- Python - 文字處理
- Python - 文字處理簡介
- Python - 文字處理環境
- Python - 字串不變性
- Python - 排序行
- Python - 段落重新格式化
- Python - 統計段落中的詞元
- Python - 二進位制ASCII轉換
- Python - 字串作為檔案
- Python - 反向讀取檔案
- Python - 過濾重複單詞
- Python - 從文字中提取電子郵件
- Python - 從文字中提取URL
- Python - 美化列印
- Python - 文字處理狀態機
- Python - 首字母大寫和翻譯
- Python - 分詞
- Python - 刪除停用詞
- Python - 同義詞和反義詞
- Python - 文字翻譯
- Python - 單詞替換
- Python - 拼寫檢查
- Python - WordNet介面
- Python - 語料庫訪問
- Python - 詞性標註
- Python - 塊和塊隙
- Python - 塊分類
- Python - 文字分類
- Python - 二元語法
- Python - 處理PDF
- Python - 處理Word文件
- Python - 讀取RSS Feed
- Python - 情感分析
- Python - 搜尋和匹配
- Python - 文字處理
- Python - 文字換行
- Python - 頻率分佈
- Python - 文字摘要
- Python - 詞幹提取演算法
- Python - 受限搜尋
Python - 塊和塊隙
Chunking(塊化)是根據單詞的性質將相似的單詞分組在一起的過程。在下面的示例中,我們定義了一個語法,根據該語法必須生成塊。語法建議在建立塊時要遵循的短語序列,例如名詞和形容詞等。塊的圖示輸出如下所示。
import nltk
sentence = [("The", "DT"), ("small", "JJ"), ("red", "JJ"),("flower", "NN"),
("flew", "VBD"), ("through", "IN"), ("the", "DT"), ("window", "NN")]
grammar = "NP: {?*}"
cp = nltk.RegexpParser(grammar)
result = cp.parse(sentence)
print(result)
result.draw()
執行上述程式後,我們將得到以下輸出:
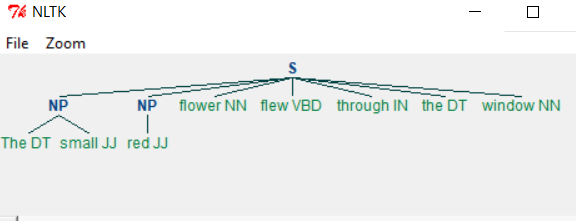
更改語法後,我們將得到如下所示的不同輸出:
import nltk
sentence = [("The", "DT"), ("small", "JJ"), ("red", "JJ"),("flower", "NN"),
("flew", "VBD"), ("through", "IN"), ("the", "DT"), ("window", "NN")]
grammar = "NP: {執行上述程式後,我們將得到以下輸出:
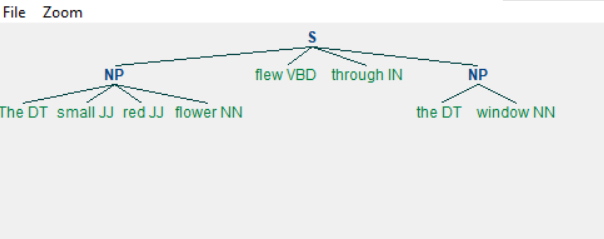
Chinking(塊隙)
Chinking(塊隙)是從塊中移除一系列詞元的過程。如果一系列詞元出現在塊的中間,則會移除這些詞元,留下它們原來存在的兩個塊。
import nltk
sentence = [("The", "DT"), ("small", "JJ"), ("red", "JJ"),("flower", "NN"), ("flew", "VBD"), ("through", "IN"), ("the", "DT"), ("window", "NN")]
grammar = r"""
NP:
{<.*>+} # Chunk everything
}+{ # Chink sequences of JJ and NN
"""
chunkprofile = nltk.RegexpParser(grammar)
result = chunkprofile.parse(sentence)
print(result)
result.draw()
執行上述程式後,我們將得到以下輸出:
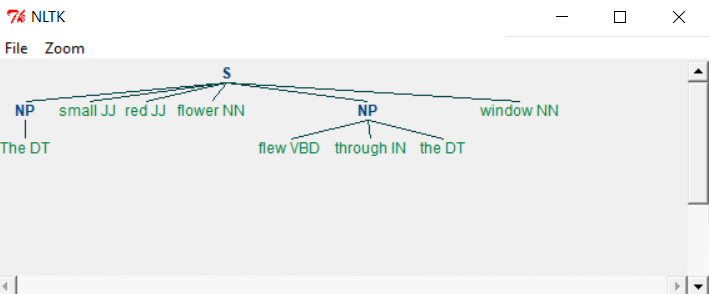
正如您所看到的,滿足語法條件的部分作為單獨的塊從名詞短語中被提取出來。這個提取不在所需塊中的文字的過程稱為chinking(塊隙)。
廣告