- TIKA 教程
- TIKA - 首頁
- TIKA - 概述
- TIKA - 架構
- TIKA - 環境
- TIKA - 參考 API
- TIKA - 檔案格式
- TIKA - 文件型別檢測
- TIKA - 內容提取
- TIKA - 元資料提取
- TIKA - 語言檢測
- TIKA - 圖形使用者介面 (GUI)
- TIKA 有用資源
- TIKA 快速指南
- TIKA - 有用資源
- TIKA - 討論
TIKA 快速指南
TIKA - 概述
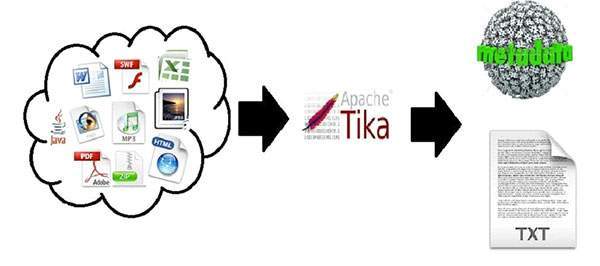
什麼是 Apache Tika?
Apache Tika 是一個用於檢測文件型別和從各種檔案格式中提取內容的庫。
在內部,Tika 使用各種現有的文件解析器和文件型別檢測技術來檢測和提取資料。
使用 Tika,可以開發一個通用的型別檢測器和內容提取器,以從不同型別的文件(如電子表格、文字文件、影像、PDF 甚至多媒體輸入格式)中提取結構化文字和元資料。
Tika 為解析不同的檔案格式提供了一個單一的通用 API。它為每種文件型別使用現有的專用解析器庫。
所有這些解析器庫都被封裝在一個名為 **Parser 介面** 的單一介面下。
為什麼選擇 Tika?
根據 filext.com 的資料,大約有 1.5 萬到 5.1 萬種內容型別,而且這個數字還在日益增長。資料以各種格式儲存,例如文字文件、Excel 電子表格、PDF、影像和多媒體檔案等等。因此,搜尋引擎和內容管理系統等應用程式需要額外的支援才能輕鬆地從這些文件型別中提取資料。Apache Tika 透過提供一個通用的 API 來定位和提取來自多種檔案格式的資料來滿足這一需求。
Apache Tika 應用
許多應用程式都使用了 Apache Tika。這裡我們將討論一些嚴重依賴 Apache Tika 的重要應用程式。
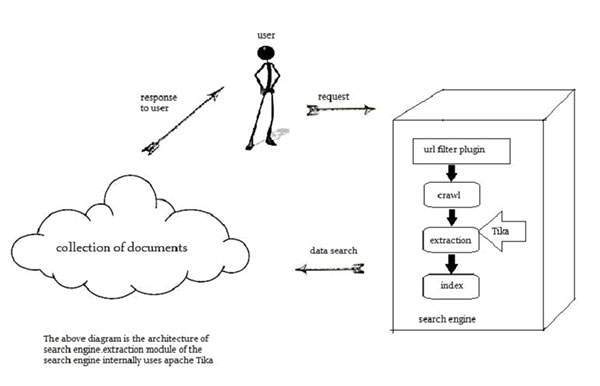
搜尋引擎
在開發搜尋引擎時,Tika 被廣泛用於索引數字文件的文字內容。
搜尋引擎是資訊處理系統,旨在從 Web 搜尋資訊和已索引的文件。
爬蟲是搜尋引擎的一個重要組成部分,它爬取 Web 以獲取要使用某種索引技術進行索引的文件。之後,爬蟲將這些已索引的文件傳輸到提取元件。
提取元件的職責是從文件中提取文字和元資料。這種提取的內容和元資料對於搜尋引擎非常有用。此提取元件包含 Tika。
然後將提取的內容傳遞給搜尋引擎的索引器,後者使用它來構建搜尋索引。除此之外,搜尋引擎還以多種其他方式使用提取的內容。
文件分析
在人工智慧領域,有一些工具可以自動在語義級別分析文件並從中提取各種資料。
在這些應用程式中,文件根據文件提取內容中的主要術語進行分類。
這些工具使用 Tika 進行內容提取來分析從純文字到數字文件的各種文件。
數字資產管理
一些組織使用稱為數字資產管理 (DAM) 的特殊應用程式來管理其數字資產,例如照片、電子書、圖紙、音樂和影片。
此類應用程式藉助文件型別檢測器和元資料提取器對各種文件進行分類。
內容分析
像亞馬遜這樣的網站會根據使用者的興趣向他們推薦網站上新發布的內容。為此,這些網站遵循 **機器學習技術**,或藉助 Facebook 等社交媒體網站提取所需資訊,例如使用者的喜好和興趣。收集到的資訊將採用 html 標籤或其他需要進一步內容型別檢測和提取的格式。
對於文件的內容分析,我們擁有實現機器學習技術的技術,例如 **UIMA** 和 **Mahout**。這些技術可用於對文件中的資料進行聚類和分析。
**Apache Mahout** 是一個框架,它在 Apache Hadoop(一個雲計算平臺)上提供 ML 演算法。Mahout 透過遵循某些聚類和過濾技術來提供架構。透過遵循此架構,程式設計師可以編寫自己的 ML 演算法,透過採用各種文字和元資料組合來生成推薦。為了向這些演算法提供輸入,Mahout 的最新版本使用 Tika 從二進位制內容中提取文字和元資料。
**Apache UIMA** 分析和處理各種程式語言並生成 UIMA 註釋。它在內部使用 Tika Annotator 來提取文件文字和元資料。
歷史
| 年份 | 開發 |
|---|---|
| 2006 | Tika 的理念是在 Lucene 專案管理委員會之前提出的。 |
| 2006 | 討論了 Tika 的概念及其在 Jackrabbit 專案中的實用性。 |
| 2007 | Tika 進入 Apache 孵化器。 |
| 2008 | 釋出了 0.1 版和 0.2 版,Tika 從孵化器畢業到 Lucene 子專案。 |
| 2009 | 釋出了 0.3 版、0.4 版和 0.5 版。 |
| 2010 | 釋出了 0.6 版和 0.7 版,Tika 畢業成為頂級 Apache 專案。 |
| 2011 | 釋出了 Tika 1.0,同年還發布了關於 Tika 的書籍“Tika in Action”。 |
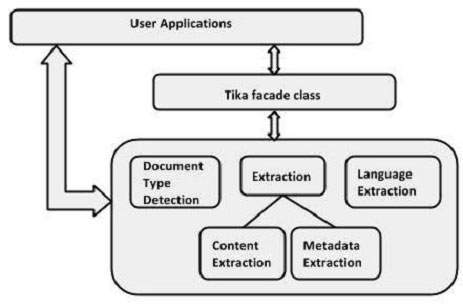
TIKA - 架構
Tika 的應用程式級架構
應用程式程式設計師可以輕鬆地將其應用程式整合到 Tika 中。Tika 提供命令列介面和 GUI 以使其更易於使用。
本章將討論構成 Tika 架構的四個重要模組。下圖顯示了 Tika 的架構及其四個模組:
- 語言檢測機制。
- MIME 檢測機制。
- 解析器介面。
- Tika Facade 類。
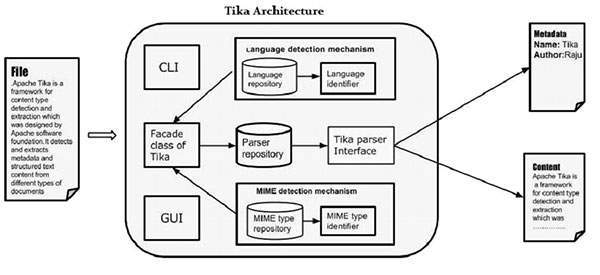
語言檢測機制
每當將文字文件傳遞給 Tika 時,它都會檢測文件的書寫語言。它接受沒有語言註釋的文件,並透過檢測語言在文件的元資料中新增該資訊。
為了支援語言識別,Tika 在包 **org.apache.tika.language** 中有一個名為 **Language Identifier** 的類,以及一個內部包含用於從給定文字檢測語言的演算法的語言識別儲存庫。Tika 在內部使用 N-gram 演算法進行語言檢測。
MIME 檢測機制
Tika 可以根據 MIME 標準檢測文件型別。Tika 中的預設 MIME 型別檢測是使用 org.apache.tika.mime.mimeTypes 完成的。它對大多數內容型別檢測使用 org.apache.tika.detect.Detector 介面。
在內部,Tika 使用多種技術,例如檔案萬用字元、內容型別提示、魔術位元組、字元編碼以及其他多種技術。
解析器介面
org.apache.tika.parser 的解析器介面是 Tika 中解析文件的關鍵介面。此介面從文件中提取文字和元資料,並將其總結給希望編寫解析器外掛的外部使用者。
使用針對各個文件型別而不同的具體解析器類,Tika 支援許多文件格式。這些特定於格式的類透過直接實現解析器邏輯或使用外部解析器庫來提供對不同文件格式的支援。
Tika Facade 類
使用 Tika Facade 類是從 Java 呼叫 Tika 的最簡單直接的方法,它遵循外觀設計模式。您可以在 Tika API 的 org.apache.tika 包中找到 Tika Facade 類。
透過實現基本用例,Tika 充當景觀的代理。它抽象了 Tika 庫的底層複雜性,例如 MIME 檢測機制、解析器介面和語言檢測機制,併為使用者提供了一個簡單的介面來使用。
Tika 的特性
**統一的解析器介面** - Tika 將所有第三方解析器庫封裝在一個單一的解析器介面中。由於此功能,使用者無需選擇合適的解析器庫並根據遇到的檔案型別使用它。
**低記憶體使用率** - Tika 消耗的記憶體資源較少,因此易於嵌入 Java 應用程式。我們也可以在資源較少的平臺(如移動 PDA)上執行的應用程式中使用 Tika。
**快速處理** - 可以預期應用程式快速進行內容檢測和提取。
**靈活的元資料** - Tika 理解用於描述檔案的各種元資料模型。
**解析器整合** - Tika 可以在單個應用程式中使用針對每種文件型別而可用的各種解析器庫。
**MIME 型別檢測** - Tika 可以檢測並提取 MIME 標準中包含的所有媒體型別的內容。
**語言檢測** - Tika 包含語言識別功能,因此可在多語言網站中根據語言型別使用文件。
Tika 的功能
Tika 支援各種功能:
- 文件型別檢測
- 內容提取
- 元資料提取
- 語言檢測
文件型別檢測
Tika 使用各種檢測技術來檢測給定文件的型別。

內容提取
Tika 有一個解析器庫,可以解析各種文件格式的內容並提取它們。在檢測到文件型別後,它會從解析器儲存庫中選擇合適的解析器並傳遞文件。Tika 的不同類具有解析不同文件格式的方法。

元資料提取
與內容一起,Tika 使用與內容提取相同的過程提取文件的元資料。對於某些文件型別,Tika 有類可以提取元資料。

語言檢測
在內部,Tika 使用諸如n-gram之類的演算法來檢測給定文件中內容的語言。Tika 依賴於諸如Languageidentifier和Profiler之類的類來進行語言識別。
TIKA - 環境
本章將指導您完成在 Windows 和 Linux 上設定 Apache Tika 的過程。安裝 Apache Tika 需要使用者管理。
系統要求
| JDK | Java SE 2 JDK 1.6 或更高版本 |
| 記憶體 | 1 GB RAM(推薦) |
| 磁碟空間 | 無最低要求 |
| 作業系統版本 | Windows XP 或更高版本,Linux |
步驟 1:驗證 Java 安裝
要驗證 Java 安裝,請開啟控制檯並執行以下java命令。
| 作業系統 | 任務 | 命令 |
|---|---|---|
| Windows | 開啟命令控制檯 | \>java –version |
| Linux | 開啟命令終端 | $java –version |
如果 Java 已在您的系統上正確安裝,則您應該獲得以下輸出之一,具體取決於您正在使用的平臺。
| 作業系統 | 輸出 |
|---|---|
| Windows | Java 版本 "1.7.0_60"
Java(TM) SE 執行時環境 (build 1.7.0_60-b19) Java Hotspot(TM) 64 位伺服器 VM (build 24.60-b09, mixed mode) |
| Linux | java 版本 "1.7.0_25" Open JDK 執行時環境 (rhel-2.3.10.4.el6_4-x86_64) Open JDK 64 位伺服器 VM (build 23.7-b01, mixed mode) |
在繼續本教程之前,我們假設本教程的讀者已在其系統上安裝了 Java 1.7.0_60。
如果您沒有 Java SDK,請從https://www.oracle.com/technetwork/java/javase/downloads/index.html 下載並安裝其最新版本。
步驟 2:設定 Java 環境
設定 JAVA_HOME 環境變數以指向 Java 安裝在您計算機上的基本目錄位置。例如:
| 作業系統 | 輸出 |
|---|---|
| Windows | 將環境變數 JAVA_HOME 設定為 C:\ProgramFiles\java\jdk1.7.0_60 |
| Linux | export JAVA_HOME=/usr/local/java-current |
將 Java 編譯器位置的完整路徑新增到系統路徑。
| 作業系統 | 輸出 |
|---|---|
| Windows | 將字串 ;C:\Program Files\Java\jdk1.7.0_60\bin 附加到系統變數 PATH 的末尾。 |
| Linux | export PATH=$PATH:$JAVA_HOME/bin/ |
如上所述,從命令提示符驗證命令 java -version。
步驟 3:設定 Apache Tika 環境
