Caffe2 快速指南
Caffe2 - 簡介
過去幾年,深度學習已成為機器學習領域的一大趨勢。它已成功應用於解決計算機視覺、語音識別和自然語言處理 (NLP) 中以前無法解決的問題。深度學習正被應用於更多領域,並展現出其實用性。
Caffe(用於快速特徵嵌入的卷積架構)是伯克利視覺和學習中心 (BVLC) 開發的一個深度學習框架。Caffe 專案由楊慶佳 (Yangqing Jia) 在加州大學伯克利分校攻讀博士學位期間建立。Caffe 提供了一種簡單的方法來試驗深度學習。它使用 C++編寫,併為Python 和Matlab 提供繫結。
它支援許多不同型別的深度學習架構,例如CNN(卷積神經網路)、LSTM(長短期記憶)和 FC(全連線)。它支援 GPU,因此非常適合涉及深度神經網路的生產環境。它還支援基於 CPU 的核心庫,例如NVIDIA 的 CUDA 深度神經網路庫(cuDNN) 和英特爾數學核心庫(Intel MKL)。
2017 年 4 月,美國社交網路服務公司 Facebook 宣佈推出 Caffe2,其中現在包含 RNN(迴圈神經網路),並在 2018 年 3 月,Caffe2 併入 PyTorch。Caffe2 的建立者和社群成員建立了用於解決各種問題的模型。這些模型作為預訓練模型提供給公眾。Caffe2 幫助建立者使用這些模型並建立自己的網路,以便對資料集進行預測。
在我們深入瞭解 Caffe2 的細節之前,讓我們瞭解一下機器學習和深度學習之間的區別。這對於理解如何在 Caffe2 中建立和使用模型至關重要。
機器學習與深度學習
在任何機器學習演算法中,無論是傳統的還是深度學習的,資料集中的特徵選擇在獲得所需的預測精度方面都起著極其重要的作用。在傳統的機器學習技術中,特徵選擇主要透過人工檢查、判斷和深入的領域知識來完成。有時,您可能需要一些經過測試的特徵選擇演算法的幫助。
傳統的機器學習流程如下圖所示:

在深度學習中,特徵選擇是自動的,並且是深度學習演算法本身的一部分。如下圖所示:

在深度學習演算法中,特徵工程是自動完成的。通常,特徵工程非常耗時,需要良好的領域專業知識。為了實現自動特徵提取,深度學習演算法通常需要大量資料,因此,如果您只有數千或數萬個數據點,深度學習技術可能無法為您提供令人滿意的結果。
對於更大的資料量,與傳統的機器學習演算法相比,深度學習演算法可以產生更好的結果,並且具有較少或無需進行特徵工程的額外優勢。
Caffe2 - 概述
現在,您已經對深度學習有了一些瞭解,讓我們概述一下什麼是 Caffe。
訓練 CNN
讓我們學習訓練 CNN 以對影像進行分類的過程。該過程包括以下步驟:
資料準備 - 在此步驟中,我們對影像進行中心裁剪並調整其大小,以便所有用於訓練和測試的影像都具有相同的大小。這通常是透過對影像資料執行一個小型的 Python 指令碼來完成的。
模型定義 - 在此步驟中,我們定義 CNN 架構。配置儲存在.pb (protobuf) 檔案中。典型的 CNN 架構如下圖所示。
求解器定義 - 我們定義求解器配置檔案。求解器執行模型最佳化。
模型訓練 - 我們使用內建的 Caffe 實用程式來訓練模型。訓練可能需要相當長的時間和 CPU 使用率。訓練完成後,Caffe 將模型儲存在一個檔案中,該檔案稍後可用於測試資料和最終預測部署。

Caffe2 的新功能
在 Caffe2 中,您會發現許多可立即使用的預訓練模型,並且還可以經常利用社群對新模型和演算法的貢獻。您可以建立的模型可以使用雲中的 GPU 能力輕鬆擴充套件,並且也可以透過其跨平臺庫將其縮減到大眾使用。
Caffe2 對 Caffe 的改進可以概括如下:
- 移動端部署
- 新的硬體支援
- 支援大規模分散式訓練
- 量化計算
- 在 Facebook 上進行了壓力測試
預訓練模型演示
