- Hadoop 教程
- Hadoop - 首頁
- Hadoop - 大資料概述
- Hadoop - 大資料解決方案
- Hadoop - 簡介
- Hadoop - 環境搭建
- Hadoop - HDFS 概述
- Hadoop - HDFS 操作
- Hadoop - 命令參考
- Hadoop - MapReduce
- Hadoop - 流處理 (Streaming)
- Hadoop - 多節點叢集
- Hadoop 有用資源
- Hadoop - 常見問題解答
- Hadoop 快速指南
- Hadoop - 有用資源
Hadoop 快速指南
Hadoop - 大資料概述
“全球90%的資料是在過去幾年中產生的。”
由於新技術、裝置和社交網路等通訊手段的出現,人類每年產生的資料量都在迅速增長。從古至今到2003年,我們產生的資料總量為50億吉位元組。如果把這些資料以磁碟的形式堆疊起來,可能可以填滿整個足球場。而同樣的資料量,在2011年每兩天產生一次,在2013年每十分鐘產生一次。這一增長速度仍在持續快速增長。儘管所有這些產生的資訊都很有意義,並在經過處理後可以發揮作用,但它們卻被忽視了。
什麼是大資料?
大資料是指無法使用傳統計算技術進行處理的大型資料集的集合。它不是單一的技術或工具,而是一個完整的學科,涉及各種工具、技術和框架。
大資料包含哪些內容?
大資料包含不同裝置和應用程式產生的資料。以下是屬於大資料領域的一些方面。
黑盒資料 - 它是直升機、飛機和噴氣式飛機等的組成部分。它捕獲飛行機組人員的聲音、麥克風和耳機的錄音以及飛機的效能資訊。
社交媒體資料 - Facebook 和 Twitter 等社交媒體包含來自全球數百萬人的資訊和觀點。
證券交易資料 - 證券交易資料包含客戶對不同公司股票的“買入”和“賣出”決策資訊。
電網資料 - 電網資料包含特定節點相對於基站的功耗資訊。
交通資料 - 交通資料包括車輛的型號、容量、行駛距離和可用性。
搜尋引擎資料 - 搜尋引擎從不同的資料庫檢索大量資料。

因此,大資料包含海量資料、高速資料和可擴充套件的各種資料。其中的資料將分為三種類型。
結構化資料 - 關係資料。
半結構化資料 - XML 資料。
非結構化資料 - Word、PDF、文字、媒體日誌。
大資料的益處
利用 Facebook 等社交網路中的資訊,營銷機構可以瞭解其活動、促銷和其他廣告媒介的響應情況。
透過利用社交媒體中的資訊,例如消費者的偏好和產品認知,產品公司和零售組織正在規劃其生產。
透過使用患者既往病史的資料,醫院可以提供更好、更快捷的服務。
大資料技術
大資料技術對於提供更準確的分析至關重要,這可能帶來更具體的決策,從而提高業務運營效率、降低成本並降低風險。
為了利用大資料的力量,您需要一個能夠即時管理和處理海量結構化和非結構化資料,並能夠保護資料隱私和安全的架構。
市場上有來自亞馬遜、IBM、微軟等不同供應商的各種技術來處理大資料。在研究處理大資料的技術時,我們考察以下兩類技術:
運營型大資料
這包括像 MongoDB 這樣的系統,它們為即時、互動式工作負載提供操作能力,資料主要在其中捕獲和儲存。
NoSQL 大資料系統旨在利用過去十年中出現的新型雲計算架構,從而允許以經濟高效的方式執行海量計算。這使得運營型大資料工作負載更容易管理、更便宜且更快地實現。
一些 NoSQL 系統可以在無需編碼,並且無需資料科學家和額外基礎設施的情況下,根據即時資料提供對模式和趨勢的洞察。
分析型大資料
這包括像大規模並行處理 (MPP) 資料庫系統和 MapReduce 這樣的系統,它們為回顧性和複雜分析提供分析能力,這些分析可能涉及大部分或全部資料。
MapReduce 提供了一種新的資料分析方法,它與 SQL 提供的功能相輔相成,並且基於 MapReduce 的系統可以從單臺伺服器擴充套件到數千臺高低端機器。
這兩類技術是互補的,並且經常一起部署。
運營型系統與分析型系統
| 運營型 | 分析型 | |
|---|---|---|
| 延遲 | 1 毫秒 - 100 毫秒 | 1 分鐘 - 100 分鐘 |
| 併發性 | 1000 - 100,000 | 1 - 10 |
| 訪問模式 | 寫入和讀取 | 讀取 |
| 查詢 | 選擇性 | 非選擇性 |
| 資料範圍 | 運營型 | 回顧性 |
| 終端使用者 | 客戶 | 資料科學家 |
| 技術 | NoSQL | MapReduce,MPP 資料庫 |
大資料挑戰
與大資料相關的重大挑戰如下:
- 資料採集
- 資料整理
- 資料儲存
- 資料搜尋
- 資料共享
- 資料傳輸
- 資料分析
- 資料呈現
為了應對上述挑戰,組織通常會藉助企業伺服器。
Hadoop - 大資料解決方案
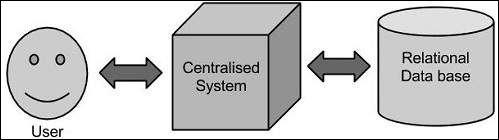
傳統方法
在這種方法中,企業將擁有一臺計算機來儲存和處理大資料。為了儲存,程式設計師將藉助他們選擇的資料庫供應商,例如 Oracle、IBM 等。在這種方法中,使用者與應用程式互動,應用程式反過來處理資料儲存和分析的部分。
侷限性
這種方法適用於處理那些標準資料庫伺服器可以容納的資料量較小的應用程式,或者處理資料的處理器的限制範圍內。但是,當涉及到處理大量可擴充套件資料時,透過單個數據庫瓶頸來處理此類資料是一項繁瑣的任務。
Google 的解決方案
Google 使用名為 MapReduce 的演算法解決了這個問題。此演算法將任務劃分為小的部分並將其分配給許多計算機,並從它們那裡收集結果,這些結果整合後形成結果資料集。

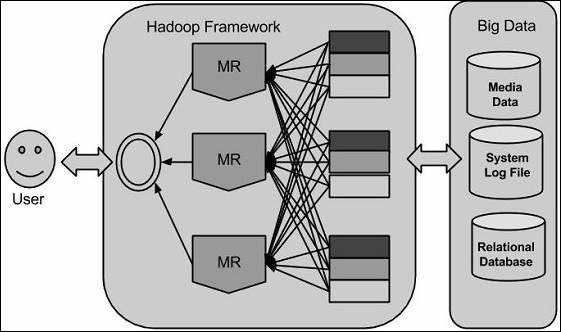
Hadoop
利用 Google 提供的解決方案,Doug Cutting 和他的團隊開發了一個名為 HADOOP 的開源專案。
Hadoop 使用 MapReduce 演算法執行應用程式,其中資料與其他資料並行處理。簡而言之,Hadoop 用於開發能夠對海量資料執行完整統計分析的應用程式。
Hadoop - 簡介
Hadoop 是一個用 Java 編寫的 Apache 開源框架,它允許使用簡單的程式設計模型跨計算機叢集分散式處理大型資料集。Hadoop 框架應用程式在一個環境中執行,該環境在計算機叢集中提供分散式儲存和計算。Hadoop 設計用於從單臺伺服器擴充套件到數千臺機器,每臺機器都提供本地計算和儲存。
Hadoop 架構
Hadoop 的核心有兩個主要層:
- 處理/計算層 (MapReduce),和
- 儲存層 (Hadoop 分散式檔案系統)。

MapReduce
MapReduce 是一種並行程式設計模型,用於編寫分散式應用程式,由 Google 設計用於在大型商品硬體叢集(數千個節點)上高效處理大量資料(多 TB 資料集),以可靠、容錯的方式。MapReduce 程式執行在 Hadoop 上,Hadoop 是一個 Apache 開源框架。
Hadoop 分散式檔案系統
Hadoop 分散式檔案系統 (HDFS) 基於 Google 檔案系統 (GFS),並提供一個設計在商品硬體上執行的分散式檔案系統。它與現有的分散式檔案系統有很多相似之處。但是,與其他分散式檔案系統的區別是顯著的。它具有高度容錯性,並設計用於部署在低成本硬體上。它提供對應用程式資料的較高吞吐量訪問,並且適用於具有大型資料集的應用程式。
除了上述兩個核心元件外,Hadoop 框架還包括以下兩個模組:
Hadoop Common - 這些是其他 Hadoop 模組所需的 Java 庫和實用程式。
Hadoop YARN - 這是一個用於作業排程和叢集資源管理的框架。
Hadoop 如何工作?