程式設計師可以透過使用以下方式將其環境整合到 Apache Tika 中:
- 命令列、
- Tika API、
- Tika 的命令列介面 (CLI)、
- Tika 的圖形使用者介面 (GUI) 或
- 原始碼。
對於任何這些方法,首先,您必須下載 Tika 的原始碼。
您可以在https://Tika.apache.org/download.html找到 Tika 的原始碼,您將找到兩個連結:
apache-tika-1.6-src.zip - 它包含 Tika 的原始碼,以及
tika-app-1.6.jar - 它是一個包含 Tika 應用程式的 jar 檔案。
下載這兩個檔案。下面顯示了 Tika 官方網站的快照。
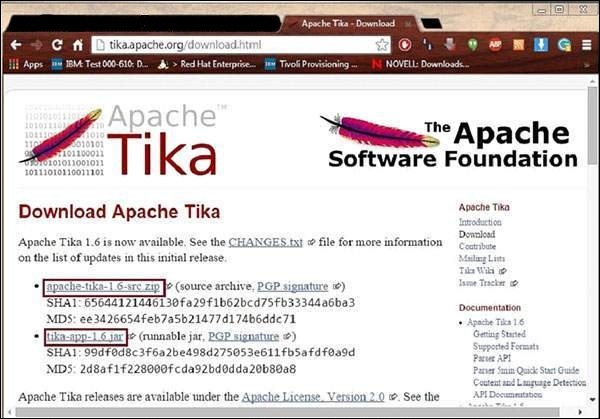
下載檔案後,設定 jar 檔案tika-app-1.6.jar的類路徑。新增 jar 檔案的完整路徑,如下表所示。
| 作業系統 | 輸出 |
|---|---|
| Windows | 將字串“C:\jars\tika-app-1.6.jar”附加到使用者環境變數 CLASSPATH |
| Linux | export CLASSPATH=$CLASSPATH: /usr/share/jars/tika-app-1.6.jar |
Apache 提供了 Tika 應用程式,這是一個使用 Eclipse 的圖形使用者介面 (GUI) 應用程式。
使用 Eclipse 的 Tika-Maven 構建
開啟 Eclipse 並建立一個新專案。
如果您在 Eclipse 中沒有 Maven,請按照以下步驟進行設定。
開啟連結 https://wiki.eclipse.org/M2E_updatesite_and_gittags。在那裡,您將以表格格式找到 m2e 外掛版本。
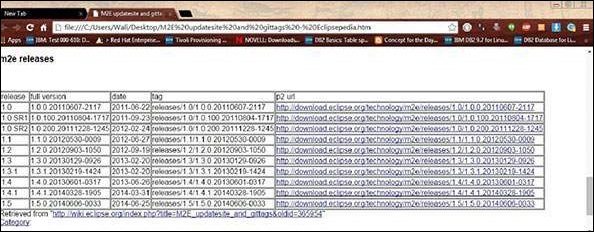
選擇最新版本並將 url 的路徑儲存在 p2 url 列中。
現在重新訪問 Eclipse,在選單欄中,單擊幫助,然後從下拉選單中選擇安裝新軟體
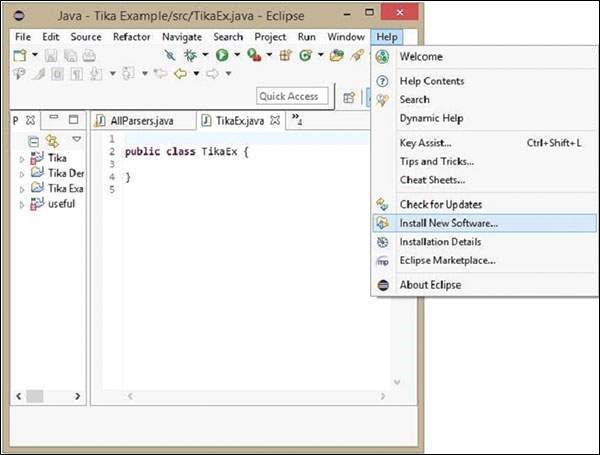
單擊新增按鈕,鍵入任何所需的名稱(可選)。現在將儲存的 url 貼上到位置欄位中。
將新增一個新的外掛,其名稱是您在上一步中選擇的名稱,選中其前面的複選框,然後單擊下一步。
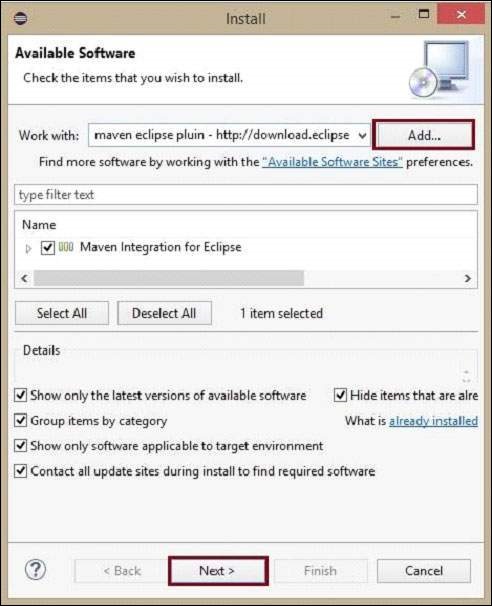
繼續安裝。完成後,重新啟動 Eclipse。
現在右鍵單擊專案,在配置選項中,選擇轉換為 Maven 專案。
將出現一個用於建立新 pom 的新嚮導。將 Group Id 輸入為 org.apache.tika,輸入 Tika 的最新版本,將打包選擇為 jar,然後單擊完成。
Maven 專案已成功安裝,並且您的專案已轉換為 Maven。現在您必須配置 pom.xml 檔案。
配置 XML 檔案
從https://mvnrepository.com/artifact/org.apache.tika 獲取 Tika maven 依賴項
以下是 Apache Tika 的完整 Maven 依賴項。
<dependency> <groupId>org.apache.Tika</groupId> <artifactId>Tika-core</artifactId> <version>1.6</version> <groupId>org.apache.Tika</groupId> <artifactId> Tika-parsers</artifactId> <version> 1.6</version> <groupId> org.apache.Tika</groupId> <artifactId>Tika</artifactId> <version>1.6</version> <groupId>org.apache.Tika</groupId> < artifactId>Tika-serialization</artifactId> < version>1.6< /version> < groupId>org.apache.Tika< /groupId> < artifactId>Tika-app< /artifactId> < version>1.6< /version> <groupId>org.apache.Tika</groupId> <artifactId>Tika-bundle</artifactId> <version>1.6</version> </dependency>
TIKA - 參考 API
使用者可以使用 Tika facade 類將其嵌入到他們的應用程式中。它具有探索 Tika 所有功能的方法。因為它是一個 facade 類,所以 Tika 隱藏了其功能背後的複雜性。除此之外,使用者還可以使用 Tika 的各種類在其應用程式中。
Tika 類 (facade)
這是 Tika 庫中最突出的類,遵循 facade 設計模式。因此,它隱藏了所有內部實現,並提供簡單的訪問 Tika 功能的方法。下表列出了此類的建構函式及其描述。
包 - org.apache.tika
類 - Tika
| 序號 | 建構函式和說明 |
|---|---|
| 1 |
Tika() 使用預設配置並構造 Tika 類。 |
| 2 |
Tika(Detector detector) 透過接受檢測器例項作為引數來建立 Tika facade。 |
| 3 |
Tika(Detector detector, Parser parser) 透過接受檢測器和解析器例項作為引數來建立 Tika facade。 |
| 4 |
Tika(Detector detector, Parser parser, Translator translator) 透過接受檢測器、解析器和翻譯器例項作為引數來建立 Tika facade。 |
| 5 |
Tika(TikaConfig config) 透過接受 TikaConfig 類的物件作為引數來建立 Tika facade。 |
方法和說明
以下是 Tika facade 類的重要方法:
| 序號 | 方法和說明 |
|---|---|
| 1 |
parseToString(File file) 此方法及其所有變體都會解析作為引數傳遞的檔案,並以字串格式返回提取的文字內容。預設情況下,此字串引數的長度是有限制的。 |
| 2 |
int getMaxStringLength() 返回 parseToString 方法返回的字串的最大長度。 |
| 3 |
void setMaxStringLength(int maxStringLength) 設定 parseToString 方法返回的字串的最大長度。 |
| 4 |
Reader parse(File file) 此方法及其所有變體都會解析作為引數傳遞的檔案,並以 java.io.reader 物件的形式返回提取的文字內容。 |
| 5 |
String detect(InputStream stream, Metadata metadata) 此方法及其所有變體接受 InputStream 物件和 Metadata 物件作為引數,檢測給定文件的型別,並以 String 物件的形式返回文件型別名稱。此方法隱藏了 Tika 使用的檢測機制。 |
| 6 |
String translate(InputStream text, String targetLanguage) 此方法及其所有變體接受 InputStream 物件和一個表示我們希望將文字翻譯成的語言的字串,並將給定文字翻譯成所需的語言,嘗試自動檢測源語言。 |
解析器介面
這是 Tika 包的所有解析器類實現的介面。
包 - org.apache.tika.parser
介面 - Parser
方法和說明
以下是 Tika Parser 介面的重要方法:
| 序號 | 方法和說明 |
|---|---|
| 1 |
parse(InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context) 此方法將給定文件解析為一系列 XHTML 和 SAX 事件。解析後,它將提取的文件內容放入 ContentHandler 類的物件中,並將元資料放入 Metadata 類的物件中。 |
Metadata 類
此類實現了各種介面,例如 CreativeCommons、Geographic、HttpHeaders、Message、MSOffice、ClimateForcast、TIFF、TikaMetadataKeys、TikaMimeKeys、Serializable,以支援各種資料模型。下表列出了此類的建構函式和方法及其描述。
包 - org.apache.tika.metadata
類 - Metadata
| 序號 | 建構函式和說明 |
|---|---|
| 1 |
Metadata() 構造一個新的空元資料。 |
| 序號 | 方法和說明 |
|---|---|
| 1 |
add(Property property, String value) 將元資料屬性/值對映新增到給定文件。使用此函式,我們可以將值設定為屬性。 |
| 2 |
add(String name, String value) 將元資料屬性/值對映新增到給定文件。使用此方法,我們可以將新的名稱值設定為文件的現有元資料。 |
| 3 |
String get(Property property) 返回給定元資料屬性的值(如果有)。 |
| 4 |
String get(String name) 返回給定元資料名稱的值(如果有)。 |
| 5 |
Date getDate(Property property) 返回 Date 元資料屬性的值。 |
| 6 |
String[] getValues(Property property) 返回元資料屬性的所有值。 |
| 7 |
String[] getValues(String name) 返回給定元資料名稱的所有值。 |
| 8 |
String[] names() 返回元資料物件中元資料元素的所有名稱。 |
| 9 |
set(Property property, Date date) 設定給定元資料屬性的日期值 |
| 10 |
set(Property property, String[] values) 將多個值設定為元資料屬性。 |
Language Identifier 類
此類識別給定內容的語言。下表列出了此類的建構函式及其描述。
包 - org.apache.tika.language
類 - LanguageIdentifier
| 序號 | 建構函式和說明 |
|---|---|
| 1 |
LanguageIdentifier(LanguageProfile profile) 例項化語言識別器。在這裡,您必須將 LanguageProfile 物件作為引數傳遞。 |
| 2 |
LanguageIdentifier(String content) 此建構函式可以透過傳遞文字內容的字串來例項化語言識別器。 |
| 序號 | 方法和說明 |
|---|---|
| 1 |
String getLanguage() 返回給定當前 LanguageIdentifier 物件的語言。 |
TIKA - 檔案格式
Tika 支援的檔案格式
下表顯示了 Tika 支援的檔案格式。
| 檔案格式 | 包庫 | Tika 中的類 |
|---|---|---|
| XML | org.apache.tika.parser.xml | XMLParser |
| HTML | org.apache.tika.parser.html,並使用 Tagsoup 庫 | HtmlParser |
