- AWS Glue 教程
- AWS Glue - 首頁
- AWS Glue - 簡介
- AWS Glue - 快速入門
- AWS Glue - 資料目錄
- AWS Glue - Amazon S3 整合
- AWS Glue - 爬蟲
- AWS Glue - 效能最佳化
- AWS Glue - 成本最佳化
- AWS Glue 資源
- AWS Glue - 快速指南
- AWS Glue - 資源
- AWS Glue - 討論
AWS Glue - 快速入門
為您的第一個作業設定 AWS Glue
按照以下步驟設定您的第一個 AWS Glue 作業:
步驟 1:先決條件
您必須擁有一個AWS 賬戶才能使用AWS Glue。您應該擁有IAM 角色。它允許 AWS Glue 訪問您在 Amazon S3、RDS 或任何其他資料來源中的資料。
此外,您應該將資料儲存在 Amazon S3、RDS 或其他受支援的資料庫中。
步驟 2:設定 AWS Glue 資料目錄
首先,在 Glue 資料目錄中建立一個數據庫。接下來,您需要設定一個爬蟲來掃描和分類您的資料來源(例如 Amazon S3)。
爬蟲的作用是自動檢測資料型別並在您的 Glue 資料目錄中建立元資料表。
步驟 3:在 AWS Glue 中建立一個新作業
資料編目完成後,轉到AWS Glue 控制檯並選擇作業。然後,單擊新增作業以建立一個新的 ETL 作業。
接下來,您需要配置作業。使用以下選項進行配置:
- 命名您的作業。
- 選擇 Glue 將使用的IAM 角色。
- 選擇您的ETL 指令碼源(自動生成或自定義編寫)。
- 定義資料來源(Amazon S3、RDS 等)和目標
這是可選的,但最好在您的作業指令碼中新增轉換或過濾器。
步驟 4:執行您的 Glue 作業
設定完成後,檢視作業設定並單擊執行作業。AWS Glue 將根據定義的 ETL 指令碼開始處理資料。
現在您可以在AWS Glue 控制檯的“作業”部分監控作業進度。
步驟 5:驗證輸出
要驗證輸出,作業完成後,檢查目標位置(例如 Amazon S3)。傳輸的資料應成功載入到那裡。
建立 AWS Glue 爬蟲和資料庫
AWS Glue 的關鍵元件之一是爬蟲,它會自動發現新資料,識別其模式,並相應地更新資料目錄。以下是為您的資料建立 AWS Glue 爬蟲和資料庫的步驟。
步驟 1:設定您的 AWS Glue 資料庫
在 AWS Glue 中建立爬蟲之前,您需要設定一個資料庫。此資料庫將充當資料來源元資料的容器。
按照以下步驟設定資料庫:
- 首先,登入到 AWS Glue 控制檯。
- 在左側導航窗格中,單擊資料目錄部分下的資料庫。
- 選擇新增資料庫並輸入資料庫名稱(例如,my-data-catalog)。
- 最後,單擊建立按鈕,您的資料庫即可使用。
步驟 2:建立 AWS Glue 爬蟲
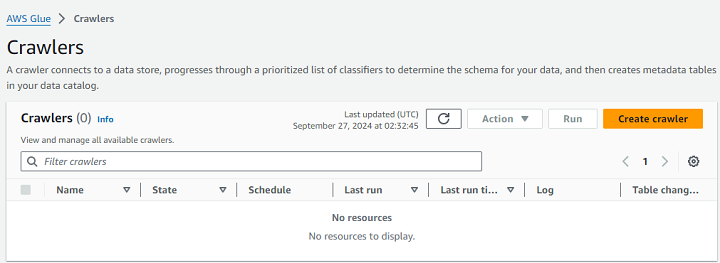
首先,轉到AWS Glue 控制檯並導航到爬蟲部分。接下來,單擊建立爬蟲按鈕。
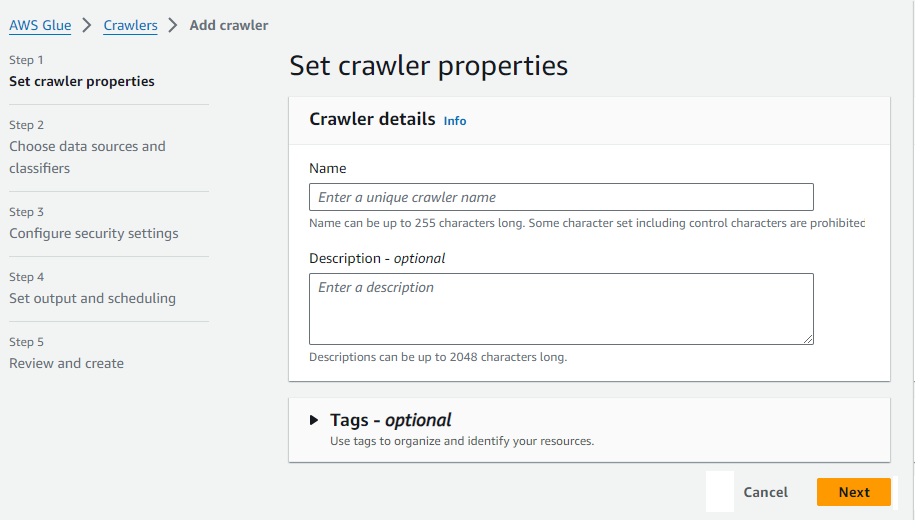
現在,輸入爬蟲的名稱(例如,my-data-crawler)。
您還需要定義資料來源。這可以是 Amazon S3、DynamoDB 或任何儲存您資料的受支援資料來源。
接下來,在配置安全設定部分,設定允許 AWS Glue 訪問您的資料的IAM 角色。然後,指定您之前建立的目標資料庫。爬蟲將在其中儲存其發現的元資料。
您可以將爬蟲安排為按需執行或定期執行以保持元資料最新。最後,檢視您的設定並單擊完成。
步驟 3:執行爬蟲
設定爬蟲後,首先返回 Glue 控制檯的“爬蟲”部分並選擇您新建立的爬蟲。
接下來,單擊執行爬蟲以啟動該過程。爬蟲完成後,它將使用它發現的每個資料集的表和元資料填充 Glue 資料目錄。