- Prolog 教程
- Prolog - 首頁
- Prolog - 簡介
- Prolog - 環境設定
- Prolog - Hello World
- Prolog - 基礎知識
- Prolog - 關係
- Prolog - 資料物件
- Prolog - 運算子
- 迴圈與決策
- 合取與析取
- Prolog - 列表
- 遞迴和結構
- Prolog - 回溯
- Prolog - 不同與非
- Prolog - 輸入和輸出
- Prolog - 內建謂詞
- 樹形資料結構(案例研究)
- Prolog - 例子
- Prolog - 基本程式
- Prolog - cut 的例子
- 漢諾塔問題
- Prolog - 連結串列
- 猴子和香蕉問題
- Prolog 有用資源
- Prolog 快速指南
- Prolog - 有用資源
- Prolog - 討論
Prolog 快速指南
Prolog - 簡介
Prolog,顧名思義,是**LOG**ical **PRO**gramming 的縮寫。它是一種邏輯和宣告式程式語言。在深入探討 Prolog 的概念之前,讓我們首先了解邏輯程式設計究竟是什麼。
邏輯程式設計是計算機程式設計正規化的一種,其中程式語句表達了系統中形式邏輯內不同問題的 facts 和 rules。這裡的規則以邏輯子句的形式編寫,其中包含頭部和體部。例如,H 是頭部,B1、B2、B3 是體部的元素。現在,如果我們宣告“當 B1、B2、B3 全都為真時,H 為真”,這就是一個規則。另一方面,事實就像規則,但沒有體部。因此,“H 為真”就是一個事實的例子。
一些邏輯程式語言,如 Datalog 或 ASP(Answer Set Programming),被稱為純粹的宣告式語言。這些語言允許關於程式應該完成什麼的語句。沒有關於如何逐步執行任務的說明。然而,像 Prolog 這樣的其他語言既具有宣告式特性,也具有命令式特性。這可能還包括程式性語句,例如“要解決問題 H,執行 B1、B2 和 B3”。
下面列出了一些邏輯程式語言:
ALF(代數邏輯函數語言程式設計語言)
ASP(Answer Set Programming)
CycL
Datalog
FuzzyCLIPS
Janus
Parlog
Prolog
Prolog++
ROOP
邏輯程式設計和函數語言程式設計
我們將討論邏輯程式設計和傳統的函數語言程式設計語言之間的區別。我們可以使用下圖來說明這兩者:
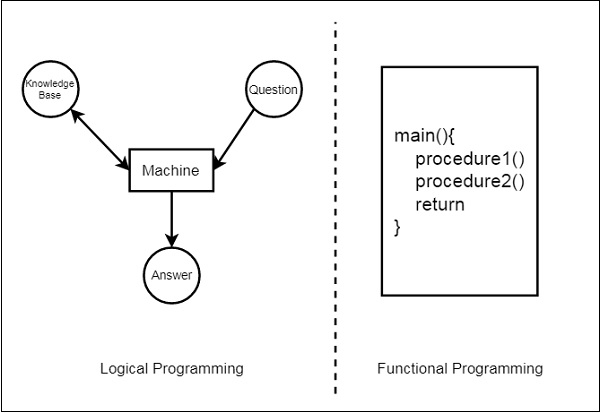
從這個圖示中,我們可以看到,在函數語言程式設計中,我們必須定義過程和過程的工作方式。這些過程一步一步地解決基於演算法的特定問題。另一方面,對於邏輯程式設計,我們將提供知識庫。使用這個知識庫,機器可以找到給定問題的答案,這與函數語言程式設計完全不同。
在函數語言程式設計中,我們必須提到如何解決一個問題,但在邏輯程式設計中,我們必須指定我們實際上想要解決哪個問題。然後邏輯程式設計會自動找到一個合適的解決方案來幫助我們解決那個特定問題。
現在讓我們看看下面更多區別:
| 函數語言程式設計 | 邏輯程式設計 |
|---|---|
| 函數語言程式設計遵循馮·諾依曼架構,或使用順序步驟。 | 邏輯程式設計使用抽象模型,或處理物件及其關係。 |
| 語法實際上是語句的序列,例如 (a, s, I)。 | 語法基本上是邏輯公式(Horn 子句)。 |
| 計算透過順序執行語句來進行。 | 它透過演繹子句來計算。 |
| 邏輯和控制混合在一起。 | 邏輯和控制可以分開。 |
什麼是 Prolog?
Prolog 或 **PRO**gramming in **LOG**ics 是一種邏輯和宣告式程式語言。它是支援宣告式程式設計正規化的第四代語言的一個主要例子。這尤其適用於涉及**符號**或**非數值計算**的程式。這是在**人工智慧**中使用 Prolog 作為程式語言的主要原因,其中**符號操作**和**推理操作**是基本任務。
在 Prolog 中,我們不需要提及如何解決一個問題,我們只需要提及問題是什麼,這樣 Prolog 就會自動解決它。但是,在 Prolog 中,我們應該給出作為**解決方案方法**的線索。
Prolog 語言基本上有三個不同的元素:
**事實** - 事實是為真的謂詞,例如,如果我們說“Tom 是 Jack 的兒子”,那麼這是一個事實。
**規則** - 規則是包含條件子句的事實的擴充套件。為了滿足規則,這些條件應該得到滿足。例如,如果我們定義一個規則為:
grandfather(X, Y) :- father(X, Z), parent(Z, Y)
這意味著,對於 X 來說是 Y 的祖父,Z 應該是 Y 的父母,而 X 應該是 Z 的父親。
**問題** - 為了執行 Prolog 程式,我們需要一些問題,而這些問題可以透過給定的 facts 和 rules 來回答。
Prolog 的歷史
Prolog 的起源包括對定理證明器和其他一些在 1960 年代和 1970 年代開發的自動化演繹系統的研究。Prolog 的推理機制基於 Robinson 在 1965 年提出的 Resolution Principle,以及 Green (1968) 提出的答案提取機制。這些想法隨著線性解析度程式的出現而強有力地結合在一起。
明確的目標導向線性解析度程式推動了通用邏輯程式設計系統的開發。**第一個**Prolog 是**Marseille Prolog**,基於**Colmerauer**在 1970 年的工作。這個 Marseille Prolog 直譯器的說明書 (Roussel, 1975) 是 Prolog 語言的第一個詳細描述。
Prolog 也被認為是支援宣告式程式設計正規化的第四代程式語言。1981 年宣佈的著名的日本第五代計算機專案採用了 Prolog 作為開發語言,從而引起了人們對這種語言及其能力的廣泛關注。
Prolog 的一些應用
Prolog 用於各個領域。它在自動化系統中發揮著至關重要的作用。以下是 Prolog 使用的其他一些重要領域:
智慧資料庫檢索
自然語言理解
規範語言
機器學習
機器人規劃
自動化系統
問題解決
Prolog - 環境設定
在本章中,我們將討論如何在我們的系統中安裝 Prolog。
Prolog 版本
在本教程中,我們使用的是 GNU Prolog,版本:1.4.5
官方網站
這是 GNU Prolog 的官方網站,我們可以在那裡看到關於 GNU Prolog 的所有必要細節,並獲得下載連結。
直接下載連結
以下是 Windows 系統 GNU Prolog 的直接下載連結。對於其他作業系統(如 Mac 或 Linux),您可以訪問官方網站(連結如上所示)獲取下載連結:
http://www.gprolog.org/#download(32 位系統)
安裝指南
下載 exe 檔案並執行它。
您將看到如下所示的視窗,然後單擊**下一步**:
選擇要安裝軟體的正確**目錄**,否則將其安裝在預設目錄中。然後點選**下一步**。
您將看到以下螢幕,只需轉到**下一步**。
您可以驗證以下螢幕,並**選中/取消選中**相應的複選框,否則您可以將其保留為預設設定。然後點選**下一步**。
在下一步中,您將看到以下螢幕,然後單擊**安裝**。
然後等待安裝過程完成。
最後單擊**完成**以啟動 GNU Prolog。
GNU prolog 成功安裝,如下所示:
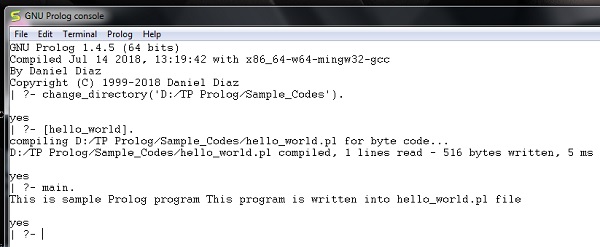
Prolog - Hello World
在上一節中,我們已經看到了如何安裝 GNU Prolog。現在,我們將瞭解如何在我們的 Prolog 環境中編寫一個簡單的**Hello World**程式。
Hello World 程式
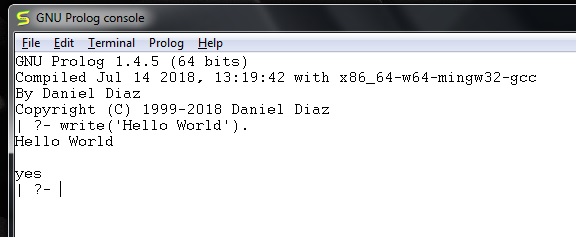
執行 GNU prolog 後,我們可以直接從控制檯編寫 hello world 程式。為此,我們必須編寫如下命令:
write('Hello World').
**注意** - 每行之後,都必須使用一個句點 (.) 符號來表示該行已結束。
相應的輸出將如下所示:
現在讓我們看看如何將 Prolog 指令碼檔案(副檔名為 *.pl)執行到 Prolog 控制檯中。
在執行 *.pl 檔案之前,我們必須將檔案儲存到 GNU prolog 控制檯指向的目錄中,否則只需按照以下步驟更改目錄:
**步驟 1** - 在 prolog 控制檯中,轉到檔案 > 更改目錄,然後單擊該選單。
**步驟 2** - 選擇正確的資料夾並按**確定**。
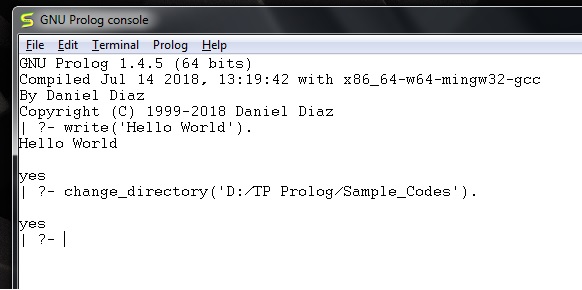
現在,我們可以在 prolog 控制檯中看到,它顯示我們已成功更改目錄。
**步驟 3** - 現在建立一個檔案(副檔名為 *.pl)並編寫如下程式碼:
main :- write('This is sample Prolog program'),
write(' This program is written into hello_world.pl file').
現在讓我們執行程式碼。要執行它,我們必須編寫檔名如下:
[hello_world]
輸出如下:
Prolog - 基礎知識
在本章中,我們將瞭解一些關於 Prolog 的基本知識。因此,我們將繼續進行 Prolog 程式設計的第一步。
本章將涵蓋的不同主題包括:
**知識庫** - 這是邏輯程式設計的基本部分之一。我們將詳細瞭解知識庫以及它如何幫助邏輯程式設計。
**事實、規則和查詢** - 這些是邏輯程式設計的構建塊。我們將獲得關於事實和規則的一些詳細知識,並瞭解一些將在邏輯程式設計中使用的查詢。
在這裡,我們將討論邏輯程式設計的基本構建塊。這些構建塊是**事實、規則和查詢**。
事實
我們可以將事實定義為物件之間以及物件可能具有的屬性之間的顯式關係。因此,事實本質上是無條件為真的。假設我們有一些如下所示的事實:
Tom 是一隻貓
Kunal 喜歡吃義大利麵
頭髮是黑色的
Nawaz 喜歡玩遊戲
Pratyusha 很懶。
所以這些是一些無條件為真的事實。這些實際上是我們必須認為是正確的陳述。
以下是編寫事實的一些指導原則:
屬性/關係的名稱以小寫字母開頭。
關係名稱顯示為第一個術語。
物件顯示為括號內用逗號分隔的引數。
句點“.”必須結束一個事實。
物件也以小寫字母開頭。它們也可以以數字開頭(如 1234),並且可以是用引號括起來的字元字串,例如 color(penink, ‘red’)。
phoneno(agnibha, 1122334455)。也稱為謂詞或子句。
語法
事實的語法如下:
relation(object1,object2...).
例子
以下是上述概念的一個例子:
cat(tom). loves_to_eat(kunal,pasta). of_color(hair,black). loves_to_play_games(nawaz). lazy(pratyusha).
規則
我們可以將規則定義為物件之間的隱式關係。因此,事實是有條件為真的。因此,當一個關聯條件為真時,謂詞也為真。假設我們有一些如下所示的規則:
如果 Lili 跳舞,她就會快樂。
如果 Tom 正在尋找食物,他就餓了。
如果 Jack 和 Bili 都喜歡打板球,那麼他們是朋友。
如果學校放假,而且他空閒,他就會去玩。
這些規則是條件性成立的,即當右側為真時,左側也為真。
這裡符號 (:- ) 讀作“如果”或“由…蘊含”。它也稱為箭頭符號,符號左側稱為頭部 (Head),右側稱為體 (Body)。這裡可以使用逗號 (,),它表示合取;也可以使用分號 (;),它表示析取。
語法
rule_name(object1, object2, ...) :- fact/rule(object1, object2, ...) Suppose a clause is like : P :- Q;R. This can also be written as P :- Q. P :- R. If one clause is like : P :- Q,R;S,T,U. Is understood as P :- (Q,R);(S,T,U). Or can also be written as: P :- Q,R. P :- S,T,U.
例子
happy(lili) :- dances(lili). hungry(tom) :- search_for_food(tom). friends(jack, bili) :- lovesCricket(jack), lovesCricket(bili). goToPlay(ryan) :- isClosed(school), free(ryan).
查詢
查詢是對物件和物件屬性之間關係的一些提問。問題可以是任何內容,例如:
Tom 是否是一隻貓?
Kunal 是否喜歡吃義大利麵?
Lili 是否快樂?
Ryan 會去玩嗎?
根據這些查詢,邏輯程式語言可以找到答案並返回它們。
邏輯程式設計中的知識庫
在本節中,我們將瞭解邏輯程式設計中的知識庫是什麼。
眾所周知,邏輯程式設計中有三個主要組成部分:事實、規則和查詢。如果將這三個部分中的事實和規則作為一個整體收集起來,則構成一個知識庫。因此,可以說知識庫是事實和規則的集合。
現在,我們將瞭解如何編寫一些知識庫。假設我們有第一個知識庫,稱為 KB1。在 KB1 中,我們有一些事實。事實用於陳述對感興趣的領域無條件為真的事情。
知識庫 1
假設我們知道 Priya、Tiyasha 和 Jaya 是三個女孩,其中 Priya 會做飯。讓我們嘗試以更通用的方式編寫這些事實,如下所示:
girl(priya). girl(tiyasha). girl(jaya). can_cook(priya).
注意 - 這裡我們將名稱寫成小寫字母,因為在 Prolog 中,以大寫字母開頭的字串表示變數。
現在,我們可以透過提出一些查詢來使用這個知識庫。“Priya 是女孩嗎?”,它將回答“是”;“Jamini 是女孩嗎?”,它將回答“否”,因為它不知道 Jamini 是誰。我們的下一個問題是“Priya 會做飯嗎?”,它會說“是”,但如果我們對 Jaya 提問相同的問題,它會說“否”。
輸出
GNU Prolog 1.4.5 (64 bits)
Compiled Jul 14 2018, 13:19:42 with x86_64-w64-mingw32-gcc
By Daniel Diaz
Copyright (C) 1999-2018 Daniel Diaz
| ?- change_directory('D:/TP Prolog/Sample_Codes').
yes
| ?- [kb1]
.
compiling D:/TP Prolog/Sample_Codes/kb1.pl for byte code...
D:/TP Prolog/Sample_Codes/kb1.pl compiled, 3 lines read - 489 bytes written, 10 ms
yes
| ?- girl(priya)
.
yes
| ?- girl(jamini).
no
| ?- can_cook(priya).
yes
| ?- can_cook(jaya).
no
| ?-
讓我們看看另一個知識庫,其中我們有一些規則。規則包含一些關於感興趣的領域條件為真的資訊。假設我們的知識庫如下所示:
sing_a_song(ananya). listens_to_music(rohit). listens_to_music(ananya) :- sing_a_song(ananya). happy(ananya) :- sing_a_song(ananya). happy(rohit) :- listens_to_music(rohit). playes_guitar(rohit) :- listens_to_music(rohit).
上面給出了一些事實和規則。前兩個是事實,但其餘的是規則。我們知道 Ananya 會唱歌,這意味著她也會聽音樂。因此,如果我們問“Ananya 聽音樂嗎?”,答案將為真。同樣,“Rohit 快樂嗎?”,這也將為真,因為他聽音樂。但如果我們的問題是“Ananya 彈吉他嗎?”,那麼根據知識庫,它將說“否”。這些是基於此知識庫的一些查詢示例。
輸出
| ?- [kb2]. compiling D:/TP Prolog/Sample_Codes/kb2.pl for byte code... D:/TP Prolog/Sample_Codes/kb2.pl compiled, 6 lines read - 1066 bytes written, 15 ms yes | ?- happy(rohit). yes | ?- sing_a_song(rohit). no | ?- sing_a_song(ananya). yes | ?- playes_guitar(rohit). yes | ?- playes_guitar(ananya). no | ?- listens_to_music(ananya). yes | ?-
知識庫 3
知識庫 3 的事實和規則如下:
can_cook(priya). can_cook(jaya). can_cook(tiyasha). likes(priya,jaya) :- can_cook(jaya). likes(priya,tiyasha) :- can_cook(tiyasha).
