- Python 資料持久化教程
- Python 資料持久化 - 首頁
- Python 資料持久化 - 簡介
- Python 資料持久化 - 檔案 API
- 使用 os 模組處理檔案
- Python 資料持久化 - 物件序列化
- Python 資料持久化 - Pickle 模組
- Python 資料持久化 - Marshal 模組
- Python 資料持久化 - Shelve 模組
- Python 資料持久化 - dbm 包
- Python 資料持久化 - CSV 模組
- Python 資料持久化 - JSON 模組
- Python 資料持久化 - XML 解析器
- Python 資料持久化 - Plistlib 模組
- Python 資料持久化 - Sqlite3 模組
- Python 資料持久化 - SQLAlchemy
- Python 資料持久化 - PyMongo 模組
- Python 資料持久化 - Cassandra 驅動程式
- 資料持久化 - ZODB
- 資料持久化 - Openpyxl 模組
- Python 資料持久化資源
- Python 資料持久化 - 快速指南
- Python 資料持久化 - 有用資源
- Python 資料持久化 - 討論
Python 資料持久化 - 快速指南
Python 資料持久化 - 簡介
Python - 資料持久化概述
在使用任何軟體應用程式的過程中,使用者會提供一些資料進行處理。資料可以透過標準輸入裝置(鍵盤)或其他裝置(如磁碟檔案、掃描器、相機、網路電纜、WiFi 連線等)輸入。
接收到的資料以各種資料結構(如變數和物件)的形式儲存在計算機的主記憶體(RAM)中,直到應用程式執行。之後,RAM 中的記憶體內容將被擦除。
但是,很多時候,希望以某種方式儲存變數和/或物件的值,以便在需要時檢索,而不是再次輸入相同的資料。
“持久化”一詞表示“在原因消除後效果的持續”。資料持久化表示即使在應用程式結束之後,資料也仍然存在。因此,儲存在非易失性儲存介質(如磁碟檔案)中的資料是永續性資料儲存。
在本教程中,我們將探索各種內建和第三方 Python 模組,以將資料儲存到和從各種格式(如文字檔案、CSV、JSON 和 XML 檔案以及關係和非關係資料庫)中檢索資料。
使用 Python 的內建 File 物件,可以將字串資料寫入磁碟檔案並從中讀取。Python 的標準庫提供了模組來以各種資料結構(如 JSON 和 XML)儲存和檢索序列化資料。
Python 的 DB-API 提供了一種與關係資料庫互動的標準方法。其他第三方 Python 包提供了與 MongoDB 和 Cassandra 等 NoSQL 資料庫互動的功能。
本教程還介紹了 ZODB 資料庫,它是 Python 物件的持久化 API。Microsoft Excel 格式是一種非常流行的資料檔案格式。在本教程中,我們將學習如何透過 Python 處理 .xlsx 檔案。
Python 資料持久化 - 檔案 API
Python 使用內建的 input() 和 print() 函式執行標準輸入/輸出操作。input() 函式從標準輸入流裝置(即鍵盤)讀取位元組。
另一方面,print() 函式將資料傳送到標準輸出流裝置(即顯示器)。Python 程式透過 sys 模組中定義的標準流物件 stdin 和 stdout 與這些 IO 裝置互動。
input() 函式實際上是 sys.stdin 物件的 readline() 方法的包裝器。從輸入流接收所有擊鍵,直到按下“Enter”鍵。
>>> import sys >>> x=sys.stdin.readline() Welcome to TutorialsPoint >>> x 'Welcome to TutorialsPoint\n'
請注意,readline() 函式會留下一個尾隨的“\n”字元。還有一個 read() 方法,它會從標準輸入流讀取資料,直到它被 Ctrl+D 字元終止。
>>> x=sys.stdin.read() Hello Welcome to TutorialsPoint >>> x 'Hello\nWelcome to TutorialsPoint\n'
類似地,print() 是一個模擬 stdout 物件的 write() 方法的便捷函式。
>>> x='Welcome to TutorialsPoint\n' >>> sys.stdout.write(x) Welcome to TutorialsPoint 26
就像 stdin 和 stdout 預定義的流物件一樣,Python 程式可以從磁碟檔案或網路套接字讀取資料並向其傳送資料。它們也是流。任何具有 read() 方法的物件都是輸入流。任何具有 write() 方法的物件都是輸出流。透過使用內建的 open() 函式獲取對流物件的引用來建立與流的通訊。
open() 函式
此內建函式使用以下引數:
f=open(name, mode, buffering)
name 引數是磁碟檔案或位元組字串的名稱,mode 是可選的單字元字串,用於指定要執行的操作型別(讀取、寫入、追加等),buffering 引數為 0、1 或 -1,表示緩衝區關閉、開啟或系統預設值。
檔案開啟模式根據下表列出。預設模式為“r”
| 序號 | 引數及說明 |
|---|---|
| 1 |
R 開啟以進行讀取(預設) |
| 2 |
W 開啟以進行寫入,首先截斷檔案 |
| 3 |
X 建立一個新檔案並將其開啟以進行寫入 |
| 4 |
A 開啟以進行寫入,如果檔案存在則追加到檔案末尾 |
| 5 |
B 二進位制模式 |
| 6 |
T 文字模式(預設) |
| 7 |
+ 開啟磁碟檔案以進行更新(讀取和寫入) |
為了將資料儲存到檔案,必須以“w”模式開啟它。
f=open('test.txt','w')
此檔案物件充當輸出流,並可以訪問 write() 方法。write() 方法將字串傳送到此物件,並將其儲存在底層檔案中。
string="Hello TutorialsPoint\n" f.write(string)
關閉流非常重要,以確保緩衝區中任何剩餘的資料都完全傳輸到它。
file.close()
嘗試使用任何文字編輯器(如記事本)開啟“test.txt”,以確認檔案已成功建立。
要以程式設計方式讀取“test.txt”的內容,必須以“r”模式開啟它。
f=open('test.txt','r')
此物件充當輸入流。Python 可以使用 read() 方法從流中獲取資料。
string=f.read() print (string)
檔案的內容顯示在 Python 控制檯上。File 物件還支援 readline() 方法,該方法能夠讀取字串,直到遇到 EOF 字元。
但是,如果以“w”模式開啟同一個檔案以在其儲存其他文字,則先前的內容將被擦除。每當以寫入許可權開啟檔案時,都會將其視為新檔案。要將資料新增到現有檔案,請使用“a”表示追加模式。
f=open('test.txt','a')
f.write('Python Tutorials\n')
現在,檔案具有先前以及新新增的字串。檔案物件還支援 writelines() 方法將列表物件中的每個字串寫入檔案。
f=open('test.txt','a')
lines=['Java Tutorials\n', 'DBMS tutorials\n', 'Mobile development tutorials\n']
f.writelines(lines)
f.close()
示例
readlines() 方法返回一個字串列表,每個字串代表檔案中的一個行。還可以逐行讀取檔案,直到到達檔案末尾。
f=open('test.txt','r')
while True:
line=f.readline()
if line=='' : break
print (line, end='')
f.close()
輸出
Hello TutorialsPoint Python Tutorials Java Tutorials DBMS tutorials Mobile development tutorials
二進位制模式
預設情況下,檔案物件上的讀/寫操作對文字字串資料執行。如果我們要處理不同其他型別的檔案,例如媒體 (mp3)、可執行檔案 (exe)、圖片 (jpg) 等,我們需要在讀/寫模式中新增“b”字首。
以下語句會將字串轉換為位元組並寫入檔案。
f=open('test.bin', 'wb')
data=b"Hello World"
f.write(data)
f.close()
也可以使用 encode() 函式將文字字串轉換為位元組。
data="Hello World".encode('utf-8')
我們需要使用 'rb' 模式讀取二進位制檔案。在列印之前,首先對 read() 方法的返回值進行解碼。
f=open('test.bin', 'rb')
data=f.read()
print (data.decode(encoding='utf-8'))
為了在二進位制檔案中寫入整數資料,應使用 to_bytes() 方法將整數物件轉換為位元組。
n=25
n.to_bytes(8,'big')
f=open('test.bin', 'wb')
data=n.to_bytes(8,'big')
f.write(data)
要從二進位制檔案讀取回資料,請使用 from_bytes() 函式將 read() 函式的輸出轉換為整數。
f=open('test.bin', 'rb')
data=f.read()
n=int.from_bytes(data, 'big')
print (n)
對於浮點數資料,我們需要使用 Python 標準庫中的 struct 模組。
import struct
x=23.50
data=struct.pack('f',x)
