- Mahout 有用資源
- Mahout 快速指南
- Mahout - 資源
- Mahout - 討論
Mahout 快速指南
Mahout - 簡介
我們生活在一個資訊充裕的時代。資訊過載已經達到了如此的高度,以至於有時難以管理我們小小的郵箱!想象一下,一些流行的網站(如 Facebook、Twitter 和 Youtube)每天必須收集和管理的資料和記錄量。即使是鮮為人知的網站,接收大量資訊也是很常見的。
通常,我們依靠資料探勘演算法來分析海量資料,以識別趨勢並得出結論。但是,除非計算任務在雲端分佈在多臺機器上執行,否則沒有資料探勘演算法能夠高效地處理非常大的資料集並在短時間內提供結果。
現在我們有了新的框架,允許我們將計算任務分解成多個片段,並在不同的機器上執行每個片段。Mahout 就是這樣一個數據挖掘框架,它通常在其後臺與 Hadoop 基礎架構耦合執行,以管理海量資料。
什麼是 Apache Mahout?
Mahout 指的是駕馭大象的馴象人。這個名字來源於它與 Apache Hadoop 的密切關聯,後者使用大象作為其標誌。
Hadoop 是 Apache 的一個開源框架,它允許使用簡單的程式設計模型在計算機叢集的分散式環境中儲存和處理大資料。
Apache Mahout 是一個開源專案,主要用於建立可擴充套件的機器學習演算法。它實現了流行的機器學習技術,例如:
- 推薦系統
- 分類
- 聚類
Apache Mahout 於 2008 年作為 Apache Lucene 的子專案啟動。2010 年,Mahout 成為 Apache 的頂級專案。
Mahout 的特點
下面列出了 Apache Mahout 的主要特點。
Mahout 的演算法構建在 Hadoop 之上,因此它在分散式環境中執行良好。Mahout 使用 Apache Hadoop 庫在雲中有效地進行擴充套件。
Mahout 為程式設計師提供了一個現成的框架,用於對海量資料執行資料探勘任務。
Mahout 允許應用程式有效且快速地分析大型資料集。
包含多個支援 MapReduce 的聚類實現,例如 k-means、模糊 k-means、Canopy、Dirichlet 和 Mean-Shift。
支援分散式樸素貝葉斯和互補樸素貝葉斯分類實現。
具有用於進化程式設計的分散式適應度函式功能。
包含矩陣和向量庫。
Mahout 的應用
Adobe、Facebook、LinkedIn、Foursquare、Twitter 和 Yahoo 等公司都在內部使用 Mahout。
Foursquare 幫助你找到特定區域可用的場所、食物和娛樂。它使用 Mahout 的推薦引擎。
Twitter 使用 Mahout 進行使用者興趣建模。
雅虎!使用 Mahout 進行模式挖掘。
Mahout - 機器學習
Apache Mahout 是一個高度可擴充套件的機器學習庫,它使開發人員能夠使用最佳化的演算法。Mahout 實現了流行的機器學習技術,例如推薦、分類和聚類。因此,在我們進一步講解之前,最好簡要介紹一下機器學習。
什麼是機器學習?