如果我們想檢視會做飯的成員,可以在查詢中使用一個變數。變數應以大寫字母開頭。結果將逐一顯示。如果按 Enter 鍵,則會退出;否則,如果按分號 (;),則會顯示下一個結果。
讓我們看看一個實際演示輸出,以瞭解其工作原理。
輸出
| ?- [kb3].
compiling D:/TP Prolog/Sample_Codes/kb3.pl for byte code...
D:/TP Prolog/Sample_Codes/kb3.pl compiled, 5 lines read - 737 bytes written, 22 ms
warning: D:/TP Prolog/Sample_Codes/kb3.pl:1: redefining procedure can_cook/1
D:/TP Prolog/Sample_Codes/kb1.pl:4: previous definition
yes
| ?- can_cook(X).
X = priya ? ;
X = jaya ? ;
X = tiyasha
yes
| ?- likes(priya,X).
X = jaya ? ;
X = tiyasha
yes
| ?-
Prolog - 關係
關係是我們在 Prolog 中必須正確提及的主要特徵之一。這些關係可以表示為事實和規則。之後,我們將瞭解家庭關係,如何在 Prolog 中表達基於家庭的關係,以及檢視家庭的遞迴關係。
我們將透過建立事實和規則來建立知識庫,並在其上執行查詢。
Prolog 中的關係
在 Prolog 程式中,它指定了物件及其屬性之間的關係。
例如,有一句話:“Amit 有一輛腳踏車”,我們實際上是在宣告兩個物件之間的所有權關係——一個是 Amit,另一個是腳踏車。
如果我們問一個問題:“Amit 是否擁有腳踏車?”,我們實際上是在試圖瞭解一種關係。
有各種各樣的關係,其中一些也可以是規則。即使關係沒有明確定義為事實,規則也可以找出關係。
我們可以定義兄弟關係如下:
兩個人是兄弟,如果:
他們都是男性。
他們有相同的父母。
現在考慮我們有以下短語:
parent(sudip, piyus).
parent(sudip, raj).
male(piyus).
male(raj).
brother(X,Y) :- parent(Z,X), parent(Z,Y),male(X), male(Y)
這些子句可以給出 Piyus 和 Raj 是兄弟的答案,但在這裡我們將得到三對輸出。它們是:(piyus, piyus), (piyus, raj), (raj, raj)。對於這些對,給定條件為真,但對於 (piyus, piyus), (raj, raj) 這兩對,他們實際上不是兄弟,他們是同一個人。因此,我們必須正確建立子句以形成關係。
修改後的關係可以如下所示:
A 和 B 是兄弟,如果:
A 和 B 都是男性
他們有相同的父親
他們有相同的母親
A 和 B 不是同一個人
Prolog 中的家庭關係
在這裡,我們將看到家庭關係。這是一個使用 Prolog 可以形成的複雜關係的示例。我們想要製作一個家譜,並將該家譜對映到事實和規則中,然後我們可以對其執行一些查詢。
假設家譜如下所示:
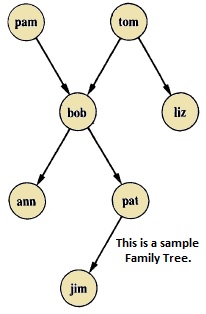
從這棵樹中,我們可以瞭解到有一些關係。Bob 是 Pam 和 Tom 的孩子,Bob 也有兩個孩子——Ann 和 Pat。Bob 還有一個兄弟 Liz,其父母也是 Tom。因此,我們希望製作如下謂詞:
謂詞
parent(pam, bob).
parent(tom, bob).
parent(tom, liz).
parent(bob, ann).
parent(bob, pat).
parent(pat, jim).
parent(bob, peter).
parent(peter, jim).
從我們的示例中,它有助於說明一些要點:
我們根據家譜中給出的資訊,透過宣告基於物件的 n 元組來定義父關係。
使用者可以輕鬆地查詢 Prolog 系統關於程式中定義的關係。
Prolog 程式由以句點結尾的子句組成。
關係的引數可以(除其他外)是:具體物件或常量(例如 pat 和 jim),或通用物件,例如 X 和 Y。程式中第一類物件稱為原子。第二類物件稱為變數。
對系統的問題包含一個或多個目標。
有些事實可以用兩種不同的方式編寫,例如家庭成員的性別可以用以下兩種形式中的任何一種編寫:
female(pam).
male(tom).
male(bob).
female(liz).
female(pat).
female(ann).
male(jim).
或以下形式:
sex( pam, feminine).
sex( tom, masculine).
sex( bob, masculine).
……等等。
現在,如果我們想建立母親和姐妹的關係,我們可以按如下方式編寫:
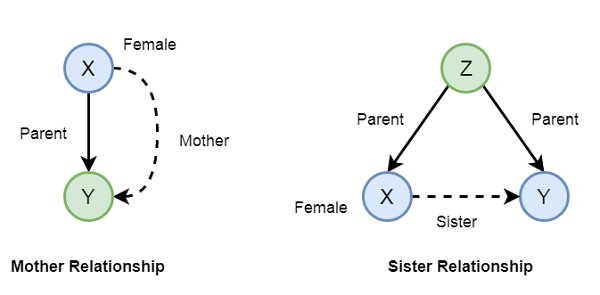
在 Prolog 語法中,我們可以編寫:
mother(X,Y) :- parent(X,Y), female(X).
sister(X,Y) :- parent(Z,X), parent(Z,Y), female(X), X \== Y.
現在讓我們看看實際演示:
知識庫 (family.pl)
female(pam). female(liz). female(pat). female(ann). male(jim). male(bob). male(tom). male(peter). parent(pam,bob). parent(tom,bob). parent(tom,liz). parent(bob,ann). parent(bob,pat). parent(pat,jim). parent(bob,peter). parent(peter,jim). mother(X,Y):- parent(X,Y),female(X). father(X,Y):- parent(X,Y),male(X). haschild(X):- parent(X,_). sister(X,Y):- parent(Z,X),parent(Z,Y),female(X),X\==Y. brother(X,Y):-parent(Z,X),parent(Z,Y),male(X),X\==Y.
輸出
| ?- [family]. compiling D:/TP Prolog/Sample_Codes/family.pl for byte code... D:/TP Prolog/Sample_Codes/family.pl compiled, 23 lines read - 3088 bytes written, 9 ms yes | ?- parent(X,jim). X = pat ? ; X = peter yes | ?- mother(X,Y). X = pam Y = bob ? ; X = pat Y = jim ? ; no | ?- haschild(X). X = pam ? ; X = tom ? ; X = tom ? ; X = bob ? ; X = bob ? ; X = pat ? ; X = bob ? ; X = peter yes | ?- sister(X,Y). X = liz Y = bob ? ; X = ann Y = pat ? ; X = ann Y = peter ? ; X = pat Y = ann ? ; X = pat Y = peter ? ; (16 ms) no | ?-
現在讓我們看看從先前家庭關係中可以建立的一些更多關係。因此,如果我們想要建立祖父母關係,則可以如下形成:
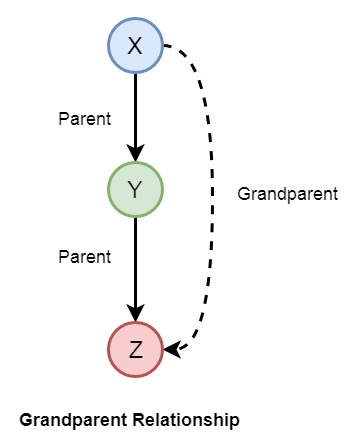
我們還可以建立其他一些關係,例如妻子、叔叔等。我們可以按如下方式編寫關係:
grandparent(X,Y) :- parent(X,Z), parent(Z,Y).
grandmother(X,Z) :- mother(X,Y), parent(Y,Z).
grandfather(X,Z) :- father(X,Y), parent(Y,Z).
wife(X,Y) :- parent(X,Z),parent(Y,Z), female(X),male(Y).
uncle(X,Z) :- brother(X,Y), parent(Y,Z).
因此,讓我們編寫一個 Prolog 程式來實際檢視這一點。在這裡,我們還將看到跟蹤以跟蹤執行過程。
知識庫 (family_ext.pl)
female(pam). female(liz). female(pat). female(ann). male(jim). male(bob). male(tom). male(peter). parent(pam,bob). parent(tom,bob). parent(tom,liz). parent(bob,ann). parent(bob,pat). parent(pat,jim). parent(bob,peter). parent(peter,jim). mother(X,Y):- parent(X,Y),female(X). father(X,Y):-parent(X,Y),male(X). sister(X,Y):-parent(Z,X),parent(Z,Y),female(X),X\==Y. brother(X,Y):-parent(Z,X),parent(Z,Y),male(X),X\==Y. grandparent(X,Y):-parent(X,Z),parent(Z,Y). grandmother(X,Z):-mother(X,Y),parent(Y,Z). grandfather(X,Z):-father(X,Y),parent(Y,Z). wife(X,Y):-parent(X,Z),parent(Y,Z),female(X),male(Y). uncle(X,Z):-brother(X,Y),parent(Y,Z).
輸出
| ?- [family_ext]. compiling D:/TP Prolog/Sample_Codes/family_ext.pl for byte code... D:/TP Prolog/Sample_Codes/family_ext.pl compiled, 27 lines read - 4646 bytes written, 10 ms | ?- uncle(X,Y). X = peter Y = jim ? ; no | ?- grandparent(X,Y). X = pam Y = ann ? ; X = pam Y = pat ? ; X = pam Y = peter ? ; X = tom Y = ann ? ; X = tom Y = pat ? ; X = tom Y = peter ? ; X = bob Y = jim ? ; X = bob Y = jim ? ; no | ?- wife(X,Y). X = pam Y = tom ? ; X = pat Y = peter ? ; (15 ms) no | ?-
跟蹤輸出
在 Prolog 中,我們可以跟蹤執行過程。要跟蹤輸出,必須透過鍵入“trace.”進入跟蹤模式。然後從輸出中我們可以看到我們只是在跟蹤“Pam 是誰的母親?”。透過將 X=pam 和 Y 作為變數來檢視跟蹤輸出,則 Y 的答案將是 bob。要退出跟蹤模式,請按“notrace.”。
程式
| ?- [family_ext].
compiling D:/TP Prolog/Sample_Codes/family_ext.pl for byte code...
D:/TP Prolog/Sample_Codes/family_ext.pl compiled, 27 lines read - 4646 bytes written, 10 ms
(16 ms) yes
| ?- mother(X,Y).
X = pam
Y = bob ? ;
X = pat
Y = jim ? ;
no
| ?- trace.
The debugger will first creep -- showing everything (trace)
yes
{trace}
| ?- mother(pam,Y).
1 1 Call: mother(pam,_23) ?
2 2 Call: parent(pam,_23) ?
2 2 Exit: parent(pam,bob) ?
3 2 Call: female(pam) ?
3 2 Exit: female(pam) ?
1 1 Exit: mother(pam,bob) ?
Y = bob
(16 ms) yes
{trace}
| ?- notrace.
The debugger is switched off
yes
| ?-
家庭關係中的遞迴
在上一節中,我們已經看到我們可以定義一些家庭關係。這些關係本質上是靜態的。我們還可以建立一些遞迴關係,這些關係可以從以下圖示中表達:
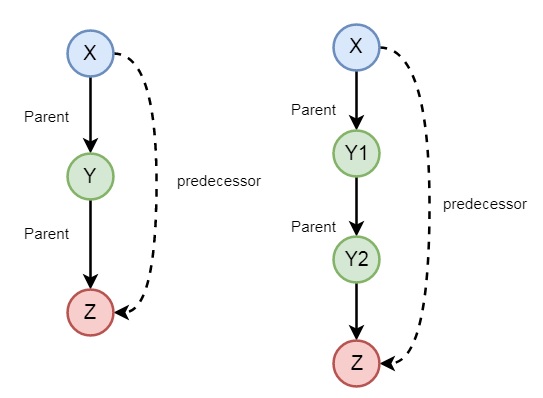
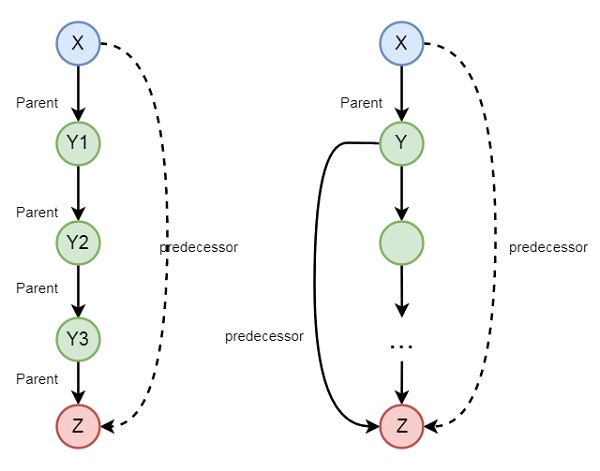
因此,我們可以理解先行關係是遞迴的。我們可以使用以下語法表達這種關係:
predecessor(X, Z) :- parent(X, Z). predecessor(X, Z) :- parent(X, Y),predecessor(Y, Z).
現在讓我們看看實際演示。
知識庫 (family_rec.pl)
female(pam). female(liz). female(pat). female(ann). male(jim). male(bob). male(tom). male(peter). parent(pam,bob). parent(tom,bob). parent(tom,liz). parent(bob,ann). parent(bob,pat). parent(pat,jim). parent(bob,peter). parent(peter,jim). predecessor(X, Z) :- parent(X, Z). predecessor(X, Z) :- parent(X, Y),predecessor(Y, Z).
輸出
| ?- [family_rec].
compiling D:/TP Prolog/Sample_Codes/family_rec.pl for byte code...
D:/TP Prolog/Sample_Codes/family_rec.pl compiled, 21 lines read - 1851 bytes written, 14 ms
yes
| ?- predecessor(peter,X).
X = jim ? ;
no
| ?- trace.
The debugger will first creep -- showing everything (trace)
yes
{trace}
| ?- predecessor(bob,X).
1 1 Call: predecessor(bob,_23) ?
2 2 Call: parent(bob,_23) ?
2 2 Exit: parent(bob,ann) ?
1 1 Exit: predecessor(bob,ann) ?
X = ann ? ;
1 1 Redo: predecessor(bob,ann) ?
2 2 Redo: parent(bob,ann) ?
2 2 Exit: parent(bob,pat) ?
1 1 Exit: predecessor(bob,pat) ?
X = pat ? ;
1 1 Redo: predecessor(bob,pat) ?
2 2 Redo: parent(bob,pat) ?
2 2 Exit: parent(bob,peter) ?
1 1 Exit: predecessor(bob,peter) ?
X = peter ? ;
1 1 Redo: predecessor(bob,peter) ?
2 2 Call: parent(bob,_92) ?
2 2 Exit: parent(bob,ann) ?
3 2 Call: predecessor(ann,_23) ?
4 3 Call: parent(ann,_23) ?
4 3 Fail: parent(ann,_23) ?
4 3 Call: parent(ann,_141) ?
4 3 Fail: parent(ann,_129) ?
3 2 Fail: predecessor(ann,_23) ?
2 2 Redo: parent(bob,ann) ?
2 2 Exit: parent(bob,pat) ?
3 2 Call: predecessor(pat,_23) ?
4 3 Call: parent(pat,_23) ?
4 3 Exit: parent(pat,jim) ?
3 2 Exit: predecessor(pat,jim) ?
1 1 Exit: predecessor(bob,jim) ?
X = jim ? ;
1 1 Redo: predecessor(bob,jim) ?
3 2 Redo: predecessor(pat,jim) ?
4 3 Call: parent(pat,_141) ?
4 3 Exit: parent(pat,jim) ?
5 3 Call: predecessor(jim,_23) ?
6 4 Call: parent(jim,_23) ?
6 4 Fail: parent(jim,_23) ?
6 4 Call: parent(jim,_190) ?
6 4 Fail: parent(jim,_178) ?
5 3 Fail: predecessor(jim,_23) ?
3 2 Fail: predecessor(pat,_23) ?
2 2 Redo: parent(bob,pat) ?
2 2 Exit: parent(bob,peter) ?
3 2 Call: predecessor(peter,_23) ?
4 3 Call: parent(peter,_23) ?
4 3 Exit: parent(peter,jim) ?
3 2 Exit: predecessor(peter,jim) ?
1 1 Exit: predecessor(bob,jim) ?
X = jim ?
(78 ms) yes
{trace}
| ?-
Prolog - 資料物件
在本章中,我們將學習 Prolog 中的資料物件。它們可以分為以下幾類:
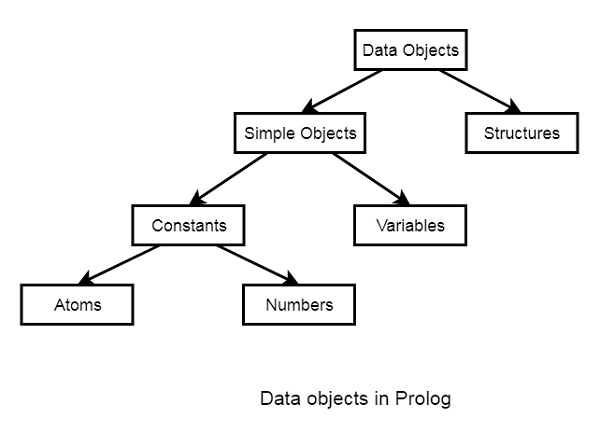
以下是各種資料物件的示例:
原子 - tom、pat、x100、x_45
數字 - 100、1235、2000.45
變數 - X、Y、Xval、_X
結構 - day(9, jun, 2017)、point(10, 25)
原子和變數
在本節中,我們將討論 Prolog 的原子、數字和變數。
原子
原子是常量的一種變體。它們可以是任何名稱或物件。在嘗試使用原子時,應遵循以下一些規則:
以小寫字母開頭的字母、數字和下劃線字元“_”的字串。例如:
azahar
b59
b_59
b_59AB
b_x25
antara_sarkar
特殊字元的字串
我們必須記住,當使用這種形式的原子時,需要小心,因為某些特殊字元的字串已經具有預定義的含義;例如 ':-'。
<--->
=======>
...