構建具有強大配置以處理大規模處理的更大伺服器非常昂貴,但作為替代方案,您可以將許多帶有單 CPU 的商品計算機連線在一起,作為一個單一的、功能性的分散式系統,實際上,叢集機器可以並行讀取資料集並提供更高的吞吐量。此外,它比一臺高階伺服器更便宜。因此,這是使用 Hadoop 的第一個動機因素,因為它可以在叢集式和低成本機器上執行。
Hadoop 在計算機叢集上執行程式碼。此過程包括 Hadoop 執行的以下核心任務:
資料最初被劃分為目錄和檔案。檔案被劃分為大小相同的塊,為 128M 和 64M(最好是 128M)。
然後將這些檔案分發到各個叢集節點以進行進一步處理。
HDFS 位於本地檔案系統之上,負責監督處理過程。
複製塊以處理硬體故障。
檢查程式碼是否已成功執行。
執行 map 和 reduce 階段之間發生的排序。
將排序後的資料傳送到特定計算機。
為每個作業編寫除錯日誌。
Hadoop 的優勢
Hadoop 框架允許使用者快速編寫和測試分散式系統。它效率很高,它自動將資料和工作分配到各個機器上,從而利用 CPU 核心的底層並行性。
Hadoop 不依賴於硬體來提供容錯性和高可用性 (FTHA),而是 Hadoop 庫本身的設計就是為了檢測和處理應用程式層面的故障。
可以動態地向叢集新增或刪除伺服器,而 Hadoop 繼續不間斷地執行。
Hadoop 的另一個巨大優勢是,它除了是開源的之外,由於它是基於 Java 的,因此在所有平臺上都相容。
Hadoop - 環境搭建
Hadoop 支援 GNU/Linux 平臺及其衍生版本。因此,我們必須安裝 Linux 作業系統才能搭建 Hadoop 環境。如果您使用的作業系統不是 Linux,可以在其中安裝 Virtualbox 軟體,並在 Virtualbox 中安裝 Linux。
安裝前設定
在 Linux 環境中安裝 Hadoop 之前,我們需要使用ssh(安全外殼)設定 Linux。請按照以下步驟設定 Linux 環境。
建立使用者
首先,建議為 Hadoop 建立一個單獨的使用者,以將 Hadoop 檔案系統與 Unix 檔案系統隔離。請按照以下步驟建立使用者:
使用命令“su”開啟 root。
使用命令“useradd 使用者名稱”從 root 帳戶建立使用者。
現在,您可以使用命令“su 使用者名稱”開啟現有的使用者帳戶。
開啟 Linux 終端並鍵入以下命令以建立使用者。
$ su password: # useradd hadoop # passwd hadoop New passwd: Retype new passwd
SSH 設定和金鑰生成
SSH 設定是執行叢集上不同操作(例如啟動、停止、分散式守護程式 shell 操作)所必需的。為了對 Hadoop 的不同使用者進行身份驗證,需要為 Hadoop 使用者提供公鑰/私鑰對,並將其與不同的使用者共享。
以下命令用於使用 SSH 生成金鑰值對。將公鑰從 id_rsa.pub 複製到 authorized_keys,並分別為所有者提供對 authorized_keys 檔案的讀寫許可權。
$ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
安裝 Java
Java 是 Hadoop 的主要先決條件。首先,您應該使用命令“java -version”驗證系統中是否存在 java。java 版本命令的語法如下所示。
$ java -version
如果一切正常,它將為您提供以下輸出。
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果您的系統中未安裝 java,則請按照以下步驟安裝 java。
步驟 1
訪問以下連結下載 java(JDK <最新版本>-X64.tar.gz)www.oracle.com
然後jdk-7u71-linux-x64.tar.gz 將下載到您的系統中。
步驟 2
通常,您會在 Downloads 資料夾中找到下載的 java 檔案。驗證它並使用以下命令解壓jdk-7u71-linux-x64.gz 檔案。
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
步驟 3
要使所有使用者都能使用 java,您必須將其移動到“/usr/local/”位置。開啟 root,然後鍵入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
步驟 4
要設定PATH 和JAVA_HOME 變數,請將以下命令新增到~/.bashrc 檔案中。
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH=$PATH:$JAVA_HOME/bin
現在將所有更改應用到當前執行的系統中。
$ source ~/.bashrc
步驟 5
使用以下命令配置 java 替代項:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2 # alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 # alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 # alternatives --set java usr/local/java/bin/java # alternatives --set javac usr/local/java/bin/javac # alternatives --set jar usr/local/java/bin/jar
現在,如上所述,從終端驗證 java -version 命令。
下載 Hadoop
使用以下命令從 Apache 軟體基金會下載並解壓 Hadoop 2.4.1。
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
Hadoop 操作模式
下載 Hadoop 後,您可以透過三種受支援的模式之一來操作 Hadoop 叢集:
本地/獨立模式 - 在您的系統中下載 Hadoop 後,預設情況下,它以獨立模式配置,並且可以作為單個 java 程序執行。
偽分散式模式 - 這是在單臺機器上的分散式模擬。每個 Hadoop 守護程式(例如 hdfs、yarn、MapReduce 等)都將作為單獨的 java 程序執行。此模式對於開發很有用。
完全分散式模式 - 此模式是完全分散式的,至少需要兩臺或多臺機器作為叢集。我們將在接下來的章節中詳細介紹此模式。
在獨立模式下安裝 Hadoop
在這裡,我們將討論在獨立模式下安裝Hadoop 2.4.1。
沒有執行的守護程式,所有內容都在單個 JVM 中執行。獨立模式適用於在開發過程中執行 MapReduce 程式,因為它易於測試和除錯。
設定 Hadoop
您可以透過將以下命令新增到~/.bashrc 檔案來設定 Hadoop 環境變數。
export HADOOP_HOME=/usr/local/hadoop
在繼續之前,您需要確保 Hadoop 執行良好。只需發出以下命令:
$ hadoop version
如果您的設定一切正常,那麼您應該看到以下結果:
Hadoop 2.4.1 Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
這意味著您的 Hadoop 獨立模式設定執行良好。預設情況下,Hadoop 配置為在單臺機器上以非分散式模式執行。
示例
讓我們檢查一下 Hadoop 的一個簡單示例。Hadoop 安裝提供以下示例 MapReduce jar 檔案,該檔案提供 MapReduce 的基本功能,可用於計算,例如 Pi 值、給定檔案列表中的單詞計數等。
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar
讓我們建立一個輸入目錄,我們將向其中推送一些檔案,我們的要求是計算這些檔案中的總單詞數。為了計算總單詞數,我們不需要編寫自己的 MapReduce,前提是 .jar 檔案包含單詞計數的實現。您可以使用相同的 .jar 檔案嘗試其他示例;只需發出以下命令即可檢查 hadoop-mapreduce-examples-2.2.0.jar 檔案支援的 MapReduce 功能程式。
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar
步驟 1
在輸入目錄中建立臨時內容檔案。您可以在任何想要工作的地方建立此輸入目錄。
$ mkdir input $ cp $HADOOP_HOME/*.txt input $ ls -l input
它將在您的輸入目錄中提供以下檔案:
total 24 -rw-r--r-- 1 root root 15164 Feb 21 10:14 LICENSE.txt -rw-r--r-- 1 root root 101 Feb 21 10:14 NOTICE.txt -rw-r--r-- 1 root root 1366 Feb 21 10:14 README.txt
這些檔案已從 Hadoop 安裝主目錄複製。在您的實驗中,您可以擁有不同且更大的檔案集。
步驟 2
讓我們啟動 Hadoop 程序來計算輸入目錄中所有檔案的總單詞數,如下所示:
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar wordcount input output
步驟 3
步驟 2 將執行所需的處理並將輸出儲存在 output/part-r00000 檔案中,您可以使用以下方法檢查:
$cat output/*
它將列出輸入目錄中所有檔案中所有單詞及其總計數。
"AS 4 "Contribution" 1 "Contributor" 1 "Derivative 1 "Legal 1 "License" 1 "License"); 1 "Licensor" 1 "NOTICE” 1 "Not 1 "Object" 1 "Source” 1 "Work” 1 "You" 1 "Your") 1 "[]" 1 "control" 1 "printed 1 "submitted" 1 (50%) 1 (BIS), 1 (C) 1 (Don't) 1 (ECCN) 1 (INCLUDING 2 (INCLUDING, 2 .............