伯克利視覺和學習中心 (BVLC) 網站提供了其預訓練網路的演示。一個用於影像分類的此類網路可在以下連結中找到 https://caffe2.ai/docs/learn-more#null__caffe-neural-network-for-image-classification,如下圖所示。

在螢幕截圖中,對狗的影像進行了分類並標註了其預測精度。它還指出對影像進行分類僅用了0.068 秒。您可以透過在螢幕底部提供的選項中指定影像 URL 或上傳影像本身來嘗試自己選擇的影像。
Caffe2 - 安裝
現在,您已經對 Caffe2 的功能有了足夠的瞭解,是時候自己嘗試一下 Caffe2 了。要使用預訓練模型或在您自己的 Python 程式碼中開發模型,您必須首先在您的機器上安裝 Caffe2。
在 Caffe2 網站的安裝頁面(可在以下連結中找到) https://caffe2.ai/docs/getting-started.html,您將看到以下內容以選擇您的平臺和安裝型別。

如上圖所示,Caffe2 支援多個流行的平臺,包括移動平臺。
現在,我們將瞭解本教程中所有專案都在其上進行測試的MacOS 安裝步驟。
MacOS 安裝
安裝可以分為以下四種類型:
- 預構建二進位制檔案
- 從原始碼構建
- Docker 映象
- 雲
根據您的喜好,選擇上述任何一種作為您的安裝型別。此處提供的說明根據 Caffe2 安裝網站上的預構建二進位制檔案提供。它使用 Anaconda 用於Jupyter 環境。在您的控制檯提示符下執行以下命令
pip install torch_nightly -f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html
此外,您還需要一些第三方庫,這些庫可以使用以下命令安裝:
conda install -c anaconda setuptools conda install -c conda-forge graphviz conda install -c conda-forge hypothesis conda install -c conda-forge ipython conda install -c conda-forge jupyter conda install -c conda-forge matplotlib conda install -c anaconda notebook conda install -c anaconda pydot conda install -c conda-forge python-nvd3 conda install -c anaconda pyyaml conda install -c anaconda requests conda install -c anaconda scikit-image conda install -c anaconda scipy
Caffe2 網站中的一些教程還需要安裝zeromq,安裝命令如下:
conda install -c anaconda zeromq
Windows/Linux 安裝
在您的控制檯提示符下執行以下命令:
conda install -c pytorch pytorch-nightly-cpu
您可能已經注意到,您需要 Anaconda 才能使用上述安裝。您需要安裝MacOS 安裝中指定的附加包。
測試安裝
要測試您的安裝,下面提供了一個小的 Python 指令碼,您可以將其剪下並貼上到您的 Juypter 專案中並執行。
from caffe2.python import workspace
import numpy as np
print ("Creating random data")
data = np.random.rand(3, 2)
print(data)
print ("Adding data to workspace ...")
