無伺服器 - 快速指南
無伺服器 - 簡介
什麼是無伺服器?
嗯,這個名字給了你不少提示。無需維護伺服器即可進行計算——這就是無伺服器計算(簡稱無伺服器)的核心。這個概念具有相當的革命性和顛覆性。它已被廣泛採用。許多新的應用程式都是從設計無伺服器後端開始的,而擁有專用伺服器的遺留應用程式也正在緩慢地遷移到無伺服器架構。那麼是什麼導致了無伺服器的廣泛採用呢?與所有事情一樣,經濟因素使無伺服器非常有利。
你看,使用無伺服器,你只為使用的資源付費。假設你每天需要對資料庫進行一些例行維護。這個過程每天可能需要大約 10 分鐘。
現在,在沒有無伺服器計算的情況下,你的維護 cron 作業可能駐留在伺服器上。除非你在剩餘時間內還有其他事情要做,否則你最終可能會為一項需要 10 分鐘的任務支付 24 小時的費用。相當浪費錢,對吧?如果有人告訴你有一項新服務,只會為你維護 cron 作業執行的這 10 分鐘收費呢?你難道不想簡單地切換到這項新服務嗎?這就是無伺服器採用如此迅速和廣泛的原因。它降低了多個組織的後端賬單,同時也減少了他們的伺服器維護難題。
雲服務提供商(AWS、Azure 等)承擔了確保無伺服器應用程式在需要時且以所需數量可用的難題。因此,在高負載期間,你可能會呼叫多個無伺服器應用程式,而在正常負載期間,你可能會呼叫單個應用程式。當然,你只會為高負載持續時間內額外呼叫的時間付費。
再次什麼是無伺服器?
上面解釋的概念似乎很棒,但是你如何實現它呢?你需要一個框架。它被稱為,呃,serverless。
無伺服器框架幫助我們開發和部署設計為以無伺服器方式執行的函式/應用程式。該框架更進一步,負責部署無伺服器函式執行所需的整個堆疊。什麼是堆疊?嗯,堆疊包含你部署、儲存和監控無伺服器應用程式所需的所有資源。
它包括實際的函式/應用程式、儲存容器、監控解決方案等等。例如,在 AWS 的上下文中,你的堆疊將包含你的實際 Lambda 函式、用於函式檔案的 S3 儲存桶、與你的函式關聯的 Cloudwatch 資源等等。無伺服器框架為我們建立了這個整個堆疊。這使我們能夠完全專注於我們的函式。無伺服器消除了維護伺服器的難題,而無伺服器(框架)消除了建立和部署執行我們的函式所需的堆疊的難題。
無伺服器框架還負責為我們的函式/應用程式分配必要的許可權。一些應用程式(我們將在本教程中看到示例)甚至需要將資料庫連結到它們。無伺服器框架再次負責建立和連結資料庫。無伺服器如何知道在堆疊中包含什麼以及要提供哪些許可權?所有這些都寫在 serverless.yml 檔案中,這將是本教程的主要焦點。更多內容將在接下來的章節中介紹。
AWS 中的無伺服器
AWS 的許多服務都屬於“無伺服器計算”的範疇。你可以在這裡找到整個組織列表here。有計算服務、整合服務,甚至資料儲存服務(是的,AWS 甚至有無伺服器資料庫)。在本教程中,我們將重點關注 AWS Lambda 函式。那麼什麼是 AWS Lambda 呢?AWS Lambda 網站將其定義如下:
AWS Lambda 是一種無伺服器計算服務,允許你執行程式碼而無需預置或管理伺服器、建立瞭解工作負載的叢集擴充套件邏輯、維護事件整合或管理執行時。
用通俗的話說,AWS Lambda 是你在 AWS 上進行無伺服器計算的視窗。正是 AWS Lambda 使無伺服器概念如此流行。你只需定義你的函式和函式的觸發器,函式將在你想要呼叫時被呼叫,你只需為函式執行所需的時間付費。更重要的是,你可以將 AWS Lambda 與 AWS 提供的幾乎所有其他服務連結起來——EC2、S3、dynamoDB 等等。
因此,如果你已經是 AWS 生態系統的一部分,那麼 Lambda 整合非常無縫。如果你像我第一次瞭解 AWS Lambda 時一樣不熟悉 AWS 生態系統,它將作為進入 AWS 宇宙的良好閘道器。
在本教程中,我們將學習使用無伺服器框架部署 AWS Lambda 函式的所有知識。你興奮嗎?然後繼續下一章開始吧。
無伺服器 - 安裝
無伺服器安裝已經在另一個 tutorialspoint 教程中介紹過。在此處進行復制,並進行一些修改和補充。
步驟 1 - 安裝 nodejs
首先,你需要安裝 nodejs。你可以透過開啟命令提示符並鍵入 **node -v** 來檢查你的機器上是否已安裝 nodejs。如果已安裝,你將獲得 node 的版本號。否則,你可以從此處下載並安裝 node here.

步驟 2 - 使用 npm 命令安裝無伺服器
你可以使用以下命令安裝無伺服器(npm 代表 node 包管理器):
npm install -g serverless
你可以透過執行 **serverless create --help** 來檢查它是否成功安裝。如果無伺服器成功安裝,你應該會看到 create 外掛的幫助螢幕。
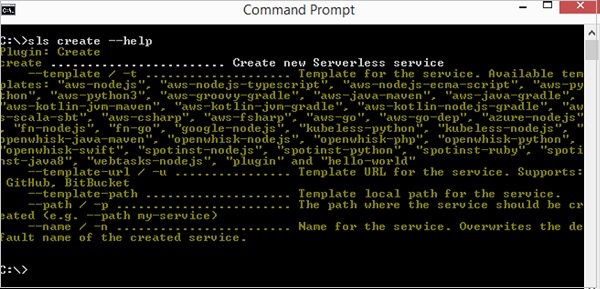
請注意,你可以在所有命令中使用簡寫 **sls** 代替 **serverless**。
步驟 3 - 配置憑據
你需要從 AWS 獲取憑據來配置無伺服器。為此,你可以在 AWS 控制檯中建立一個使用者(透過 IAM -> 使用者 -> 新增使用者),或者點選 IAM -> 使用者中的現有使用者。如果你正在建立新使用者,你需要附加一些必需的策略(例如 Lambda 訪問、S3 訪問等),或者向用戶提供管理員訪問許可權。
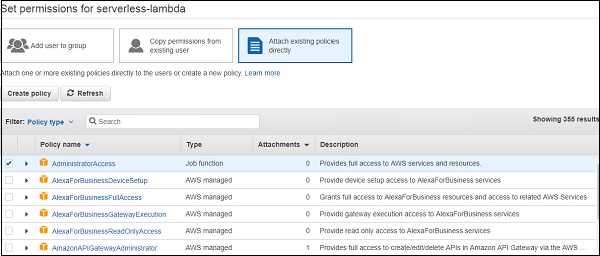
建立使用者後,你將能夠看到訪問金鑰和金鑰。請妥善保管這些金鑰,並將其保密。

如果你是一個現有使用者,你可以按照此處提到的步驟生成新的訪問金鑰和金鑰 here.
一旦你準備好訪問金鑰和金鑰,你就可以使用以下命令在無伺服器中配置憑據:
serverless config credentials --provider aws --key 1234 --secret 5678 --profile custom-profile
profile 欄位是可選的。如果你留空,預設 profile 為“aws”。記住你設定的 profile 名稱,因為你必須在下一個教程中看到的 serverless.yml 檔案中提及它。
如果你完成了上述步驟,則無伺服器配置已完成。繼續下一章以建立你的第一個無伺服器專案。
無伺服器 - 部署函式
建立新專案
導航到一個新資料夾,你希望在其中建立要部署到無伺服器的第一個專案。在該資料夾中,執行以下命令:
sls create --template aws-python3
此命令將建立使用無伺服器和 python 執行時部署 lambda 函式的樣板程式碼。
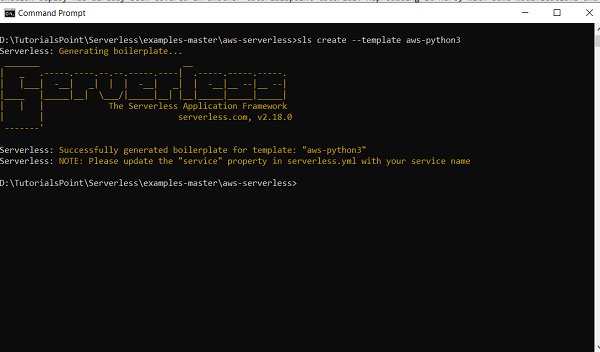
請注意,你也可以使用其他執行時。執行 **sls create --help** 以獲取所有模板的列表。
建立樣板程式碼後,你將在資料夾中看到兩個檔案:handler.py 和 serverless.yml。handler.py 是包含 lambda 函式程式碼的檔案。serverless.yml 是告訴 AWS 如何建立 lambda 函式的檔案。它是配置檔案或設定檔案,將成為本教程幾章的重點。讓我們首先瀏覽 handler.py 檔案。
import json
def hello(event, context):
body = {
"message": "Go Serverless v1.0! Your function executed successfully!", "input": event
}
response = {
"statusCode": 200, "body": json.dumps(body)
}
return response
# Use this code if you don't use the http event with the LAMBDA-PROXY
# integration
"""
return {
"message": "Go Serverless v1.0! Your function executed successfully!", "event": event
}
"""
它包含一個函式 **hello**。此函式接受兩個引數:event 和 context。對於任何 AWS Lambda 函式,這兩個引數都是必需的。每當呼叫 lambda 函式時,lambda 執行時都會將兩個引數傳遞給函式——event 和 context。
**event** 引數包含 lambda 函式要處理的資料。例如,如果透過 REST API 觸發 lambda 函式,你透過 API 的路徑引數或正文傳送的任何資料都會作為 event 引數傳送到 lambda 函式。更多內容將在後面的章節中介紹。需要注意的是,event 通常是 python **dict** 型別,儘管也可以是 **str**、**float**、**int**、**list** 或 **NoneType** 型別。
**context** 物件是執行時傳遞給 lambda 函式的另一個引數。它並不經常使用。AWS 官方文件指出,*此物件提供提供有關呼叫、函式和執行時環境的資訊的方法和屬性。* 你可以在這裡閱讀有關 **event** 和 **context** 物件的更多資訊 here.
