
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP什麼是過擬合以及如何避免?
簡介
在統計學中,“過擬合”指的是模型誤差,它發生在函式與特定資料集關聯過於緊密時。結果,過擬合可能無法擬合新資料,這可能會降低預測未來觀察值的精度。
檢查諸如準確性和損失之類的驗證指標可能會顯示過擬合。當模型受到過擬合的影響時,驗證指標通常會增加到某個點,然後趨於平穩或開始下降。在上升趨勢中,模型尋找良好的匹配,一旦找到,趨勢就開始下降或停滯。
過擬合是模型的一個問題,當模型存在偏差因為它與資料集過於相關。
當模型過擬合時,它僅適用於其設計的資料集,而不適用於任何其他資料集。
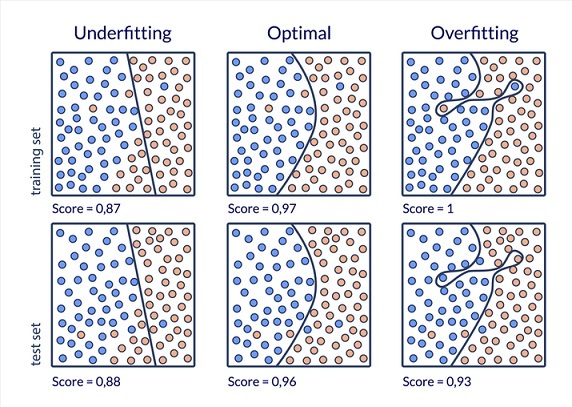
整合、資料增強、資料簡化和交叉驗證是避免過擬合的一些技術。
如何檢測過擬合?
在測試資料之前,幾乎很難檢測到過擬合。它可以幫助解決過擬合無法泛化資料集的能力,這是它的一個獨特特徵。因此,可以將資料分成幾個子集以方便訓練和測試。資料主要分為訓練集和測試集兩大類。
訓練集約佔總資料量的80%,也用於訓練模型。測試集約佔總資料集的20%,用於評估從未使用過的資料的正確性。我們可以評估模型對每條資料的效能來識別過擬合何時發生,並觀察訓練過程是如何透過分割資料集來工作的。
可以在兩個資料集上觀察到的準確性可以用來評估效能並確定是否存在過擬合。如果模型在訓練集和測試集上的表現都很好,那麼很明顯模型是過擬合的。
如何防止過擬合?
使用更多資料進行訓練
在訓練中使用更多資料是避免過擬合的一種方法。在此設定下,演算法可以更容易地識別模式並減少錯誤。隨著使用者新增更多訓練資料,模型將無法對所有樣本進行過擬合,迫使其進行泛化以產生結果。
使用者應繼續收集更多資料以提高模型的準確性。 使用者應確保所使用的資料是準確和相關的,因為這種方法成本很高。
資料增強
資料增強比使用更多資料進行訓練成本更低。 如果你無法繼續收集新資料,你可以透過使用已有的資料集來實現多樣化。
每次模型處理資料樣本時,資料增強都會導致樣本外觀發生細微變化。該方法阻止模型學習資料集的屬性,同時使每個資料集看起來對模型都是唯一的。
向輸入和輸出資料新增噪聲是另一種類似於資料增強的技術。向輸出新增噪聲會導致更多樣化的資料,而向輸入新增噪聲則使模型更穩定,而不會影響資料質量或隱私。但是,應謹慎使用噪聲新增,以免噪聲量過多地影響資料的準確性或一致性。
資料簡化
當模型即使訪問大量資料也能成功地對訓練資料集進行過擬合時,模型的複雜性會導致過擬合。資料簡化技術降低了模型的複雜性,使模型足夠簡單以防止過擬合。
修剪決策樹、減少神經網路中的引數數量以及在中性網路上應用 dropout 是可以實施的一些示例活動。如果模型得到簡化,則可以執行得更快,並且更輕量級。
整合
一種稱為整合的機器學習方法結合了來自兩個或多個不同模型的預測。兩種最常見的整合技術是Bagging和Boosting。
Boosting 透過使用簡單的基礎模型來提高模型的總複雜性。它按順序指導大量弱學習器,以便序列中的每個學習器都能從其前面學習器的錯誤中學習。
Boosting 透過組合序列中的所有弱學習器來產生一個強學習器。Boosting 的替代方法是稱為 Bagging 的整合技術。為了最大化預測,大量強學習器並行訓練,然後組合起來。這就是 Bagging 的工作方式。
結論
過擬合是指計算機程式無法泛化資料集。為了避免過擬合,可以將資料分解成訓練集和測試子集。使用者應繼續收集更多資料以提高模型的準確性。資料增強向資料新增噪聲,使每個資料集看起來都是唯一的。應謹慎使用噪聲新增,以免過多地影響資料的準確性或一致性。

瀏覽量:355
