- Spark SQL 教程
- Spark SQL - 首頁
- Spark - 簡介
- Spark - RDD
- Spark - 安裝
- Spark SQL - 簡介
- Spark SQL - DataFrame
- Spark SQL - 資料來源
- Spark SQL 有用資源
- Spark SQL 快速指南
- Spark SQL - 有用資源
- Spark SQL - 討論
Spark SQL 快速指南
Spark - 簡介
各行業廣泛使用 Hadoop 來分析其資料集。原因在於 Hadoop 框架基於簡單的程式設計模型(MapReduce),它能夠提供可擴充套件、靈活、容錯且經濟高效的計算解決方案。這裡,主要關注的是在處理大型資料集時保持速度,包括查詢之間的等待時間和程式執行的等待時間。
Apache 軟體基金會推出了 Spark,旨在加快 Hadoop 計算軟體的處理速度。
與普遍的看法相反,Spark 不是 Hadoop 的修改版本,實際上也不依賴於 Hadoop,因為它擁有自己的叢集管理機制。Hadoop 只是實現 Spark 的一種方式。
Spark 以兩種方式使用 Hadoop——一種是儲存,另一種是處理。由於 Spark 擁有自己的叢集管理計算,它只將 Hadoop 用於儲存目的。
Apache Spark
Apache Spark 是一種閃電般快速的叢集計算技術,專為快速計算而設計。它基於 Hadoop MapReduce,並擴充套件了 MapReduce 模型,以便高效地將其用於更多型別的計算,包括互動式查詢和流處理。Spark 的主要特點是其記憶體叢集計算,這提高了應用程式的處理速度。
Spark 旨在涵蓋各種工作負載,例如批處理應用程式、迭代演算法、互動式查詢和流處理。除了支援各個系統中的所有這些工作負載外,它還減少了維護單獨工具的管理負擔。
Apache Spark 的發展
Spark 是 Hadoop 的一個子專案,由 Matei Zaharia 於 2009 年在加州大學伯克利分校的 AMPLab 開發。它於 2010 年在 BSD 許可下開源。它於 2013 年捐贈給 Apache 軟體基金會,現在 Apache Spark 已成為自 2014 年 2 月以來的頂級 Apache 專案。
Apache Spark 的特性
Apache Spark 具有以下特性:
速度 - Spark 有助於在 Hadoop 叢集中執行應用程式,在記憶體中執行速度快達 100 倍,在磁碟上執行速度快達 10 倍。這是透過減少對磁碟的讀/寫操作次數實現的。它將中間處理資料儲存在記憶體中。
支援多種語言 - Spark 提供了 Java、Scala 或 Python 的內建 API。因此,您可以使用不同的語言編寫應用程式。Spark 提供了 80 多個用於互動式查詢的高階運算子。
高階分析 - Spark 不僅支援“Map”和“reduce”,還支援 SQL 查詢、流資料、機器學習 (ML) 和圖演算法。
Spark 基於 Hadoop
下圖顯示了 Spark 如何與 Hadoop 元件結合使用的三種方式。
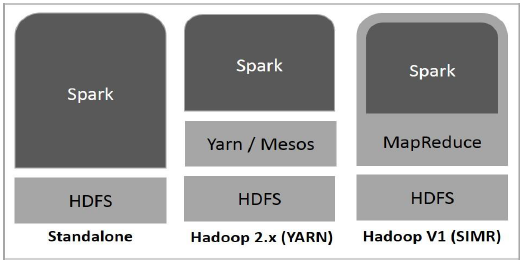
Spark 部署方式如下所述,共有三種。
獨立模式 - Spark 獨立模式部署意味著 Spark 位於 HDFS(Hadoop 分散式檔案系統)之上,併為 HDFS 顯式分配空間。在這裡,Spark 和 MapReduce 將並行執行以覆蓋叢集上的所有 Spark 作業。
Hadoop Yarn - Hadoop Yarn 部署意味著 Spark 執行在 Yarn 上,無需任何預安裝或 root 訪問許可權。它有助於將 Spark 整合到 Hadoop 生態系統或 Hadoop 堆疊中。它允許其他元件在堆疊頂部執行。
Spark in MapReduce (SIMR) - Spark in MapReduce 用於除了獨立部署之外還啟動 Spark 作業。使用 SIMR,使用者可以啟動 Spark 並使用其 shell,而無需任何管理許可權。
Spark 的元件
下圖描述了 Spark 的不同元件。
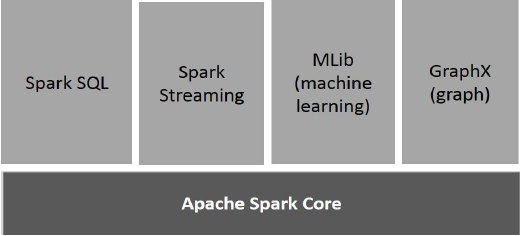
Apache Spark Core
Spark Core 是 Spark 平臺的基礎通用執行引擎,所有其他功能都基於它構建。它提供記憶體計算和引用外部儲存系統中的資料集。
Spark SQL
Spark SQL 是 Spark Core 之上的一個元件,它引入了一種名為 SchemaRDD 的新的資料抽象,該抽象為結構化和半結構化資料提供支援。
Spark Streaming
Spark Streaming 利用 Spark Core 的快速排程功能來執行流分析。它以小批次的形式攝取資料,並在這些小批次資料上執行 RDD(彈性分散式資料集)轉換。