在偽分散式模式下安裝 Hadoop
請按照以下步驟在偽分散式模式下安裝 Hadoop 2.4.1。
步驟 1 - 設定 Hadoop
您可以透過將以下命令新增到~/.bashrc 檔案來設定 Hadoop 環境變數。
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOME
現在將所有更改應用到當前執行的系統中。
$ source ~/.bashrc
步驟 2 - Hadoop 配置
您可以在“$HADOOP_HOME/etc/hadoop”位置找到所有 Hadoop 配置檔案。需要根據您的 Hadoop 基礎設施更改這些配置檔案。
$ cd $HADOOP_HOME/etc/hadoop
為了用 java 開發 Hadoop 程式,您必須透過將JAVA_HOME 值替換為系統中 java 的位置來重置hadoop-env.sh 檔案中的 java 環境變數。
export JAVA_HOME=/usr/local/jdk1.7.0_71
以下是您必須編輯以配置 Hadoop 的檔案列表。
core-site.xml
core-site.xml 檔案包含諸如 Hadoop 例項使用的埠號、為檔案系統分配的記憶體、儲存資料的記憶體限制以及讀/寫緩衝區的大小等資訊。
開啟 core-site.xml 並將以下屬性新增到 <configuration>、</configuration> 標記之間。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://:9000</value>
</property>
</configuration>
hdfs-site.xml
hdfs-site.xml 檔案包含諸如複製資料的值、namenode 路徑和本地檔案系統的 datanode 路徑等資訊。這意味著您要儲存 Hadoop 基礎設施的位置。
讓我們假設以下資料。
dfs.replication (data replication value) = 1 (In the below given path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
開啟此檔案並將以下屬性新增到此檔案中的 <configuration> </configuration> 標記之間。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>
注意 - 在上述檔案中,所有屬性值都是使用者定義的,您可以根據您的 Hadoop 基礎設施進行更改。
yarn-site.xml
此檔案用於將 yarn 配置到 Hadoop 中。開啟 yarn-site.xml 檔案並將以下屬性新增到此檔案中的 <configuration>、</configuration> 標記之間。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
此檔案用於指定我們正在使用哪個 MapReduce 框架。預設情況下,Hadoop 包含 yarn-site.xml 的模板。首先,需要使用以下命令將檔案從mapred-site.xml.template 複製到mapred-site.xml 檔案:
$ cp mapred-site.xml.template mapred-site.xml
開啟mapred-site.xml 檔案並將以下屬性新增到此檔案中的 <configuration>、</configuration> 標記之間。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
驗證 Hadoop 安裝
以下步驟用於驗證 Hadoop 安裝。
步驟 1 - Name Node 設定
使用命令“hdfs namenode -format”設定 namenode,如下所示。
$ cd ~ $ hdfs namenode -format
預期結果如下。
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
步驟 2 - 驗證 Hadoop dfs
以下命令用於啟動 dfs。執行此命令將啟動您的 Hadoop 檔案系統。
$ start-dfs.sh
預期輸出如下:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
步驟 3 - 驗證 Yarn 指令碼
以下命令用於啟動 yarn 指令碼。執行此命令將啟動您的 yarn 守護程式。
$ start-yarn.sh
預期輸出如下:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop 2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
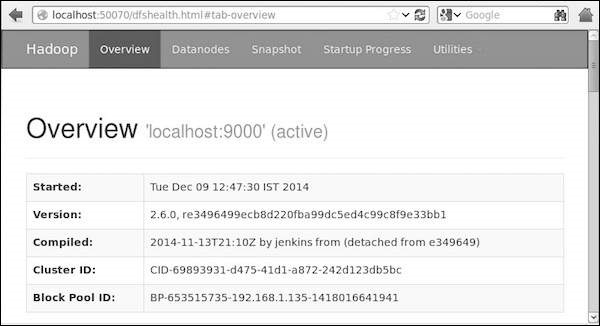
步驟 4 - 在瀏覽器上訪問 Hadoop
訪問 Hadoop 的預設埠號為 50070。使用以下網址在瀏覽器上獲取 Hadoop 服務。
https://:50070/
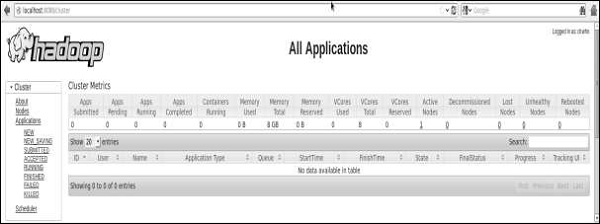
步驟 5 - 驗證叢集的所有應用程式
訪問叢集所有應用程式的預設埠號為 8088。使用以下網址訪問此服務。
https://:8088/
Hadoop - HDFS 概述
Hadoop 檔案系統是使用分散式檔案系統設計開發的。它執行在商用硬體上。與其他分散式系統不同,HDFS 具有高度容錯性,並使用低成本硬體進行設計。
HDFS 儲存海量資料,並提供更輕鬆的訪問。為了儲存如此龐大的資料,檔案儲存在多臺機器上。這些檔案以冗餘方式儲存,以在發生故障時保護系統免受可能的資料丟失的影響。HDFS 還使應用程式能夠進行並行處理。
HDFS 的特點
- 它適用於分散式儲存和處理。
- Hadoop 提供命令介面與 HDFS 互動。
- namenode 和 datanode 的內建伺服器幫助使用者輕鬆檢查叢集狀態。
- 流式訪問檔案系統資料。
- HDFS 提供檔案許可權和身份驗證。
HDFS 架構
以下是 Hadoop 檔案系統的架構。
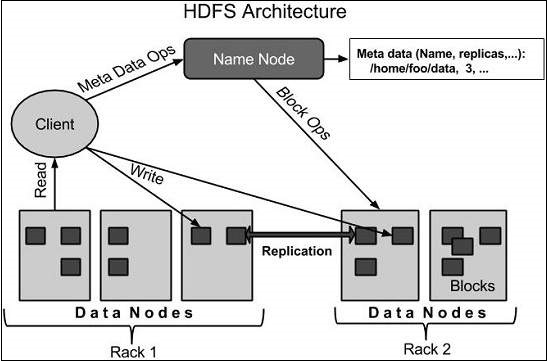
HDFS 遵循主從架構,它具有以下元素。
Namenode
namenode 是包含 GNU/Linux 作業系統和 namenode 軟體的商用硬體。它是一種可以在商用硬體上執行的軟體。擁有 namenode 的系統充當主伺服器,它執行以下任務:
管理檔案系統名稱空間。
規範客戶端對檔案的訪問。
它還執行檔案系統操作,例如重新命名、關閉和開啟檔案和目錄。
Datanode
datanode 是一種具有 GNU/Linux 作業系統和 datanode 軟體的商用硬體。對於叢集中的每個節點(商用硬體/系統),都將有一個 datanode。這些節點管理其系統的資料儲存。
根據客戶端請求,Datanode 對檔案系統執行讀寫操作。
它們還根據 namenode 的指令執行諸如塊建立、刪除和複製等操作。
塊
通常,使用者資料儲存在 HDFS 的檔案中。檔案系統中的檔案將被分成一個或多個段,並/或儲存在各個資料節點中。這些檔案段稱為塊。換句話說,HDFS 可以讀取或寫入的最小資料量稱為塊。預設塊大小為 64MB,但可以根據需要更改 HDFS 配置來增加。
HDFS 的目標
故障檢測和恢復 − 由於HDFS包含大量商用硬體,元件故障頻繁發生。因此,HDFS應該具有快速自動故障檢測和恢復機制。
海量資料集 − HDFS應該擁有每叢集數百個節點來管理具有海量資料集的應用程式。