f=open('test.bin', 'wb')
f.write(data)
解壓縮 read() 函式的字串,以從二進位制檔案中檢索浮點數資料。
f=open('test.bin', 'rb')
data=f.read()
x=struct.unpack('f', data)
print (x)
同時讀寫
當檔案以寫入方式開啟(使用“w”或“a”)時,無法從中讀取,反之亦然。這樣做會引發 UnSupportedOperation 錯誤。我們需要在執行其他操作之前關閉檔案。
為了同時執行這兩個操作,我們必須在 mode 引數中新增“+”字元。因此,“w+”或“r+”模式允許使用 write() 和 read() 方法,而無需關閉檔案。File 物件還支援 seek() 函式將流倒回至任何所需的位元組位置。
f=open('test.txt','w+')
f.write('Hello world')
f.seek(0,0)
data=f.read()
print (data)
f.close()
下表總結了檔案類物件可用的所有方法。
| 序號 | 方法及說明 |
|---|---|
| 1 |
close() 關閉檔案。關閉的檔案無法再讀取或寫入。 |
| 2 |
flush() 重新整理內部緩衝區。 |
| 3 |
fileno() 返回整數檔案描述符。 |
| 4 |
next() 每次呼叫時都返回檔案中的下一行。在 Python 3 中使用 next() 迭代器。 |
| 5 |
read([size]) 最多從檔案讀取 size 個位元組(如果讀取在獲取 size 個位元組之前遇到 EOF,則讀取更少的位元組)。 |
| 6 |
readline([size]) 從檔案讀取整行。字串中保留尾隨換行符。 |
| 7 |
readlines([sizehint]) 使用 readline() 讀取直到 EOF 並返回包含這些行的列表。 |
| 8 |
seek(offset[, whence]) 設定檔案當前位置。0-開頭 1-當前 2-結尾。 |
| 9 |
seek(offset[, whence]) 設定檔案當前位置。0-開頭 1-當前 2-結尾。 |
| 10 |
tell() 返回檔案當前位置 |
| 11 |
truncate([size]) 截斷檔案大小。 |
| 12 |
write(str) 將字串寫入檔案。沒有返回值。 |
使用 os 模組處理檔案
除了 open() 函式返回的 File 物件之外,還可以使用 Python 的內建庫執行檔案 IO 操作,該庫具有 os 模組,該模組提供了有用的作業系統相關函式。這些函式對檔案執行低階讀/寫操作。
os 模組中的 open() 函式類似於內建的 open()。但是,它不返回檔案物件,而是返回檔案描述符,即對應於開啟檔案的唯一整數。檔案描述符的值 0、1 和 2 分別表示 stdin、stdout 和 stderr 流。其他檔案將從 2 開始獲得遞增的檔案描述符。
與 open() 內建函式一樣,os.open() 函式也需要指定檔案訪問模式。下表列出了 os 模組中定義的各種模式。
| 序號 | Os 模組及說明 |
|---|---|
| 1 |
os.O_RDONLY 僅開啟以進行讀取 |
| 2 |
os.O_WRONLY 僅開啟以進行寫入 |
| 3 |
os.O_RDWR 開啟以進行讀取和寫入 |
| 4 |
os.O_NONBLOCK 開啟時不要阻塞 |
| 5 |
os.O_APPEND 每次寫入時追加 |
| 6 |
os.O_CREAT 如果檔案不存在則建立檔案 |
| 7 |
os.O_TRUNC 將大小截斷為 0 |
| 8 |
os.O_EXCL 如果建立且檔案存在則出錯 |
要開啟一個新檔案以在其寫入資料,請透過插入管道 (|) 運算子指定 O_WRONLY 和 O_CREAT 模式。os.open() 函式返回檔案描述符。
f=os.open("test.dat", os.O_WRONLY|os.O_CREAT)
請注意,資料以位元組字串的形式寫入磁碟檔案。因此,普通字串透過使用 encode() 函式(如前所述)轉換為位元組字串。
data="Hello World".encode('utf-8')
os 模組中的 write() 函式接受此位元組字串和檔案描述符。
os.write(f,data)
不要忘記使用 close() 函式關閉檔案。
os.close(f)
要使用 os.read() 函式讀取檔案內容,請使用以下語句
f=os.open("test.dat", os.O_RDONLY)
data=os.read(f,20)
print (data.decode('utf-8'))
請注意,os.read() 函式需要檔案描述符和要讀取的位元組數(位元組字串的長度)。
如果要開啟檔案以進行同時讀寫操作,請使用 O_RDWR 模式。下表顯示了 os 模組中重要的檔案操作相關函式。
| 序號 | 函式及說明 |
|---|---|
| 1 |
os.close(fd) 關閉檔案描述符。 |
| 2 |
os.open(file, flags[, mode]) 開啟檔案並根據 flags 設定各種標誌,並可能根據 mode 設定其模式。 |
| 3 |
os.read(fd, n) 從檔案描述符 fd 讀取最多 n 個位元組。返回一個包含讀取的位元組的字串。如果已到達 fd 引用的檔案的末尾,則返回空字串。 |
| 4 |
os.write(fd, str) 將字串 str 寫入檔案描述符 fd。返回實際寫入的位元組數。 |
Python 資料持久化 - 物件序列化
Python 內建的 open() 函式返回的檔案物件有一個重要的缺點。當以 'w' 模式開啟時,write() 方法只接受字串物件。
這意味著,如果您的資料以任何非字串形式表示,無論是內建類(數字、字典、列表或元組)的物件還是其他使用者定義類的物件,都無法直接寫入檔案。在寫入之前,您需要將其轉換為字串表示形式。
numbers=[10,20,30,40]
file=open('numbers.txt','w')
file.write(str(numbers))
file.close()
對於二進位制檔案,write() 方法的引數必須是位元組物件。例如,整數列表透過 bytearray() 函式轉換為位元組,然後寫入檔案。
numbers=[10,20,30,40] data=bytearray(numbers) file.write(data) file.close()
要從檔案中讀取回相應資料型別的資料,需要進行反向轉換。
file=open('numbers.txt','rb')
data=file.read()
print (list(data))
這種將物件手動轉換為字串或位元組格式(反之亦然)的過程非常繁瑣且乏味。可以將 Python 物件的狀態以位元組流的形式直接儲存到檔案或記憶體流中,並檢索回其原始狀態。此過程稱為序列化和反序列化。
Python 的內建庫包含各種用於序列化和反序列化過程的模組。
| 序號 | 名稱和描述 |
|---|---|
| 1 |
pickle Python 特定的序列化庫 |
| 2 |
marshal 內部用於序列化的庫 |
| 3 |
shelve Pythonic 物件持久化 |
| 4 |
dbm 提供與 Unix 資料庫介面的庫 |
| 5 |
csv 用於將 Python 資料儲存和檢索到 CSV 格式的庫 |
| 6 |
json 用於序列化到通用 JSON 格式的庫 |
Python 資料持久化 - Pickle 模組
Python 將序列化和反序列化分別稱為 pickling 和 unpickling。Python 庫中的 pickle 模組使用非常 Python 特定的資料格式。因此,非 Python 應用程式可能無法正確地反序列化 pickled 資料。建議不要從未經身份驗證的來源反序列化資料。
序列化(pickled)的資料可以儲存在位元組字串或二進位制檔案中。此模組定義了 dumps() 和 loads() 函式,分別用於使用位元組字串對資料進行 pickling 和 unpickling。對於基於檔案的處理,該模組具有 dump() 和 load() 函式。
Python 的 pickle 協議是在將 Python 物件構造和解構為/從二進位制資料中使用的約定。目前,pickle 模組定義了 5 種不同的協議,如下所示:
| 序號 | 名稱和描述 |
|---|---|
| 1 |
協議版本 0 原始的“人類可讀”協議,與早期版本向後相容。 |
| 2 |
協議版本 1 舊的二進位制格式,也與早期版本的 Python 相容。 |
| 3 |
協議版本 2 在 Python 2.3 中引入,提供了對新式類的有效 pickling。 |
| 4 |
協議版本 3 在 Python 3.0 中新增。當需要與其他 Python 3 版本相容時推薦使用。 |
| 5 |
協議版本 4 在 Python 3.4 中新增。它增加了對非常大的物件的支援。 |
示例
pickle 模組包含 dumps() 函式,該函式返回 pickled 資料的字串表示形式。
from pickle import dump
dct={"name":"Ravi", "age":23, "Gender":"M","marks":75}
dctstring=dumps(dct)
print (dctstring)
輸出
b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x04\x00\x00\x00Raviq\x02X\x03\x00\x00\x00ageq\x03K\x17X\x06\x00\x00\x00Genderq\x04X\x01\x00\x00\x00Mq\x05X\x05\x00\x00\x00marksq\x06KKu.