| MS-Office 複合文件 Ole2(2007 年以前)和 ooxml(2007 年及以後) | org.apache.tika.parser.microsoft org.apache.tika.parser.microsoft.ooxml,並使用 Apache Poi 庫 |
OfficeParser (ole2) OOXMLParser (ooxml) |
| OpenDocument 格式 (OpenOffice) | org.apache.tika.parser.odf | OpenOfficeParser |
| 行動式文件格式 (PDF) | org.apache.tika.parser.pdf,此包使用 Apache PdfBox 庫 | PDFParser |
| 電子出版物格式(電子書) | org.apache.tika.parser.epub | EpubParser |
| 富文字格式 | org.apache.tika.parser.rtf | RTFParser |
| 壓縮和打包格式 | org.apache.tika.parser.pkg,此包使用 Common Compress 庫 | PackageParser 和 CompressorParser 及其子類 |
| 文字格式 | org.apache.tika.parser.txt | TXTParser |
| Feed 和聚合格式 | org.apache.tika.parser.feed | FeedParser |
| 音訊格式 | org.apache.tika.parser.audio 和 org.apache.tika.parser.mp3 | AudioParser、MidiParser、Mp3Parser(用於 mp3 解析) |
| 影像解析器 | org.apache.tika.parser.jpeg | JpegParser(用於 jpeg 圖片) |
| 影片格式 | org.apache.tika.parser.mp4 和 org.apache.tika.parser.video,此解析器內部使用簡單的演算法來解析 Flash 影片格式 | Mp4Parser、FlvParser |
| Java 類檔案和 jar 檔案 | org.apache.tika.parser.asm | ClassParser、CompressorParser |
| mbox 格式(電子郵件) | org.apache.tika.parser.mbox | MboxParser |
| CAD 格式 | org.apache.tika.parser.dwg | DWGParser |
| 字型格式 | org.apache.tika.parser.font | TrueTypeParser |
| 可執行程式和庫 | org.apache.tika.parser.executable | ExecutableParser |
TIKA - 文件型別檢測
MIME 標準
多用途網際網路郵件擴充套件 (MIME) 標準是識別文件型別的最佳可用標準。瞭解這些標準有助於瀏覽器在內部互動期間進行操作。
當瀏覽器遇到媒體檔案時,它會選擇與其相容的可用軟體來顯示其內容。如果它沒有任何合適的應用程式來執行特定的媒體檔案,它會建議使用者獲取合適的外掛軟體。
Tika 中的型別檢測
Tika 支援 MIME 中提供的所有網際網路媒體文件型別。當檔案透過 Tika 傳遞時,它會檢測檔案及其文件型別。為了檢測媒體型別,Tika 內部使用以下機制。
副檔名
檢查副檔名是檢測檔案格式最簡單、最常用的方法。許多應用程式和作業系統都支援這些副檔名。以下是幾種已知檔案型別的副檔名。
| 檔名 | 副檔名 |
|---|---|
| 影像 | .jpg |
| 音訊 | .mp3 |
| Java 存檔檔案 | .jar |
| Java 類檔案 | .class |
內容型別提示
當您從資料庫檢索檔案或將其附加到另一個文件時,您可能會丟失檔案的名稱或副檔名。在這種情況下,使用與檔案一起提供的元資料來檢測副檔名。
魔數字節
觀察檔案的原始位元組,您可以找到每個檔案的一些獨特的字元模式。某些檔案具有特殊的位元組字首,稱為**魔數字節**,這些位元組是專門製作幷包含在檔案中用於識別檔案型別的。
例如,您可以在 Java 檔案中找到 CA FE BA BE(十六進位制格式),在 PDF 檔案中找到 %PDF(ASCII 格式)。Tika 使用此資訊來識別檔案的媒體型別。
字元編碼
包含純文字的檔案使用不同型別的字元編碼進行編碼。這裡的主要挑戰是識別檔案中使用的字元編碼型別。Tika 使用**BOM 標記**和**位元組頻率**等字元編碼技術來識別純文字內容使用的編碼系統。
XML 根字元
為了檢測 XML 文件,Tika 解析 XML 文件並提取資訊,例如根元素、名稱空間和引用的模式,從中可以找到檔案的真實媒體型別。
使用外觀類進行型別檢測
外觀類的 `detect()` 方法用於檢測文件型別。此方法接受檔案作為輸入。以下是使用 Tika 外觀類進行文件型別檢測的示例程式。
import java.io.File;
import org.apache.tika.Tika;
public class Typedetection {
public static void main(String[] args) throws Exception {
//assume example.mp3 is in your current directory
File file = new File("example.mp3");//
//Instantiating tika facade class
Tika tika = new Tika();
//detecting the file type using detect method
String filetype = tika.detect(file);
System.out.println(filetype);
}
}
將上述程式碼儲存為 TypeDetection.java,並使用以下命令從命令提示符執行它:
javac TypeDetection.java java TypeDetection audio/mpeg
TIKA - 內容提取
Tika 使用各種解析器庫從給定的解析器中提取內容。它選擇正確的解析器來提取給定的文件型別。
為了解析文件,通常使用 Tika 外觀類的 `parseToString()` 方法。以下是解析過程中涉及的步驟,這些步驟由 Tika ParsertoString() 方法進行抽象。
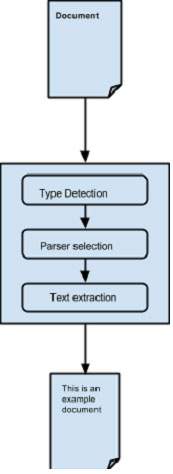
抽象解析過程:
最初,當我們將文件傳遞給 Tika 時,它會使用其可用的合適的型別檢測機制並檢測文件型別。
一旦知道文件型別,它就會從其解析器儲存庫中選擇合適的解析器。解析器儲存庫包含使用外部庫的類。
然後將文件傳遞給選擇的解析器,該解析器將解析內容、提取文字,併為不可讀的格式丟擲異常。
使用 Tika 進行內容提取
以下是使用 Tika 外觀類從檔案中提取文字的程式:
import java.io.File;
import java.io.IOException;
import org.apache.tika.Tika;
import org.apache.tika.exception.TikaException;
import org.xml.sax.SAXException;
public class TikaExtraction {
public static void main(final String[] args) throws IOException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//Instantiating Tika facade class
Tika tika = new Tika();
String filecontent = tika.parseToString(file);
System.out.println("Extracted Content: " + filecontent);
}
}
將上述程式碼儲存為 TikaExtraction.java,並從命令提示符執行它:
javac TikaExtraction.java java TikaExtraction
以下是 sample.txt 的內容。
Hi students welcome to tutorialspoint
它會給出以下輸出:
Extracted Content: Hi students welcome to tutorialspoint
使用解析器介面進行內容提取
Tika 的解析器包提供了幾個介面和類,我們可以使用它們來解析文字文件。以下是 **org.apache.tika.parser** 包的框圖。
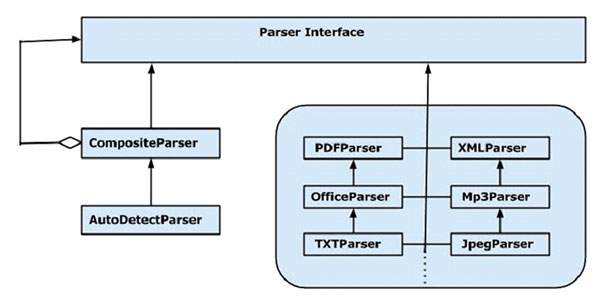
有幾個可用的解析器類,例如 pdf 解析器、Mp3Passer、OfficeParser 等,用於分別解析各個文件。所有這些類都實現瞭解析器介面。
CompositeParser
該圖顯示了 Tika 的通用解析器類:**CompositeParser** 和 **AutoDetectParser**。由於 CompositeParser 類遵循組合設計模式,您可以將一組解析器例項用作單個解析器。CompositeParser 類還允許訪問實現解析器介面的所有類。
AutoDetectParser
這是 CompositeParser 的子類,它提供自動型別檢測。使用此功能,AutoDetectParser 使用組合方法自動將傳入的文件傳送到相應的解析器類。
parse() 方法
除了 `parseToString()` 之外,您還可以使用解析器介面的 `parse()` 方法。此方法的原型如下所示。
parse(InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context)
下表列出了它作為引數接受的四個物件。
| 序號 | 物件和說明 |
|---|---|
| 1 |
InputStream stream 任何包含檔案內容的 Inputstream 物件 |
| 2 |
ContentHandler handler Tika 將文件作為 XHTML 內容傳遞給此處理程式,然後使用 SAX API 處理文件。它提供對文件中內容的高效後處理。 |
| 3 |
Metadata metadata 元資料物件既用作文件元資料的源,也用作目標。 |
| 4 |
ParseContext context 當客戶端應用程式想要自定義解析過程時,使用此物件。 |
示例
以下是顯示如何使用 `parse()` 方法的示例。
**步驟 1**:
要使用解析器介面的 `parse()` 方法,請例項化為此介面提供實現的任何類。
有一些單獨的解析器類,例如 PDFParser、OfficeParser、XMLParser 等。您可以使用任何這些單獨的文件解析器。或者,您可以使用 CompositeParser 或 AutoDetectParser,它在內部使用所有解析器類,並使用合適的解析器提取文件的內容。
Parser parser = new AutoDetectParser(); (or) Parser parser = new CompositeParser(); (or) object of any individual parsers given in Tika Library
**步驟 2**:
建立處理程式類物件。以下是三個內容處理程式:
| 序號 | 類和說明 |
|---|---|
| 1 |
BodyContentHandler 此類選擇 XHTML 輸出的主體部分並將該內容寫入輸出寫入器或輸出流。然後它將 XHTML 內容重定向到另一個內容處理程式例項。 |
| 2 |