此函式非常簡單明瞭。它僅返回一條包含狀態碼 200 的訊息。底部有一條註釋,如果我們不使用帶有 LAMBDA-PROXY 設定的 HTTP 事件,則應該使用它。更多內容請參見 API 觸發 lambda 章節。
現在,讓我們來看一下 serverless.yml 檔案。這是一個註釋非常多的檔案。對於剛接觸無伺服器的開發者來說,這些註釋非常有用。建議您仔細閱讀這些註釋。在接下來的章節中,我們將學習許多與 serverless.yml 相關的概念。這裡我們只瀏覽一下基本概念。
如果您刪除註釋後檢視 serverless.yml 檔案,它將如下所示:
service: aws-serverless
frameworkVersion: '2'
provider:
name: aws
runtime: python3.8
lambdaHashingVersion: 20201221
functions:
hello:
handler: handler.hello
service 欄位確定您的 lambda 函式和所有所需資源將在其中建立的 CloudFormation 堆疊的名稱。您可以將 service 視為您的專案。AWS Lambda 函式執行所需的一切都將在該 service 中建立。您可以設定您選擇的 service 名稱。
framework version 指的是無伺服器框架的版本。這是一個可選欄位,通常用於確保與您共享程式碼的人使用相同的版本號。如果 serverless.yml 中提到的 frameworkVersion 與您機器上安裝的 serverless 版本不同,則在部署過程中會收到錯誤。您還可以為 frameworkVersion 指定一個範圍,例如 **frameworkVersion − >=2.1.0 && <3.0.0**。您可以在 此處 閱讀更多關於 frameworkVersion 的資訊。
下一個部分 **provider** 可以被認為是一組全域性設定。我們將在後面的章節中討論 provider 下包含的其他引數。在這裡,我們將關注可用的引數。**name** 欄位確定您的平臺環境的名稱,在本例中為 aws。runtime 為 python3.8,因為我們使用了 python3 模板。lambdaHashingVersion 指的是框架應使用的雜湊演算法的名稱。
請注意,如果您在上章的配置憑證步驟中添加了自定義配置檔案,則需要在 provider 中新增 profile 引數。例如,我將我的配置檔名稱設定為 yash-sanghvi。因此,我的 provider 看起來像這樣:
provider: name: aws runtime: python3.8 lambdaHashingVersion: 20201221 profile: yash-sanghvi
最後,functions 塊定義所有 lambda 函式。這裡我們只有一個函式,在 handler 檔案中。函式的名稱為 hello。函式的路徑在 handler 欄位中提到。
部署函式
要部署函式,您需要開啟命令提示符,導航到包含 serverless.yml 檔案的資料夾,然後輸入以下命令:
sls deploy -v
**-v** 是一個可選引數,表示詳細輸出。它可以幫助您更好地理解後臺程序。函式部署後,您應該能夠在 us-east-1 區域(預設區域)的 AWS 控制檯中看到它。您可以使用“測試”功能從控制檯呼叫它(您可以保留相同的預設事件,因為我們的 lambda 函式無論如何都不會使用事件輸入)。您也可以使用命令提示符進行測試:
sls invoke --function hello
請注意,如果您的函式與其他 AWS 服務(如 S3 或 dynamoDB)互動,則您不能始終在本地測試您的函式。只有最基本的函式可以在本地測試。
從現有專案部署函式
如果您想將現有專案部署到 AWS,請修改現有函式,使其僅接收 **event** 和 **context** 作為引數。接下來,在資料夾中新增一個 serverless.yml 檔案,並在 serverless.yml 中定義您的函式。然後開啟命令提示符,導航到該資料夾,然後輸入 **sls deploy -v**。這樣,您的現有函式也可以部署到 AWS Lambda。
Serverless - 區域、記憶體大小、超時
在上章中,我們學習瞭如何使用 serverless 部署我們的第一個函式。本章,我們將學習一些可以對函式進行的配置。我們將主要關注區域、記憶體大小和超時。
區域
預設情況下,使用 serverless 部署的所有 lambda 函式都將在 us-east-1 區域中建立。如果您希望您的 lambda 函式在其他區域建立,您可以在 provider 中指定。
provider: name: aws runtime: python3.6 region: us-east-2 profile: yash-sanghvi
在一個 serverless.yml 檔案中,無法為不同的函式指定不同的區域。您應該在一個 serverless.yml 檔案中只包含屬於單個區域的函式。屬於不同區域的函式可以使用單獨的 serverless.yml 檔案部署。
記憶體大小
AWS Lambda 會根據選擇的記憶體大小按比例分配 CPU。根據最近釋出的變更,您可以為您的 lambda 函式選擇高達 10GB 的 RAM(之前約為 3GB)。
選擇的 RAM 越高,分配的 CPU 越高,函式執行速度越快,執行時間越短。AWS Lambda 會按消耗的 GB-s 收費。因此,如果一個 1 GB RAM 的函式需要 10 秒才能執行,而一個 2 GB RAM 的函式需要 5 秒才能執行,那麼這兩個呼叫的收費金額相同。將記憶體加倍後時間是否減半很大程度上取決於函式的性質,您可能會或可能不會從增加記憶體中獲益。關鍵在於分配的記憶體大小是每個 lambda 函式的重要設定,也是您希望控制的一個設定。
使用 serverless,很容易為 serverless.yml 檔案中定義的函式設定記憶體大小的預設值。也可以為不同的函式定義不同的記憶體大小。讓我們看看如何操作。
為所有函式設定預設記憶體大小
預設值始終在 provider 中提到。此值將由 serverless.yml 中的所有函式繼承。**memorySize** 鍵用於設定此值。該值以 MB 為單位表示。
provider: name: aws runtime: python3.6 region: us-east-2 profile: yash-sanghvi memorySize: 512 #will be inherited by all functions
如果您沒有在 provider 中或單個函式中指定 memorySize,則將考慮預設值 1024。
為某些函式設定自定義記憶體大小
如果您希望某些函式的值與預設記憶體不同,則可以在 serverless.yml 的 functions 部分中指定。
functions:
custom_memory_func: #will override the default memorySize
handler: handler.custom_memory
memorySize: 2048
default_memory_func: #will inherit the default memorySize from provider
handler: handler.default_memory
超時
與 memorySize 一樣,超時(以秒為單位)的預設值可以在 provider 中設定,並且可以在 functions 部分中為單個函式指定自定義超時。
如果您沒有指定全域性或自定義超時,則預設值為 6 秒。
provider:
name: aws
runtime: python3.6
region: us-east-2
profile: yash-sanghvi