示例
使用 loads() 函式,對字串進行 unpickling 並獲取原始字典物件。
from pickle import load dct=loads(dctstring) print (dct)
輸出
{'name': 'Ravi', 'age': 23, 'Gender': 'M', 'marks': 75}
pickled 物件也可以使用 dump() 函式持久儲存在磁碟檔案中,並使用 load() 函式檢索。
import pickle
f=open("data.txt","wb")
dct={"name":"Ravi", "age":23, "Gender":"M","marks":75}
pickle.dump(dct,f)
f.close()
#to read
import pickle
f=open("data.txt","rb")
d=pickle.load(f)
print (d)
f.close()
pickle 模組還提供面向物件的 API,用於以 Pickler 和 Unpickler 類形式實現序列化機制。
如上所述,與 Python 中的內建物件一樣,使用者定義類的物件也可以持久序列化到磁碟檔案中。在下面的程式中,我們定義了一個 User 類,其名稱和手機號碼作為其例項屬性。除了 __init__() 建構函式之外,該類還覆蓋了 __str__() 方法,該方法返回其物件的字串表示形式。
class User:
def __init__(self,name, mob):
self.name=name
self.mobile=mob
def __str__(self):
return ('Name: {} mobile: {} '. format(self.name, self.mobile))
要將上述類的物件 pickle 到檔案中,我們使用 pickler 類及其 dump() 方法。
from pickle import Pickler
user1=User('Rajani', 'raj@gmail.com', '1234567890')
file=open('userdata','wb')
Pickler(file).dump(user1)
Pickler(file).dump(user2)
file.close()
相反,Unpickler 類具有 load() 方法,用於檢索序列化的物件,如下所示:
from pickle import Unpickler
file=open('usersdata','rb')
user1=Unpickler(file).load()
print (user1)
Python 資料持久化 - Marshal 模組
Python 標準庫中 marshal 模組的物件序列化功能類似於 pickle 模組。但是,此模組不用於通用資料。另一方面,它被 Python 本身用於 Python 的內部物件序列化,以支援對 Python 模組的編譯版本(.pyc 檔案)執行讀/寫操作。
marshal 模組使用的資料格式在 Python 版本之間不相容。因此,一個版本的編譯 Python 指令碼(.pyc 檔案)很可能無法在另一個版本上執行。
與 pickle 模組一樣,marshal 模組也定義了 load() 和 dump() 函式,用於從檔案讀取和寫入 marshalled 物件。
dump()
此函式將支援的 Python 物件的位元組表示形式寫入檔案。該檔案本身必須是具有寫許可權的二進位制檔案。
load()
此函式從二進位制檔案讀取位元組資料並將其轉換為 Python 物件。
以下示例演示瞭如何使用 dump() 和 load() 函式處理 Python 的程式碼物件,這些物件用於儲存預編譯的 Python 模組。
該程式碼使用內建的 compile() 函式從包含 Python 指令的源字串構建程式碼物件。
compile(source, file, mode)
file 引數應為從中讀取程式碼的檔案。如果它不是從檔案讀取的,則傳遞任何任意字串。
如果源包含語句序列,則 mode 引數為 'exec';如果存在單個表示式,則為 'eval';如果它包含單個互動式語句,則為 'single'。
然後使用 dump() 函式將編譯後的程式碼物件儲存在 .pyc 檔案中。
import marshal
script = """
a=10
b=20
print ('addition=',a+b)
"""
code = compile(script, "script", "exec")
f=open("a.pyc","wb")
marshal.dump(code, f)
f.close()
要從 .pyc 檔案反序列化物件,請使用 load() 函式。由於它返回一個程式碼物件,因此可以使用 exec()(另一個內建函式)執行它。
import marshal
f=open("a.pyc","rb")
data=marshal.load(f)
exec (data)
Python 資料持久化 - Shelve 模組
Python 標準庫中的 shelve 模組提供了一個簡單但有效的物件持久化機制。此模組中定義的 shelf 物件是類似字典的物件,持久儲存在磁碟檔案中。這會建立一個類似於類 Unix 系統上 dbm 資料庫的檔案。
shelf 字典有一些限制。此特殊字典物件只能使用字串資料型別作為鍵,而任何可 pickling 的 Python 物件都可以用作值。
shelve 模組定義了以下三個類:
| 序號 | Shelve 模組和描述 |
|---|---|
| 1 |
Shelf 這是 shelf 實現的基類。它使用類似字典的物件進行初始化。 |
| 2 |
BsdDbShelf 這是 Shelf 類的子類。傳遞給其建構函式的 dict 物件必須支援 first()、next()、previous()、last() 和 set_location() 方法。 |
| 3 |
DbfilenameShelf 這也是 Shelf 的子類,但它接受檔名作為其建構函式的引數,而不是 dict 物件。 |
shelve 模組中定義的 open() 函式返回 DbfilenameShelf 物件。
open(filename, flag='c', protocol=None, writeback=False)
filename 引數分配給建立的資料庫。flag 引數的預設值為 'c',用於讀/寫訪問。其他標誌為 'w'(只寫)、'r'(只讀)和 'n'(新的讀/寫)。
序列化本身受 pickle 協議控制,預設為 none。最後一個引數 writeback 引數預設為 false。如果設定為 true,則快取訪問的條目。每次訪問都會呼叫 sync() 和 close() 操作,因此程序可能會變慢。
以下程式碼建立了一個數據庫並在其中儲存字典條目。
import shelve
s=shelve.open("test")
s['name']="Ajay"
s['age']=23
s['marks']=75
s.close()
這將在當前目錄中建立 test.dir 檔案,並將鍵值資料以雜湊形式儲存。Shelf 物件具有以下可用方法:
| 序號 | 方法和描述 |
|---|---|
| 1 |
close() 同步並關閉持久化字典物件。 |
| 2 |
sync() 如果 shelf 以 writeback 設定為 True 開啟,則寫回快取中的所有條目。 |
| 3 |
get() 返回與鍵關聯的值 |
| 4 |
items() 元組列表 - 每個元組都是鍵值對 |
| 5 |
keys() shelf 鍵列表 |
| 6 |
pop() 刪除指定的鍵並返回相應的值。 |
| 7 |
update() 從另一個 dict/iterable 更新 shelf |
| 8 |
values() shelf 值列表 |
要訪問 shelf 中特定鍵的值,請執行以下操作:
s=shelve.open('test')
print (s['age']) #this will print 23
s['age']=25
print (s.get('age')) #this will print 25
s.pop('marks') #this will remove corresponding k-v pair
與內建字典物件一樣,items()、keys() 和 values() 方法返回檢視物件。
print (list(s.items()))
[('name', 'Ajay'), ('age', 25), ('marks', 75)]
print (list(s.keys()))
['name', 'age', 'marks']
print (list(s.values()))
['Ajay', 25, 75]
要將另一個字典的專案與 shelf 合併,請使用 update() 方法。
d={'salary':10000, 'designation':'manager'}
s.update(d)
print (list(s.items()))
[('name', 'Ajay'), ('age', 25), ('salary', 10000), ('designation', 'manager')]
Python 資料持久化 - dbm 包
dbm 包提供了一個類似字典的介面,用於 DBM 樣式資料庫。DBM 代表 DataBase Manager。它由 UNIX(和類 Unix)作業系統使用。dbbm 庫是由 Ken Thompson 編寫的簡單資料庫引擎。這些資料庫使用二進位制編碼的字串物件作為鍵以及值。
資料庫透過使用單個鍵(主鍵)在固定大小的桶中儲存資料,並使用雜湊技術透過鍵快速檢索資料。
dbm 包包含以下模組:
dbm.gnu 模組是 GNU 專案實現的 DBM 庫版本的介面。
dbm.ndbm 模組提供與 UNIX nbdm 實現的介面。
dbm.dumb 用作後備選項,以防找不到其他 dbm 實現。這不需要外部依賴項,但速度比其他選項慢。
>>> dbm.whichdb('mydbm.db')
'dbm.dumb'
>>> import dbm
>>> db=dbm.open('mydbm.db','n')
>>> db['name']=Raj Deshmane'
>>> db['address']='Kirtinagar Pune'
>>> db['PIN']='431101'
>>> db.close()
open() 函式允許使用以下標誌:
| 序號 | 值和含義 |
|---|---|
| 1 |
'r' 以只讀方式開啟現有資料庫(預設值) |
| 2 | 'w' 以讀寫方式開啟現有資料庫 |
| 3 | 'c' 以讀寫方式開啟資料庫,如果它不存在則建立它 |
| 4 | 'n' 始終建立一個新的空資料庫,以讀寫方式開啟 |
dbm 物件是一個類似字典的物件,就像 shelf 物件一樣。因此,可以執行所有字典操作。dbm 物件可以呼叫 get()、pop()、append() 和 update() 方法。以下程式碼使用 'r' 標誌開啟 'mydbm.db' 並迭代鍵值對的集合。
>>> db=dbm.open('mydbm.db','r')
>>> for k,v in db.items():
print (k,v)
b'name' : b'Raj Deshmane'
b'address' : b'Kirtinagar Pune'
b'PIN' : b'431101'
Python 資料持久化 - CSV 模組
CSV 代表逗號分隔值。此檔案格式是在將資料匯出/匯入到/從電子表格和資料庫中的資料表時常用的資料格式。csv 模組已整合到 Python 的標準庫中,這是 PEP 305 的結果。它提供了類和方法,根據 PEP 305 的建議對 CSV 檔案執行讀/寫操作。
CSV 是 Microsoft Excel 電子表格軟體的首選匯出資料格式。但是,csv 模組也可以處理其他方言表示的資料。
CSV API 介面包含以下寫入器和讀取器類:
writer()