LinkContentHandler 此類檢測並選擇 XHTML 文件的所有 H-Ref 標籤,並將其轉發給 Web 抓取工具等工具使用。 |
| 3 |
TeeContentHandler 此類有助於同時使用多種工具。 |
由於我們的目標是從文件中提取文字內容,因此請按如下所示例項化 BodyContentHandler:
BodyContentHandler handler = new BodyContentHandler( );
**步驟 3**:
建立元資料物件,如下所示:
Metadata metadata = new Metadata();
**步驟 4**:
建立任何輸入流物件,並將應從中提取的檔案傳遞給它。
FileInputstream
透過將檔案路徑作為引數傳遞來例項化檔案物件,並將此物件傳遞給 FileInputStream 類的建構函式。
**注意**:傳遞給檔案物件的路徑不應包含空格。
這些輸入流類的問題在於它們不支援隨機訪問讀取,而這對於有效處理某些檔案格式是必需的。為了解決這個問題,Tika 提供了 TikaInputStream。
File file = new File(filepath) FileInputStream inputstream = new FileInputStream(file); (or) InputStream stream = TikaInputStream.get(new File(filename));
**步驟 5**:
建立解析上下文物件,如下所示:
ParseContext context =new ParseContext();
**步驟 6**:
例項化解析器物件,呼叫 parse 方法,並傳遞所有必需的物件,如下所示:
parser.parse(inputstream, handler, metadata, context);
以下是使用解析器介面進行內容提取的程式:
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class ParserExtraction {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//parse method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//parsing the file
parser.parse(inputstream, handler, metadata, context);
System.out.println("File content : " + Handler.toString());
}
}
將上述程式碼儲存為 ParserExtraction.java,並從命令提示符執行它:
javac ParserExtraction.java java ParserExtraction
以下是 sample.txt 的內容
Hi students welcome to tutorialspoint
如果執行上述程式,它將給出以下輸出:
File content : Hi students welcome to tutorialspoint
TIKA - 元資料提取
除了內容外,Tika 還會從檔案中提取元資料。元資料只不過是與檔案一起提供的附加資訊。如果我們考慮一個音訊檔案,藝術家姓名、專輯名稱、標題都屬於元資料。
XMP 標準
可擴充套件元資料平臺 (XMP) 是用於處理和儲存與檔案內容相關資訊的標準。它由Adobe Systems Inc建立。XMP 提供定義、建立和處理元資料的標準。您可以將此標準嵌入到多種檔案格式中,例如PDF、JPEG、JPEG 2000、GIF、PNG、HTML等。
屬性類
Tika 使用 Property 類來遵循 XMP 屬性定義。它提供PropertyType和ValueType列舉來捕獲元資料的名稱和值。
Metadata 類
此類實現各種介面,例如 ClimateForcast、CativeCommons、Geographic 和 TIFF 等,以提供對各種元資料模型的支援。此外,此類還提供多種方法來提取檔案中的內容。
元資料名稱
我們可以使用 names() 方法從檔案的元資料物件中提取所有元資料名稱列表。它返回所有名稱作為字串陣列。使用元資料名稱,我們可以使用 **get()** 方法獲取值。它接收一個元資料名稱並返回與其關聯的值。
String[] metadaNames = metadata.names(); String value = metadata.get(name);
使用 Parse 方法提取元資料
每當我們使用 parse() 解析檔案時,我們都會將一個空的元資料物件作為引數之一傳遞。此方法提取給定檔案的元資料(如果該檔案包含任何元資料),並將它們放入元資料物件中。因此,使用 parse() 解析檔案後,我們可以從該物件中提取元資料。
Parser parser = new AutoDetectParser(); BodyContentHandler handler = new BodyContentHandler(); Metadata metadata = new Metadata(); //empty metadata object FileInputStream inputstream = new FileInputStream(file); ParseContext context = new ParseContext(); parser.parse(inputstream, handler, metadata, context); // now this metadata object contains the extracted metadata of the given file. metadata.metadata.names();
以下是從文字檔案提取元資料的完整程式。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class GetMetadata {
public static void main(final String[] args) throws IOException, TikaException {
//Assume that boy.jpg is in your current directory
File file = new File("boy.jpg");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
parser.parse(inputstream, handler, metadata, context);
System.out.println(handler.toString());
//getting the list of all meta data elements
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
將上述程式碼儲存為 GetMetadata.java,並使用以下命令從命令提示符執行它:
javac GetMetadata .java java GetMetadata
以下是 boy.jpg 的快照
如果執行上述程式,它將給出以下輸出:
X-Parsed-By: org.apache.tika.parser.DefaultParser Resolution Units: inch Compression Type: Baseline Data Precision: 8 bits Number of Components: 3 tiff:ImageLength: 3000 Component 2: Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert Component 1: Y component: Quantization table 0, Sampling factors 2 horiz/2 vert Image Height: 3000 pixels X Resolution: 300 dots Original Transmission Reference: 53616c7465645f5f2368da84ca932841b336ac1a49edb1a93fae938b8db2cb3ec9cc4dc28d7383f1 Image Width: 4000 pixels IPTC-NAA record: 92 bytes binary data Component 3: Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert tiff:BitsPerSample: 8 Application Record Version: 4 tiff:ImageWidth: 4000 Content-Type: image/jpeg Y Resolution: 300 dots
我們也可以獲取我們想要的元資料值。
新增新的元資料值
我們可以使用元資料類的 add() 方法新增新的元資料值。以下是此方法的語法。在這裡,我們新增作者姓名。
metadata.add(“author”,”Tutorials point”);
Metadata 類具有預定義的屬性,包括從 ClimateForcast、CativeCommons、Geographic 等類繼承的屬性,以支援各種資料模型。下面顯示的是 Tika 實現的 TIFF 介面繼承的 SOFTWARE 資料型別的用法,以遵循 TIFF 影像格式的 XMP 元資料標準。
metadata.add(Metadata.SOFTWARE,"ms paint");
以下是演示如何向給定檔案新增元資料值的完整程式。此處在輸出中顯示元資料元素列表,以便您可以觀察新增新值後列表的變化。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Arrays;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class AddMetadata {
public static void main(final String[] args) throws IOException, SAXException, TikaException {
//create a file object and assume sample.txt is in your current directory
File file = new File("Example.txt");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//parsing the document
parser.parse(inputstream, handler, metadata, context);
//list of meta data elements before adding new elements
System.out.println( " metadata elements :" +Arrays.toString(metadata.names()));
//adding new meta data name value pair
metadata.add("Author","Tutorials Point");
System.out.println(" metadata name value pair is successfully added");
//printing all the meta data elements after adding new elements
System.out.println("Here is the list of all the metadata
