- Avro 基礎
- Avro - 首頁
- Avro - 概述
- Avro - 序列化
- Avro - 環境設定
- Avro 模式 & API
- Avro - 模式
- Avro - 參考 API
- 透過生成類使用 Avro
- 透過生成類進行序列化
- 透過生成類進行反序列化
- 使用解析器庫使用 Avro
- 使用解析器進行序列化
- 使用解析器進行反序列化
- Avro 有用資源
- Avro - 快速指南
- Avro - 有用資源
- Avro - 討論
Avro - 序列化
資料序列化有兩個目標:
用於持久儲存
透過網路傳輸資料
什麼是序列化?
序列化是將資料結構或物件狀態轉換為二進位制或文字形式以透過網路傳輸資料或儲存在某些持久儲存中的過程。一旦資料透過網路傳輸或從持久儲存中檢索,就需要再次反序列化。序列化稱為 **封送處理**,反序列化稱為 **解封送處理**。
Java 中的序列化
Java 提供了一種稱為 **物件序列化** 的機制,其中物件可以表示為位元組序列,其中包括物件的資料以及有關物件型別和儲存在物件中的資料型別的資訊。
將序列化後的物件寫入檔案後,可以從檔案中讀取並反序列化。也就是說,表示物件及其資料的資訊和位元組可用於在記憶體中重新建立物件。
**ObjectInputStream** 和 **ObjectOutputStream** 類分別用於在 Java 中序列化和反序列化物件。
Hadoop 中的序列化
通常在像 Hadoop 這樣的分散式系統中,序列化概念用於 **程序間通訊** 和 **持久儲存**。
程序間通訊
為了建立連線在網路中的節點之間的程序間通訊,使用了 RPC 技術。
RPC 使用內部序列化將訊息轉換為二進位制格式,然後再透過網路傳送到遠端節點。在另一端,遠端系統將二進位制流反序列化為原始訊息。
RPC 序列化格式需要如下所示:
**緊湊** - 為了最大限度地利用網路頻寬,這是資料中心中最稀缺的資源。
**快速** - 由於節點之間的通訊在分散式系統中至關重要,因此序列化和反序列化過程應該很快,產生較少的開銷。
**可擴充套件** - 協議會隨著時間的推移而改變以滿足新的需求,因此應該能夠以受控的方式輕鬆地為客戶端和伺服器發展協議。
**互操作性** - 訊息格式應支援以不同語言編寫的節點。
持久儲存
持久儲存是一種數字儲存設施,不會因電源中斷而丟失資料。檔案、資料夾、資料庫是持久儲存的示例。
Writable 介面
這是 Hadoop 中提供序列化和反序列化方法的介面。下表描述了這些方法:
| 序號 | 方法和描述 |
|---|---|
| 1 | void readFields(DataInput in) 此方法用於反序列化給定物件欄位。 |
| 2 | void write(DataOutput out) 此方法用於序列化給定物件欄位。 |
Writable Comparable 介面
它是 **Writable** 和 **Comparable** 介面的組合。此介面繼承了 Hadoop 的 **Writable** 介面以及 Java 的 **Comparable** 介面。因此,它提供了資料序列化、反序列化和比較的方法。
| 序號 | 方法和描述 |
|---|---|
| 1 | int compareTo(class obj) 此方法將當前物件與給定物件 obj 進行比較。 |
除了這些類之外,Hadoop 還支援許多實現 WritableComparable 介面的包裝類。每個類都包裝了一個 Java 基本型別。Hadoop 序列化的類層次結構如下所示:
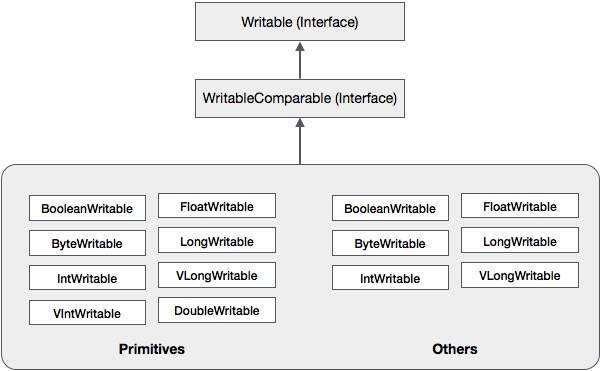
這些類可用於序列化 Hadoop 中各種型別的資料。例如,讓我們考慮一下 **IntWritable** 類。讓我們看看如何使用此類在 Hadoop 中序列化和反序列化資料。
IntWritable 類
此類實現了 **Writable、Comparable** 和 **WritableComparable** 介面。它在其內部包裝了一個整數資料型別。此類提供了用於序列化和反序列化整數型別資料的方法。
建構函式
| 序號 | 摘要 |
|---|---|
| 1 | IntWritable() |
| 2 | IntWritable( int value) |
方法
| 序號 | 摘要 |
|---|---|
| 1 | int get() 使用此方法,您可以獲取當前物件中存在的整數值。 |
| 2 | void readFields(DataInput in) 此方法用於反序列化給定 **DataInput** 物件中的資料。 |
| 3 | void set(int value) 此方法用於設定當前 **IntWritable** 物件的值。 |
| 4 | void write(DataOutput out) 此方法用於將當前物件中的資料序列化到給定的 **DataOutput** 物件。 |
在 Hadoop 中序列化資料
下面討論了序列化整數型別資料的過程。
透過在其內部包裝一個整數值來例項化 **IntWritable** 類。
例項化 **ByteArrayOutputStream** 類。
例項化 **DataOutputStream** 類並將 **ByteArrayOutputStream** 類的物件傳遞給它。
使用 **write()** 方法序列化 IntWritable 物件中的整數值。此方法需要一個 DataOutputStream 類的物件。
序列化後的資料將儲存在作為引數傳遞給 **DataOutputStream** 類(在例項化時)的位元組陣列物件中。將物件中的資料轉換為位元組陣列。