機器學習是科學的一個分支,它處理以這樣的方式對系統進行程式設計:它們會根據經驗自動學習和改進。在這裡,學習意味著識別和理解輸入資料,並根據提供的資料做出明智的決策。
根據所有可能的輸入來滿足所有決策是非常困難的。為了解決這個問題,開發了演算法。這些演算法根據統計學、機率論、邏輯、組合最佳化、搜尋、強化學習和控制理論的原理,從特定資料和過去的經驗中構建知識。
開發的演算法構成了各種應用程式的基礎,例如:
- 視覺處理
- 語言處理
- 預測(例如,股市趨勢)
- 模式識別
- 遊戲
- 資料探勘
- 專家系統
- 機器人技術
機器學習是一個廣闊的領域,本教程無法涵蓋其所有功能。有多種方法可以實現機器學習技術,但是最常用的方法是監督學習和無監督學習。
監督學習
監督學習處理從可用的訓練資料中學習函式。監督學習演算法分析訓練資料並生成一個推斷函式,該函式可用於對映新示例。監督學習的常見示例包括:
- 將電子郵件分類為垃圾郵件;
- 根據其內容標記網頁;以及
- 語音識別。
有很多監督學習演算法,例如神經網路、支援向量機 (SVM) 和樸素貝葉斯分類器。Mahout 實現了樸素貝葉斯分類器。
無監督學習
無監督學習無需任何預定義的訓練資料集即可理解未標記的資料。無監督學習是分析可用資料並查詢模式和趨勢的極其強大的工具。它最常用於將相似的輸入聚類到邏輯組中。無監督學習的常見方法包括:
- k-means
- 自組織對映;以及
- 層次聚類
推薦系統
推薦是一種流行的技術,它根據使用者資訊(例如之前的購買、點選和評分)提供相似的推薦。
亞馬遜使用此技術來顯示您可能感興趣的推薦商品列表,這些資訊來自您的過去行為。亞馬遜背後有推薦引擎來捕捉使用者行為,並根據您之前的行為推薦選擇的商品。
Facebook 使用推薦技術來識別和推薦“你可能認識的人”列表。

分類
分類,也稱為分類,是一種機器學習技術,它使用已知資料來確定如何將新資料分類到一組現有類別中。分類是一種監督學習形式。
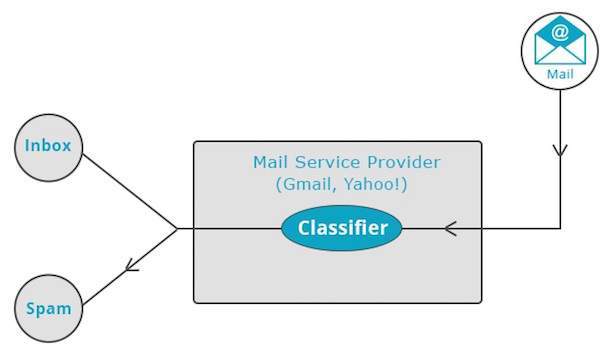
雅虎!和 Gmail 等郵件服務提供商使用此技術來確定是否應將新郵件分類為垃圾郵件。分類演算法透過分析使用者將某些郵件標記為垃圾郵件的習慣來自我訓練。基於此,分類器會決定是否應將未來的郵件存放到您的收件箱中或垃圾郵件資料夾中。
iTunes 應用程式使用分類來準備播放列表。
聚類
聚類用於根據共同特徵形成相似資料的組或聚類。聚類是一種無監督學習形式。
谷歌和雅虎!等搜尋引擎使用聚類技術對具有相似特徵的資料進行分組。
新聞組使用聚類技術根據相關主題對各種文章進行分組。
聚類引擎會完全遍歷輸入資料,並根據資料的特徵決定應將其分組到哪個聚類中。請看下面的例子。
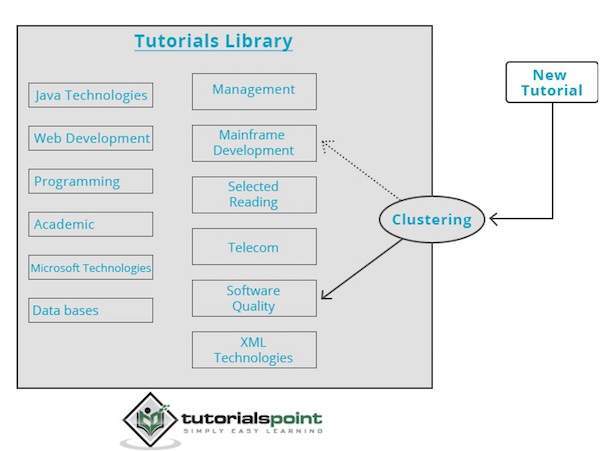
我們的教程庫包含關於各種主題的主題。當我們在 TutorialsPoint 收到新的教程時,它會由聚類引擎處理,該引擎會根據其內容決定將其分組到哪裡。
Mahout - 環境配置
本章將教你如何設定 Mahout。Java 和 Hadoop 是 Mahout 的先決條件。下面是下載和安裝 Java、Hadoop 和 Mahout 的步驟。
預安裝設定
在將 Hadoop 安裝到 Linux 環境之前,我們需要使用ssh(安全外殼)設定 Linux。請按照以下步驟設定 Linux 環境。
建立使用者
建議為 Hadoop 建立一個單獨的使用者,以將 Hadoop 檔案系統與 Unix 檔案系統隔離。請按照以下步驟建立使用者
使用命令“su”開啟 root。
- 使用命令“useradd 使用者名稱”從 root 帳戶建立使用者。
現在,您可以使用命令“su 使用者名稱”開啟現有的使用者帳戶。
開啟 Linux 終端,並鍵入以下命令以建立使用者。
$ su password: # useradd hadoop # passwd hadoop New passwd: Retype new passwd
SSH 設定和金鑰生成
SSH 設定是執行叢集上不同操作(例如啟動、停止和分散式守護程序 shell 操作)所必需的。為了驗證 Hadoop 的不同使用者,需要為 Hadoop 使用者提供公鑰/私鑰對,並與不同的使用者共享。
以下命令用於使用 SSH 生成金鑰值對,將公鑰從 id_rsa.pub 複製到 authorized_keys,並分別為 authorized_keys 檔案提供所有者、讀和寫許可權。
$ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
驗證 ssh
ssh localhost
安裝 Java
Java 是 Hadoop 和 HBase 的主要先決條件。首先,你應該使用“java -version”驗證系統中 Java 的存在。Java 版本命令的語法如下所示。
$ java -version
它應該產生以下輸出。