.:.
::=
用單引號括起來的字元字串。
如果我們想要一個以大寫字母開頭的原子,這將非常有用。透過將其括在引號中,我們可以使其與變數區分開來:
‘Rubai’
‘Arindam_Chatterjee’
‘Sumit Mitra’
數字
常量的另一個變體是數字。因此,整數可以表示為 100、4、-81、1202。在 Prolog 中,整數的正常範圍是從 -16383 到 16383。
Prolog 還支援實數,但通常在 Prolog 程式中很少使用浮點數,因為 Prolog 用於符號而非數值計算。實數的處理取決於 Prolog 的實現。實數的示例是 3.14159、-0.00062、450.18 等。
變數屬於簡單物件部分。變數可以在我們之前看到的 Prolog 程式中的許多情況下使用。因此,在 Prolog 中定義變數有一些規則。
我們可以定義 Prolog 變數,使得變數是字母、數字和下劃線字元的字串。它們以大寫字母或下劃線字元開頭。一些變數示例如下:
X
Sum
Memer_name
Student_list
Shoppinglist
_a50
_15
Prolog 中的匿名變數
匿名變數沒有名稱。Prolog 中的匿名變數由單個下劃線字元“_”表示。重要的一點是,每個單獨的匿名變數都被視為不同的。它們並不相同。
現在的問題是,我們應該在哪裡使用這些匿名變數?
假設在我們的知識庫中有一些事實——“jim討厭tom”、“pat討厭bob”。所以如果tom想知道誰討厭他,他可以使用變數。但是,如果他想檢查是否有人討厭他,我們可以使用匿名變數。所以當我們想使用變數,但不想透露變數的值時,我們可以使用匿名變數。
讓我們看看它的實際實現:
知識庫 (var_anonymous.pl)
hates(jim,tom). hates(pat,bob). hates(dog,fox). hates(peter,tom).
輸出
| ?- [var_anonymous]. compiling D:/TP Prolog/Sample_Codes/var_anonymous.pl for byte code... D:/TP Prolog/Sample_Codes/var_anonymous.pl compiled, 3 lines read - 536 bytes written, 16 ms yes | ?- hates(X,tom). X = jim ? ; X = peter yes | ?- hates(_,tom). true ? ; (16 ms) yes | ?- hates(_,pat). no | ?- hates(_,fox). true ? ; no | ?-
Prolog - 運算子
在接下來的部分中,我們將瞭解Prolog中不同型別的運算子。比較運算子和算術運算子的型別。
我們還將瞭解這些運算子與任何其他高階語言運算子的不同之處,它們的語法差異以及它們的工作方式差異。我們還將看到一些實際演示,以瞭解不同運算子的使用。
比較運算子
比較運算子用於比較兩個等式或狀態。以下是不同的比較運算子:
| 運算子 | 含義 |
|---|---|
| X > Y | X 大於 Y |
| X < Y | X 小於 Y |
| X >= Y | X 大於或等於 Y |
| X =< Y | X 小於或等於 Y |
| X =:= Y | X 和 Y 的值相等 |
| X =\= Y | X 和 Y 的值不相等 |
您可以看到,'=<' 運算子、'=:= '運算子和'=\='運算子在語法上與其他語言不同。讓我們來看一些實際演示。
例子
| ?- 1+2=:=2+1. yes | ?- 1+2=2+1. no | ?- 1+A=B+2. A = 2 B = 1 yes | ?- 5<10. yes | ?- 5>10. no | ?- 10=\=100. yes
在這裡我們可以看到 1+2=:=2+1 返回 true,但 1+2=2+1 返回 false。這是因為,在第一種情況下,它檢查 1 + 2 的值是否與 2 + 1 相同,而另一種情況則檢查兩個模式 '1+2' 和 '2+1' 是否相同。由於它們不相同,它返回 no (false)。在 1+A=B+2 的情況下,A 和 B 是兩個變數,它們會自動賦值為一些與模式匹配的值。
Prolog中的算術運算子
算術運算子用於執行算術運算。有幾種不同型別的算術運算子,如下所示:
| 運算子 | 含義 |
|---|---|
| + | 加法 |
| - | 減法 |
| * | 乘法 |
| / | 除法 |
| ** | 乘方 |
| // | 整數除法 |
| 模運算 | 取模 |
讓我們看一個實際程式碼來了解這些運算子的使用。
程式
calc :- X is 100 + 200,write('100 + 200 is '),write(X),nl,
Y is 400 - 150,write('400 - 150 is '),write(Y),nl,
Z is 10 * 300,write('10 * 300 is '),write(Z),nl,
A is 100 / 30,write('100 / 30 is '),write(A),nl,
B is 100 // 30,write('100 // 30 is '),write(B),nl,
C is 100 ** 2,write('100 ** 2 is '),write(C),nl,
D is 100 mod 30,write('100 mod 30 is '),write(D),nl.
注意 - nl 用於建立新行。
輸出
| ?- change_directory('D:/TP Prolog/Sample_Codes').
yes
| ?- [op_arith].
compiling D:/TP Prolog/Sample_Codes/op_arith.pl for byte code...
D:/TP Prolog/Sample_Codes/op_arith.pl compiled, 6 lines read - 2390 bytes written, 11 ms
yes
| ?- calc.
100 + 200 is 300
400 - 150 is 250
10 * 300 is 3000
100 / 30 is 3.3333333333333335
100 // 30 is 3
100 ** 2 is 10000.0
100 mod 30 is 10
yes
| ?-
Prolog - 迴圈和決策
在本章中,我們將討論Prolog中的迴圈和決策。
迴圈
迴圈語句用於多次執行程式碼塊。通常,for、while、do-while 是程式語言(如 Java、C、C++)中的迴圈結構。
使用遞迴謂詞邏輯多次執行程式碼塊。某些其他語言中沒有直接迴圈,但我們可以使用幾種不同的技術來模擬迴圈。
程式
count_to_10(10) :- write(10),nl. count_to_10(X) :- write(X),nl, Y is X + 1, count_to_10(Y).
輸出
| ?- [loop]. compiling D:/TP Prolog/Sample_Codes/loop.pl for byte code... D:/TP Prolog/Sample_Codes/loop.pl compiled, 4 lines read - 751 bytes written, 16 ms (16 ms) yes | ?- count_to_10(3). 3 4 5 6 7 8 9 10 true ? yes | ?-
現在建立一個迴圈,該迴圈取最小值和最大值。因此,我們可以使用 between() 來模擬迴圈。
程式
讓我們看一個示例程式:
count_down(L, H) :- between(L, H, Y), Z is H - Y, write(Z), nl. count_up(L, H) :- between(L, H, Y), Z is L + Y, write(Z), nl.
輸出
| ?- [loop]. compiling D:/TP Prolog/Sample_Codes/loop.pl for byte code... D:/TP Prolog/Sample_Codes/loop.pl compiled, 14 lines read - 1700 bytes written, 16 ms yes | ?- count_down(12,17). 5 true ? ; 4 true ? ; 3 true ? ; 2 true ? ; 1 true ? ; 0 yes | ?- count_up(5,12). 10 true ? ; 11 true ? ; 12 true ? ; 13 true ? ; 14 true ? ; 15 true ? ; 16 true ? ; 17 yes | ?-
決策
決策語句是 If-Then-Else 語句。因此,當我們嘗試匹配某些條件並執行某些任務時,我們將使用決策語句。基本用法如下:
If <condition> is true, Then <do this>, Else
在一些不同的程式語言中,有 If-Else 語句,但在 Prolog 中,我們必須以其他方式定義我們的語句。以下是 Prolog 中決策的一個示例。
程式
% If-Then-Else statement
gt(X,Y) :- X >= Y,write('X is greater or equal').
gt(X,Y) :- X < Y,write('X is smaller').
% If-Elif-Else statement
gte(X,Y) :- X > Y,write('X is greater').
gte(X,Y) :- X =:= Y,write('X and Y are same').
gte(X,Y) :- X < Y,write('X is smaller').
輸出
| ?- [test]. compiling D:/TP Prolog/Sample_Codes/test.pl for byte code... D:/TP Prolog/Sample_Codes/test.pl compiled, 3 lines read - 529 bytes written, 15 ms yes | ?- gt(10,100). X is smaller yes | ?- gt(150,100). X is greater or equal true ? yes | ?- gte(10,20). X is smaller (15 ms) yes | ?- gte(100,20). X is greater true ? yes | ?- gte(100,100). X and Y are same true ? yes | ?-
Prolog - 連線詞和析取詞
在本章中,我們將討論連線詞和析取詞屬性。這些屬性在其他程式語言中使用 AND 和 OR 邏輯。Prolog 也在其語法中使用相同的邏輯。
連線詞
連線詞 (AND 邏輯) 可以使用逗號 (,) 運算子實現。因此,用逗號分隔的兩個謂詞與 AND 語句連線在一起。假設我們有一個謂詞,parent(jhon, bob),這意味著“Jhon 是 Bob 的父母”,另一個謂詞,male(jhon),這意味著“Jhon 是男性”。所以我們可以建立另一個謂詞 father(jhon,bob),這意味著“Jhon 是 Bob 的父親”。當他是父母 **AND** 他是男性時,我們可以定義謂詞 **father**。
析取詞
析取詞 (OR 邏輯) 可以使用分號 (;) 運算子實現。因此,用分號分隔的兩個謂詞與 OR 語句連線在一起。假設我們有一個謂詞,father(jhon, bob)。這表示“Jhon 是 Bob 的父親”,另一個謂詞,mother(lili,bob),這表示“lili 是 bob 的母親”。如果我們建立另一個謂詞為 child(),則當 father(jhon, bob) 為真 **OR** mother(lili,bob) 為真時,它將為真。
程式
parent(jhon,bob). parent(lili,bob). male(jhon). female(lili). % Conjunction Logic father(X,Y) :- parent(X,Y),male(X). mother(X,Y) :- parent(X,Y),female(X). % Disjunction Logic child_of(X,Y) :- father(X,Y);mother(X,Y).
輸出
| ?- [conj_disj]. compiling D:/TP Prolog/Sample_Codes/conj_disj.pl for byte code... D:/TP Prolog/Sample_Codes/conj_disj.pl compiled, 11 lines read - 1513 bytes written, 24 ms yes | ?- father(jhon,bob). yes | ?- child_of(jhon,bob). true ? yes | ?- child_of(lili,bob). yes | ?-
Prolog - 列表
在本章中,我們將討論 Prolog 中的一個重要概念:列表。它是一種資料結構,可用於非數值程式設計的不同情況下。列表用於將原子儲存為集合。
在後續章節中,我們將討論以下主題:
Prolog 中列表的表示
Prolog 的基本操作,例如插入、刪除、更新、追加。
重新定位運算子,例如排列、組合等。
集合運算,例如集合並集、集合交集等。
列表的表示
列表是一種簡單的資料結構,廣泛用於非數值程式設計。列表包含任意數量的專案,例如 red、green、blue、white、dark。它將表示為 [red, green, blue, white, dark]。元素列表將用 **方括號** 括起來。
列表可以是 **空** 的或 **非空** 的。在第一種情況下,列表簡單地寫為 Prolog 原子,[]。在第二種情況下,列表包含如下所示的兩部分:
第一項,稱為列表的 **頭部**;
列表的其餘部分,稱為 **尾部**。
假設我們有一個列表: [red, green, blue, white, dark]。這裡頭部是 red,尾部是 [green, blue, white, dark]。因此尾部是另一個列表。
現在,讓我們考慮我們有一個列表,L = [a, b, c]。如果我們寫 Tail = [b, c],那麼我們也可以將列表 L 寫為 L = [ a | Tail]。這裡豎線 (|) 分隔頭部和尾部。
因此,以下列表表示也是有效的:
[a, b, c] = [x | [b, c] ]
[a, b, c] = [a, b | [c] ]
[a, b, c] = [a, b, c | [ ] ]
對於這些屬性,我們可以將列表定義為:
一種資料結構,或者是空的,或者由兩部分組成:頭部和尾部。尾部本身必須是一個列表。
列表的基本操作
下表包含 Prolog 列表的各種操作:
| 操作 | 定義 |
|---|---|
| 成員資格檢查 | 在此操作期間,我們可以驗證給定元素是否是指定列表的成員? |
| 長度計算 | 透過此操作,我們可以找到列表的長度。 |
| 連線 | 連線是一個用於連線/新增兩個列表的操作。 |
| 刪除專案 | 此操作將從列表中刪除指定的元素。 |
| 追加專案 | 追加操作將一個列表新增到另一個列表中(作為一項)。 |
| 插入專案 | 此操作將給定專案插入到列表中。 |
成員資格操作
在此操作期間,我們可以檢查成員 X 是否存在於列表 L 中?那麼如何檢查呢?好吧,我們必須定義一個謂詞來做到這一點。假設謂詞名稱為 list_member(X,L)。此謂詞的目標是檢查 X 是否存在於 L 中。
要設計此謂詞,我們可以遵循以下觀察結果。如果 X 是 L 的成員,則:
X 是 L 的頭部,或者
X 是 L 的尾部的成員
程式
list_member(X,[X|_]). list_member(X,[_|TAIL]) :- list_member(X,TAIL).
輸出
| ?- [list_basics]. compiling D:/TP Prolog/Sample_Codes/list_basics.pl for byte code... D:/TP Prolog/Sample_Codes/list_basics.pl compiled, 1 lines read - 467 bytes written, 13 ms yes | ?- list_member(b,[a,b,c]). true ? yes | ?- list_member(b,[a,[b,c]]). no | ?- list_member([b,c],[a,[b,c]]). true ? yes | ?- list_member(d,[a,b,c]). no | ?- list_member(d,[a,b,c]).
長度計算
這用於查詢列表 L 的長度。我們將定義一個謂詞來執行此任務。假設謂詞名稱為 list_length(L,N)。它將 L 和 N 作為輸入引數。這將計算列表 L 中的元素並將 N 例項化為它們的個數。與我們之前涉及列表的關係一樣,考慮兩種情況很有用:
如果列表為空,則長度為 0。
如果列表不為空,則 L = [Head|Tail],則其長度為 1 + 尾部的長度。
程式
list_length([],0). list_length([_|TAIL],N) :- list_length(TAIL,N1), N is N1 + 1.
輸出
| ?- [list_basics]. compiling D:/TP Prolog/Sample_Codes/list_basics.pl for byte code... D:/TP Prolog/Sample_Codes/list_basics.pl compiled, 4 lines read - 985 bytes written, 23 ms yes | ?- list_length([a,b,c,d,e,f,g,h,i,j],Len). Len = 10 yes | ?- list_length([],Len). Len = 0 yes | ?- list_length([[a,b],[c,d],[e,f]],Len). Len = 3 yes | ?-
連線
兩個列表的連線意味著在第一個列表之後新增第二個列表的列表項。因此,如果兩個列表是 [a,b,c] 和 [1,2],則最終列表將是 [a,b,c,1,2]。因此,要執行此任務,我們將建立一個名為 list_concat() 的謂詞,它將第一個列表 L1、第二個列表 L2 和 L3 作為結果列表。這裡有兩個觀察結果。
如果第一個列表為空,而第二個列表是 L,則結果列表將是 L。
如果第一個列表不為空,則將其寫為 [Head|Tail],遞迴地將 Tail 與 L2 連線起來,並以 [Head|New List] 的形式將其儲存到新列表中。
程式
list_concat([],L,L). list_concat([X1|L1],L2,[X1|L3]) :- list_concat(L1,L2,L3).
輸出
| ?- [list_basics]. compiling D:/TP Prolog/Sample_Codes/list_basics.pl for byte code... D:/TP Prolog/Sample_Codes/list_basics.pl compiled, 7 lines read - 1367 bytes written, 19 ms yes | ?- list_concat([1,2],[a,b,c],NewList). NewList = [1,2,a,b,c] yes | ?- list_concat([],[a,b,c],NewList). NewList = [a,b,c] yes | ?- list_concat([[1,2,3],[p,q,r]],[a,b,c],NewList). NewList = [[1,2,3],[p,q,r],a,b,c] yes | ?-
從列表中刪除
假設我們有一個列表 L 和一個元素 X,我們必須從 L 中刪除 X。因此有三種情況:
如果 X 是唯一的元素,則刪除它後,它將返回空列表。
如果 X 是 L 的頭部,則結果列表將是尾部。
如果 X 存在於尾部,則從那裡遞迴刪除。
程式
list_delete(X, [X], []). list_delete(X,[X|L1], L1). list_delete(X, [Y|L2], [Y|L1]) :- list_delete(X,L2,L1).
輸出
| ?- [list_basics]. compiling D:/TP Prolog/Sample_Codes/list_basics.pl for byte code... D:/TP Prolog/Sample_Codes/list_basics.pl compiled, 11 lines read - 1923 bytes written, 25 ms yes | ?- list_delete(a,[a,e,i,o,u],NewList). NewList = [e,i,o,u] ? yes | ?- list_delete(a,[a],NewList). NewList = [] ? yes | ?- list_delete(X,[a,e,i,o,u],[a,e,o,u]). X = i ? ; no | ?-
追加到列表
追加兩個列表意味著將兩個列表加在一起,或者將一個列表新增為一項。現在,如果該項存在於列表中,則追加函式將不起作用。因此,我們將建立一個名為 list_append(L1, L2, L3) 的謂詞。以下是一些觀察結果:
令 A 為一個元素,L1 為一個列表,當 L1 已經包含 A 時,輸出也將是 L1。
否則,新列表將是 L2 = [A|L1]。
程式
list_member(X,[X|_]). list_member(X,[_|TAIL]) :- list_member(X,TAIL). list_append(A,T,T) :- list_member(A,T),!. list_append(A,T,[A|T]).