memorySize: 512 #will be inherited by all functions
timeout: 50 #will be inherited by all functions
functions:
custom_timeout: #will override the default timeout
handler: handler.custom_memory
timeout: 30
default_timeout_func: #will inherit the default timeout from provider
handler: handler.default_memory
確保將超時設定為保守值。它不應該太小以至於您的函式頻繁超時,也不應該太大以至於函式中的錯誤導致您支付過高的賬單。
無伺服器 - 服務
您不會希望為部署的每個函式建立一個單獨的 serverless.yml 檔案。那將非常繁瑣。幸運的是,serverless 提供了在同一個 serverless.yml 檔案中部署多個函式的機制。所有這些函式都屬於一個名為“service”的組。service 名稱通常是 serverless.yml 檔案中定義的第一個內容。
service: my-first-service
provider:
name: aws
runtime: python3.6
stage: prod
region: us-east-2
profile: yash-sanghvi
functions:
func1:
handler: handler1.func1
func2:
handler: handler2.func2
部署時,同一個 service 中的所有函式在 AWS Lambda 控制檯中採用以下名稱格式:**service_name-stage_name-function_name**。因此,上面的示例中的兩個函式部署後將採用名稱:**my-first-service-prod-func1** 和 **my-first-service-prod-func2**。stage 引數幫助您區分程式碼開發的不同階段。
因此,如果您的函式處於開發階段,您可以使用階段 **dev**;如果它處於測試階段,您可以使用階段 **test**;如果它處於生產階段,您可以使用階段 **prod**。這樣,您可以確保對 dev 階段所做的更改不會影響生產程式碼。階段名稱並非一成不變。**dev、test、prod** 只是示例。
您可以選擇任何您想要的階段名稱。請注意,如果您有 API Gateway 觸發的 lambda(更多內容將在後面的章節中介紹),那麼每個階段的端點將有所不同。
此外,如果您轉到 AWS Lambda 控制檯較少使用的“應用程式”部分,您將能夠看到帶有階段的整個服務。
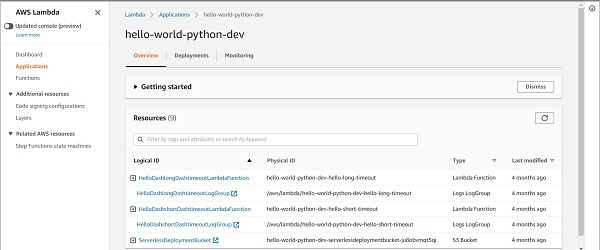
如果您單擊您選擇的 service 和 stage 組合,您將能夠在一個地方看到服務使用 的所有資源:Lambda 函式、API 閘道器、事件規則、日誌組、S3 儲存桶等等。
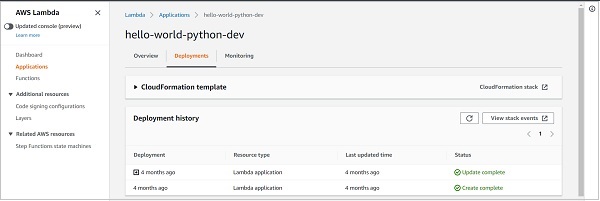
更有趣的是,您可以轉到“監控”選項卡,檢視整個服務的效能:呼叫次數、平均持續時間、錯誤計數等。您可以瞭解哪個函式對您的賬單貢獻最大。當您的服務中有多個函式時,監控每個函式的效能變得非常困難。服務級別的“監控”選項卡在這裡非常有幫助。
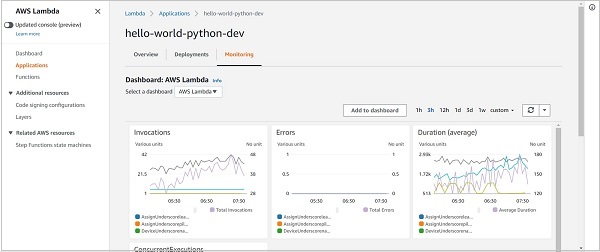
最後,“部署”選項卡可以幫助您檢視服務的過去所有部署以及部署的狀態。
無伺服器 - 定時 Lambda 函式
通常,您需要您的函式以固定的時間間隔呼叫。它可以是一天一次,一週兩次,工作日每分鐘一次,等等。Serverless 提供兩種型別的事件,以便以固定的頻率呼叫函式。它們是 cron 事件和 rate 事件。
Cron 事件
cron 事件比 rate 事件具有更大的靈活性。唯一的缺點是它不如 rate 事件容易理解。cron 表示式的語法在 AWS 文件 中定義:
cron(minutes hours day-of-month month day-of-week year)
如您所見,cron 表示式由 6 個欄位組成。每個欄位都可以接受一些值,以及一些 AWS 所稱的 *萬用字元*。
讓我們先來看看可接受的值:
**分鐘** - 0-59
**小時** - 0-23
**月份中的某一天** - 1-31
**月份** - 1-12 或 JAN-DEC
**星期中的某一天** - 1-7 或 SUN-SAT
**年份** - 1970-2199
現在可接受的值已經清楚了,讓我們來看看萬用字元。cron 表示式中總共有 8 個可能的萬用字元(一些允許用於所有 6 個欄位,一些僅允許用於特定欄位)。這裡列出它們:
**\*(星號,允許用於所有 6 個欄位)** - 這是最流行的萬用字元。它只是說包含欄位的所有值。小時欄位中的 * 表示 cron 將每小時執行一次。月份中的某一天欄位中的 * 表示 cron 將每天執行一次。
, (逗號,所有6個欄位都允許) − 用於指定多個值。例如,如果希望您的 cron 在每小時的第 5、7 和 9 分鐘執行,則分鐘欄位應如下所示:5,7,9。類似地,在星期欄位中使用 MON,TUE,WED,THU,FRI 可以表示 cron 僅在工作日執行。
- (短橫線,所有6個欄位都允許) − 此萬用字元指定範圍。在之前的萬用字元示例中,為了指定工作日,無需指定 5 個逗號分隔的值,只需編寫 MON-FRI 即可。
? (問號,僅限於月份和星期) − 這就像一個“不關心”萬用字元。如果在星期欄位中指定了 MON,則不關心星期一落在哪一天。因此,您將在月份欄位中輸入 ?。類似地,如果希望 cron 在每月的第 5 天執行,則在月份欄位中輸入 5,在星期欄位中輸入 ?,因為您不關心每月的第 5 天是星期幾。請注意,AWS 文件明確指出,不能同時在星期欄位和月份欄位中使用 *。如果在一個欄位中使用 *,則必須在另一個欄位中使用 ?
/ (正斜槓,除月份外,所有 5 個欄位都允許) − 此欄位指定增量。如果在小時欄位中輸入 0/2,則此 cron 將每隔偶數小時執行一次(0、0+2、0+2+2 等)。如果在小時欄位中指定 1/2,則此 cron 將每隔奇數小時執行一次(1、1+2、1+2+2 等)。正如您可能猜到的那樣,/ 前面的值是起始值,/ 後面的值定義增量。
L (僅限於月份和星期) − 指定月份的最後一天或星期的最後一天。
W (僅限於月份) − 指定最接近該特定月份的某一天的工作日(星期一到星期五)。因此,如果在月份欄位中指定 8W,並且它對應於一個工作日,例如星期二,則 cron 將在第 8 天觸發。但是,如果 8 對應於週末,例如星期六,則 cron 將在第 7 天(星期五)觸發。如果第 8 天是星期日,則 cron 將在第 9 天(星期一)觸發。這是最少使用的萬用字元之一。
# (僅限於星期) − 這是一個非常特殊的萬用字元,最好透過示例來理解。假設您希望 cron 在母親節執行。母親節每年都在五月的第二個星期日。因此,您的月份欄位將包含 MAY 或 5。但是,如何指定第二個星期日呢?這裡就用到了井號。表示式為 0#2。萬用字元前面的值是星期幾(0 代表星期日,1 代表星期一,以此類推)。萬用字元後面的值指定出現次數。因此,這裡的 2 指的是星期日的第二次出現,即第二個星期日。
現在,要為您的 lambda 函式定義一個 cron 觸發器,您只需在 serverless.yml 檔案中函式的 events 金鑰內指定 cron 表示式即可。
functions:
cron_triggered_lambda:
handler: handler.hello
events:
- schedule: cron(10 03 * * ? *) #run at 03:10 (UTC) every day.