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果你的系統中沒有安裝 Java,那麼請按照以下步驟安裝 Java。
步驟 1
訪問以下連結下載 java(JDK <最新版本> - X64.tar.gz):Oracle
然後jdk-7u71-linux-x64.tar.gz 下載到你的系統上。
步驟 2
通常,你會在“下載”資料夾中找到下載的 Java 檔案。驗證它並使用以下命令解壓jdk-7u71-linux-x64.gz檔案。
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
步驟 3
為了使 Java 可供所有使用者使用,你需要將其移動到“/usr/local/”位置。開啟 root,並鍵入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
步驟 4
為了設定PATH和JAVA_HOME變數,請將以下命令新增到~/.bashrc 檔案中。
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH= $PATH:$JAVA_HOME/bin
現在,如上所述,從終端驗證java -version命令。
下載 Hadoop
安裝 Java 後,你需要先安裝 Hadoop。使用以下所示的“Hadoop version”命令驗證 Hadoop 的存在。
hadoop version
它應該產生以下輸出
Hadoop 2.6.0 Compiled by jenkins on 2014-11-13T21:10Z Compiled with protoc 2.5.0 From source with checksum 18e43357c8f927c0695f1e9522859d6a This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoopcommon-2.6.0.jar
如果你的系統無法找到 Hadoop,那麼請下載 Hadoop 並將其安裝到你的系統上。請按照以下命令操作。
使用以下命令從 Apache 軟體基金會下載並解壓 hadoop-2.6.0。
$ su password: # cd /usr/local # wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop- 2.6.0/hadoop-2.6.0-src.tar.gz # tar xzf hadoop-2.6.0-src.tar.gz # mv hadoop-2.6.0/* hadoop/ # exit
安裝 Hadoop
以任何所需模式安裝 Hadoop。在這裡,我們演示了偽分散式模式下的 HBase 功能,因此請以偽分散式模式安裝 Hadoop。
請按照以下步驟在你的系統上安裝Hadoop 2.4.1。
步驟 1:設定 Hadoop
你可以透過將以下命令新增到~/.bashrc檔案中來設定 Hadoop 環境變數。
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOME
現在,將所有更改應用到當前正在執行的系統。
$ source ~/.bashrc
步驟 2:Hadoop 配置
你可以在“$HADOOP_HOME/etc/hadoop”位置找到所有 Hadoop 配置檔案。需要根據你的 Hadoop 基礎架構更改這些配置檔案。
$ cd $HADOOP_HOME/etc/hadoop
為了用 Java 開發 Hadoop 程式,你需要透過用系統中 Java 的位置替換JAVA_HOME值來重置hadoop-env.sh檔案中的 Java 環境變數。
export JAVA_HOME=/usr/local/jdk1.7.0_71
下面列出了你需要編輯以配置 Hadoop 的檔案列表。
core-site.xml
core-site.xml檔案包含諸如 Hadoop 例項使用的埠號、為檔案系統分配的記憶體、儲存資料的記憶體限制以及讀/寫緩衝區的大小等資訊。
開啟 core-site.xml 檔案,在 `
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://:9000</value>
</property>
</configuration>
hdfs-site.xml
hdfs-site.xml 檔案包含諸如複製資料值、namenode 路徑和本地檔案系統的 datanode 路徑等資訊。這意味著您希望儲存 Hadoop 基礎架構的位置。
讓我們假設以下資料
dfs.replication (data replication value) = 1 (In the below given path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
開啟此檔案,在此檔案的 `