資料本地化 − 當計算發生在資料附近時,可以高效地完成請求的任務。尤其是在涉及海量資料集的情況下,它可以減少網路流量並提高吞吐量。
Hadoop - HDFS 操作
啟動HDFS
最初,您必須格式化已配置的HDFS檔案系統,開啟namenode(HDFS伺服器)並執行以下命令。
$ hadoop namenode -format
格式化HDFS後,啟動分散式檔案系統。以下命令將啟動namenode以及資料節點作為叢集。
$ start-dfs.sh
列出HDFS中的檔案
在伺服器中載入資訊後,我們可以使用‘ls’查詢目錄中的檔案列表和檔案狀態。下面是您可以將目錄或檔名作為引數傳遞給ls的語法。
$ $HADOOP_HOME/bin/hadoop fs -ls <args>
將資料插入HDFS
假設我們在本地系統中有一個名為file.txt的檔案,需要將其儲存到hdfs檔案系統中。請按照以下步驟將所需檔案插入Hadoop檔案系統。
步驟 1
您必須建立一個輸入目錄。
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/input
步驟 2
使用put命令將資料檔案從本地系統傳輸並存儲到Hadoop檔案系統中。
$ $HADOOP_HOME/bin/hadoop fs -put /home/file.txt /user/input
步驟 3
您可以使用ls命令驗證檔案。
$ $HADOOP_HOME/bin/hadoop fs -ls /user/input
從HDFS檢索資料
假設我們在HDFS中有一個名為outfile的檔案。下面是從小Hadoop檔案系統檢索所需檔案的簡單演示。
步驟 1
首先,使用cat命令檢視HDFS中的資料。
$ $HADOOP_HOME/bin/hadoop fs -cat /user/output/outfile
步驟 2
使用get命令將檔案從HDFS獲取到本地檔案系統。
$ $HADOOP_HOME/bin/hadoop fs -get /user/output/ /home/hadoop_tp/
關閉HDFS
您可以使用以下命令關閉HDFS。
$ stop-dfs.sh
Hadoop - 命令參考
"$HADOOP_HOME/bin/hadoop fs" 中還有許多在此處未演示的命令,儘管這些基本操作可以幫助您入門。執行 ./bin/hadoop dfs 而不新增任何引數將列出可以使用FsShell系統執行的所有命令。此外,如果您遇到問題,$HADOOP_HOME/bin/hadoop fs -help commandName 命令將顯示有關該操作的簡短用法摘要。
下面顯示所有操作的表格。引數使用以下約定:
"<path>" means any file or directory name. "<path>..." means one or more file or directory names. "<file>" means any filename. "<src>" and "<dest>" are path names in a directed operation. "<localSrc>" and "<localDest>" are paths as above, but on the local file system.
所有其他檔案和路徑名都指HDFS內部的物件。
| 序號 | 命令和描述 |
|---|---|
| 1 | -ls <path> 列出path指定目錄的內容,顯示每個條目的名稱、許可權、所有者、大小和修改日期。 |
| 2 | -lsr <path> 類似於-ls,但遞迴地顯示path所有子目錄中的條目。 |
| 3 | -du <path> 顯示與path匹配的所有檔案的磁碟使用情況(以位元組為單位);檔名將使用完整的HDFS協議字首報告。 |
| 4 | -dus <path> 類似於-du,但列印path中所有檔案/目錄的磁碟使用情況摘要。 |
| 5 | -mv <src><dest> 將src指示的檔案或目錄移動到HDFS中的dest。 |
| 6 | -cp <src> <dest> 將src標識的檔案或目錄複製到HDFS中的dest。 |
| 7 | -rm <path> 刪除path標識的檔案或空目錄。 |
| 8 | -rmr <path> 刪除path標識的檔案或目錄。遞迴刪除任何子條目(即path的檔案或子目錄)。 |
| 9 | -put <localSrc> <dest> 將本地檔案系統中由localSrc標識的檔案或目錄複製到DFS中的dest。 |
| 10 | -copyFromLocal <localSrc> <dest> 與-put相同 |
| 11 | -moveFromLocal <localSrc> <dest> 將本地檔案系統中由localSrc標識的檔案或目錄複製到HDFS中的dest,然後在成功後刪除本地副本。 |
| 12 | -get [-crc] <src> <localDest> 將HDFS中由src標識的檔案或目錄複製到由localDest標識的本地檔案系統路徑。 |
| 13 | -getmerge <src> <localDest> 檢索HDFS中與路徑src匹配的所有檔案,並將它們複製到本地檔案系統中由localDest標識的單個合併檔案中。 |
| 14 | -cat <filen-ame> 在stdout上顯示filename的內容。 |
| 15 | -copyToLocal <src> <localDest> 與-get相同 |
| 16 | -moveToLocal <src> <localDest> 類似於-get,但在成功後刪除HDFS副本。 |
| 17 | -mkdir <path> 在HDFS中建立名為path的目錄。 建立path中任何缺少的父目錄(例如,Linux中的mkdir -p)。 |
| 18 | -setrep [-R] [-w] rep <path> 將path標識的檔案的目標副本數設定為rep。(實際副本數將隨著時間的推移向目標移動) |
| 19 | -touchz <path> 在path處建立一個檔案,其中包含當前時間作為時間戳。如果path處已存在檔案,則失敗,除非檔案大小已為0。 |
| 20 | -test -[ezd] <path> 如果path存在;長度為零;或者是一個目錄,則返回1;否則返回0。 |
| 21 | -stat [format] <path> 列印有關path的資訊。format是一個字串,它接受以塊為單位的檔案大小(%b)、檔名(%n)、塊大小(%o)、副本數(%r)和修改日期(%y,%Y)。 |
| 22 | -tail [-f] <file2name> 在stdout上顯示檔案的最後1KB。 |
| 23 | -chmod [-R] mode,mode,... <path>... 更改path…標識的一個或多個物件關聯的檔案許可權。使用R遞迴執行更改。mode是3位八進位制模式,或{augo}+/-{rwxX}。假設如果沒有指定範圍並且不應用umask。 |
| 24 | -chown [-R] [owner][:[group]] <path>... 設定path…標識的檔案或目錄的所有者使用者和/或組。如果指定-R,則遞迴設定所有者。 |
| 25 | -chgrp [-R] group <path>... 設定path…標識的檔案或目錄的所有者組。如果指定-R,則遞迴設定組。 |
| 26 | -help <cmd-name> 返回上面列出的命令之一的用法資訊。您必須省略cmd開頭的'-'字元。 |
Hadoop - MapReduce
MapReduce是一個框架,我們可以使用它編寫應用程式來並行處理大量資料,在大規模商用硬體叢集上可靠地執行。
什麼是MapReduce?
