- Zookeeper 教程
- Zookeeper – 首頁
- Zookeeper – 概述
- Zookeeper 基礎
- Zookeeper – 工作流程
- Zookeeper – Leader 選舉
- Zookeeper – 安裝
- Zookeeper – 命令列介面 (CLI)
- Zookeeper – API
- Zookeeper – 應用
- Zookeeper 有用資源
- Zookeeper – 快速指南
- Zookeeper – 有用資源
- Zookeeper – 討論
Zookeeper 基礎
在深入研究 ZooKeeper 的工作原理之前,讓我們先了解一下 ZooKeeper 的基本概念。本章將討論以下主題:
- 架構
- 分層名稱空間
- 會話
- Watcher (觀察器)
ZooKeeper 架構
請檢視下圖。它描述了 ZooKeeper 的“客戶端-伺服器架構”。
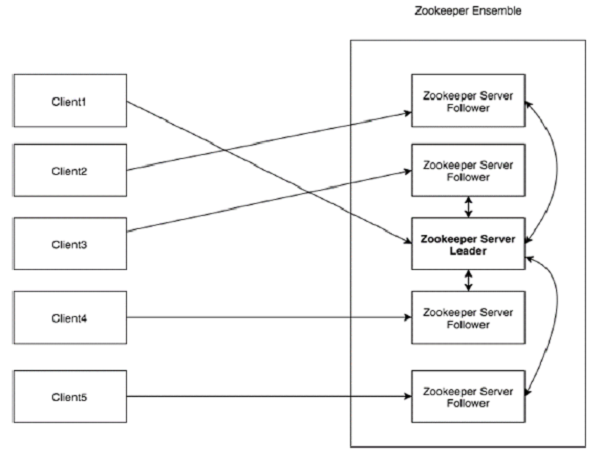
下表解釋了 ZooKeeper 架構中每個元件。
| 組成部分 | 描述 |
|---|---|
| 客戶端 | 客戶端是分散式應用程式叢集中的一個節點,它從伺服器訪問資訊。在特定時間間隔內,每個客戶端都會向伺服器傳送訊息,以告知伺服器客戶端處於活動狀態。 同樣,伺服器在客戶端連線時會發送確認訊息。如果從連線的伺服器沒有收到響應,客戶端會自動將訊息重定向到另一個伺服器。 |
| 伺服器 | 伺服器是 ZooKeeper 叢集中的一個節點,它為客戶端提供所有服務。向客戶端傳送確認訊息以告知伺服器處於活動狀態。 |
| 叢集 (Ensemble) | ZooKeeper 伺服器組。形成叢集所需的最小節點數為 3。 |
| Leader (領導者) | 伺服器節點,如果任何連線的節點發生故障,它會執行自動恢復。領導者在服務啟動時被選舉產生。 |
| Follower (跟隨者) | 遵循領導者指令的伺服器節點。 |
分層名稱空間
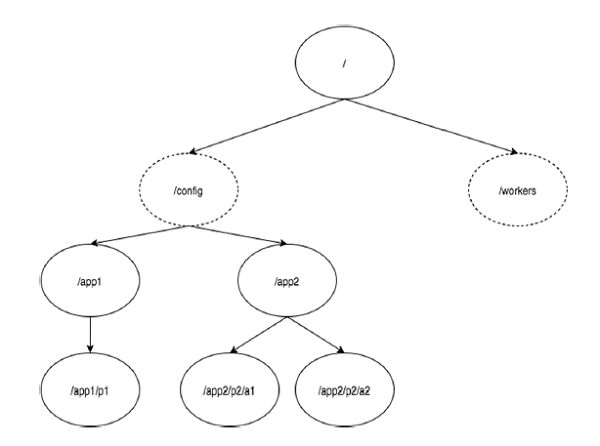
下圖描述了用於記憶體表示的 ZooKeeper 檔案系統的樹結構。ZooKeeper 節點稱為 **znode**。每個 znode 都由名稱標識,並透過路徑序列 (/) 分隔。
在上圖中,首先有一個根 **znode**,用“/”分隔。在根目錄下,有兩個邏輯名稱空間 **config** 和 **workers**。
**config** 名稱空間用於集中式配置管理,而 **workers** 名稱空間用於命名。
在 **config** 名稱空間下,每個 znode 可以儲存最多 1MB 的資料。這類似於 UNIX 檔案系統,只是父 znode 也能儲存資料。這種結構的主要目的是儲存同步資料並描述 znode 的元資料。這種結構稱為 **ZooKeeper 資料模型**。
ZooKeeper 資料模型中的每個 znode 都維護一個 **stat** 結構。stat 簡單地提供 znode 的 **元資料**。它包含 *版本號、訪問控制列表 (ACL)、時間戳和資料長度*。
