- HBase 教程
- HBase - 首頁
- HBase - 概述
- HBase - 架構
- HBase - 安裝
- HBase - Shell
- HBase - 常用命令
- HBase - 管理員 API
- HBase - 建立表
- HBase - 列出表
- HBase - 停用表
- HBase - 啟用表
- HBase - 描述和修改
- HBase - 檢查表是否存在
- HBase - 刪除表
- HBase - 關閉
- HBase - 客戶端 API
- HBase - 建立資料
- HBase - 更新資料
- HBase - 讀取資料
- HBase - 刪除資料
- HBase - 掃描
- HBase - 計數和截斷
- HBase - 安全性
- HBase 資源
- HBase - 問答
- HBase - 快速指南
- HBase - 有用資源
HBase - 概述
自 1970 年以來,關係型資料庫管理系統 (RDBMS) 一直是解決資料儲存和維護相關問題的方案。在大資料出現後,企業意識到處理大資料的益處,並開始選擇 Hadoop 等解決方案。
Hadoop 使用分散式檔案系統來儲存大資料,並使用 MapReduce 來處理它。Hadoop 擅長儲存和處理各種格式的海量資料,例如任意格式、半結構化甚至非結構化資料。
Hadoop 的侷限性
Hadoop 只能執行批處理,並且只能以順序方式訪問資料。這意味著即使是最簡單的任務,也必須搜尋整個資料集。
當處理海量資料集時,會產生另一個海量資料集,該資料集也需要按順序進行處理。此時,需要一個新的解決方案來在單個時間單位內訪問資料的任意點(隨機訪問)。
Hadoop 隨機訪問資料庫
HBase、Cassandra、CouchDB、Dynamo 和 MongoDB 等應用程式是一些儲存海量資料並以隨機方式訪問資料的資料庫。
什麼是 HBase?
HBase 是一個構建在 Hadoop 檔案系統之上的分散式列式資料庫。它是一個開源專案,並且具有水平可擴充套件性。
HBase 是一種類似於 Google 的 Bigtable 的資料模型,旨在提供對海量結構化資料的快速隨機訪問。它利用了 Hadoop 檔案系統 (HDFS) 提供的容錯能力。
它是 Hadoop 生態系統的一部分,它提供對 Hadoop 檔案系統中資料的隨機即時讀寫訪問。
可以將資料直接儲存在 HDFS 中,也可以透過 HBase 儲存。資料消費者使用 HBase 以隨機方式讀取/訪問 HDFS 中的資料。HBase 位於 Hadoop 檔案系統之上,並提供讀寫訪問。
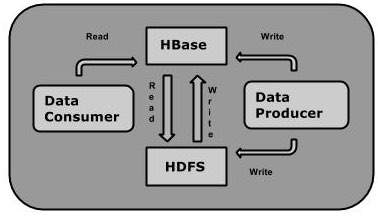
HBase 和 HDFS
| HDFS | HBase |
|---|---|
| HDFS 是一種適合儲存大型檔案的分散式檔案系統。 | HBase 是一個構建在 HDFS 之上的資料庫。 |
| HDFS 不支援快速單個記錄查詢。 | HBase 為更大的表提供快速查詢。 |
| 它提供高延遲批處理;沒有批處理的概念。 | 它提供對數十億條記錄中的單個行的低延遲訪問(隨機訪問)。 |
| 它僅提供資料的順序訪問。 | HBase 內部使用雜湊表並提供隨機訪問,它將資料儲存在索引的 HDFS 檔案中以加快查詢速度。 |
HBase 中的儲存機制
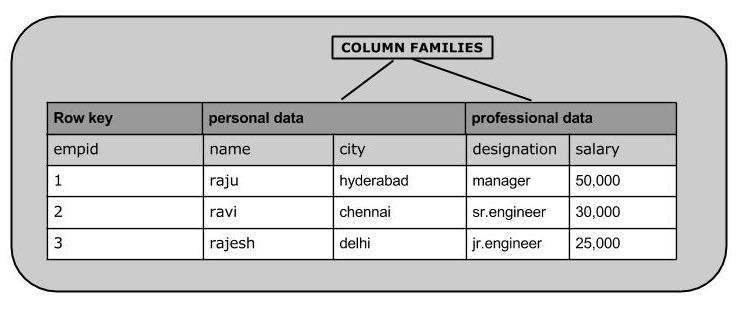