MapReduce是一種基於Java的分散式計算處理技術和程式模型。MapReduce演算法包含兩個重要的任務,即Map和Reduce。Map接收一組資料並將其轉換為另一組資料,其中單個元素被分解成元組(鍵/值對)。其次,reduce任務將map的輸出作為輸入,並將這些資料元組組合成更小的元組集。正如MapReduce名稱的順序所示,reduce任務總是在map作業之後執行。
MapReduce的主要優勢在於它易於跨多個計算節點擴充套件資料處理。在MapReduce模型下,資料處理原語稱為mapper和reducer。將資料處理應用程式分解成mapper和reducer有時並非易事。但是,一旦我們以MapReduce的形式編寫應用程式,將應用程式擴充套件到在叢集中的數百、數千甚至數萬臺機器上執行僅僅是配置更改的問題。這種簡單的可擴充套件性吸引了許多程式設計師使用MapReduce模型。
演算法
通常,MapReduce範例基於將計算傳送到資料所在的位置!
MapReduce程式分三個階段執行,即map階段、shuffle階段和reduce階段。
Map階段 − map或mapper的任務是處理輸入資料。通常,輸入資料是檔案或目錄的形式,並存儲在Hadoop檔案系統(HDFS)中。輸入檔案逐行傳遞給mapper函式。mapper處理資料並建立多個小的資料塊。
Reduce階段 − 此階段是Shuffle階段和Reduce階段的組合。Reducer的任務是處理來自mapper的資料。處理後,它會生成一組新的輸出,這些輸出將儲存在HDFS中。
在MapReduce作業期間,Hadoop將Map和Reduce任務傳送到叢集中的相應伺服器。
該框架管理所有資料傳遞細節,例如發出任務、驗證任務完成以及在節點之間複製資料。
大部分計算發生在本地磁碟上有資料的節點上,從而減少了網路流量。
給定任務完成後,叢集收集並減少資料以形成適當的結果,並將其傳送回Hadoop伺服器。

輸入和輸出(Java視角)
MapReduce框架操作於<key, value>對,也就是說,該框架將作業的輸入視為一組<key, value>對,並生成一組<key, value>對作為作業的輸出,這些對可能屬於不同的型別。
鍵和值類應該以序列化的方式由框架處理,因此需要實現Writable介面。此外,鍵類必須實現Writable-Comparable介面,以方便框架進行排序。MapReduce作業的輸入和輸出型別 − (輸入) <k1, v1> → map → <k2, v2> → reduce → <k3, v3>(輸出)。
| 輸入 | 輸出 | |
|---|---|---|
| Map | <k1, v1> | 列表 (<k2, v2>) |
| Reduce | <k2, 列表(v2)> | 列表 (<k3, v3>) |
術語
有效載荷 − 應用程式實現Map和Reduce函式,構成作業的核心。
Mapper − Mapper將輸入鍵/值對對映到一組中間鍵/值對。
NamedNode − 管理Hadoop分散式檔案系統(HDFS)的節點。
DataNode − 在任何處理發生之前提前呈現資料的節點。
主節點 (MasterNode) − JobTracker執行的節點,接收來自客戶端的作業請求。
從節點 (SlaveNode) − Map和Reduce程式執行的節點。
JobTracker − 排程作業並將分配的作業跟蹤到Task tracker。
Task Tracker − 跟蹤任務並將狀態報告給JobTracker。
作業 (Job) − 程式是在資料集上執行Mapper和Reducer。
任務 (Task) − 在資料片上執行Mapper或Reducer。
任務嘗試 (Task Attempt) − 在SlaveNode上執行任務嘗試的特定例項。
示例場景
下面是關於某組織電力消耗的資料。它包含各個年份的月度電力消耗和年度平均值。
| 一月 | 二月 | 三月 | 四月 | 五月 | 六月 | 七月 | 八月 | 九月 | 十月 | 十一月 | 十二月 | 平均值 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
如果以上資料作為輸入給出,我們必須編寫應用程式來處理它並生成結果,例如查詢最大使用量年份、最小使用量年份等等。對於具有有限記錄數的程式設計師來說,這是一個簡單的任務。他們只需編寫邏輯來生成所需的輸出,並將資料傳遞給編寫的應用程式。
但是,考慮一下表示某個州自成立以來所有大型工業的電力消耗的資料。
當我們編寫應用程式來處理此類海量資料時,
它們將花費大量時間來執行。
當我們將資料從源移動到網路伺服器等等時,將會有大量的網路流量。
為了解決這些問題,我們有MapReduce框架。
輸入資料
以上資料儲存為sample.txt並作為輸入提供。輸入檔案如下所示。
1979 23 23 2 43 24 25 26 26 26 26 25 26 25 1980 26 27 28 28 28 30 31 31 31 30 30 30 29 1981 31 32 32 32 33 34 35 36 36 34 34 34 34 1984 39 38 39 39 39 41 42 43 40 39 38 38 40 1985 38 39 39 39 39 41 41 41 00 40 39 39 45
示例程式
下面是使用MapReduce框架對示例資料進行處理的程式。
package hadoop;
import java.util.*;
import java.io.IOException;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class ProcessUnits {
//Mapper class
public static class E_EMapper extends MapReduceBase implements
Mapper<LongWritable ,/*Input key Type */
Text, /*Input value Type*/
Text, /*Output key Type*/
IntWritable> /*Output value Type*/
{
//Map function
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
String line = value.toString();
String lasttoken = null;
StringTokenizer s = new StringTokenizer(line,"\t");
String year = s.nextToken();
while(s.hasMoreTokens()) {
lasttoken = s.nextToken();
}
int avgprice = Integer.parseInt(lasttoken);
output.collect(new Text(year), new IntWritable(avgprice));
}
}
//Reducer class
public static class E_EReduce extends MapReduceBase implements Reducer< Text, IntWritable, Text, IntWritable > {
//Reduce function
public void reduce( Text key, Iterator <IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int maxavg = 30;
int val = Integer.MIN_VALUE;
while (values.hasNext()) {
if((val = values.next().get())>maxavg) {
output.collect(key, new IntWritable(val));
}
}
}
}
//Main function
public static void main(String args[])throws Exception {
JobConf conf = new JobConf(ProcessUnits.class);
conf.setJobName("max_eletricityunits");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(E_EMapper.class);
conf.setCombinerClass(E_EReduce.class);
conf.setReducerClass(E_EReduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
將上述程式儲存為ProcessUnits.java。程式的編譯和執行解釋如下。
Process Units程式的編譯和執行
讓我們假設我們在Hadoop使用者的home目錄中(例如 /home/hadoop)。
按照以下步驟編譯並執行上述程式。
步驟 1
以下命令用於建立一個目錄來儲存編譯後的Java類。
$ mkdir units
步驟 2
下載**Hadoop-core-1.2.1.jar**,該檔案用於編譯和執行MapReduce程式。訪問以下連結mvnrepository.com下載jar包。假設下載後的資料夾路徑為** /home/hadoop/。**
步驟 3
以下命令用於編譯**ProcessUnits.java**程式併為該程式建立一個jar包。
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java $ jar -cvf units.jar -C units/ .
