- Avro 基礎
- Avro - 首頁
- Avro - 概述
- Avro - 序列化
- Avro - 環境設定
- Avro Schema & API
- Avro - Schema
- Avro - 參考 API
- 透過生成類使用 Avro
- 透過生成類進行序列化
- 透過生成類進行反序列化
- 使用解析器庫使用 Avro
- 使用解析器進行序列化
- 使用解析器進行反序列化
- Avro 有用資源
- Avro 快速指南
- Avro - 有用資源
- Avro - 討論
Avro 快速指南
Avro - 概述
為了在網路上傳輸資料或將其持久儲存,您需要序列化資料。在 Java 和 Hadoop 提供的序列化 API 之前,我們有一個特殊的實用程式,稱為Avro,這是一種基於模式的序列化技術。
本教程將教您如何使用 Avro 序列化和反序列化資料。Avro 為各種程式語言提供了庫。在本教程中,我們將使用 Java 庫演示示例。
什麼是 Avro?
Apache Avro 是一種與語言無關的資料序列化系統。它由 Hadoop 之父 Doug Cutting 開發。由於 Hadoop 可寫類缺乏語言可移植性,因此 Avro 變得非常有用,因為它處理可以由多種語言處理的資料格式。Avro 是在 Hadoop 中序列化資料的首選工具。
Avro 具有基於模式的系統。與語言無關的模式與其讀寫操作相關聯。Avro 序列化具有內建模式的資料。Avro 將資料序列化為緊湊的二進位制格式,任何應用程式都可以對其進行反序列化。
Avro 使用 JSON 格式宣告資料結構。目前,它支援 Java、C、C++、C#、Python 和 Ruby 等語言。
Avro Schema
Avro 嚴重依賴其Schema。它允許在沒有先驗 Schema 知識的情況下寫入所有資料。它序列化速度快,並且生成的序列化資料大小更小。Schema 與 Avro 資料一起儲存在檔案中,以便進一步處理。
在 RPC 中,客戶端和伺服器在連線期間交換 Schema。此交換有助於在同名欄位、缺少欄位、額外欄位等之間進行通訊。
Avro Schema 使用 JSON 定義,這簡化了在具有 JSON 庫的語言中的實現。
與 Avro 一樣,Hadoop 中還有其他序列化機制,例如順序檔案、協議緩衝區和Thrift。
與 Thrift 和 Protocol Buffers 的比較
Thrift 和Protocol Buffers 是 Avro 最有競爭力的庫。Avro 在以下方面與這些框架不同:
Avro 根據需要支援動態型別和靜態型別。Protocol Buffers 和 Thrift 使用介面定義語言 (IDL) 來指定 Schema 及其型別。這些 IDL 用於生成序列化和反序列化的程式碼。
Avro 內置於 Hadoop 生態系統中。Thrift 和 Protocol Buffers 未內置於 Hadoop 生態系統中。
與 Thrift 和 Protocol Buffer 不同,Avro 的 Schema 定義使用 JSON,而不是任何專有的 IDL。
| 屬性 | Avro | Thrift & Protocol Buffer |
|---|---|---|
| 動態 Schema | 是 | 否 |
| 內置於 Hadoop | 是 | 否 |
| Schema 使用 JSON | 是 | 否 |
| 無需編譯 | 是 | 否 |
| 無需宣告 ID | 是 | 否 |
| 前沿技術 | 是 | 否 |
Avro 的特性
下面列出了一些 Avro 的主要特性:
Avro 是一種與語言無關的資料序列化系統。
它可以被多種語言處理(目前包括 C、C++、C#、Java、Python 和 Ruby)。
Avro 建立二進位制結構化格式,該格式既可壓縮又可分割。因此,它可以有效地用作 Hadoop MapReduce 作業的輸入。
Avro 提供豐富的 資料結構。例如,您可以建立一個包含陣列、列舉型別和子記錄的記錄。這些資料型別可以在任何語言中建立,可以在 Hadoop 中處理,並且結果可以饋送到第三種語言。
Avro Schema 使用JSON 定義,這便於在已具有 JSON 庫的語言中實現。
Avro 建立一個名為Avro 資料檔案的自描述檔案,其中它將資料及其 Schema 儲存在元資料部分。
Avro 也用於遠端過程呼叫 (RPC)。在 RPC 期間,客戶端和伺服器在連線握手期間交換 Schema。
Avro 的一般工作原理
要使用 Avro,您需要遵循以下工作流程:
步驟 1 - 建立 Schema。在這裡,您需要根據您的資料設計 Avro Schema。
步驟 2 - 將 Schema 讀取到您的程式中。這可以透過兩種方式完成:
透過生成與 Schema 對應的類 - 使用 Avro 編譯 Schema。這將生成與 Schema 對應的類檔案
透過使用解析器庫 - 您可以使用解析器庫直接讀取 Schema。
步驟 3 - 使用 Avro 提供的序列化 API 序列化資料,該 API 位於包 org.apache.avro.specific 中。
步驟 4 - 使用 Avro 提供的反序列化 API 反序列化資料,該 API 位於包 org.apache.avro.specific 中。
Avro - 序列化
資料序列化有兩個目的:
用於持久儲存
在網路上傳輸資料
什麼是序列化?
