- Cassandra 教程
- Cassandra - 首頁
- Cassandra - 簡介
- Cassandra - 架構
- Cassandra - 資料模型
- Cassandra - 安裝
- Cassandra - 參考 API
- Cassandra - Cqlsh
- Cassandra - Shell 命令
- Cassandra Keyspace 操作
- Cassandra - 建立 Keyspace
- Cassandra - 修改 Keyspace
- Cassandra - 刪除 Keyspace
- Cassandra 表操作
- Cassandra - 建立表
- Cassandra - 修改表
- Cassandra - 刪除表
- Cassandra - 清空表
- Cassandra - 建立索引
- Cassandra - 刪除索引
- Cassandra - 批處理
- Cassandra CURD 操作
- Cassandra - 建立資料
- Cassandra - 更新資料
- Cassandra - 讀取資料
- Cassandra - 刪除資料
- Cassandra CQL 型別
- Cassandra - CQL 資料型別
- Cassandra - CQL 集合
- CQL 使用者自定義資料型別
- Cassandra 有用資源
- Cassandra - 快速指南
- Cassandra - 有用資源
- Cassandra - 討論
Cassandra - 快速指南
Cassandra - 簡介
Apache Cassandra 是一個高度可擴充套件、高效能的分散式資料庫,旨在跨多個商品伺服器處理大量資料,提供高可用性且沒有單點故障。它是一種 NoSQL 資料庫。讓我們首先了解一下 NoSQL 資料庫的作用。
NoSQL 資料庫
NoSQL 資料庫(有時稱為 Not Only SQL)是一種資料庫,它提供了一種儲存和檢索資料的機制,而不是關係資料庫中使用的表格關係。這些資料庫是無模式的,支援輕鬆複製,具有簡單的 API,最終一致,並且可以處理海量資料。
NoSQL 資料庫的主要目標是擁有
- 簡單的設計,
- 水平擴充套件,以及
- 對可用性的更精細控制。
與關係資料庫相比,NoSql 資料庫使用不同的資料結構。這使得某些操作在 NoSQL 中更快。給定 NoSQL 資料庫的適用性取決於它必須解決的問題。
NoSQL 與關係資料庫
下表列出了區分關係資料庫和 NoSQL 資料庫的要點。
| 關係資料庫 | NoSql 資料庫 |
|---|---|
| 支援強大的查詢語言。 | 支援非常簡單的查詢語言。 |
| 它具有固定模式。 | 沒有固定模式。 |
| 遵循 ACID(原子性、一致性、隔離性和永續性)。 | 它只是“最終一致”。 |
| 支援事務。 | 不支援事務。 |
除了 Cassandra 之外,我們還有以下一些非常流行的 NoSQL 資料庫:
Apache HBase - HBase 是一個開源的、非關係型的、分散式的資料庫,其模型參考了 Google 的 BigTable,並且是用 Java 編寫的。它是作為 Apache Hadoop 專案的一部分開發的,並執行在 HDFS 之上,為 Hadoop 提供類似 BigTable 的功能。
MongoDB - MongoDB 是一個跨平臺的面向文件的資料庫系統,它避免使用傳統的基於表的資料庫結構,轉而使用類似 JSON 的文件和動態模式,從而使某些型別應用程式中的資料整合變得更容易、更快。
什麼是 Apache Cassandra?
Apache Cassandra 是一個開源的、分散式和去中心化/分散式儲存系統(資料庫),用於管理分佈在世界各地的海量結構化資料。它提供高可用性服務,沒有單點故障。
以下是 Apache Cassandra 的一些值得注意的要點:
它是可擴充套件的、容錯的和一致的。
它是一個面向列的資料庫。
其分散式設計基於 Amazon 的 Dynamo,其資料模型基於 Google 的 Bigtable。
在 Facebook 建立,它與關係資料庫管理系統截然不同。
Cassandra 實現了一個 Dynamo 風格的複製模型,沒有單點故障,但添加了一個更強大的“列族”資料模型。
Cassandra 正在被一些最大的公司使用,例如 Facebook、Twitter、Cisco、Rackspace、ebay、Twitter、Netflix 等。
Cassandra 的特性
Cassandra 因其出色的技術特性而變得如此受歡迎。以下是 Cassandra 的一些特性
彈性可擴充套件性 - Cassandra 是高度可擴充套件的;它允許根據需要新增更多硬體以容納更多客戶和更多資料。
始終線上架構 - Cassandra 沒有單點故障,並且始終可用於無法承受故障的關鍵業務應用程式。
快速線性擴充套件效能 - Cassandra 是線性可擴充套件的,即隨著叢集中節點數量的增加,吞吐量也會增加。因此,它保持了快速的響應時間。
靈活的資料儲存 - Cassandra 可以容納所有可能的資料格式,包括:結構化、半結構化和非結構化。它可以根據您的需要動態適應資料結構的變化。
輕鬆的資料分發 - Cassandra 提供靈活性,可以將資料複製到多個數據中心,從而將資料分發到您需要的位置。
事務支援 - Cassandra 支援原子性、一致性、隔離性和永續性(ACID)等屬性。
快速寫入 - Cassandra 旨在執行在廉價的商品硬體上。它執行極快的寫入,並且可以儲存數百 TB 的資料,而不會犧牲讀取效率。
Cassandra 的歷史
- Cassandra 是在 Facebook 為收件箱搜尋而開發的。
- 它於 2008 年 7 月由 Facebook 開源。
- Cassandra 於 2009 年 3 月被接受進入 Apache Incubator。
- 自 2010 年 2 月起,它成為 Apache 的頂級專案。
Cassandra - 架構
Cassandra 的設計目標是在多個節點上處理大資料工作負載,而沒有任何單點故障。Cassandra 在其節點之間具有對等分散式系統,並且資料分佈在叢集中的所有節點之間。
叢集中的所有節點都扮演相同的角色。每個節點都是獨立的,同時又與其他節點互連。
叢集中的每個節點都可以接受讀寫請求,而不管資料實際位於叢集中的哪個位置。
當某個節點出現故障時,可以從網路中的其他節點提供讀/寫請求服務。
Cassandra 中的資料複製
在 Cassandra 中,叢集中的一個或多個節點充當給定資料片段的副本。如果檢測到某些節點響應了過時的值,Cassandra 將向客戶端返回最新值。返回最新值後,Cassandra 會在後臺執行讀取修復以更新過時的值。
下圖顯示了 Cassandra 如何在叢集中的節點之間使用資料複製以確保沒有單點故障的示意圖。
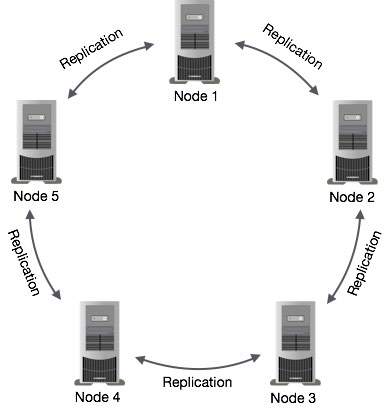
注意 - Cassandra 在後臺使用Gossip 協議,允許節點相互通訊並檢測叢集中的任何故障節點。
Cassandra 的元件
Cassandra 的關鍵元件如下:
節點 - 它是儲存資料的位置。
資料中心 - 它是相關節點的集合。
叢集 - 叢集是一個包含一個或多個數據中心的元件。
提交日誌 - 提交日誌是 Cassandra 中的崩潰恢復機制。每個寫入操作都會寫入提交日誌。
Mem-table - Mem-table 是一個駐留在記憶體中的資料結構。在提交日誌之後,資料將寫入 Mem-table。有時,對於單個列族,將存在多個 Mem-table。
SSTable - 它是將資料從 Mem-table 刷出到磁碟的檔案,當其內容達到閾值時。
布隆過濾器 - 這些只不過是快速、非確定性的演算法,用於測試元素是否為集合的成員。它是一種特殊的快取。在每次查詢後都會訪問布隆過濾器。
Cassandra 查詢語言
使用者可以透過其節點使用 Cassandra 查詢語言 (CQL) 訪問 Cassandra。CQL 將資料庫(Keyspace)視為表的容器。程式設計師使用cqlsh: 提示符來使用 CQL 或單獨的應用程式語言驅動程式。
客戶端為其讀寫操作聯絡任何節點。該節點(協調器)充當客戶端和儲存資料的節點之間的代理。
寫入操作
節點的每個寫入活動都由寫入節點的提交日誌捕獲。稍後將捕獲資料並存儲在Mem-table中。每當 Mem-table 滿了時,資料將寫入SStable資料檔案。所有寫入都會自動分割槽並在整個叢集中複製。Cassandra 定期合併 SSTable,丟棄不必要的資料。
讀取操作
在讀取操作期間,Cassandra 從 Mem-table 獲取值並檢查布隆過濾器以找到儲存所需資料的適當 SSTable。
Cassandra - 資料模型
Cassandra 的資料模型與我們在 RDBMS 中通常看到的模型有很大不同。本章概述了 Cassandra 如何儲存其資料。
叢集
Cassandra 資料庫分佈在多臺協同工作的機器上。最外層的容器稱為叢集。為了處理故障,每個節點都包含一個副本,並且在發生故障時,副本將接管。Cassandra 以環形格式在叢集中排列節點,並將資料分配給它們。
Keyspace
Keyspace 是 Cassandra 中資料的最外層容器。Cassandra 中 Keyspace 的基本屬性有:
複製因子 - 它是叢集中將接收相同資料副本的機器數量。
副本放置策略 - 這只不過是在環中放置副本的策略。我們有諸如簡單策略(機架感知策略)、舊網路拓撲策略(機架感知策略)和網路拓撲策略(資料中心共享策略)等策略。
列族 - Keyspace 是一個或多個列族的容器。反過來,列族是行集合的容器。每一行都包含有序的列。列族表示資料的結構。每個 Keyspace 至少有一個,通常有多個列族。
建立 Keyspace 的語法如下:
CREATE KEYSPACE Keyspace name
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};
下圖顯示了 Keyspace 的示意圖。

列族
列族是有序行集合的容器。反過來,每一行都是有序列的集合。下表列出了區分列族和關係資料庫表的要點。
| 關係表 | Cassandra 列族 |
|---|---|
| 關係模型中的模式是固定的。一旦我們為表定義了某些列,在插入資料時,在每一行中,所有列都必須至少填充一個空值。 | 在 Cassandra 中,儘管定義了列族,但列卻沒有定義。您可以隨時自由地向任何列族新增任何列。 |
| 關係表僅定義列,使用者使用值填充表。 | 在 Cassandra 中,表包含列,或者可以定義為超級列族。 |
Cassandra 列族具有以下屬性:
keys_cached - 它表示每個 SSTable 要保留快取的位置數。
rows_cached - 它表示其整個內容將快取在記憶體中的行的數量。
preload_row_cache - 它指定您是否要預填充行快取。
注意 - 與關係表(其中列族的模式不固定)不同,Cassandra 不會強制各個行具有所有列。
下圖顯示了 Cassandra 列族的示例。
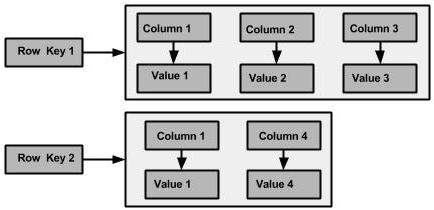
列
列是 Cassandra 的基本資料結構,具有三個值,即鍵或列名、值和時間戳。以下是列的結構。

超級列
超級列是一種特殊的列,因此它也是鍵值對。但是超級列儲存了一個子列的對映。
通常,列族儲存在磁碟上的單個檔案中。因此,為了最佳化效能,將您可能一起查詢的列儲存在同一個列族中非常重要,而超級列在這裡可以提供幫助。以下是超級列的結構。

Cassandra 和 RDBMS 的資料模型
下表列出了將 Cassandra 的資料模型與 RDBMS 的資料模型區分開來的要點。
| RDBMS | Cassandra |
|---|---|
| RDBMS 處理結構化資料。 | Cassandra 處理非結構化資料。 |
| 它具有固定模式。 | Cassandra 具有靈活的模式。 |
| 在 RDBMS 中,表是陣列的陣列。(行 x 列) | 在 Cassandra 中,表是“巢狀鍵值對”的列表。(行 x 列鍵 x 列值) |
| 資料庫是最外層的容器,包含與應用程式對應的資料。 | Keyspace 是最外層的容器,包含與應用程式對應的資料。 |
| 表是資料庫的實體。 | 表或列族是 keyspace 的實體。 |
| 行是 RDBMS 中的單個記錄。 | 行是 Cassandra 中的複製單元。 |
| 列表示關係的屬性。 | 列是 Cassandra 中的儲存單元。 |
| RDBMS 支援外部索引鍵、連線的概念。 | 關係使用集合表示。 |
Cassandra - 安裝
Cassandra 可以使用 cqlsh 以及不同語言的驅動程式進行訪問。本章介紹如何設定 cqlsh 和 java 環境以使用 Cassandra。
安裝前設定
在 Linux 環境中安裝 Cassandra 之前,我們需要使用 **ssh**(安全外殼)設定 Linux。請按照以下步驟設定 Linux 環境。
建立使用者
首先,建議為 Hadoop 建立一個單獨的使用者,以將 Hadoop 檔案系統與 Unix 檔案系統隔離。請按照以下步驟建立使用者。
使用命令 **“su”** 開啟 root。
使用命令 **“useradd username”** 從 root 帳戶建立使用者。
現在,您可以使用命令 **“su username”** 開啟現有的使用者帳戶。
開啟 Linux 終端並鍵入以下命令以建立使用者。
$ su password: # useradd hadoop # passwd hadoop New passwd: Retype new passwd
SSH 設定和金鑰生成
SSH 設定是執行叢集上的不同操作(例如啟動、停止和分散式守護程式 shell 操作)所必需的。為了對 Hadoop 的不同使用者進行身份驗證,需要為 Hadoop 使用者提供公鑰/私鑰對,並與不同的使用者共享。
以下命令用於使用 SSH 生成金鑰值對:
- 將公鑰從 id_rsa.pub 複製到 authorized_keys,
- 並提供所有者,
- 分別向 authorized_keys 檔案提供讀寫許可權。
$ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
- 驗證 ssh
ssh localhost
安裝 Java
Java 是 Cassandra 的主要先決條件。首先,您應該使用以下命令驗證系統中是否存在 Java:
$ java -version
如果一切正常,它將為您提供以下輸出。
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果您的系統中沒有 Java,請按照以下步驟安裝 Java。
步驟 1
從以下連結下載 java(JDK <最新版本> - X64.tar.gz):連結
然後 jdk-7u71-linux-x64.tar.gz 將下載到您的系統上。
步驟 2
通常,您會在 Downloads 資料夾中找到下載的 java 檔案。驗證它並使用以下命令解壓縮 **jdk-7u71-linux-x64.gz** 檔案。
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
步驟 3
要使所有使用者都能使用 Java,您必須將其移動到“/usr/local/”位置。開啟 root,並鍵入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
步驟 4
要設定 **PATH** 和 **JAVA_HOME** 變數,請將以下命令新增到 **~/.bashrc** 檔案中。
export JAVA_HOME = /usr/local/jdk1.7.0_71 export PATH = $PATH:$JAVA_HOME/bin
現在將所有更改應用到當前執行的系統中。
$ source ~/.bashrc
步驟 5
使用以下命令配置 java 備選方案。
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2 # alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 # alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 # alternatives --set java usr/local/java/bin/java # alternatives --set javac usr/local/java/bin/javac # alternatives --set jar usr/local/java/bin/jar
現在從終端使用 **java -version** 命令,如上所述。
設定路徑
如下所示,在“/.bashrc”中設定 Cassandra 路徑。
[hadoop@linux ~]$ gedit ~/.bashrc export CASSANDRA_HOME = ~/cassandra export PATH = $PATH:$CASSANDRA_HOME/bin
下載 Cassandra
Apache Cassandra 可在 下載連結 中獲得。使用以下命令下載 Cassandra。
$ wget http://supergsego.com/apache/cassandra/2.1.2/apache-cassandra-2.1.2-bin.tar.gz
使用命令 **zxvf** 解壓縮 Cassandra,如下所示。
