
 資料結構
資料結構 網路
網路 關係型資料庫管理系統 (RDBMS)
關係型資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP機器學習分類中使用的交叉熵代價函式
在機器學習中,迴歸任務的目的是確定一個能夠可靠地預測資料模式的函式值。另一方面,分類任務則需要確定一個能夠正確識別不同資料類別的函式值。模型的準確性取決於模型在給定輸入值的情況下預測輸出值的有效性。代價函式就是這樣一種度量標準,它用於迭代地校準模型的準確性,我們將在下面探討這一點。
什麼是代價函式?
在訓練階段,模型嘗試在訓練資料上生成預測,同時隨機選擇初始權重。但是模型如何學習其預測“偏差”有多大呢?它毫無疑問需要此知識,以便在後續訓練資料迭代中使用梯度下降並相應地調整權重。
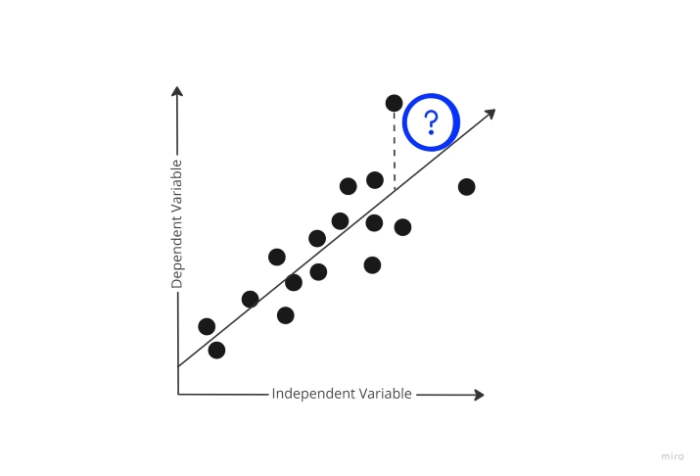
此時,代價函式登場。為了確定模型預測的錯誤程度,代價函式會比較模型的預測輸出和實際輸出。
利用代價函式提供的這些可量化的資料,模型現在正嘗試更改其引數的權重,以便在後續的訓練資料迭代中進一步最小化代價函式報告的誤差。訓練階段的目標是迭代地建立最小化此誤差的權重,直到無法再最小化為止。這本質上是一個最佳化問題。
分類中使用的代價函式
交叉熵損失度量用於衡量機器學習分類模型的效能。損失用 0 到 1 之間的數字表示,其中 0 表示完美模型(或無錯誤)。主要目標是使模型儘可能接近 0。交叉熵損失有時會與邏輯損失(或對數損失,有時稱為二元交叉熵損失)混淆,但這並非總是如此。
交叉熵損失衡量機器學習分類模型的發現機率分佈與預期機率分佈之間的差距。它會儲存所有可能的預測,因此,如果你正在尋找拋硬幣的機率,它會將其儲存為 0.5 和 0.5。(正面和反面)。相反,二元交叉熵損失僅儲存一個值。也就是說,它只會儲存 0.5,而在另一種情況下則假設另一個為 0.5(例如,如果第一個機率為 0.7,它會假設第二個為 0.3)。它還使用對數(因此稱為“對數損失”)。
雖然很明顯,當有三個或更多結果時它會失敗,但當只有兩個結果時,二元交叉熵損失(也稱為對數損失)用於此目的。交叉熵損失廣泛用於包含三個或更多分類選項的模型。當僅考慮單個訓練樣本中的誤差時,代價函式可以類似地稱為“損失函式”。
梯度下降
梯度下降是一種用於最小化模型或代價函式中誤差的方法。它用於找到模型中哪怕是最微小的錯誤。你可以將梯度下降視為必須遵循的路徑,以使錯誤最小化。你的模型的準確性在不同位置可能會有所不同,因此你必須確定最快的減少錯誤的方法,以避免浪費資源。
梯度下降是一種技術,用於找出給定不同輸入變數值時模型的錯誤程度。你可以觀察到,隨著這種操作的重複進行,隨著時間的推移,錯誤會越來越少。代價函式將被最佳化,並且你將很快達到具有最小誤差的變數值。
分類中使用的代價函式型別
1. 二元交叉熵代價函式
當只有一個輸出並且它只取 0 或 1 的二元值分別表示負類和正類時,二元交叉熵是分類交叉熵的一個特例。例如,對狗和貓進行分類。
假設 y 表示實際輸出,則給定資料集 D 的交叉熵可以簡化為:
交叉熵(D) = – y*log(p) 當 y = 1 時
交叉熵(D) = – (1-y)*log(1-p) 當 y = 0 時
所有 N 個訓練資料的交叉熵的平均值,也稱為二元交叉熵,決定了整個模型在二元分類中的誤差。
二元交叉熵 = (N 個數據的交叉熵之和)/N
2. 多類別分類交叉熵代價函式
當有多個類別並且輸入資料只屬於一個類別時,此代價函式用於解決分類問題。讓我們現在檢查一下交叉熵的計算。假設模型為“n”個類別和特定輸入資料集 D 輸出以下所示的機率分佈。
然後,特定資料 D 的交叉熵計算如下:
交叉熵損失(y,p) = – yT log(p)
= -(y1 log(p1) + y2 log(p2) + ……yn log(pn) )
結論
最後一點,我可以說代價函式作為各種演算法和模型的監控工具,因為它突出了預期結果和實際結果之間的差異,並有助於改進模型。

453 次瀏覽
