
 資料結構
資料結構 網路
網路 關係型資料庫管理系統 (RDBMS)
關係型資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用Python進行高斯擬合
資料分析和視覺化在當今時代至關重要,資料就是新的石油。資料分析通常涉及將資料輸入數學模型並提取有用的資訊。高斯擬合是一個強大的數學模型,資料科學家使用它根據鐘形曲線對資料進行建模。在本文中,我們將瞭解高斯擬合以及如何使用Python對其進行編碼。
什麼是高斯擬合
鐘形曲線是高斯分佈的特徵。鐘形曲線圍繞均值(μ)對稱。我們定義機率密度函式如下:
f(x) = (1 / (σ * sqrt(2π))) * exp(-(x - μ)² / (2 * σ²))
這裡σ表示分佈的標準差,μ是均值,π(圓周率)是一個常數,其值約為3.14。
我們必須估計μ和σ的值才能將任何資料擬合到高斯分佈中。手動執行此任務或建立邏輯程式碼將非常繁瑣且不方便。因此,Python為我們提供了一些內建庫和函式來處理它。
鐘形曲線
鐘形曲線是透過高斯分佈獲得的圖。在進一步討論之前,讀者需要了解鐘形曲線的典型形狀。這將在讀者將來處理高斯分佈時提供更好的直覺。
示例程式碼
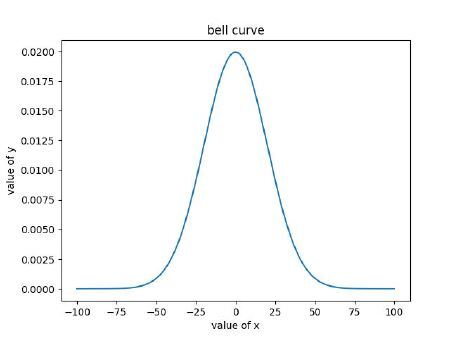
在下面的程式碼中,我們使用Numpy的arrange函式生成了均勻的資料點。我們使用norm.pdf函式計算高斯分佈的機率分佈函式。我們將均值設定為25,標準差也設定為25。我們使用matplotlib庫繪製了機率分佈函式。從圖表中可以看出一個重要的觀察結果是,圍繞0的值比-100和100等極值更常見。
import numpy as np
import scipy as sp
from scipy import stats
import matplotlib.pyplot as plt
x_data = np.arange(-100, 100, 0.01)
y_data = stats.norm.pdf(x_data, 25, 20)
plt.plot(x_data, y_data)
plt.title("bell curve")
plt.xlabel("value of x")
plt.ylabel("value of y")
plt.show()
輸出
如何使用curve_fit方法
正如我們前面部分所討論的,高斯分佈擬合的主要思想是找到μ和σ的最優值。因此,我們可以執行以下演算法來實現相同的結果。
首先,定義高斯函式。這可以由我們自己編寫如下:
def gaussian(x, μ, σ): return (1 / (σ * np.sqrt(2 * np.pi))) * np.exp(-((x - μ) ** 2) / (2 * σ ** 2))
在SciPy包的幫助下,使用curve_fit方法執行高斯擬合。該方法返回μ和σ的最優引數。
接下來,透過生成y值並使用任何標準資料視覺化庫(如Matplotlib)生成圖。
示例
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
def gaussian(x, μ, σ):
return (1 / (σ * np.sqrt(2 * np.pi))) * np.exp(-((x - μ) ** 2) / (2 * σ** 2))
x_data = np.linspace(-5, 5, 100)
y_data = gaussian(x_data, 0, 1) + np.random.normal(0, 0.2, 100)
popt, pcov = curve_fit(gaussian, x_data, y_data)
μ_fit, σ_fit = popt
y_fit = gaussian(x_data, μ_fit, σ_fit)
plt.scatter(x_data, y_data, label='Data')
plt.plot(x_data, y_fit, 'r', label='Fit')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.show()
輸出
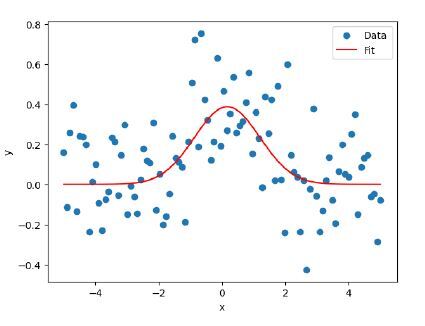
注意 - 生成的輸出每次都會有所不同,因為我們生成的是隨機數。
結論
在本文中,我們瞭解瞭如何在Python中執行高斯擬合。這是一種處理鐘形分佈曲線的寶貴技術。幸運的是,Python為我們提供了標準庫,我們可以使用這些庫將資料擬合到高斯分佈模型。我們建議讀者嘗試在更多資料集上使用該分佈,以便對該主題有更多信心。

5K+ 瀏覽量