在這種情況下,我們使用了 (!) 符號,它被稱為剪下。因此,當第一行成功執行時,我們將對其進行剪下,因此它將不會執行下一個操作。
輸出
| ?- [list_basics]. compiling D:/TP Prolog/Sample_Codes/list_basics.pl for byte code... D:/TP Prolog/Sample_Codes/list_basics.pl compiled, 14 lines read - 2334 bytes written, 25 ms (16 ms) yes | ?- list_append(a,[e,i,o,u],NewList). NewList = [a,e,i,o,u] yes | ?- list_append(e,[e,i,o,u],NewList). NewList = [e,i,o,u] yes | ?- list_append([a,b],[e,i,o,u],NewList). NewList = [[a,b],e,i,o,u] yes | ?-
插入到列表
此方法用於將專案 X 插入到列表 L 中,結果列表將是 R。因此,謂詞將採用此形式 list_insert(X, L, R)。因此,這可以將 X 插入到 L 的所有可能位置。如果我們仔細觀察,則會有一些觀察結果。
如果我們執行 list_insert(X,L,R),我們可以使用 list_delete(X,R,L),因此從 R 中刪除 X 並建立新的列表 L。
程式
list_delete(X, [X], []). list_delete(X,[X|L1], L1). list_delete(X, [Y|L2], [Y|L1]) :- list_delete(X,L2,L1). list_insert(X,L,R) :- list_delete(X,R,L).
輸出
| ?- [list_basics]. compiling D:/TP Prolog/Sample_Codes/list_basics.pl for byte code... D:/TP Prolog/Sample_Codes/list_basics.pl compiled, 16 lines read - 2558 bytes written, 22 ms (16 ms) yes | ?- list_insert(a,[e,i,o,u],NewList). NewList = [a,e,i,o,u] ? a NewList = [e,a,i,o,u] NewList = [e,i,a,o,u] NewList = [e,i,o,a,u] NewList = [e,i,o,u,a] NewList = [e,i,o,u,a] (15 ms) no | ?-
列表項的重新定位操作
以下是重新定位操作:
| 重新定位操作 | 定義 |
|---|---|
| 排列 | 此操作將更改列表項的位置並生成所有可能的結果。 |
| 反轉專案 | 此操作將列表的專案按反向順序排列。 |
| 移位專案 | 此操作將列表中的一個元素向左迴圈移動。 |
| 順序項 | 此操作驗證給定列表是否已排序。 |
排列操作
此操作將更改列表項的位置並生成所有可能的結果。因此,我們將建立一個謂詞 list_perm(L1,L2),這將生成 L1 的所有排列,並將它們儲存到 L2 中。為此,我們需要 list_delete() 子句來幫助。
為了設計這個謂詞,我們可以遵循以下一些觀察結果:
如果 X 是 L 的成員,則:
如果第一個列表為空,則第二個列表也必須為空。
如果第一個列表不為空,則它具有形式 [X | L],並且可以如下構造此類列表的排列:首先排列 L 得到 L1,然後將 X 插入到 L1 的任何位置。
程式
list_delete(X,[X|L1], L1). list_delete(X, [Y|L2], [Y|L1]) :- list_delete(X,L2,L1). list_perm([],[]). list_perm(L,[X|P]) :- list_delete(X,L,L1),list_perm(L1,P).
輸出
| ?- [list_repos]. compiling D:/TP Prolog/Sample_Codes/list_repos.pl for byte code... D:/TP Prolog/Sample_Codes/list_repos.pl compiled, 4 lines read - 1060 bytes written, 17 ms (15 ms) yes | ?- list_perm([a,b,c,d],X). X = [a,b,c,d] ? a X = [a,b,d,c] X = [a,c,b,d] X = [a,c,d,b] X = [a,d,b,c] X = [a,d,c,b] X = [b,a,c,d] X = [b,a,d,c] X = [b,c,a,d] X = [b,c,d,a] X = [b,d,a,c] X = [b,d,c,a] X = [c,a,b,d] X = [c,a,d,b] X = [c,b,a,d] X = [c,b,d,a] X = [c,d,a,b] X = [c,d,b,a] X = [d,a,b,c] X = [d,a,c,b] X = [d,b,a,c] X = [d,b,c,a] X = [d,c,a,b] X = [d,c,b,a] (31 ms) no | ?-
反轉操作
假設我們有一個列表 L = [a,b,c,d,e],我們想要反轉元素,則輸出將為 [e,d,c,b,a]。為此,我們將建立一個子句 list_reverse(List, ReversedList)。以下是一些觀察結果:
如果列表為空,則結果列表也將為空。
否則,將列表項命名為 [Head|Tail],遞迴反轉 Tail 項,並與 Head 連線。
否則,將列表項命名為 [Head|Tail],遞迴反轉 Tail 項,並與 Head 連線。
程式
list_concat([],L,L). list_concat([X1|L1],L2,[X1|L3]) :- list_concat(L1,L2,L3). list_rev([],[]). list_rev([Head|Tail],Reversed) :- list_rev(Tail, RevTail),list_concat(RevTail, [Head],Reversed).
輸出
| ?- [list_repos]. compiling D:/TP Prolog/Sample_Codes/list_repos.pl for byte code... D:/TP Prolog/Sample_Codes/list_repos.pl compiled, 10 lines read - 1977 bytes written, 19 ms yes | ?- list_rev([a,b,c,d,e],NewList). NewList = [e,d,c,b,a] yes | ?- list_rev([a,b,c,d,e],[e,d,c,b,a]). yes | ?-
移位操作
使用移位操作,我們可以將列表的一個元素向左迴圈移動。因此,如果列表項為 [a,b,c,d],則移位後將為 [b,c,d,a]。因此,我們將建立一個子句 list_shift(L1, L2)。
我們將列表表示為 [Head|Tail],然後遞迴地將 Head 連線到 Tail 之後,因此我們可以感覺到元素被移動了。
這也可以用來檢查兩個列表是否在一個位置移位。
程式
list_concat([],L,L). list_concat([X1|L1],L2,[X1|L3]) :- list_concat(L1,L2,L3). list_shift([Head|Tail],Shifted) :- list_concat(Tail, [Head],Shifted).
輸出
| ?- [list_repos]. compiling D:/TP Prolog/Sample_Codes/list_repos.pl for byte code... D:/TP Prolog/Sample_Codes/list_repos.pl compiled, 12 lines read - 2287 bytes written, 10 ms yes | ?- list_shift([a,b,c,d,e],L2). L2 = [b,c,d,e,a] (16 ms) yes | ?- list_shift([a,b,c,d,e],[b,c,d,e,a]). yes | ?-
排序操作
在這裡,我們將定義一個謂詞 list_order(L),它檢查 L 是否已排序。因此,如果 L = [1,2,3,4,5,6],則結果為真。
如果只有一個元素,則該元素已排序。
否則,將前兩個元素 X 和 Y 作為 Head,其餘作為 Tail。如果 X <= Y,則再次呼叫該子句,引數為 [Y|Tail],因此這將遞迴地從下一個元素開始檢查。
程式
list_order([X, Y | Tail]) :- X =< Y, list_order([Y|Tail]). list_order([X]).
輸出
| ?- [list_repos]. compiling D:/TP Prolog/Sample_Codes/list_repos.pl for byte code... D:/TP Prolog/Sample_Codes/list_repos.pl:15: warning: singleton variables [X] for list_order/1 D:/TP Prolog/Sample_Codes/list_repos.pl compiled, 15 lines read - 2805 bytes written, 18 ms yes | ?- list_order([1,2,3,4,5,6,6,7,7,8]). true ? yes | ?- list_order([1,4,2,3,6,5]). no | ?-
列表上的集合操作
我們將嘗試編寫一個子句,該子句將獲取給定集合的所有可能的子集。因此,如果集合是 [a,b],則結果將為 [],[a],[b],[a,b]。為此,我們將建立一個子句 list_subset(L, X)。它將獲取 L 並將每個子集返回到 X 中。因此,我們將按以下方式進行:
如果列表為空,則子集也為空。
透過保留 Head 遞迴地查詢子集,並且
進行另一個遞迴呼叫,我們將刪除 Head。
程式
list_subset([],[]). list_subset([Head|Tail],[Head|Subset]) :- list_subset(Tail,Subset). list_subset([Head|Tail],Subset) :- list_subset(Tail,Subset).
輸出
| ?- [list_set]. compiling D:/TP Prolog/Sample_Codes/list_set.pl for byte code... D:/TP Prolog/Sample_Codes/list_set.pl:3: warning: singleton variables [Head] for list_subset/2 D:/TP Prolog/Sample_Codes/list_set.pl compiled, 2 lines read - 653 bytes written, 7 ms yes | ?- list_subset([a,b],X). X = [a,b] ? ; X = [a] ? ; X = [b] ? ; X = [] (15 ms) yes | ?- list_subset([x,y,z],X). X = [x,y,z] ? a X = [x,y] X = [x,z] X = [x] X = [y,z] X = [y] X = [z] X = [] yes | ?-
並集操作
讓我們定義一個名為 list_union(L1,L2,L3) 的子句,因此這將獲取 L1 和 L2,並對它們執行並集,並將結果儲存到 L3 中。正如您所知,如果兩個列表具有相同的元素兩次,則並集後將只有一個。因此,我們需要另一個輔助子句來檢查成員資格。
程式
list_member(X,[X|_]). list_member(X,[_|TAIL]) :- list_member(X,TAIL). list_union([X|Y],Z,W) :- list_member(X,Z),list_union(Y,Z,W). list_union([X|Y],Z,[X|W]) :- \+ list_member(X,Z), list_union(Y,Z,W). list_union([],Z,Z).
注意 - 在程式中,我們使用了 (\+) 運算子,此運算子用於表示非。
輸出
| ?- [list_set]. compiling D:/TP Prolog/Sample_Codes/list_set.pl for byte code... D:/TP Prolog/Sample_Codes/list_set.pl:6: warning: singleton variables [Head] for list_subset/2 D:/TP Prolog/Sample_Codes/list_set.pl compiled, 9 lines read - 2004 bytes written, 18 ms yes | ?- list_union([a,b,c,d,e],[a,e,i,o,u],L3). L3 = [b,c,d,a,e,i,o,u] ? (16 ms) yes | ?- list_union([a,b,c,d,e],[1,2],L3). L3 = [a,b,c,d,e,1,2] yes
交集操作
讓我們定義一個名為 list_intersection(L1,L2,L3) 的子句,因此這將獲取 L1 和 L2,並執行交集運算,並將結果儲存到 L3 中。交集將返回同時存在於兩個列表中的元素。因此,如果 L1 = [a,b,c,d,e],L2 = [a,e,i,o,u],則 L3 = [a,e]。在這裡,我們將使用 list_member() 子句來檢查一個元素是否存在於列表中。
程式
list_member(X,[X|_]). list_member(X,[_|TAIL]) :- list_member(X,TAIL). list_intersect([X|Y],Z,[X|W]) :- list_member(X,Z), list_intersect(Y,Z,W). list_intersect([X|Y],Z,W) :- \+ list_member(X,Z), list_intersect(Y,Z,W). list_intersect([],Z,[]).
輸出
| ?- [list_set]. compiling D:/TP Prolog/Sample_Codes/list_set.pl for byte code... D:/TP Prolog/Sample_Codes/list_set.pl compiled, 13 lines read - 3054 bytes written, 9 ms (15 ms) yes | ?- list_intersect([a,b,c,d,e],[a,e,i,o,u],L3). L3 = [a,e] ? yes | ?- list_intersect([a,b,c,d,e],[],L3). L3 = [] yes | ?-
列表上的雜項操作
以下是可以在列表上執行的一些雜項操作:
| 雜項操作 | 定義 |
|---|---|
| 查詢奇數和偶數長度 | 驗證列表是否具有奇數或偶數個元素。 |
| 劃分 | 將列表分成兩個列表,並且這些列表的長度大致相同。 |
| 最大值 | 從給定列表中檢索具有最大值的元素。 |
| Sum | 返回給定列表中元素的總和。 |
| 歸併排序 | 按順序排列給定列表的元素(使用歸併排序演算法)。 |
奇數和偶數長度操作
在這個例子中,我們將看到兩個操作,我們可以使用它們來檢查列表是否具有奇數個元素或偶數個元素。我們將定義謂詞 list_even_len(L) 和 list_odd_len(L)。
如果列表沒有元素,則它是偶數長度的列表。
否則,我們將它視為 [Head|Tail],如果 Tail 的長度為奇數,則整個列表是偶數長度的字串。
同樣,如果列表只有一個元素,則它是奇數長度的列表。
將其視為 [Head|Tail],如果 Tail 是偶數長度的字串,則整個列表是奇數長度的列表。
程式
list_even_len([]). list_even_len([Head|Tail]) :- list_odd_len(Tail). list_odd_len([_]). list_odd_len([Head|Tail]) :- list_even_len(Tail).
輸出
| ?- [list_misc]. compiling D:/TP Prolog/Sample_Codes/list_misc.pl for byte code... D:/TP Prolog/Sample_Codes/list_misc.pl:2: warning: singleton variables [Head] for list_even_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl:5: warning: singleton variables [Head] for list_odd_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl compiled, 4 lines read - 726 bytes written, 20 ms yes | ?- list_odd_len([a,2,b,3,c]). true ? yes | ?- list_odd_len([a,2,b,3]). no | ?- list_even_len([a,2,b,3]). true ? yes | ?- list_even_len([a,2,b,3,c]). no | ?-
劃分列表操作
此操作將列表分成兩個列表,並且這些列表的長度大致相同。因此,如果給定列表為 [a,b,c,d,e],則結果將為 [a,c,e],[b,d]。這會將所有奇數位置的元素放入一個列表中,並將所有偶數位置的元素放入另一個列表中。我們將定義謂詞 list_divide(L1,L2,L3) 來解決此任務。
如果給定列表為空,則它將返回空列表。
如果只有一個元素,則第一個列表將是包含該元素的列表,而第二個列表將為空。
假設 X、Y 是來自頭部(Head)的兩個元素,其餘為 Tail,所以建立兩個列表 [X|List1],[Y|List2],這些 List1 和 List2 透過劃分 Tail 分隔。
程式
list_divide([],[],[]). list_divide([X],[X],[]). list_divide([X,Y|Tail], [X|List1],[Y|List2]) :- list_divide(Tail,List1,List2).
輸出
| ?- [list_misc]. compiling D:/TP Prolog/Sample_Codes/list_misc.pl for byte code... D:/TP Prolog/Sample_Codes/list_misc.pl:2: warning: singleton variables [Head] for list_even_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl:5: warning: singleton variables [Head] for list_odd_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl compiled, 8 lines read - 1432 bytes written, 8 ms yes | ?- list_divide([a,1,b,2,c,3,d,5,e],L1,L2). L1 = [a,b,c,d,e] L2 = [1,2,3,5] ? yes | ?- list_divide([a,b,c,d],L1,L2). L1 = [a,c] L2 = [b,d] yes | ?-
最大項操作
此操作用於從列表中查詢最大元素。我們將定義一個謂詞 list_max_elem(List, Max),然後這將從列表中查詢 Max 元素並返回。
如果只有一個元素,則它將是最大元素。
將列表劃分為 [X,Y|Tail]。現在遞迴地查詢 [Y|Tail] 的最大值並將其儲存到 MaxRest 中,並將 X 和 MaxRest 的最大值儲存,然後將其儲存到 Max 中。
程式
max_of_two(X,Y,X) :- X >= Y. max_of_two(X,Y,Y) :- X < Y. list_max_elem([X],X). list_max_elem([X,Y|Rest],Max) :- list_max_elem([Y|Rest],MaxRest), max_of_two(X,MaxRest,Max).
輸出
| ?- [list_misc]. compiling D:/TP Prolog/Sample_Codes/list_misc.pl for byte code... D:/TP Prolog/Sample_Codes/list_misc.pl:2: warning: singleton variables [Head] for list_even_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl:5: warning: singleton variables [Head] for list_odd_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl compiled, 16 lines read - 2385 bytes written, 16 ms yes | ?- list_max_elem([8,5,3,4,7,9,6,1],Max). Max = 9 ? yes | ?- list_max_elem([5,12,69,112,48,4],Max). Max = 112 ? yes | ?-
列表求和操作
在這個例子中,我們將定義一個子句 list_sum(List, Sum),這將返回列表中元素的總和。
如果列表為空,則總和為 0。
將列表表示為 [Head|Tail],遞迴查詢尾部的總和並將其儲存到 SumTemp 中,然後設定 Sum = Head + SumTemp。
程式
list_sum([],0). list_sum([Head|Tail], Sum) :- list_sum(Tail,SumTemp), Sum is Head + SumTemp.
輸出
yes | ?- [list_misc]. compiling D:/TP Prolog/Sample_Codes/list_misc.pl for byte code... D:/TP Prolog/Sample_Codes/list_misc.pl:2: warning: singleton variables [Head] for list_even_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl:5: warning: singleton variables [Head] for list_odd_len/1 D:/TP Prolog/Sample_Codes/list_misc.pl compiled, 21 lines read - 2897 bytes written, 21 ms (32 ms) yes | ?- list_sum([5,12,69,112,48,4],Sum). Sum = 250 yes | ?- list_sum([8,5,3,4,7,9,6,1],Sum). Sum = 43 yes | ?-
列表歸併排序
如果列表是 [4,5,3,7,8,1,2],則結果將是 [1,2,3,4,5,7,8]。執行歸併排序的步驟如下:
獲取列表並將其拆分為兩個子列表。此拆分將遞迴執行。
以排序順序合併每個拆分。
因此,整個列表將被排序。
我們將定義一個名為 mergesort(L, SL) 的謂詞,它將獲取 L 並將結果返回到 SL 中。
程式
mergesort([],[]). /* covers special case */ mergesort([A],[A]). mergesort([A,B|R],S) :- split([A,B|R],L1,L2), mergesort(L1,S1), mergesort(L2,S2), merge(S1,S2,S). split([],[],[]). split([A],[A],[]). split([A,B|R],[A|Ra],[B|Rb]) :- split(R,Ra,Rb). merge(A,[],A). merge([],B,B). merge([A|Ra],[B|Rb],[A|M]) :- A =< B, merge(Ra,[B|Rb],M). merge([A|Ra],[B|Rb],[B|M]) :- A > B, merge([A|Ra],Rb,M).
