與 SQL 中的 OUTER JOIN 相同。JOIN 條件需要使用表的 primary keys 和 foreign keys 來提出。
以下查詢在 CUSTOMER 和 ORDER 表上執行 JOIN,並檢索記錄
hive> SELECT c.ID, c.NAME, c.AGE, o.AMOUNT > FROM CUSTOMERS c JOIN ORDERS o > ON (c.ID = o.CUSTOMER_ID);
查詢成功執行後,您將看到以下響應
+----+----------+-----+--------+ | ID | NAME | AGE | AMOUNT | +----+----------+-----+--------+ | 3 | kaushik | 23 | 3000 | | 3 | kaushik | 23 | 1500 | | 2 | Khilan | 25 | 1560 | | 4 | Chaitali | 25 | 2060 | +----+----------+-----+--------+
LEFT OUTER JOIN
HiveQL LEFT OUTER JOIN 返回左側表中的所有行,即使右側表中沒有匹配項也是如此。這意味著,如果 ON 子句在右側表中匹配 0(零)條記錄,則 JOIN 仍會在結果中返回一行,但在右側表中的每一列中都為 NULL。
LEFT JOIN 返回左側表中的所有值,加上右側表中匹配的值,或者在沒有匹配的 JOIN 謂詞的情況下為 NULL。
以下查詢演示了 CUSTOMER 和 ORDER 表之間的 LEFT OUTER JOIN
hive> SELECT c.ID, c.NAME, o.AMOUNT, o.DATE > FROM CUSTOMERS c > LEFT OUTER JOIN ORDERS o > ON (c.ID = o.CUSTOMER_ID);
查詢成功執行後,您將看到以下響應
+----+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +----+----------+--------+---------------------+ | 1 | Ramesh | NULL | NULL | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | | 5 | Hardik | NULL | NULL | | 6 | Komal | NULL | NULL | | 7 | Muffy | NULL | NULL | +----+----------+--------+---------------------+
RIGHT OUTER JOIN
HiveQL RIGHT OUTER JOIN 返回右側表中的所有行,即使左側表中沒有匹配項。如果 ON 子句在左側表中匹配 0(零)條記錄,則 JOIN 仍會在結果中返回一行,但在左側表的每一列中都填充 NULL。
RIGHT JOIN 返回右側表中的所有值,以及左側表中匹配的值,或者在沒有匹配聯接謂詞的情況下返回 NULL。
以下查詢演示了 CUSTOMER 和 ORDER 表之間的 RIGHT OUTER JOIN。
hive> SELECT c.ID, c.NAME, o.AMOUNT, o.DATE > FROM CUSTOMERS c > RIGHT OUTER JOIN ORDERS o > ON (c.ID = o.CUSTOMER_ID);
查詢成功執行後,您將看到以下響應
+------+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +------+----------+--------+---------------------+ | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +------+----------+--------+---------------------+
FULL OUTER JOIN
HiveQL FULL OUTER JOIN 組合了滿足 JOIN 條件的左側和右側外部表兩者的記錄。聯接表包含來自兩個表的所有記錄,或者為任一側缺少的匹配項填充 NULL 值。
以下查詢演示了 CUSTOMER 和 ORDER 表之間的 FULL OUTER JOIN
hive> SELECT c.ID, c.NAME, o.AMOUNT, o.DATE > FROM CUSTOMERS c > FULL OUTER JOIN ORDERS o > ON (c.ID = o.CUSTOMER_ID);
查詢成功執行後,您將看到以下響應
+------+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +------+----------+--------+---------------------+ | 1 | Ramesh | NULL | NULL | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | | 5 | Hardik | NULL | NULL | | 6 | Komal | NULL | NULL | | 7 | Muffy | NULL | NULL | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +------+----------+--------+---------------------+
Hive - 內建函式
本章解釋了 Hive 中可用的內建函式。除了用法之外,這些函式看起來與 SQL 函式非常相似。
內建函式
Hive 支援以下內建函式
| 返回型別 | 簽名 | 描述 |
|---|---|---|
| BIGINT | round(double a) | 它返回 double 的四捨五入後的 BIGINT 值。 |
| BIGINT | floor(double a) | 它返回等於或小於 double 的最大 BIGINT 值。 |
| BIGINT | ceil(double a) | 它返回等於或大於 double 的最小 BIGINT 值。 |
| double | rand(), rand(int seed) | 它返回一個隨機數,該隨機數隨行而異。 |
| string | concat(string A, string B,...) | 它返回將 B 連線到 A 後形成的字串。 |
| string | substr(string A, int start) | 它返回從起始位置到字串 A 末尾的 A 的子字串。 |
| string | substr(string A, int start, int length) | 它返回從起始位置開始,長度為給定長度的 A 的子字串。 |
| string | upper(string A) | 它返回將 A 的所有字元轉換為大寫後形成的字串。 |
| string | ucase(string A) | 與上面相同。 |
| string | lower(string A) | 它返回將 B 的所有字元轉換為小寫後形成的字串。 |
| string | lcase(string A) | 與上面相同。 |
| string | trim(string A) | 它返回從 A 的兩端去除空格後形成的字串。 |
| string | ltrim(string A) | 它返回從 A 的開頭(左側)去除空格後形成的字串。 |
| string | rtrim(string A) | rtrim(string A) 它返回從 A 的末尾(右側)去除空格後形成的字串。 |