$ tar zxvf apache-cassandra-2.1.2-bin.tar.gz.
建立一個名為 cassandra 的新目錄,並將下載的檔案內容移動到其中,如下所示。
$ mkdir Cassandra $ mv apache-cassandra-2.1.2/* cassandra.
配置 Cassandra
開啟 **cassandra.yaml:** 檔案,該檔案將在 Cassandra 的 **bin** 目錄中可用。
$ gedit cassandra.yaml
**注意** - 如果您從 deb 或 rpm 包安裝了 Cassandra,則配置檔案將位於 Cassandra 的 **/etc/cassandra** 目錄中。
上述命令開啟 **cassandra.yaml** 檔案。驗證以下配置。預設情況下,這些值將設定為指定的目錄。
data_file_directories **“/var/lib/cassandra/data”**
commitlog_directory **“/var/lib/cassandra/commitlog”**
saved_caches_directory **“/var/lib/cassandra/saved_caches”**
確保這些目錄存在並且可以寫入,如下所示。
建立目錄
作為超級使用者,建立兩個目錄 **/var/lib/cassandra** 和 **/var./log/cassandra**,Cassandra 將其資料寫入其中。
[root@linux cassandra]# mkdir /var/lib/cassandra [root@linux cassandra]# mkdir /var/log/cassandra
向資料夾授予許可權
如下所示,向新建立的資料夾授予讀寫許可權。
[root@linux /]# chmod 777 /var/lib/cassandra [root@linux /]# chmod 777 /var/log/cassandra
啟動 Cassandra
要啟動 Cassandra,請開啟終端視窗,導航到 Cassandra 主目錄/home(您在其中解壓縮 Cassandra 的位置),並執行以下命令以啟動您的 Cassandra 伺服器。
$ cd $CASSANDRA_HOME $./bin/cassandra -f
使用 –f 選項告訴 Cassandra 保持在前臺而不是作為後臺程序執行。如果一切順利,您可以看到 Cassandra 伺服器正在啟動。
程式設計環境
要以程式設計方式設定 Cassandra,請下載以下 jar 檔案:
- slf4j-api-1.7.5.jar
- cassandra-driver-core-2.0.2.jar
- guava-16.0.1.jar
- metrics-core-3.0.2.jar
- netty-3.9.0.Final.jar
將它們放在一個單獨的資料夾中。例如,我們將這些 jar 下載到名為 **“Cassandra_jars”** 的資料夾中。
如下所示,在 **“.bashrc”** 檔案中為該資料夾設定類路徑。
[hadoop@linux ~]$ gedit ~/.bashrc //Set the following class path in the .bashrc file. export CLASSPATH = $CLASSPATH:/home/hadoop/Cassandra_jars/*
Eclipse 環境
開啟 Eclipse 並建立一個名為 Cassandra _Examples 的新專案。
右鍵單擊該專案,選擇 **Build Path→Configure Build Path**,如下所示。

它將開啟屬性視窗。在“庫”選項卡下,選擇 **新增外部 JAR**。導航到儲存 jar 檔案的目錄。選擇所有五個 jar 檔案並單擊“確定”,如下所示。

在“引用庫”下,您可以看到所有新增的必需 jar,如下所示:
Maven 依賴項
以下是使用 maven 構建 Cassandra 專案的 pom.xml。
<project xmlns = "http://maven.apache.org/POM/4.0.0"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>com.datastax.cassandra</groupId>
<artifactId>cassandra-driver-core</artifactId>
<version>2.0.2</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0.1</version>
</dependency>
<dependency>
<groupId>com.codahale.metrics</groupId>
<artifactId>metrics-core</artifactId>
<version>3.0.2</version>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty</artifactId>
<version>3.9.0.Final</version>
</dependency>
</dependencies>
</project>
Cassandra - 參考 API
本章涵蓋了 Cassandra 中所有重要的類。
叢集
此類是驅動程式的主要入口點。它屬於 **com.datastax.driver.core** 包。
方法
| 序號 | 方法和描述 |
|---|---|
| 1 | Session connect() 它在當前叢集上建立一個新會話並對其進行初始化。 |
| 2 | void close() 它用於關閉叢集例項。 |
| 3 | static Cluster.Builder builder() 它用於建立一個新的 Cluster.Builder 例項。 |
Cluster.Builder
此類用於例項化 **Cluster.Builder** 類。
方法
| 序號 | 方法和描述 |
|---|---|
| 1 | Cluster.Builder addContactPoint(String address) 此方法向叢集新增一個聯絡點。 |
| 2 | Cluster build() 此方法使用給定的聯絡點構建叢集。 |
Session
此介面儲存與 Cassandra 叢集的連線。使用此介面,您可以執行 **CQL** 查詢。它屬於 **com.datastax.driver.core** 包。
方法
| 序號 | 方法和描述 |
|---|---|
| 1 | void close() 此方法用於關閉當前會話例項。 |
| 2 | ResultSet execute(Statement statement) 此方法用於執行查詢。它需要一個語句物件。 |
| 3 | ResultSet execute(String query) 此方法用於執行查詢。它需要一個以字串物件形式存在的查詢。 |
| 4 | PreparedStatement prepare(RegularStatement statement) 此方法準備提供的查詢。查詢需要以語句的形式提供。 |
| 5 | PreparedStatement prepare(String query) 此方法準備提供的查詢。查詢需要以字串的形式提供。 |
Cassandra - Cqlsh
本章介紹 Cassandra 查詢語言 shell 並解釋如何使用其命令。
預設情況下,Cassandra 提供了一個提示 Cassandra 查詢語言 shell **(cqlsh)**,允許使用者與其通訊。使用此 shell,您可以執行 **Cassandra 查詢語言 (CQL)**。
使用 cqlsh,您可以
- 定義模式,
- 插入資料,以及
- 執行查詢。
啟動 cqlsh
使用命令 **cqlsh** 啟動 cqlsh,如下所示。它以輸出形式提供 Cassandra cqlsh 提示符。
[hadoop@linux bin]$ cqlsh Connected to Test Cluster at 127.0.0.1:9042. [cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3] Use HELP for help. cqlsh>
**Cqlsh** - 如上所述,此命令用於啟動 cqlsh 提示符。此外,它還支援一些其他選項。下表解釋了 **cqlsh** 的所有選項及其用法。
| 選項 | 用法 |
|---|---|
| cqlsh --help | 顯示有關 **cqlsh** 命令選項的幫助主題。 |
| cqlsh --version | 提供您正在使用的 cqlsh 的版本。 |
| cqlsh --color | 指示 shell 使用彩色輸出。 |
| cqlsh --debug | 顯示其他除錯資訊。 |
|
cqlsh --execute cql_statement |
指示 shell 接受並執行 CQL 命令。 |
| cqlsh --file= **“檔名”** | 如果您使用此選項,Cassandra 將執行給定檔案中的命令並退出。 |
| cqlsh --no-color | 指示 Cassandra 不要使用彩色輸出。 |
| cqlsh -u **“使用者名稱”** | 使用此選項,您可以對使用者進行身份驗證。預設使用者名稱為:cassandra。 |
| cqlsh-p **“密碼”** | 使用此選項,您可以使用密碼對使用者進行身份驗證。預設密碼為:cassandra。 |
Cqlsh 命令
Cqlsh 有一些命令允許使用者與其互動。這些命令列在下面。
已記錄的 Shell 命令
以下是 Cqlsh 已記錄的 shell 命令。這些是用於執行任務的命令,例如顯示幫助主題、退出 cqlsh、描述等。
**HELP** - 顯示所有 cqlsh 命令的幫助主題。
**CAPTURE** - 捕獲命令的輸出並將其新增到檔案中。
**CONSISTENCY** - 顯示當前一致性級別,或設定新的一致性級別。
**COPY** - 將資料複製到 Cassandra 和從 Cassandra 複製資料。
**DESCRIBE** - 描述 Cassandra 的當前叢集及其物件。
**EXPAND** - 垂直擴充套件查詢的輸出。
**EXIT** - 使用此命令,您可以終止 cqlsh。
**PAGING** - 啟用或停用查詢分頁。
**SHOW** - 顯示當前 cqlsh 會話的詳細資訊,例如 Cassandra 版本、主機或資料型別假設。
**SOURCE** - 執行包含 CQL 語句的檔案。
**TRACING** - 啟用或停用請求跟蹤。
CQL 資料定義命令
**CREATE KEYSPACE** - 在 Cassandra 中建立 KeySpace。
**USE** - 連線到已建立的 KeySpace。
ALTER KEYSPACE − 更改鍵空間的屬性。
DROP KEYSPACE − 刪除鍵空間。
CREATE TABLE − 在鍵空間中建立一個表。
ALTER TABLE − 修改表的列屬性。
DROP TABLE − 刪除表。
TRUNCATE − 刪除表中的所有資料。
CREATE INDEX − 在表的單個列上定義一個新的索引。
DROP INDEX − 刪除命名索引。
CQL 資料操作命令
INSERT − 為表中的一行新增列。
UPDATE − 更新行的一列。
DELETE − 從表中刪除資料。
BATCH − 同時執行多個 DML 語句。
CQL 子句
SELECT − 此子句從表中讀取資料。
WHERE − where 子句與 select 一起使用以讀取特定資料。
ORDERBY − orderby 子句與 select 一起使用以按特定順序讀取特定資料。
Cassandra - Shell 命令
除了 CQL 命令之外,Cassandra 還提供了已記錄的 shell 命令。下面列出了 Cassandra 已記錄的 shell 命令。
幫助
HELP 命令顯示所有 cqlsh 命令的摘要和簡要說明。以下是 help 命令的使用方法。
cqlsh> help Documented shell commands: =========================== CAPTURE COPY DESCRIBE EXPAND PAGING SOURCE CONSISTENCY DESC EXIT HELP SHOW TRACING. CQL help topics: ================ ALTER CREATE_TABLE_OPTIONS SELECT ALTER_ADD CREATE_TABLE_TYPES SELECT_COLUMNFAMILY ALTER_ALTER CREATE_USER SELECT_EXPR ALTER_DROP DELETE SELECT_LIMIT ALTER_RENAME DELETE_COLUMNS SELECT_TABLE
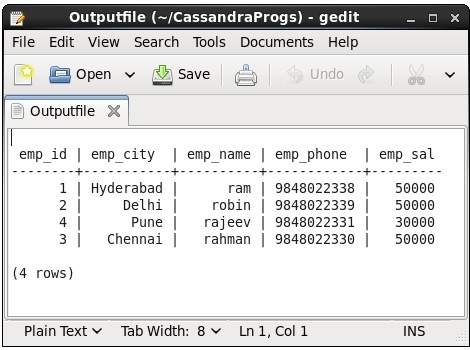
捕獲
此命令捕獲命令的輸出並將其新增到檔案中。例如,檢視以下捕獲輸出到名為Outputfile的檔案的程式碼。
cqlsh> CAPTURE '/home/hadoop/CassandraProgs/Outputfile'
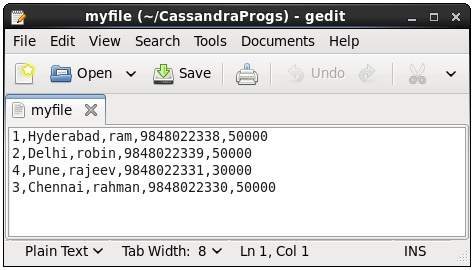
當我們在終端中鍵入任何命令時,輸出將被給定的檔案捕獲。以下是使用的命令和輸出檔案的快照。
cqlsh:tutorialspoint> select * from emp;
您可以使用以下命令關閉捕獲。
cqlsh:tutorialspoint> capture off;
一致性
此命令顯示當前一致性級別,或設定新的一致性級別。
cqlsh:tutorialspoint> CONSISTENCY Current consistency level is 1.
複製
此命令在 Cassandra 和檔案之間複製資料。以下是一個將名為emp的表複製到檔案myfile的示例。
cqlsh:tutorialspoint> COPY emp (emp_id, emp_city, emp_name, emp_phone,emp_sal) TO ‘myfile’; 4 rows exported in 0.034 seconds.
如果開啟並驗證給定的檔案,您可以在下面看到已複製的資料。
描述
此命令描述 Cassandra 的當前叢集及其物件。下面解釋了此命令的變體。
Describe cluster − 此命令提供有關叢集的資訊。
cqlsh:tutorialspoint> describe cluster;
Cluster: Test Cluster
Partitioner: Murmur3Partitioner
Range ownership:
-658380912249644557 [127.0.0.1]
-2833890865268921414 [127.0.0.1]
-6792159006375935836 [127.0.0.1]
Describe Keyspaces − 此命令列出叢集中的所有鍵空間。以下是此命令的使用方法。
cqlsh:tutorialspoint> describe keyspaces; system_traces system tp tutorialspoint
Describe tables − 此命令列出鍵空間中的所有表。以下是此命令的使用方法。
cqlsh:tutorialspoint> describe tables; emp
Describe table − 此命令提供表的描述。以下是此命令的使用方法。
cqlsh:tutorialspoint> describe table emp;
CREATE TABLE tutorialspoint.emp (
emp_id int PRIMARY KEY,
emp_city text,
emp_name text,
emp_phone varint,
emp_sal varint
) WITH bloom_filter_fp_chance = 0.01
AND caching = '{"keys":"ALL", "rows_per_partition":"NONE"}'
AND comment = ''
AND compaction = {'min_threshold': '4', 'class':
'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy',
'max_threshold': '32'}
AND compression = {'sstable_compression':
'org.apache.cassandra.io.compress.LZ4Compressor'}
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99.0PERCENTILE';
CREATE INDEX emp_emp_sal_idx ON tutorialspoint.emp (emp_sal);
描述型別
此命令用於描述使用者定義的資料型別。以下是此命令的使用方法。
cqlsh:tutorialspoint> describe type card_details; CREATE TYPE tutorialspoint.card_details ( num int, pin int, name text, cvv int, phone set<int>, mail text );