MLlib(機器學習庫)
MLlib 是 Spark 之上的一個分散式機器學習框架,因為它基於分散式記憶體的 Spark 架構。根據 MLlib 開發人員對交替最小二乘法 (ALS) 實現進行的基準測試,Spark MLlib 的速度是 Hadoop 基於磁碟版本的Apache Mahout(在 Mahout 獲得 Spark 介面之前)的九倍。
GraphX
GraphX 是 Spark 之上的一個分散式圖處理框架。它提供了一個用於表達圖計算的 API,可以使用 Pregel 抽象 API 對使用者定義的圖進行建模。它還為此抽象提供了最佳化的執行時。
Spark – RDD
彈性分散式資料集
彈性分散式資料集 (RDD) 是 Spark 的基本資料結構。它是一個不可變的分散式物件集合。RDD 中的每個資料集都分為邏輯分割槽,這些分割槽可以在叢集的不同節點上計算。RDD 可以包含任何型別的 Python、Java 或 Scala 物件,包括使用者定義的類。
正式地說,RDD 是一個只讀的分割槽記錄集合。RDD 可以透過對穩定儲存中的資料或其他 RDD 執行確定性操作來建立。RDD 是一個容錯的元素集合,可以並行操作。
建立 RDD 有兩種方法:並行化驅動程式程式中已有的集合,或引用外部儲存系統(例如共享檔案系統、HDFS、HBase 或任何提供 Hadoop 輸入格式的資料來源)中的資料集。
Spark 利用 RDD 的概念來實現更快更高效的 MapReduce 操作。讓我們首先討論 MapReduce 操作是如何進行的,以及為什麼它們效率不高。
MapReduce 中的資料共享速度慢
MapReduce 被廣泛採用,用於在叢集上使用並行分散式演算法處理和生成大型資料集。它允許使用者使用一組高階運算子編寫平行計算,而無需擔心工作分配和容錯。
不幸的是,在大多數現有框架中,在計算之間(例如,在兩個 MapReduce 作業之間)重用資料的唯一方法是將其寫入外部穩定儲存系統(例如 HDFS)。雖然此框架提供了許多用於訪問叢集計算資源的抽象,但使用者仍然需要更多。
迭代和互動式應用程式都需要在並行作業之間更快地共享資料。由於複製、序列化和磁碟 I/O,MapReduce 中的資料共享速度很慢。關於儲存系統,大多數 Hadoop 應用程式花費 90% 以上的時間進行 HDFS 讀寫操作。
MapReduce 上的迭代操作
在多階段應用程式中跨多個計算重用中間結果。下圖說明了當前框架在 MapReduce 上執行迭代操作時的工作方式。由於資料複製、磁碟 I/O 和序列化,這會產生大量的開銷,從而使系統變慢。
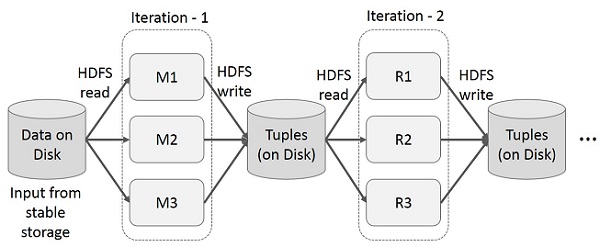
MapReduce 上的互動式操作
使用者對同一資料集的子集執行 ad-hoc 查詢。每個查詢都將在穩定儲存上執行磁碟 I/O,這可能會主導應用程式的執行時間。
下圖說明了當前框架在 MapReduce 上執行互動式查詢時的工作方式。

使用 Spark RDD 進行資料共享
由於複製、序列化和磁碟 I/O,MapReduce 中的資料共享速度很慢。大多數 Hadoop 應用程式花費 90% 以上的時間進行 HDFS 讀寫操作。
研究人員認識到這個問題,開發了一個名為 Apache Spark 的專用框架。Spark 的核心思想是彈性分散式資料集 (RDD);它支援記憶體處理計算。這意味著它將記憶體狀態作為跨作業的物件儲存,並且該物件可以在這些作業之間共享。記憶體中的資料共享速度比網路和磁碟快 10 到 100 倍。
現在讓我們嘗試找出 Spark RDD 中迭代和互動式操作是如何進行的。
Spark RDD 上的迭代操作
下圖顯示了 Spark RDD 上的迭代操作。它將中間結果儲存在分散式記憶體中而不是穩定儲存(磁碟)中,從而使系統更快。
注意 - 如果分散式記憶體 (RAM) 足夠儲存中間結果(作業狀態),則它會將這些結果儲存在磁碟上。
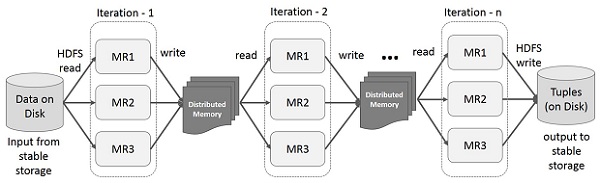
Spark RDD 上的互動式操作
此圖顯示了 Spark RDD 上的互動式操作。如果對同一資料集重複執行不同的查詢,則可以將此特定資料儲存在記憶體中以獲得更好的執行時間。
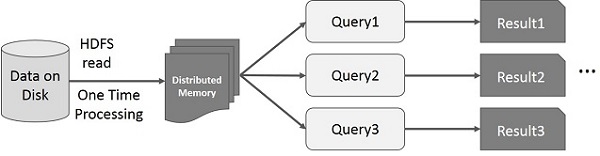
預設情況下,每次對轉換後的 RDD 執行操作時,都可能會重新計算它。但是,您也可以將 RDD 儲存在記憶體中,在這種情況下,Spark 將在下一次查詢它時將元素保留在叢集中以實現更快的訪問。還支援將 RDD 儲存在磁碟上或跨多個節點進行復制。
Spark - 安裝
Spark 是 Hadoop 的子專案。因此,最好將 Spark 安裝到基於 Linux 的系統中。以下步驟顯示瞭如何安裝 Apache Spark。
步驟 1:驗證 Java 安裝
Java 安裝是安裝 Spark 的一項強制性操作。嘗試使用以下命令驗證 JAVA 版本。
$java -version
如果 Java 已安裝在您的系統上,您將看到以下響應:
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果您系統上未安裝 Java,請在繼續下一步之前安裝 Java。
步驟 2:驗證 Scala 安裝
您應該使用 Scala 語言來實現 Spark。因此,讓我們使用以下命令驗證 Scala 的安裝。
$scala -version
如果您的系統上已經安裝了 Scala,您將看到以下響應:
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
如果您系統上沒有安裝 Scala,則繼續執行下一步安裝 Scala。
步驟 3:下載 Scala
訪問以下連結下載最新版本的 Scala 下載 Scala。在本教程中,我們使用的是 scala-2.11.6 版本。下載後,您將在下載資料夾中找到 Scala 的 tar 檔案。
步驟 4:安裝 Scala
按照以下步驟安裝 Scala。
解壓 Scala tar 檔案
輸入以下命令解壓 Scala tar 檔案:
$ tar xvf scala-2.11.6.tgz
移動 Scala 軟體檔案
使用以下命令將 Scala 軟體檔案移動到相應的目錄 **(/usr/local/scala)**。
$ su – Password: # cd /home/Hadoop/Downloads/ # mv scala-2.11.6 /usr/local/scala # exit
設定 Scala 的 PATH
使用以下命令設定 Scala 的 PATH。
$ export PATH = $PATH:/usr/local/scala/bin
驗證 Scala 安裝
安裝後,最好驗證一下。使用以下命令驗證 Scala 安裝。
$scala -version
如果您的系統上已經安裝了 Scala,您將看到以下響應:
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
步驟 5:下載 Apache Spark
訪問以下連結下載最新版本的 Spark 下載 Spark。在本教程中,我們使用的是 **spark-1.3.1-bin-hadoop2.6** 版本。下載後,您將在下載資料夾中找到 Spark 的 tar 檔案。
步驟 6:安裝 Spark
按照以下步驟安裝 Spark。
解壓 Spark tar 檔案
以下命令用於解壓 Spark tar 檔案:
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgz
移動 Spark 軟體檔案
以下命令用於將 Spark 軟體檔案移動到相應的目錄 **(/usr/local/spark)**。
$ su – Password: # cd /home/Hadoop/Downloads/ # mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark # exit
設定 Spark 的環境
將以下行新增到 ~ **/.bashrc** 檔案中。這意味著將 Spark 軟體檔案所在的路徑新增到 PATH 變數中。
export PATH = $PATH:/usr/local/spark/bin
使用以下命令更新 ~/.bashrc 檔案。
$ source ~/.bashrc
步驟 7:驗證 Spark 安裝
輸入以下命令開啟 Spark shell。
$spark-shell
如果 Spark 安裝成功,您將看到以下輸出。
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>
Spark SQL - 簡介
Spark 引入了一個用於結構化資料處理的程式設計模組,稱為 Spark SQL。它提供了一個稱為 DataFrame 的程式設計抽象,並且可以充當分散式 SQL 查詢引擎。
Spark SQL 的特性
以下是 Spark SQL 的特性:
**整合性** - 將 SQL 查詢與 Spark 程式無縫混合。Spark SQL 允許您將結構化資料作為 Spark 中的分散式資料集 (RDD) 進行查詢,並提供 Python、Scala 和 Java 的整合 API。這種緊密整合使得輕鬆執行 SQL 查詢以及複雜的分析演算法成為可能。
**統一的資料訪問** - 從各種來源載入和查詢資料。Schema-RDD 提供了一個單一介面,用於高效地處理結構化資料,包括 Apache Hive 表、parquet 檔案和 JSON 檔案。
**Hive 相容性** - 在現有倉庫上執行未修改的 Hive 查詢。Spark SQL 重用 Hive 前端和 MetaStore,使您可以完全相容現有的 Hive 資料、查詢和 UDF。只需將其與 Hive 一起安裝即可。
**標準連線性** - 透過 JDBC 或 ODBC 連線。Spark SQL 包含一個具有行業標準 JDBC 和 ODBC 連線性的伺服器模式。
**可擴充套件性** - 對互動式查詢和長時間查詢使用相同的引擎。Spark SQL 利用 RDD 模型來支援查詢中間的容錯能力,使其能夠擴充套件到大型作業。無需擔心對歷史資料使用不同的引擎。
Spark SQL 架構
下圖解釋了 Spark SQL 的架構:

此架構包含三個層,即語言 API、Schema RDD 和資料來源。
**語言 API** - Spark 與不同的語言和 Spark SQL 相容。它也受這些語言支援 - API(python、scala、java、HiveQL)。
**Schema RDD** - Spark Core 使用稱為 RDD 的特殊資料結構進行設計。通常,Spark SQL 處理模式、表和記錄。因此,我們可以使用 Schema RDD 作為臨時表。我們可以將此 Schema RDD 稱為 DataFrame。
**資料來源** - 通常,spark-core 的資料來源是文字檔案、Avro 檔案等。但是,Spark SQL 的資料來源不同。它們是 Parquet 檔案、JSON 文件、HIVE 表和 Cassandra 資料庫。
我們將在後續章節中詳細討論這些內容。
Spark SQL - DataFrame
DataFrame 是一個分散式資料集合,它被組織成命名列。從概念上講,它等效於具有良好最佳化技術的關聯表。
DataFrame 可以從各種不同的來源構建,例如 Hive 表、結構化資料檔案、外部資料庫或現有的 RDD。該 API 是為現代大資料和資料科學應用程式設計的,其靈感來自 **R 程式設計中的 DataFrame** 和 **Python 中的 Pandas**。
DataFrame 的特性
這是一組 DataFrame 的幾個特徵:
能夠在單節點叢集到大型叢集上處理從千位元組到拍位元組大小的資料。
支援不同的資料格式(Avro、csv、elastic search 和 Cassandra)和儲存系統(HDFS、HIVE 表、mysql 等)。
透過 Spark SQL Catalyst 最佳化器(樹轉換框架)進行最先進的最佳化和程式碼生成。
可以透過 Spark-Core 輕鬆整合所有大資料工具和框架。
提供 Python、Java、Scala 和 R 程式設計的 API。
SQLContext
SQLContext 是一個類,用於初始化 Spark SQL 的功能。初始化 SQLContext 類物件需要 SparkContext 類物件 (sc)。
以下命令用於透過 spark-shell 初始化 SparkContext。
$ spark-shell
預設情況下,當 spark-shell 啟動時,SparkContext 物件以名稱 **sc** 初始化。
使用以下命令建立 SQLContext。
scala> val sqlcontext = new org.apache.spark.sql.SQLContext(sc)
示例
讓我們考慮一個名為 **employee.json** 的 JSON 檔案中的員工記錄示例。使用以下命令建立一個 DataFrame (df) 並讀取名為 **employee.json** 的 JSON 文件,其內容如下。
**employee.json** - 將此檔案放在當前 **scala>** 指標所在的目錄中。
{
{"id" : "1201", "name" : "satish", "age" : "25"}
{"id" : "1202", "name" : "krishna", "age" : "28"}
{"id" : "1203", "name" : "amith", "age" : "39"}
{"id" : "1204", "name" : "javed", "age" : "23"}
{"id" : "1205", "name" : "prudvi", "age" : "23"}
}
DataFrame 操作
DataFrame 提供了一種用於結構化資料操作的特定領域語言。在這裡,我們包含一些使用 DataFrame 進行結構化資料處理的基本示例。
按照以下步驟執行 DataFrame 操作:
讀取 JSON 文件
首先,我們必須讀取 JSON 文件。基於此,生成一個名為 (dfs) 的 DataFrame。
使用以下命令讀取名為 **employee.json** 的 JSON 文件。資料顯示為一個表,欄位為:id、name 和 age。