序列化是將資料結構或物件狀態轉換為二進位制或文字形式以在網路上傳輸資料或儲存在某些持久儲存中的過程。一旦資料透過網路傳輸或從持久儲存中檢索,就需要再次對其進行反序列化。序列化稱為封送,反序列化稱為解封送。
Java 中的序列化
Java 提供了一種稱為物件序列化的機制,其中物件可以表示為位元組序列,其中包括物件的資料以及有關物件型別和儲存在物件中的資料型別的資訊。
將序列化後的物件寫入檔案後,可以從檔案中讀取並反序列化。也就是說,表示物件及其資料型別資訊和位元組可用於在記憶體中重新建立物件。
ObjectInputStream 和ObjectOutputStream 類分別用於在 Java 中序列化和反序列化物件。
Hadoop 中的序列化
通常在像 Hadoop 這樣的分散式系統中,序列化的概念用於程序間通訊和持久儲存。
程序間通訊
為了建立連線到網路中的節點之間的程序間通訊,使用了 RPC 技術。
RPC 使用內部序列化在將訊息傳送到遠端節點之前將其轉換為二進位制格式。在另一端,遠端系統將二進位制流反序列化為原始訊息。
RPC 序列化格式需要如下所示:
緊湊 - 以最佳方式利用網路頻寬,這是資料中心中最稀缺的資源。
快速 - 由於節點之間的通訊在分散式系統中至關重要,因此序列化和反序列化過程應快速,產生較少的開銷。
可擴充套件 - 協議會隨著時間的推移而發生變化以滿足新的需求,因此應該能夠以受控的方式輕鬆地發展客戶端和伺服器的協議。
互操作性 - 訊息格式應支援用不同語言編寫的節點。
持久儲存
持久儲存是一種數字儲存設施,不會因電源供應中斷而丟失資料。檔案、資料夾、資料庫是持久儲存的示例。
Writable 介面
這是 Hadoop 中提供序列化和反序列化方法的介面。下表描述了這些方法:
| 序號 | 方法和描述 |
|---|---|
| 1 | void readFields(DataInput in) 此方法用於反序列化給定物件的欄位。 |
| 2 | void write(DataOutput out) 此方法用於序列化給定物件的欄位。 |
Writable Comparable 介面
它是Writable 和Comparable 介面的組合。此介面繼承了 Hadoop 的Writable 介面以及 Java 的Comparable 介面。因此,它提供了資料序列化、反序列化和比較的方法。
| 序號 | 方法和描述 |
|---|---|
| 1 | int compareTo(class obj) 此方法將當前物件與給定物件 obj 進行比較。 |
除了這些類之外,Hadoop 還支援許多實現 WritableComparable 介面的包裝類。每個類都包裝了一個 Java 基本型別。Hadoop 序列化的類層次結構如下所示:
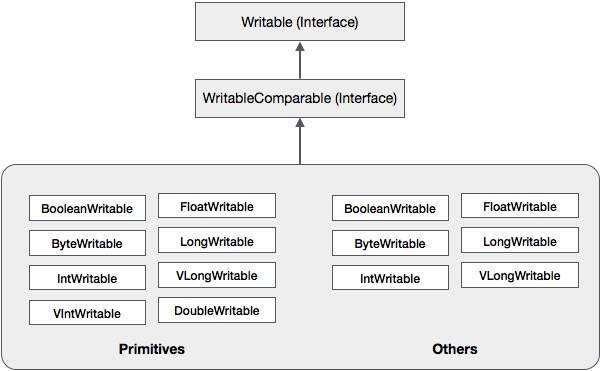
這些類可用於在 Hadoop 中序列化各種型別的資料。例如,讓我們考慮IntWritable 類。讓我們看看如何使用此類在 Hadoop 中序列化和反序列化資料。
IntWritable 類
此類實現了Writable、Comparable 和WritableComparable 介面。它在其內部包裝了一個整數資料型別。此類提供用於序列化和反序列化整數型別資料的方法。
建構函式
| 序號 | 摘要 |
|---|---|
| 1 | IntWritable() |
| 2 | IntWritable( int value) |
方法
| 序號 | 摘要 |
|---|---|
| 1 | int get() 使用此方法,您可以獲取當前物件中存在的整數值。 |
| 2 | void readFields(DataInput in) 此方法用於反序列化給定DataInput 物件中的資料。 |
| 3 | void set(int value) 此方法用於設定當前IntWritable 物件的值。 |
| 4 | void write(DataOutput out) 此方法用於將當前物件中的資料序列化到給定的DataOutput 物件。 |
在 Hadoop 中序列化資料
下面討論了序列化整數型別資料的過程。
透過在其內部包裝一個整數值來例項化IntWritable 類。
例項化ByteArrayOutputStream 類。
例項化DataOutputStream 類並將ByteArrayOutputStream 類的物件傳遞給它。
使用write() 方法序列化 IntWritable 物件中的整數值。此方法需要一個 DataOutputStream 類的物件。
序列化後的資料將儲存在作為引數傳遞給DataOutputStream 類(在例項化時)的位元組陣列物件中。將物件中的資料轉換為位元組陣列。
示例
以下示例顯示瞭如何在 Hadoop 中序列化整數型別的資料:
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
public class Serialization {
public byte[] serialize() throws IOException{
//Instantiating the IntWritable object
IntWritable intwritable = new IntWritable(12);
//Instantiating ByteArrayOutputStream object
ByteArrayOutputStream byteoutputStream = new ByteArrayOutputStream();
//Instantiating DataOutputStream object
DataOutputStream dataOutputStream = new
DataOutputStream(byteoutputStream);
//Serializing the data
intwritable.write(dataOutputStream);
//storing the serialized object in bytearray
byte[] byteArray = byteoutputStream.toByteArray();
//Closing the OutputStream
dataOutputStream.close();
return(byteArray);
}
public static void main(String args[]) throws IOException{
Serialization serialization= new Serialization();
serialization.serialize();
System.out.println();
}
}
在 Hadoop 中反序列化資料
下面討論了反序列化整數型別資料的過程:
透過在其內部包裝一個整數值來例項化IntWritable 類。
例項化ByteArrayOutputStream 類。
例項化DataOutputStream 類並將ByteArrayOutputStream 類的物件傳遞給它。
使用 IntWritable 類的readFields() 方法反序列化DataInputStream 物件中的資料。
反序列化後的資料將儲存在 IntWritable 類的物件中。您可以使用此類的get() 方法檢索此資料。
示例
以下示例顯示瞭如何在 Hadoop 中反序列化整數型別的資料:
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import org.apache.hadoop.io.IntWritable;
public class Deserialization {
public void deserialize(byte[]byteArray) throws Exception{
//Instantiating the IntWritable class
IntWritable intwritable =new IntWritable();
//Instantiating ByteArrayInputStream object
ByteArrayInputStream InputStream = new ByteArrayInputStream(byteArray);
//Instantiating DataInputStream object
DataInputStream datainputstream=new DataInputStream(InputStream);
//deserializing the data in DataInputStream
intwritable.readFields(datainputstream);
//printing the serialized data
System.out.println((intwritable).get());
}
public static void main(String args[]) throws Exception {
Deserialization dese = new Deserialization();
dese.deserialize(new Serialization().serialize());
}
}
Hadoop 相對於 Java 序列化的優勢
Hadoop 基於 Writable 的序列化能夠透過重用 Writable 物件來減少物件建立開銷,這在 Java 的原生序列化框架中是不可能的。
Hadoop 序列化的缺點
要序列化 Hadoop 資料,有兩種方法:
您可以使用 Hadoop 原生庫提供的Writable 類。
您還可以使用順序檔案,這些檔案以二進位制格式儲存資料。
這兩種機制的主要缺點是Writable 和順序檔案僅具有 Java API,並且無法用任何其他語言編寫或讀取。
因此,使用上述兩種機制在 Hadoop 中建立的任何檔案都無法被任何其他第三方語言讀取,這使得 Hadoop 成為一個有限的盒子。為了解決此缺點,Doug Cutting 建立了Avro,這是一種與語言無關的資料結構。
Avro - 環境設定
Apache 軟體基金會為 Avro 提供了各種版本。您可以從 Apache 映象下載所需的版本。讓我們看看如何設定環境以使用 Avro -
下載 Avro
要下載 Apache Avro,請執行以下操作 -
開啟網頁 Apache.org。您將看到 Apache Avro 的主頁,如下所示 -
點選 project → releases。您將獲得一個版本列表。
選擇最新版本,這將引導您到一個下載連結。
mirror.nexcess 是您可以找到 Avro 支援的所有不同語言庫列表的連結之一,如下所示 -
您可以選擇並下載任何提供的語言的庫。在本教程中,我們使用 Java。因此,下載 jar 檔案 avro-1.7.7.jar 和 avro-tools-1.7.7.jar。
使用 Eclipse 的 Avro
要在 Eclipse 環境中使用 Avro,您需要按照以下步驟操作 -
步驟 1. 開啟 Eclipse。
步驟 2. 建立一個專案。
步驟 3. 右鍵單擊專案名稱。您將獲得一個快捷選單。
步驟 4. 點選Build Path。它將引導您到另一個快捷選單。
步驟 5. 點選Configure Build Path... 您可以看到專案的屬性視窗,如下所示 -
步驟 6. 在庫選項卡下,點選ADD EXternal JARs... 按鈕。
步驟 7. 選擇您下載的 jar 檔案 avro-1.77.jar。
步驟 8. 點選OK。
使用 Maven 的 Avro
您也可以使用 Maven 將 Avro 庫引入您的專案。以下是 Avro 的 pom.xml 檔案。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=" http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>Test</groupId>
<artifactId>Test</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-tools</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.0-beta9</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.0-beta9</version>
</dependency>
</dependencies>
</project>
設定類路徑
要在 Linux 環境中使用 Avro,請下載以下 jar 檔案 -
- avro-1.77.jar
- avro-tools-1.77.jar
- log4j-api-2.0-beta9.jar
- log4j-core-2.0.beta9.jar。
將這些檔案複製到一個資料夾中,並在 ./bashrc 檔案中將類路徑設定為該資料夾,如下所示。
#class path for Avro export CLASSPATH=$CLASSPATH://home/Hadoop/Avro_Work/jars/*

Avro - Schema
Avro 作為一種基於模式的序列化實用程式,接受模式作為輸入。儘管有各種模式可用,但 Avro 遵循其自身的模式定義標準。這些模式描述以下詳細資訊 -
- 檔案型別(預設為記錄)
- 記錄的位置
- 記錄的名稱
- 記錄中的欄位及其對應的資料型別
使用這些模式,您可以使用更少的空間以二進位制格式儲存序列化值。這些值儲存時沒有任何元資料。