輸出
| ?- [merge_sort]. compiling D:/TP Prolog/Sample_Codes/merge_sort.pl for byte code... D:/TP Prolog/Sample_Codes/merge_sort.pl compiled, 17 lines read - 3048 bytes written, 19 ms yes | ?- mergesort([4,5,3,7,8,1,2],L). L = [1,2,3,4,5,7,8] ? yes | ?- mergesort([8,5,3,4,7,9,6,1],L). L = [1,3,4,5,6,7,8,9] ? yes | ?-
Prolog - 遞迴和結構
本章涵蓋遞迴和結構。
遞迴
遞迴是一種技術,其中一個謂詞使用自身(可能與其他一些謂詞一起)來查詢真值。
讓我們透過一個例子來理解這個定義:
is_digesting(X,Y) :- just_ate(X,Y).
is_digesting(X,Y) :-just_ate(X,Z),is_digesting(Z,Y).
因此,這個謂詞本質上是遞迴的。假設我們說 *just_ate(deer, grass)*,這意味著 *is_digesting(deer, grass)* 為真。現在如果我們說 *is_digesting(tiger, grass)*,如果 *is_digesting(tiger, grass)* :- *just_ate(tiger, deer), is_digesting(deer, grass)*,則語句 *is_digesting(tiger, grass)* 也為真。
可能還有一些其他的例子,所以讓我們來看一個家庭的例子。如果我們想表達前驅邏輯,可以使用以下圖表來表達:
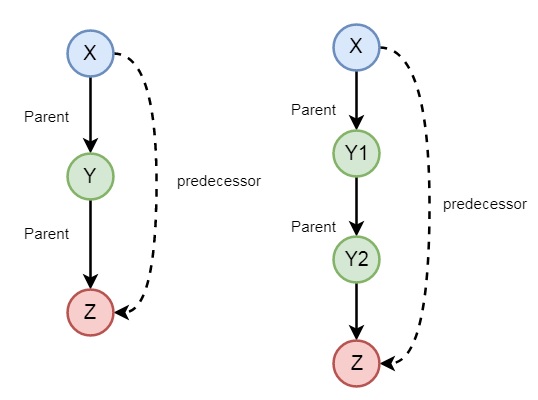
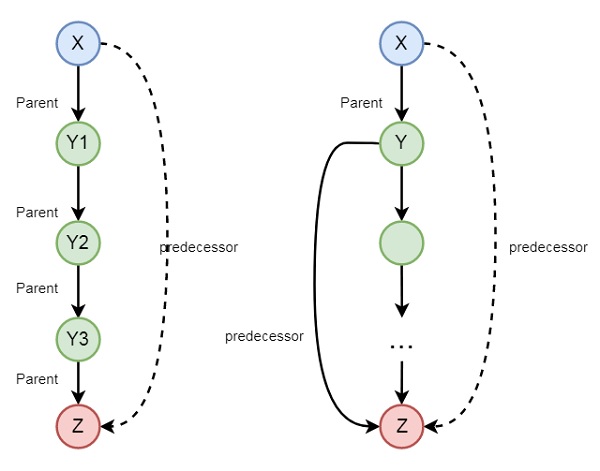
所以我們可以理解前驅關係是遞迴的。我們可以使用以下語法表達這種關係:
predecessor(X, Z) :- parent(X, Z).
predecessor(X, Z) :- parent(X, Y),predecessor(Y, Z).
結構
結構是包含多個元件的資料物件。
例如,日期可以看作是一個具有三個元件的結構——日、月和年。那麼 2020 年 4 月 9 日可以寫成:date(9, apr, 2020)。
注意 - 結構本身可以包含另一個結構作為其元件。
因此,我們可以將檢視視為樹形結構和Prolog 函式符。
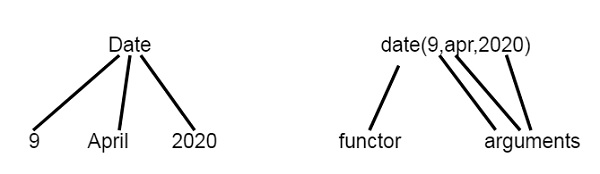
現在讓我們來看一個 Prolog 中結構的例子。我們將定義點、線段和三角形作為結構的結構。
為了用 Prolog 中的結構表示點、線段和三角形,我們可以考慮以下語句:
p1 - point(1, 1)
p2 - point(2,3)
S - seg( Pl, P2): seg( point(1,1), point(2,3))
T - triangle( point(4,Z), point(6,4), point(7,1) )
注意 - 結構可以自然地描繪成樹。Prolog 可以被視為一種用於處理樹的語言。
Prolog 中的匹配
匹配用於檢查兩個給定項是否相同(相同)或者兩個項中的變數在被例項化後是否可以具有相同的物件。讓我們來看一個例子。
假設日期結構定義為 date(D,M,2020) = date(D1,apr, Y1),這表示 D = D1,M = feb 並且 Y1 = 2020。
以下規則用於檢查兩個項 S 和 T 是否匹配:
如果 S 和 T 是常量,如果兩者是相同的物件,則 S=T。
如果 S 是變數,而 T 是任何東西,則 T=S。
如果 T 是變數,而 S 是任何東西,則 S=T。
如果 S 和 T 是結構,則 S=T 如果:
S 和 T 具有相同的函式符。
所有對應的引數元件都必須匹配。
二叉樹
以下是使用遞迴結構的二叉樹結構:
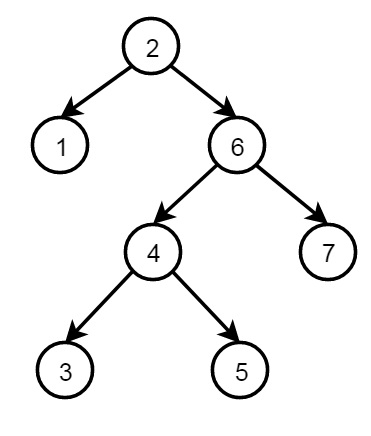
結構的定義如下:
node(2, node(1,nil,nil), node(6, node(4,node(3,nil,nil), node(5,nil,nil)), node(7,nil,nil))
每個節點都有三個欄位,資料和兩個節點。一個沒有子節點(葉節點)的節點結構寫為 node(value, nil, nil),只有一個左子節點的節點寫為 node(value, left_node, nil),只有一個右子節點的節點寫為 node(value, nil; right_node),並且具有兩個子節點的節點具有 node(value, left_node, right_node)。
Prolog - 回溯
在本章中,我們將討論 Prolog 中的回溯。回溯是一個過程,其中 Prolog 透過檢查謂詞是否正確來搜尋不同謂詞的真值。回溯這個術語在演算法設計和不同的程式設計環境中非常常見。在 Prolog 中,直到到達正確的目的地,它才會嘗試回溯。找到目的地後,它會停止。
讓我們看看使用樹狀結構回溯是如何發生的:
假設 A 到 G 是某些規則和事實。我們從 A 開始,想到達 G。正確的路徑將是 A-C-G,但首先,它將從 A 到 B,然後從 B 到 D。當它發現 D 不是目的地時,它回溯到 B,然後到 E,然後再次回溯到 B,因為 B 沒有其他子節點,然後它回溯到 A,因此它搜尋 G,最終在路徑 A-C-G 中找到 G。(虛線表示回溯。)所以當它找到 G 時,它就停止了。
回溯是如何工作的?
現在我們知道了 Prolog 中的回溯是什麼。讓我們來看一個例子,
注意 - 當我們執行一些 Prolog 程式碼時,在回溯過程中可能會有多個答案,我們可以按分號(;)來一個一個地獲取下一個答案,這有助於回溯。否則,當我們得到一個結果時,它將停止。
現在,考慮一種情況,兩個人 X 和 Y 可以互相支付,但條件是一個男孩可以支付給一個女孩,所以 X 將是一個男孩,而 Y 將是一個女孩。因此,我們為此定義了一些事實和規則:
知識庫
boy(tom). boy(bob). girl(alice). girl(lili). pay(X,Y) :- boy(X), girl(Y).
以下是上述場景的圖示:
由於 X 將是一個男孩,所以有兩個選擇,對於每個男孩,都有兩個選擇 alice 和 lili。現在讓我們看看輸出,回溯是如何工作的。
輸出
| ?- [backtrack].
compiling D:/TP Prolog/Sample_Codes/backtrack.pl for byte code...
D:/TP Prolog/Sample_Codes/backtrack.pl compiled, 5 lines read - 703 bytes written, 22 ms
yes
| ?- pay(X,Y).
X = tom
Y = alice ?
(15 ms) yes
| ?- pay(X,Y).
X = tom
Y = alice ? ;
X = tom
Y = lili ? ;
X = bob
Y = alice ? ;
X = bob
Y = lili
yes
| ?- trace.
The debugger will first creep -- showing everything (trace)
(16 ms) yes
{trace}
| ?- pay(X,Y).
1 1 Call: pay(_23,_24) ?
2 2 Call: boy(_23) ?
2 2 Exit: boy(tom) ?
3 2 Call: girl(_24) ?
3 2 Exit: girl(alice) ?
1 1 Exit: pay(tom,alice) ?
X = tom
Y = alice ? ;
1 1 Redo: pay(tom,alice) ?
3 2 Redo: girl(alice) ?
3 2 Exit: girl(lili) ?
1 1 Exit: pay(tom,lili) ?
X = tom
Y = lili ? ;
1 1 Redo: pay(tom,lili) ?
2 2 Redo: boy(tom) ?
2 2 Exit: boy(bob) ?
3 2 Call: girl(_24) ?
3 2 Exit: girl(alice) ?
1 1 Exit: pay(bob,alice) ?
X = bob
Y = alice ? ;
1 1 Redo: pay(bob,alice) ?
3 2 Redo: girl(alice) ?
3 2 Exit: girl(lili) ?
1 1 Exit: pay(bob,lili) ?
X = bob
Y = lili
yes
{trace}
| ?-
防止回溯
到目前為止,我們已經瞭解了一些回溯的概念。現在讓我們看看回溯的一些缺點。有時,當我們的程式需要時,我們會多次編寫相同的謂詞,例如編寫遞迴規則或製作一些決策系統。在這種情況下,不受控制的回溯可能會導致程式效率低下。為了解決這個問題,我們將使用Prolog中的剪枝。
假設我們有一些如下所示的規則:
雙步函式
規則 1 &minnus; 如果 X < 3,則 Y = 0
規則 2 &minnus; 如果 3 <= X 且 X < 6,則 Y = 2
規則 3 &minnus; 如果 6 <= X,則 Y = 4
在Prolog語法中,我們可以這樣寫:
f(X,0) :- X < 3. % 規則 1
f(X,2) :- 3 =< X, X < 6. % 規則 2
f(X,4) :- 6 =< X. % 規則 3
現在,如果我們提出一個問題,例如 f(1,Y), 2 < Y。
第一個目標 f(1,Y) 將 Y 例項化為 0。第二個目標變為 2 < 0,這將失敗。Prolog 透過回溯嘗試了兩個無結果的替代方案(規則 2 和規則 3)。如果我們仔細觀察,我們可以發現:
這三個規則是互斥的,最多隻有一個會成功。
一旦其中一個成功,就沒有必要嘗試使用其他的,因為它們註定會失敗。
所以我們可以使用剪枝來解決這個問題。剪枝可以用感嘆號表示。Prolog語法如下:
f(X,0) :- X < 3, !. % 規則 1
f(X,2) :- 3 =< X, X < 6, !. % 規則 2
f(X,4) :- 6 =< X. % 規則 3
現在,如果我們使用相同的問題,?- f(1,Y), 2 < Y。Prolog 選擇規則 1,因為 1 < 3,並且目標 2 < Y 失敗。Prolog 將嘗試回溯,但不會超出程式中標記為 ! 的點,規則 2 和規則 3 將不會被生成。
讓我們在下面的執行中看到這一點:
程式
f(X,0) :- X < 3. % Rule 1 f(X,2) :- 3 =< X, X < 6. % Rule 2 f(X,4) :- 6 =< X. % Rule 3
輸出
| ?- [backtrack].
compiling D:/TP Prolog/Sample_Codes/backtrack.pl for byte code...
D:/TP Prolog/Sample_Codes/backtrack.pl compiled, 10 lines read - 1224 bytes written, 17 ms
yes
| ?- f(1,Y), 2<Y.
no
| ?- trace
.
The debugger will first creep -- showing everything (trace)
yes
{trace}
| ?- f(1,Y), 2<Y.
1 1 Call: f(1,_23) ?
2 2 Call: 1<3 ?
2 2 Exit: 1<3 ?
1 1 Exit: f(1,0) ?
3 1 Call: 2<0 ?
3 1 Fail: 2<0 ?
1 1 Redo: f(1,0) ?
2 2 Call: 3=<1 ?
2 2 Fail: 3=<1 ?
2 2 Call: 6=<1 ?
2 2 Fail: 6=<1 ?
1 1 Fail: f(1,_23) ?
(46 ms) no
{trace}
| ?-
讓我們看看使用剪枝的相同情況。
程式
f(X,0) :- X < 3,!. % Rule 1 f(X,2) :- 3 =< X, X < 6,!. % Rule 2 f(X,4) :- 6 =< X. % Rule 3
輸出
| ?- [backtrack].
1 1 Call: [backtrack] ?
compiling D:/TP Prolog/Sample_Codes/backtrack.pl for byte code...
D:/TP Prolog/Sample_Codes/backtrack.pl compiled, 10 lines read - 1373 bytes written, 15 ms
1 1 Exit: [backtrack] ?
(16 ms) yes
{trace}
| ?- f(1,Y), 2<Y.
1 1 Call: f(1,_23) ?
2 2 Call: 1<3 ?
2 2 Exit: 1<3 ?
1 1 Exit: f(1,0) ?
3 1 Call: 2<0 ?
3 1 Fail: 2<0 ?
no
{trace}
| ?-
失敗即否定
在這裡,當條件不滿足時,我們將執行失敗。假設我們有一句話:“瑪麗喜歡所有動物,除了蛇”,我們將用Prolog來表達這句話。
如果語句是“瑪麗喜歡所有動物”,那就很容易直接表達了。在這種情況下,我們可以寫“如果X是動物,瑪麗喜歡X”。在Prolog中,我們可以將此語句寫成:likes(mary, X) := animal(X)。
我們的實際語句可以表達為:
如果X是蛇,“瑪麗喜歡X”為假
否則,如果X是動物,則瑪麗喜歡X。
在Prolog中,我們可以這樣寫:
likes(mary,X) :- snake(X), !, fail.
likes(mary, X) :- animal(X).
‘fail’語句會導致失敗。現在讓我們看看它如何在Prolog中工作。
程式
animal(dog). animal(cat). animal(elephant). animal(tiger). animal(cobra). animal(python). snake(cobra). snake(python). likes(mary, X) :- snake(X), !, fail. likes(mary, X) :- animal(X).
輸出
| ?- [negate_fail].
compiling D:/TP Prolog/Sample_Codes/negate_fail.pl for byte code...
D:/TP Prolog/Sample_Codes/negate_fail.pl compiled, 11 lines read - 1118 bytes written, 17 ms
yes
| ?- likes(mary,elephant).
yes
| ?- likes(mary,tiger).
yes
| ?- likes(mary,python).
no
| ?- likes(mary,cobra).
no
| ?- trace
.
The debugger will first creep -- showing everything (trace)
yes
{trace}
| ?- likes(mary,dog).
1 1 Call: likes(mary,dog) ?
2 2 Call: snake(dog) ?
2 2 Fail: snake(dog) ?
2 2 Call: animal(dog) ?
2 2 Exit: animal(dog) ?
1 1 Exit: likes(mary,dog) ?
yes
{trace}
| ?- likes(mary,python).
1 1 Call: likes(mary,python) ?
2 2 Call: snake(python) ?
2 2 Exit: snake(python) ?
3 2 Call: fail ?
3 2 Fail: fail ?
1 1 Fail: likes(mary,python) ?
no
{trace}
| ?-
Prolog - 不同與非
在這裡,我們將定義兩個謂詞——different和not。different謂詞將檢查兩個給定的引數是否相同。如果它們相同,它將返回false,否則它將返回true。not謂詞用於否定某個語句,這意味著,當一個語句為真時,not(statement)為假,否則如果語句為假,則not(statement)為真。
因此,“different”可以用三種不同的方式表達,如下所示:
X和Y不是字面上的相同
X和Y不匹配
算術表示式X和Y的值不相等
所以在Prolog中,我們將嘗試將語句表達如下:
如果X和Y匹配,則different(X,Y)失敗;
否則different(X,Y)成功。
相應的Prolog語法如下:
different(X, X) :- !, fail.
different(X, Y).
我們也可以使用析取子句來表達它,如下所示:
different(X, Y) :- X = Y, !, fail ; true. % true是一個總是成功的目標
程式
下面的例子展示瞭如何在Prolog中做到這一點:
different(X, X) :- !, fail. different(X, Y).