步驟 4
以下命令用於在HDFS中建立一個輸入目錄。
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
步驟 5
以下命令用於將名為**sample.txt**的輸入檔案複製到HDFS的輸入目錄中。
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dir
步驟6
以下命令用於驗證輸入目錄中的檔案。
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
步驟7
以下命令用於執行Eleunit_max應用程式,並從輸入目錄讀取輸入檔案。
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir
等待一段時間直到檔案執行完畢。執行完畢後,如下所示,輸出將包含輸入分片數、Map任務數、Reducer任務數等資訊。
INFO mapreduce.Job: Job job_1414748220717_0002
completed successfully
14/10/31 06:02:52
INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read = 61
FILE: Number of bytes written = 279400
FILE: Number of read operations = 0
FILE: Number of large read operations = 0
FILE: Number of write operations = 0
HDFS: Number of bytes read = 546
HDFS: Number of bytes written = 40
HDFS: Number of read operations = 9
HDFS: Number of large read operations = 0
HDFS: Number of write operations = 2 Job Counters
Launched map tasks = 2
Launched reduce tasks = 1
Data-local map tasks = 2
Total time spent by all maps in occupied slots (ms) = 146137
Total time spent by all reduces in occupied slots (ms) = 441
Total time spent by all map tasks (ms) = 14613
Total time spent by all reduce tasks (ms) = 44120
Total vcore-seconds taken by all map tasks = 146137
Total vcore-seconds taken by all reduce tasks = 44120
Total megabyte-seconds taken by all map tasks = 149644288
Total megabyte-seconds taken by all reduce tasks = 45178880
Map-Reduce Framework
Map input records = 5
Map output records = 5
Map output bytes = 45
Map output materialized bytes = 67
Input split bytes = 208
Combine input records = 5
Combine output records = 5
Reduce input groups = 5
Reduce shuffle bytes = 6
Reduce input records = 5
Reduce output records = 5
Spilled Records = 10
Shuffled Maps = 2
Failed Shuffles = 0
Merged Map outputs = 2
GC time elapsed (ms) = 948
CPU time spent (ms) = 5160
Physical memory (bytes) snapshot = 47749120
Virtual memory (bytes) snapshot = 2899349504
Total committed heap usage (bytes) = 277684224
File Output Format Counters
Bytes Written = 40
步驟8
以下命令用於驗證輸出資料夾中的結果檔案。
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
步驟9
以下命令用於檢視**Part-00000**檔案中的輸出。此檔案由HDFS生成。
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
以下是MapReduce程式生成的輸出。
1981 34 1984 40 1985 45
步驟10
以下命令用於將輸出資料夾從HDFS複製到本地檔案系統以進行分析。
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs get output_dir /home/hadoop
重要命令
所有Hadoop命令都透過**$HADOOP_HOME/bin/hadoop**命令呼叫。執行Hadoop指令碼而不帶任何引數將列印所有命令的描述。
**用法** − hadoop [--config confdir] COMMAND
下表列出了可用的選項及其描述。
| 序號 | 選項和描述 |
|---|---|
| 1 | namenode -format 格式化DFS檔案系統。 |
| 2 | secondarynamenode 執行DFS輔助NameNode。 |
| 3 | namenode 執行DFS NameNode。 |
| 4 | datanode 執行DFS DataNode。 |
| 5 | dfsadmin 執行DFS管理客戶端。 |
| 6 | mradmin 執行Map-Reduce管理客戶端。 |
| 7 | fsck 執行DFS檔案系統檢查實用程式。 |
| 8 | fs 執行通用檔案系統使用者客戶端。 |
| 9 | balancer 執行叢集平衡實用程式。 |
| 10 | oiv 將離線fsimage檢視器應用於fsimage。 |
| 11 | fetchdt 從NameNode獲取委託令牌。 |
| 12 | jobtracker 執行MapReduce JobTracker節點。 |
| 13 | pipes 執行Pipes作業。 |
| 14 | tasktracker 執行MapReduce TaskTracker節點。 |
| 15 | historyserver 作為獨立守護程序執行作業歷史伺服器。 |
| 16 | job 操作MapReduce作業。 |
| 17 | queue 獲取有關JobQueue的資訊。 |
| 18 | version 列印版本。 |
| 19 | jar <jar> 執行jar檔案。 |
| 20 | distcp <srcurl> <desturl> 遞迴複製檔案或目錄。 |
| 21 | distcp2 <srcurl> <desturl> DistCp版本2。 |
| 22 | archive -archiveName NAME -p <parent path> <src>* <dest> 建立Hadoop歸檔。 |
| 23 | classpath 列印獲取Hadoop jar和所需庫所需的類路徑。 |
| 24 | daemonlog 獲取/設定每個守護程式的日誌級別 |
如何與MapReduce作業互動
用法 − hadoop job [GENERIC_OPTIONS]
以下是Hadoop作業中可用的通用選項。
| 序號 | GENERIC_OPTION和描述 |
|---|---|
| 1 | -submit <job-file> 提交作業。 |
| 2 | -status <job-id> 列印對映和歸併完成百分比以及所有作業計數器。 |
| 3 | -counter <job-id> <group-name> <countername> 列印計數器值。 |
| 4 | -kill <job-id> 殺死作業。 |
| 5 | -events <job-id> <fromevent-#> <#-of-events> 列印JobTracker在給定範圍內接收的事件詳細資訊。 |
| 6 | -history [all] <jobOutputDir> - history < jobOutputDir> 列印作業詳細資訊、失敗和被殺死的提示詳細資訊。透過指定[all]選項,可以檢視有關作業的更多詳細資訊,例如每個任務成功完成的任務和任務嘗試次數。 |
| 7 | -list[all] 顯示所有作業。-list僅顯示尚未完成的作業。 |
| 8 | -kill-task <task-id> 殺死任務。被殺死的任務不計入失敗的嘗試次數。 |
| 9 | -fail-task <task-id> 使任務失敗。失敗的任務計入失敗的嘗試次數。 |
| 10 | -set-priority <job-id> <priority> 更改作業的優先順序。允許的優先順序值為VERY_HIGH、HIGH、NORMAL、LOW、VERY_LOW |
檢視作業狀態
$ $HADOOP_HOME/bin/hadoop job -status <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -status job_201310191043_0004
檢視作業輸出目錄的歷史記錄
$ $HADOOP_HOME/bin/hadoop job -history <DIR-NAME> e.g. $ $HADOOP_HOME/bin/hadoop job -history /user/expert/output
殺死作業
$ $HADOOP_HOME/bin/hadoop job -kill <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -kill job_201310191043_0004
Hadoop - 流處理 (Streaming)
Hadoop streaming是Hadoop發行版中自帶的一個實用程式。此實用程式允許您使用任何可執行檔案或指令碼作為mapper和/或reducer來建立和執行Map/Reduce作業。
使用Python的示例
對於Hadoop streaming,我們考慮單詞計數問題。Hadoop中的任何作業都必須包含兩個階段:mapper和reducer。我們已經用python指令碼編寫了mapper和reducer的程式碼,以便在Hadoop下執行它。也可以用Perl和Ruby編寫相同的程式碼。
Mapper階段程式碼
!/usr/bin/python
import sys
# Input takes from standard input for myline in sys.stdin:
# Remove whitespace either side
myline = myline.strip()
# Break the line into words
words = myline.split()
# Iterate the words list
for myword in words:
# Write the results to standard output
print '%s\t%s' % (myword, 1)
確保此檔案具有執行許可權(chmod +x /home/expert/hadoop-1.2.1/mapper.py)。
Reducer階段程式碼
#!/usr/bin/python
from operator import itemgetter
import sys
current_word = ""
current_count = 0
word = ""
# Input takes from standard input for myline in sys.stdin:
# Remove whitespace either side
myline = myline.strip()
# Split the input we got from mapper.py word,
count = myline.split('\t', 1)
# Convert count variable to integer
try:
count = int(count)
except ValueError:
# Count was not a number, so silently ignore this line continue
if current_word == word:
current_count += count
else:
if current_word:
# Write result to standard output print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# Do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)
將mapper和reducer程式碼儲存在Hadoop主目錄下的mapper.py和reducer.py中。確保這些檔案具有執行許可權(chmod +x mapper.py和chmod +x reducer.py)。由於python對縮排敏感,因此可以從以下連結下載相同的程式碼。
WordCount程式的執行
$ $HADOOP_HOME/bin/hadoop jar contrib/streaming/hadoop-streaming-1. 2.1.jar \ -input input_dirs \ -output output_dir \ -mapper <path/mapper.py \ -reducer <path/reducer.py
其中“\”用於換行,以便清晰易讀。
例如:
./bin/hadoop jar contrib/streaming/hadoop-streaming-1.2.1.jar -input myinput -output myoutput -mapper /home/expert/hadoop-1.2.1/mapper.py -reducer /home/expert/hadoop-1.2.1/reducer.py
Streaming的工作原理
在上面的示例中,mapper和reducer都是python指令碼,它們從標準輸入讀取輸入,並將輸出傳送到標準輸出。該實用程式將建立一個Map/Reduce作業,將作業提交到合適的叢集,並監視作業的進度,直到它完成。
當為mapper指定指令碼時,在初始化mapper時,每個mapper任務都會將指令碼作為單獨的程序啟動。當mapper任務執行時,它會將其輸入轉換為行,並將行饋送到程序的標準輸入(STDIN)。同時,mapper會從程序的標準輸出(STDOUT)收集面向行的輸出,並將每一行轉換為鍵/值對,這些鍵/值對作為mapper的輸出收集。預設情況下,一行中第一個製表符之前的部分是鍵,其餘部分(不包括製表符)是值。如果行中沒有製表符,則整行都被視為鍵,而值為空。但是,可以根據需要自定義此設定。
當為reducer指定指令碼時,在初始化reducer時,每個reducer任務都會將指令碼作為單獨的程序啟動。當reducer任務執行時,它會將其輸入鍵/值對轉換為行,並將行饋送到程序的標準輸入(STDIN)。同時,reducer會從程序的標準輸出(STDOUT)收集面向行的輸出,並將每一行轉換為鍵/值對,這些鍵/值對作為reducer的輸出收集。預設情況下,一行中第一個製表符之前的部分是鍵,其餘部分(不包括製表符)是值。但是,可以根據特定需求自定義此設定。
重要命令
| 引數 | 選項 | 描述 |
|---|---|---|
| -input directory/file-name | 必需 | mapper的輸入位置。 |
| -output directory-name | 必需 | reducer的輸出位置。 |
| -mapper 可執行檔案或指令碼或JavaClassName | 必需 | Mapper可執行檔案。 |
| -reducer 可執行檔案或指令碼或JavaClassName | 必需 | Reducer可執行檔案。 |
| -file file-name | 可選 | 使mapper、reducer或combiner可執行檔案在計算節點上本地可用。 |
| -inputformat JavaClassName | 可選 | 您提供的類應返回Text類的鍵/值對。如果未指定,則使用TextInputFormat作為預設值。 |
| -outputformat JavaClassName | 可選 | 您提供的類應採用Text類的鍵/值對。如果未指定,則使用TextOutputformat作為預設值。 |
| -partitioner JavaClassName | 可選 | 確定將哪個鍵傳送到哪個reduce的類。 |
| -combiner streamingCommand 或 JavaClassName | 可選 | map輸出的Combiner可執行檔案。 |
| -cmdenv name=value | 可選 | 將環境變數傳遞給streaming命令。 |
| -inputreader | 可選 | 為了向後相容性:指定記錄讀取器類(而不是輸入格式類)。 |
| -verbose | 可選 | 詳細輸出。 |
| -lazyOutput | 可選 | 延遲建立輸出。例如,如果輸出格式基於FileOutputFormat,則只有在第一次呼叫output.collect(或Context.write)時才會建立輸出檔案。 |
| -numReduceTasks | 可選 | 指定reducer的數量。 |
| -mapdebug | 可選 | map任務失敗時要呼叫的指令碼。 |
| -reducedebug | 可選 | reduce任務失敗時要呼叫的指令碼。 |
Hadoop - 多節點叢集
本章介紹在分散式環境中設定Hadoop多節點叢集。
由於無法演示整個叢集,我們將使用三個系統(一個主節點和兩個從節點)來解釋Hadoop叢集環境;以下是它們的IP地址。
- Hadoop主節點:192.168.1.15 (hadoop-master)
- Hadoop從節點:192.168.1.16 (hadoop-slave-1)
- Hadoop從節點:192.168.1.17 (hadoop-slave-2)
按照以下步驟設定Hadoop多節點叢集。
安裝 Java
Java是Hadoop的主要前提條件。首先,您應該使用“java -version”驗證系統中是否存在java。java版本命令的語法如下所示。
$ java -version
如果一切正常,它將為您提供以下輸出。
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果您的系統中未安裝java,請按照給定的步驟安裝java。
步驟 1
訪問以下連結下載java(JDK <最新版本> - X64.tar.gz)www.oracle.com
然後jdk-7u71-linux-x64.tar.gz 將下載到您的系統中。
步驟 2
通常,您會在 Downloads 資料夾中找到下載的 java 檔案。驗證它並使用以下命令解壓jdk-7u71-linux-x64.gz 檔案。
$ cd Downloads/ $ ls jdk-7u71-Linux-x64.gz $ tar zxf jdk-7u71-Linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-Linux-x64.gz
步驟 3
要使所有使用者都能使用java,您必須將其移動到“/usr/local/”位置。開啟root使用者,然後輸入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
步驟 4
要設定PATH 和JAVA_HOME 變數,請將以下命令新增到~/.bashrc 檔案中。
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH=PATH:$JAVA_HOME/bin
現在,如上所述,從終端驗證**java -version**命令。按照上述過程,在所有叢集節點上安裝java。
建立使用者帳戶
在主節點和從節點上建立一個系統使用者帳戶來使用Hadoop安裝。
# useradd hadoop # passwd hadoop
對映節點
您必須在所有節點上的**/etc/**資料夾中編輯**hosts**檔案,指定每個系統的IP地址及其主機名。
# vi /etc/hosts enter the following lines in the /etc/hosts file. 192.168.1.109 hadoop-master 192.168.1.145 hadoop-slave-1 192.168.56.1 hadoop-slave-2
配置基於金鑰的登入
在每個節點上設定ssh,以便它們可以相互通訊,而無需任何密碼提示。
# su hadoop $ ssh-keygen -t rsa $ ssh-copy-id -i ~/.ssh/id_rsa.pub tutorialspoint@hadoop-master $ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp1@hadoop-slave-1 $ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp2@hadoop-slave-2 $ chmod 0600 ~/.ssh/authorized_keys $ exit
安裝Hadoop
在主伺服器中,使用以下命令下載並安裝Hadoop。
# mkdir /opt/hadoop # cd /opt/hadoop/ # wget http://apache.mesi.com.ar/hadoop/common/hadoop-1.2.1/hadoop-1.2.0.tar.gz # tar -xzf hadoop-1.2.0.tar.gz # mv hadoop-1.2.0 hadoop # chown -R hadoop /opt/hadoop # cd /opt/hadoop/hadoop/
配置Hadoop
您必須透過進行以下更改來配置Hadoop伺服器,如下所示。
core-site.xml
開啟**core-site.xml**檔案並按如下所示進行編輯。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master:9000/</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
hdfs-site.xml