一些示例
下面是一些 cron 表示式的示例 −
cron(30 15 ? * MON-FRI *) − 在每個工作日的 15:30 (UTC) 觸發。
cron(0 9 ? 6 0#3 *) − 在 6 月份的第三個星期日 (父親節) 的 09:00 (UTC) 觸發。
cron(0/15 * ? * MON *) − 每 15 分鐘在星期一觸發一次。
cron(0/30 9-18 ? * MON-FRI *) − 在工作日(對應於許多地方的辦公時間)的上午 9 點到下午 5:30 之間每 30 分鐘觸發一次。
速率事件
與 cron 表示式相比,這要簡單得多。語法很簡單:rate(value unit)。例如,rate(5 minutes)。
值可以是任何正整數,允許的單位是分鐘、小時、天。
為您的 lambda 函式定義速率觸發器與定義 cron 觸發器類似。
functions:
rate_triggered_lambda:
handler: handler.hello
events:
- schedule: rate(10 minutes) #run every 10 minutes
一些示例
rate(2 hours) − 每 2 小時觸發一次。
rate(1 day) − 每天觸發一次(UTC 00:00)。
rate(90 minutes) − 每 90 分鐘觸發一次。
您可能已經意識到,速率表示式的簡單性是以降低靈活性為代價的。您可以將速率用於每 N 分鐘/小時/天執行的 lambda。要執行更復雜的操作,例如僅在工作日觸發您的 lambda,您必須使用 cron 表示式。
請注意,如果您的 cron 表示式導致觸發時間小於一分鐘,則不支援。
參考資料
無伺服器 - API 閘道器觸發的 Lambda 函式
API 閘道器是觸發 lambda 的另一種常用方法,就像 cron/rate 事件一樣。基本上,您可以為您的 lambda 函式獲取一個 URL 終結點。此 URL 屬於連線到您的 lambda 的 API 閘道器。每當您在瀏覽器或應用程式中呼叫 URL 時,您的 lambda 函式就會被呼叫。在本章中,我們將瞭解如何使用無伺服器框架將 API 閘道器連線到您的 lambda 函式,以及如何測試它。
HTTP 事件
要將 API 閘道器連結到 lambda 函式,我們需要在 serverless.yml 中的函式定義中建立 HTTP 事件。以下示例顯示瞭如何將您的 lambda 函式連結到 REST API 並使用 GET 請求觸發它。
functions:
user_details_api:
handler: handler.send_user_details
events:
- http:
path: details/{user_id}
method: get
integration: lambda-proxy
cors: true
location_api:
handler: handler.send_location
events:
- http:
path: location/{user_id}
method: get
integration: lambda-proxy
cors: true
讓我們逐一分解這些金鑰。我們只討論上面列表中的第一個函式 (user_details_api)。下面介紹的概念也適用於其他函式。
path 的值指定呼叫 URL 後面的地址。上述示例中定義的兩個函式將共享相同的終結點,但一個將使用終結點/details/{user_id} 呼叫,而另一個將使用終結點/location/{user_id} 呼叫。花括號中的元素是路徑引數。我可以替換 user_id 中的任何值,並且可以對 lambda 函式進行程式設計以返回該特定使用者的詳細資訊(請參見下面的示例函式)。
method 的值指示請求方法。常用的方法是 get 和 post。還有其他幾種方法。深入研究這些方法的細節超出了本章的範圍。還有一個tutorialspoint 上的文章,您可以參考以瞭解詳細資訊。
integration 欄位指定 lambda 函式如何與 API 閘道器整合。預設值為 lambda-proxy,其他可能的選項為 lambda、http、http-proxy、mock。這兩個選項中最常用的選項是 lambda 和 lambda-proxy。簡單來說,lambda-proxy 將完全控制權交給您的 lambda 函式,而 lambda 將部分控制權交給 API 閘道器,部分控制權交給 lambda 函式。
如果您選擇 lambda-proxy 作為整合型別,則整個 HTTP 請求將以原始形式傳遞給您的 lambda 函式,並且 lambda 函式傳送的響應將無需更改地傳遞給發出請求的客戶端。因此,您必須在 lambda 函式的響應中定義 statusCode 和 headers。
如果您選擇 lambda 作為整合型別,則您的 API 閘道器可以在將其傳遞給 lambda 函式之前修改接收到的請求。類似地,它還可以修改 lambda 函式傳送的響應,然後再將其轉發給客戶端。API 閘道器將狀態碼和標頭新增到響應中,因此 lambda 函式只需擔心傳送正文即可。兩種選項各有優缺點。
如果您喜歡簡單性,可以使用 lambda-proxy。如果您不介意一些複雜性(因為您需要同時處理 lambda 函式的程式碼和 API 閘道器的配置),但需要更多控制,可以選擇 lambda。
您可以閱讀更多關於這兩種型別之間區別的資訊這裡。在其他整合型別中,http 和 http-proxy 用於將 API 閘道器與 HTTP 後端而不是 lambda 函式整合,因此與我們無關。mock 用於在不呼叫後端的情況下測試 API。
cors − true 配置啟用 CORS(跨源資源共享)。簡單來說,這意味著您允許來自另一個域的伺服器的請求。沒有 cors − true,只允許來自同一域的請求。當然,您也可以只允許某些特定域,而不是允許所有域。要了解如何執行此操作,請參閱文件。
在無伺服器中,對於 API 閘道器觸發的 lambda,還可以進行更多配置。強烈建議您閱讀文件,或者至少將連結新增為書籤,以便在需要時查詢。
示例 Lambda 函式
此時,您可能想知道您建立了 API 閘道器觸發的函式,但是如何在 lambda 函式中訪問路徑引數?以下 python 中的示例 lambda 函式將解答此問題。當整合型別為 lambda-proxy 時,我們基本上使用 'pathParameters' 屬性。
import json
def lambda_handler(event, context):
# TODO implement
# print(event)
#helps you see the entire input request. The printed output can be found in CloudWatch logs
user = event['pathParameters']['user_id']
return {
'statusCode': 200,
'body': json.dumps('Hello ' + str(user))
}
訪問終結點
現在,您可能還有另一個問題,即如何訪問終結點。有多種方法可以做到這一點。第一種方法是透過無伺服器部署。每當您透過服務部署一個函式或多個函式時,終結點都會顯示在無伺服器部署的末尾。
第二種方法是透過 Lambda 控制檯。如果您在 lambda 控制檯中導航到您的函式,則可以看到附加到它的 API 閘道器。單擊它應該會顯示終結點。
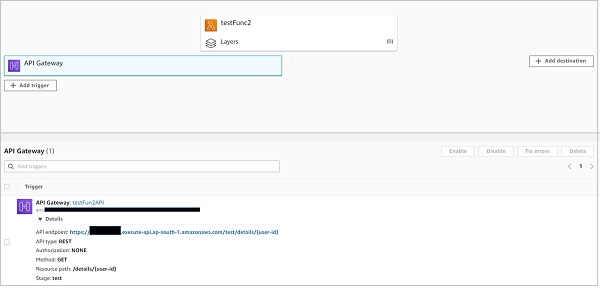
請注意,如上所述,一個服務中的所有函式共享相同的終結點。path 屬性區分一個函式的實際觸發 URL 與另一個函式的實際觸發 URL。
參考資料
無伺服器 - 包含/排除
我們在“部署函式”一章中已經看到,要將現有專案中的函式部署到 AWS Lambda,需要修改函式以接受**event** 和 **context** 作為引數,並且需要在專案資料夾中新增一個 serverless.yml 檔案,其中定義了這些函式。然後執行**serverless deploy** 即可完成部署。
尤其是在將大型現有專案中的某些函式遷移到 AWS Lambda 時,經常會遇到大小方面的挑戰。如果專案足夠大,很可能會超過 AWS 對 Lambda 函式施加的大小限制 (250 MB,包括應用程式程式碼及其依賴項)。
一些依賴項,例如 NumPy,本身就佔用大量空間。例如,NumPy 大約 80 MB,SciPy 也差不多,等等。在這種情況下,應用程式程式碼的剩餘空間非常有限,需要一種方法來排除 Lambda 部署包中不需要的檔案。幸運的是,serverless 使這變得非常容易。
include 和 exclude 欄位
正如你所猜想的那樣,可以使用“exclude”標籤指定要從部署構建中排除的檔案和資料夾。預設情況下,未在 exclude 部分中指定的所有檔案/資料夾都將包含在內。“include”標籤有什麼用呢?如果你想全域性排除某個資料夾,但又想包含該資料夾內的一些檔案或子資料夾,則可以在“include”標籤中指定這些檔案/子資料夾。這樣,該資料夾內的所有其他檔案都將被排除,只有在“include”部分中指定的檔案才會保留。下面的示例將更好地解釋這一點。
service: influx-archive-pipeline
provider:
name: aws
runtime: python3.6
stage: prod
region: us-east-2
profile: yash-sanghvi
timeout: 900
memorySize: 1024
# you can add packaging information here
package:
include:
- src/models/config.py
- src/models/lambda_apis/**
- src/models/scheduled_lambdas/**
exclude:
- docs/**
- models/**
- notebooks/**
- references/**
- reports/**
- src/data/**
- src/visualization/**
- src/models/**
- utils/**
functions:
user_details_api:
handler: src/models/lambda_apis/user_details_api.sync_user_details
events:
- http:
path: details/{user_id}
method: get
integration: lambda
cors: true
monitoring_lambda:
handler: src/models/scheduled_lambdas/monitoring_lambda.periodic_monitoring
events:
- schedule: cron(15 16 * * ? *)