描述型別
此命令列出所有使用者定義的資料型別。以下是此命令的使用方法。假設有兩個使用者定義的資料型別:card 和 card_details。
cqlsh:tutorialspoint> DESCRIBE TYPES; card_details card
擴充套件
此命令用於擴充套件輸出。在使用此命令之前,您必須開啟擴充套件命令。以下是此命令的使用方法。
cqlsh:tutorialspoint> expand on;
cqlsh:tutorialspoint> select * from emp;
@ Row 1
-----------+------------
emp_id | 1
emp_city | Hyderabad
emp_name | ram
emp_phone | 9848022338
emp_sal | 50000
@ Row 2
-----------+------------
emp_id | 2
emp_city | Delhi
emp_name | robin
emp_phone | 9848022339
emp_sal | 50000
@ Row 3
-----------+------------
emp_id | 4
emp_city | Pune
emp_name | rajeev
emp_phone | 9848022331
emp_sal | 30000
@ Row 4
-----------+------------
emp_id | 3
emp_city | Chennai
emp_name | rahman
emp_phone | 9848022330
emp_sal | 50000
(4 rows)
注意 − 您可以使用以下命令關閉擴充套件選項。
cqlsh:tutorialspoint> expand off; Disabled Expanded output.
退出
此命令用於終止 cql shell。
顯示
此命令顯示當前 cqlsh 會話的詳細資訊,例如 Cassandra 版本、主機或資料型別假設。以下是此命令的使用方法。
cqlsh:tutorialspoint> show host; Connected to Test Cluster at 127.0.0.1:9042. cqlsh:tutorialspoint> show version; [cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]
源
使用此命令,您可以執行檔案中的命令。假設我們的輸入檔案如下所示:
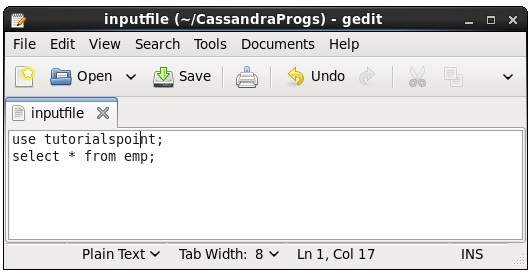
然後,您可以執行包含命令的檔案,如下所示。
cqlsh:tutorialspoint> source '/home/hadoop/CassandraProgs/inputfile';
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Pune | rajeev | 9848022331 | 30000
4 | Chennai | rahman | 9848022330 | 50000
(4 rows)
Cassandra - 建立 Keyspace
使用 Cqlsh 建立鍵空間
Cassandra 中的鍵空間是一個名稱空間,用於定義節點上的資料複製。一個叢集每個節點包含一個鍵空間。以下是使用語句CREATE KEYSPACE建立鍵空間的語法。
語法
CREATE KEYSPACE <identifier> WITH <properties>
例如
CREATE KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’};
CREATE KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’}
AND durable_writes = ‘Boolean value’;
CREATE KEYSPACE 語句有兩個屬性:replication 和 durable_writes。
複製
複製選項用於指定副本放置策略和所需的副本數量。下表列出了所有副本放置策略。
| 策略名稱 | 描述 |
|---|---|
| 簡單策略' | 為叢集指定一個簡單的複製因子。 |
| 網路拓撲策略 | 使用此選項,您可以獨立地為每個資料中心設定複製因子。 |
| 舊網路拓撲策略 | 這是一種遺留複製策略。 |
使用此選項,您可以指示 Cassandra 是否對當前鍵空間的更新使用commitlog。此選項不是必需的,預設情況下設定為 true。
示例
以下是建立鍵空間的示例。
這裡我們正在建立一個名為TutorialsPoint的鍵空間。
我們使用第一個副本放置策略,即簡單策略。
並且我們選擇複製因子為1 個副本。
cqlsh.> CREATE KEYSPACE tutorialspoint
WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};
驗證
您可以使用命令Describe驗證表是否已建立。如果您在鍵空間上使用此命令,它將顯示如下所示的所有已建立的鍵空間。
cqlsh> DESCRIBE keyspaces; tutorialspoint system system_traces
在這裡,您可以觀察到新建立的鍵空間tutorialspoint。
Durable_writes
預設情況下,表的 durable_writes 屬性設定為true,但可以設定為 false。您不能將此屬性設定為simplex 策略。
示例
以下是演示 durable writes 屬性用法的示例。
cqlsh> CREATE KEYSPACE test
... WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3 }
... AND DURABLE_WRITES = false;
驗證
您可以透過查詢 System 鍵空間來驗證 test 鍵空間的 durable_writes 屬性是否已設定為 false。此查詢為您提供所有鍵空間及其屬性。
cqlsh> SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | False | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1" : "3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor" : "4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor" : "2"}
(4 rows)
在這裡,您可以觀察到 test 鍵空間的 durable_writes 屬性已設定為 false。
使用鍵空間
您可以使用關鍵字USE使用已建立的鍵空間。其語法如下:
Syntax:USE <identifier>
示例
在以下示例中,我們正在使用鍵空間tutorialspoint。
cqlsh> USE tutorialspoint; cqlsh:tutorialspoint>
使用 Java API 建立鍵空間
您可以使用Session類的execute()方法建立鍵空間。請按照以下步驟使用 Java API 建立鍵空間。
步驟 1:建立叢集物件
首先,建立com.datastax.driver.core包的Cluster.builder類的例項,如下所示。
//Creating Cluster.Builder object Cluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder物件的addContactPoint()方法新增聯絡人(節點的 IP 地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder object Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的 builder 物件,建立一個叢集物件。為此,您在Cluster.Builder類中有一個名為build()的方法。以下程式碼顯示瞭如何建立叢集物件。
//Building a cluster Cluster cluster = builder.build();
您可以使用一行程式碼構建叢集物件,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
步驟 2:建立會話物件
使用Cluster類的connect()方法建立Session物件的例項,如下所示。
Session session = cluster.connect( );
此方法建立一個新會話並對其進行初始化。如果您已經擁有鍵空間,則可以透過以字串格式將鍵空間名稱傳遞給此方法來將其設定為現有鍵空間,如下所示。
Session session = cluster.connect(“ Your keyspace name ” );
步驟 3:執行查詢
您可以使用Session類的execute()方法執行CQL查詢。將查詢以字串格式或作為Statement類物件傳遞給execute()方法。您以字串格式傳遞給此方法的任何內容都將在cqlsh上執行。
在此示例中,我們正在建立一個名為tp的鍵空間。我們使用第一個副本放置策略,即簡單策略,並且我們選擇複製因子為 1 個副本。
您必須將查詢儲存在字串變數中並將其傳遞給 execute() 方法,如下所示。
String query = "CREATE KEYSPACE tp WITH replication "
+ "= {'class':'SimpleStrategy', 'replication_factor':1}; ";
session.execute(query);
步驟 4:使用鍵空間
您可以使用 execute() 方法使用已建立的鍵空間,如下所示。
execute(“ USE tp ” );
以下是使用 Java API 在 Cassandra 中建立和使用鍵空間的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_KeySpace {
public static void main(String args[]){
//Query
String query = "CREATE KEYSPACE tp WITH replication "
+ "= {'class':'SimpleStrategy', 'replication_factor':1};";
//creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
//using the KeySpace
session.execute("USE tp");
System.out.println("Keyspace created");
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Create_KeySpace.java $java Create_KeySpace
在正常情況下,它將產生以下輸出:
Keyspace created
Cassandra - 修改 Keyspace
更改鍵空間
ALTER KEYSPACE 可用於更改鍵空間的屬性,例如副本數量和 durable_writes。以下是此命令的語法。
語法
ALTER KEYSPACE <identifier> WITH <properties>
例如
ALTER KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’};
ALTER KEYSPACE的屬性與 CREATE KEYSPACE 相同。它有兩個屬性:replication 和 durable_writes。
複製
複製選項指定副本放置策略和所需的副本數量。
Durable_writes
使用此選項,您可以指示 Cassandra 是否對當前鍵空間的更新使用 commitlog。此選項不是必需的,預設情況下設定為 true。
示例
以下是更改鍵空間的示例。
這裡我們正在更改名為TutorialsPoint的鍵空間。
我們將複製因子從 1 更改為 3。
cqlsh.> ALTER KEYSPACE tutorialspoint
WITH replication = {'class':'NetworkTopologyStrategy', 'replication_factor' : 3};
更改 Durable_writes
您還可以更改鍵空間的 durable_writes 屬性。以下是test鍵空間的 durable_writes 屬性。
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | False | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1":"3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}
(4 rows)
ALTER KEYSPACE test
WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}
AND DURABLE_WRITES = true;
再次,如果您驗證鍵空間的屬性,它將產生以下輸出。
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | True | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1":"3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}
(4 rows)
使用 Java API 更改鍵空間
您可以使用Session類的execute()方法更改鍵空間。請按照以下步驟使用 Java API 更改鍵空間。
步驟 1:建立叢集物件
首先,建立com.datastax.driver.core包的Cluster.builder類的例項,如下所示。
//Creating Cluster.Builder object Cluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder物件的addContactPoint()方法新增聯絡人(節點的 IP 地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder object Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的 builder 物件,建立一個叢集物件。為此,您在Cluster.Builder類中有一個名為build()的方法。以下程式碼顯示瞭如何建立叢集物件。
//Building a cluster Cluster cluster = builder.build();
您可以使用一行程式碼構建叢集物件,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
步驟 2:建立會話物件
使用Cluster類的connect()方法建立Session物件的例項,如下所示。
Session session = cluster.connect( );
此方法建立一個新會話並對其進行初始化。如果您已經擁有鍵空間,則可以透過以字串格式將鍵空間名稱傳遞給此方法來將其設定為現有鍵空間,如下所示。
Session session = cluster.connect(“ Your keyspace name ” );
步驟 3:執行查詢
您可以使用 Session 類的 execute() 方法執行 CQL 查詢。將查詢以字串格式或作為 Statement 類物件傳遞給 execute() 方法。您以字串格式傳遞給此方法的任何內容都將在 cqlsh 上執行。
在此示例中,
我們正在更改名為tp的鍵空間。我們正在將複製選項從簡單策略更改為網路拓撲策略。
我們正在將durable_writes更改為 false
您必須將查詢儲存在字串變數中並將其傳遞給 execute() 方法,如下所示。
//Query
String query = "ALTER KEYSPACE tp WITH replication " + "= {'class':'NetworkTopologyStrategy', 'datacenter1':3}" +" AND DURABLE_WRITES = false;";
session.execute(query);
以下是使用 Java API 在 Cassandra 中建立和使用鍵空間的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Alter_KeySpace {
public static void main(String args[]){
//Query
String query = "ALTER KEYSPACE tp WITH replication " + "= {'class':'NetworkTopologyStrategy', 'datacenter1':3}"
+ "AND DURABLE_WRITES = false;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