| string | regexp_replace(string A, string B, string C) | 它返回用 C 替換 B 中與 Java 正則表示式語法匹配的所有子字串後形成的字串。 |
| int | size(Map<K.V>) | 它返回對映型別中元素的數量。 |
| int | size(Array<T>) | 它返回陣列型別中元素的數量。 |
| <type> 的值 | cast(<expr> as <type>) | 它將表示式 expr 的結果轉換為 <type>,例如 cast('1' as BIGINT) 將字串 '1' 轉換為其整數表示。如果轉換不成功,則返回 NULL。 |
| string | from_unixtime(int unixtime) | 將自 Unix 紀元(1970-01-01 00:00:00 UTC)以來的秒數轉換為表示當前系統時區中該時刻時間戳的字串,格式為“1970-01-01 00:00:00” |
| string | to_date(string timestamp) | 它返回時間戳字串的日期部分:to_date("1970-01-01 00:00:00") = "1970-01-01" |
| int | year(string date) | 它返回日期或時間戳字串的年份部分:year("1970-01-01 00:00:00") = 1970,year("1970-01-01") = 1970 |
| int | month(string date) | 它返回日期或時間戳字串的月份部分:month("1970-11-01 00:00:00") = 11,month("1970-11-01") = 11 |
| int | day(string date) | 它返回日期或時間戳字串的日期部分:day("1970-11-01 00:00:00") = 1,day("1970-11-01") = 1 |
| string | get_json_object(string json_string, string path) | 它根據指定的 json 路徑從 json 字串中提取 json 物件,並返回提取的 json 物件的 json 字串。如果輸入的 json 字串無效,則返回 NULL。 |
示例
以下查詢演示了一些內建函式
round() 函式
hive> SELECT round(2.6) from temp;
查詢成功執行後,您將看到以下響應
3.0
floor() 函式
hive> SELECT floor(2.6) from temp;
查詢成功執行後,您將看到以下響應
2.0
ceil() 函式
hive> SELECT ceil(2.6) from temp;
查詢成功執行後,您將看到以下響應
3.0
聚合函式
Hive 支援以下內建聚合函式。這些函式的用法與 SQL 聚合函式相同。
| 返回型別 | 簽名 | 描述 |
|---|---|---|
| BIGINT | count(*), count(expr), | count(*) - 返回檢索到的行總數。 |
| DOUBLE | sum(col), sum(DISTINCT col) | 它返回組中元素的總和或組中列的不同值的總和。 |
| DOUBLE | avg(col), avg(DISTINCT col) | 它返回組中元素的平均值或組中列的不同值的平均值。 |
| DOUBLE | min(col) | 它返回組中列的最小值。 |
| DOUBLE | max(col) | 它返回組中列的最大值。 |
Hive - 檢視和索引
本章介紹如何建立和管理檢視。檢視是根據使用者需求生成的。您可以將任何結果集資料儲存為檢視。Hive 中檢視的用法與 SQL 中的檢視相同。這是一個標準的 RDBMS 概念。我們可以在檢視上執行所有 DML 操作。
建立檢視
您可以在執行 SELECT 語句時建立檢視。語法如下
CREATE VIEW [IF NOT EXISTS] view_name [(column_name [COMMENT column_comment], ...) ] [COMMENT table_comment] AS SELECT ...
示例
讓我們以檢視為例。假設員工表如下所示,欄位為 Id、Name、Salary、Designation 和 Dept。生成一個查詢以檢索薪資超過 30000 元的員工詳細資訊。我們將結果儲存在名為emp_30000的檢視中。
+------+--------------+-------------+-------------------+--------+ | ID | Name | Salary | Designation | Dept | +------+--------------+-------------+-------------------+--------+ |1201 | Gopal | 45000 | Technical manager | TP | |1202 | Manisha | 45000 | Proofreader | PR | |1203 | Masthanvali | 40000 | Technical writer | TP | |1204 | Krian | 40000 | Hr Admin | HR | |1205 | Kranthi | 30000 | Op Admin | Admin | +------+--------------+-------------+-------------------+--------+
以下查詢使用上述場景檢索員工詳細資訊
hive> CREATE VIEW emp_30000 AS > SELECT * FROM employee > WHERE salary>30000;
刪除檢視
使用以下語法刪除檢視
DROP VIEW view_name
以下查詢刪除名為 emp_30000 的檢視
hive> DROP VIEW emp_30000;
建立索引
索引只不過是指向表特定列的指標。建立索引意味著在表的特定列上建立指標。其語法如下
CREATE INDEX index_name ON TABLE base_table_name (col_name, ...) AS 'index.handler.class.name' [WITH DEFERRED REBUILD] [IDXPROPERTIES (property_name=property_value, ...)] [IN TABLE index_table_name] [PARTITIONED BY (col_name, ...)] [ [ ROW FORMAT ...] STORED AS ... | STORED BY ... ] [LOCATION hdfs_path] [TBLPROPERTIES (...)]
示例
讓我們以索引為例。使用我們之前使用過的相同的員工表,欄位為 Id、Name、Salary、Designation 和 Dept。在員工表的 salary 列上建立一個名為 index_salary 的索引。
以下查詢建立了一個索引
hive> CREATE INDEX inedx_salary ON TABLE employee(salary) > AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler';
它是 salary 列的指標。如果修改了該列,則使用索引值儲存更改。
刪除索引
以下語法用於刪除索引
DROP INDEX <index_name> ON <table_name>
以下查詢刪除名為 index_salary 的索引
hive> DROP INDEX index_salary ON employee;