csv 模組中的此函式返回一個寫入器物件,該物件將資料轉換為分隔的字串並存儲在檔案物件中。該函式需要一個具有寫許可權的檔案物件作為引數。寫入檔案中的每一行都會發出換行符。為了防止行之間出現額外的空格,newline 引數設定為 ''。
Writer 類包含以下方法:
writerow()
此方法將可迭代物件(列表、元組或字串)中的專案寫入檔案,並使用逗號字元分隔它們。
writerows()
此方法將可迭代物件的列表作為引數,並將每個專案作為檔案中的逗號分隔行寫入。
示例
以下示例演示了 writer() 函式的使用。首先,以“w”模式開啟一個檔案。此檔案用於獲取 writer 物件。然後使用 writerow() 方法將元組列表中的每個元組寫入檔案。
import csv
persons=[('Lata',22,45),('Anil',21,56),('John',20,60)]
csvfile=open('persons.csv','w', newline='')
obj=csv.writer(csvfile)
for person in persons:
obj.writerow(person)
csvfile.close()
輸出
這將在當前目錄中建立“persons.csv”檔案。它將顯示以下資料。
Lata,22,45 Anil,21,56 John,20,60
無需遍歷列表逐行寫入,我們可以使用 writerows() 方法。
csvfile=open('persons.csv','w', newline='')
persons=[('Lata',22,45),('Anil',21,56),('John',20,60)]
obj=csv.writer(csvfile)
obj.writerows(persons)
obj.close()
reader()
此函式返回一個 reader 物件,該物件返回 **csv 檔案**中各行的迭代器。使用常規的 for 迴圈,以下示例顯示了檔案中的所有行:
示例
csvfile=open('persons.csv','r', newline='')
obj=csv.reader(csvfile)
for row in obj:
print (row)
輸出
['Lata', '22', '45'] ['Anil', '21', '56'] ['John', '20', '60']
reader 物件是一個迭代器。因此,它支援 next() 函式,該函式也可用於顯示 csv 檔案中的所有行,而不是使用 **for 迴圈**。
csvfile=open('persons.csv','r', newline='')
obj=csv.reader(csvfile)
while True:
try:
row=next(obj)
print (row)
except StopIteration:
break
如前所述,csv 模組使用 Excel 作為其預設方言。csv 模組還定義了一個方言類。方言是一組用於實現 CSV 協議的標準。可以使用 list_dialects() 函式獲取可用的方言列表。
>>> csv.list_dialects() ['excel', 'excel-tab', 'unix']
除了可迭代物件之外,csv 模組還可以將字典物件匯出到 CSV 檔案並讀取它以填充 Python 字典物件。為此,此模組定義了以下類:
DictWriter()
此函式返回一個 DictWriter 物件。它類似於 writer 物件,但行對映到字典物件。該函式需要具有寫許可權的檔案物件以及字典中使用的鍵列表作為 fieldnames 引數。這用於將檔案中的第一行作為標題寫入。
writeheader()
此方法將字典中的鍵列表作為逗號分隔行寫入檔案的第一行。
在以下示例中,定義了一個字典項列表。列表中的每個專案都是一個字典。使用 writrows() 方法,它們以逗號分隔的方式寫入檔案。
persons=[
{'name':'Lata', 'age':22, 'marks':45},
{'name':'Anil', 'age':21, 'marks':56},
{'name':'John', 'age':20, 'marks':60}
]
csvfile=open('persons.csv','w', newline='')
fields=list(persons[0].keys())
obj=csv.DictWriter(csvfile, fieldnames=fields)
obj.writeheader()
obj.writerows(persons)
csvfile.close()
persons.csv 檔案顯示以下內容:
name,age,marks Lata,22,45 Anil,21,56 John,20,60
DictReader()
此函式從底層 CSV 檔案返回一個 DictReader 物件。與 reader 物件一樣,它也是一個迭代器,可以使用它來檢索檔案的內容。
csvfile=open('persons.csv','r', newline='')
obj=csv.DictReader(csvfile)
該類提供 fieldnames 屬性,返回用作檔案標題的字典鍵。
print (obj.fieldnames) ['name', 'age', 'marks']
使用迴圈遍歷 DictReader 物件以獲取各個字典物件。
for row in obj: print (row)
這將產生以下輸出:
OrderedDict([('name', 'Lata'), ('age', '22'), ('marks', '45')])
OrderedDict([('name', 'Anil'), ('age', '21'), ('marks', '56')])
OrderedDict([('name', 'John'), ('age', '20'), ('marks', '60')])
要將 OrderedDict 物件轉換為普通字典,我們必須首先從 collections 模組匯入 OrderedDict。
from collections import OrderedDict
r=OrderedDict([('name', 'Lata'), ('age', '22'), ('marks', '45')])
dict(r)
{'name': 'Lata', 'age': '22', 'marks': '45'}
Python 資料持久化 - JSON 模組
JSON 代表 **JavaScript 物件表示法**。它是一種輕量級的資料交換格式。它是一種與語言無關且跨平臺的文字格式,許多程式語言都支援它。此格式用於 Web 伺服器和客戶端之間的資料交換。
JSON 格式類似於 pickle。但是,pickle 序列化是特定於 Python 的,而 JSON 格式由許多語言實現,因此已成為通用標準。Python 標準庫中 json 模組的功能和介面類似於 pickle 和 marshal 模組。
就像 pickle 模組一樣,json 模組也提供了 **dumps()** 和 **loads()** 函式,用於將 Python 物件序列化為 JSON 編碼字串,以及 **dump()** 和 **load()** 函式,用於將序列化後的 Python 物件寫入/讀取到檔案。
**dumps()** - 此函式將物件轉換為 JSON 格式。
**loads()** - 此函式將 JSON 字串轉換回 Python 物件。
以下示例演示了這些函式的基本用法:
import json
data=['Rakesh',{'marks':(50,60,70)}]
s=json.dumps(data)
json.loads(s)
dumps() 函式可以接受可選的 sort_keys 引數。預設情況下,它為 False。如果設定為 True,則字典鍵將按排序順序出現在 JSON 字串中。
dumps() 函式還有另一個可選引數稱為 indent,它接受一個數字作為值。它決定 json 字串格式化表示的每個段的長度,類似於列印輸出。
json 模組還具有與上述函式相對應的面向物件的 API。模組中定義了兩個類 - JSONEncoder 和 JSONDecoder。
JSONEncoder 類
此類的物件是 Python 資料結構的編碼器。每個 Python 資料型別都轉換為相應的 JSON 型別,如下表所示:
| Python | JSON |
|---|---|
| Dict | 物件 |
| 列表,元組 | 陣列 |
| Str | 字串 |
| int,float,int- 和 float-派生的列舉 | 數字 |
| True | true |
| False | false |
| None | null |
JSONEncoder 類由 JSONEncoder() 建構函式例項化。編碼器類中定義了以下重要方法:
| 序號 | 方法和描述 |
|---|---|
| 1 |
encode() 將 Python 物件序列化為 JSON 格式 |
| 2 |
iterencode() 對物件進行編碼並返回一個迭代器,該迭代器生成物件中每個專案的編碼形式。 |
| 3 |
縮排 確定編碼字串的縮排級別 |
| 4 |
sort_keys 為 true 或 false,使鍵按排序順序顯示或不顯示。 |
| 5 |
Check_circular 如果為 True,則檢查容器型別物件中的迴圈引用 |
以下示例對 Python 列表物件進行編碼。
e=json.JSONEncoder() e.encode(data)
JSONDecoder 類
此類的物件有助於將 json 字串解碼回 Python 資料結構。此類中的主要方法是 decode()。以下示例程式碼從先前步驟中編碼的字串中檢索 Python 列表物件。
d=json.JSONDecoder() d.decode(s)
json 模組定義了 **load()** 和 **dump()** 函式,用於將 JSON 資料寫入檔案類物件(可能是磁碟檔案或位元組流)並從中讀取資料。
dump()
此函式將 JSON 化的 Python 物件資料寫入檔案。檔案必須以“w”模式開啟。
import json
data=['Rakesh', {'marks': (50, 60, 70)}]
fp=open('json.txt','w')
json.dump(data,fp)
fp.close()
此程式碼將在當前目錄中建立“json.txt”。它顯示以下內容:
["Rakesh", {"marks": [50, 60, 70]}]
load()
此函式從檔案中載入 JSON 資料並從中返回 Python 物件。檔案必須以讀取許可權開啟(應具有“r”模式)。
示例
fp=open('json.txt','r')
ret=json.load(fp)
print (ret)
fp.close()
輸出
['Rakesh', {'marks': [50, 60, 70]}]
**json.tool** 模組還具有命令列介面,該介面驗證檔案中的資料並以漂亮格式化的方式列印 JSON 物件。
C:\python37>python -m json.tool json.txt
[
"Rakesh",
{
"marks": [
50,
60,
70
]
}
]
Python 資料持久化 - XML 解析器
XML 是 **可擴充套件標記語言**的首字母縮寫詞。它是一種可移植的、開源的和跨平臺的語言,非常類似於 HTML 或 SGML,並且由全球資訊網聯盟推薦。
它是一種眾所周知的的資料交換格式,被大量應用程式使用,例如 Web 服務、辦公工具和 **面向服務的體系結構** (SOA)。XML 格式既可由機器讀取也可由人類讀取。
標準 Python 庫的 xml 包包含以下用於 XML 處理的模組:
| 序號 | 模組和說明 |
|---|---|
| 1 |
xml.etree.ElementTree ElementTree API,一個簡單輕量級的 XML 處理器 |
| 2 |
xml.dom DOM API 定義 |
| 3 |
xml.dom.minidom 一個最小的 DOM 實現 |
| 4 |