elements after adding new elements");
System.out.println( Arrays.toString(metadata.names()));
}
}
將上述程式碼儲存為 AddMetadata.java 類,並從命令提示符執行它:
javac AddMetadata .java java AddMetadata
以下是 Example.txt 的內容
Hi students welcome to tutorialspoint
如果執行上述程式,它將給出以下輸出:
metadata elements of the given file : [Content-Encoding, Content-Type] enter the number of metadata name value pairs to be added 1 enter metadata1name: Author enter metadata1value: Tutorials point metadata name value pair is successfully added Here is the list of all the metadata elements after adding new elements [Content-Encoding, Author, Content-Type]
將值設定為現有元資料元素
您可以使用 set() 方法將值設定為現有元資料元素。使用 set() 方法設定 date 屬性的語法如下:
metadata.set(Metadata.DATE, new Date());
您還可以使用 set() 方法將多個值設定為屬性。使用 set() 方法將多個值設定為 Author 屬性的語法如下:
metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin ");
以下是演示 set() 方法的完整程式。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Date;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class SetMetadata {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//Create a file object and assume example.txt is in your current directory
File file = new File("example.txt");
//parameters of parse() method
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//Parsing the given file
parser.parse(inputstream, handler, metadata, context);
//list of meta data elements elements
System.out.println( " metadata elements and values of the given file :");
String[] metadataNamesb4 = metadata.names();
for(String name : metadataNamesb4) {
System.out.println(name + ": " + metadata.get(name));
}
//setting date meta data
metadata.set(Metadata.DATE, new Date());
//setting multiple values to author property
metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin ");
//printing all the meta data elements with new elements
System.out.println("List of all the metadata elements after adding new elements ");
String[] metadataNamesafter = metadata.names();
for(String name : metadataNamesafter) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
將上述程式碼儲存為 SetMetadata.java,並從命令提示符執行它:
javac SetMetadata.java java SetMetadata
以下是 example.txt 的內容。
Hi students welcome to tutorialspoint
如果執行上述程式,將得到以下輸出。在輸出中,您可以觀察到新新增的元資料元素。
metadata elements and values of the given file : Content-Encoding: ISO-8859-1 Content-Type: text/plain; charset = ISO-8859-1 Here is the list of all the metadata elements after adding new elements date: 2014-09-24T07:01:32Z Content-Encoding: ISO-8859-1 Author: ram, raheem, robin Content-Type: text/plain; charset = ISO-8859-1
TIKA - 語言檢測
語言檢測的必要性
對於基於多語言網站中所寫語言對文件進行分類,需要一個語言檢測工具。此工具應接受沒有語言註釋(元資料)的文件,並透過檢測語言在文件的元資料中新增該資訊。
用於分析語料庫的演算法
什麼是語料庫?
為了檢測文件的語言,會構建語言配置檔案並將其與已知語言的配置檔案進行比較。這些已知語言的文字集稱為 **語料庫**。
語料庫是書面語言文字的集合,它解釋瞭如何在實際情況下使用該語言。
語料庫是從書籍、成績單和其他資料資源(如網際網路)中開發的。語料庫的準確性取決於我們用來構建語料庫的分析演算法。
什麼是分析演算法?
檢測語言的常用方法是使用字典。給定文字中使用的單詞將與字典中的單詞進行匹配。
在一個語言中使用的常用詞列表將是檢測特定語言最簡單有效的語料庫,例如,英語中的冠詞 **a**、**an**、**the**。
使用詞集作為語料庫
使用詞集,構建一個簡單的演算法來查詢兩個語料庫之間的距離,這將等於匹配詞的頻率差異之和。
此類演算法存在以下問題:
由於匹配詞的頻率非常低,因此該演算法無法有效地處理只有幾句話的小文字。它需要大量的文字才能進行準確匹配。
它無法檢測具有複合句的語言的詞邊界,以及那些沒有空格或標點符號等詞分隔符的語言的詞邊界。
由於使用詞集作為語料庫存在這些困難,因此會考慮單個字元或字元組。
使用字元集作為語料庫
由於在一個語言中常用的字元數量有限,因此很容易應用基於詞頻而不是字元的演算法。對於一種或極少數語言使用的某些字元集,此演算法效果更好。
此演算法存在以下缺點:
難以區分字元頻率相似的兩種語言。
沒有特定的工具或演算法可以專門利用(作為語料庫)多種語言使用的字元集來識別一種語言。
N 元語法演算法
上述缺點導致了一種新的方法,即使用給定長度的字元序列來分析語料庫。這樣的字元序列通常稱為 N 元語法,其中 N 代表字元序列的長度。
N 元語法演算法是有效的語言檢測方法,尤其是在英語等歐洲語言的情況下。
此演算法適用於短文字。
儘管存在更高階的語言分析演算法來檢測多語言文件中的多種語言,並具有更具吸引力的功能,但 Tika 使用 3 元語法演算法,因為它適用於大多數實際情況。
Tika 中的語言檢測
在 ISO 639-1 標準化的所有 184 種標準語言中,Tika 可以檢測 18 種語言。Tika 中的語言檢測是使用 **LanguageIdentifier** 類的 **getLanguage()** 方法完成的。此方法以字串格式返回語言的程式碼名稱。以下是 Tika 檢測到的 18 個語言程式碼對列表:
| da——丹麥語 | de——德語 | et——愛沙尼亞語 | el——希臘語 |
| en——英語 | es——西班牙語 | fi——芬蘭語 | fr——法語 |
| hu——匈牙利語 | is——冰島語 | it——義大利語 | nl——荷蘭語 |
| no——挪威語 | pl——波蘭語 | pt——葡萄牙語 | ru——俄語 |
| sv——瑞典語 | th——泰語 |
例項化 **LanguageIdentifier** 類時,應傳遞要提取的內容的字串格式或 **LanguageProfile** 類物件。
LanguageIdentifier object = new LanguageIdentifier(“this is english”);
以下是 Tika 中語言檢測的示例程式。
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.language.LanguageIdentifier;
import org.xml.sax.SAXException;
public class LanguageDetection {
public static void main(String args[])throws IOException, SAXException, TikaException {
LanguageIdentifier identifier = new LanguageIdentifier("this is english ");
String language = identifier.getLanguage();
System.out.println("Language of the given content is : " + language);
}
}
將上述程式碼儲存為 **LanguageDetection.java**,並使用以下命令從命令提示符執行它:
javac LanguageDetection.java java LanguageDetection
如果執行上述程式,則會得到以下輸出:
Language of the given content is : en
文件的語言檢測
要檢測給定文件的語言,必須使用 parse() 方法對其進行解析。parse() 方法解析內容並將其儲存在作為引數之一傳遞給它的處理程式物件中。將處理程式物件的字串格式傳遞給 **LanguageIdentifier** 類的建構函式,如下所示:
parser.parse(inputstream, handler, metadata, context); LanguageIdentifier object = new LanguageIdentifier(handler.toString());
以下是演示如何檢測給定文件的語言的完整程式:
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.language.*;
import org.xml.sax.SAXException;
public class DocumentLanguageDetection {
public static void main(final String[] args) throws IOException, SAXException, TikaException {
//Instantiating a file object
