
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP理解機器學習中的啟用函式
在機器學習中,啟用函式就像神經網路中的魔法成分一樣。它們是數學公式,根據神經元接收到的資訊來決定是否應該啟用。神經網路學習和表示複雜資料模式的能力,很大程度上取決於啟用函式。這些函式為網路引入了非線性,使其能夠處理各種問題,包括複雜的關係和互動。簡單來說,啟用函式使神經網路能夠發現隱藏模式、預測結果和正確分類資料。在這篇文章中,我們將瞭解機器學習中的啟用函式。
什麼是啟用函式?
啟用函式是神經網路的一個重要組成部分,它根據神經元接收到的資訊來決定是否啟用該神經元。啟用函式的主要作用是使網路非線性化。在一個線性模型中,輸入只是被縮放和相加,其輸出也是輸入的線性組合。
然而,啟用函式賦予神經網路學習和表示複雜函式的能力,這些函式與簡單的線性連線建模的函式不可比擬。由於啟用函式的非線性特性,網路能夠識別資料中複雜的模式和關係。它使網路能夠處理非線性變化的輸入,從而能夠處理各種現實世界的問題,包括時間序列預測、影像識別和自然語言處理。
非線性的重要性
非線性是神經網路成功的一個關鍵因素。它至關重要,因為現實世界中的許多現象和關係本質上是非線性的。線性啟用函式由於只能模擬簡單的線性關係,因此在捕捉複雜模式方面的能力有限。如果沒有非線性,神經網路只能表示線性函式,這將極大地限制其處理複雜問題的能力。另一方面,非線性啟用函式使神經網路能夠逼近和表示資料中的複雜關係。它們使網路能夠學習和模擬複雜的模式,從而反映現實世界中存在的複雜性和非線性關係。
機器學習中啟用函式的型別
Sigmoid啟用函式
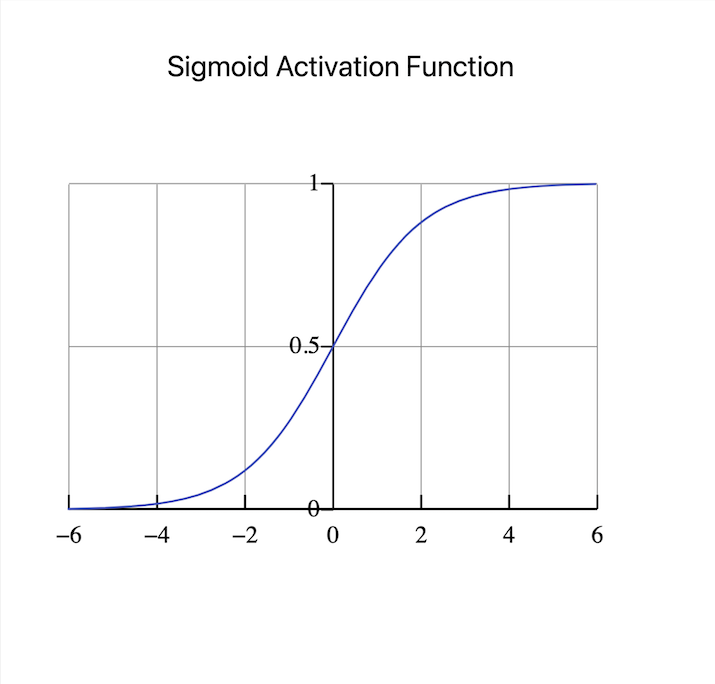
Sigmoid啟用函式是大多數人選擇的函式。它具有S形曲線,將輸入對映到0到1之間的範圍。它可用於二元分類問題,目標是預測兩個類別中的哪一個會發生。Sigmoid函式透過將輸入壓縮到機率範圍內,產生易於理解的輸出,可以解釋為屬於特定類別的機率。
然而,Sigmoid啟用函式容易受到梯度消失問題的困擾。隨著網路深度的增加,梯度變得非常小,這會阻礙學習並導致收斂緩慢。由於這個限制,研究人員正在探索新的啟用函式,以解決梯度消失問題並改進深度神經網路的訓練。
Tanh啟用函式