xml.sax SAX2 介面實現 |
| 5 |
xml.parsers.expat Expat 解析器繫結 |
XML 文件中的資料以樹狀分層格式排列,從根和元素開始。每個元素都是樹中的單個節點,並且具有包含在 <> 和 </> 標記中的屬性。可以為每個元素分配一個或多個子元素。
以下是一個典型的 XML 文件示例:
<?xml version = "1.0" encoding = "iso-8859-1"?>
<studentlist>
<student>
<name>Ratna</name>
<subject>Physics</subject>
<marks>85</marks>
</student>
<student>
<name>Kiran</name>
<subject>Maths</subject>
<marks>100</marks>
</student>
<student>
<name>Mohit</name>
<subject>Biology</subject>
<marks>92</marks>
</student>
</studentlist>
在使用 **ElementTree** 模組時,第一步是設定樹的根元素。每個元素都有一個標籤和 attrib,它是一個 dict 物件。對於根元素,attrib 是一個空字典。
import xml.etree.ElementTree as xmlobj
root=xmlobj.Element('studentList')
現在,我們可以在根元素下新增一個或多個元素。每個元素物件可能具有 **子元素**。每個子元素都有一個屬性和文字屬性。
student=xmlobj.Element('student')
nm=xmlobj.SubElement(student, 'name')
nm.text='name'
subject=xmlobj.SubElement(student, 'subject')
nm.text='Ratna'
subject.text='Physics'
marks=xmlobj.SubElement(student, 'marks')
marks.text='85'
使用 append() 方法將此新元素追加到根元素。
root.append(student)
使用上述方法追加任意數量的元素。最後,將根元素物件寫入檔案。
tree = xmlobj.ElementTree(root)
file = open('studentlist.xml','wb')
tree.write(file)
file.close()
現在,我們看看如何解析 XML 檔案。為此,在 ElementTree 建構函式中使用檔名作為檔案引數構造文件樹。
tree = xmlobj.ElementTree(file='studentlist.xml')
tree 物件具有 **getroot()** 方法以獲取根元素,而 getchildren() 返回其下方的元素列表。
root = tree.getroot() children = root.getchildren()
透過迭代每個子節點的子元素集合,構造與每個子元素對應的字典物件。
for child in children:
student={}
pairs = child.getchildren()
for pair in pairs:
product[pair.tag]=pair.text
然後將每個字典追加到列表中,返回原始的字典物件列表。
**SAX** 是用於事件驅動的 XML 解析的標準介面。使用 SAX 解析 XML 需要透過子類化 xml.sax.ContentHandler 來建立 ContentHandler。您為感興趣的事件註冊回撥,然後讓解析器遍歷文件。
當您的文件很大或記憶體有限時,SAX 很有用,因為它在從磁碟讀取檔案時對其進行解析,因此整個檔案永遠不會儲存在記憶體中。
文件物件模型
(DOM) API 是全球資訊網聯盟的建議。在這種情況下,整個檔案將讀取到記憶體中並以分層(基於樹)的形式儲存,以表示 XML 文件的所有功能。
對於大型檔案,SAX 的速度不如 DOM。另一方面,如果在許多小檔案上使用 DOM,它可能會佔用大量資源。SAX 是隻讀的,而 DOM 允許更改 XML 檔案。
Python 資料持久化 - Plistlib 模組
plist 格式主要由 MAC OS X 使用。這些檔案基本上是 XML 文件。它們儲存和檢索物件的屬性。Python 庫包含 plist 模組,用於讀取和寫入“屬性列表”檔案(它們通常具有“.plist”副檔名)。
**plistlib** 模組或多或少類似於其他序列化庫,因為它也提供 dumps() 和 loads() 函式用於 Python 物件的字串表示,以及 load() 和 dump() 函式用於磁碟操作。
以下字典物件維護屬性(鍵)和相應的 value:
proplist = {
"name" : "Ganesh",
"designation":"manager",
"dept":"accts",
"salary" : {"basic":12000, "da":4000, "hra":800}
}
為了將這些屬性寫入磁碟檔案,我們在 plist 模組中呼叫 dump() 函式。
import plistlib
fileName=open('salary.plist','wb')
plistlib.dump(proplist, fileName)
fileName.close()
相反,要讀回屬性值,請按如下方式使用 load() 函式:
fp= open('salary.plist', 'rb')
pl = plistlib.load(fp)
print(pl)
Python 資料持久化 - Sqlite3 模組
CSV、JSON、XML 等檔案的最大缺點之一是它們對於隨機訪問和事務處理不是很有用,因為它們本質上很大程度上是非結構化的。因此,修改內容變得非常困難。
這些平面檔案不適用於客戶端-伺服器環境,因為它們缺乏非同步處理能力。使用非結構化資料檔案會導致資料冗餘和不一致。
這些問題可以透過使用關係資料庫來克服。資料庫是組織好的資料集合,用於消除冗餘和不一致性,並維護資料完整性。關係資料庫模型非常流行。
其基本概念是將資料排列在實體表(稱為關係)中。實體表結構提供一個屬性,該屬性的值對於每一行都是唯一的。這樣的屬性稱為 **“主鍵”**。
當一個表的 primary key 出現在其他表的結構中時,它被稱為 **“外部索引鍵”**,這構成了這兩個表之間關係的基礎。基於此模型,目前有許多流行的 RDBMS 產品可用:
- GadFly
- mSQL
- MySQL
- PostgreSQL
- Microsoft SQL Server 2000
- Informix
- Interbase
- Oracle
- Sybase
- SQLite
SQLite 是一種輕量級關係資料庫,廣泛應用於各種應用程式。它是一個自包含的、無伺服器的、零配置的、事務性 SQL 資料庫引擎。整個資料庫是一個單一檔案,可以放置在檔案系統中的任何位置。它是一個開源軟體,佔用空間非常小,並且零配置。它在嵌入式裝置、物聯網和移動應用中很受歡迎。
所有關係型資料庫都使用 SQL 來處理表中的資料。然而,早些時候,這些資料庫中的每一個都透過特定於資料庫型別的 Python 模組與 Python 應用程式連線。
因此,它們之間缺乏相容性。如果使用者想要更改到不同的資料庫產品,將會非常困難。透過提出“Python 增強提案 (PEP 248)”來解決此相容性問題,該提案建議使用一致的介面連線關係型資料庫,稱為 DB-API。最新的建議稱為DB-API 2.0 版。(PEP 249)
Python 的標準庫包含 sqlite3 模組,這是一個符合 DB-API 的模組,用於透過 Python 程式處理 SQLite 資料庫。本章解釋了 Python 與 SQLite 資料庫的連線。
如前所述,Python 以 sqlite3 模組的形式內建支援 SQLite 資料庫。對於其他資料庫,需要使用 pip 工具安裝相應的符合 DB-API 的 Python 模組。例如,要使用 MySQL 資料庫,我們需要安裝 PyMySQL 模組。
pip install pymysql
DB-API 建議以下步驟:
使用connect() 函式建立與資料庫的連線並獲取連線物件。
呼叫連線物件的cursor() 方法獲取遊標物件。
形成一個由要執行的 SQL 語句組成的查詢字串。
透過呼叫execute() 方法執行所需的查詢。
關閉連線。
import sqlite3
db=sqlite3.connect('test.db')
這裡,db 是代表 test.db 的連線物件。請注意,如果資料庫不存在,則會建立它。連線物件 db 具有以下方法:
| 序號 | 方法和描述 |
|---|---|
| 1 |
cursor() 返回一個使用此連線的遊標物件。 |
| 2 |
commit() 顯式地將任何掛起的交易提交到資料庫。 |
| 3 |
rollback() 此可選方法會導致事務回滾到起始點。 |
| 4 |
close() 永久關閉與資料庫的連線。 |
遊標充當給定 SQL 查詢的控制代碼,允許檢索結果的一行或多行。從連線中獲取遊標物件以使用以下語句執行 SQL 查詢:
cur=db.cursor()
遊標物件定義了以下方法:
| 序號 | 方法和描述 |
|---|---|
| 1 |
execute() 執行字串引數中的 SQL 查詢。 |
| 2 |
executemany() 使用元組列表中的一組引數執行 SQL 查詢。 |
| 3 |
fetchone() 從查詢結果集中獲取下一行。 |
| 4 |
fetchall() 從查詢結果集中獲取所有剩餘的行。 |
| 5 |
callproc() 呼叫儲存過程。 |
| 6 |
close() 關閉遊標物件。 |
以下程式碼在 test.db 中建立了一個表:
import sqlite3
db=sqlite3.connect('test.db')
cur =db.cursor()
cur.execute('''CREATE TABLE student (
StudentID INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT (20) NOT NULL,
age INTEGER,
marks REAL);''')
print ('table created successfully')
db.close()
資料庫中所需的完整性資料是透過連線物件的commit() 和rollback() 方法實現的。SQL 查詢字串可能包含不正確的 SQL 查詢,這可能會引發異常,應正確處理。為此,execute() 語句放置在 try 塊中,如果成功,則使用 commit() 方法持久儲存結果。如果查詢失敗,則使用 rollback() 方法撤消事務。
以下程式碼在 test.db 中的 student 表上執行 INSERT 查詢。
import sqlite3
db=sqlite3.connect('test.db')
qry="insert into student (name, age, marks) values('Abbas', 20, 80);"
try:
cur=db.cursor()
cur.execute(qry)
db.commit()
print ("record added successfully")
except:
print ("error in query")
db.rollback()
db.close()
如果希望 INSERT 查詢的 values 子句中的資料由使用者輸入動態提供,請按照 Python DB-API 中的建議使用引數替換。? 字元用作查詢字串中的佔位符,並以元組的形式在 execute() 方法中提供值。以下示例使用引數替換方法插入記錄。姓名、年齡和分數作為輸入。
import sqlite3
db=sqlite3.connect('test.db')
nm=input('enter name')