HBase 是一個**列式資料庫**,其中的表按行排序。表模式僅定義列族,它們是鍵值對。一個表可以有多個列族,每個列族可以有任意數量的列。後續列值連續儲存在磁碟上。表的每個單元格值都有一個時間戳。簡而言之,在 HBase 中
- 表是行的集合。
- 行是列族的集合。
- 列族是列的集合。
- 列是鍵值對的集合。
以下是 HBase 中表的示例模式。
| 行 ID | 列族 | 列族 | 列族 | 列族 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | |
| 1 | ||||||||||||
| 2 | ||||||||||||
| 3 | ||||||||||||
列式和行式
列式資料庫是指將資料表儲存為資料列的部分,而不是資料行的部分。簡而言之,它們將具有列族。
| 行式資料庫 | 列式資料庫 |
|---|---|
| 它適用於聯機事務處理 (OLTP)。 | 它適用於聯機分析處理 (OLAP)。 |
| 此類資料庫設計用於少量行和列。 | 列式資料庫設計用於大型表。 |
下圖顯示了列式資料庫中的列族
HBase 和 RDBMS
| HBase | RDBMS |
|---|---|
| HBase 是無模式的,它沒有固定列模式的概念;僅定義列族。 | RDBMS 受其模式的約束,模式描述了表的整個結構。 |
| 它構建用於寬表。HBase 具有水平可擴充套件性。 | 它很薄,並且構建用於小型表。難以擴充套件。 |
| HBase 中沒有事務。 | RDBMS 是事務型的。 |
| 它具有非規範化資料。 | 它將具有規範化資料。 |
| 它適用於半結構化資料和結構化資料。 | 它適用於結構化資料。 |
HBase 的特性
- HBase 具有線性可擴充套件性。
- 它具有自動故障支援。
- 它提供一致的讀寫。
- 它與 Hadoop 整合,既作為源也作為目標。
- 它具有易於使用的 Java API 供客戶端使用。
- 它提供跨叢集的資料複製。
在哪裡使用 HBase
Apache HBase 用於對大資料進行隨機、即時的讀寫訪問。
它在商品硬體叢集之上託管超大型表。
Apache HBase 是一個非關係型資料庫,其模型參考了 Google 的 Bigtable。Bigtable 在 Google 檔案系統上執行,類似地,Apache HBase 在 Hadoop 和 HDFS 之上執行。
HBase 的應用
- 當需要編寫重量級應用程式時使用它。
- 當我們需要為可用資料提供快速的隨機訪問時使用 HBase。
- Facebook、Twitter、Yahoo 和 Adobe 等公司在內部使用 HBase。
HBase 歷史
| 年份 | 事件 |
|---|---|
| 2006 年 11 月 | Google 釋出了關於 Bigtable 的論文。 |
| 2007 年 2 月 | 建立了最初的 HBase 原型作為 Hadoop 的貢獻。 |
| 2007 年 10 月 | 釋出了第一個可用的 HBase 以及 Hadoop 0.15.0。 |
| 2008 年 1 月 | HBase 成為 Hadoop 的子專案。 |
| 2008 年 10 月 | 釋出了 HBase 0.18.1。 |
| 2009 年 1 月 | 釋出了 HBase 0.19.0。 |
| 2009 年 9 月 | 釋出了 HBase 0.20.0。 |
| 2010 年 5 月 | HBase 成為 Apache 的頂級專案。 |