輸出
| ?- [diff_rel]. compiling D:/TP Prolog/Sample_Codes/diff_rel.pl for byte code... D:/TP Prolog/Sample_Codes/diff_rel.pl:2: warning: singleton variables [X,Y] for different/2 D:/TP Prolog/Sample_Codes/diff_rel.pl compiled, 2 lines read - 327 bytes written, 11 ms yes | ?- different(100,200). yes | ?- different(100,100). no | ?- different(abc,def). yes | ?- different(abc,abc). no | ?-
讓我們看看一個使用析取子句的程式:
程式
different(X, Y) :- X = Y, !, fail ; true.
輸出
| ?- [diff_rel]. compiling D:/TP Prolog/Sample_Codes/diff_rel.pl for byte code... D:/TP Prolog/Sample_Codes/diff_rel.pl compiled, 0 lines read - 556 bytes written, 17 ms yes | ?- different(100,200). yes | ?- different(100,100). no | ?- different(abc,def). yes | ?- different(abc,abc). no | ?-
Prolog中的否定關係
not關係在不同的情況下非常有用。在我們傳統的程式語言中,我們也使用邏輯非運算來否定某個語句。這意味著,當一個語句為真時,not(statement)為假,否則如果語句為假,則not(statement)為真。
在Prolog中,我們可以定義如下:
not(P) :- P, !, fail ; true.
所以如果P為真,則剪枝並失敗,這將返回false,否則將返回true。現在讓我們看一段簡單的程式碼來理解這個概念。
程式
not(P) :- P, !, fail ; true.
輸出
| ?- [not_rel]. compiling D:/TP Prolog/Sample_Codes/not_rel.pl for byte code... D:/TP Prolog/Sample_Codes/not_rel.pl compiled, 0 lines read - 630 bytes written, 17 ms yes | ?- not(true). no | ?- not(fail). yes | ?-
Prolog - 輸入和輸出
在本章中,我們將瞭解一些透過Prolog處理輸入和輸出的技術。我們將使用一些內建謂詞來完成這些任務,並將看到檔案處理技術。
我們將詳細討論以下主題:
處理輸入和輸出
使用Prolog進行檔案處理
使用一些外部檔案來讀取行和項
用於輸入和輸出的字元操作
構造和分解原子
將Prolog檔案匯入其他Prolog程式的技術。
處理輸入和輸出
到目前為止,我們已經看到我們可以編寫一個程式和控制檯上的查詢來執行。在某些情況下,我們在控制檯上列印一些內容,這些內容寫在我們的Prolog程式碼中。所以在這裡我們將更詳細地看到Prolog中讀寫任務。這將是輸入和輸出處理技術。
write()謂詞
要寫入輸出,我們可以使用write()謂詞。此謂詞將引數作為輸入,並預設將內容寫入控制檯。write()也可以寫入檔案。讓我們看看write()函式的一些例子。
程式
| ?- write(56).
56
yes
| ?- write('hello').
hello
yes
| ?- write('hello'),nl,write('world').
hello
world
yes
| ?- write("ABCDE")
.
[65,66,67,68,69]
yes
從上面的例子可以看出,write()謂詞可以將內容寫入控制檯。我們可以使用'nl'來建立新行。從這個例子可以看出,如果我們想在控制檯上列印一些字串,我們必須使用單引號('string')。但是如果我們使用雙引號("string"),它將返回ASCII值的列表。
read()謂詞
read()謂詞用於從控制檯讀取。使用者可以在控制檯中寫入一些內容,這些內容可以作為輸入並進行處理。read()通常用於從控制檯讀取,但也可以用於從檔案讀取。現在讓我們看一個例子來了解read()是如何工作的。
程式
cube :-
write('Write a number: '),
read(Number),
process(Number).
process(stop) :- !.
process(Number) :-
C is Number * Number * Number,
write('Cube of '),write(Number),write(': '),write(C),nl, cube.
輸出
| ?- [read_write]. compiling D:/TP Prolog/Sample_Codes/read_write.pl for byte code... D:/TP Prolog/Sample_Codes/read_write.pl compiled, 9 lines read - 1226 bytes written, 12 ms (15 ms) yes | ?- cube. Write a number: 2. Cube of 2: 8 Write a number: 10. Cube of 10: 1000 Write a number: 12. Cube of 12: 1728 Write a number: 8. Cube of 8: 512 Write a number: stop . (31 ms) yes | ?-
tab()謂詞
tab()是可以使用的另一個謂詞,當我們寫一些東西時,它可以新增一些空格。它將一個數字作為引數,並列印那麼多空格。
程式
| ?- write('hello'),tab(15),write('world').
hello world
yes
| ?- write('We'),tab(5),write('will'),tab(5),write('use'),tab(5),write('tabs').
We will use tabs
yes
| ?-
讀取/寫入檔案
在本節中,我們將瞭解如何使用檔案進行讀取和寫入。有一些內建謂詞可以用於從檔案讀取和寫入檔案。
tell和told
如果我們想寫入檔案而不是控制檯,我們可以寫入tell()謂詞。此tell()謂詞將檔名作為引數。如果該檔案不存在,則建立一個新檔案並寫入其中。該檔案將開啟,直到我們寫入told命令。我們可以使用tell()開啟多個檔案。當呼叫told時,所有檔案都將關閉。
Prolog命令
| ?- told('myFile.txt').
uncaught exception: error(existence_error(procedure,told/1),top_level/0)
| ?- told("myFile.txt").
uncaught exception: error(existence_error(procedure,told/1),top_level/0)
| ?- tell('myFile.txt').
yes
| ?- tell('myFile.txt').
yes
| ?- write('Hello World').
yes
| ?- write(' Writing into a file'),tab(5),write('myFile.txt'),nl.
yes
| ?- write("Write some ASCII values").
yes
| ?- told.
yes
| ?-
輸出 (myFile.txt)
Hello World Writing into a file myFile.txt [87,114,105,116,101,32,115,111,109,101,32,65,83,67,73,73,32,118,97,108,117,101,115]
同樣,我們也可以從檔案讀取。讓我們看一些從檔案讀取的例子。
see和seen
當我們想從檔案而不是鍵盤讀取時,我們必須更改當前輸入流。所以我們可以使用see()謂詞。這將接收檔名作為輸入。當讀取操作完成後,我們將使用seen命令。
示例檔案 (sample_predicate.txt)
likes(lili, cat). likes(jhon,dog).
輸出
| ?- see('sample_predicate.txt'),
read(X),
read(Y),
seen,
read(Z).
the_end.
X = end_of_file
Y = end_of_file
Z = the_end
yes
| ?-
所以從這個例子可以看出,使用see()謂詞我們可以從檔案中讀取。現在在使用seen命令後,控制權再次轉移到控制檯。所以最後它從控制檯接收輸入。
處理術語檔案
我們已經瞭解瞭如何讀取檔案的特定內容(幾行)。現在,如果我們想讀取/處理檔案的全部內容,我們需要編寫一個子句來處理檔案(process_file),直到到達檔案的末尾。
程式
process_file :- read(Line), Line \== end_of_file, % when Line is not not end of file, call process. process(Line). process_file :- !. % use cut to stop backtracking process(Line):- %this will print the line into the console write(Line),nl, process_file.
示例檔案 (sample_predicate.txt)
likes(lili, cat). likes(jhon,dog). domestic(dog). domestic(cat).
輸出
| ?- [process_file].
compiling D:/TP Prolog/Sample_Codes/process_file.pl for byte code...
D:/TP Prolog/Sample_Codes/process_file.pl compiled, 9 lines read - 774 bytes written, 23 ms
yes
| ?- see('sample_predicate.txt'), process_file, seen.
likes(lili,cat)
likes(jhon,dog)
domestic(dog)
domestic(cat)
true ?
(15 ms) yes
| ?-
操作字元
使用read()和write(),我們可以讀取或寫入原子、謂詞、字串等的值。在本節中,我們將瞭解如何將單個字元寫入當前輸出流,或如何從當前輸入流讀取。因此,有一些預定義的謂詞可以執行這些任務。
put(C)和put_char(C)謂詞
我們可以使用put(C)一次一個字元地將字元寫入當前輸出流。輸出流可以是檔案或控制檯。在像SWI Prolog這樣的其他版本的Prolog中,C可以是字元或ASCII碼,但在GNU Prolog中,它只支援ASCII值。要使用字元而不是ASCII,我們可以使用put_char(C)。
程式
| ?- put(97),put(98),put(99),put(100),put(101).
abcde
yes
| ?- put(97),put(66),put(99),put(100),put(101).
aBcde
(15 ms) yes
| ?- put(65),put(66),put(99),put(100),put(101).
ABcde
yes
| ?-put_char('h'),put_char('e'),put_char('l'),put_char('l'),put_char('o').
hello
yes
| ?-
get_char(C)和get_code(C)謂詞
要從當前輸入流讀取單個字元,我們可以使用get_char(C)謂詞。這將獲取字元。如果我們想要ASCII碼,我們可以使用get_code(C)。
程式
| ?- get_char(X).
A.
X = 'A'
yes
uncaught exception: error(syntax_error('user_input:6 (char:689) expression expected'),read_term/3)
| ?- get_code(X).
A.
X = 65
yes
uncaught exception: error(syntax_error('user_input:7 (char:14) expression expected'),read_term/3)
| ?-
構造原子
原子構造是指從字元列表中,我們可以建立一個原子,或者從ASCII值列表中也可以建立原子。為此,我們必須使用atom_chars()和atom_codes()謂詞。在這兩種情況下,第一個引數將是一個變數,第二個引數將是一個列表。所以atom_chars()從字元構造原子,而atom_codes()從ASCII序列構造原子。
例子
| ?- atom_chars(X, ['t','i','g','e','r']). X = tiger yes | ?- atom_chars(A, ['t','o','m']). A = tom yes | ?- atom_codes(X, [97,98,99,100,101]). X = abcde yes | ?- atom_codes(A, [97,98,99]). A = abc yes | ?-
分解原子
原子分解是指從一個原子中,我們可以得到一個字元序列或一個ASCII碼序列。為此,我們必須使用相同的atom_chars()和atom_codes()謂詞。但不同之處在於,在這兩種情況下,第一個引數將是一個原子,第二個引數將是一個變數。所以atom_chars()將原子分解為字元,而atom_codes()將原子分解為ASCII序列。
例子
| ?- atom_chars(tiger,X). X = [t,i,g,e,r] yes | ?- atom_chars(tom,A). A = [t,o,m] yes | ?- atom_codes(tiger,X). X = [116,105,103,101,114] yes | ?- atom_codes(tom,A). A = [116,111,109] (16 ms) yes | ?-
Prolog中的consult
諮詢是一種技術,用於合併來自不同檔案的謂詞。我們可以使用 consult() 謂詞,並傳遞檔名來附加謂詞。讓我們看一個示例程式來理解這個概念。
假設我們有兩個檔案,分別是 prog1.pl 和 prog2.pl。
程式 (prog1.pl)
likes(mary,cat). likes(joy,rabbit). likes(tim,duck).
程式 (prog2.pl)
likes(suman,mouse). likes(angshu,deer).
輸出
| ?- [prog1].
compiling D:/TP Prolog/Sample_Codes/prog1.pl for byte code...
D:/TP Prolog/Sample_Codes/prog1.pl compiled, 2 lines read - 443 bytes written, 23 ms
yes
| ?- likes(joy,rabbit).
yes
| ?- likes(suman,mouse).
no
| ?- consult('prog2.pl').
compiling D:/TP Prolog/Sample_Codes/prog2.pl for byte code...
D:/TP Prolog/Sample_Codes/prog2.pl compiled, 1 lines read - 366 bytes written, 20 ms
warning: D:/TP Prolog/Sample_Codes/prog2.pl:1: redefining procedure likes/2
D:/TP Prolog/Sample_Codes/prog1.pl:1: previous definition
yes
| ?- likes(suman,mouse).
yes
| ?- likes(joy,rabbit).
no
| ?-
從這個輸出中我們可以理解,這不像看起來那麼簡單。如果兩個檔案具有**完全不同的子句**,那麼它將正常工作。但是,如果存在相同的謂詞,那麼當我們嘗試諮詢該檔案時,它將檢查第二個檔案中的謂詞,當它找到一些匹配項時,它會簡單地刪除本地資料庫中相同謂詞的所有條目,然後從第二個檔案中再次載入它們。
Prolog - 內建謂詞
在 Prolog 中,我們已經看到在大多數情況下都是使用者定義的謂詞,但也有一些內建謂詞。內建謂詞分為以下三種類型:
標識項
分解結構
收集所有解決方案
所以這是一個屬於標識項組的一些謂詞的列表:
| 謂詞 | 描述 |
|---|---|
| var(X) | 如果 X 當前是一個未例項化的變數,則成功。 |
| novar(X) | 如果 X 不是變數,或者已經例項化,則成功。 |
| atom(X) | 如果 X 當前代表一個原子,則為真。 |
| number(X) | 如果 X 當前代表一個數字,則為真。 |
| integer(X) | 如果 X 當前代表一個整數,則為真。 |
| float(X) | 如果 X 當前代表一個實數,則為真。 |
| atomic(X) | 如果 X 當前代表一個數字或一個原子,則為真。 |
| compound(X) | 如果 X 當前代表一個結構,則為真。 |
| ground(X) | 如果 X 不包含任何未例項化的變數,則成功。 |
var(X) 謂詞
當 X 未初始化時,它將顯示 true,否則為 false。讓我們來看一個例子。
例子
| ?- var(X). yes | ?- X = 5, var(X). no | ?- var([X]). no | ?-
novar(X) 謂詞
當 X 未初始化時,它將顯示 false,否則為 true。讓我們來看一個例子。
例子
| ?- nonvar(X). no | ?- X = 5,nonvar(X). X = 5 yes | ?- nonvar([X]). yes | ?-
atom(X) 謂詞
當傳遞給 X 的是非變數項,且引數為 0 且不是數字項時,這將返回 true,否則為 false。
例子
| ?- atom(paul). yes | ?- X = paul,atom(X). X = paul yes | ?- atom([]). yes | ?- atom([a,b]). no | ?-
number(X) 謂詞
如果 X 代表任何數字,則返回 true,否則為 false。
例子
| ?- number(X). no | ?- X=5,number(X). X = 5 yes | ?- number(5.46). yes | ?-
integer(X) 謂詞
如果 X 是正整數或負整數,則返回 true,否則為 false。
例子
| ?- integer(5). yes | ?- integer(5.46). no | ?-
float(X) 謂詞
如果 X 是浮點數,則返回 true,否則為 false。
例子
| ?- float(5). no | ?- float(5.46). yes | ?-
atomic(X) 謂詞
我們有 atom(X),它過於具體,對於數值資料返回 false,atomic(X) 與 atom(X) 類似,但它接受數字。
例子
| ?- atom(5). no | ?- atomic(5). yes | ?-
compound(X) 謂詞
如果 atomic(X) 失敗,則項要麼是一個未例項化的變數(可以使用 var(X) 測試),要麼是一個複合項。當我們傳遞一些複合結構時,Compound 將為 true。
例子
| ?- compound([]). no | ?- compound([a]). yes | ?- compound(b(a)). yes | ?-
ground(X) 謂詞
如果 X 不包含任何未例項化的變數,則返回 true。這也檢查複合項內部,否則返回 false。
例子
| ?- ground(X). no | ?- ground(a(b,X)). no | ?- ground(a). yes | ?- ground([a,b,c]). yes | ?-
分解結構
現在我們將看到另一組內建謂詞,即分解結構。我們之前已經看到過標識項。因此,當我們使用複合結構時,我們不能使用變數來檢查或建立函子。它將返回錯誤。因此,函子名稱不能由變量表示。
錯誤
X = tree, Y = X(maple). Syntax error Y=X<>(maple)
現在,讓我們看看屬於分解結構組的一些內建謂詞。
functor(T,F,N) 謂詞
如果 F 是 T 的主函子,並且 N 是 F 的元數,則返回 true。
**注意** - 元數表示屬性的數量。
例子
| ?- functor(t(f(X),a,T),Func,N). Func = t N = 3 (15 ms) yes | ?-
arg(N,Term,A) 謂詞
如果 A 是 Term 中的第 N 個引數,則返回 true。否則返回 false。
例子
| ?- arg(1,t(t(X),[]),A). A = t(X) yes | ?- arg(2,t(t(X),[]),A). A = [] yes | ?-
現在,讓我們看另一個例子。在這個例子中,我們檢查 D 的第一個引數將是 12,第二個引數將是 apr,第三個引數將是 2020。
例子
| ?- functor(D,date,3), arg(1,D,12), arg(2,D,apr), arg(3,D,2020). D = date(12,apr,2020) yes | ?-
../2 謂詞
這是另一個表示為雙點 (..) 的謂詞。它接受 2 個引數,所以寫為“/2”。所以 Term = .. L,如果 L 是一個列表,其中包含 Term 的函子及其引數,則為真。
例子
| ?- f(a,b) =.. L. L = [f,a,b] yes | ?- T =.. [is_blue,sam,today]. T = is_blue(sam,today) yes | ?-
透過將結構的元件表示為列表,可以在不知道函子名稱的情況下遞迴地處理它們。讓我們看另一個例子:
例子
| ?- f(2,3)=..[F,N|Y], N1 is N*3, L=..[F,N1|Y]. F = f L = f(6,3) N = 2 N1 = 6 Y = [3] yes | ?-
收集所有解決方案
現在讓我們看看第三類,稱為收集所有解決方案,它屬於 Prolog 中的內建謂詞。
我們已經看到,可以使用提示符中的分號來生成給定目標的所有給定解決方案。這是一個例子:
例子
| ?- member(X, [1,2,3,4]). X = 1 ? ; X = 2 ? ; X = 3 ? ; X = 4 yes
有時,我們需要在某些 AI 相關應用程式中生成某個目標的所有解決方案。因此,有三個內建謂詞可以幫助我們獲得結果。這些謂詞如下:
findall/3
setoff/3
bagof/3
這三個謂詞接受三個引數,因此我們在謂詞名稱後寫了“/3”。
這些也被稱為**元謂詞**。它們用於操縱 Prolog 的證明策略。
語法
findall(X,P,L). setof(X,P,L) bagof(X,P,L)
這三個謂詞列出了所有物件 X,只要目標 P 滿足(例如:age(X,Age))。它們都重複呼叫目標 P,透過在 P 中例項化變數 X 並將其新增到列表 L 中。當沒有更多解決方案時,這將停止。
Findall/3、Setof/3 和 Bagof/3
在這裡,我們將看到三個不同的內建謂詞 findall/3、setof/3 和 bagof/3,它們屬於**收集所有解決方案**類別。
findall/3 謂詞
此謂詞用於從謂詞 P 中建立所有解決方案 X 的列表。返回的列表將是 L。因此,我們將讀取此內容為“查詢所有 Xs,這樣 X 是謂詞 P 的解決方案,並將結果列表放入 L 中”。在這裡,此謂詞按 Prolog 找到它們的順序儲存結果。如果存在重複的解決方案,則所有解決方案都將進入結果列表,如果存在無限的解決方案,則該過程將永遠不會終止。
現在我們也可以對它們進行一些改進。第二個引數,即目標,可能是一個複合目標。那麼語法將是**findall(X, (Predicate on X, other goal), L)**
而且第一個引數可以是任何複雜度的項。讓我們看看這幾個規則的例子,並檢查輸出。
例子
| ?- findall(X, member(X, [1,2,3,4]), Results). Results = [1,2,3,4] yes | ?- findall(X, (member(X, [1,2,3,4]), X > 2), Results). Results = [3,4] yes | ?- findall(X/Y, (member(X,[1,2,3,4]), Y is X * X), Results). Results = [1/1,2/4,3/9,4/16] yes | ?-
setof/3 謂詞
setof/3 也類似於 findall/3,但它在這裡刪除所有重複的輸出,答案將被排序。
如果在目標中使用任何變數,則該變數不會出現在第一個引數中,setof/3 將為該變數的每個可能的例項化返回一個單獨的結果。
讓我們看一個例子來理解這個 setof/3。假設我們有一個如下所示的知識庫:
age(peter, 7). age(ann, 5). age(pat, 8). age(tom, 5). age(ann, 5).