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>
注意:在上文中,所有屬性值都是使用者定義的。您可以根據您的 Hadoop 基礎架構進行更改。
mapred-site.xml
此檔案用於將 yarn 配置到 Hadoop 中。開啟 mapred-site.xml 檔案,在此檔案的 `
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
此檔案用於指定我們正在使用哪個 MapReduce 框架。預設情況下,Hadoop 包含 mapred-site.xml 的模板。首先,需要使用以下命令將檔案從 mapred-site.xml.template 複製到 mapred-site.xml 檔案。
$ cp mapred-site.xml.template mapred-site.xml
開啟 mapred-site.xml 檔案,在此檔案的 `
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
驗證 Hadoop 安裝
以下步驟用於驗證 Hadoop 安裝。
步驟 1:Name Node 設定
使用命令“hdfs namenode -format”設定 namenode,如下所示
$ cd ~ $ hdfs namenode -format
預期結果如下所示
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
步驟 2:驗證 Hadoop dfs
以下命令用於啟動 dfs。此命令啟動您的 Hadoop 檔案系統。
$ start-dfs.sh
預期輸出如下所示
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
步驟 3:驗證 Yarn 指令碼
以下命令用於啟動 yarn 指令碼。執行此命令將啟動您的 yarn 守護程序。
$ start-yarn.sh
預期輸出如下所示
starting yarn daemons starting resource manager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn- hadoop-resourcemanager-localhost.out localhost: starting node manager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
步驟 4:在瀏覽器上訪問 Hadoop
訪問 hadoop 的預設埠號為 50070。使用以下 URL 在瀏覽器上獲取 Hadoop 服務。
https://:50070/

步驟 5:驗證叢集的所有應用程式
訪問叢集所有應用程式的預設埠號為 8088。使用以下 URL 訪問此服務。
https://:8088/

下載 Mahout
Mahout 可在網站 Mahout 上獲得。從網站提供的連結下載 Mahout。以下是網站的螢幕截圖。

步驟 1
使用以下命令從連結 https://mahout.apache.org/general/downloads 下載 Apache mahout。
[Hadoop@localhost ~]$ wget http://mirror.nexcess.net/apache/mahout/0.9/mahout-distribution-0.9.tar.gz
然後 mahout-distribution-0.9.tar.gz 將下載到您的系統中。
步驟 2
瀏覽儲存 mahout-distribution-0.9.tar.gz 的資料夾,並解壓下載的 jar 檔案,如下所示。
[Hadoop@localhost ~]$ tar zxvf mahout-distribution-0.9.tar.gz
Maven 倉庫
以下是使用 Eclipse 構建 Apache Mahout 的 pom.xml。
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>0.9</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-math</artifactId>
<version>${mahout.version}</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-integration</artifactId>
<version>${mahout.version}</version>
</dependency>
Mahout - 推薦系統
本章介紹流行的機器學習技術——推薦,其機制以及如何編寫實現 Mahout 推薦的應用程式。
推薦系統
您是否曾經想過亞馬遜是如何提出推薦商品列表,來吸引您注意您可能感興趣的特定產品的!