建立 Avro 模式
Avro 模式以 JavaScript 物件表示法 (JSON) 文件格式建立,這是一種輕量級的基於文字的資料交換格式。它可以透過以下幾種方式建立 -
- JSON 字串
- JSON 物件
- JSON 陣列
示例 - 下面的示例顯示了一個模式,該模式在名稱空間 Tutorialspoint 下定義了一個文件,名稱為 Employee,具有 name 和 age 欄位。
{
"type" : "record",
"namespace" : "Tutorialspoint",
"name" : "Employee",
"fields" : [
{ "name" : "Name" , "type" : "string" },
{ "name" : "Age" , "type" : "int" }
]
}
在此示例中,您可以觀察到每個記錄有四個欄位 -
type - 此欄位位於文件下以及名為 fields 的欄位下。
在文件的情況下,它顯示文件的型別,通常是記錄,因為有多個欄位。
當它是欄位時,type 描述資料型別。
namespace - 此欄位描述物件所在的名稱空間的名稱。
name - 此欄位位於文件下以及名為 fields 的欄位下。
在文件的情況下,它描述模式名稱。此模式名稱與名稱空間一起唯一標識儲存中的模式(Namespace.schema name)。在上面的示例中,模式的全名將是 Tutorialspoint.Employee。
在欄位的情況下,它描述欄位的名稱。
Avro 的基本資料型別
Avro 模式具有基本資料型別和複雜資料型別。下表描述了 Avro 的基本資料型別 -
| 資料型別 | 描述 |
|---|---|
| null | Null 是一種沒有值的型別。 |
| int | 32 位有符號整數。 |
| long | 64 位有符號整數。 |
| float | 單精度 (32 位) IEEE 754 浮點數。 |
| double | 雙精度 (64 位) IEEE 754 浮點數。 |
| bytes | 8 位無符號位元組序列。 |
| string | Unicode 字元序列。 |
Avro 的複雜資料型別
除了基本資料型別之外,Avro 還提供了六種複雜資料型別,即記錄、列舉、陣列、對映、聯合和固定。
記錄
Avro 中的記錄資料型別是多個屬性的集合。它支援以下屬性 -
name - 此欄位的值儲存記錄的名稱。
namespace - 此欄位的值儲存物件儲存的名稱空間的名稱。
type - 此屬性的值儲存文件(記錄)的型別或模式中欄位的資料型別。
fields - 此欄位儲存一個 JSON 陣列,其中包含模式中所有欄位的列表,每個欄位都具有 name 和 type 屬性。
示例
下面是記錄的示例。
{
" type " : "record",
" namespace " : "Tutorialspoint",
" name " : "Employee",
" fields " : [
{ "name" : " Name" , "type" : "string" },
{ "name" : "age" , "type" : "int" }
]
}
列舉
列舉是集合中專案的列表,Avro 列舉支援以下屬性 -
name - 此欄位的值儲存列舉的名稱。
namespace - 此欄位的值包含限定列舉名稱的字串。
symbols - 此欄位的值儲存列舉的符號,作為名稱陣列。
示例
下面是列舉的示例。
{
"type" : "enum",
"name" : "Numbers",
"namespace": "data",
"symbols" : [ "ONE", "TWO", "THREE", "FOUR" ]
}
陣列
此資料型別定義了一個數組欄位,該欄位具有單個屬性 items。此 items 屬性指定陣列中專案的型別。
示例
{ " type " : " array ", " items " : " int " }
對映
對映資料型別是鍵值對的陣列,它將資料組織為鍵值對。Avro 對映的鍵必須是字串。對映的值儲存對映內容的資料型別。
示例
{"type" : "map", "values" : "int"}
聯合
當欄位具有一個或多個數據型別時,使用聯合資料型別。它們表示為 JSON 陣列。例如,如果一個欄位可以是 int 或 null,則聯合表示為 ["int", "null"]。
示例
下面是使用聯合的示例文件 -
{
"type" : "record",
"namespace" : "tutorialspoint",
"name" : "empdetails ",
"fields" :
[
{ "name" : "experience", "type": ["int", "null"] }, { "name" : "age", "type": "int" }
]
}
固定
此資料型別用於宣告一個固定大小的欄位,該欄位可用於儲存二進位制資料。它具有欄位名稱和資料作為屬性。Name 儲存欄位的名稱,size 儲存欄位的大小。
示例
{ "type" : "fixed" , "name" : "bdata", "size" : 1048576}
Avro - 參考 API
在上一章中,我們描述了 Avro 的輸入型別,即 Avro 模式。在本章中,我們將解釋 Avro 模式序列化和反序列化中使用的類和方法。
SpecificDatumWriter 類
此類屬於包 org.apache.avro.specific。它實現了 DatumWriter 介面,該介面將 Java 物件轉換為記憶體中的序列化格式。
建構函式
| 序號 | 描述 |
|---|---|
| 1 | SpecificDatumWriter(Schema schema) |
方法
| 序號 | 描述 |
|---|---|
| 1 | SpecificData getSpecificData() 返回此寫入器使用的 SpecificData 實現。 |
SpecificDatumReader 類
此類屬於包 org.apache.avro.specific。它實現了 DatumReader 介面,該介面讀取模式的資料並確定記憶體中的資料表示。SpecificDatumReader 是支援生成的 Java 類的類。
建構函式
| 序號 | 描述 |
|---|---|
| 1 | SpecificDatumReader(Schema schema) 寫入器和讀取器的模式相同的構造。 |
方法
| 序號 | 描述 |
|---|---|
| 1 | SpecificData getSpecificData() 返回包含的 SpecificData。 |
| 2 | void setSchema(Schema actual) 此方法用於設定寫入器的模式。 |
