
 資料結構
資料結構 網路
網路 RDBMS
RDBMS 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 語言程式設計
C 語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPYen 演算法,資料結構中的 K-最短路徑演算法
Yen 的 K 短路徑演算法不會只給出單條最短路徑,而是給出 *k* 條最短路徑,這樣我們就能獲得第二條、第三條最短路徑,以此類推。
設想這樣一個場景:我們必須從 A 地前往 B 地,且在 A 地和 B 地之間有多條可用路線,但我們必須找到最短路徑,並且略過所有在時間複雜度方面考慮較少的路徑,才能到達目的地。
我們用一個例子來理解一下 -
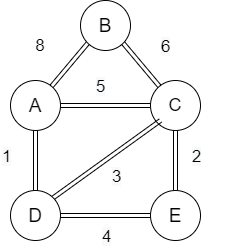
以給定的示例為橋,它具有 B 點的峰值。如果有人希望從 A 點穿越橋樑到達 C 點,那麼沒有人會走到橋的最高點去穿越它。所以從 A 點到 C 點會是一條更長的路徑。
透過多種方法可以獲得最短路徑。但我們必須找到至多 (k-1) 條最短路徑。
K 最短路徑演算法
query= “””
MATCH(start: place{id:source}),*end: Place {Id:destination})
Call algo.kshortestPaths.stream(start,end,10, “distance”)
Yield nodeIDs, path costs, index
Return index.
[node in algo.getNodeByID(nodeId[1…..-1]) | node.id] aS,
Reduce (acc=0.0, cost in costs | acc+cost ) as total cost
“””
params= {“source”: Alex,Destination: “US”}
With driver.selection() as session:
Row session.run(query, params)
df = pd.DataFrame[dict(record) for record in rows])
pd.set_option(‘max_colwidth’, 100)
display(df)

更新於:2021 年 2 月 23 日
1K+ 瀏覽量

廣告