示例
以下示例演示瞭如何在 Hadoop 中序列化整數型別的資料:
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
public class Serialization {
public byte[] serialize() throws IOException{
//Instantiating the IntWritable object
IntWritable intwritable = new IntWritable(12);
//Instantiating ByteArrayOutputStream object
ByteArrayOutputStream byteoutputStream = new ByteArrayOutputStream();
//Instantiating DataOutputStream object
DataOutputStream dataOutputStream = new
DataOutputStream(byteoutputStream);
//Serializing the data
intwritable.write(dataOutputStream);
//storing the serialized object in bytearray
byte[] byteArray = byteoutputStream.toByteArray();
//Closing the OutputStream
dataOutputStream.close();
return(byteArray);
}
public static void main(String args[]) throws IOException{
Serialization serialization= new Serialization();
serialization.serialize();
System.out.println();
}
}
在 Hadoop 中反序列化資料
下面討論了反序列化整數型別資料的過程:
透過在其內部包裝一個整數值來例項化 **IntWritable** 類。
例項化 **ByteArrayOutputStream** 類。
例項化 **DataOutputStream** 類並將 **ByteArrayOutputStream** 類的物件傳遞給它。
使用 IntWritable 類的 **readFields()** 方法反序列化 **DataInputStream** 物件中的資料。
反序列化的資料將儲存在 IntWritable 類的物件中。您可以使用此類的 **get()** 方法檢索此資料。
示例
以下示例演示瞭如何在 Hadoop 中反序列化整數型別的資料:
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import org.apache.hadoop.io.IntWritable;
public class Deserialization {
public void deserialize(byte[]byteArray) throws Exception{
//Instantiating the IntWritable class
IntWritable intwritable =new IntWritable();
//Instantiating ByteArrayInputStream object
ByteArrayInputStream InputStream = new ByteArrayInputStream(byteArray);
//Instantiating DataInputStream object
DataInputStream datainputstream=new DataInputStream(InputStream);
//deserializing the data in DataInputStream
intwritable.readFields(datainputstream);
//printing the serialized data
System.out.println((intwritable).get());
}
public static void main(String args[]) throws Exception {
Deserialization dese = new Deserialization();
dese.deserialize(new Serialization().serialize());
}
}
Hadoop 相對於 Java 序列化的優勢
Hadoop 基於 Writable 的序列化能夠透過重用 Writable 物件來減少物件建立開銷,這在 Java 的原生序列化框架中是不可能的。
Hadoop 序列化的缺點
要序列化 Hadoop 資料,有兩種方法:
您可以使用 Hadoop 原生庫提供的 **Writable** 類。
您還可以使用 **Sequence 檔案**,這些檔案以二進位制格式儲存資料。
這兩種機制的主要缺點是 **Writable** 和 **Sequence 檔案** 只有 Java API,並且不能用任何其他語言編寫或讀取。
因此,使用上述兩種機制在 Hadoop 中建立的任何檔案都無法被任何其他第三方語言讀取,這使得 Hadoop 成為一個有限的盒子。為了解決這個缺點,Doug Cutting 建立了 **Avro**,這是一種 **與語言無關的資料結構**。