System.out.println("Keyspace altered");
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Alter_KeySpace.java $java Alter_KeySpace
在正常情況下,它會產生以下輸出:
Keyspace Altered
Cassandra - 刪除 Keyspace
刪除鍵空間
您可以使用命令DROP KEYSPACE刪除鍵空間。以下是刪除鍵空間的語法。
語法
DROP KEYSPACE <identifier>
例如
DROP KEYSPACE “KeySpace name”
示例
以下程式碼刪除鍵空間tutorialspoint。
cqlsh> DROP KEYSPACE tutorialspoint;
驗證
使用命令Describe驗證鍵空間並檢查表是否已刪除,如下所示。
cqlsh> DESCRIBE keyspaces; system system_traces
由於我們已刪除鍵空間 tutorialspoint,因此您不會在鍵空間列表中找到它。
使用 Java API 刪除鍵空間
您可以使用 Session 類的 execute() 方法建立鍵空間。請按照以下步驟使用 Java API 刪除鍵空間。
步驟 1:建立叢集物件
首先,建立com.datastax.driver.core包的Cluster.builder類的例項,如下所示。
//Creating Cluster.Builder object Cluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder物件的addContactPoint()方法新增聯絡人(節點的 IP 地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder object Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的 builder 物件,建立一個叢集物件。為此,您在Cluster.Builder類中有一個名為build()的方法。以下程式碼顯示瞭如何建立叢集物件。
//Building a cluster Cluster cluster = builder.build();
您可以使用一行程式碼構建叢集物件,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
步驟 2:建立會話物件
使用 Cluster 類的 connect() 方法建立 Session 物件的例項,如下所示。
Session session = cluster.connect( );
此方法建立一個新會話並對其進行初始化。如果您已經擁有鍵空間,則可以透過以字串格式將鍵空間名稱傳遞給此方法來將其設定為現有鍵空間,如下所示。
Session session = cluster.connect(“ Your keyspace name”);
步驟 3:執行查詢
您可以使用 Session 類的 execute() 方法執行 CQL 查詢。將查詢以字串格式或作為 Statement 類物件傳遞給 execute() 方法。您以字串格式傳遞給此方法的任何內容都將在 cqlsh 上執行。
在以下示例中,我們正在刪除名為tp的鍵空間。您必須將查詢儲存在字串變數中並將其傳遞給 execute() 方法,如下所示。
String query = "DROP KEYSPACE tp; "; session.execute(query);
以下是使用 Java API 在 Cassandra 中建立和使用鍵空間的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_KeySpace {
public static void main(String args[]){
//Query
String query = "Drop KEYSPACE tp";
//creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
System.out.println("Keyspace deleted");
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Delete_KeySpace.java $java Delete_KeySpace
在正常情況下,它應該產生以下輸出:
Keyspace deleted
Cassandra - 建立表
建立表
您可以使用CREATE TABLE命令建立表。以下是建立表的語法。
語法
CREATE (TABLE | COLUMNFAMILY) <tablename>
('<column-definition>' , '<column-definition>')
(WITH <option> AND <option>)
定義列
您可以如下所示定義列。
column name1 data type, column name2 data type, example: age int, name text
主鍵
主鍵是用於唯一標識行的列。因此,在建立表時,定義主鍵是強制性的。主鍵由一個或多個表的列組成。您可以如下所示定義表的 主鍵。
CREATE TABLE tablename( column1 name datatype PRIMARYKEY, column2 name data type, column3 name data type. )
或
CREATE TABLE tablename( column1 name datatype PRIMARYKEY, column2 name data type, column3 name data type, PRIMARY KEY (column1) )
示例
以下是在 Cassandra 中使用 cqlsh 建立表的示例。這裡我們:
使用 keyspace tutorialspoint
建立名為emp的表
它將包含諸如員工姓名、ID、城市、薪資和電話號碼等詳細資訊。員工 ID 是主鍵。
cqlsh> USE tutorialspoint; cqlsh:tutorialspoint>; CREATE TABLE emp( emp_id int PRIMARY KEY, emp_name text, emp_city text, emp_sal varint, emp_phone varint );
驗證
select 語句將為您提供架構。使用如下所示的 select 語句驗證表。
cqlsh:tutorialspoint> select * from emp; emp_id | emp_city | emp_name | emp_phone | emp_sal --------+----------+----------+-----------+--------- (0 rows)
在這裡,您可以觀察到使用給定列建立的表。由於我們已刪除 keyspace tutorialspoint,您將無法在 keyspaces 列表中找到它。
使用 Java API 建立表
您可以使用 Session 類的 execute() 方法建立表。請按照以下步驟使用 Java API 建立表。
步驟 1:建立叢集物件
首先,建立com.datastax.driver.core包的Cluster.builder類的例項,如下所示。
//Creating Cluster.Builder object Cluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder物件的addContactPoint()方法新增聯絡人(節點的 IP 地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder object Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的 builder 物件,建立一個叢集物件。為此,您在Cluster.Builder類中有一個名為build()的方法。以下程式碼顯示瞭如何建立叢集物件。
//Building a cluster Cluster cluster = builder.build();
您可以使用一行程式碼構建叢集物件,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
步驟 2:建立會話物件
使用Cluster類的connect()方法建立 Session 物件的例項,如下所示。
Session session = cluster.connect( );
此方法建立一個新會話並對其進行初始化。如果您已經擁有鍵空間,則可以透過以字串格式將鍵空間名稱傳遞給此方法來將其設定為現有鍵空間,如下所示。
Session session = cluster.connect(“ Your keyspace name ” );
這裡我們使用名為tp的 keyspace。因此,建立 Session 物件,如下所示。
Session session = cluster.connect(“ tp” );
步驟 3:執行查詢
您可以使用 Session 類的 execute() 方法執行 CQL 查詢。將查詢以字串格式或作為 Statement 類物件傳遞給 execute() 方法。您以字串格式傳遞給此方法的任何內容都將在 cqlsh 上執行。
在以下示例中,我們正在建立名為emp的表。您必須將查詢儲存在字串變數中,並將其傳遞給 execute() 方法,如下所示。
//Query String query = "CREATE TABLE emp(emp_id int PRIMARY KEY, " + "emp_name text, " + "emp_city text, " + "emp_sal varint, " + "emp_phone varint );"; session.execute(query);
以下是使用 Java API 在 Cassandra 中建立和使用鍵空間的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Table {
public static void main(String args[]){
//Query
String query = "CREATE TABLE emp(emp_id int PRIMARY KEY, "
+ "emp_name text, "
+ "emp_city text, "
+ "emp_sal varint, "
+ "emp_phone varint );";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table created");
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Create_Table.java $java Create_Table
在正常情況下,它應該產生以下輸出:
Table created
Cassandra - 修改表
更改表
您可以使用ALTER TABLE命令更改表。以下是建立表的語法。
語法
ALTER (TABLE | COLUMNFAMILY) <tablename> <instruction>
使用 ALTER 命令,您可以執行以下操作:
新增列
刪除列
新增列
使用 ALTER 命令,您可以向表中新增列。新增列時,您需要注意列名稱不要與現有列名稱衝突,並且表未定義為使用緊湊儲存選項。以下是向表中新增列的語法。
ALTER TABLE table name ADD new column datatype;
示例
以下是如何向現有表新增列的示例。這裡我們向名為emp的表中新增一個名為emp_email的文字資料型別列。
cqlsh:tutorialspoint> ALTER TABLE emp ... ADD emp_email text;
驗證
使用 SELECT 語句驗證列是否已新增。在這裡,您可以觀察到新新增的列 emp_email。
cqlsh:tutorialspoint> select * from emp; emp_id | emp_city | emp_email | emp_name | emp_phone | emp_sal --------+----------+-----------+----------+-----------+---------
刪除列
使用 ALTER 命令,您可以從表中刪除列。在從表中刪除列之前,請檢查表是否未定義為使用緊湊儲存選項。以下是使用 ALTER 命令從表中刪除列的語法。
ALTER table name DROP column name;
示例
以下是如何從表中刪除列的示例。這裡我們刪除名為emp_email的列。
cqlsh:tutorialspoint> ALTER TABLE emp DROP emp_email;
驗證
使用select語句驗證列是否已刪除,如下所示。
cqlsh:tutorialspoint> select * from emp; emp_id | emp_city | emp_name | emp_phone | emp_sal --------+----------+----------+-----------+--------- (0 rows)
由於emp_email列已被刪除,您將無法再找到它。
使用 Java API 更改表
您可以使用 Session 類的 execute() 方法建立表。請按照以下步驟使用 Java API 更改表。
步驟 1:建立叢集物件
首先,建立com.datastax.driver.core包的Cluster.builder類的例項,如下所示。
//Creating Cluster.Builder object Cluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder物件的addContactPoint()方法新增聯絡人(節點的 IP 地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder object Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的 builder 物件,建立一個叢集物件。為此,您在Cluster.Builder類中有一個名為build()的方法。以下程式碼顯示瞭如何建立叢集物件。
//Building a cluster Cluster cluster = builder.build();
您可以使用一行程式碼構建叢集物件,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
步驟 2:建立會話物件
使用 Cluster 類的 connect() 方法建立 Session 物件的例項,如下所示。
Session session = cluster.connect( );
此方法建立一個新會話並對其進行初始化。如果您已經擁有 keyspace,則可以透過將 KeySpace 名稱以字串格式傳遞給此方法來將其設定為現有的 keyspace,如下所示。
Session session = cluster.connect(“ Your keyspace name ” ); Session session = cluster.connect(“ tp” );
這裡我們使用名為 tp 的 KeySpace。因此,建立 Session 物件,如下所示。
步驟 3:執行查詢
您可以使用 Session 類的 execute() 方法執行 CQL 查詢。將查詢以字串格式或作為 Statement 類物件傳遞給 execute() 方法。您以字串格式傳遞給此方法的任何內容都將在cqlsh上執行。
在以下示例中,我們正在向名為emp的表中新增一列。為此,您必須將查詢儲存在字串變數中,並將其傳遞給 execute() 方法,如下所示。
//Query String query1 = "ALTER TABLE emp ADD emp_email text"; session.execute(query);
以下是向現有表新增列的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Add_column {
public static void main(String args[]){
//Query
String query = "ALTER TABLE emp ADD emp_email text";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Column added");
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Add_Column.java $java Add_Column
在正常情況下,它應該產生以下輸出:
Column added
刪除列
以下是從現有表中刪除列的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Delete_Column {
public static void main(String args[]){
//Query
String query = "ALTER TABLE emp DROP emp_email;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//executing the query