workspace.FeedBlob("mydata", data)
print ("Retrieving data from workspace")
mydata = workspace.FetchBlob("mydata")
print(mydata)
執行上述程式碼時,您應該看到以下輸出:
Creating random data [[0.06152718 0.86448082] [0.36409966 0.52786113] [0.65780886 0.67101053]] Adding data to workspace ... Retrieving data from workspace [[0.06152718 0.86448082] [0.36409966 0.52786113] [0.65780886 0.67101053]]
此處顯示安裝測試頁面的螢幕截圖,供您快速參考:
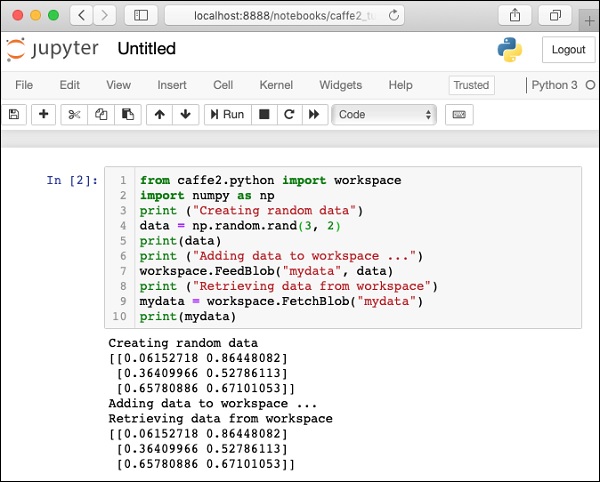
現在,您已在您的機器上安裝了 Caffe2,請繼續安裝教程應用程式。
教程安裝
使用以下命令在您的控制檯中下載教程原始碼:
git clone --recursive https://github.com/caffe2/tutorials caffe2_tutorials
下載完成後,您將在安裝目錄的caffe2_tutorials 資料夾中找到多個 Python 專案。為了方便您快速瀏覽,此處提供了該資料夾的螢幕截圖。
/Users/yourusername/caffe2_tutorials
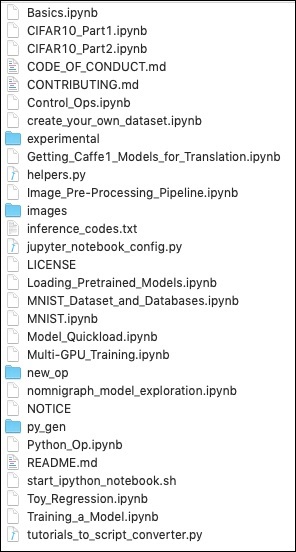
您可以開啟其中一些教程來檢視Caffe2 程式碼是什麼樣的。本教程中描述的接下來的兩個專案主要基於上述示例。
現在是時候進行一些我們自己的 Python 編碼了。讓我們瞭解如何使用來自 Caffe2 的預訓練模型。稍後,您將學習如何建立您自己的微不足道的用於在您自己的資料集上進行訓練的神經網路。
Caffe2 - 驗證對預訓練模型的訪問許可權
在學習如何在您的 Python 應用程式中使用預訓練模型之前,讓我們首先驗證這些模型是否已安裝在您的機器上,並且可以透過 Python 程式碼訪問。
安裝 Caffe2 時,預訓練模型會複製到安裝資料夾中。在安裝了 Anaconda 的機器上,這些模型位於以下資料夾中。
anaconda3/lib/python3.7/site-packages/caffe2/python/models
檢查您的機器上的安裝資料夾中是否存在這些模型。您可以嘗試使用以下簡短的 Python 指令碼來從安裝資料夾中載入這些模型:
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')
print(INIT_NET)
print(PREDICT_NET)
當指令碼成功執行時,您將看到以下輸出:
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/init_net.pb /anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/predict_net.pb
這確認squeezenet 模組已安裝在您的機器上,並且您的程式碼可以訪問它。
現在,您可以編寫您自己的 Python 程式碼來使用 Caffe2 squeezenet 預訓練模組進行影像分類了。
使用預訓練模型進行影像分類
在本課中,您將學習如何使用預訓練模型來檢測給定影像中的物件。您將使用squeezenet 預訓練模組,該模組可以高精度地檢測和分類給定影像中的物件。
開啟一個新的Juypter 筆記本,並按照步驟開發此影像分類應用程式。
匯入庫
首先,我們使用以下程式碼匯入所需的包:
from caffe2.proto import caffe2_pb2 from caffe2.python import core, workspace, models import numpy as np import skimage.io import skimage.transform from matplotlib import pyplot import os import urllib.request as urllib2 import operator
接下來,我們設定一些變數:
INPUT_IMAGE_SIZE = 227 mean = 128
用於訓練的影像尺寸顯然會有所不同。為了確保訓練的準確性,所有這些影像都必須轉換為固定尺寸。同樣,測試影像以及您希望在生產環境中預測的影像也必須轉換為與訓練期間使用的相同尺寸。因此,我們在上面建立一個名為INPUT_IMAGE_SIZE的變數,其值為227。因此,我們將把所有影像轉換為227x227大小,然後再將其用於分類器。
我們還宣告一個名為mean的變數,其值為128,稍後用於改進分類結果。
接下來,我們將開發兩個用於影像處理的函式。
影像處理
影像處理包括兩個步驟。第一個是調整影像大小,第二個是中心裁剪影像。對於這兩個步驟,我們將編寫兩個用於調整大小和裁剪的函式。
影像大小調整
首先,我們將編寫一個用於調整影像大小的函式。如前所述,我們將影像大小調整為227x227。因此,讓我們定義如下函式resize:
def resize(img, input_height, input_width):
我們透過將寬度除以高度來獲得影像的縱橫比。
original_aspect = img.shape[1]/float(img.shape[0])
如果縱橫比大於1,則表示影像較寬,也就是說它是橫向模式。我們現在調整影像高度並使用以下程式碼返回調整大小後的影像:
if(original_aspect>1): new_height = int(original_aspect * input_height) return skimage.transform.resize(img, (input_width, new_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)
如果縱橫比小於1,則表示縱向模式。我們現在使用以下程式碼調整寬度:
if(original_aspect<1): new_width = int(input_width/original_aspect) return skimage.transform.resize(img, (new_width, input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)
如果縱橫比等於1,我們不會進行任何高度/寬度調整。
if(original_aspect == 1): return skimage.transform.resize(img, (input_width, input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)
為了方便參考,完整的函式程式碼如下:
def resize(img, input_height, input_width):
original_aspect = img.shape[1]/float(img.shape[0])
if(original_aspect>1):
new_height = int(original_aspect * input_height)
return skimage.transform.resize(img, (input_width,
new_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)
if(original_aspect<1):
new_width = int(input_width/original_aspect)
return skimage.transform.resize(img, (new_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)
if(original_aspect == 1):
return skimage.transform.resize(img, (input_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)
現在,我們將編寫一個用於裁剪影像中心的函式。
影像裁剪
我們將函式crop_image定義如下:
def crop_image(img,cropx,cropy):
我們使用以下語句提取影像的尺寸:
y,x,c = img.shape
我們使用以下兩行程式碼建立影像的新起點:
startx = x//2-(cropx//2) starty = y//2-(cropy//2)
最後,我們透過使用新的尺寸建立一個影像物件來返回裁剪後的影像:
return img[starty:starty+cropy,startx:startx+cropx]
為了方便參考,完整的函式程式碼如下:
def crop_image(img,cropx,cropy): y,x,c = img.shape startx = x//2-(cropx//2) starty = y//2-(cropy//2) return img[starty:starty+cropy,startx:startx+cropx]
現在,我們將編寫程式碼來測試這些函式。
影像處理
首先,將影像檔案複製到專案目錄中的images子資料夾中。tree.jpg檔案已複製到專案中。以下Python程式碼載入影像並將其顯示在控制檯中:
img = skimage.img_as_float(skimage.io.imread("images/tree.jpg")).astype(np.float32)
print("Original Image Shape: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Original image')
輸出如下:

請注意,原始影像的大小為600 x 960。我們需要將其調整為我們指定的227 x 227。呼叫我們前面定義的resize函式可以完成這項工作。
img = resize(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after resizing: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Resized image')
輸出如下:

請注意,現在影像大小為227 x 363。我們需要將其裁剪為227 x 227,以便最終饋送到我們的演算法中。為此,我們呼叫前面定義的裁剪函式。
img = crop_image(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after cropping: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Center Cropped')
以下是程式碼的輸出:

此時,影像大小為227 x 227,並準備好進行進一步處理。我們現在交換影像軸以將三種顏色提取到三個不同的區域。
img = img.swapaxes(1, 2).swapaxes(0, 1)
print("CHW Image Shape: " , img.shape)
輸出如下:
CHW Image Shape: (3, 227, 227)
請注意,最後一個軸現在已成為陣列中的第一個維度。我們現在將使用以下程式碼繪製三個通道:
pyplot.figure()
for i in range(3):