在這裡我們可以看到 age(ann, 5) 在知識庫中有兩個條目。在這種情況下,年齡未排序,名稱未按字典順序排序。現在讓我們看一個 setof/3 用法的例子。
例子
| ?- setof(Child, age(Child,Age),Results). Age = 5 Results = [ann,tom] ? ; Age = 7 Results = [peter] ? ; Age = 8 Results = [pat] (16 ms) yes | ?-
在這裡,我們可以看到年齡和名稱都是排序的。對於年齡 5,有兩個條目,因此謂詞建立了一個包含兩個元素的與年齡值對應的列表。並且重複的條目只出現一次。
我們可以使用 setof/3 的巢狀呼叫來收集各個結果。我們將看到另一個例子,其中第一個引數將是 Age/Children。作為第二個引數,它將像之前一樣接受另一個 setof。因此,這將返回一個 (age/Children) 對列表。讓我們在 Prolog 執行中檢視:
例子
| ?- setof(Age/Children, setof(Child,age(Child,Age), Children), AllResults). AllResults = [5/[ann,tom],7/[peter],8/[pat]] yes | ?-
現在,如果我們不關心第一個引數中未出現的變數,則可以使用以下示例:
例子
| ?- setof(Child, Age^age(Child,Age), Results). Results = [ann,pat,peter,tom] yes | ?-
在這裡,我們使用上標符號 (^),這表示 Age 不在第一個引數中。因此,我們將讀取此內容為,“查詢所有孩子的集合,這樣孩子有年齡(無論是什麼),並將結果放入 Results 中”。
bagof/3 謂詞
bagof/3 類似於 setof/3,但它不刪除重複的輸出,答案可能未排序。
讓我們看一個例子來理解這個 bagof/3。假設我們有一個如下所示的知識庫:
知識庫
age(peter, 7). age(ann, 5). age(pat, 8). age(tom, 5). age(ann, 5).
例子
| ?- bagof(Child, age(Child,Age),Results). Age = 5 Results = [ann,tom,ann] ? ; Age = 7 Results = [peter] ? ; Age = 8 Results = [pat] (15 ms) yes | ?-
在這裡,對於 Age 值 5,結果是 [ann, tom, ann]。因此答案未排序,並且未刪除重複的條目,因此我們得到了兩個“ann”值。
bagof/3 與 findall/3 不同,因為它為目標中所有未出現在第一個引數中的變數生成單獨的結果。我們將在下面的示例中看到這一點:
例子
| ?- findall(Child, age(Child,Age),Results). Results = [peter,ann,pat,tom,ann] yes | ?-
數學謂詞
以下是數學謂詞:
| 謂詞 | 描述 |
|---|---|
| random(L,H,X)。 | 獲取 L 和 H 之間的隨機值 |
| between(L,H,X)。 | 獲取 L 和 H 之間的所有值 |
| succ(X,Y)。 | 加 1 並將其賦值給 X |
| abs(X)。 | 獲取 X 的絕對值 |
| max(X,Y)。 | 獲取 X 和 Y 之間的最大值 |
| min(X,Y)。 | 獲取 X 和 Y 之間的最小值 |
| round(X)。 | 四捨五入到接近 X 的值 |
| truncate(X)。 | 將浮點數轉換為整數,刪除小數部分 |
| floor(X)。 | 向下取整 |
| ceiling(X)。 | 向上取整 |
| sqrt(X)。 | 平方根 |
除此之外,還有一些其他謂詞,例如 sin、cos、tan、asin、acos、atan、atan2、sinh、cosh、tanh、asinh、acosh、atanh、log、log10、exp、pi 等。
現在讓我們使用 Prolog 程式看看這些函式的實際作用。
例子
| ?- random(0,10,X). X = 0 yes | ?- random(0,10,X). X = 5 yes | ?- random(0,10,X). X = 1 yes | ?- between(0,10,X). X = 0 ? a X = 1 X = 2 X = 3 X = 4 X = 5 X = 6 X = 7 X = 8 X = 9 X = 10 (31 ms) yes | ?- succ(2,X). X = 3 yes | ?- X is abs(-8). X = 8 yes | ?- X is max(10,5). X = 10 yes | ?- X is min(10,5). X = 5 yes | ?- X is round(10.56). X = 11 yes | ?- X is truncate(10.56). X = 10 yes | ?- X is floor(10.56). X = 10 yes | ?- X is ceiling(10.56). X = 11 yes | ?- X is sqrt(144). X = 12.0 yes | ?-
樹形資料結構(案例研究)
到目前為止,我們已經瞭解了Prolog中邏輯程式設計的不同概念。現在,我們將研究一個Prolog的案例研究。我們將學習如何使用Prolog實現樹形資料結構,並建立我們自己的運算子。讓我們開始規劃。
假設我們有如下所示的樹:
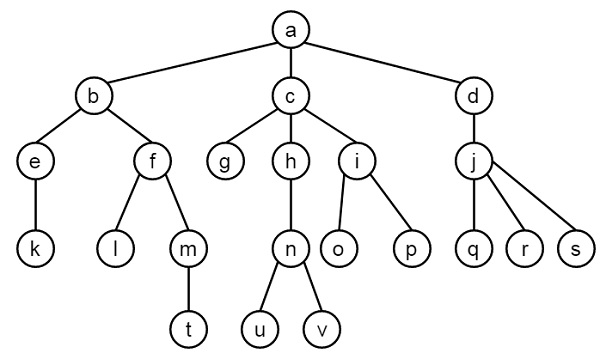
我們必須使用Prolog實現這棵樹。我們有一些操作如下:
op(500, xfx, ‘is_parent’).
op(500, xfx, ‘is_sibling_of’).
op(500, xfx, ‘is_at_same_level’).
還有一個謂詞,即leaf_node(Node)
在這些運算子中,你看到了一些引數,例如(500, xfx, <operator_name>)。第一個引數(此處為500)是該運算子的優先順序。'xfx'表示這是一個二元運算子,而<operator_name>是運算子的名稱。
這些運算子可以用來定義樹資料庫。我們可以如下使用這些運算子:
a is_parent b,或 is_parent(a, b)。 這表示節點a是節點b的父節點。
X is_sibling_of Y 或 is_sibling_of(X,Y)。 這表示X是節點Y的兄弟節點。規則是,如果另一個節點Z是X的父節點,並且Z也是Y的父節點,並且X和Y不同,那麼X和Y就是兄弟節點。
leaf_node(Node)。 如果一個節點(Node)沒有子節點,則稱該節點為葉子節點。
X is_at_same_level Y,或 is_at_same_level(X,Y)。 這將檢查X和Y是否在同一層級。條件是:如果X和Y相同,則返回true;否則,W是X的父節點,Z是Y的父節點,並且W和Z在同一層級。
如上所示,其他規則在程式碼中定義。讓我們看看程式以獲得更好的瞭解。
程式
/* The tree database */
:- op(500,xfx,'is_parent').
a is_parent b. c is_parent g. f is_parent l. j is_parent q.
a is_parent c. c is_parent h. f is_parent m. j is_parent r.
a is_parent d. c is_parent i. h is_parent n. j is_parent s.
b is_parent e. d is_parent j. i is_parent o. m is_parent t.
b is_parent f. e is_parent k. i is_parent p. n is_parent u.
n
is_parent v.
/* X and Y are siblings i.e. child from the same parent */
:- op(500,xfx,'is_sibling_of').
X is_sibling_of Y :- Z is_parent X,
Z is_parent Y,
X \== Y.
leaf_node(Node) :- \+ is_parent(Node,Child). % Node grounded
/* X and Y are on the same level in the tree. */
:-op(500,xfx,'is_at_same_level').
X is_at_same_level X .
X is_at_same_level Y :- W is_parent X,
Z is_parent Y,
W is_at_same_level Z.
輸出
| ?- [case_tree]. compiling D:/TP Prolog/Sample_Codes/case_tree.pl for byte code... D:/TP Prolog/Sample_Codes/case_tree.pl:20: warning: singleton variables [Child] for leaf_node/1 D:/TP Prolog/Sample_Codes/case_tree.pl compiled, 28 lines read - 3244 bytes written, 7 ms yes | ?- i is_parent p. yes | ?- i is_parent s. no | ?- is_parent(i,p). yes | ?- e is_sibling_of f. true ? yes | ?- is_sibling_of(e,g). no | ?- leaf_node(v). yes | ?- leaf_node(a). no | ?- is_at_same_level(l,s). true ? yes | ?- l is_at_same_level v. no | ?-
更多關於樹形資料結構
這裡,我們將看到一些更多將對上述給定的樹形資料結構執行的操作。
讓我們在這裡考慮同一棵樹:
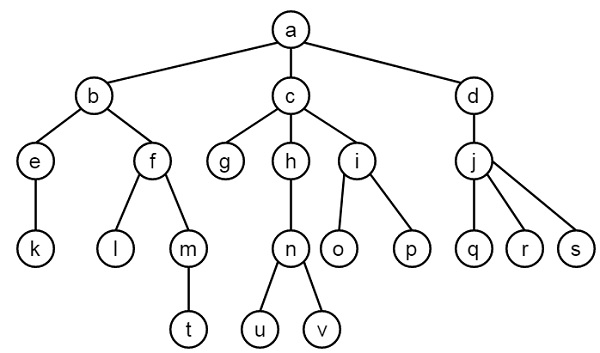
我們將定義其他操作:
path(Node)
locate(Node)
由於我們已經建立了最後一個數據庫,我們將建立一個新的程式來儲存這些操作,然後查詢新檔案以便在現有的程式上使用這些操作。
讓我們看看這些運算子的目的:
path(Node) - 這將顯示從根節點到給定節點的路徑。為了解決這個問題,假設X是Node的父節點,那麼找到path(X),然後寫入X。當到達根節點'a'時,它將停止。
locate(Node) - 這將從樹的根部定位一個節點(Node)。在這種情況下,我們將呼叫path(Node)並寫入Node。
程式
讓我們看看程式的執行:
path(a). /* Can start at a. */
path(Node) :- Mother is_parent Node, /* Choose parent, */
path(Mother), /* find path and then */
write(Mother),
write(' --> ').
/* Locate node by finding a path from root down to the node */
locate(Node) :- path(Node),
write(Node),
nl.
輸出
| ?- consult('case_tree_more.pl').
compiling D:/TP Prolog/Sample_Codes/case_tree_more.pl for byte code...
D:/TP Prolog/Sample_Codes/case_tree_more.pl compiled, 9 lines read - 866 bytes written, 6 ms
yes
| ?- path(n).
a --> c --> h -->
true ?
yes
| ?- path(s).
a --> d --> j -->
true ?
yes
| ?- path(w).
no
| ?- locate(n).
a --> c --> h --> n
true ?
yes
| ?- locate(s).
a --> d --> j --> s
true ?
yes
| ?- locate(w).
no
| ?-
樹形資料結構的改進
現在讓我們在相同的樹形資料結構上定義一些高階操作。
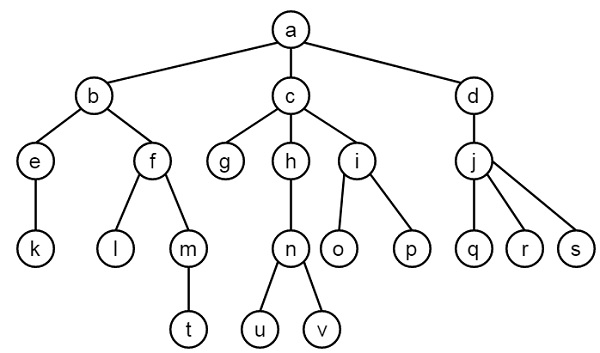
在這裡,我們將學習如何使用Prolog內建謂詞setof/3查詢節點的高度,即從該節點到最長路徑的長度。此謂詞采用(Template, Goal, Set)。這將Set繫結到滿足目標Goal的所有Template例項的列表。
我們之前已經定義了樹,因此我們將查詢當前程式碼以執行這些操作集,而無需再次重新定義樹資料庫。
我們將建立一些謂詞,如下所示:
ht(Node,H)。 這查詢高度。它還會檢查節點是否是葉子節點,如果是,則將高度H設定為0,否則遞迴查詢Node子節點的高度,併為它們加1。
max([X|R], M,A)。 這從列表和值M中計算最大元素。如果M是最大值,則返回M,否則返回列表中大於M的最大元素。為了解決這個問題,如果給定的列表為空,則返回M作為最大元素,否則檢查Head是否大於M,如果是,則使用尾部和值X呼叫max(),否則使用尾部和值M呼叫max()。
height(N,H)。 這使用setof/3謂詞。這將使用目標ht(N,Z)為模板Z查詢結果集,並存儲到稱為Set的列表型別變數中。現在找到Set的最大值和值0,並將結果儲存到H中。
現在讓我們看看程式的執行:
程式
height(N,H) :- setof(Z,ht(N,Z),Set),
max(Set,0,H).
ht(Node,0) :- leaf_node(Node),!.
ht(Node,H) :- Node is_parent Child,
ht(Child,H1),
H is H1 + 1.
max([],M,M).
max([X|R],M,A) :- (X > M -> max(R,X,A) ; max(R,M,A)).
輸出
| ?- consult('case_tree_adv.pl').
compiling D:/TP Prolog/Sample_Codes/case_tree_adv.pl for byte code...
D:/TP Prolog/Sample_Codes/case_tree_adv.pl compiled, 9 lines read - 2060 bytes written, 9 ms
yes
| ?- ht(c,H).
H = 1 ? a
H = 3
H = 3
H = 2
H = 2
yes
| ?- max([1,5,3,4,2],10,Max).
Max = 10
yes
| ?- max([1,5,3,40,2],10,Max).
Max = 40
yes
| ?- setof(H, ht(c,H),Set).
Set = [1,2,3]
yes
| ?- max([1,2,3],0,H).
H = 3
yes
| ?- height(c,H).
H = 3
yes
| ?- height(a,H).
H = 4
yes
| ?-
Prolog - 基本程式
在下一章中,我們將討論基本的Prolog示例,以:
查詢兩個數字的最小值和最大值
查詢電阻電路的等效電阻
驗證線段是水平的、垂直的還是傾斜的
兩個數字的最大值和最小值
在這裡,我們將看到一個Prolog程式,它可以找到兩個數字的最小值和最大值。首先,我們將建立兩個謂詞,find_max(X,Y,Max)。這將採用X和Y值,並將最大值儲存到Max中。類似地,find_min(X,Y,Min)將採用X和Y值,並將最小值儲存到Min變數中。
程式
find_max(X, Y, X) :- X >= Y, !. find_max(X, Y, Y) :- X < Y. find_min(X, Y, X) :- X =< Y, !. find_min(X, Y, Y) :- X > Y.