DataFileWriter
為emp 類例項化DataFileWrite。此類將符合模式的資料的序列化記錄序列以及模式寫入檔案。
建構函式
| 序號 | 描述 |
|---|---|
| 1 | DataFileWriter(DatumWriter<D> dout) |
方法
| 序號 | 描述 |
|---|---|
| 1 | void append(D datum) 將資料追加到檔案。 |
| 2 | DataFileWriter<D> appendTo(File file) 此方法用於開啟一個追加到現有檔案的寫入器。 |
Data FileReader
此類提供對使用DataFileWriter寫入的檔案的隨機訪問。它繼承了類DataFileStream。
建構函式
| 序號 | 描述 |
|---|---|
| 1 | DataFileReader(File file, DatumReader<D> reader)) |
方法
| 序號 | 描述 |
|---|---|
| 1 | next() 讀取檔案中下一個資料。 |
| 2 | Boolean hasNext() 如果此檔案中還有更多條目,則返回 true。 |
Class Schema.parser
此類是 JSON 格式模式的解析器。它包含解析模式的方法。它屬於org.apache.avro包。
建構函式
| 序號 | 描述 |
|---|---|
| 1 | Schema.Parser() |
方法
| 序號 | 描述 |
|---|---|
| 1 | parse (File file) 解析給定file中提供的模式。 |
| 2 | parse (InputStream in) 解析給定InputStream中提供的模式。 |
| 3 | parse (String s) 解析給定String中提供的模式。 |
介面 GenricRecord
此介面提供透過名稱和索引訪問欄位的方法。
方法
| 序號 | 描述 |
|---|---|
| 1 | Object get(String key) 返回給定欄位的值。 |
| 2 | void put(String key, Object v) 設定給定名稱的欄位的值。 |
Class GenericData.Record
建構函式
| 序號 | 描述 |
|---|---|
| 1 | GenericData.Record(Schema schema) |
方法
| 序號 | 描述 |
|---|---|
| 1 | Object get(String key) 返回給定名稱的欄位的值。 |
| 2 | Schema getSchema() 返回此例項的模式。 |
| 3 | void put(int i, Object v) 設定給定模式中位置的欄位的值。 |
| 4 | void put(String key, Object value) 設定給定名稱的欄位的值。 |
AVRO - 透過生成類進行序列化
可以透過生成與模式對應的類或使用解析器庫將 Avro 模式讀入程式。本章介紹如何透過生成類並序列化資料來讀取模式。
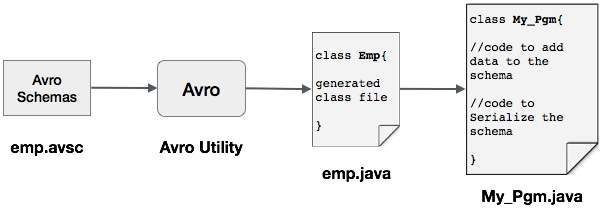
透過生成類進行序列化
要使用 Avro 序列化資料,請按照以下步驟操作 -
編寫 Avro 模式。
使用 Avro 實用程式編譯模式。您將獲得與該模式對應的 Java 程式碼。
使用資料填充模式。
使用 Avro 庫對其進行序列化。
定義模式
假設您想要一個具有以下詳細資訊的模式 -
| 欄位 | 名稱 | id | age | salary | address |
| 型別 | String | int | int | int | string |
建立 Avro 模式,如下所示。
將其儲存為emp.avsc。
{
"namespace": "tutorialspoint.com",
"type": "record",
"name": "emp",
"fields": [
{"name": "name", "type": "string"},
{"name": "id", "type": "int"},
{"name": "salary", "type": "int"},
{"name": "age", "type": "int"},
{"name": "address", "type": "string"}
]
}
編譯模式
建立 Avro 模式後,您需要使用 Avro 工具編譯建立的模式。avro-tools-1.7.7.jar 是包含工具的 jar 檔案。
編譯 Avro 模式的語法
java -jar <path/to/avro-tools-1.7.7.jar> compile schema <path/to/schema-file> <destination-folder>
在主資料夾中開啟終端。
建立一個新目錄以使用 Avro,如下所示 -
$ mkdir Avro_Work
在新建立的目錄中,建立三個子目錄 -
第一個名為schema,用於放置模式。
第二個名為with_code_gen,用於放置生成的程式碼。
第三個名為jars,用於放置 jar 檔案。
$ mkdir schema $ mkdir with_code_gen $ mkdir jars
以下螢幕截圖顯示了建立所有目錄後您的Avro_work資料夾應如何顯示。
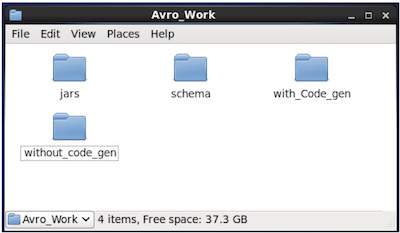
現在/home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar 是您下載 avro-tools-1.7.7.jar 檔案的目錄的路徑。
/home/Hadoop/Avro_work/schema/ 是儲存模式檔案 emp.avsc 的目錄的路徑。
/home/Hadoop/Avro_work/with_code_gen 是您希望將生成的類檔案儲存到的目錄。
現在編譯模式,如下所示 -
$ java -jar /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar compile schema /home/Hadoop/Avro_work/schema/emp.avsc /home/Hadoop/Avro/with_code_gen
編譯完成後,將在目標目錄中根據架構名稱空間建立一個包。在此包中,將建立具有架構名稱的 Java 原始碼。此生成的原始碼是給定架構的 Java 程式碼,可直接在應用程式中使用。
例如,在此示例中,建立了一個名為tutorialspoint的包/資料夾,其中包含另一個名為 com 的資料夾(因為名稱空間是 tutorialspoint.com),並且在其中,您可以看到生成的emp.java檔案。以下快照顯示了emp.java -