File file = new File("Example.txt");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream content = new FileInputStream(file);
//Parsing the given document
parser.parse(content, handler, metadata, new ParseContext());
LanguageIdentifier object = new LanguageIdentifier(handler.toString());
System.out.println("Language name :" + object.getLanguage());
}
}
將上述程式碼儲存為 SetMetadata.java,並從命令提示符執行它:
javac SetMetadata.java java SetMetadata
以下是 Example.txt 的內容。
Hi students welcome to tutorialspoint
如果執行上述程式,它將給出以下輸出:
Language name :en
除了 Tika jar 之外,Tika 還提供了一個圖形使用者介面應用程式 (GUI) 和一個命令列介面 (CLI) 應用程式。您可以像其他 Java 應用程式一樣,從命令提示符執行 Tika 應用程式。
TIKA - 圖形使用者介面 (GUI)
圖形使用者介面 (GUI)
Tika 在以下連結 https://tika.apache.org/download.html 中提供其原始碼及其 jar 檔案。
下載這兩個檔案,設定 jar 檔案的類路徑。
解壓縮原始碼 zip 資料夾,開啟 tika-app 資料夾。
在解壓縮的資料夾“tika-1.6\tika-app\src\main\java\org\apache\Tika\gui”中,您將看到兩個類檔案:**ParsingTransferHandler.java** 和 **TikaGUI.java**。
編譯這兩個類檔案並執行 TikaGUI.java 類檔案,它將開啟以下視窗。
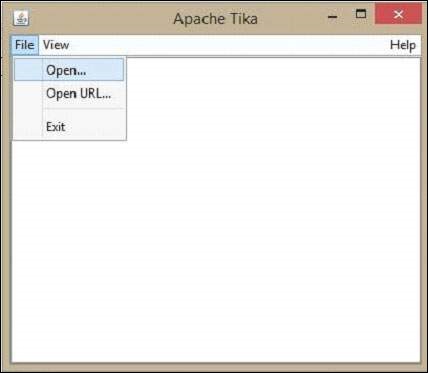
現在讓我們看看如何使用 Tika GUI。
在 GUI 上,單擊開啟,瀏覽並選擇要提取的檔案,或將其拖放到視窗的空白處。
Tika 提取檔案的內容並以五種不同的格式顯示它,即後設資料、格式化文字、純文字、主要內容和結構化文字。您可以選擇任何您想要的格式。
同樣,您還將在“tika-1.6\tikaapp\src\main\java\org\apache\tika\cli”資料夾中找到 CLI 類。
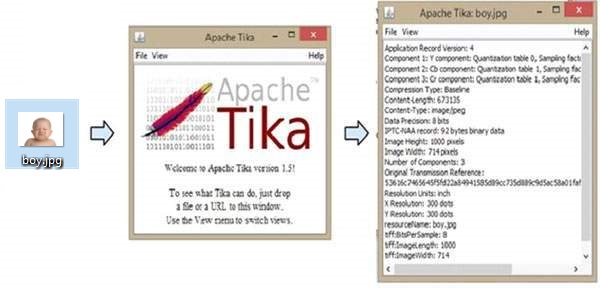
下圖顯示了 Tika 的功能。當我們將影像拖放到 GUI 上時,Tika 會提取並顯示其元資料。
TIKA - 提取 PDF
以下是從 PDF 提取內容和元資料的程式。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.pdf.PDFParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class PdfParse {
public static void main(final String[] args) throws IOException,TikaException {
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.pdf"));
ParseContext pcontext = new ParseContext();
//parsing the document using PDF parser
PDFParser pdfparser = new PDFParser();
pdfparser.parse(inputstream, handler, metadata,pcontext);
//getting the content of the document
System.out.println("Contents of the PDF :" + handler.toString());
//getting metadata of the document
System.out.println("Metadata of the PDF:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name+ " : " + metadata.get(name));
}
}
}
將上述程式碼儲存為 **PdfParse.java**,並使用以下命令從命令提示符編譯它:
javac PdfParse.java java PdfParse
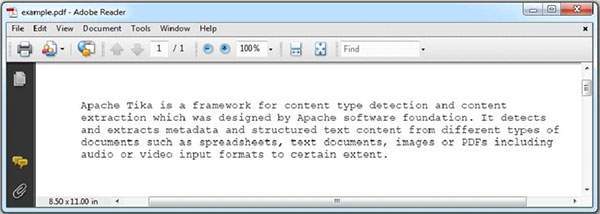
以下是 example.pdf 的快照
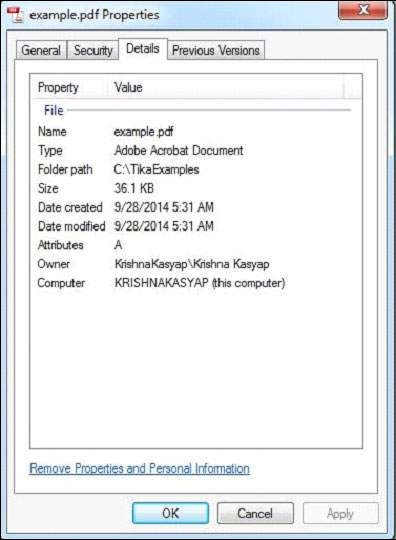
我們傳遞的 PDF 具有以下屬性:
編譯程式後,您將得到如下所示的輸出。
**輸出**:
Contents of the PDF: Apache Tika is a framework for content type detection and content extraction which was designed by Apache software foundation. It detects and extracts metadata and structured text content from different types of documents such as spreadsheets, text documents, images or PDFs including audio or video input formats to certain extent. Metadata of the PDF: dcterms:modified : 2014-09-28T12:31:16Z meta:creation-date : 2014-09-28T12:31:16Z meta:save-date : 2014-09-28T12:31:16Z dc:creator : Krishna Kasyap pdf:PDFVersion : 1.5 Last-Modified : 2014-09-28T12:31:16Z Author : Krishna Kasyap dcterms:created : 2014-09-28T12:31:16Z date : 2014-09-28T12:31:16Z modified : 2014-09-28T12:31:16Z creator : Krishna Kasyap xmpTPg:NPages : 1 Creation-Date : 2014-09-28T12:31:16Z pdf:encrypted : false meta:author : Krishna Kasyap created : Sun Sep 28 05:31:16 PDT 2014 dc:format : application/pdf; version = 1.5 producer : Microsoft® Word 2013 Content-Type : application/pdf xmp:CreatorTool : Microsoft® Word 2013 Last-Save-Date : 2014-09-28T12:31:16Z
TIKA - 提取 ODF
以下是從開放文件格式 (ODF) 提取內容和元資料的程式。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.odf.OpenDocumentParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class OpenDocumentParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example_open_document_presentation.odp"));
ParseContext pcontext = new ParseContext();
//Open Document Parser
OpenDocumentParser openofficeparser = new OpenDocumentParser ();
openofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}
將以上程式碼儲存為OpenDocumentParse.java,然後使用以下命令在命令提示符中編譯:
javac OpenDocumentParse.java java OpenDocumentParse
以下是example_open_document_presentation.odp檔案的快照。

此文件具有以下屬性:
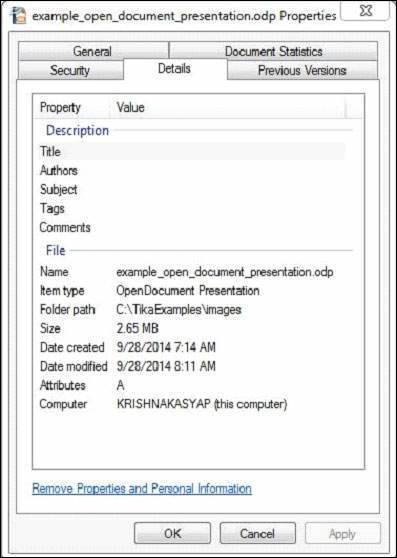
編譯程式後,您將獲得以下輸出。
**輸出**:
Contents of the document: Apache Tika Apache Tika is a framework for content type detection and content extraction which was designed by Apache software foundation. It detects and extracts metadata and structured text content from different types of documents such as spreadsheets, text documents, images or PDFs including audio or video input formats to certain extent. Metadata of the document: editing-cycles: 4 meta:creation-date: 2009-04-16T11:32:32.86 dcterms:modified: 2014-09-28T07:46:13.03 meta:save-date: 2014-09-28T07:46:13.03 Last-Modified: 2014-09-28T07:46:13.03 dcterms:created: 2009-04-16T11:32:32.86 date: 2014-09-28T07:46:13.03 modified: 2014-09-28T07:46:13.03 nbObject: 36 Edit-Time: PT32M6S Creation-Date: 2009-04-16T11:32:32.86 Object-Count: 36 meta:object-count: 36 generator: OpenOffice/4.1.0$Win32 OpenOffice.org_project/410m18$Build-9764 Content-Type: application/vnd.oasis.opendocument.presentation Last-Save-Date: 2014-09-28T07:46:13.03
TIKA - 提取 MS Office 檔案
以下是用於從Microsoft Office文件中提取內容和元資料的程式。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.microsoft.ooxml.OOXMLParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class MSExcelParse {