a=int(input('enter age'))
m=int(input('enter marks'))
qry="insert into student (name, age, marks) values(?,?,?);"
try:
cur=db.cursor()
cur.execute(qry, (nm,a,m))
db.commit()
print ("one record added successfully")
except:
print("error in operation")
db.rollback()
db.close()
sqlite3 模組定義了executemany() 方法,該方法能夠一次新增多條記錄。要新增的資料應以元組列表的形式給出,每個元組包含一條記錄。列表物件是 executemany() 方法的引數,以及查詢字串。但是,一些其他模組不支援 executemany() 方法。
UPDATE 查詢通常包含由 WHERE 子句指定的邏輯表示式。execute() 方法中的查詢字串應包含 UPDATE 查詢語法。要將 name='Anil' 的 'age' 值更新為 23,請將字串定義如下
qry="update student set age=23 where name='Anil';"
為了使更新過程更加動態,我們使用上面描述的引數替換方法。
import sqlite3
db=sqlite3.connect('test.db')
nm=input(‘enter name’)
a=int(input(‘enter age’))
qry="update student set age=? where name=?;"
try:
cur=db.cursor()
cur.execute(qry, (a, nm))
db.commit()
print("record updated successfully")
except:
print("error in query")
db.rollback()
db.close()
類似地,DELETE 操作是透過使用包含 SQL DELETE 查詢語法的字串呼叫 execute() 方法來執行的。順便說一句,DELETE 查詢通常也包含WHERE 子句。
import sqlite3
db=sqlite3.connect('test.db')
nm=input(‘enter name’)
qry="DELETE from student where name=?;"
try:
cur=db.cursor()
cur.execute(qry, (nm,))
db.commit()
print("record deleted successfully")
except:
print("error in operation")
db.rollback()
db.close()
資料庫表上的重要操作之一是從表中檢索記錄。SQL 提供SELECT 查詢用於此目的。當包含 SELECT 查詢語法的字串傳遞給 execute() 方法時,會返回一個結果集物件。遊標物件有兩個重要方法,可以使用它們從結果集中檢索一條或多條記錄。
fetchone()
從結果集中獲取下一條可用記錄。它是一個元組,包含獲取的記錄的每一列的值。
fetchall()
以元組列表的形式獲取所有剩餘的記錄。每個元組對應一條記錄,幷包含表中每一列的值。
以下示例列出了 student 表中的所有記錄
import sqlite3
db=sqlite3.connect('test.db')
37
sql="SELECT * from student;"
cur=db.cursor()
cur.execute(sql)
while True:
record=cur.fetchone()
if record==None:
break
print (record)
db.close()
如果您計劃使用 MySQL 資料庫而不是 SQLite 資料庫,則需要如上所述安裝PyMySQL 模組。由於 MySQL 資料庫安裝在伺服器上,因此連線過程中的所有步驟都相同,connect() 函式需要 URL 和登入憑據。
import pymysql
con=pymysql.connect('localhost', 'root', '***')
唯一可能與 SQLite 不同的方面是 MySQL 特定的資料型別。類似地,任何與 ODBC 相容的資料庫都可以透過安裝 pyodbc 模組與 Python 一起使用。
Python 資料持久化 - SQLAlchemy
任何關係型資料庫都將資料儲存在表中。表結構定義屬性的資料型別,這些屬性基本上只是基本資料型別,這些資料型別對映到 Python 的相應內建資料型別。但是,Python 的使用者定義物件無法持久儲存和檢索到/從 SQL 表中。
這是 SQL 型別和麵向物件程式語言(如 Python)之間的差異。SQL 沒有其他型別(如 dict、tuple、list 或任何使用者定義的類)的等效資料型別。
如果必須將物件儲存在關係型資料庫中,則在執行 INSERT 查詢之前,必須首先將其例項屬性分解為 SQL 資料型別。另一方面,從 SQL 表中檢索到的資料為基本型別。將不得不構造所需型別的 Python 物件以供 Python 指令碼使用。這就是物件關係對映器有用的地方。
物件關係對映器 (ORM)
物件關係對映器 (ORM) 是類和 SQL 表之間的介面。Python 類對映到資料庫中的某個表,以便自動執行物件和 SQL 型別之間的轉換。
用 Python 程式碼編寫的 Students 類對映到資料庫中的 Students 表。因此,所有 CRUD 操作都是透過呼叫類的相應方法來完成的。這消除了在 Python 指令碼中執行硬編碼 SQL 查詢的需要。
因此,ORM 庫充當原始 SQL 查詢的抽象層,有助於快速應用程式開發。SQLAlchemy 是一個流行的 Python 物件關係對映器。模型物件狀態的任何操作都與其在資料庫表中的相關行同步。
SQLALchemy 庫包含ORM API 和 SQL 表示式語言(SQLAlchemy Core)。表示式語言直接執行關係資料庫的基本結構。
ORM 是構建在 SQL 表示式語言之上的高階且抽象的使用模式。可以說 ORM 是表示式語言的應用用法。在本主題中,我們將討論 SQLAlchemy ORM API 並使用 SQLite 資料庫。
SQLAlchemy 透過其各自的 DBAPI 實現使用方言系統與各種型別的資料庫進行通訊。所有方言都需要安裝相應的 DBAPI 驅動程式。包含以下型別資料庫的方言:
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQLite
- Sybase

使用 pip 工具安裝 SQLAlchemy 很容易且簡單。
pip install sqlalchemy
要檢查 SQLalchemy 是否已正確安裝及其版本,請在 Python 提示符下輸入以下內容:
>>> import sqlalchemy >>>sqlalchemy.__version__ '1.3.11'
與資料庫的互動是透過作為create_engine() 函式返回值獲取的 Engine 物件完成的。
engine =create_engine('sqlite:///mydb.sqlite')
SQLite 允許建立記憶體資料庫。記憶體資料庫的 SQLAlchemy 引擎建立如下:
from sqlalchemy import create_engine
engine=create_engine('sqlite:///:memory:')
如果您打算使用 MySQL 資料庫,請使用其 DB-API 模組 – pymysql 和相應的方言驅動程式。
engine = create_engine('mysql+pymydsql://root@localhost/mydb')
create_engine 具有可選的 echo 引數。如果設定為 true,則引擎生成的 SQL 查詢將在終端上回顯。
SQLAlchemy 包含宣告式基類。它充當模型類和對映表的目錄。
from sqlalchemy.ext.declarative import declarative_base base=declarative_base()
下一步是定義模型類。它必須從基類派生——如上所示的 declarative_base 類的物件。
將__tablename__ 屬性設定為要建立的資料庫表的名。其他屬性對應於欄位。每個屬性都是 SQLAlchemy 中的 Column 物件,其資料型別來自以下列表之一:
- BigInteger
- Boolean
- Date
- DateTime
- Float
- Integer
- Numeric
- SmallInteger
- String
- Text
- Time
以下程式碼是名為 Student 的模型類,它對映到 Students 表。
#myclasses.py from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, Numeric base=declarative_base() class Student(base): __tablename__='Students' StudentID=Column(Integer, primary_key=True) name=Column(String) age=Column(Integer) marks=Column(Numeric)
要建立一個具有相應結構的 Students 表,請執行為基類定義的 create_all() 方法。
base.metadata.create_all(engine)
現在我們必須宣告我們 Student 類的物件。所有資料庫事務(例如新增、刪除或從資料庫檢索資料等)都由 Session 物件處理。
from sqlalchemy.orm import sessionmaker Session = sessionmaker(bind=engine) sessionobj = Session()
儲存在 Student 物件中的資料透過會話的 add() 方法在底層表中物理新增。
s1 = Student(name='Juhi', age=25, marks=200) sessionobj.add(s1) sessionobj.commit()
這是在 students 表中新增記錄的完整程式碼。在執行時,相應的 SQL 語句日誌將顯示在控制檯上。
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
from myclasses import Student, base
engine = create_engine('sqlite:///college.db', echo=True)
base.metadata.create_all(engine)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()
s1 = Student(name='Juhi', age=25, marks=200)
sessionobj.add(s1)
sessionobj.commit()
控制檯輸出
CREATE TABLE "Students" (
"StudentID" INTEGER NOT NULL,
name VARCHAR,
age INTEGER,
marks NUMERIC,
PRIMARY KEY ("StudentID")
)
INFO sqlalchemy.engine.base.Engine ()
INFO sqlalchemy.engine.base.Engine COMMIT
INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
INFO sqlalchemy.engine.base.Engine INSERT INTO "Students" (name, age, marks) VALUES (?, ?, ?)