假設您想從亞馬遜購買“Mahout in Action”這本書
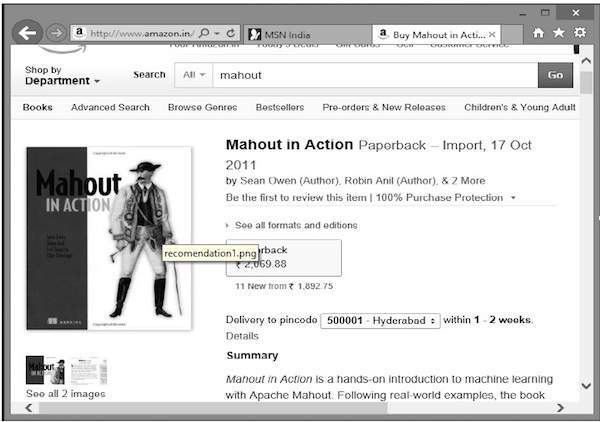
除了所選產品外,亞馬遜還會顯示相關的推薦商品列表,如下所示。
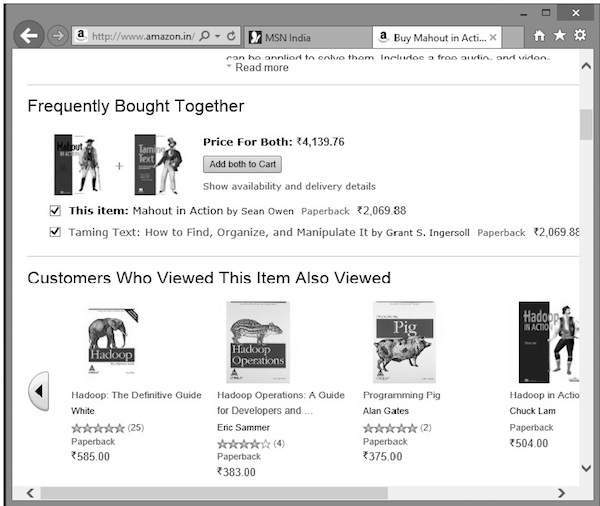
此類推薦列表是在 推薦引擎 的幫助下生成的。Mahout 提供了幾種型別的推薦引擎,例如
- 基於使用者的推薦器,
- 基於專案的推薦器,以及
- 其他幾種演算法。
Mahout 推薦引擎
Mahout 有一個非分散式、非基於 Hadoop 的推薦引擎。您應該傳遞一個包含使用者對商品偏好的文字文件。該引擎的輸出將是特定使用者對其他商品的估計偏好。
示例
考慮一個銷售消費品(如手機、小工具及其配件)的網站。如果我們想在此類網站中實現 Mahout 的功能,那麼我們可以構建一個推薦引擎。該引擎分析使用者的過去購買資料,並據此推薦新產品。
Mahout 提供的用於構建推薦引擎的元件如下
- 資料模型 (DataModel)
- 使用者相似度 (UserSimilarity)
- 專案相似度 (ItemSimilarity)
- 使用者鄰域 (UserNeighborhood)
- 推薦器 (Recommender)
從資料儲存中準備資料模型,並將其作為輸入傳遞給推薦引擎。推薦引擎會為特定使用者生成推薦。以下是推薦引擎的架構。
推薦引擎架構
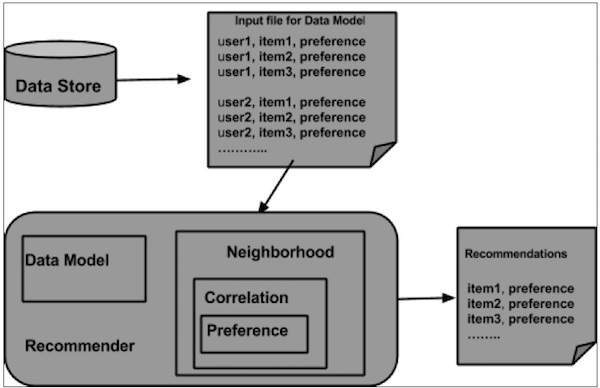
使用 Mahout 構建推薦器
以下是開發簡單推薦器的步驟
步驟 1:建立 DataModel 物件
PearsonCorrelationSimilarity 類的建構函式需要一個數據模型物件,該物件儲存包含使用者、商品和產品偏好詳細資訊的檔案。以下是示例資料模型檔案
1,00,1.0 1,01,2.0 1,02,5.0 1,03,5.0 1,04,5.0 2,00,1.0 2,01,2.0 2,05,5.0 2,06,4.5 2,02,5.0 3,01,2.5 3,02,5.0 3,03,4.0 3,04,3.0 4,00,5.0 4,01,5.0 4,02,5.0 4,03,0.0
DataModel 物件需要檔案物件,其中包含輸入檔案的路徑。如下所示建立 DataModel 物件。
DataModel datamodel = new FileDataModel(new File("input file"));
步驟 2:建立 UserSimilarity 物件
如下所示,使用 PearsonCorrelationSimilarity 類建立 UserSimilarity 物件
UserSimilarity similarity = new PearsonCorrelationSimilarity(datamodel);
步驟 3:建立 UserNeighborhood 物件
此物件計算與給定使用者相似的使用者“鄰域”。鄰域有兩種型別
NearestNUserNeighborhood - 此類計算一個鄰域,該鄰域包含與給定使用者最近的 *n* 個使用者。“最近”由給定的 UserSimilarity 定義。
ThresholdUserNeighborhood - 此類計算一個鄰域,該鄰域包含所有與給定使用者的相似度達到或超過某個閾值的使用者的相似度。相似度由給定的 UserSimilarity 定義。
這裡我們使用 ThresholdUserNeighborhood 並將偏好限制設定為 3.0。
UserNeighborhood neighborhood = new ThresholdUserNeighborhood(3.0, similarity, model);
步驟 4:建立 Recommender 物件
建立 UserbasedRecomender 物件。將所有上述建立的物件傳遞給其建構函式,如下所示。
UserBasedRecommender recommender = new GenericUserBasedRecommender(model, neighborhood, similarity);
步驟 5:向用戶推薦商品
使用 Recommender 介面的 recommend() 方法向用戶推薦產品。此方法需要兩個引數。第一個表示需要向其傳送推薦的使用者 ID,第二個表示要傳送的推薦數量。以下是 recommender() 方法的用法