public static void main(final String[] args) throws IOException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example_msExcel.xlsx"));
ParseContext pcontext = new ParseContext();
//OOXml parser
OOXMLParser msofficeparser = new OOXMLParser ();
msofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
將以上程式碼儲存為MSExelParse.java,然後使用以下命令在命令提示符中進行編譯:
javac MSExcelParse.java java MSExcelParse
這裡我們正在傳遞以下示例Excel檔案。
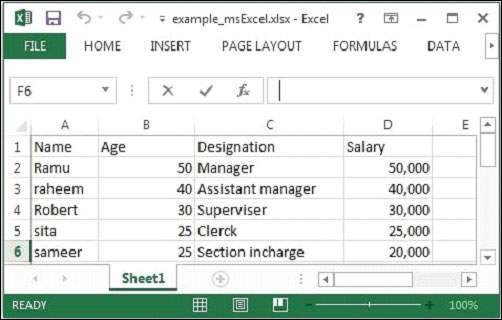
給定的Excel檔案具有以下屬性:
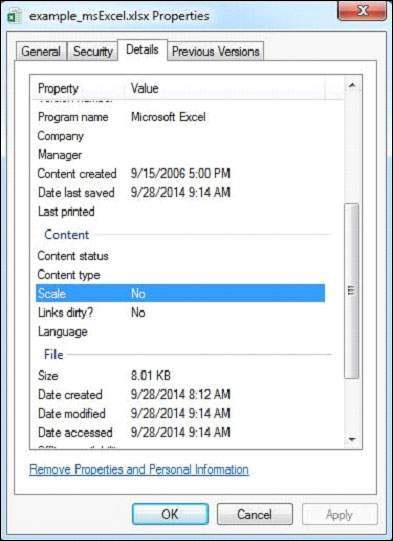
執行上述程式後,您將獲得以下輸出。
**輸出**:
Contents of the document: Sheet1 Name Age Designation Salary Ramu 50 Manager 50,000 Raheem 40 Assistant manager 40,000 Robert 30 Superviser 30,000 sita 25 Clerk 25,000 sameer 25 Section in-charge 20,000 Metadata of the document: meta:creation-date: 2006-09-16T00:00:00Z dcterms:modified: 2014-09-28T15:18:41Z meta:save-date: 2014-09-28T15:18:41Z Application-Name: Microsoft Excel extended-properties:Company: dcterms:created: 2006-09-16T00:00:00Z Last-Modified: 2014-09-28T15:18:41Z Application-Version: 15.0300 date: 2014-09-28T15:18:41Z publisher: modified: 2014-09-28T15:18:41Z Creation-Date: 2006-09-16T00:00:00Z extended-properties:AppVersion: 15.0300 protected: false dc:publisher: extended-properties:Application: Microsoft Excel Content-Type: application/vnd.openxmlformats-officedocument.spreadsheetml.sheet Last-Save-Date: 2014-09-28T15:18:41Z
TIKA - 提取文字文件
以下是用於從文字文件中提取內容和元資料的程式:
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.parser.txt.TXTParser;
import org.xml.sax.SAXException;
public class TextParser {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.txt"));
ParseContext pcontext=new ParseContext();
//Text document parser
TXTParser TexTParser = new TXTParser();
TexTParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}
將以上程式碼儲存為TextParser.java,然後使用以下命令在命令提示符中進行編譯:
javac TextParser.java java TextParser
以下是sample.txt檔案的快照:
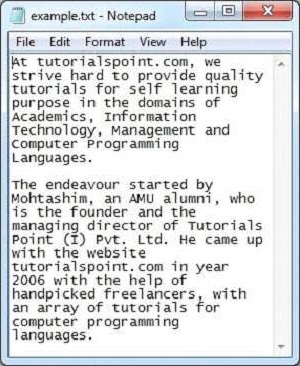
文字文件具有以下屬性:
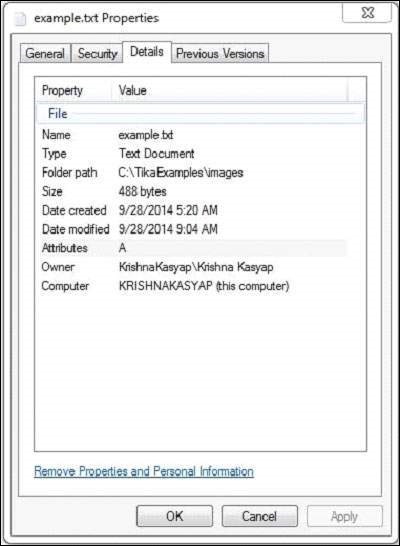
如果執行上述程式,它將提供以下輸出。
**輸出**:
Contents of the document: At tutorialspoint.com, we strive hard to provide quality tutorials for self-learning purpose in the domains of Academics, Information Technology, Management and Computer Programming Languages. The endeavour started by Mohtashim, an AMU alumni, who is the founder and the managing director of Tutorials Point (I) Pvt. Ltd. He came up with the website tutorialspoint.com in year 2006 with the help of handpicked freelancers, with an array of tutorials for computer programming languages. Metadata of the document: Content-Encoding: windows-1252 Content-Type: text/plain; charset = windows-1252
TIKA - 提取 HTML 文件
以下是用於從HTML文件中提取內容和元資料的程式。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.html.HtmlParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class HtmlParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.html"));
ParseContext pcontext = new ParseContext();
//Html parser
HtmlParser htmlparser = new HtmlParser();
htmlparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
將以上程式碼儲存為HtmlParse.java,然後使用以下命令在命令提示符中進行編譯:
javac HtmlParse.java java HtmlParse
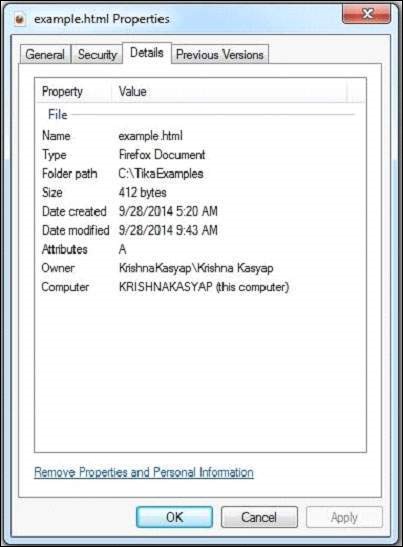
以下是example.txt檔案的快照。
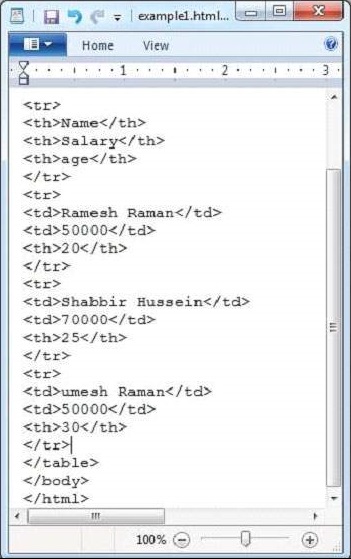
HTML文件具有以下屬性:
如果執行上述程式,它將提供以下輸出。
**輸出**:
Contents of the document: Name Salary age Ramesh Raman 50000 20 Shabbir Hussein 70000 25 Umesh Raman 50000 30 Somesh 50000 35 Metadata of the document: title: HTML Table Header Content-Encoding: windows-1252 Content-Type: text/html; charset = windows-1252 dc:title: HTML Table Header
TIKA - 提取 XML 文件
以下是用於從XML文件中提取內容和元資料的程式。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.xml.XMLParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class XmlParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("pom.xml"));
ParseContext pcontext = new ParseContext();
//Xml parser
XMLParser xmlparser = new XMLParser();
xmlparser.parse(inputstream, handler, metadata, pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
將以上程式碼儲存為XmlParse.java,然後使用以下命令在命令提示符中進行編譯:
javac XmlParse.java java XmlParse
以下是example.xml檔案的快照
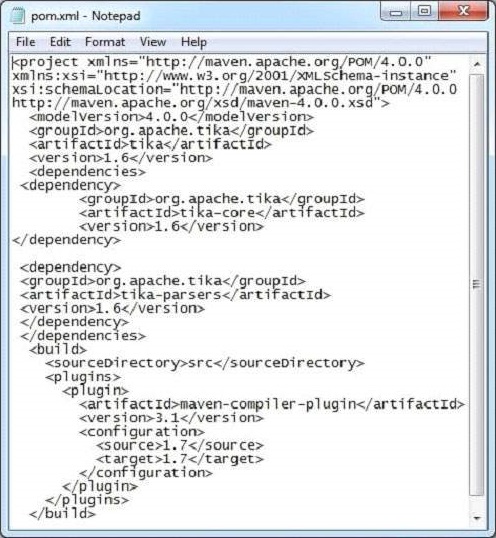
此文件具有以下屬性:
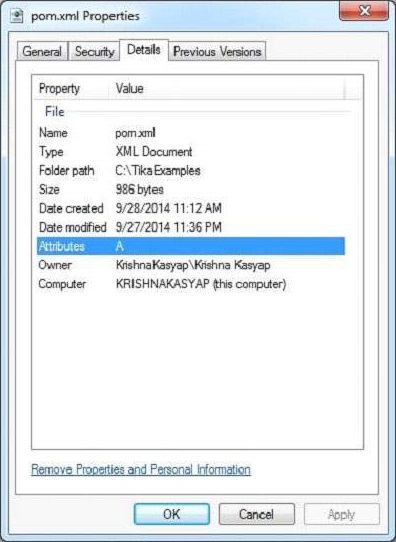
執行上述程式後,您將獲得以下輸出:
**輸出**:
Contents of the document: 4.0.0 org.apache.tika tika 1.6 org.apache.tika tika-core 1.6 org.apache.tika tika-parsers 1.6 src maven-compiler-plugin 3.1 1.7 1.7 Metadata of the document: Content-Type: application/xml
TIKA - 提取 .class 檔案
以下是用於從.class檔案中提取內容和元資料的程式。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.asm.ClassParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class JavaClassParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.class"));
ParseContext pcontext = new ParseContext();
//Html parser
ClassParser ClassParser = new ClassParser();
ClassParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}
將以上程式碼儲存為JavaClassParse.java,然後使用以下命令在命令提示符中進行編譯:
javac JavaClassParse.java java JavaClassParse
以下是Example.java的快照,編譯後將生成Example.class。
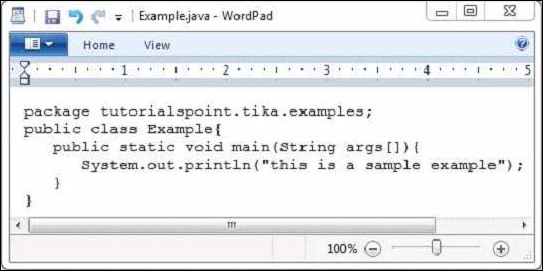
Example.class檔案具有以下屬性:
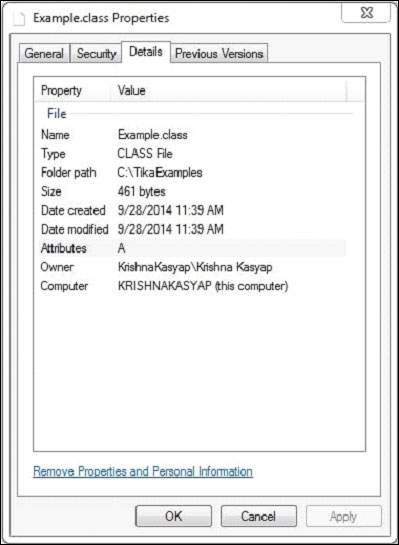
執行上述程式後,您將獲得以下輸出。
**輸出**:
Contents of the document:
package tutorialspoint.tika.examples;
public synchronized class Example {
public void Example();
public static void main(String[]);
}
Metadata of the document:
title: Example
resourceName: Example.class
dc:title: Example
TIKA - 提取 JAR 檔案
以下是用於從Java歸檔(jar)檔案中提取內容和元資料的程式:
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.parser.pkg.PackageParser;
import org.xml.sax.SAXException;
public class PackageParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.jar"));
ParseContext pcontext = new ParseContext();
//Package parser
PackageParser packageparser = new PackageParser();
packageparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document: " + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
將以上程式碼儲存為PackageParse.java,然後使用以下命令在命令提示符中進行編譯:
javac PackageParse.java java PackageParse
以下是位於包內的Example.java的快照。
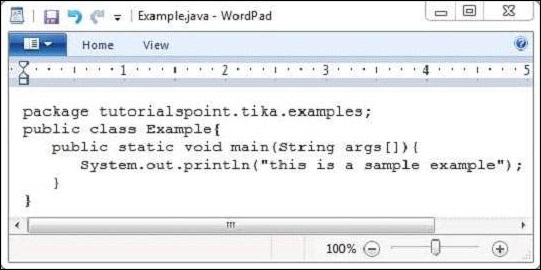
jar檔案具有以下屬性:
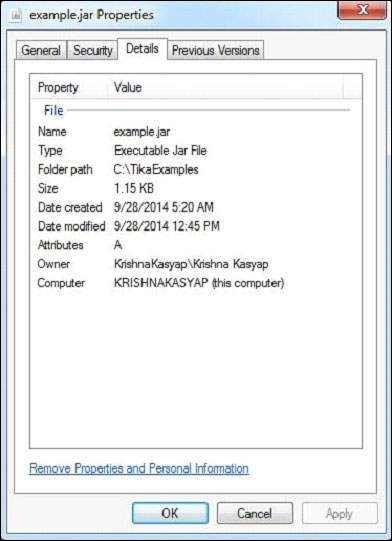
執行上述程式後,它將提供以下輸出:
**輸出**:
Contents of the document: META-INF/MANIFEST.MF tutorialspoint/tika/examples/Example.class Metadata of the document: Content-Type: application/zip
TIKA - 提取影像檔案
以下是用於從JPEG影像中提取內容和元資料的程式。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.jpeg.JpegParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class JpegParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("boy.jpg"));
ParseContext pcontext = new ParseContext();
//Jpeg Parse
JpegParser JpegParser = new JpegParser();
JpegParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
將以上程式碼儲存為JpegParse.java,然後使用以下命令在命令提示符中進行編譯:
javac JpegParse.java java JpegParse
以下是Example.jpeg的快照:
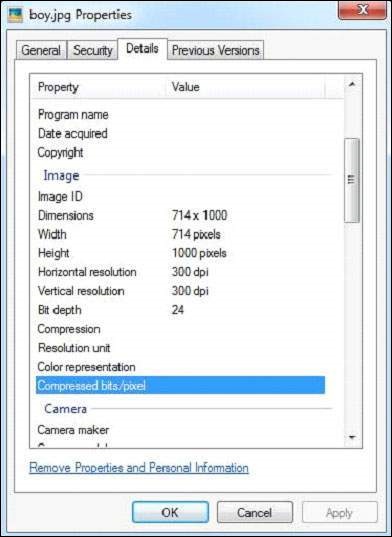
JPEG檔案具有以下屬性:
執行程式後,您將獲得以下輸出。
輸出:
Contents of the document: Meta data of the document: Resolution Units: inch Compression Type: Baseline Data Precision: 8 bits Number of Components: 3 tiff:ImageLength: 3000 Component 2: Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert Component 1: Y component: Quantization table 0, Sampling factors 2 horiz/2 vert Image Height: 3000 pixels X Resolution: 300 dots Original Transmission Reference: 53616c7465645f5f2368da84ca932841b336ac1a49edb1a93fae938b8db2cb3ec9cc4dc28d7383f1 Image Width: 4000 pixels IPTC-NAA record: 92 bytes binary data Component 3: Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert tiff:BitsPerSample: 8 Application Record Version: 4 tiff:ImageWidth: 4000 Y Resolution: 300 dots
TIKA - 提取 mp4 檔案
以下是用於從mp4檔案中提取內容和元資料的程式:
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.mp4.MP4Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class Mp4Parse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.mp4"));
ParseContext pcontext = new ParseContext();
//Html parser
MP4Parser MP4Parser = new MP4Parser();
MP4Parser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document: :" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
將以上程式碼儲存為JpegParse.java,然後使用以下命令在命令提示符中進行編譯:
javac Mp4Parse.java java Mp4Parse
以下是Example.mp4檔案屬性的快照。
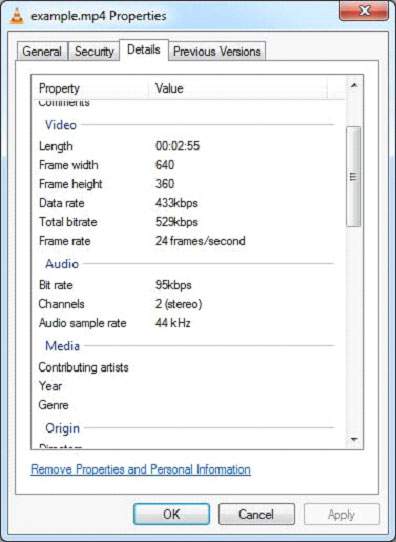
執行上述程式後,您將獲得以下輸出:
**輸出**:
Contents of the document: Metadata of the document: dcterms:modified: 2014-01-06T12:10:27Z meta:creation-date: 1904-01-01T00:00:00Z meta:save-date: 2014-01-06T12:10:27Z Last-Modified: 2014-01-06T12:10:27Z dcterms:created: 1904-01-01T00:00:00Z date: 2014-01-06T12:10:27Z tiff:ImageLength: 360 modified: 2014-01-06T12:10:27Z Creation-Date: 1904-01-01T00:00:00Z tiff:ImageWidth: 640 Content-Type: video/mp4 Last-Save-Date: 2014-01-06T12:10:27Z
TIKA - 提取 mp3 檔案
以下是用於從mp3檔案中提取內容和元資料的程式:
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.mp3.LyricsHandler;
import org.apache.tika.parser.mp3.Mp3Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class Mp3Parse {
public static void main(final String[] args) throws Exception, IOException, SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.mp3"));
ParseContext pcontext = new ParseContext();
//Mp3 parser
Mp3Parser Mp3Parser = new Mp3Parser();
Mp3Parser.parse(inputstream, handler, metadata, pcontext);
LyricsHandler lyrics = new LyricsHandler(inputstream,handler);
while(lyrics.hasLyrics()) {
System.out.println(lyrics.toString());
}
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
將以上程式碼儲存為JpegParse.java,然後使用以下命令在命令提示符中進行編譯:
javac Mp3Parse.java java Mp3Parse
Example.mp3檔案具有以下屬性:
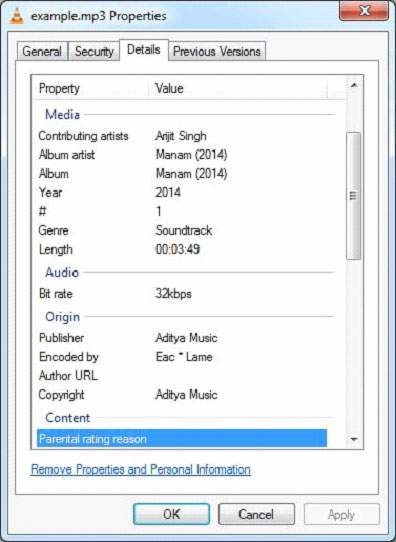
執行程式後,您將獲得以下輸出。如果給定檔案有任何歌詞,我們的應用程式將捕獲並將其與輸出一起顯示。
**輸出**:
Contents of the document: Kanulanu Thaake Arijit Singh Manam (2014), track 01/06 2014 Soundtrack 30171.65 eng - DRGM Arijit Singh Manam (2014), track 01/06 2014 Soundtrack 30171.65 eng - DRGM Metadata of the document: xmpDM:releaseDate: 2014 xmpDM:duration: 30171.650390625 xmpDM:audioChannelType: Stereo dc:creator: Arijit Singh xmpDM:album: Manam (2014) Author: Arijit Singh xmpDM:artist: Arijit Singh channels: 2 xmpDM:audioSampleRate: 44100 xmpDM:logComment: eng - DRGM xmpDM:trackNumber: 01/06 version: MPEG 3 Layer III Version 1 creator: Arijit Singh xmpDM:composer: Music : Anoop Rubens | Lyrics : Vanamali xmpDM:audioCompressor: MP3 title: Kanulanu Thaake samplerate: 44100 meta:author: Arijit Singh xmpDM:genre: Soundtrack Content-Type: audio/mpeg xmpDM:albumArtist: Manam (2014) dc:title: Kanulanu Thaake