session.execute(query);
System.out.println("Column deleted");
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Delete_Column.java $java Delete_Column
在正常情況下,它應該產生以下輸出:
Column deleted
Cassandra - 刪除表
刪除表
您可以使用Drop Table命令刪除表。其語法如下:
語法
DROP TABLE <tablename>
示例
以下程式碼從 KeySpace 中刪除現有表。
cqlsh:tutorialspoint> DROP TABLE emp;
驗證
使用 Describe 命令驗證表是否已刪除。由於 emp 表已被刪除,您將無法在列族列表中找到它。
cqlsh:tutorialspoint> DESCRIBE COLUMNFAMILIES; employee
使用 Java API 刪除表
您可以使用 Session 類的 execute() 方法刪除表。請按照以下步驟使用 Java API 刪除表。
步驟 1:建立叢集物件
首先,建立com.datastax.driver.core包的Cluster.builder類的例項,如下所示:
//Creating Cluster.Builder object Cluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder物件的addContactPoint()方法新增聯絡人(節點的 IP 地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder object Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的 builder 物件,建立一個叢集物件。為此,您在Cluster.Builder類中有一個名為build()的方法。以下程式碼顯示瞭如何建立叢集物件。
//Building a cluster Cluster cluster = builder.build();
您可以使用一行程式碼構建叢集物件,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
步驟 2:建立會話物件
使用 Cluster 類的 connect() 方法建立 Session 物件的例項,如下所示。
Session session = cluster.connect( );
此方法建立一個新會話並對其進行初始化。如果您已經擁有 keyspace,則可以透過將 KeySpace 名稱以字串格式傳遞給此方法來將其設定為現有的 keyspace,如下所示。
Session session = cluster.connect(“Your keyspace name”);
這裡我們使用名為tp的 keyspace。因此,建立 Session 物件,如下所示。
Session session = cluster.connect(“tp”);
步驟 3:執行查詢
您可以使用 Session 類的 execute() 方法執行 CQL 查詢。將查詢以字串格式或作為 Statement 類物件傳遞給 execute() 方法。您以字串格式傳遞給此方法的任何內容都將在cqlsh上執行。
在以下示例中,我們正在刪除名為emp的表。您必須將查詢儲存在字串變數中,並將其傳遞給 execute() 方法,如下所示。
// Query String query = "DROP TABLE emp1;”; session.execute(query);
以下是使用 Java API 在 Cassandra 中刪除表的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_Table {
public static void main(String args[]){
//Query
String query = "DROP TABLE emp1;";
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table dropped");
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Drop_Table.java $java Drop_Table
在正常情況下,它應該產生以下輸出:
Table dropped
Cassandra - 清空表
截斷表
您可以使用 TRUNCATE 命令截斷表。當您截斷表時,表中的所有行將被永久刪除。以下是此命令的語法。
語法
TRUNCATE <tablename>
示例
假設有一個名為student的表,其中包含以下資料。
| s_id | s_name | s_branch | s_aggregate |
|---|---|---|---|
| 1 | ram | IT | 70 |
| 2 | rahman | EEE | 75 |
| 3 | robbin | Mech | 72 |
當您執行 select 語句以獲取表student時,它將為您提供以下輸出。
cqlsh:tp> select * from student;
s_id | s_aggregate | s_branch | s_name
------+-------------+----------+--------
1 | 70 | IT | ram
2 | 75 | EEE | rahman
3 | 72 | MECH | robbin
(3 rows)
現在使用 TRUNCATE 命令截斷表。
cqlsh:tp> TRUNCATE student;
驗證
透過執行select語句驗證表是否已截斷。以下是截斷後對 student 表執行 select 語句的輸出。
cqlsh:tp> select * from student; s_id | s_aggregate | s_branch | s_name ------+-------------+----------+-------- (0 rows)
使用 Java API 截斷表
您可以使用 Session 類的 execute() 方法截斷表。請按照以下步驟截斷表。
步驟 1:建立叢集物件
首先,建立com.datastax.driver.core包的Cluster.builder類的例項,如下所示。
//Creating Cluster.Builder object Cluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder物件的addContactPoint()方法新增聯絡人(節點的 IP 地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder object Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的 builder 物件,建立一個叢集物件。為此,您在Cluster.Builder類中有一個名為build()的方法。以下程式碼顯示瞭如何建立叢集物件。
//Building a cluster Cluster cluster = builder.build();
您可以使用一行程式碼構建叢集物件,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
步驟 2:建立 Session 物件
使用 Cluster 類的 connect() 方法建立 Session 物件的例項,如下所示。
Session session = cluster.connect( );
此方法建立一個新會話並對其進行初始化。如果您已經擁有 keyspace,則可以透過將 KeySpace 名稱以字串格式傳遞給此方法來將其設定為現有的 keyspace,如下所示。
Session session = cluster.connect(“ Your keyspace name ” ); Session session = cluster.connect(“ tp” );
這裡我們使用名為 tp 的 keyspace。因此,建立 Session 物件,如下所示。
步驟 3:執行查詢
您可以使用 Session 類的 execute() 方法執行 CQL 查詢。將查詢以字串格式或作為 Statement 類物件傳遞給 execute() 方法。您以字串格式傳遞給此方法的任何內容都將在cqlsh上執行。
在以下示例中,我們正在截斷名為emp的表。您必須將查詢儲存在字串變數中,並將其傳遞給execute()方法,如下所示。
//Query String query = "TRUNCATE emp;;”; session.execute(query);
以下是使用 Java API 在 Cassandra 中截斷表的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Truncate_Table {
public static void main(String args[]){
//Query
String query = "Truncate student;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table truncated");
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Truncate_Table.java $java Truncate_Table
在正常情況下,它應該產生以下輸出:
Table truncated
Cassandra - 建立索引
使用 Cqlsh 建立索引
您可以使用CREATE INDEX命令在 Cassandra 中建立索引。其語法如下:
CREATE INDEX <identifier> ON <tablename>
以下是如何向列建立索引的示例。這裡我們向名為 emp 的表中的列“emp_name”建立索引。
cqlsh:tutorialspoint> CREATE INDEX name ON emp1 (emp_name);
使用 Java API 建立索引
您可以使用 Session 類的 execute() 方法向表的列建立索引。請按照以下步驟向表中的列建立索引。
步驟 1:建立叢集物件
首先,建立com.datastax.driver.core包的Cluster.builder類的例項,如下所示。
//Creating Cluster.Builder object Cluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder物件的addContactPoint()方法新增聯絡人(節點的 IP 地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder object Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的 builder 物件,建立一個叢集物件。為此,您在Cluster.Builder類中有一個名為build()的方法。以下程式碼顯示瞭如何建立叢集物件。
//Building a cluster Cluster cluster = builder.build();
您可以使用一行程式碼構建叢集物件,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
步驟 2:建立會話物件
使用Cluster類的 connect() 方法建立 Session 物件的例項,如下所示。
Session session = cluster.connect( );
此方法建立一個新會話並對其進行初始化。如果您已經擁有 keyspace,則可以透過將 KeySpace 名稱以字串格式傳遞給此方法來將其設定為現有的 keyspace,如下所示。
Session session = cluster.connect(“ Your keyspace name ” );
這裡我們使用名為tp的 KeySpace。因此,建立 Session 物件,如下所示。
Session session = cluster.connect(“ tp” );
步驟 3:執行查詢
您可以使用 Session 類的 execute() 方法執行 CQL 查詢。將查詢以字串格式或作為 Statement 類物件傳遞給 execute() 方法。您以字串格式傳遞給此方法的任何內容都將在cqlsh上執行。
在以下示例中,我們正在向名為emp的表中的名為 emp_name 的列建立索引。您必須將查詢儲存在字串變數中,並將其傳遞給 execute() 方法,如下所示。
//Query String query = "CREATE INDEX name ON emp1 (emp_name);"; session.execute(query);
以下是使用 Java API 在 Cassandra 中建立表中列索引的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Index {
public static void main(String args[]){
//Query
String query = "CREATE INDEX name ON emp1 (emp_name);";
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Index created");
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Create_Index.java $java Create_Index
在正常情況下,它應該產生以下輸出:
Index created
Cassandra - 刪除索引
刪除索引
您可以使用DROP INDEX命令刪除索引。其語法如下:
DROP INDEX <identifier>
以下是如何刪除表中列索引的示例。這裡我們刪除表 emp 中列名稱的索引。
cqlsh:tp> drop index name;
使用 Java API 刪除索引
您可以使用 Session 類的 execute() 方法刪除表的索引。請按照以下步驟從表中刪除索引。
步驟 1:建立叢集物件
建立com.datastax.driver.core包的Cluster.builder類的例項,如下所示。
//Creating Cluster.Builder object Cluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder物件的addContactPoint()方法新增聯絡點(節點的 IP 地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder object Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的 builder 物件,建立一個叢集物件。為此,您在Cluster.Builder類中有一個名為build()的方法。以下程式碼顯示瞭如何建立叢集物件。
//Building a cluster Cluster cluster = builder.build();
您可以使用一行程式碼構建叢集物件,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
步驟 2:建立會話物件
使用 Cluster 類的 connect() 方法建立 Session 物件的例項,如下所示。
Session session = cluster.connect( );
此方法建立一個新會話並對其進行初始化。如果您已經擁有 keyspace,則可以透過將 KeySpace 名稱以字串格式傳遞給此方法來將其設定為現有的 keyspace,如下所示。
Session session = cluster.connect(“ Your keyspace name ” );
這裡我們使用名為tp的 KeySpace。因此,建立 Session 物件,如下所示。
Session session = cluster.connect(“ tp” );
步驟 3:執行查詢
您可以使用 Session 類的 execute() 方法執行 CQL 查詢。將查詢以字串格式或作為 Statement 類物件傳遞給 execute() 方法。您以字串格式傳遞給此方法的任何內容都將在 cqlsh 上執行。
在以下示例中,我們正在刪除emp表的索引“name”。您必須將查詢儲存在字串變數中,並將其傳遞給 execute() 方法,如下所示。
//Query String query = "DROP INDEX user_name;"; session.execute(query);
以下是使用 Java API 在 Cassandra 中刪除索引的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_Index {
public static void main(String args[]){
//Query
String query = "DROP INDEX user_name;";
//Creating cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();.