List<RecommendedItem> recommendations = recommender.recommend(2, 3);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}
示例程式
以下是設定推薦的示例程式。為使用者 ID 為 2 的使用者準備推薦。
import java.io.File;
import java.util.List;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.ThresholdUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.UserBasedRecommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
public class Recommender {
public static void main(String args[]){
try{
//Creating data model
DataModel datamodel = new FileDataModel(new File("data")); //data
//Creating UserSimilarity object.
UserSimilarity usersimilarity = new PearsonCorrelationSimilarity(datamodel);
//Creating UserNeighbourHHood object.
UserNeighborhood userneighborhood = new ThresholdUserNeighborhood(3.0, usersimilarity, datamodel);
//Create UserRecomender
UserBasedRecommender recommender = new GenericUserBasedRecommender(datamodel, userneighborhood, usersimilarity);
List<RecommendedItem> recommendations = recommender.recommend(2, 3);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}
}catch(Exception e){}
}
}
使用以下命令編譯程式
javac Recommender.java java Recommender
它應該產生以下輸出
RecommendedItem [item:3, value:4.5] RecommendedItem [item:4, value:4.0]
Mahout - 聚類
聚類是根據專案之間的相似性將給定集合的元素或專案組織成組的過程。例如,與線上新聞釋出相關的應用程式使用聚類對其新聞文章進行分組。
聚類的應用
聚類廣泛應用於許多應用程式中,例如市場研究、模式識別、資料分析和影像處理。
聚類可以幫助營銷人員在其客戶群中發現不同的群體。他們可以根據購買模式來描述其客戶群體。
在生物學領域,它可用於推導植物和動物分類法、對具有相似功能的基因進行分類以及深入瞭解群體中固有的結構。
聚類有助於識別地球觀測資料庫中具有相似土地利用面積的區域。
聚類還有助於對網路上的文件進行分類以進行資訊發現。
聚類用於異常值檢測應用程式,例如信用卡欺詐檢測。
作為一種資料探勘功能,聚類分析可作為一種工具來深入瞭解資料的分佈,從而觀察每個聚類的特徵。
使用 Mahout,我們可以對給定的一組資料進行聚類。所需的步驟如下
演算法您需要選擇合適的聚類演算法來對聚類的元素進行分組。
相似性和相異性您需要制定規則來驗證新遇到的元素與組中元素之間的相似性。
停止條件需要停止條件來定義不需要聚類的點。
聚類過程
要對給定資料進行聚類,您需要:
啟動 Hadoop 伺服器。建立在 Hadoop 檔案系統中儲存檔案的所需目錄。(為輸入檔案、序列檔案和(在 canopy 的情況下)聚類輸出建立目錄)。
將輸入檔案從 Unix 檔案系統複製到 Hadoop 檔案系統。
從輸入資料準備序列檔案。
執行任何可用的聚類演算法。
獲取聚類資料。
啟動 Hadoop
Mahout 與 Hadoop 一起工作,因此請確保 Hadoop 伺服器已啟動並正在執行。
$ cd HADOOP_HOME/bin $ start-all.sh
準備輸入檔案目錄
使用以下命令在 Hadoop 檔案系統中建立目錄以儲存輸入檔案、序列檔案和聚類資料