INFO sqlalchemy.engine.base.Engine ('Juhi', 25, 200.0)
INFO sqlalchemy.engine.base.Engine COMMIT
session 物件還提供 add_all() 方法,以便在單個事務中插入多個物件。
sessionobj.add_all([s2,s3,s4,s5]) sessionobj.commit()
現在,記錄已新增到表中,我們希望像 SELECT 查詢一樣從中獲取。session 物件具有 query() 方法來執行此任務。Query 物件由 Student 模型上的 query() 方法返回。
qry=seesionobj.query(Student)
使用此 Query 物件的 get() 方法獲取對應於給定主鍵的物件。
S1=qry.get(1)
在執行此語句時,其在控制檯上回顯的相應 SQL 語句如下:
BEGIN (implicit) SELECT "Students"."StudentID" AS "Students_StudentID", "Students".name AS "Students_name", "Students".age AS "Students_age", "Students".marks AS "Students_marks" FROM "Students" WHERE "Products"."Students" = ? sqlalchemy.engine.base.Engine (1,)
query.all() 方法返回所有物件的列表,可以使用迴圈遍歷這些物件。
from sqlalchemy import Column, Integer, String, Numeric
from sqlalchemy import create_engine
from myclasses import Student,base
engine = create_engine('sqlite:///college.db', echo=True)
base.metadata.create_all(engine)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()
qry=sessionobj.query(Students)
rows=qry.all()
for row in rows:
print (row)
更新對映表中的記錄非常容易。您需要做的就是使用 get() 方法獲取記錄,為所需的屬性分配新值,然後使用 session 物件提交更改。下面我們將 Juhi 學生的分數更改為 100。
S1=qry.get(1) S1.marks=100 sessionobj.commit()
刪除記錄也同樣容易,方法是從會話中刪除所需的物件。
S1=qry.get(1) Sessionobj.delete(S1) sessionobj.commit()
Python 資料持久化 - PyMongo 模組
MongoDB 是面向文件的NoSQL 資料庫。它是一個跨平臺資料庫,在伺服器端公共許可證下分發。它使用類似 JSON 的文件作為模式。
為了提供儲存海量資料的能力,多個物理伺服器(稱為分片)相互連線,從而實現水平可擴充套件性。MongoDB 資料庫由文件組成。
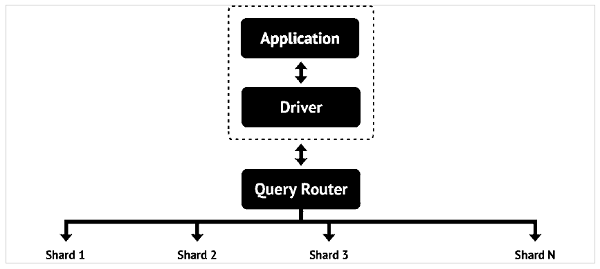
文件類似於關係型資料庫表中的一行。但是,它沒有特定的模式。文件是鍵值對的集合——類似於字典。但是,每個文件中鍵值對的數量可能不同。就像關係型資料庫中的表具有主鍵一樣,MongoDB 資料庫中的文件具有一個名為"_id" 的特殊鍵。
在瞭解如何將MongoDB資料庫與Python一起使用之前,讓我們簡要了解如何安裝和啟動MongoDB。MongoDB有社群版和商業版兩種版本。社群版可以從www.mongodb.com/download-center/community下載。
假設MongoDB安裝在c:\mongodb目錄下,可以使用以下命令啟動伺服器。
c:\mongodb\bin>mongod
預設情況下,MongoDB伺服器在22017埠上執行。資料庫預設儲存在data/bin資料夾中,但可以透過–dbpath選項更改位置。
MongoDB有一套自己的命令,可以在MongoDB shell中使用。要啟動shell,請使用Mongo命令。
x:\mongodb\bin>mongo
一個類似於MySQL或SQLite shell提示符的shell提示符將出現,在該提示符前可以執行本機NoSQL命令。但是,我們感興趣的是將MongoDB資料庫連線到Python。
PyMongo模組由MongoDB Inc本身開發,用於提供Python程式設計介面。使用眾所周知的pip工具安裝PyMongo。
pip3 install pymongo
假設MongoDB伺服器已啟動並正在執行(使用mongod命令)並在22017埠監聽,我們首先需要宣告一個MongoClient物件。它控制Python會話和資料庫之間所有事務。
from pymongo import MongoClient client=MongoClient()
使用此客戶端物件建立與MongoDB伺服器的連線。
client = MongoClient('localhost', 27017)
使用以下命令建立一個新的資料庫。
db=client.newdb
MongoDB資料庫可以有多個集合,類似於關係資料庫中的表。集合物件由Create_collection()函式建立。
db.create_collection('students')
現在,我們可以按如下方式在集合中新增一個或多個文件。
from pymongo import MongoClient
client=MongoClient()
db=client.newdb
db.create_collection("students")
student=db['students']
studentlist=[{'studentID':1,'Name':'Juhi','age':20, 'marks'=100},
{'studentID':2,'Name':'dilip','age':20, 'marks'=110},
{'studentID':3,'Name':'jeevan','age':24, 'marks'=145}]
student.insert_many(studentlist)
client.close()
要檢索文件(類似於SELECT查詢),我們應該使用find()方法。它返回一個遊標,藉助該遊標可以獲取所有文件。
students=db['students'] docs=students.find() for doc in docs: print (doc['Name'], doc['age'], doc['marks'] )
要查詢集合中特定文件而不是所有文件,我們需要對find()方法應用過濾器。過濾器使用邏輯運算子。MongoDB有自己的一套邏輯運算子,如下所示:
| 序號 | MongoDB運算子 & 傳統邏輯運算子 |
|---|---|
| 1 |
$eq 等於 (==) |
| 2 |
$gt 大於 (>) |
| 3 |
$gte 大於或等於 (>=) |
| 4 |
$in 如果等於陣列中的任何值 |
| 5 |
$lt 小於 (<) |
| 6 |
$lte 小於或等於 (<=) |
| 7 |
$ne 不等於 (!=) |
| 8 |
$nin 如果不同於陣列中的任何值 |
例如,我們有興趣獲取年齡大於21歲的學生列表。在find()方法的過濾器中使用$gt運算子,如下所示:
students=db['students']
docs=students.find({'age':{'$gt':21}})
for doc in docs:
print (doc.get('Name'), doc.get('age'), doc.get('marks'))
PyMongo模組提供了update_one()和update_many()方法,用於修改滿足特定過濾器表示式的單個文件或多個文件。
讓我們更新名為Juhi的文件的marks屬性。
from pymongo import MongoClient
client=MongoClient()
db=client.newdb
doc=db.students.find_one({'Name': 'Juhi'})
db['students'].update_one({'Name': 'Juhi'},{"$set":{'marks':150}})
client.close()
Python 資料持久化 - Cassandra 驅動程式
Cassandra是另一個流行的NoSQL資料庫。高可擴充套件性、一致性和容錯性——這些是Cassandra的一些重要特性。這是一個列儲存資料庫。資料儲存在許多商品伺服器中。因此,資料高度可用。
Cassandra是Apache軟體基金會的產品。資料以分散式方式儲存在多個節點中。每個節點都是一個包含鍵空間的單個伺服器。Cassandra資料庫的基本構建塊是鍵空間,它可以被認為類似於資料庫。
Cassandra的一個節點中的資料會在節點的點對點網路中的其他節點中進行復制。這使得Cassandra成為一個萬無一失的資料庫。該網路稱為資料中心。多個數據中心可以互連形成一個叢集。複製的性質是在建立鍵空間時透過設定複製策略和複製因子來配置的。
一個鍵空間可以有多個列族——就像一個數據庫可以包含多個表一樣。Cassandra的鍵空間沒有預定義的模式。Cassandra表中的每一行都可能具有不同名稱和數量可變的列。

Cassandra軟體也有兩個版本:社群版和企業版。Cassandra的最新企業版可從https://cassandra.apache.org/download/下載。
Cassandra有自己的查詢語言,稱為Cassandra查詢語言 (CQL)。CQL查詢可以在CQLASH shell內部執行——類似於MySQL或SQLite shell。CQL語法看起來類似於標準SQL。
Datastax社群版還帶有一個Develcenter IDE,如下所示:

用於處理Cassandra資料庫的Python模組稱為Cassandra Driver。它也是由Apache基金會開發的。此模組包含一個ORM API,以及一個類似於關係資料庫DB-API的核心API。
可以使用pip工具輕鬆安裝Cassandra驅動程式。
pip3 install cassandra-driver
與Cassandra資料庫的互動是透過Cluster物件進行的。Cassandra.cluster模組定義了Cluster類。我們首先需要宣告Cluster物件。
from cassandra.cluster import Cluster clstr=Cluster()
所有事務(如插入/更新等)都是透過與鍵空間啟動會話來執行的。
session=clstr.connect()
要建立一個新的鍵空間,請使用會話物件的execute()方法。execute()方法採用一個字串引數,該引數必須是一個查詢字串。CQL有CREATE KEYSPACE語句,如下所示。完整程式碼如下:
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect()
session.execute(“create keyspace mykeyspace with replication={
'class': 'SimpleStrategy', 'replication_factor' : 3
};”
這裡,SimpleStrategy是複製策略的值,複製因子設定為3。如前所述,一個鍵空間包含一個或多個表。每個表都以其資料型別為特徵。Python資料型別會根據以下表格自動解析為相應的CQL資料型別:
| Python型別 | CQL型別 |
|---|---|
| None | NULL |
| Bool | Boolean |
| Float | float, double |
| int, long | int, bigint, varint, smallint, tinyint, counter |
| decimal.Decimal | Decimal |
| str, Unicode | ascii, varchar, text |
| buffer, bytearray | Blob |
| Date | Date |
| Datetime | Timestamp |
| Time | Time |
| list, tuple, generator | List |
| set, frozenset | Set |
| dict, OrderedDict | Map |
| uuid.UUID | timeuuid, uuid |
要建立一個表,請使用會話物件執行建立表的CQL查詢。
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
qry= '''
create table students (
studentID int,
name text,
age int,
marks int,
primary key(studentID)
);'''
session.execute(qry)
建立的鍵空間可進一步用於插入行。INSERT查詢的CQL版本類似於SQL Insert語句。以下程式碼在students表中插入一行。
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
session.execute("insert into students (studentID, name, age, marks) values
(1, 'Juhi',20, 200);"
正如您所期望的那樣,SELECT語句也與Cassandra一起使用。如果execute()方法包含SELECT查詢字串,它將返回一個結果集物件,可以使用迴圈遍歷該物件。
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
rows=session.execute("select * from students;")
for row in rows:
print (StudentID: {} Name:{} Age:{} price:{} Marks:{}'
.format(row[0],row[1], row[2], row[3]))
Cassandra的SELECT查詢支援使用WHERE子句對要獲取的結果集應用過濾器。傳統邏輯運算子(如<、>、==等)都得到識別。要僅從students表中檢索名稱年齡>20的行,execute()方法中的查詢字串應如下所示:
rows=session.execute("select * from students WHERE age>20 allow filtering;")
請注意,使用了ALLOW FILTERING。此語句的ALLOW FILTERING部分允許顯式允許(某些)需要過濾的查詢。
Cassandra驅動程式API在其cassendra.query模組中定義了以下Statement型別的類。
SimpleStatement
包含在查詢字串中的簡單、未準備的CQL查詢。上面所有示例都是SimpleStatement的示例。
BatchStatement
將多個查詢(如INSERT、UPDATE和DELETE)放入批處理中並立即執行。每個行首先轉換為SimpleStatement,然後新增到批處理中。
讓我們將要新增到Students表中的行以元組列表的形式放入,如下所示:
studentlist=[(1,'Juhi',20,100), ('2,'dilip',20, 110),(3,'jeevan',24,145)]
要使用BathStatement新增上述行,請執行以下指令碼:
from cassandra.query import SimpleStatement, BatchStatement
batch=BatchStatement()
for student in studentlist:
batch.add(SimpleStatement("INSERT INTO students
(studentID, name, age, marks) VALUES
(%s, %s, %s %s)"), (student[0], student[1],student[2], student[3]))
session.execute(batch)
PreparedStatement
Prepared語句類似於DB-API中的引數化查詢。它的查詢字串由Cassandra儲存以備後用。Session.prepare()方法返回一個PreparedStatement例項。
對於我們的students表,INSERT查詢的PreparedStatement如下所示:
stmt=session.prepare("INSERT INTO students (studentID, name, age, marks) VALUES (?,?,?)")