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Index dropped");
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Drop_index.java $java Drop_index
在正常情況下,它應該產生以下輸出:
Index dropped
Cassandra - 批處理語句
使用批處理語句
使用BATCH,您可以同時執行多個修改語句(插入、更新、刪除)。其語法如下:
BEGIN BATCH <insert-stmt>/ <update-stmt>/ <delete-stmt> APPLY BATCH
示例
假設 Cassandra 中有一個名為 emp 的表,其中包含以下資料:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ram | Hyderabad | 9848022338 | 50000 |
| 2 | robin | Delhi | 9848022339 | 50000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
在此示例中,我們將執行以下操作:
- 插入具有以下詳細資訊的新行 (4, rajeev, pune, 9848022331, 30000)。
- 將行 ID 為 3 的員工的薪資更新為 50000。
- 刪除行 ID 為 2 的員工的城市。
要一次性執行上述操作,請使用以下 BATCH 命令:
cqlsh:tutorialspoint> BEGIN BATCH ... INSERT INTO emp (emp_id, emp_city, emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000); ... UPDATE emp SET emp_sal = 50000 WHERE emp_id =3; ... DELETE emp_city FROM emp WHERE emp_id = 2; ... APPLY BATCH;
驗證
進行更改後,使用 SELECT 語句驗證表。它應產生以下輸出:
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)
這裡您可以檢視包含修改後資料的表格。
使用 Java API 的批處理語句
可以使用 Session 類的 execute() 方法以程式設計方式在表中編寫批處理語句。請按照以下步驟使用 Java API 透過批處理語句執行多個語句。
步驟 1:建立叢集物件
建立com.datastax.driver.core包的Cluster.builder類的例項,如下所示。
//Creating Cluster.Builder object Cluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder物件的addContactPoint()方法新增聯絡人(節點的 IP 地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder object Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的構建器物件建立叢集物件。為此,您可以在 Cluster.Builder 類中使用名為 build() 的方法。使用以下程式碼建立叢集物件:
//Building a cluster Cluster cluster = builder.build();
您可以使用一行程式碼構建叢集物件,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
步驟 2:建立會話物件
使用 Cluster 類的 connect() 方法建立 Session 物件的例項,如下所示。
Session session = cluster.connect( );
此方法建立一個新會話並對其進行初始化。如果您已經擁有 keyspace,則可以透過將 KeySpace 名稱以字串格式傳遞給此方法來將其設定為現有的 keyspace,如下所示。
Session session = cluster.connect(“ Your keyspace name ”);
這裡我們使用名為 tp 的鍵空間。因此,請按如下所示建立會話物件。
Session session = cluster.connect(“tp”);
步驟 3:執行查詢
您可以使用 Session 類的 execute() 方法執行 CQL 查詢。將查詢以字串格式或作為 Statement 類物件傳遞給 execute() 方法。您以字串格式傳遞給此方法的任何內容都將在cqlsh上執行。
在此示例中,我們將執行以下操作:
- 插入具有以下詳細資訊的新行 (4, rajeev, pune, 9848022331, 30000)。
- 將行 ID 為 3 的員工的薪資更新為 50000。
- 刪除行 ID 為 2 的員工的城市。
您必須將查詢儲存在字串變數中並將其傳遞給 execute() 方法,如下所示。
String query1 = ” BEGIN BATCH INSERT INTO emp (emp_id, emp_city, emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000); UPDATE emp SET emp_sal = 50000 WHERE emp_id =3; DELETE emp_city FROM emp WHERE emp_id = 2; APPLY BATCH;”;
以下是使用 Java API 在 Cassandra 中同時在表上執行多個語句的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Batch {
public static void main(String args[]){
//query
String query =" BEGIN BATCH INSERT INTO emp (emp_id, emp_city,
emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);"
+ "UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;"
+ "DELETE emp_city FROM emp WHERE emp_id = 2;"
+ "APPLY BATCH;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Changes done");
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Batch.java $java Batch
在正常情況下,它應該產生以下輸出:
Changes done
Cassandra - 建立資料
在表中建立資料
您可以使用 INSERT 命令將資料插入表中行的列中。以下是建立表中資料的語法。
INSERT INTO <tablename> (<column1 name>, <column2 name>....) VALUES (<value1>, <value2>....) USING <option>
示例
假設有一個名為 emp 的表,其列為 (emp_id, emp_name, emp_city, emp_phone, emp_sal),您需要將以下資料插入 emp 表中。
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ram | Hyderabad | 9848022338 | 50000 |
| 2 | robin | Hyderabad | 9848022339 | 40000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
使用以下命令填充表中所需的資料。
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal) VALUES(1,'ram', 'Hyderabad', 9848022338, 50000); cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal) VALUES(2,'robin', 'Hyderabad', 9848022339, 40000); cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal) VALUES(3,'rahman', 'Chennai', 9848022330, 45000);
驗證
插入資料後,使用 SELECT 語句驗證資料是否已插入。如果您使用 SELECT 語句驗證 emp 表,則會得到以下輸出。
cqlsh:tutorialspoint> SELECT * FROM emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Hyderabad | robin | 9848022339 | 40000
3 | Chennai | rahman | 9848022330 | 45000
(3 rows)
這裡您可以看到表已填充我們插入的資料。
使用 Java API 建立資料
您可以使用 Session 類的 execute() 方法在表中建立資料。請按照以下步驟使用 Java API 在表中建立資料。
步驟 1:建立叢集物件
建立com.datastax.driver.core包的Cluster.builder類的例項,如下所示。
//Creating Cluster.Builder object Cluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder物件的addContactPoint()方法新增聯絡人(節點的 IP 地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint("127.0.0.1");
使用新的 builder 物件,建立一個叢集物件。為此,您在Cluster.Builder類中有一個名為build()的方法。以下程式碼顯示瞭如何建立叢集物件。
//Building a cluster Cluster cluster = builder.build();
您可以使用一行程式碼構建叢集物件,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
步驟 2:建立會話物件
使用 Cluster 類的 connect() 方法建立 Session 物件的例項,如下所示。
Session session = cluster.connect( );
此方法建立一個新會話並對其進行初始化。如果您已經擁有 keyspace,則可以透過將 KeySpace 名稱以字串格式傳遞給此方法來將其設定為現有的 keyspace,如下所示。
Session session = cluster.connect(“ Your keyspace name ” );
這裡我們使用名為 tp 的鍵空間。因此,請按如下所示建立會話物件。
Session session = cluster.connect(“ tp” );
步驟 3:執行查詢
您可以使用 Session 類的 execute() 方法執行 CQL 查詢。將查詢以字串格式或作為 Statement 類物件傳遞給 execute() 方法。您以字串格式傳遞給此方法的任何內容都將在 cqlsh 上執行。
在以下示例中,我們正在將資料插入名為 emp 的表中。您需要將查詢儲存在字串變數中,並將其作為引數傳遞給 execute() 方法,如下所示。
String query1 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal) VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);” ; String query2 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal) VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);” ; String query3 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal) VALUES(3,'rahman', 'Chennai', 9848022330, 45000);” ; session.execute(query1); session.execute(query2); session.execute(query3);
以下是使用 Java API 將資料插入 Cassandra 表中的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Data {
public static void main(String args[]){
//queries
String query1 = "INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)"
+ " VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);" ;
String query2 = "INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal)"
+ " VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);" ;
String query3 = "INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)"
+ " VALUES(3,'rahman', 'Chennai', 9848022330, 45000);" ;
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query1);
session.execute(query2);
session.execute(query3);
System.out.println("Data created");
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Create_Data.java $java Create_Data
在正常情況下,它應該產生以下輸出:
Data created
Cassandra - 更新資料
更新表中的資料
UPDATE 是用於更新表中資料的命令。在更新表中的資料時,會使用以下關鍵字:
Where - 此子句用於選擇要更新的行。
Set - 使用此關鍵字設定值。
Must - 包括構成主鍵的所有列。
在更新行時,如果給定的行不可用,則 UPDATE 會建立一個新的行。以下是 UPDATE 命令的語法:
UPDATE <tablename> SET <column name> = <new value> <column name> = <value>.... WHERE <condition>
示例
假設有一個名為 emp 的表。此表儲存特定公司員工的詳細資訊,並且包含以下詳細資訊:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ram | Hyderabad | 9848022338 | 50000 |
| 2 | robin | Hyderabad | 9848022339 | 40000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
現在讓我們將 robin 的 emp_city 更新為 Delhi,並將他的薪資更新為 50000。以下是執行所需更新的查詢。
cqlsh:tutorialspoint> UPDATE emp SET emp_city='Delhi',emp_sal=50000 WHERE emp_id=2;
驗證
使用 SELECT 語句驗證資料是否已更新。如果您使用 SELECT 語句驗證 emp 表,則會產生以下輸出。
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 45000
(3 rows)
這裡您可以看到表資料已更新。
使用 Java API 更新資料
您可以使用 Session 類的 execute() 方法更新表中的資料。請按照以下步驟使用 Java API 更新表中的資料。
步驟 1:建立叢集物件
建立com.datastax.driver.core包的Cluster.builder類的例項,如下所示。