從上面的 serverless.yml 檔案可以看出,我們排除了包含 serverless.yml 的根資料夾中的大部分資料夾。我們甚至排除了 src/models 資料夾。但是,我們想包含 src/models 中的 2 個子資料夾和 1 個檔案。因此,這些檔案已在“include”部分中特別新增。請注意,預設情況下,任何不是 exclude 部分一部分的檔案/資料夾都將包含在內。
請注意兩個 Lambda 函式的路徑。它們都位於 src/models 中。雖然 src/models 預設情況下會被排除,但這些函式特別位於“include”部分中提到的子資料夾中。因此,它們將能夠正常執行。如果我新增一個位於 src/data 中的函式,則該函式將不被允許,因為 src/data 的所有內容都被排除了。
請注意,指定**/** 表示該資料夾內的所有內容(檔案/子資料夾)都將被包含。因此,如果 docs 資料夾包含 10 個子資料夾和 12 個檔案,並且所有這些都需要排除,則**-docs/** 就可以完成任務。我們不需要單獨提及每個檔案/資料夾。
無伺服器 - 外掛
隨著 serverless 的普及,對更多針對特定使用者案例的功能的需求自然會增加。這些需求可以透過外掛來滿足。顧名思義,外掛是可選的,你只需要安裝你需要的外掛即可。在本節中,我們將瞭解如何訪問 serverless 可用的多個外掛,如何安裝這些外掛以及如何在 serverless.yml 中引用它們。
瀏覽外掛列表
所有可用於 serverless 的外掛都可以在www.serverless.com/plugins/ 找到。
你可以在此處搜尋外掛。例如,如果你搜索“Python”,你將看到專門為 Python 執行時開發的幾個外掛。它們按照流行程度的順序排列。
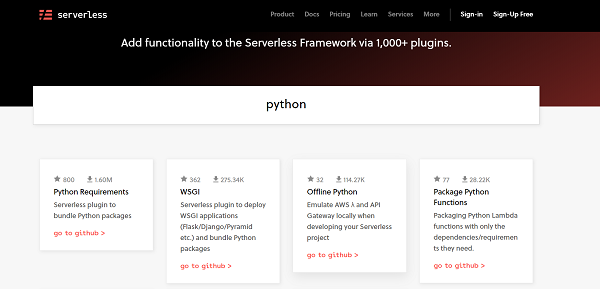
讓我們看一下最流行的 Python 外掛(撰寫本文時):Python Requirements。單擊該外掛。這將開啟與該外掛相關的詳細文件。
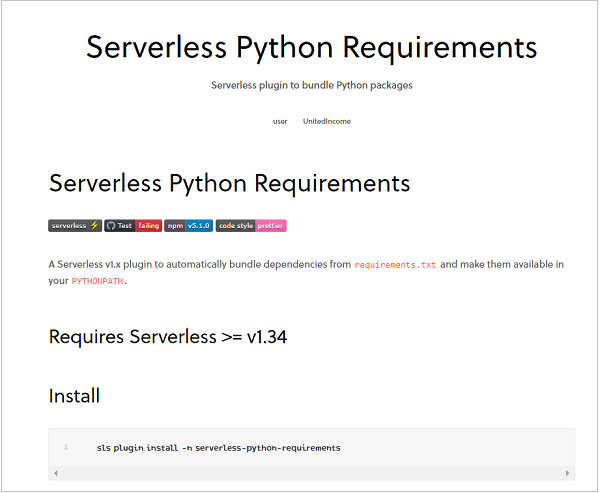
此文件涵蓋了兩個最重要的方面:安裝外掛以及在 serverless.yml 中引用它。這適用於任何外掛。你只需要開啟其文件即可瞭解該外掛的安裝和使用方法。回到 Python Requirements 外掛,文件指出此外掛會自動捆綁來自 requirements.txt 的依賴項,並在你的 PYTHONPATH 中提供它們。
換句話說,如果你的 Lambda 函式需要額外的依賴項,例如 pandas、numpy、matplotlib 等,你只需要在一個 requirements.txt 檔案中指定這些依賴項,該檔案與你的 serverless.yml 檔案位於同一資料夾中。然後,此外掛將完成其餘工作。你甚至可以在 requirements.txt 中指定庫的版本號。例如,這是一個示例 requirements.txt 檔案:
aws-psycopg2==1.2.1 boto boto3==1.7.62 botocore==1.10.62 numpy==1.14.5 pandas==0.25.0 scipy==1.5.2 sqlalchemy==1.2.15
如你所見,你可以只提及依賴項名稱,也可以新增版本號(用 == 符號分隔)。當然,依賴項以及應用程式程式碼的大小不應超過 250 MB。因此,務必僅包含實際需要的依賴項。
現在,讓我們回到我們的外掛。我們已經準備好 requirements.txt 檔案。下一步是安裝外掛。開啟你的命令提示符並導航到包含 serverless.yml 檔案的專案資料夾。然後,按照文件說明,執行以下命令來安裝外掛:
sls plugin install -n serverless-python-requirements
事實上,如果你將**serverless-python-requirements**替換為任何其他外掛名稱,上述命令對於大多數外掛仍然有效。但是,建議你在安裝新外掛時,按照文件中給出的安裝命令操作。執行上述命令時,你應該會看到類似於下圖中的訊息:

如你所見,在專案資料夾中建立了一個 packages.json 檔案。如果你的專案資料夾中已存在 packages.json 檔案,它將被編輯以包含上述外掛。此外,serverless.yml 檔案將自動編輯以包含已安裝的外掛。如果你現在開啟 serverless.yml 檔案,你應該會看到添加了以下幾行:
plugins: - serverless-python-requirements
這意味著在 serverless.yml 中對外掛的引用是自動完成的。此外掛有幾個相關的設定,可以在文件中找到。我們將在下一章討論與“交叉編譯”相關的設定。但現在,讓我們只看看使用此外掛的效果。我在我的 requirements.txt 中添加了 numpy。我的 handler.py 檔案如下所示:
import time
import numpy
def hello(event, context):
print("second update!")
time.sleep(4)
print(numpy.random.randint(100))
return("hello")
現在,讓我們將其部署到 Lambda。你應該會看到類似於下圖中的訊息。關注包的大小。它現在 > 14 MB(這是壓縮包的大小),而不是新增外掛之前的 ~10 kB,因為 numpy 依賴項也一起打包了。
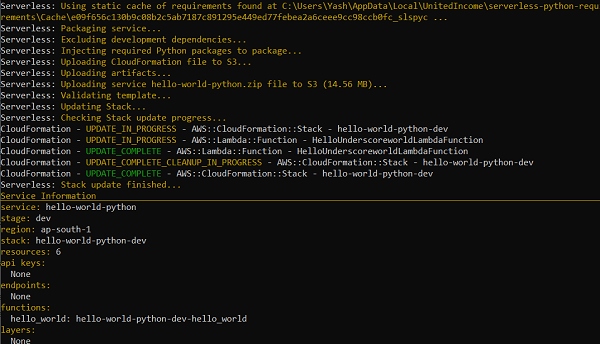
這證明依賴項現在與應用程式程式碼一起打包了。你可以使用**sls invoke local -f function_name**在本地對其進行測試。如果你使用的是 Windows 或 Mac,則很有可能在 AWS Lambda 控制檯中測試已部署的 Lambda 函式會丟擲錯誤,類似於以下錯誤:
Unable to import module 'handler': IMPORTANT: PLEASE READ THIS FOR ADVICE ON HOW TO SOLVE THIS ISSUE! Importing the numpy C-extensions failed. This error can happen for many reasons, often due to issues with your setup or how NumPy was installed. We have compiled some common reasons and troubleshooting tips at: https://numpy.org/devdocs/user/troubleshooting-importerror.html Please note and check the following: * The Python version is: Python3.8 from "/var/lang/bin/python3.8" * The NumPy version is: "1.19.4" and make sure that they are the versions you expect. Please carefully study the documentation linked above for further help. Original error was: No module named 'numpy.core._multiarray_umath'
請繼續閱讀下一章,瞭解為什麼會出現此錯誤以及如何處理它。
無伺服器 - 打包依賴項
在上一章中,我們瞭解瞭如何在 serverless 中使用外掛。我們特別關注了 Python Requirements 外掛,並瞭解瞭如何使用它將 numpy、scipy、pandas 等依賴項與你的 Lambda 函式的應用程式程式碼捆綁在一起。我們甚至看到了部署需要 numpy 依賴項的函式的示例。我們看到它在本地執行良好,但在 AWS Lambda 控制檯中,如果你使用的是 Windows 或 Mac 機器,則會遇到錯誤。讓我們瞭解為什麼函式可以在本地執行,但在部署後卻無法執行。
如果你檢視錯誤訊息,你會得到一些提示。我特別指的是一行:“匯入 numpy C 擴充套件失敗”。現在,許多重要的 python 包,例如 numpy、pandas、scipy 等,都需要編譯 C 擴充套件。如果我們在 Windows 或 Mac 機器上編譯它們,那麼 Lambda(Linux 環境)在嘗試載入它們時會丟擲錯誤。所以重要的問題是,有什麼方法可以避免此錯誤。Docker 登場了!
什麼是 Docker?
根據維基百科,Docker 是一套平臺即服務 (PaaS) 產品,它們使用作業系統級虛擬化來將軟體打包到稱為容器的包中。如果你再多瀏覽一下 Docker 的維基百科頁面,你還會看到一些更相關的語句:Docker 可以將應用程式及其依賴項打包到可在任何 Linux、Windows 或 macOS 計算機上執行的虛擬容器中。這使應用程式能夠在各種位置執行,例如本地、公共雲和/或私有云。我認為在上述語句之後應該非常清楚了。我們出現錯誤是因為在 Windows/Mac 上編譯的 C 擴充套件在 Linux 中不起作用。
我們可以透過將應用程式打包到可在任何作業系統上執行的容器中來簡單地繞過該錯誤。Docker 在後臺為實現這種作業系統級虛擬化所做的工作超出了本章的範圍。
安裝 Docker
你可以訪問https://dockerdocs.tw/engine/install/ 來安裝 Docker Desktop。如果你使用的是 Windows 10 家庭版,則 Windows 版本應至少為 1903(2019 年 5 月更新)。因此,你可能需要升級你的 Windows 10 作業系統才能安裝 Docker Desktop。Windows 專業版或企業版沒有此類限制。
在 serverless 中使用 dockerizePip
在你的機器上安裝 Docker Desktop 後,你只需要在你的 serverless.yml 檔案中新增以下內容即可使用 docker 打包你的應用程式和依賴項:
custom:
pythonRequirements:
dockerizePip: true
請注意,如果你從上一章開始一直跟著我操作,你很可能已經將程式碼部署到 Lambda 一次了。這會在你的本地儲存中建立靜態快取。預設情況下,serverless 將使用該快取來捆綁依賴項,因此不會建立 docker 容器。因此,為了強制 serverless 使用 docker,我們將向 pythonRequirements 新增另一個語句:
custom:
pythonRequirements:
dockerizePip: true
useStaticCache: false #not necessary if you will be deploying the code to lambda for the first time.