scala> val dfs = sqlContext.read.json("employee.json")
**輸出** - 欄位名稱是從 **employee.json** 自動獲取的。
dfs: org.apache.spark.sql.DataFrame = [age: string, id: string, name: string]
顯示資料
如果要檢視 DataFrame 中的資料,請使用以下命令。
scala> dfs.show()
**輸出** - 您可以以表格格式檢視員工資料。
<console>:22, took 0.052610 s +----+------+--------+ |age | id | name | +----+------+--------+ | 25 | 1201 | satish | | 28 | 1202 | krishna| | 39 | 1203 | amith | | 23 | 1204 | javed | | 23 | 1205 | prudvi | +----+------+--------+
使用 printSchema 方法
如果要檢視 DataFrame 的結構(模式),請使用以下命令。
scala> dfs.printSchema()
輸出
root |-- age: string (nullable = true) |-- id: string (nullable = true) |-- name: string (nullable = true)
使用 Select 方法
使用以下命令從 DataFrame 中獲取三個列中的 **name** 列。
scala> dfs.select("name").show()
**輸出** - 您可以看到 **name** 列的值。
<console>:22, took 0.044023 s +--------+ | name | +--------+ | satish | | krishna| | amith | | javed | | prudvi | +--------+
使用 Age 過濾器
使用以下命令查詢年齡大於 23 (age > 23) 的員工。
scala> dfs.filter(dfs("age") > 23).show()
輸出
<console>:22, took 0.078670 s +----+------+--------+ |age | id | name | +----+------+--------+ | 25 | 1201 | satish | | 28 | 1202 | krishna| | 39 | 1203 | amith | +----+------+--------+
使用 groupBy 方法
使用以下命令計算相同年齡的員工人數。
scala> dfs.groupBy("age").count().show()
**輸出** - 兩名員工的年齡為 23。
<console>:22, took 5.196091 s +----+-----+ |age |count| +----+-----+ | 23 | 2 | | 25 | 1 | | 28 | 1 | | 39 | 1 | +----+-----+
以程式設計方式執行 SQL 查詢
SQLContext 使應用程式能夠在執行 SQL 函式的同時以程式設計方式執行 SQL 查詢,並將結果作為 DataFrame 返回。
通常,在後臺,SparkSQL 支援兩種不同的方法將現有的 RDD 轉換為 DataFrame:
| 序號 | 方法和描述 |
|---|---|
| 1 | 使用反射推斷模式
此方法使用反射來生成包含特定型別物件的 RDD 的模式。 |
| 2 | 以程式設計方式指定模式
建立 DataFrame 的第二種方法是透過程式設計介面,該介面允許您構建模式,然後將其應用於現有 RDD。 |
Spark SQL - 資料來源
DataFrame 介面允許不同的資料來源在 Spark SQL 上工作。它是一個臨時表,可以像普通 RDD 一樣操作。將 DataFrame 註冊為表允許您在其資料上執行 SQL 查詢。
在本章中,我們將描述使用不同的 Spark 資料來源載入和儲存資料的常用方法。此後,我們將詳細討論內建資料來源可用的特定選項。
SparkSQL 中有不同型別的資料來源可用,其中一些列在下面:
| 序號 | 資料來源 |
|---|---|
| 1 | JSON 資料集
Spark SQL 可以自動捕獲 JSON 資料集的模式並將其載入為 DataFrame。 |
| 2 | Hive 表
Hive 作為 HiveContext 與 Spark 庫捆綁在一起,它繼承自 SQLContext。 |
| 3 | Parquet 檔案
Parquet 是一種列式格式,許多資料處理系統都支援它。 |