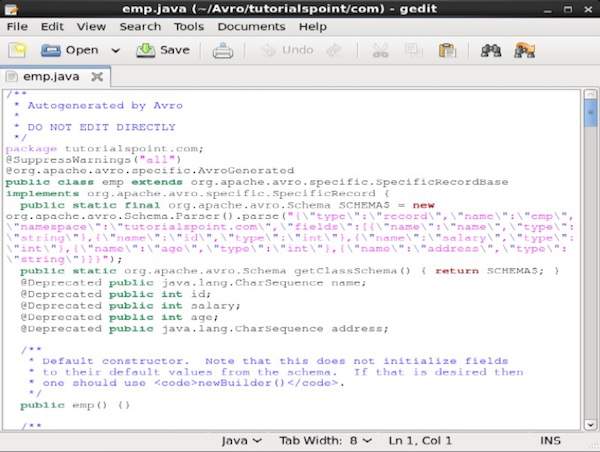
此類用於根據架構建立資料。
生成的類包含 -
- 預設建構函式和引數化建構函式,接受架構的所有變數。
- 架構中所有變數的 setter 和 getter 方法。
- 返回架構的 Get() 方法。
- 構建器方法。
建立和序列化資料
首先,將此專案中使用的生成的 java 檔案複製到當前目錄或從其所在位置匯入。
現在,我們可以編寫一個新的 Java 檔案並在生成的 emp 檔案中例項化類,以將員工資料新增到架構中。
讓我們看看使用 apache Avro 根據架構建立資料的過程。
步驟 1
例項化生成的 emp 類。
emp e1=new emp( );
步驟 2
使用 setter 方法插入第一個員工的資料。例如,我們建立了名為 Omar 的員工的詳細資訊。
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);
類似地,使用 setter 方法填寫所有員工詳細資訊。
步驟 3
使用 SpecificDatumWriter 類建立 DatumWriter 介面的物件。這將 Java 物件轉換為記憶體中的序列化格式。以下示例為 emp 類例項化 SpecificDatumWriter 類物件。
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
步驟 4
為 emp 類例項化 DataFileWriter。此類將符合架構的一系列序列化資料記錄(以及架構本身)寫入檔案。此類需要 DatumWriter 物件作為建構函式的引數。
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);
步驟 5
使用 create() 方法開啟一個新檔案以儲存與給定架構匹配的資料。此方法需要架構和儲存資料的檔案路徑作為引數。
在以下示例中,使用 getSchema() 方法傳遞架構,並將資料檔案儲存在路徑 /home/Hadoop/Avro/serialized_file/emp.avro 中。
empFileWriter.create(e1.getSchema(),new File("/home/Hadoop/Avro/serialized_file/emp.avro"));
步驟 6
使用 append() 方法將所有建立的記錄新增到檔案中,如下所示 -
empFileWriter.append(e1); empFileWriter.append(e2); empFileWriter.append(e3);
示例 – 透過生成類進行序列化
以下完整程式演示瞭如何使用 Apache Avro 將資料序列化到檔案中 -
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.specific.SpecificDatumWriter;
public class Serialize {
public static void main(String args[]) throws IOException{
//Instantiating generated emp class
emp e1=new emp();
//Creating values according the schema
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);
emp e2=new emp();
e2.setName("ram");
e2.setAge(30);
e2.setSalary(40000);
e2.setAddress("Hyderabad");
e2.setId(002);
emp e3=new emp();
e3.setName("robbin");
e3.setAge(25);
e3.setSalary(35000);
e3.setAddress("Hyderabad");
e3.setId(003);
//Instantiate DatumWriter class
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);
empFileWriter.create(e1.getSchema(), new File("/home/Hadoop/Avro_Work/with_code_gen/emp.avro"));
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);
empFileWriter.close();
System.out.println("data successfully serialized");
}
}
瀏覽放置生成程式碼的目錄。在本例中,位於home/Hadoop/Avro_work/with_code_gen。
在終端中 -
$ cd home/Hadoop/Avro_work/with_code_gen/
在 GUI 中 -
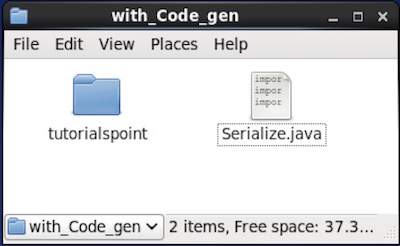
現在將上述程式複製並儲存到名為 Serialize.java 的檔案中
編譯並執行它,如下所示 -
$ javac Serialize.java $ java Serialize
輸出
data successfully serialized
如果您驗證程式中給定的路徑,您會發現生成的序列化檔案,如下所示。
AVRO - 透過生成類進行反序列化
如前所述,可以透過生成與架構對應的類或使用解析器庫將 Avro 架構讀入程式。本章介紹如何透過生成類讀取架構並使用 Avro反序列化資料。
透過生成類進行反序列化
序列化資料儲存在檔案 emp.avro 中。您可以使用 Avro 反序列化並讀取它。
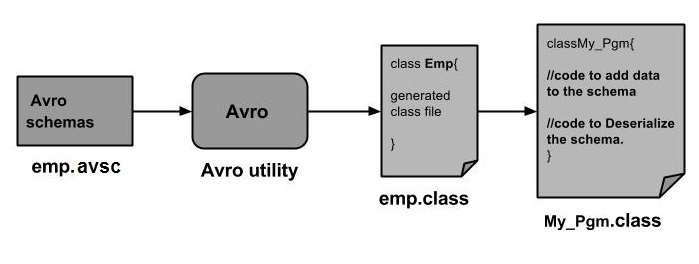
請按照以下步驟從檔案中反序列化序列化資料。
步驟 1
使用 SpecificDatumReader 類建立 DatumReader 介面的物件。
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);
步驟 2
為 emp 類例項化 DataFileReader。此類從檔案中讀取序列化資料。它需要 Dataumeader 物件和存在序列化資料的檔案的路徑作為建構函式的引數。
DataFileReader<emp> dataFileReader = new DataFileReader(new File("/path/to/emp.avro"), empDatumReader);
步驟 3
使用 DataFileReader 的方法列印反序列化的資料。
如果 Reader 中有任何元素,hasNext() 方法將返回一個布林值。
DataFileReader 的 next() 方法返回 Reader 中的資料。
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}
示例 – 透過生成類進行反序列化
以下完整程式演示瞭如何使用 Avro 反序列化檔案中的資料。
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileReader;
import org.apache.avro.io.DatumReader;
import org.apache.avro.specific.SpecificDatumReader;
public class Deserialize {
public static void main(String args[]) throws IOException{
//DeSerializing the objects
DatumReader<emp> empDatumReader = new SpecificDatumReader<emp>(emp.class);
//Instantiating DataFileReader
DataFileReader<emp> dataFileReader = new DataFileReader<emp>(new
File("/home/Hadoop/Avro_Work/with_code_genfile/emp.avro"), empDatumReader);
emp em=null;
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}
}
}
瀏覽放置生成程式碼的目錄。在本例中,位於home/Hadoop/Avro_work/with_code_gen。
$ cd home/Hadoop/Avro_work/with_code_gen/
現在,將上述程式複製並儲存到名為 DeSerialize.java 的檔案中。編譯並執行它,如下所示 -
$ javac Deserialize.java $ java Deserialize
輸出
{"name": "omar", "id": 1, "salary": 30000, "age": 21, "address": "Hyderabad"}
{"name": "ram", "id": 2, "salary": 40000, "age": 30, "address": "Hyderabad"}
{"name": "robbin", "id": 3, "salary": 35000, "age": 25, "address": "Hyderabad"}
AVRO - 使用解析器進行序列化
可以透過生成與架構對應的類或使用解析器庫將 Avro 架構讀入程式。在 Avro 中,資料始終與其對應的架構一起儲存。因此,我們始終可以在沒有程式碼生成的情況下讀取架構。
本章介紹如何使用解析器庫讀取架構並使用 Avro序列化資料。

使用解析器庫進行序列化
要序列化資料,我們需要讀取架構,根據架構建立資料,並使用 Avro API 序列化架構。以下過程在不生成任何程式碼的情況下序列化資料 -
步驟 1
首先,從檔案中讀取架構。為此,請使用 Schema.Parser 類。此類提供方法以不同格式解析架構。
透過傳遞儲存架構的檔案路徑來例項化 Schema.Parser 類。
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));
步驟 2
透過例項化 GenericData.Record 類來建立 GenericRecord 介面的物件,如下所示。將上面建立的架構物件傳遞給它的建構函式。
GenericRecord e1 = new GenericData.Record(schema);
步驟 3
使用 GenericData 類的 put() 方法在架構中插入值。
e1.put("name", "ramu");
e1.put("id", 001);
e1.put("salary",30000);
e1.put("age", 25);
e1.put("address", "chennai");
步驟 4
使用 SpecificDatumWriter 類建立 DatumWriter 介面的物件。它將 Java 物件轉換為記憶體中的序列化格式。以下示例為 emp 類例項化 SpecificDatumWriter 類物件 -
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
步驟 5
為 emp 類例項化 DataFileWriter。此類將符合架構的一系列序列化資料記錄(以及架構本身)寫入檔案。此類需要 DatumWriter 物件作為建構函式的引數。
DataFileWriter<emp> dataFileWriter = new DataFileWriter<emp>(empDatumWriter);
步驟 6
使用 create() 方法開啟一個新檔案以儲存與給定架構匹配的資料。此方法需要架構和儲存資料的檔案路徑作為引數。
在下面給出的示例中,使用 getSchema() 方法傳遞架構,並將資料檔案儲存在路徑
/home/Hadoop/Avro/serialized_file/emp.avro 中。
empFileWriter.create(e1.getSchema(), new
File("/home/Hadoop/Avro/serialized_file/emp.avro"));
步驟 7
使用 append( ) 方法將所有建立的記錄新增到檔案中,如下所示。
empFileWriter.append(e1); empFileWriter.append(e2); empFileWriter.append(e3);
示例 – 使用解析器進行序列化
以下完整程式演示瞭如何使用解析器序列化資料 -
import java.io.File;
import java.io.IOException;
import org.apache.avro.Schema;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericDatumWriter;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.io.DatumWriter;
public class Seriali {
public static void main(String args[]) throws IOException{
//Instantiating the Schema.Parser class.
Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc"));
//Instantiating the GenericRecord class.
GenericRecord e1 = new GenericData.Record(schema);
//Insert data according to schema
e1.put("name", "ramu");
e1.put("id", 001);
e1.put("salary",30000);
e1.put("age", 25);
e1.put("address", "chenni");
GenericRecord e2 = new GenericData.Record(schema);
e2.put("name", "rahman");
e2.put("id", 002);
e2.put("salary", 35000);
e2.put("age", 30);
e2.put("address", "Delhi");
DatumWriter<GenericRecord> datumWriter = new GenericDatumWriter<GenericRecord>(schema);
DataFileWriter<GenericRecord> dataFileWriter = new DataFileWriter<GenericRecord>(datumWriter);
dataFileWriter.create(schema, new File("/home/Hadoop/Avro_work/without_code_gen/mydata.txt"));
dataFileWriter.append(e1);
dataFileWriter.append(e2);
dataFileWriter.close();
System.out.println(“data successfully serialized”);
}
}
瀏覽放置生成程式碼的目錄。在本例中,位於home/Hadoop/Avro_work/without_code_gen。
$ cd home/Hadoop/Avro_work/without_code_gen/

現在將上述程式複製並儲存到名為 Serialize.java 的檔案中。編譯並執行它,如下所示 -
$ javac Serialize.java $ java Serialize
輸出
data successfully serialized
如果您驗證程式中給定的路徑,您會發現生成的序列化檔案,如下所示。
AVRO - 使用解析器進行反序列化
如前所述,可以透過生成與架構對應的類或使用解析器庫將 Avro 架構讀入程式。在 Avro 中,資料始終與其對應的架構一起儲存。因此,我們始終可以在沒有程式碼生成的情況下讀取序列化項。
本章介紹如何使用解析器庫讀取架構並使用 Avro反序列化資料。
使用解析器庫進行反序列化
序列化資料儲存在檔案 mydata.txt 中。您可以使用 Avro 反序列化並讀取它。
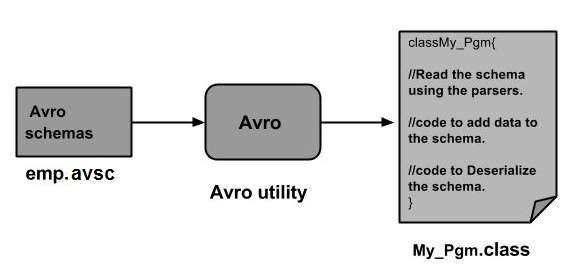
請按照以下步驟從檔案中反序列化序列化資料。
步驟 1
首先,從檔案中讀取架構。為此,請使用 Schema.Parser 類。此類提供方法以不同格式解析架構。
透過傳遞儲存架構的檔案路徑來例項化 Schema.Parser 類。
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));
步驟 2
使用 SpecificDatumReader 類建立 DatumReader 介面的物件。
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);
步驟 3
例項化 DataFileReader 類。此類從檔案中讀取序列化資料。它需要 DatumReader 物件和存在序列化資料的檔案的路徑作為建構函式的引數。
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("/path/to/mydata.txt"), datumReader);
步驟 4
使用 DataFileReader 的方法列印反序列化的資料。
如果 Reader 中有任何元素,hasNext() 方法將返回一個布林值。
DataFileReader 的 next() 方法返回 Reader 中的資料。
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}
示例 – 使用解析器庫進行反序列化
以下完整程式演示瞭如何使用解析器庫反序列化序列化資料 -
public class Deserialize {
public static void main(String args[]) throws Exception{
//Instantiating the Schema.Parser class.
Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc"));
DatumReader<GenericRecord> datumReader = new GenericDatumReader<GenericRecord>(schema);
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("/home/Hadoop/Avro_Work/without_code_gen/mydata.txt"), datumReader);
GenericRecord emp = null;
while (dataFileReader.hasNext()) {
emp = dataFileReader.next(emp);
System.out.println(emp);
}
System.out.println("hello");
}
}
瀏覽放置生成程式碼的目錄。在本例中,位於home/Hadoop/Avro_work/without_code_gen。
$ cd home/Hadoop/Avro_work/without_code_gen/
現在將上述程式複製並儲存到名為 DeSerialize.java 的檔案中。編譯並執行它,如下所示 -
$ javac Deserialize.java $ java Deserialize
輸出
{"name": "ramu", "id": 1, "salary": 30000, "age": 25, "address": "chennai"}
{"name": "rahman", "id": 2, "salary": 35000, "age": 30, "address": "Delhi"}