pyplot.subplot(1, 3, i+1)
pyplot.imshow(img[i])
pyplot.axis('off')
pyplot.title('RGB channel %d' % (i+1))
輸出如下:

最後,我們對影像進行一些額外的處理,例如將紅綠藍 (RGB)轉換為藍綠紅 (BGR),去除均值以獲得更好的結果,並使用以下三行程式碼新增批大小軸:
# convert RGB --> BGR img = img[(2, 1, 0), :, :] # remove mean img = img * 255 - mean # add batch size axis img = img[np.newaxis, :, :, :].astype(np.float32)
此時,您的影像採用NCHW格式,並已準備好饋送到我們的網路中。接下來,我們將載入我們預訓練的模型檔案並將上述影像饋送到其中進行預測。
預測處理後的影像中的物件
我們首先為在Caffe的預訓練模型中定義的init和predict網路設定路徑。
設定模型檔案路徑
請記住我們之前的討論,所有預訓練模型都安裝在models資料夾中。我們將路徑設定為該資料夾,如下所示:
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")
我們將路徑設定為squeezenet模型的init_net protobuf檔案,如下所示:
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')
同樣,我們將路徑設定為predict_net protobuf,如下所示:
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')
出於診斷目的,我們列印這兩條路徑:
print(INIT_NET) print(PREDICT_NET)
為了方便參考,此處提供了上述程式碼及其輸出:
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')
print(INIT_NET)
print(PREDICT_NET)
輸出如下:
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/init_net.pb /anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/predict_net.pb
接下來,我們將建立一個預測器。
建立預測器
我們使用以下兩個語句讀取模型檔案:
with open(INIT_NET, "rb") as f: init_net = f.read() with open(PREDICT_NET, "rb") as f: predict_net = f.read()
透過將指向這兩個檔案的指標作為引數傳遞給Predictor函式來建立預測器。
p = workspace.Predictor(init_net, predict_net)
p物件是預測器,用於預測任何給定影像中的物件。請注意,每個輸入影像都必須採用NCHW格式,就像我們之前對tree.jpg檔案所做的那樣。
預測物件
預測給定影像中的物件很簡單 - 只需執行一行命令。我們在predictor物件上呼叫run方法來檢測給定影像中的物件。
results = p.run({'data': img})
預測結果現在可在results物件中獲得,為了方便閱讀,我們將它轉換為陣列。
results = np.asarray(results)
使用以下語句列印陣列的維度,以便您瞭解:
print("results shape: ", results.shape)
輸出如下所示:
results shape: (1, 1, 1000, 1, 1)
我們現在將刪除不必要的軸:
preds = np.squeeze(results)
現在可以透過獲取preds陣列中的max值來檢索最高的預測結果。
curr_pred, curr_conf = max(enumerate(preds), key=operator.itemgetter(1))
print("Prediction: ", curr_pred)
print("Confidence: ", curr_conf)
輸出如下:
Prediction: 984 Confidence: 0.89235985
正如您所看到的,該模型預測了一個索引值為984,置信度為89%的物件。984的索引對於我們理解檢測到的是什麼型別的物件並沒有多大意義。我們需要使用其索引值獲取物件的字串化名稱。模型識別的物件型別及其相應的索引值可在github儲存庫中找到。
現在,我們將瞭解如何檢索索引值為984的物件的名稱。
將結果轉換為字串
我們建立一個指向github儲存庫的URL物件,如下所示:
codes = "https://gist.githubusercontent.com/aaronmarkham/cd3a6b6ac0 71eca6f7b4a6e40e6038aa/raw/9edb4038a37da6b5a44c3b5bc52e448ff09bfe5b/alexnet_codes"
我們讀取URL的內容:
response = urllib2.urlopen(codes)
響應將包含所有程式碼及其描述的列表。為了讓您瞭解它包含的內容,下面顯示了響應的幾行:
5: 'electric ray, crampfish, numbfish, torpedo', 6: 'stingray', 7: 'cock', 8: 'hen', 9: 'ostrich, Struthio camelus', 10: 'brambling, Fringilla montifringilla',
我們現在使用for迴圈迭代整個陣列,以找到我們想要的程式碼984,如下所示:
for line in response:
mystring = line.decode('ascii')
code, result = mystring.partition(":")[::2]
code = code.strip()
result = result.replace("'", "")
if (code == str(curr_pred)):
name = result.split(",")[0][1:]
print("Model predicts", name, "with", curr_conf, "confidence")
執行程式碼時,您將看到以下輸出:
Model predicts rapeseed with 0.89235985 confidence
您現在可以嘗試在另一個影像上使用該模型。
預測不同的影像
要預測另一個影像,只需將影像檔案複製到專案目錄的images資料夾中。這就是我們之前儲存tree.jpg檔案的目錄。更改程式碼中影像檔案的名稱。只需要更改一個地方,如下所示
img = skimage.img_as_float(skimage.io.imread("images/pretzel.jpg")).astype(np.float32)
原始圖片和預測結果如下所示:

輸出如下:
Model predicts pretzel with 0.99999976 confidence
正如您所看到的,預訓練模型能夠以很高的精度檢測給定影像中的物件。
完整原始碼
此處提供了上述使用預訓練模型在給定影像中進行物件檢測的完整程式碼,以方便您參考:
def crop_image(img,cropx,cropy):
y,x,c = img.shape
startx = x//2-(cropx//2)
starty = y//2-(cropy//2)
return img[starty:starty+cropy,startx:startx+cropx]
img = skimage.img_as_float(skimage.io.imread("images/pretzel.jpg")).astype(np.float32)
print("Original Image Shape: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Original image')
img = resize(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after resizing: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Resized image')
img = crop_image(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after cropping: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Center Cropped')
img = img.swapaxes(1, 2).swapaxes(0, 1)
print("CHW Image Shape: " , img.shape)
pyplot.figure()
for i in range(3):
pyplot.subplot(1, 3, i+1)
pyplot.imshow(img[i])
pyplot.axis('off')
pyplot.title('RGB channel %d' % (i+1))
# convert RGB --> BGR
img = img[(2, 1, 0), :, :]
# remove mean
img = img * 255 - mean
# add batch size axis
img = img[np.newaxis, :, :, :].astype(np.float32)
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')
print(INIT_NET)
print(PREDICT_NET)
with open(INIT_NET, "rb") as f:
init_net = f.read()
with open(PREDICT_NET, "rb") as f:
predict_net = f.read()
p = workspace.Predictor(init_net, predict_net)
results = p.run({'data': img})
results = np.asarray(results)
print("results shape: ", results.shape)
preds = np.squeeze(results)
curr_pred, curr_conf = max(enumerate(preds), key=operator.itemgetter(1))
print("Prediction: ", curr_pred)
print("Confidence: ", curr_conf)
codes = "https://gist.githubusercontent.com/aaronmarkham/cd3a6b6ac071eca6f7b4a6e40e6038aa/raw/9edb4038a37da6b5a44c3b5bc52e448ff09bfe5b/alexnet_codes"
response = urllib2.urlopen(codes)
for line in response:
mystring = line.decode('ascii')
code, result = mystring.partition(":")[::2]