**版本號** – 每個 znode 都有一個版本號,這意味著每次與 znode 關聯的資料發生更改時,其對應的版本號也會增加。當多個 ZooKeeper 客戶端嘗試對同一 znode 執行操作時,版本號的使用非常重要。
**訪問控制列表 (ACL)** – ACL 基本上是訪問 znode 的身份驗證機制。它控制所有 znode 的讀寫操作。
**時間戳** – 時間戳表示從 znode 建立和修改開始經過的時間。通常以毫秒錶示。ZooKeeper 透過“事務 ID”(zxid)識別對 znode 的每次更改。**Zxid** 是唯一的,併為每個事務維護時間,以便您可以輕鬆識別從一個請求到另一個請求經過的時間。
**資料長度** – 儲存在 znode 中的資料總量就是資料長度。您可以儲存最多 1MB 的資料。
Znode 型別
Znode 分為永續性、順序性和臨時性三種。
**永續性 znode** – 即使建立該特定 znode 的客戶端斷開連線後,永續性 znode 也仍然存在。預設情況下,所有 znode 都是永續性的,除非另有指定。
**臨時性 znode** – 臨時性 znode 在客戶端處於活動狀態時有效。當客戶端與 ZooKeeper 叢集斷開連線時,臨時性 znode 會自動刪除。因此,臨時性 znode 不允許有子節點。如果臨時性 znode 被刪除,則下一個合適的節點將填充其位置。臨時性 znode 在 Leader 選舉中起著重要作用。
**順序性 znode** – 順序性 znode 可以是永續性的或臨時性的。當建立一個新的順序性 znode 時,ZooKeeper 會透過在其原始名稱後面附加一個 10 位序列號來設定 znode 的路徑。例如,如果將路徑為 **`/myapp`** 的 znode 建立為順序性 znode,ZooKeeper 將路徑更改為 **`/myapp0000000001`** 並將下一個序列號設定為 0000000002。如果同時建立兩個順序性 znode,則 ZooKeeper 絕不會對每個 znode 使用相同的編號。順序性 znode 在鎖和同步中起著重要作用。
會話
會話對於 ZooKeeper 的操作非常重要。會話中的請求以 FIFO 順序執行。客戶端連線到伺服器後,將建立會話併為客戶端分配一個 **會話 ID**。
客戶端在特定時間間隔內傳送 **心跳** 以保持會話有效。如果 ZooKeeper 叢集在服務啟動時指定的時間段(會話超時)內沒有收到客戶端的心跳,它會判斷客戶端已死亡。
會話超時通常以毫秒錶示。無論出於何種原因,當會話結束時,在此會話期間建立的臨時性 znode 也將被刪除。
Watcher (觀察器)
Watcher (觀察器) 是一種簡單的機制,客戶端可以使用它來獲取有關 ZooKeeper 叢集更改的通知。客戶端在讀取特定 znode 時可以設定 Watcher。對於任何 znode(客戶端在其上註冊)的更改,Watcher 都會向註冊的客戶端傳送通知。
Znode 更改是指與 znode 關聯的資料的修改或 znode 子節點的更改。Watcher 只觸發一次。如果客戶端想要再次收到通知,則必須透過另一個讀取操作來完成。當連線會話過期時,客戶端將與伺服器斷開連線,並且關聯的 Watcher 也將被刪除。