如果你第一次部署到 Lambda,則不需要此最後一條語句。通常,你應該將 useStaticCache 設定為 true,因為這會在你沒有更改依賴項或打包方式時節省一些打包時間。
新增這些內容後,serverless.yml 檔案現在如下所示:
service: hello-world-python
provider:
name: aws
runtime: python3.6
profile: yash-sanghvi
region: ap-south-1
functions:
hello_world:
handler: handler.hello
timeout: 6
memorySize: 128
plugins:
- serverless-python-requirements
custom:
pythonRequirements:
dockerizePip: true
useStaticCache: false #not necessary if you will be deploying the code to lambda for the first time.
現在,當你執行**sls deploy -v**命令時,請確保 docker 在後臺執行。在 Windows 上,你只需在“開始”選單中搜索 Docker Desktop 並雙擊該應用程式即可。你很快就會收到一條訊息,表明它正在執行。你也可以透過 Windows 電池圖示附近的彈出視窗來驗證這一點。如果你在那裡看到 docker 圖示,則表示它正在執行。

現在,當你在 AWS Lambda 控制檯中執行你的函式時,它應該可以正常工作了。恭喜!
但是,在 AWS Lambda 控制檯的“函式程式碼”部分,您會看到一條訊息,提示“Lambda 函式“hello-world-python-dev-hello_world”的部署包太大,無法啟用內聯程式碼編輯。但是,您仍然可以呼叫您的函式。”

看來新增 Numpy 依賴項使包大小過大,因此我們甚至無法在 lambda 控制檯中編輯應用程式程式碼。我們如何解決這個問題?請繼續閱讀下一章以瞭解解決方案。
參考資料
無伺服器 - 層建立
什麼是層?
層是一種隔離程式碼塊的方法。假設您想在應用程式中匯入 NumPy 庫。您信任該庫,並且幾乎沒有機會更改該庫的原始碼。因此,如果您不希望 NumPy 的原始碼弄亂您的應用程式工作區,您會怎麼做呢?簡單來說,您只需要 NumPy 位於其他地方,與您的應用程式程式碼隔離即可。層允許您做到這一點。您可以簡單地將所有依賴項(NumPy、Pandas、SciPy 等)捆綁在一個單獨的層中,然後在 serverless 中的 lambda 函式中引用該層。就是這樣!現在可以將該層中捆綁的所有庫匯入到您的應用程式中。同時,您的應用程式工作區保持完全整潔。您只需檢視應用程式程式碼即可進行編輯。

照片由 Iva Rajovic 在 Unsplash 上提供,表示層中的程式碼分離
層真正酷的一點是它們可以在函式之間共享。假設您部署了一個帶有包含 NumPy 和 Pandas 的 python-requirements 層的 lambda 函式。現在,如果另一個 lambda 函式需要 NumPy,則無需為此函式部署單獨的層。您可以簡單地使用先前函式的層,它也可以與新函式一起正常工作。
這將節省您在部署期間的大量寶貴時間。畢竟,您只需要部署應用程式程式碼。依賴項已存在於現有層中。因此,許多開發人員將依賴項層儲存在單獨的堆疊中。然後,他們在所有其他應用程式中使用此層。這樣,他們就不需要反覆部署依賴項。畢竟,依賴項相當龐大。僅 NumPy 庫就大約有 80 MB 大。每次更改應用程式程式碼(可能只有幾 KB)時都部署依賴項將非常不方便。
新增依賴項層只是一個示例。還有其他幾個用例。例如,serverless.com 上提供的示例涉及使用 FFmpeg 工具建立 GIF。在該示例中,他們將 FFmpeg 工具儲存在一個層中。總而言之,AWS Lambda 允許我們為每個函式最多新增 5 個層。唯一的條件是 5 個層的總大小和應用程式應小於 250 MB。
建立 python-requirements 層
現在讓我們看看如何使用 serverless 建立和部署包含所有依賴項的層。為此,我們需要 **serverless-python-requirements** 外掛。此外掛僅適用於 Serverless 1.34 及更高版本。因此,如果您使用的是低於 1.34 的版本,則可能需要升級您的 Serverless 版本。您可以使用以下命令安裝外掛:
sls plugin install -n serverless-python-requirements
接下來,您在 serverless.yml 的 plugins 部分新增此外掛,並在 custom 部分提及其配置:
plugins:
- serverless-python-requirements
custom:
pythonRequirements:
dockerizePip: true
layer: true
這裡,**dockerizePip** - **true** 啟用 docker 的使用,並允許您在 docker 容器中打包所有依賴項。我們在上一章討論了使用 docker 打包的方法。**layer** - **true** 告訴 serverless 應將 python 依賴項儲存在單獨的層中。現在,您可能想知道 serverless 如何知道要打包哪些依賴項?答案,如外掛章節中所述,在於 requirements.txt 檔案。
定義層外掛和自定義配置後,您可以按如下方式將層新增到 serverless 中的各個函式:
functions:
hello:
handler: handler.hello
layers:
- { Ref: PythonRequirementsLambdaLayer }
關鍵字 **PythonRequirementsLambdaLayer** 來自 CloudFormation 參考。一般來說,它源自層的名稱。語法是“LayerNameLambdaLayer”(標題大小寫,無空格)。在我們的例子中,由於層名稱是 python requirements,因此引用變為 PythonRequirementsLambdaLayer。如果您不確定 lambda 層的名稱,您可以按照以下步驟獲取:
執行 **sls package**
開啟 .serverless/cloudformation-template-update-stack.json
搜尋“LambdaLayer”
使用同一區域中另一個函式的現有層
正如我在開頭提到的那樣,層真正酷的一點是能夠在函式中使用現有層。這可以透過使用現有層的 ARN 來輕鬆完成。使用 ARN 將現有層新增到函式的語法非常簡單:
functions:
hello:
handler: handler.hello
layers:
- arn:aws:lambda:region:XXXXXX:layer:LayerName:Y
就是這樣。現在,具有指定 ARN 的層將與您的函式一起工作。如果層包含 NumPy 庫,您可以直接在您的“hello”函式中呼叫 **import numpy**。它將執行而不會出現任何錯誤。
如果您想知道從哪裡可以獲取 ARN,實際上非常簡單。只需導航到 AWS 控制檯中包含該層的函式,然後單擊“層”。
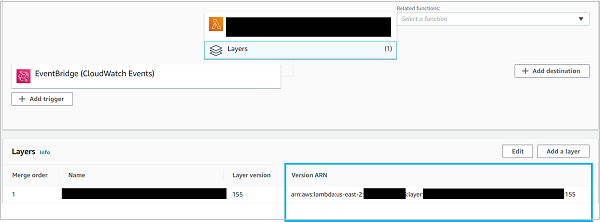
當然,如果該層不屬於您的帳戶,則需要將其公開共享或專門與您的帳戶共享。稍後將詳細介紹。
另外,請記住,該層應與您的應用程式相容。不要指望與 node.js 執行時相容的層能夠與在 python3.6 執行時中建立的函式一起執行。
非依賴項/通用層
如開頭所述,層的主要功能是隔離程式碼塊。因此,它們不需要只包含依賴項。它們可以包含您指定的任何程式碼片段。在 **custom** 中的 **pythonRequirements** 中呼叫 **layer: true** 是 **serverless-python-requirements** 外掛實現的一種快捷方式。但是,要建立通用層,serverless.yml 中的語法,如 serverless 文件 中所述,如下所示:
layers:
hello:
path: layer-dir # required, path to layer contents on disk
name: ${opt:stage, self:provider.stage, 'dev'}-layerName # optional, Deployed Lambda layer name
description: Description of what the lambda layer does # optional, Description to publish to AWS