//Creating Cluster.Builder object Cluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder物件的addContactPoint()方法新增聯絡人(節點的 IP 地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint("127.0.0.1");
使用新的構建器物件建立叢集物件。為此,您可以在 Cluster.Builder 類中使用名為 build() 的方法。使用以下程式碼建立叢集物件。
//Building a cluster Cluster cluster = builder.build();
您可以使用一行程式碼構建叢集物件,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
步驟 2:建立會話物件
使用 Cluster 類的 connect() 方法建立 Session 物件的例項,如下所示。
Session session = cluster.connect( );
此方法建立一個新會話並對其進行初始化。如果您已經擁有 keyspace,則可以透過將 KeySpace 名稱以字串格式傳遞給此方法來將其設定為現有的 keyspace,如下所示。
Session session = cluster.connect(“ Your keyspace name”);
這裡我們使用名為 tp 的鍵空間。因此,請按如下所示建立會話物件。
Session session = cluster.connect(“tp”);
步驟 3:執行查詢
您可以使用 Session 類的 execute() 方法執行 CQL 查詢。將查詢以字串格式或作為 Statement 類物件傳遞給 execute() 方法。您以字串格式傳遞給此方法的任何內容都將在cqlsh上執行。
在以下示例中,我們正在更新 emp 表。您需要將查詢儲存在字串變數中,並將其作為引數傳遞給 execute() 方法,如下所示。
String query = “ UPDATE emp SET emp_city='Delhi',emp_sal=50000 WHERE emp_id = 2;” ;
以下是使用 Java API 更新表中資料的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Update_Data {
public static void main(String args[]){
//query
String query = " UPDATE emp SET emp_city='Delhi',emp_sal=50000"
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Data updated");
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Update_Data.java $java Update_Data
在正常情況下,它應該產生以下輸出:
Data updated
Cassandra - 讀取資料
使用 Select 子句讀取資料
SELECT 子句用於從 Cassandra 中的表讀取資料。使用此子句,您可以讀取整個表、單個列或特定單元格。以下是 SELECT 子句的語法。
SELECT FROM <tablename>
示例
假設鍵空間中有一個名為 emp 的表,包含以下詳細資訊:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ram | Hyderabad | 9848022338 | 50000 |
| 2 | robin | 空 | 9848022339 | 50000 |
| 3 | rahman | Chennai | 9848022330 | 50000 |
| 4 | rajeev | Pune | 9848022331 | 30000 |
以下示例顯示瞭如何使用 SELECT 子句讀取整個表。這裡我們正在讀取名為 emp 的表。
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)
讀取所需列
以下示例顯示瞭如何讀取表中的特定列。
cqlsh:tutorialspoint> SELECT emp_name, emp_sal from emp;
emp_name | emp_sal
----------+---------
ram | 50000
robin | 50000
rajeev | 30000
rahman | 50000
(4 rows)
Where 子句
使用 WHERE 子句,您可以對所需列施加約束。其語法如下:
SELECT FROM <table name> WHERE <condition>;
注意 - WHERE 子句只能用於構成主鍵的一部分或在其上具有二級索引的列。
在以下示例中,我們正在讀取薪資為 50000 的員工的詳細資訊。首先,為 emp_sal 列設定二級索引。
cqlsh:tutorialspoint> CREATE INDEX ON emp(emp_sal);
cqlsh:tutorialspoint> SELECT * FROM emp WHERE emp_sal=50000;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
使用 Java API 讀取資料
您可以使用 Session 類的 execute() 方法從表中讀取資料。請按照以下步驟使用 Java API 透過批處理語句執行多個語句。
步驟 1:建立叢集物件
建立com.datastax.driver.core包的Cluster.builder類的例項,如下所示。
//Creating Cluster.Builder object Cluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder物件的addContactPoint()方法新增聯絡人(節點的 IP 地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder object Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的構建器物件建立叢集物件。為此,您可以在 Cluster.Builder 類中使用名為 build() 的方法。使用以下程式碼建立叢集物件。
//Building a cluster Cluster cluster = builder.build();
您可以使用一行程式碼構建叢集物件,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
步驟 2:建立會話物件
使用 Cluster 類的 connect() 方法建立 Session 物件的例項,如下所示。
Session session = cluster.connect( );
此方法建立一個新會話並對其進行初始化。如果您已經擁有 keyspace,則可以透過將 KeySpace 名稱以字串格式傳遞給此方法來將其設定為現有的 keyspace,如下所示。
Session session = cluster.connect(“Your keyspace name”);
這裡我們使用名為 tp 的鍵空間。因此,請按如下所示建立會話物件。
Session session = cluster.connect(“tp”);
步驟 3:執行查詢
您可以使用 Session 類的 execute() 方法執行 CQL 查詢。將查詢以字串格式或作為 Statement 類物件傳遞給 execute() 方法。您以字串格式傳遞給此方法的任何內容都將在cqlsh上執行。
在此示例中,我們正在從 emp 表中檢索資料。將查詢儲存在字串中,並將其作為引數傳遞給 session 類的 execute() 方法,如下所示。
String query = ”SELECT 8 FROM emp”; session.execute(query);
使用 Session 類的 execute() 方法執行查詢。
步驟 4:獲取 ResultSet 物件
select 查詢將以 ResultSet 物件的形式返回結果,因此請將結果儲存在 RESULTSET 類的物件中,如下所示。
ResultSet result = session.execute( );
以下是讀取表中資料的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Session;
public class Read_Data {
public static void main(String args[])throws Exception{
//queries
String query = "SELECT * FROM emp";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tutorialspoint");
//Getting the ResultSet
ResultSet result = session.execute(query);
System.out.println(result.all());
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Read_Data.java $java Read_Data
在正常情況下,它應該產生以下輸出:
[Row[1, Hyderabad, ram, 9848022338, 50000], Row[2, Delhi, robin, 9848022339, 50000], Row[4, Pune, rajeev, 9848022331, 30000], Row[3, Chennai, rahman, 9848022330, 50000]]
Cassandra - 讀取資料
使用 Select 子句讀取資料
SELECT 子句用於從 Cassandra 中的表讀取資料。使用此子句,您可以讀取整個表、單個列或特定單元格。以下是 SELECT 子句的語法。
SELECT FROM <tablename>
示例
假設鍵空間中有一個名為 emp 的表,包含以下詳細資訊:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ram | Hyderabad | 9848022338 | 50000 |
| 2 | robin | 空 | 9848022339 | 50000 |
| 3 | rahman | Chennai | 9848022330 | 50000 |
| 4 | rajeev | Pune | 9848022331 | 30000 |
以下示例顯示瞭如何使用 SELECT 子句讀取整個表。這裡我們正在讀取名為 emp 的表。
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)
讀取所需列
以下示例顯示瞭如何讀取表中的特定列。
cqlsh:tutorialspoint> SELECT emp_name, emp_sal from emp;
emp_name | emp_sal
----------+---------
ram | 50000
robin | 50000
rajeev | 30000
rahman | 50000
(4 rows)
Where 子句
使用 WHERE 子句,您可以對所需列施加約束。其語法如下:
SELECT FROM <table name> WHERE <condition>;
注意 - WHERE 子句只能用於構成主鍵的一部分或在其上具有二級索引的列。
在以下示例中,我們正在讀取薪資為 50000 的員工的詳細資訊。首先,為 emp_sal 列設定二級索引。
cqlsh:tutorialspoint> CREATE INDEX ON emp(emp_sal);
cqlsh:tutorialspoint> SELECT * FROM emp WHERE emp_sal=50000;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
使用 Java API 讀取資料
您可以使用 Session 類的 execute() 方法從表中讀取資料。請按照以下步驟使用 Java API 透過批處理語句執行多個語句。
步驟 1:建立叢集物件
建立com.datastax.driver.core包的Cluster.builder類的例項,如下所示。
//Creating Cluster.Builder object Cluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder物件的addContactPoint()方法新增聯絡人(節點的 IP 地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder object Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的構建器物件建立叢集物件。為此,您可以在 Cluster.Builder 類中使用名為 build() 的方法。使用以下程式碼建立叢集物件。
//Building a cluster Cluster cluster = builder.build();
您可以使用一行程式碼構建叢集物件,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
步驟 2:建立會話物件
使用 Cluster 類的 connect() 方法建立 Session 物件的例項,如下所示。
Session session = cluster.connect( );
此方法建立一個新會話並對其進行初始化。如果您已經擁有 keyspace,則可以透過將 KeySpace 名稱以字串格式傳遞給此方法來將其設定為現有的 keyspace,如下所示。
Session session = cluster.connect(“Your keyspace name”);
這裡我們使用名為 tp 的鍵空間。因此,請按如下所示建立會話物件。
Session session = cluster.connect(“tp”);
步驟 3:執行查詢
您可以使用 Session 類的 execute() 方法執行 CQL 查詢。將查詢以字串格式或作為 Statement 類物件傳遞給 execute() 方法。您以字串格式傳遞給此方法的任何內容都將在cqlsh上執行。
在此示例中,我們正在從 emp 表中檢索資料。將查詢儲存在字串中,並將其作為引數傳遞給 session 類的 execute() 方法,如下所示。
String query = ”SELECT 8 FROM emp”; session.execute(query);
使用 Session 類的 execute() 方法執行查詢。
步驟 4:獲取 ResultSet 物件
select 查詢將以 ResultSet 物件的形式返回結果,因此請將結果儲存在 RESULTSET 類的物件中,如下所示。
ResultSet result = session.execute( );
以下是讀取表中資料的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Session;
public class Read_Data {
public static void main(String args[])throws Exception{
//queries
String query = "SELECT * FROM emp";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tutorialspoint");
//Getting the ResultSet
ResultSet result = session.execute(query);
System.out.println(result.all());
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Read_Data.java $java Read_Data
在正常情況下,它應該產生以下輸出:
[Row[1, Hyderabad, ram, 9848022338, 50000], Row[2, Delhi, robin, 9848022339, 50000], Row[4, Pune, rajeev, 9848022331, 30000], Row[3, Chennai, rahman, 9848022330, 50000]]
Cassandra - 刪除資料
從表中刪除資料
您可以使用 DELETE 命令從表中刪除資料。其語法如下:
DELETE FROM <identifier> WHERE <condition>;
示例
假設 Cassandra 中有一個名為 emp 的表,其中包含以下資料:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ram | Hyderabad | 9848022338 | 50000 |
| 2 | robin | Hyderabad | 9848022339 | 40000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
以下語句刪除最後一行中的 emp_sal 列:
cqlsh:tutorialspoint> DELETE emp_sal FROM emp WHERE emp_id=3;
驗證
使用 SELECT 語句驗證資料是否已刪除。如果您使用 SELECT 驗證 emp 表,則會產生以下輸出:
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | null
(3 rows)
由於我們已刪除 Rahman 的薪資,您會在薪資位置看到一個空值。
刪除整行
以下命令從表中刪除整行。
cqlsh:tutorialspoint> DELETE FROM emp WHERE emp_id=3;
驗證
使用 SELECT 語句驗證資料是否已刪除。如果您使用 SELECT 驗證 emp 表,則會產生以下輸出:
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
(2 rows)
由於我們已刪除最後一行,因此表中只剩下兩行。
使用 Java API 刪除資料
您可以使用 Session 類的 execute() 方法刪除表中的資料。請按照以下步驟使用 Java API 從表中刪除資料。
步驟 1:建立叢集物件
建立com.datastax.driver.core包的Cluster.builder類的例項,如下所示。
//Creating Cluster.Builder object Cluster.Builder builder1 = Cluster.builder();
使用Cluster.Builder物件的addContactPoint()方法新增聯絡人(節點的 IP 地址)。此方法返回Cluster.Builder。
//Adding contact point to the Cluster.Builder object Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );
使用新的構建器物件建立叢集物件。為此,您可以在 Cluster.Builder 類中使用名為 build() 的方法。使用以下程式碼建立叢集物件。
//Building a cluster Cluster cluster = builder.build();
您可以使用一行程式碼構建叢集物件,如下所示。
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
步驟 2:建立會話物件
使用 Cluster 類的 connect() 方法建立 Session 物件的例項,如下所示。
Session session = cluster.connect();
此方法建立一個新會話並對其進行初始化。如果您已經擁有 keyspace,則可以透過將 KeySpace 名稱以字串格式傳遞給此方法來將其設定為現有的 keyspace,如下所示。
Session session = cluster.connect(“ Your keyspace name ”);
這裡我們使用名為 tp 的鍵空間。因此,請按如下所示建立會話物件。
Session session = cluster.connect(“tp”);
步驟 3:執行查詢
您可以使用 Session 類的 execute() 方法執行 CQL 查詢。將查詢以字串格式或作為 Statement 類物件傳遞給 execute() 方法。您以字串格式傳遞給此方法的任何內容都將在cqlsh上執行。
在以下示例中,我們正在從名為 emp 的表中刪除資料。您需要將查詢儲存在字串變數中,並將其作為引數傳遞給 execute() 方法,如下所示。
String query1 = ”DELETE FROM emp WHERE emp_id=3; ”; session.execute(query);
以下是使用 Java API 從 Cassandra 中的表刪除資料的完整程式。
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Delete_Data {
public static void main(String args[]){
//query
String query = "DELETE FROM emp WHERE emp_id=3;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Data deleted");
}
}
將上述程式儲存為類名後跟 .java,瀏覽到其儲存位置。編譯並執行程式,如下所示。
$javac Delete_Data.java $java Delete_Data
在正常情況下,它應該產生以下輸出:
Data deleted
Cassandra - CQL 資料型別
CQL 提供了一套豐富的內建資料型別,包括集合型別。除了這些資料型別之外,使用者還可以建立自己的自定義資料型別。下表提供了 CQL 中可用的內建資料型別的列表。
| 資料型別 | 常量 | 描述 |
|---|---|---|
| ascii | 字串 | 表示 ASCII 字串 |
| bigint | bigint | 表示 64 位有符號長整數 |
| blob | blob | 表示任意位元組 |
| Boolean | 布林值 | 表示真或假 |
| counter | 整數 | 表示計數器列 |
| decimal | 整數、浮點數 | 表示可變精度的十進位制數 |
| double | 整數 | 表示 64 位 IEEE-754 浮點數 |
| float | 整數、浮點數 | 表示 32 位 IEEE-754 浮點數 |
| inet | 字串 | 表示 IP 地址,IPv4 或 IPv6 |
| int | 整數 | 表示 32 位有符號整數 |
| text | 字串 | 表示 UTF8 編碼的字串 |
| timestamp | 整數、字串 | 表示時間戳 |
| timeuuid | uuid | 表示型別 1 UUID |
| uuid | uuid | 表示型別 1 或型別 4 |
| UUID | ||
| varchar | 字串 | 表示 uTF8 編碼的字串 |
| varint | 整數 | 表示任意精度的整數 |
集合型別
Cassandra 查詢語言還提供了集合資料型別。下表提供了 CQL 中可用的集合的列表。
| 集合 | 描述 |
|---|---|
| list | 列表是一個或多個有序元素的集合。 |
| map | 對映是鍵值對的集合。 |
| set | 集合是一個或多個元素的集合。 |
使用者定義的資料型別
Cqlsh 為使用者提供了建立自己的資料型別的功能。以下是處理使用者定義的資料型別時使用的命令。
CREATE TYPE - 建立使用者定義的資料型別。
ALTER TYPE - 修改使用者定義的資料型別。
DROP TYPE - 刪除使用者定義的資料型別。
DESCRIBE TYPE - 描述使用者定義的資料型別。
DESCRIBE TYPES - 描述使用者定義的資料型別。
Cassandra - CQL 集合
CQL 提供了使用集合資料型別的功能。使用這些集合型別,您可以在單個變數中儲存多個值。本章介紹如何在 Cassandra 中使用集合。
列表
列表用於以下情況:
- 需要維護元素的順序,並且
- 需要多次儲存值。
您可以使用列表中元素的索引獲取列表資料型別的值。
建立帶列表的表
以下是一個建立示例表的例子,該表有兩個列,name 和 email。為了儲存多個電子郵件,我們使用列表。
cqlsh:tutorialspoint> CREATE TABLE data(name text PRIMARY KEY, email list<text>);
將資料插入列表
將資料插入列表中的元素時,請在方括號 [ ] 內以逗號分隔輸入所有值,如下所示。
cqlsh:tutorialspoint> INSERT INTO data(name, email) VALUES ('ramu',
['abc@gmail.com','cba@yahoo.com'])
更新列表
下面是一個更新名為data表的列表資料型別的示例。這裡我們向列表中添加了另一個電子郵件。
cqlsh:tutorialspoint> UPDATE data ... SET email = email +['xyz@tutorialspoint.com'] ... where name = 'ramu';
驗證
如果您使用SELECT語句驗證表,您將得到以下結果:
cqlsh:tutorialspoint> SELECT * FROM data; name | email ------+-------------------------------------------------------------- ramu | ['abc@gmail.com', 'cba@yahoo.com', 'xyz@tutorialspoint.com'] (1 rows)
SET
Set是一種用於儲存一組元素的資料型別。集合的元素將按排序順序返回。
建立帶有Set的表
以下示例建立一個包含兩列的示例表,名稱和電話。為了儲存多個電話號碼,我們使用set。
cqlsh:tutorialspoint> CREATE TABLE data2 (name text PRIMARY KEY, phone set<varint>);
將資料插入Set
將資料插入集合中的元素時,請在花括號 { } 內以逗號分隔輸入所有值,如下所示。
cqlsh:tutorialspoint> INSERT INTO data2(name, phone)VALUES ('rahman', {9848022338,9848022339});
更新Set
以下程式碼顯示瞭如何在名為data2的表中更新set。這裡我們向set中添加了另一個電話號碼。
cqlsh:tutorialspoint> UPDATE data2
... SET phone = phone + {9848022330}
... where name = 'rahman';
驗證
如果您使用SELECT語句驗證表,您將得到以下結果:
cqlsh:tutorialspoint> SELECT * FROM data2;
name | phone
--------+--------------------------------------
rahman | {9848022330, 9848022338, 9848022339}
(1 rows)
MAP
Map是一種用於儲存元素的鍵值對的資料型別。
建立帶有Map的表
以下示例顯示瞭如何建立一個包含兩列的示例表,名稱和地址。為了儲存多個地址值,我們使用map。
cqlsh:tutorialspoint> CREATE TABLE data3 (name text PRIMARY KEY, address map<timestamp, text>);
將資料插入Map
將資料插入對映中的元素時,請在花括號 { } 內以逗號分隔輸入所有鍵:值對,如下所示。
cqlsh:tutorialspoint> INSERT INTO data3 (name, address)
VALUES ('robin', {'home' : 'hyderabad' , 'office' : 'Delhi' } );
更新Set
以下程式碼顯示瞭如何在名為data3的表中更新map資料型別。這裡我們正在更改鍵office的值,即我們正在更改名為robin的人的辦公地址。
cqlsh:tutorialspoint> UPDATE data3
... SET address = address+{'office':'mumbai'}
... WHERE name = 'robin';
驗證
如果您使用SELECT語句驗證表,您將得到以下結果:
cqlsh:tutorialspoint> select * from data3;
name | address
-------+-------------------------------------------
robin | {'home': 'hyderabad', 'office': 'mumbai'}
(1 rows)
Cassandra - CQL使用者定義資料型別
CQL提供了建立和使用使用者定義資料型別的功能。您可以建立一個數據型別來處理多個欄位。本章介紹如何建立、更改和刪除使用者定義的資料型別。
建立使用者定義的資料型別
命令CREATE TYPE用於建立使用者定義的資料型別。其語法如下:
CREATE TYPE <keyspace name>. <data typename> ( variable1, variable2).
示例
下面是一個建立使用者定義資料型別的示例。在這個示例中,我們正在建立一個包含以下詳細資訊的card_details資料型別。
| 欄位 | 欄位名稱 | 資料型別 |
|---|---|---|
| 信用卡號 | num | int |
| 信用卡密碼 | pin | int |
| 信用卡上的姓名 | name | text |
| cvv | cvv | int |
| 持卡人聯絡方式 | phone | set |
cqlsh:tutorialspoint> CREATE TYPE card_details ( ... num int, ... pin int, ... name text, ... cvv int, ... phone set<int> ... );
注意 - 用於使用者定義資料型別的名稱不應與保留型別名稱重合。
驗證
使用DESCRIBE命令驗證是否已建立該型別。
CREATE TYPE tutorialspoint.card_details ( num int, pin int, name text, cvv int, phone set<int> );
更改使用者定義的資料型別
ALTER TYPE - 命令用於更改現有的資料型別。使用ALTER,您可以新增新欄位或重新命名現有欄位。
向型別新增欄位
使用以下語法向現有的使用者定義資料型別新增新欄位。
ALTER TYPE typename ADD field_name field_type;
以下程式碼向Card_details資料型別新增一個新欄位。這裡我們添加了一個名為email的新欄位。
cqlsh:tutorialspoint> ALTER TYPE card_details ADD email text;
驗證
使用DESCRIBE命令驗證是否已新增新欄位。
cqlsh:tutorialspoint> describe type card_details; CREATE TYPE tutorialspoint.card_details ( num int, pin int, name text, cvv int, phone set<int>, );
重新命名型別中的欄位
使用以下語法重新命名現有的使用者定義資料型別。
ALTER TYPE typename RENAME existing_name TO new_name;
以下程式碼更改型別中欄位的名稱。這裡我們正在將欄位email重新命名為mail。
cqlsh:tutorialspoint> ALTER TYPE card_details RENAME email TO mail;
驗證
使用DESCRIBE命令驗證型別名稱是否已更改。
cqlsh:tutorialspoint> describe type card_details; CREATE TYPE tutorialspoint.card_details ( num int, pin int, name text, cvv int, phone set<int>, mail text );
刪除使用者定義的資料型別
DROP TYPE是用於刪除使用者定義的資料型別的命令。下面是一個刪除使用者定義資料型別的示例。
示例
在刪除之前,使用DESCRIBE_TYPES命令驗證所有使用者定義資料型別的列表,如下所示。
cqlsh:tutorialspoint> DESCRIBE TYPES; card_details card
從這兩種型別中,刪除名為card的型別,如下所示。
cqlsh:tutorialspoint> drop type card;
使用DESCRIBE命令驗證資料型別是否已刪除。
cqlsh:tutorialspoint> describe types; card_details