$ hadoop fs -p mkdir /mahout_data $ hadoop fs -p mkdir /clustered_data $ hadoop fs -p mkdir /mahout_seq
您可以使用以下 URL 中的 hadoop Web 介面驗證是否建立了目錄:https://:50070/
它會給你如下所示的輸出

將輸入檔案複製到 HDFS
現在,將輸入資料檔案從 Linux 檔案系統複製到 Hadoop 檔案系統中的 mahout_data 目錄,如下所示。假設您的輸入檔案是 mydata.txt,並且它位於 /home/Hadoop/data/ 目錄中。
$ hadoop fs -put /home/Hadoop/data/mydata.txt /mahout_data/
準備序列檔案
Mahout 為您提供了一個實用程式,用於將給定的輸入檔案轉換為序列檔案格式。此實用程式需要兩個引數。
- 包含原始資料所在的輸入檔案目錄。
- 要儲存聚類資料所在的輸出檔案目錄。
以下是 mahout seqdirectory 實用程式的幫助提示。
步驟 1:瀏覽到 Mahout 主目錄。您可以獲得如下所示的實用程式幫助
[Hadoop@localhost bin]$ ./mahout seqdirectory --help Job-Specific Options: --input (-i) input Path to job input directory. --output (-o) output The directory pathname for output. --overwrite (-ow) If present, overwrite the output directory
使用以下語法使用實用程式生成序列檔案
mahout seqdirectory -i <input file path> -o <output directory>
示例
mahout seqdirectory -i hdfs://:9000/mahout_seq/ -o hdfs://:9000/clustered_data/
聚類演算法
Mahout 支援兩種主要的聚類演算法,即
- Canopy 聚類
- K 均值聚類
Canopy 聚類
Canopy 聚類是 Mahout 用於聚類目的的一種簡單而快速的技法。物件將被視為平面空間中的點。此技術通常用作其他聚類技術(例如 k 均值聚類)的初始步驟。您可以使用以下語法執行 Canopy 作業
mahout canopy -i <input vectors directory> -o <output directory> -t1 <threshold value 1> -t2 <threshold value 2>
Canopy 作業需要一個包含序列檔案的輸入檔案目錄和一個要儲存聚類資料的輸出目錄。
示例
mahout canopy -i hdfs://:9000/mahout_seq/mydata.seq -o hdfs://:9000/clustered_data -t1 20 -t2 30
您將在給定的輸出目錄中獲得生成的聚類資料。
K 均值聚類
K 均值聚類是一種重要的聚類演算法。k 均值聚類演算法中的 k 表示要將資料劃分為的聚類數量。例如,如果為此演算法指定的 k 值選擇為 3,則該演算法將資料分為 3 個聚類。
每個物件都將被表示為空間中的向量。初始時,演算法將隨機選擇k個點作為中心,每個最接近每個中心的物體都被聚類。距離度量有幾種演算法,使用者應該選擇所需的演算法。
建立向量檔案
與Canopy演算法不同,k-means演算法需要向量檔案作為輸入,因此您必須建立向量檔案。
要從序列檔案格式生成向量檔案,Mahout 提供了seq2parse實用程式。
下面列出了一些seq2parse實用程式的選項。使用這些選項建立向量檔案。
$MAHOUT_HOME/bin/mahout seq2sparse --analyzerName (-a) analyzerName The class name of the analyzer --chunkSize (-chunk) chunkSize The chunkSize in MegaBytes. --output (-o) output The directory pathname for o/p --input (-i) input Path to job input directory.