compatibleRuntimes: # optional, a list of runtimes this layer is compatible with
- python3.8
licenseInfo: GPLv3 # optional, a string specifying license information
# allowedAccounts: # optional, a list of AWS account IDs allowed to access this layer.
# - '*'
# note: uncommenting this will give all AWS users access to this layer unconditionally.
retain: false # optional, false by default. If true, layer versions are not deleted as new ones are created
由於提供了註釋,因此各種配置引數是不言自明的。除了“path”之外,所有其他屬性都是可選的。path 屬性是您希望從應用程式程式碼中隔離的選擇目錄的路徑。它將被壓縮併發布為您的層。例如,在 serverless 上的示例專案 中,他們將 FFmpeg 工具託管在一個層中,他們在名為“layer”的單獨資料夾中下載該工具,並在 path 屬性中指定該資料夾。
layers:
ffmpeg:
path: layer
如前所述,我們可以在 **layers** 屬性中最多新增 5 個層。
要使用這些通用層中的函式,您可以再次使用 CloudFormation 引用或指定 ARN。
允許其他帳戶訪問層
只需在“allowedAccounts”屬性中提及帳戶編號,即可向更多帳戶提供對您的層的訪問許可權。例如:
layers:
testLayer:
path: testLayer
allowedAccounts:
- 999999999999 # a specific account ID
- 000123456789 # a different specific account ID
如果要使層公開訪問,可以在 allowedAccounts 中新增“*”:
layers:
testLayer:
path: testLayer
allowedAccounts:
- '*'
參考資料
無伺服器 - 使用 DynamoDB 的 REST API
到目前為止,我們已經學習了與無伺服器 lambda 部署相關的幾個概念。現在是時候檢視一些示例了。在本章中,我們將研究 Serverless 官方提供的示例之一。我們將建立一個 REST API(正如其名稱所示)。正如您可能猜到的那樣,我們的所有 lambda 函式都將由 API Gateway 觸發。我們的 lambda 函式將與 dynamoDB 表(本質上是一個待辦事項列表)互動,使用者將能夠使用將要公開的端點執行多項操作,例如建立新專案、獲取現有專案、刪除專案等部署後。如果您不熟悉 REST API,您可以在這裡瞭解更多資訊。
程式碼演練
程式碼可在 GitHub 上找到:https://github.com/serverless/examples/tree/master/aws-python-rest-api-with-dynamodb
我們將檢視專案結構,討論一些我們之前沒有見過的新概念,然後執行 serverless.yml 檔案的演練。所有函式處理程式的演練將是冗餘的。因此,我們將只演練一個函式處理程式。您可以將理解其他函式作為練習。
專案結構
現在,如果您檢視專案結構,lambda 函式處理程式都位於 todos 資料夾中的單獨 .py 檔案中。serverless.yml 檔案在每個函式處理程式的路徑中指定 todos 資料夾。沒有外部依賴項,因此也沒有 requirements.txt 檔案。
新概念
現在,您可能第一次看到一些術語。讓我們快速瀏覽一下:
**dynamoDB** - 這是 AWS 提供的 NoSQL(不僅僅是 SQL)資料庫。雖然不完全準確,但廣義地說,NoSQL 之於 SQL 就如同 Word 之於 Excel。您可以在這裡閱讀更多關於 NoSQL 的資訊。有四種類型的 NoSQL 資料庫:文件資料庫、鍵值資料庫、列式儲存和圖資料庫。dynamoDB 是一個鍵值資料庫,這意味著您可以將鍵值對不斷插入到資料庫中。這類似於 redis 快取。您可以透過引用其鍵來檢索值。
**boto3** - 這是 Python 的 AWS SDK。如果您需要在 lambda 函式中配置、管理、呼叫或建立任何 AWS 服務(EC2、dynamoDB、S3 等),則需要 boto3 SDK。您可以在這裡閱讀更多關於 boto3 的資訊。
除此之外,在 serverless.yml 和處理程式函式的演練過程中,我們將遇到一些概念。我們將在那裡討論它們。
serverless.yml 演練
serverless.yml 檔案以服務的定義開頭。
service: serverless-rest-api-with-dynamodb
接下來是透過以下行宣告框架版本範圍:
frameworkVersion: ">=1.1.0 <=2.1.1"
這就像一個檢查。如果您的 serverless 版本不在此範圍內,它將丟擲錯誤。當您共享程式碼並希望每個人使用此 serverless.yml 檔案都使用相同的 serverless 版本範圍以避免問題時,這很有幫助。
接下來,在 provider 中,我們看到了兩個我們之前沒有遇到過的額外欄位:**environment** 和 **iamRoleStatements**。
provider:
name: aws
runtime: python3.8
environment:
DYNAMODB_TABLE: ${self:service}-${opt:stage, self:provider.stage}
iamRoleStatements:
- Effect: Allow
Action:
- dynamodb:Query
- dynamodb:Scan
- dynamodb:GetItem
- dynamodb:PutItem
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource: "arn:aws:dynamodb:${opt:region, self:provider.region}:
*:table/${self:provider.environment.DYNAMODB_TABLE}"
**Environment**,正如您可能猜到的那樣,用於定義環境變數。在此 serverless.yml 檔案中定義的所有函式都可以獲取這些環境變數。我們將在下面的函式處理程式演練中看到一個示例。在這裡,我們將 dynamoDB 表名稱定義為環境變數。
$ 符號表示變數。self 關鍵字指代 serverless.yml 檔案本身,而 opt 指的是我們在 sls deploy 命令中提供的選項。因此,表名將是服務名稱後面跟一個連字元,再跟檔案找到的第一個階段引數: serverless deploy 命令期間可用的選項之一,或提供程式階段(預設為 dev)。因此,在這種情況下,如果您在 serverless deploy 命令期間未提供任何選項,則 dynamoDB 表名為 serverless-rest-api-with-dynamodb-dev。您可以此處瞭解更多關於 serverless 變數的資訊。
iamRoleStatements 定義賦予函式的許可權。在本例中,我們允許函式對 dynamoDB 表執行以下操作:Query、Scan、GetItem、PutItem、UpdateItem 和 DeleteItem。資源名稱指定允許執行這些操作的確切表。如果您在資源名稱位置輸入了 "*",則表示允許對所有表執行這些操作。但是,這裡我們只想允許對一個表執行這些操作,因此,使用標準 arn 格式在資源名稱中提供了此表的 arn(Amazon 資源名稱)。同樣,這裡使用 serverless deploy 命令期間指定的選項區域(如果存在)或提供程式中提到的區域(預設為 us-east-1)中的第一個。
在 functions 部分,函式按照標準格式定義。請注意,get、update、delete 都有相同的路徑,id 作為路徑引數。但是,每種方法都不同。
functions:
create:
handler: todos/create.create
events:
- http:
path: todos
method: post
cors: true
list:
handler: todos/list.list
events:
- http:
path: todos
method: get
cors: true
get:
handler: todos/get.get
events:
- http:
path: todos/{id}
method: get
cors: true
update:
handler: todos/update.update
events:
- http:
path: todos/{id}
method: put
cors: true
delete:
handler: todos/delete.delete
events:
- http:
path: todos/{id}
method: delete
cors: true
稍後,我們會遇到一個以前從未見過的塊,即 resources 塊。此塊基本上可幫助您在 CloudFormation 模板中指定函式執行所需建立的資源。在本例中,我們需要建立一個 dynamoDB 表才能使函式正常執行。到目前為止,我們已經指定了表名,甚至引用了它的 ARN。但是我們還沒有建立表。在 resources 塊中指定表的特性將為我們建立該表。
resources:
Resources:
TodosDynamoDbTable:
Type: 'AWS::DynamoDB::Table'
DeletionPolicy: Retain
Properties:
AttributeDefinitions:
-
AttributeName: id
AttributeType: S
KeySchema:
-
AttributeName: id
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 1
WriteCapacityUnits: 1
TableName: ${self:provider.environment.DYNAMODB_TABLE}
這裡定義了許多配置,其中大部分是特定於 dynamoDB 的。簡而言之,我們要求 serverless 建立一個名為 'TodosDynamoDbTable' 的資源,型別為 'DynamoDB Table',TableName(在底部提到)等於提供程式環境變數中定義的名稱。我們將它的刪除策略設定為 'Retain',這意味著如果堆疊被刪除,則資源將被保留。參見此處。我們宣告該表將具有一個名為 id 的屬性,其型別為字串。我們還指定 id 屬性將是 HASH 金鑰或分割槽金鑰。您可以此處瞭解更多關於 dynamoDB 表中 KeySchemas 的資訊。最後,我們指定表的讀取容量和寫入容量。
就是這樣!我們的 serverless.yml 檔案已準備就緒。現在,由於所有函式處理程式都大致相似,我們將僅介紹 create 函式的處理程式。
create 函式處理程式的演練
我們從幾個匯入語句開始
import json import logging import os import time import uuid
接下來,我們匯入 boto3,如上所述,它是 Python 的 AWS SDK。我們需要 boto3 來在 lambda 函式中與 dynamoDB 互動。
import boto3
dynamodb = boto3.resource('dynamodb')
接下來,在實際的函式處理程式中,我們首先檢查 'events' 有效負載的內容(create API 使用 post 方法)。如果它的主體不包含 'text' 金鑰,則表示我們沒有收到要新增到待辦事項列表中的有效專案。因此,我們將引發異常。
def create(event, context):
data = json.loads(event['body'])
if 'text' not in data:
logging.error("Validation Failed")
raise Exception("Couldn't create the todo item.")