輸出
| ?- find_max(100,200,Max). Max = 200 yes | ?- find_max(40,10,Max). Max = 40 yes | ?- find_min(40,10,Min). Min = 10 yes | ?- find_min(100,200,Min). Min = 100 yes | ?-
電阻和電阻電路
在本節中,我們將學習如何編寫一個Prolog程式,幫助我們找到電阻電路的等效電阻。
讓我們考慮以下電路來理解這個概念:
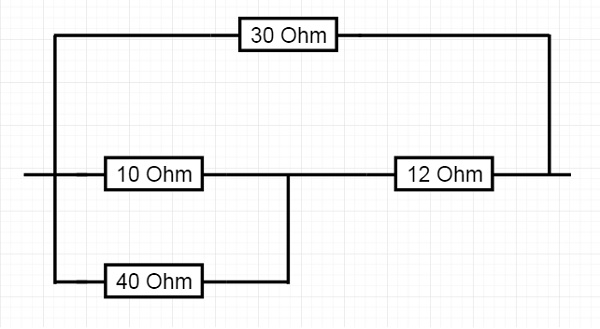
我們必須找到這個網路的等效電阻。首先,我們將嘗試手動獲得結果,然後嘗試檢視結果是否與Prolog輸出匹配。
我們知道有兩條規則:
如果R1和R2串聯,則等效電阻Re = R1 + R2。
如果R1和R2並聯,則等效電阻Re = (R1 * R2)/(R1 + R2)。
這裡10歐姆和40歐姆電阻並聯,然後與12歐姆串聯,下半部分的等效電阻與30歐姆並聯。所以讓我們嘗試計算等效電阻。
R3 = (10 * 40)/(10 + 40) = 400/50 = 8歐姆
R4 = R3 + 12 = 8 + 12 = 20歐姆
R5 = (20 * 30)/(20 + 30) = 12歐姆
程式
series(R1,R2,Re) :- Re is R1 + R2. parallel(R1,R2,Re) :- Re is ((R1 * R2) / (R1 + R2)).
輸出
| ?- [resistance]. compiling D:/TP Prolog/Sample_Codes/resistance.pl for byte code... D:/TP Prolog/Sample_Codes/resistance.pl compiled, 1 lines read - 804 bytes written, 14 ms yes | ?- parallel(10,40,R3). R3 = 8.0 yes | ?- series(8,12,R4). R4 = 20 yes | ?- parallel(20,30,R5). R5 = 12.0 yes | ?- parallel(10,40,R3),series(R3,12,R4),parallel(R4,30,R5). R3 = 8.0 R4 = 20.0 R5 = 12.0 yes | ?-
水平和垂直線段
線段有三種類型:水平、垂直或傾斜。此示例驗證線段是水平的、垂直的還是傾斜的。
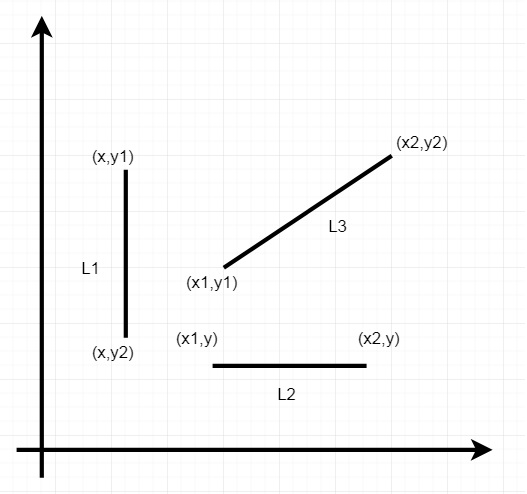
從該圖我們可以理解:
對於水平線,兩個端點的y座標值相同。
對於垂直線,兩個端點的x座標值相同。
對於傾斜線,兩個端點的(x,y)座標不同。
現在讓我們看看如何編寫程式來檢查這個。
程式
vertical(seg(point(X,_),point(X,_))).
horizontal(seg(point(_,Y),point(_,Y))).
oblique(seg(point(X1,Y1),point(X2,Y2)))
:-X1 \== X2,
Y1 \== Y2.
輸出
| ?- [line_seg]. compiling D:/TP Prolog/Sample_Codes/line_seg.pl for byte code... D:/TP Prolog/Sample_Codes/line_seg.pl compiled, 6 lines read - 1276 bytes written, 26 ms yes | ?- vertical(seg(point(10,20), point(10,30))). yes | ?- vertical(seg(point(10,20), point(15,30))). no | ?- oblique(seg(point(10,20), point(15,30))). yes | ?- oblique(seg(point(10,20), point(15,20))). no | ?- horizontal(seg(point(10,20), point(15,20))). yes | ?-
Prolog - cut 的例子
在本節中,我們將看到一些Prolog中cut的示例。讓我們考慮一下,我們想找到兩個元素的最大值。所以我們將檢查這兩個條件。
如果X > Y,則Max := X
如果X <= Y,則Max := Y
現在從這兩行,我們可以理解這兩條語句是互斥的,所以當一個為真時,另一個一定為假。在這種情況下,我們可以使用cut。所以讓我們看看程式。
我們還可以定義一個謂詞,其中我們使用析取(OR邏輯)的兩種情況。所以當第一個滿足時,它不會檢查第二個,否則,它將檢查第二個語句。
程式
max(X,Y,X) :- X >= Y,!. max(X,Y,Y) :- X < Y. max_find(X,Y,Max) :- X >= Y,!, Max = X; Max = Y.
輸出
| ?- [cut_example].
1 1 Call: [cut_example] ?
compiling D:/TP Prolog/Sample_Codes/cut_example.pl for byte code...
D:/TP Prolog/Sample_Codes/cut_example.pl compiled, 3 lines read - 1195 bytes written, 43 ms
1 1 Exit: [cut_example] ?
yes
{trace}
| ?- max(10,20,Max).
1 1 Call: max(10,20,_23) ?
2 2 Call: 10>=20 ?
2 2 Fail: 10>=20 ?
2 2 Call: 10<20 ?
2 2 Exit: 10<20 ?
1 1 Exit: max(10,20,20) ?
Max = 20
yes
{trace}
| ?- max_find(20,10,Max).
1 1 Call: max_find(20,10,_23) ?
2 2 Call: 20>=10 ?
2 2 Exit: 20>=10 ?
1 1 Exit: max_find(20,10,20) ?
Max = 20
yes
{trace}
| ?-
程式
讓我們看另一個例子,我們將使用列表。在這個程式中,我們將嘗試將一個元素插入到列表中,如果它之前不在列表中。如果列表之前有該元素,我們將簡單地將其cut掉。對於成員資格檢查,如果該項位於頭部,我們不應該進一步檢查,因此將其cut掉,否則檢查尾部。
list_member(X,[X|_]) :- !. list_member(X,[_|TAIL]) :- list_member(X,TAIL). list_append(A,T,T) :- list_member(A,T),!. list_append(A,T,[A|T]).
輸出
| ?- [cut_example].
compiling D:/TP Prolog/Sample_Codes/cut_example.pl for byte code...
D:/TP Prolog/Sample_Codes/cut_example.pl compiled, 9 lines read - 1954 bytes written, 15 ms
yes
| ?- trace.
The debugger will first creep -- showing everything (trace)
yes
{trace}
| ?- list_append(a,[a,b,c,d,e], L).
1 1 Call: list_append(a,[a,b,c,d,e],_33) ?
2 2 Call: list_member(a,[a,b,c,d,e]) ?
2 2 Exit: list_member(a,[a,b,c,d,e]) ?
1 1 Exit: list_append(a,[a,b,c,d,e],[a,b,c,d,e]) ?
L = [a,b,c,d,e]
yes
{trace}
| ?- list_append(k,[a,b,c,d,e], L).
1 1 Call: list_append(k,[a,b,c,d,e],_33) ?
2 2 Call: list_member(k,[a,b,c,d,e]) ?
3 3 Call: list_member(k,[b,c,d,e]) ?
4 4 Call: list_member(k,[c,d,e]) ?
5 5 Call: list_member(k,[d,e]) ?
6 6 Call: list_member(k,[e]) ?
7 7 Call: list_member(k,[]) ?
7 7 Fail: list_member(k,[]) ?
6 6 Fail: list_member(k,[e]) ?
5 5 Fail: list_member(k,[d,e]) ?
4 4 Fail: list_member(k,[c,d,e]) ?
3 3 Fail: list_member(k,[b,c,d,e]) ?
2 2 Fail: list_member(k,[a,b,c,d,e]) ?
1 1 Exit: list_append(k,[a,b,c,d,e],[k,a,b,c,d,e]) ?
L = [k,a,b,c,d,e]
(16 ms) yes
{trace}
| ?-
Prolog - 漢諾塔問題
漢諾塔問題是一個著名的難題,它使用中間樁作為輔助支撐樁,將N個圓盤從源樁/塔移動到目標樁/塔。解決這個問題時必須遵循兩個條件:
較大的圓盤不能放在較小的圓盤上。
一次只能移動一個圓盤。
下圖描繪了N=3個圓盤的起始設定。
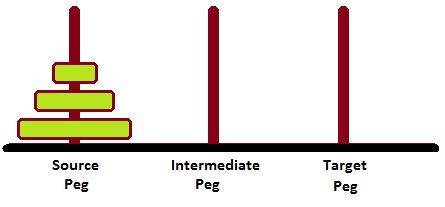
為了解決這個問題,我們必須編寫一個過程move(N, Source, Target, auxiliary)。這裡必須將N個圓盤從Source樁移到Target樁,並將Auxiliary樁作為中間樁。
例如 - move(3, source, target, auxiliary)。
將頂部圓盤從源移動到目標
將頂部圓盤從源移動到輔助
將頂部圓盤從目標移動到輔助
將頂部圓盤從源移動到目標
將頂部圓盤從輔助移動到源
將頂部圓盤從輔助移動到目標
將頂部圓盤從源移動到目標
程式
move(1,X,Y,_) :-
write('Move top disk from '), write(X), write(' to '), write(Y), nl.
move(N,X,Y,Z) :-
N>1,
M is N-1,
move(M,X,Z,Y),
move(1,X,Y,_),
move(M,Z,Y,X).
輸出
| ?- [towersofhanoi]. compiling D:/TP Prolog/Sample_Codes/towersofhanoi.pl for byte code... D:/TP Prolog/Sample_Codes/towersofhanoi.pl compiled, 8 lines read - 1409 bytes written, 15 ms yes | ?- move(4,source,target,auxiliary). Move top disk from source to auxiliary Move top disk from source to target Move top disk from auxiliary to target Move top disk from source to auxiliary Move top disk from target to source Move top disk from target to auxiliary Move top disk from source to auxiliary Move top disk from source to target Move top disk from auxiliary to target Move top disk from auxiliary to source Move top disk from target to source Move top disk from auxiliary to target Move top disk from source to auxiliary Move top disk from source to target Move top disk from auxiliary to target true ? (31 ms) yes
Prolog - 連結串列
後面的章節描述如何使用遞迴結構生成/建立連結串列。
連結串列有兩個組成部分:整數部分和連結部分。連結部分將儲存另一個節點。列表的末尾將在連結部分中包含nil。

在Prolog中,我們可以使用node(2, node(5, node(6, nil)))來表達這一點。
注意 - 最小的列表是nil,其他每個列表都將包含nil作為末尾節點的“next”。在列表術語中,第一個元素通常被稱為列表的頭部,列表的其餘部分被稱為尾部。因此,上述列表的頭部是2,其尾部是列表node(5, node(6, nil))。
我們還可以將元素插入到前面和後面:
程式
add_front(L,E,NList) :- NList = node(E,L). add_back(nil, E, NList) :- NList = node(E,nil). add_back(node(Head,Tail), E, NList) :- add_back(Tail, E, NewTail), NList = node(Head,NewTail).
輸出
| ?- [linked_list]. compiling D:/TP Prolog/Sample_Codes/linked_list.pl for byte code... D:/TP Prolog/Sample_Codes/linked_list.pl compiled, 7 lines read - 966 bytes written, 14 ms (15 ms) yes | ?- add_front(nil, 6, L1), add_front(L1, 5, L2), add_front(L2, 2, L3). L1 = node(6,nil) L2 = node(5,node(6,nil)) L3 = node(2,node(5,node(6,nil))) yes | ?- add_back(nil, 6, L1), add_back(L1, 5, L2), add_back(L2, 2, L3). L1 = node(6,nil) L2 = node(6,node(5,nil)) L3 = node(6,node(5,node(2,nil))) yes | ?- add_front(nil, 6, L1), add_front(L1, 5, L2), add_back(L2, 2, L3). L1 = node(6,nil) L2 = node(5,node(6,nil)) L3 = node(5,node(6,node(2,nil))) yes | ?-
Prolog - 猴子和香蕉問題
在這個Prolog示例中,我們將看到一個非常有趣且著名的難題:猴子和香蕉問題。
問題陳述
假設問題如下:
一隻飢餓的猴子在一個房間裡,它靠近門。
猴子在地板上。
香蕉掛在房間天花板的中央。
房間窗戶附近有一個木塊(或椅子)。
猴子想要香蕉,但夠不著。
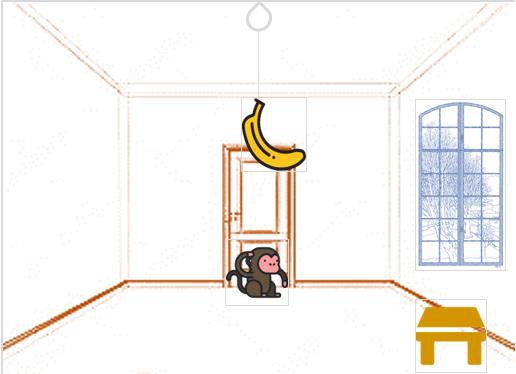
那麼猴子怎麼能得到香蕉呢?
所以如果猴子足夠聰明,它可以走到木塊旁,將木塊拖到中央,爬上去,拿到香蕉。以下是這種情況的一些觀察結果:
如果猴子和木塊都在同一層,猴子就能夠到木塊。從上圖可以看出,猴子和木塊都在地板上。
如果木塊的位置不在中央,猴子可以將其拖到中央。
如果猴子和木塊都在地板上,並且木塊在中央,那麼猴子就可以爬上木塊。因此猴子的垂直位置將改變。
當猴子在木塊上,並且木塊在中央時,猴子就可以拿到香蕉。
現在,讓我們看看如何使用Prolog來解決這個問題。我們將建立一些謂詞,如下所示:
我們有一些謂詞,透過執行動作從一個狀態移動到另一個狀態。
當木塊在中間,猴子在木塊頂部,並且猴子沒有香蕉(即has not狀態)時,使用grasp動作,它將從has not狀態變為have狀態。
從地板上,它可以透過執行動作climb移動到木塊的頂部(即on top狀態)。
push或drag操作將木塊從一個位置移動到另一個位置。
猴子可以使用walk或move子句從一個位置移動到另一個位置。
另一個謂詞將是canget()。這裡我們傳遞一個狀態,所以這將使用不同的動作執行從一個狀態到另一個狀態的移動謂詞,然後在狀態2上執行canget()。當我們到達狀態“has>”時,這表示“有香蕉”。我們將停止執行。
程式
move(state(middle,onbox,middle,hasnot), grasp, state(middle,onbox,middle,has)). move(state(P,onfloor,P,H), climb, state(P,onbox,P,H)). move(state(P1,onfloor,P1,H), drag(P1,P2), state(P2,onfloor,P2,H)). move(state(P1,onfloor,B,H), walk(P1,P2), state(P2,onfloor,B,H)). canget(state(_,_,_,has)). canget(State1) :- move(State1,_,State2), canget(State2).
輸出
| ?- [monkey_banana].
compiling D:/TP Prolog/Sample_Codes/monkey_banana.pl for byte code...
D:/TP Prolog/Sample_Codes/monkey_banana.pl compiled, 17 lines read - 2167 bytes written, 19 ms
(31 ms) yes
| ?- canget(state(atdoor, onfloor, atwindow, hasnot)).
true ?
yes
| ?- trace
.
The debugger will first creep -- showing everything (trace)
yes
{trace}
| ?- canget(state(atdoor, onfloor, atwindow, hasnot)).
1 1 Call: canget(state(atdoor,onfloor,atwindow,hasnot)) ?
2 2 Call: move(state(atdoor,onfloor,atwindow,hasnot),_52,_92) ?
2 2 Exit:move(state(atdoor,onfloor,atwindow,hasnot),walk(atdoor,_80),state(_80,onfloor,atwindow,hasnot)) ?
3 2 Call: canget(state(_80,onfloor,atwindow,hasnot)) ?
4 3 Call: move(state(_80,onfloor,atwindow,hasnot),_110,_150) ?
4 3 Exit: move(state(atwindow,onfloor,atwindow,hasnot),climb,state(atwindow,onbox,atwindow,hasnot)) ?
5 3 Call: canget(state(atwindow,onbox,atwindow,hasnot)) ?
6 4 Call: move(state(atwindow,onbox,atwindow,hasnot),_165,_205) ?
6 4 Fail: move(state(atwindow,onbox,atwindow,hasnot),_165,_193) ?
5 3 Fail: canget(state(atwindow,onbox,atwindow,hasnot)) ?
4 3 Redo: move(state(atwindow,onfloor,atwindow,hasnot),climb,state(atwindow,onbox,atwindow,hasnot)) ?
4 3 Exit: move(state(atwindow,onfloor,atwindow,hasnot),drag(atwindow,_138),state(_138,onfloor,_138,hasnot)) ?
5 3 Call: canget(state(_138,onfloor,_138,hasnot)) ?
6 4 Call: move(state(_138,onfloor,_138,hasnot),_168,_208) ?
6 4 Exit: move(state(_138,onfloor,_138,hasnot),climb,state(_138,onbox,_138,hasnot)) ?
7 4 Call: canget(state(_138,onbox,_138,hasnot)) ?
8 5 Call: move(state(_138,onbox,_138,hasnot),_223,_263) ?
8 5 Exit: move(state(middle,onbox,middle,hasnot),grasp,state(middle,onbox,middle,has)) ?
9 5 Call: canget(state(middle,onbox,middle,has)) ?
9 5 Exit: canget(state(middle,onbox,middle,has)) ?
7 4 Exit: canget(state(middle,onbox,middle,hasnot)) ?
5 3 Exit: canget(state(middle,onfloor,middle,hasnot)) ?
3 2 Exit: canget(state(atwindow,onfloor,atwindow,hasnot)) ?
1 1 Exit: canget(state(atdoor,onfloor,atwindow,hasnot)) ?
true ?
(78 ms) yes