建立向量後,繼續進行k-means演算法。執行k-means作業的語法如下
mahout kmeans -i <input vectors directory> -c <input clusters directory> -o <output working directory> -dm <Distance Measure technique> -x <maximum number of iterations> -k <number of initial clusters>
K-means聚類作業需要輸入向量目錄、輸出聚類目錄、距離度量、要執行的最大迭代次數以及表示輸入資料要劃分成的聚類數量的整數值。
Mahout - 分類
什麼是分類?
分類是一種機器學習技術,它使用已知資料來確定如何將新資料分類到一組現有類別中。例如:
iTunes 應用程式使用分類來準備播放列表。
雅虎!和 Gmail 等郵件服務提供商使用此技術來確定是否應將新郵件分類為垃圾郵件。分類演算法透過分析使用者將某些郵件標記為垃圾郵件的習慣來自我訓練。基於此,分類器會決定是否應將未來的郵件存放到您的收件箱中或垃圾郵件資料夾中。
分類的工作原理
在對給定資料集進行分類時,分類器系統執行以下操作
- 首先,使用任何學習演算法準備新的資料模型。
- 然後測試準備好的資料模型。
- 此後,使用此資料模型來評估新資料並確定其類別。

分類的應用
信用卡欺詐檢測 - 分類機制用於預測信用卡欺詐。使用以前欺詐的歷史資訊,分類器可以預測哪些未來的交易可能變成欺詐。
垃圾郵件 - 根據以前垃圾郵件的特徵,分類器確定是否應將新遇到的電子郵件傳送到垃圾郵件資料夾。
樸素貝葉斯分類器
Mahout 使用樸素貝葉斯分類器演算法。它使用兩種實現
- 分散式樸素貝葉斯分類
- 互補樸素貝葉斯分類
樸素貝葉斯是一種構建分類器的簡單技術。它不是用於訓練此類分類器的單一演算法,而是一系列演算法。貝葉斯分類器構建模型來對問題例項進行分類。這些分類是使用可用資料進行的。
樸素貝葉斯的優勢在於,它只需要少量訓練資料即可估計分類所需的必要引數。
對於某些型別的機率模型,樸素貝葉斯分類器可以在監督學習環境中非常有效地進行訓練。
儘管其假設過於簡化,但樸素貝葉斯分類器在許多複雜的現實世界情況中都表現良好。
分類過程
要實現分類,需要遵循以下步驟
- 生成示例資料
- 從資料建立序列檔案
- 將序列檔案轉換為向量
- 訓練向量
- 測試向量
步驟1:生成示例資料
生成或下載要分類的資料。例如,您可以從以下連結獲取20 個新聞組示例資料:http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz
建立一個目錄用於儲存輸入資料。如下所示下載示例。
$ mkdir classification_example $ cd classification_example $tar xzvf 20news-bydate.tar.gz wget http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz
步驟2:建立序列檔案
使用seqdirectory實用程式從示例建立序列檔案。生成序列的語法如下所示
mahout seqdirectory -i <input file path> -o <output directory>
步驟3:將序列檔案轉換為向量
使用seq2parse實用程式從序列檔案建立向量檔案。seq2parse實用程式的選項如下所示
$MAHOUT_HOME/bin/mahout seq2sparse --analyzerName (-a) analyzerName The class name of the analyzer --chunkSize (-chunk) chunkSize The chunkSize in MegaBytes. --output (-o) output The directory pathname for o/p --input (-i) input Path to job input directory.
步驟4:訓練向量
使用trainnb實用程式訓練生成的向量。使用trainnb實用程式的選項如下所示
mahout trainnb
-i ${PATH_TO_TFIDF_VECTORS}
-el
-o ${PATH_TO_MODEL}/model
-li ${PATH_TO_MODEL}/labelindex
-ow
-c
步驟5:測試向量
使用testnb實用程式測試向量。使用testnb實用程式的選項如下所示
mahout testnb
-i ${PATH_TO_TFIDF_TEST_VECTORS}
-m ${PATH_TO_MODEL}/model
-l ${PATH_TO_MODEL}/labelindex
-ow
-o ${PATH_TO_OUTPUT}
-c
-seq