隨後,它只需要傳送要繫結的引數值即可。例如:
qry=stmt.bind([1,'Ram', 23,175])
最後,執行上述繫結語句。
session.execute(qry)
這減少了網路流量和CPU利用率,因為Cassandra不必每次都重新解析查詢。
資料持久化 - ZODB
ZODB(Zope物件資料庫)是用於儲存Python物件的資料庫。它符合ACID——這是NOSQL資料庫中沒有的功能。ZODB也是開源的,水平可擴充套件的,並且像許多NoSQL資料庫一樣沒有模式。但是,它不是分散式的,也不提供簡單的複製功能。它為Python物件提供永續性機制。它是Zope應用程式伺服器的一部分,但也可以獨立使用。
ZODB是由Zope公司的Jim Fulton建立的。它最初是一個簡單的持久物件系統。其當前版本為5.5.0,完全用Python編寫。使用Python內建物件持久化(pickle)的擴充套件版本。
ZODB的一些主要特性包括:
- 事務
- 歷史記錄/撤消
- 可透明插入的儲存
- 內建快取
- 多版本併發控制 (MVCC)
- 跨網路的可擴充套件性
ZODB是一個分層資料庫。在建立資料庫時會初始化一個根物件。根物件用作Python字典,它可以包含其他物件(這些物件本身可以是字典式的)。要將物件儲存在資料庫中,只需將其分配給其容器內的新的鍵即可。
ZODB適用於資料具有層次結構並且讀取次數可能多於寫入次數的應用程式。ZODB是pickle物件的擴充套件。因此,它只能透過Python指令碼進行處理。
要安裝最新版本的ZODB,請使用pip工具:
pip install zodb
還將安裝以下依賴項:
- BTrees==4.6.1
- cffi==1.13.2
- persistent==4.5.1
- pycparser==2.19
- six==1.13.0
- transaction==2.4.0
ZODB提供以下儲存選項:
FileStorage
這是預設選項。所有內容都儲存在一個大型Data.fs檔案中,該檔案本質上是一個事務日誌。
DirectoryStorage
此選項為每個物件修訂版儲存一個檔案。在這種情況下,它不需要在非正常關閉時重建Data.fs.index。
RelStorage
此選項將pickle儲存在關係資料庫中。支援PostgreSQL、MySQL和Oracle。
要建立ZODB資料庫,我們需要一個儲存、一個數據庫以及最終的連線。
第一步是擁有儲存物件。
import ZODB, ZODB.FileStorage
storage = ZODB.FileStorage.FileStorage('mydata.fs')
DB類使用此儲存物件獲取資料庫物件。
db = ZODB.DB(storage)
將None傳遞給DB建構函式以建立記憶體資料庫。
Db=ZODB.DB(None)
最後,我們建立與資料庫的連線。
conn=db.open()
然後,連線物件使用‘root()’方法讓您訪問資料庫的‘根’。‘根’物件是儲存所有持久物件的字典。
root = conn.root()
例如,我們將學生列表新增到根物件,如下所示:
root['students'] = ['Mary', 'Maya', 'Meet']
在提交事務之前,此更改不會永久儲存到資料庫中。
import transaction transaction.commit()
要儲存使用者定義類的物件,該類必須繼承自persistent.Persistent父類。
子類的優點
子類化Persistent類有以下優點:
資料庫將透過設定屬性來自動跟蹤物件更改。
資料將儲存在其自己的資料庫記錄中。
您可以儲存不屬於Persistent子類的的資料,但它將儲存在引用它的任何持久物件的資料記錄中。非持久物件由其包含的持久物件擁有,如果多個持久物件引用同一個非持久子物件,它們將獲得自己的副本。
讓我們定義一個名為 student 的類,它繼承自 Persistent 類,如下所示:
import persistent
class student(persistent.Persistent):
def __init__(self, name):
self.name = name
def __repr__(self):
return str(self.name)
要新增此類的物件,我們首先需要像上面描述的那樣建立連線。
import ZODB, ZODB.FileStorage
storage = ZODB.FileStorage.FileStorage('studentdata.fs')
db = ZODB.DB(storage)
conn=db.open()
root = conn.root()
宣告物件並新增到根節點,然後提交事務。
s1=student("Akash")
root['s1']=s1
import transaction
transaction.commit()
conn.close()
新增到根節點的所有物件的列表可以透過 items() 方法作為檢視物件檢索,因為根物件類似於內建字典。
print (root.items())
ItemsView({'s1': Akash})
要從根節點獲取特定物件的屬性,
print (root['s1'].name) Akash
物件可以輕鬆更新。由於 ZODB API 是一個純 Python 包,因此它不需要使用任何外部 SQL 型別語言。
root['s1'].name='Abhishek' import transaction transaction.commit()
資料庫將立即更新。請注意,transaction 類還定義了 abort() 函式,它類似於 SQL 中的 rollback() 事務控制。
資料持久化 - Openpyxl 模組
微軟的 Excel 是最流行的電子表格應用程式。它已經使用了超過 25 年。Excel 的後續版本使用**Office Open XML**(OOXML) 檔案格式。因此,可以透過其他程式設計環境訪問電子表格檔案。
**OOXML** 是一個 ECMA 標準檔案格式。Python 的**openpyxl** 包提供了讀取/寫入副檔名為 .xlsx 的 Excel 檔案的功能。
openpyxl 包使用類似於 Microsoft Excel 術語的類命名法。Excel 文件稱為工作簿,並以 .xlsx 副檔名儲存在檔案系統中。一個工作簿可以有多個工作表。工作表呈現一個大型的單元格網格,每個單元格可以儲存值或公式。構成網格的行和列都有編號。列由字母標識,A、B、C、…、Z、AA、AB 等。行的編號從 1 開始。
一個典型的 Excel 工作表如下所示:

pip 工具足以安裝 openpyxl 包。
pip install openpyxl
Workbook 類表示一個空的工作簿,其中包含一個空白的工作表。我們需要啟用它,以便可以向工作表新增一些資料。
from openpyxl import Workbook wb=Workbook() sheet1=wb.active sheet1.title='StudentList'
眾所周知,工作表中的單元格以 ColumnNameRownumber 格式命名。因此,左上角的單元格是 A1。我們將一個字串分配給此單元格,如下所示:
sheet1['A1']= 'Student List'
或者,使用工作表的**cell()** 方法,該方法使用行號和列號來識別單元格。呼叫單元格物件的 value 屬性來分配值。
cell1=sheet1.cell(row=1, column=1) cell1.value='Student List'
在用資料填充工作表後,透過呼叫工作簿物件的 save() 方法儲存工作簿。
wb.save('Student.xlsx')
此工作簿檔案在當前工作目錄中建立。
以下 Python 指令碼將元組列表寫入工作簿文件。每個元組儲存學生的學號、年齡和分數。
from openpyxl import Workbook
wb = Workbook()
sheet1 = wb.active
sheet1.title='Student List'
sheet1.cell(column=1, row=1).value='Student List'
studentlist=[('RollNo','Name', 'age', 'marks'),(1,'Juhi',20,100),
(2,'dilip',20, 110) , (3,'jeevan',24,145)]
for col in range(1,5):
for row in range(1,5):
sheet1.cell(column=col, row=1+row).value=studentlist[row-1][col-1]
wb.save('students.xlsx')
工作簿 students.xlsx 儲存到當前工作目錄中。如果使用 Excel 應用程式開啟,則顯示如下:

openpyxl 模組提供**load_workbook()** 函式,該函式有助於讀取工作簿文件中的資料。
from openpyxl import load_workbook
wb=load_workbook('students.xlsx')
現在,您可以訪問由行號和列號指定的任何單元格的值。
cell1=sheet1.cell(row=1, column=1) print (cell1.value) Student List
示例
以下程式碼使用工作表資料填充列表。
from openpyxl import load_workbook
wb=load_workbook('students.xlsx')
sheet1 = wb['Student List']
studentlist=[]
for row in range(1,5):
stud=[]
for col in range(1,5):
val=sheet1.cell(column=col, row=1+row).value
stud.append(val)
studentlist.append(tuple(stud))
print (studentlist)
輸出
[('RollNo', 'Name', 'age', 'marks'), (1, 'Juhi', 20, 100), (2, 'dilip', 20, 110), (3, 'jeevan', 24, 145)]
Excel 應用程式的一個非常重要的功能是公式。要將公式分配給單元格,請將其分配給包含 Excel 公式語法的字串。將 AVERAGE 函式分配給包含年齡的 C6 單元格。
sheet1['C6']= 'AVERAGE(C3:C5)'
Openpyxl 模組具有**Translate_formula()** 函式,用於將公式複製到一個範圍內。以下程式在 C6 中定義 AVERAGE 函式,並將其複製到計算分數平均值的 C7。
from openpyxl import load_workbook
wb=load_workbook('students.xlsx')
sheet1 = wb['Student List']
from openpyxl.formula.translate import Translator#copy formula
sheet1['B6']='Average'
sheet1['C6']='=AVERAGE(C3:C5)'
sheet1['D6'] = Translator('=AVERAGE(C3:C5)', origin="C6").translate_formula("D6")
wb.save('students.xlsx')
更改後的工作表現在顯示如下:
