- Apache Pig 教程
- Apache Pig - 首頁
- Apache Pig 簡介
- Apache Pig - 概述
- Apache Pig - 架構
- Apache Pig 環境
- Apache Pig - 安裝
- Apache Pig - 執行
- Apache Pig - Grunt Shell
- Pig Latin
- Pig Latin - 基礎
- 載入 & 儲存運算子
- Apache Pig - 讀取資料
- Apache Pig - 儲存資料
- 診斷運算子
- Apache Pig - 診斷運算子
- Apache Pig - Describe 運算子
- Apache Pig - Explain 運算子
- Apache Pig - Illustrate 運算子
- 分組 & 連線
- Apache Pig - Group 運算子
- Apache Pig - Cogroup 運算子
- Apache Pig - Join 運算子
- Apache Pig - Cross 運算子
- Pig Latin 內建函式
- Apache Pig - Eval 函式
- 載入 & 儲存函式
- Apache Pig - Bag & Tuple 函式
- Apache Pig - 字串函式
- Apache Pig - 日期時間函式
- Apache Pig - 數學函式
- Apache Pig 有用資源
- Apache Pig - 快速指南
- Apache Pig - 有用資源
- Apache Pig - 討論
Apache Pig - 執行
在上一章中,我們解釋瞭如何安裝 Apache Pig。在本章中,我們將討論如何執行 Apache Pig。
Apache Pig 執行模式
您可以以兩種模式執行 Apache Pig,即 **本地模式** 和 **HDFS 模式**。
本地模式
在這種模式下,所有檔案都安裝並從您的本地主機和本地檔案系統執行。不需要 Hadoop 或 HDFS。此模式通常用於測試目的。
MapReduce 模式
MapReduce 模式是指我們使用 Apache Pig 載入或處理 Hadoop 檔案系統 (HDFS) 中存在的資料。在此模式下,每當我們執行 Pig Latin 語句來處理資料時,後臺都會呼叫一個 MapReduce 作業來對 HDFS 中存在的資料執行特定操作。
Apache Pig 執行機制
Apache Pig 指令碼可以透過三種方式執行,即互動模式、批處理模式和嵌入模式。
**互動模式** (Grunt shell) - 您可以使用 Grunt shell 以互動模式執行 Apache Pig。在此 shell 中,您可以輸入 Pig Latin 語句並獲取輸出(使用 Dump 運算子)。
**批處理模式** (指令碼) - 您可以透過將 Pig Latin 指令碼寫入副檔名為 **.pig** 的單個檔案中來以批處理模式執行 Apache Pig。
**嵌入模式** (UDF) - Apache Pig 提供了在 Java 等程式語言中定義我們自己的函式(**U**ser **D**efined **F**unctions)並在指令碼中使用它們的機制。
呼叫 Grunt Shell
您可以使用 **-x** 選項以所需的模式(本地/MapReduce)呼叫 Grunt shell,如下所示。
| 本地模式 | MapReduce 模式 |
|---|---|
命令 - $ ./pig –x local |
命令 - $ ./pig -x mapreduce |
**輸出** - 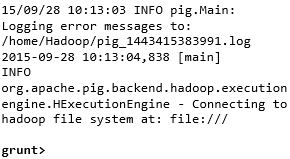 |
**輸出** - 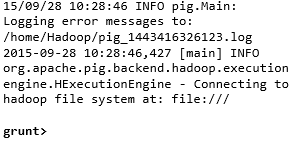 |
這兩個命令中的任何一個都會為您提供如下所示的 Grunt shell 提示符。
grunt>
您可以使用 **‘ctrl + d’** 退出 Grunt shell。
呼叫 Grunt shell 後,您可以透過直接在其中輸入 Pig Latin 語句來執行 Pig 指令碼。
grunt> customers = LOAD 'customers.txt' USING PigStorage(',');
以批處理模式執行 Apache Pig
您可以將整個 Pig Latin 指令碼寫入一個檔案中,並使用 **-x 命令** 執行它。假設我們在一個名為 **sample_script.pig** 的檔案中有一個 Pig 指令碼,如下所示。
Sample_script.pig
student = LOAD 'hdfs://:9000/pig_data/student.txt' USING
PigStorage(',') as (id:int,name:chararray,city:chararray);
Dump student;
現在,您可以執行上面檔案中指令碼,如下所示。
| 本地模式 | MapReduce 模式 |
|---|---|
| $ pig -x local Sample_script.pig | $ pig -x mapreduce Sample_script.pig |
**注意** - 我們將在後續章節中詳細討論如何在 **批處理模式** 和 **嵌入模式** 下執行 Pig 指令碼。