code = code.strip()
result = result.replace("'", "")
if (code == str(curr_pred)):
name = result.split(",")[0][1:]
print("Model predicts", name, "with", curr_conf, "confidence")
到目前為止,您已經知道如何使用預訓練模型對您的資料集進行預測。
接下來是學習如何在Caffe2中定義您的神經網路 (NN)架構並在您的資料集上對其進行訓練。我們現在將學習如何建立一個簡單的單層神經網路。
Caffe2 - 建立您自己的網路
在本課中,您將學習如何在Caffe2中定義一個單層神經網路 (NN)並在隨機生成的資料集上執行它。我們將編寫程式碼以圖形方式描繪網路架構,列印輸入、輸出、權重和偏差值。要理解本課,您必須熟悉神經網路架構、其術語和其中使用的數學。
網路架構
讓我們考慮一下我們想構建一個如下圖所示的單層神經網路:

從數學上講,這個網路由以下Python程式碼表示:
Y = X * W^T + b
其中X、W、b是張量,Y是輸出。我們將用一些隨機資料填充所有三個張量,執行網路並檢查Y輸出。為了定義網路和張量,Caffe2提供了幾個運算元函式。
Caffe2運算元
在Caffe2中,運算元是計算的基本單元。Caffe2運算元表示如下。

Caffe2提供了詳盡的運算元列表。對於我們當前正在設計的網路,我們將使用稱為FC的運算元,它計算將輸入向量X傳遞到具有二維權重矩陣W和一維偏差向量b的完全連線網路的結果。換句話說,它計算以下數學公式
Y = X * W^T + b
其中X的維度為(M x k),W的維度為(n x k),b為(1 x n)。輸出Y的維度將為(M x n),其中M是批大小。
對於向量X和W,我們將使用GaussianFill運算元來建立一些隨機資料。對於生成偏差值b,我們將使用ConstantFill運算元。
我們現在將繼續定義我們的網路。
建立網路
首先,匯入所需的包:
from caffe2.python import core, workspace
接下來,透過呼叫core.Net來定義網路,如下所示:
net = core.Net("SingleLayerFC")
網路的名稱指定為SingleLayerFC。此時,名為net的網路物件被建立。到目前為止,它不包含任何層。
建立張量
我們現在將建立網路所需的三個向量。首先,我們將透過呼叫GaussianFill運算元來建立X張量,如下所示:
X = net.GaussianFill([], ["X"], mean=0.0, std=1.0, shape=[2, 3], run_once=0)
X向量的維度為2 x 3,平均資料值為0.0,標準差為1.0。
同樣,我們建立W張量,如下所示:
W = net.GaussianFill([], ["W"], mean=0.0, std=1.0, shape=[5, 3], run_once=0)
W向量的尺寸為5 x 3。
最後,我們建立大小為5的偏差b矩陣。
b = net.ConstantFill([], ["b"], shape=[5,], value=1.0, run_once=0)
現在,程式碼最重要的部分來了,那就是定義網路本身。
定義網路
我們在下面的 Python 語句中定義網路:
Y = X.FC([W, b], ["Y"])
我們對輸入資料X呼叫FC運算子。權重在W中指定,偏差在b中指定。輸出為Y。或者,您可以使用以下更詳細的 Python 語句建立網路。
Y = net.FC([X, W, b], ["Y"])
此時,網路只是建立了。在我們至少執行一次網路之前,它不會包含任何資料。在執行網路之前,我們將檢查其架構。
列印網路架構
Caffe2 在 JSON 檔案中定義網路架構,可以透過在建立的net物件上呼叫 Proto 方法來檢查。
print (net.Proto())
這會產生以下輸出:
name: "SingleLayerFC"
op {
output: "X"
name: ""
type: "GaussianFill"
arg {
name: "mean"
f: 0.0
}
arg {
name: "std"
f: 1.0
}
arg {
name: "shape"
ints: 2
ints: 3
}
arg {
name: "run_once"
i: 0
}
}
op {
output: "W"
name: ""
type: "GaussianFill"
arg {
name: "mean"
f: 0.0
}
arg {
name: "std"
f: 1.0
}
arg {
name: "shape"
ints: 5
ints: 3
}
arg {
name: "run_once"
i: 0
}
}
op {
output: "b"
name: ""
type: "ConstantFill"
arg {
name: "shape"
ints: 5
}
arg {
name: "value"
f: 1.0
}
arg {
name: "run_once"
i: 0
}
}
op {
input: "X"
input: "W"
input: "b"
output: "Y"
name: ""
type: "FC"
}
正如您在上面的列表中看到的,它首先定義了運算子X、W和b。讓我們以W的定義為例進行檢查。W的型別被指定為GausianFill。均值定義為浮點數0.0,標準差定義為浮點數1.0,形狀為5 x 3。
op {
output: "W"
name: "" type: "GaussianFill"
arg {
name: "mean"
f: 0.0
}
arg {
name: "std"
f: 1.0
}
arg {
name: "shape"
ints: 5
ints: 3
}
...
}
檢查X和b的定義以瞭解其含義。最後,讓我們看一下我們單層網路的定義,此處進行了複製
op {
input: "X"
input: "W"
input: "b"
output: "Y"
name: ""
type: "FC"
}
這裡,網路型別為FC(全連線),輸入為X、W、b,輸出為Y。此網路定義過於冗長,對於大型網路,檢查其內容將變得乏味。幸運的是,Caffe2 為建立的網路提供了圖形表示。
網路圖形表示
要獲取網路的圖形表示,請執行以下程式碼片段,它實際上只有兩行 Python 程式碼。
from caffe2.python import net_drawer from IPython import display graph = net_drawer.GetPydotGraph(net, rankdir="LR") display.Image(graph.create_png(), width=800)
執行程式碼時,您將看到以下輸出:

對於大型網路,圖形表示在視覺化和除錯網路定義錯誤方面非常有用。
最後,現在是時候執行網路了。
執行網路
您可以透過在workspace物件上呼叫RunNetOnce方法來執行網路:
workspace.RunNetOnce(net)
網路執行一次後,我們隨機生成的所有資料都將被建立,饋送到網路中,並建立輸出。在執行網路後建立的張量在 Caffe2 中稱為blobs。工作區包含您建立並存儲在記憶體中的blobs。這與 Matlab 非常相似。
執行網路後,您可以使用以下print命令檢查工作區包含的blobs
print("Blobs in the workspace: {}".format(workspace.Blobs()))
您將看到以下輸出:
Blobs in the workspace: ['W', 'X', 'Y', 'b']
請注意,工作區包含三個輸入 blobs:X、W和b。它還包含名為Y的輸出 blob。現在讓我們檢查這些 blobs 的內容。
for name in workspace.Blobs():
print("{}:\n{}".format(name, workspace.FetchBlob(name)))
您將看到以下輸出:
W: [[ 1.0426593 0.15479846 0.25635982] [-2.2461145 1.4581774 0.16827184] [-0.12009818 0.30771437 0.00791338] [ 1.2274994 -0.903331 -0.68799865] [ 0.30834186 -0.53060573 0.88776857]] X: [[ 1.6588869e+00 1.5279824e+00 1.1889904e+00] [ 6.7048723e-01 -9.7490678e-04 2.5114202e-01]] Y: [[ 3.2709925 -0.297907 1.2803618 0.837985 1.7562964] [ 1.7633215 -0.4651525 0.9211631 1.6511179 1.4302125]] b: [1. 1. 1. 1. 1.]
請注意,您機器上的資料,或者事實上網路的每次執行中的資料都將不同,因為所有輸入都是隨機建立的。您現在已成功定義了一個網路並在您的計算機上執行它。
Caffe2 - 定義複雜的網路
在上一課中,您學習瞭如何建立一個簡單的網路,並學習瞭如何執行它並檢查其輸出。建立複雜網路的過程與上述過程類似。Caffe2 提供了大量運算子來建立複雜的架構。建議您檢視 Caffe2 文件以獲取運算子列表。在學習了各種運算子的目的之後,您就可以建立複雜的網路並對其進行訓練。為了訓練網路,Caffe2 提供了幾個預定義的計算單元——也就是運算子。您需要為要解決的問題型別選擇合適的運算子來訓練您的網路。
一旦網路訓練到您滿意的程度,您可以將其儲存在模型檔案中,類似於您之前使用的預訓練模型檔案。這些訓練好的模型可以貢獻給 Caffe2 儲存庫,以造福其他使用者。或者,您也可以將訓練好的模型用於您自己的私有生產用途。
總結
Caffe2 是一個深度學習框架,允許您試驗幾種型別的用於預測資料的的神經網路。Caffe2 網站提供了許多預訓練模型。您學習瞭如何使用其中一個預訓練模型對給定影像中的物件進行分類。您還學習瞭如何定義您選擇的神經網路架構。可以使用 Caffe 中的許多預定義運算子來訓練此類自定義網路。訓練好的模型儲存在一個檔案中,可以將其用於生產環境。