假設我們按預期獲得了 'text' 金鑰,我們將準備將其新增到 dynamoDB 表中。我們獲取當前時間戳,並連線到 dynamoDB 表。請注意如何獲取 serverless.yml 中定義的環境變數(使用 os.environ)
timestamp = str(time.time()) table = dynamodb.Table(os.environ['DYNAMODB_TABLE'])
接下來,我們透過使用 uuid 包生成隨機 uuid,使用接收到的資料作為文字,將 createdAt 和 updatedAt 設定為當前時間戳,並將欄位 'checked' 設定為 False 來建立要新增到表中的專案。'checked' 是另一個欄位,除了文字之外,您還可以使用 update 操作更新它。
item = {
'id': str(uuid.uuid1()),
'text': data['text'],
'checked': False,
'createdAt': timestamp,
'updatedAt': timestamp,
}
最後,我們將專案新增到 dynamoDB 表中,並將建立的專案返回給使用者。
# write the todo to the database
table.put_item(Item=item)
# create a response
response = {
"statusCode": 200,
"body": json.dumps(item)
}
return response
透過此演練,我認為其他函式處理程式將不言自明。在某些函式中,您可能會看到此語句:"body" − json.dumps(result['Item'], cls=decimalencoder.DecimalEncoder)。這是針對json.dumps 中的一個錯誤的解決方法。json.dumps 預設情況下無法處理十進位制數,因此,建立了decimalencoder.py檔案來包含處理此問題的 DecimalEncoder 類。
恭喜您理解了使用 serverless 建立的第一個綜合專案。專案的建立者還在README檔案中分享了他的部署端點以及測試這些函式的方法。請檢視。繼續下一章以檢視另一個示例。
無伺服器 - Telegram 回聲機器人
這是官方 serverless 專案列表中提供的另一個有趣的專案。我們基本上是在 Telegram 上建立一個新的機器人,然後使用 set_webhook 方法將其連線到我們的 lambda 函式,並在 lambda 函式中編寫使機器人回顯它接收到的任何訊息的程式碼。
先決條件
您需要在手機或桌面上安裝 Telegram 應用程式。下載選項可此處找到。Telegram 是一款訊息應用程式,類似於 WhatsApp 或 Messenger。安裝應用程式後,您需要在應用程式中建立一個新的機器人。為此,請點選“新建訊息”圖示(右下角的圓形鉛筆圖示),然後搜尋 BotFather。點選已驗證的帳戶。

與 BotFather 開始聊天后,建立新機器人非常簡單明瞭。您傳送 \newbot 命令,輸入機器人的名稱和使用者名稱,您將獲得一個訪問令牌,您需要記下它。

程式碼演練
程式碼可在 GitHub 上找到 - https://github.com/serverless/examples/tree/master/aws-python-telegram-bot
我們將檢視專案結構,然後執行 serverless.yml 檔案和 handler.py 檔案的演練。
專案結構
我們可以看到,此專案有一個外部依賴項(python telegram bot 庫),列在 requirements.py 中:
python-telegram-bot==8.1.1
package.json 和 serverless.yml 都顯示已使用 serverless-python-requirements 外掛來捆綁 python 需求(在本例中為 telegram bot 庫)。因此,README.md 檔案還建議您執行 npm install 以安裝必要的外掛。我個人建議您刪除 package.json,並使用 sls plugin install -n serverless-python-requirements 安裝 serverless-python-requirements。這將自動建立 package.json 檔案。這也將確保您安裝最新版本的 serverless-python-requirements。透過執行 npm install,您將安裝現有 package.json 中提到的版本,該版本可能已過期。
如果您閱讀 README.md 檔案,您會發現一個被引用的檔案實際上並不存在於專案中:serverless.env.yml。您需要建立此檔案並在其中輸入您的 TELEGRAM_TOKEN。這是出於安全原因考慮。TELEGRAM_TOKEN 應該保密,您不希望公開共享它。因此,此專案的建立者沒有在 GitHub 上新增 serverless.env.yml 檔案。但是您需要在本地機器上建立它。
serverless.yml 演練
serverless.yml 檔案以服務的定義開頭。
service: serverless-telegram-bot
接下來,定義提供程式。這裡再次設定了一個環境變數。此變數 (TELEGRAM_TOKEN) 的值是從您應該在本地建立的 serverless.env.yml 檔案中獲取的。同樣,我們使用 $ 來表示變數。
provider:
name: aws
runtime: python3.6
profile: ckl
environment:
TELEGRAM_TOKEN: ${file(./serverless.env.yml):TELEGRAM_TOKEN, ''}
functions 塊非常簡單明瞭。定義了兩個函式,都是 HTTP 觸發的。但是,http 事件引數在這裡用一行程式碼定義。
- http: path: /set_webhook method: post
使用的單行執行替換為 - http − POST /set_webhook
另外,請注意 webhook 和 set_webhook 函式都在同一個處理程式檔案中。
functions:
webhook:
handler: handler.webhook
events:
- http: POST /
set_webhook:
handler: handler.set_webhook
events:
- http: POST /set_webhook
最後,定義 serverless-python-requirements 外掛。
plugins: - serverless-python-requirements
handler.py 的演練
我們從幾個匯入語句開始
import json import telegram import os import logging
接下來,定義一個日誌記錄器物件,它基本上可以幫助我們輸入日誌語句。請注意,這對於 python 執行時函式不是必需的。簡單的 print 語句也會被記錄。
唯一的區別是日誌器的輸出包括日誌級別、時間戳和請求 ID。您可以此處瞭解更多關於 logging 庫的資訊。
# Logging is cool!
logger = logging.getLogger()
if logger.handlers:
for handler in logger.handlers:
logger.removeHandler(handler)
logging.basicConfig(level=logging.INFO)
接下來,定義 OK_RESPONSE 和 ERROR_RESPONSE 的 JSON。它們用作函式的返回值。
OK_RESPONSE = {
'statusCode': 200,
'headers': {'Content-Type': 'application/json'},
'body': json.dumps('ok')
}
ERROR_RESPONSE = {
'statusCode': 400,
'body': json.dumps('Oops, something went wrong!')
}
接下來,定義兩個 API 函式使用的輔助函式。此函式使用在 serverless.yml 中作為環境變數提供的令牌返回一個機器人例項。
def configure_telegram():
"""
Conimages the bot with a Telegram Token.
Returns a bot instance.
"""
TELEGRAM_TOKEN = os.environ.get('TELEGRAM_TOKEN')
if not TELEGRAM_TOKEN:
logger.error('The TELEGRAM_TOKEN must be set')
raise NotImplementedError
return telegram.Bot(TELEGRAM_TOKEN)
接下來,定義兩個 API 的處理程式函式。讓我們首先看看 set_webhook 函式。在這裡,從我們前面看到的 configure_telegram 函式中獲取機器人例項。接下來,從標頭中提取 host 欄位,並從傳入事件的 requestContext 塊中提取 stage 欄位。使用這兩個欄位,構造 webhook 的 URL。最後,使用 bot.set_webhook(url) 函式將其應用於機器人。如果 webhook 設定正確,則設定 OK_RESPONSE,否則設定 ERROR_RESPONSE。請注意,此 set_webhook API 必須使用 POSTMAN 等工具手動觸發一次。
def set_webhook(event, context):
"""
Sets the Telegram bot webhook.
"""
logger.info('Event: {}'.format(event))
bot = configure_telegram()
url = 'https://{}/{}/'.format(
event.get('headers').get('Host'),
event.get('requestContext').get('stage'),
)
webhook = bot.set_webhook(url)
if webhook:
return OK_RESPONSE
return ERROR_RESPONSE
讓我們瞭解`set_webhook`函式如何獲取正確的Webhook URL。請注意,`set_webhook`函式和`webhook`函式的路徑僅相差`/set_webhook`。它們共享相同的host和stage。因此,我們可以使用`set_webhook`函式事件中接收到的host和dev來推匯出`webhook`函式的端點。如果您的端點是'https://abcdefghijk.execute-api.us-east-1.amazonaws.com/dev',那麼host將是'https://abcdefghijk.execute-api.us-east-1.amazonaws.com',stage將是'dev'。`set_webhook`函式由'https://abcdefghijk.execute-api.us-east-1.amazonaws.com/dev/set_webhook'觸發,而`webhook`函式由'https://abcdefghijk.execute-api.us-east-1.amazonaws.com/dev'觸發。因此,`set_webhook`事件中的引數可以幫助我們構造`webhook`函式的端點URL。
最後,讓我們看看`webhook`函式。它非常簡單。它從configure_telegram輔助函式接收bot例項。然後它檢查事件。如果它是一個POST事件並且包含主體,則它從主體中提取聊天ID和訊息。如果文字是'/start',表示對話開始,它將使用bot.sendMessage(chat_id=chat_id, text=text)命令回覆標準問候語。否則,它將回復它接收到的相同文字。
def webhook(event, context):
"""
Runs the Telegram webhook.
"""
bot = configure_telegram()
logger.info('Event: {}'.format(event))
if event.get('httpMethod') == 'POST' and event.get('body'):
logger.info('Message received')
update = telegram.Update.de_json(json.loads(event.get('body')), bot)
chat_id = update.message.chat.id
text = update.message.text
if text == '/start':
text = """Hello, human! I am an echo bot, built with Python and the Serverless Framework.
You can take a look at my source code here: https://github.com/jonatasbaldin/serverless-telegram-bot.
If you have any issues, please drop a tweet to my creator: https://twitter.com/jonatsbaldin. Happy botting!"""
bot.sendMessage(chat_id=chat_id, text=text)
logger.info('Message sent')
return OK_RESPONSE
return ERROR_RESPONSE
一旦您透過POSTMAN之類的工具觸發了`set_webhook`函式,您就可以在Telegram上開啟您的機器人並與它聊天。它將按預期回顯訊息。
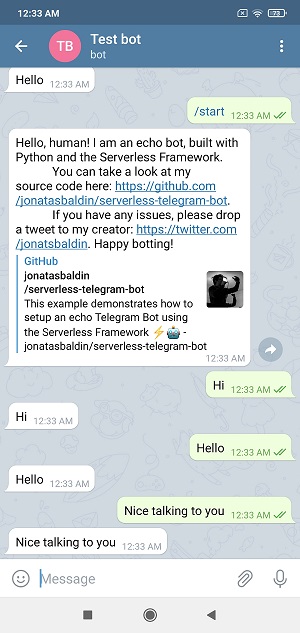
恭喜您建立了您的第一個Telegram機器人!