- Hadoop 教程
- Hadoop - 主頁
- Hadoop - 大資料概述
- Hadoop - 大資料解決方案
- Hadoop - 介紹
- Hadoop - 環境設定
- Hadoop - HDFS 概述
- Hadoop - HDFS 操作
- Hadoop - 命令參考
- Hadoop - MapReduce
- Hadoop - 流處理
- Hadoop - 多節點群集
- Hadoop 有用資源
- Hadoop - 問題與解答
- Hadoop - 快速指南
- Hadoop - 有用資源
Hadoop - 大資料解決方案
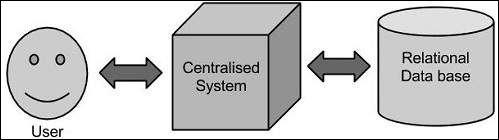
傳統方法
在這種方法中,企業將擁有一臺計算機來儲存和處理大資料。對於儲存目的,程式設計師將尋求 Oracle、IBM 等他們選擇的資料庫供應商的幫助。在此方法中,使用者與應用程式互動,而應用程式又負責處理資料儲存和分析這一部分。
侷限性
此方法適用於那些處理可由標準資料庫伺服器容納的體積較小資料或可承受正在處理資料的處理器的限制的應用程式。但當涉及處理大量可擴充套件資料時,透過單一資料庫瓶頸處理此類資料是一項繁重的任務。
Google 的解決方案
Google 使用稱為 MapReduce 的演算法解決了此問題。此演算法將任務劃分為小部分並將其分配給多臺計算機,然後從這些計算機收集結果,這些結果整合在一起形成結果資料集。

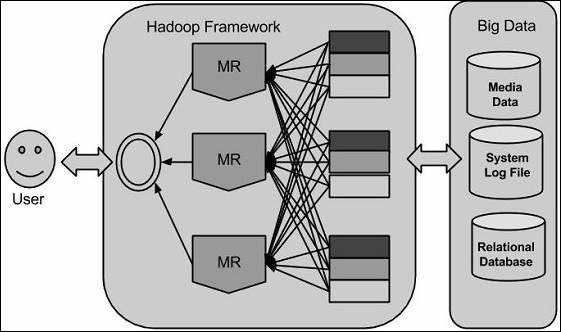
Hadoop
使用 Google 提供的解決方案,Doug Cutting 及其團隊開發了一個名為 HADOOP 的開源專案。
Hadoop 使用 MapReduce 演算法執行應用程式,其中資料與其他資料並行處理。簡而言之,Hadoop 用於開發可對大量資料執行完整統計分析的應用程式。
廣告