開啟**hdfs-site.xml**檔案並按如下所示進行編輯。
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop/hadoop/dfs/name/data</value>
<final>true</final>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml
開啟**mapred-site.xml**檔案並按如下所示進行編輯。
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop-master:9001</value>
</property>
</configuration>
hadoop-env.sh
開啟**hadoop-env.sh**檔案並按如下所示編輯JAVA_HOME、HADOOP_CONF_DIR和HADOOP_OPTS。
**注意** − 根據您的系統配置設定JAVA_HOME。
export JAVA_HOME=/opt/jdk1.7.0_17 export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true export HADOOP_CONF_DIR=/opt/hadoop/hadoop/conf
在從伺服器上安裝Hadoop
按照以下命令在所有從伺服器上安裝 Hadoop。
# su hadoop $ cd /opt/hadoop $ scp -r hadoop hadoop-slave-1:/opt/hadoop $ scp -r hadoop hadoop-slave-2:/opt/hadoop
在主伺服器上配置 Hadoop
開啟主伺服器並按照以下命令進行配置。
# su hadoop $ cd /opt/hadoop/hadoop
配置主節點
$ vi etc/hadoop/masters hadoop-master
配置從節點
$ vi etc/hadoop/slaves hadoop-slave-1 hadoop-slave-2
格式化 Hadoop 主伺服器上的 Name Node
# su hadoop $ cd /opt/hadoop/hadoop $ bin/hadoop namenode –format 11/10/14 10:58:07 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = hadoop-master/192.168.1.109 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 1.2.0 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1479473; compiled by 'hortonfo' on Mon May 6 06:59:37 UTC 2013 STARTUP_MSG: java = 1.7.0_71 ************************************************************/ 11/10/14 10:58:08 INFO util.GSet: Computing capacity for map BlocksMap editlog=/opt/hadoop/hadoop/dfs/name/current/edits …………………………………………………. …………………………………………………. …………………………………………………. 11/10/14 10:58:08 INFO common.Storage: Storage directory /opt/hadoop/hadoop/dfs/name has been successfully formatted. 11/10/14 10:58:08 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop-master/192.168.1.15 ************************************************************/
啟動 Hadoop 服務
以下命令用於在 Hadoop-Master 上啟動所有 Hadoop 服務。
$ cd $HADOOP_HOME/sbin $ start-all.sh
在 Hadoop 叢集中新增新的 DataNode
以下是將新節點新增到 Hadoop 叢集的步驟。
網路
使用一些適當的網路配置將新節點新增到現有的 Hadoop 叢集。假設以下網路配置。
對於新節點配置 -
IP address : 192.168.1.103 netmask : 255.255.255.0 hostname : slave3.in
新增使用者和 SSH 訪問
新增使用者
在新節點上,新增“hadoop”使用者,並使用以下命令將 Hadoop 使用者的密碼設定為“hadoop123”或任何您想要的密碼。
useradd hadoop passwd hadoop
設定從主伺服器到新從伺服器的無密碼連線。
在主伺服器上執行以下操作
mkdir -p $HOME/.ssh chmod 700 $HOME/.ssh ssh-keygen -t rsa -P '' -f $HOME/.ssh/id_rsa cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys chmod 644 $HOME/.ssh/authorized_keys Copy the public key to new slave node in hadoop user $HOME directory scp $HOME/.ssh/id_rsa.pub hadoop@192.168.1.103:/home/hadoop/
在從伺服器上執行以下操作
登入到 hadoop。如果沒有,請登入到 hadoop 使用者。
su hadoop ssh -X hadoop@192.168.1.103
將公鑰的內容複製到檔案"$HOME/.ssh/authorized_keys"中,然後透過執行以下命令更改其許可權。
cd $HOME mkdir -p $HOME/.ssh chmod 700 $HOME/.ssh cat id_rsa.pub >>$HOME/.ssh/authorized_keys chmod 644 $HOME/.ssh/authorized_keys
檢查來自主機的 ssh 登入。現在檢查是否可以從主伺服器無密碼 ssh 到新節點。
ssh hadoop@192.168.1.103 or hadoop@slave3
設定新節點的主機名
您可以在檔案/etc/sysconfig/network中設定主機名
On new slave3 machine NETWORKING = yes HOSTNAME = slave3.in
要使更改生效,請重新啟動機器或使用相應的主機名執行主機名命令到新機器(重新啟動是一個不錯的選擇)。
在 slave3 節點機器上 -
hostname slave3.in
使用以下行更新叢集所有機器上的/etc/hosts -
192.168.1.102 slave3.in slave3
現在嘗試使用主機名 ping 機器,以檢查它是否解析為 IP。
在新節點機器上 -
ping master.in
啟動新節點上的 DataNode
使用$HADOOP_HOME/bin/hadoop-daemon.sh 指令碼手動啟動 datanode 守護程序。它將自動聯絡主伺服器 (NameNode) 並加入叢集。我們還應該將新節點新增到主伺服器中的 conf/slaves 檔案中。基於指令碼的命令將識別新節點。
登入到新節點
su hadoop or ssh -X hadoop@192.168.1.103
使用以下命令在新新增的從節點上啟動 HDFS
./bin/hadoop-daemon.sh start datanode
檢查新節點上 jps 命令的輸出。它如下所示。
$ jps 7141 DataNode 10312 Jps
從 Hadoop 叢集中刪除 DataNode
我們可以在叢集執行時隨時刪除節點,而不會丟失任何資料。HDFS 提供了一個退役功能,確保安全地執行節點刪除。要使用它,請按照以下步驟操作 -
步驟 1 - 登入到主伺服器
登入到安裝了 Hadoop 的主伺服器使用者。
$ su hadoop
步驟 2 - 更改叢集配置
必須在啟動叢集之前配置排除檔案。在我們的$HADOOP_HOME/etc/hadoop/hdfs-site.xml檔案中新增一個名為 dfs.hosts.exclude 的鍵。與此鍵關聯的值提供了 NameNode 本地檔案系統上檔案的完整路徑,該檔案包含不允許連線到 HDFS 的機器列表。
例如,將這些行新增到etc/hadoop/hdfs-site.xml檔案中。
<property> <name>dfs.hosts.exclude</name> <value>/home/hadoop/hadoop-1.2.1/hdfs_exclude.txt</value> <description>DFS exclude</description> </property>
步驟 3 - 確定要退役的主機
每個要退役的機器都應新增到 hdfs_exclude.txt 檔案中,每行一個域名。這將阻止它們連線到 NameNode。如果您想刪除 DataNode2,則顯示"/home/hadoop/hadoop-1.2.1/hdfs_exclude.txt"檔案的內容如下所示。
slave2.in
步驟 4 - 強制重新載入配置
執行命令"$HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes"(無需引號)。
$ $HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes
這將強制 NameNode 重新讀取其配置,包括新更新的“排除”檔案。它將在一段時間內退役這些節點,從而為將每個節點的塊複製到計劃保持活動的機器上留出時間。
在slave2.in上,檢查 jps 命令的輸出。一段時間後,您將看到 DataNode 程序自動關閉。
步驟 5 - 關閉節點
退役過程完成後,可以安全地關閉退役的硬體以進行維護。執行 dfsadmin 的 report 命令以檢查退役的狀態。以下命令將描述退役節點和連線到叢集的節點的狀態。
$ $HADOOP_HOME/bin/hadoop dfsadmin -report
步驟 6 - 再次編輯排除檔案
退役機器後,可以將其從“排除”檔案中刪除。再次執行"$HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes"將把排除檔案重新讀入 NameNode;允許 DataNode 在維護完成後或叢集再次需要額外容量時重新加入叢集等。
特別說明 - 如果按照上述步驟操作,並且節點上仍然執行 tasktracker 程序,則需要將其關閉。一種方法是像我們在上述步驟中所做的那樣斷開機器的連線。主伺服器將自動識別該程序並將其宣告為已死。無需遵循相同的過程來刪除 tasktracker,因為它與 DataNode 相比並不那麼重要。DataNode 包含您想要安全刪除的資料,而不會丟失任何資料。
tasktracker 可以隨時透過以下命令執行/關閉。
$ $HADOOP_HOME/bin/hadoop-daemon.sh stop tasktracker $HADOOP_HOME/bin/hadoop-daemon.sh start tasktracker