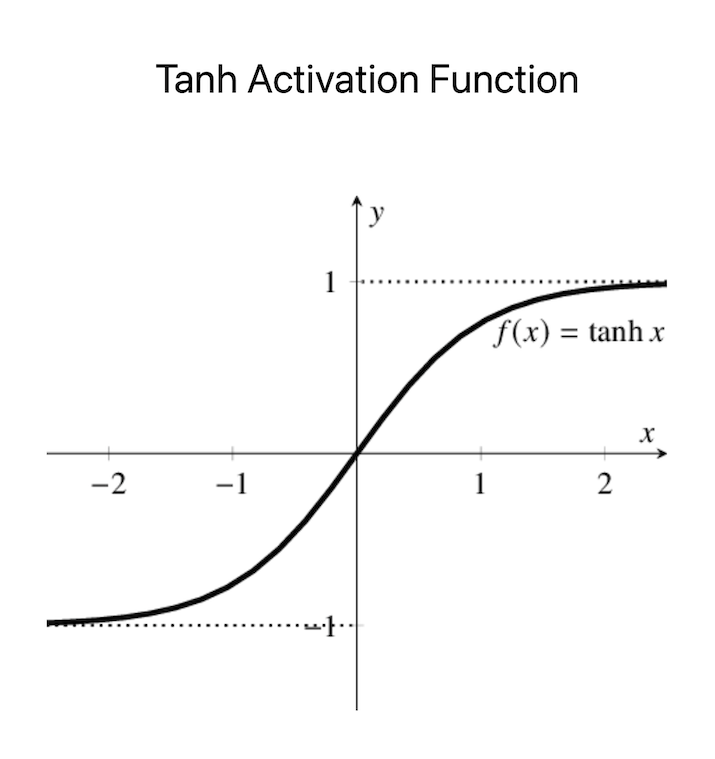
雙曲正切(tanh)啟用函式與Sigmoid函式類似,它也具有S形曲線,儘管它將輸入對映到-1到1的範圍。與Sigmoid函式類似,tanh在二元分類問題中很有用,因為它產生機率輸出,可以轉換為類別機率。tanh函式的優點是它產生零均值的輸出,這對於訓練某些模型可能很有幫助。
然而,它在深度神經網路中的應用仍然受到梯度消失問題的限制。此外,tanh函式比Sigmoid函式更容易飽和,因為它具有更陡峭的梯度。因此,它在訓練過程中可能不太穩定,並且容易受到初始引數設定的影響。但是,在某些情況下,特別是需要零均值輸出或平衡類別預測的情況下,tanh啟用函式仍然是一個可行的選擇。
修正線性單元 (ReLU)
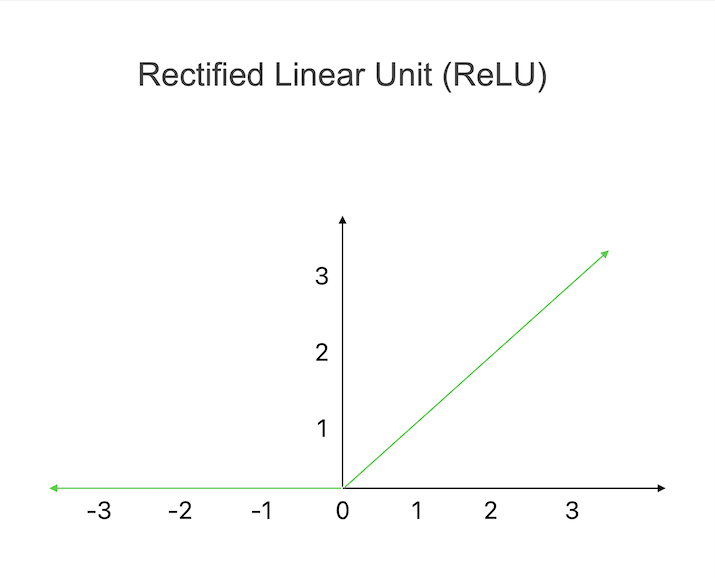
修正線性單元 (ReLU) 是一種廣泛使用的啟用函式,它將所有負輸入歸零,而將正輸入保持為原始值。透過這個簡單的啟用規則,ReLU可以引入非線性並檢測資料中的複雜模式。ReLU的主要優點之一是它的計算效率。由於它只需要簡單的操作,所以該啟用函式比其他函式更容易計算。然而,ReLU也有一些缺點。
一個潛在的問題被稱為“死亡ReLU”,其中某些神經元永久處於休眠狀態,對任何輸入都輸出0。這種現象會對訓練過程產生負面影響,因為損壞的神經元不再對學習有用。然而,諸如使用多個ReLU或適當的初始化程式之類的策略可以減少死亡ReLU的可能性,並確保深度神經網路訓練的成功。
Softmax啟用函式
Softmax函式通常用於多類別分類問題,目標是將輸入分類到多個可能的類別之一。它將實數值輸入向量歸一化為機率分佈。Softmax函式確保輸出機率之和為1,這使其適用於不能同時存在的類別的情況。Softmax函式產生一個機率分佈,這使我們能夠將輸出解釋為輸入屬於每個類別的機率。
因此,我們可以更有信心地進行預測,並將輸入分配給機率最高的類別。對於影像識別、自然語言處理和情感分析等需要同時考慮多個類別的應用,Softmax函式是一個重要的機器學習工具。
結論
總之,啟用函式在機器學習中的重要性怎麼強調都不為過。它們在神經網路中充當決策者,決定是否轉發資訊。簡而言之,啟用函式是使神經網路發揮其全部潛力、學習、適應並在各種現實環境中進行準確預測的關鍵。

259 次瀏覽
