- Keras 教程
- Keras - 首頁
- Keras - 簡介
- Keras - 安裝
- Keras - 後端配置
- Keras - 深度學習概述
- Keras - 深度學習
- Keras - 模組
- Keras - 層
- Keras - 自定義層
- Keras - 模型
- Keras - 模型編譯
- Keras - 模型評估和預測
- Keras - 卷積神經網路
- Keras - 使用 MPL 進行迴歸預測
- Keras - 使用 LSTM RNN 進行時間序列預測
- Keras - 應用
- Keras - 使用 ResNet 模型進行即時預測
- Keras - 預訓練模型
- Keras 有用資源
- Keras - 快速指南
- Keras - 有用資源
- Keras - 討論
Keras - 使用 LSTM RNN 進行時間序列預測
在本章中,讓我們編寫一個簡單的基於長短期記憶 (LSTM) 的 RNN 來進行序列分析。序列是一組值,其中每個值對應於特定時間例項。讓我們考慮一個閱讀句子的簡單例子。閱讀和理解句子涉及按給定順序閱讀單詞,並嘗試理解每個單詞及其在給定上下文中的含義,最後以正面或負面情緒理解句子。
這裡,單詞被視為值,第一個值對應於第一個單詞,第二個值對應於第二個單詞,依此類推,並且順序將嚴格保持。序列分析經常用於自然語言處理中,以查詢給定文字的情感分析。
讓我們建立一個 LSTM 模型來分析 IMDB 電影評論並找到其正面/負面情緒。
序列分析模型可以表示如下:
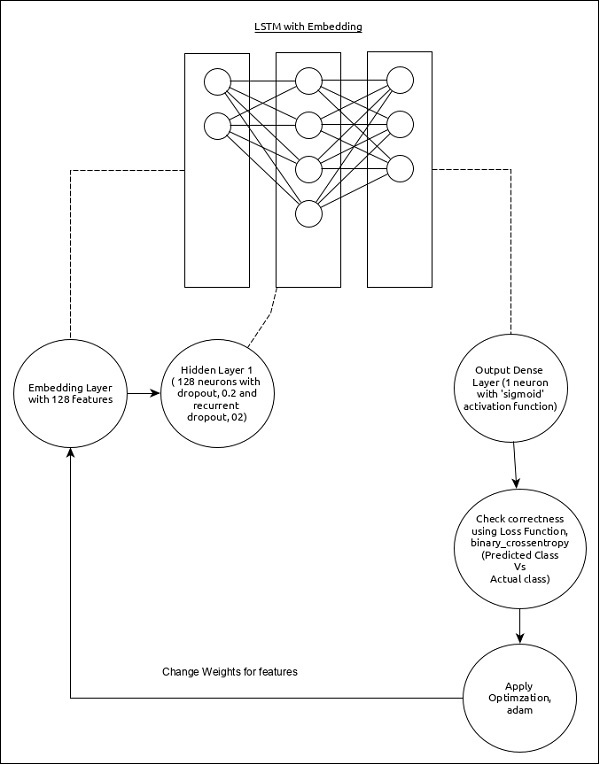
模型的核心特徵如下:
使用具有 128 個特徵的嵌入層作為輸入層。
第一層,密集層包含 128 個單元,正常 dropout 和迴圈 dropout 設定為 0.2。
輸出層,密集層包含 1 個單元和“sigmoid”啟用函式。
使用binary_crossentropy作為損失函式。
使用adam作為最佳化器。
使用accuracy作為指標。
使用 32 作為批次大小。
使用 15 作為輪數。
使用 80 作為單詞的最大長度。
使用 2000 作為給定句子中單詞的最大數量。
步驟 1:匯入模組
讓我們匯入必要的模組。
from keras.preprocessing import sequence from keras.models import Sequential from keras.layers import Dense, Embedding from keras.layers import LSTM from keras.datasets import imdb
步驟 2:載入資料
讓我們匯入 imdb 資料集。
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = 2000)
這裡:
imdb 是 Keras 提供的資料集。它表示電影及其評論的集合。
num_words 表示評論中單詞的最大數量。
步驟 3:處理資料
讓我們根據我們的模型更改資料集,以便可以將其饋送到我們的模型中。可以使用以下程式碼更改資料:
x_train = sequence.pad_sequences(x_train, maxlen=80) x_test = sequence.pad_sequences(x_test, maxlen=80)
這裡:
sequence.pad_sequences 將形狀為(data)的輸入資料列表轉換為形狀為(data, timesteps)的二維 NumPy 陣列。基本上,它在給定資料中添加了 timesteps 概念。它生成長度為maxlen的時間步長。
步驟 4:建立模型
讓我們建立實際的模型。
model = Sequential() model.add(Embedding(2000, 128)) model.add(LSTM(128, dropout = 0.2, recurrent_dropout = 0.2)) model.add(Dense(1, activation = 'sigmoid'))
這裡:
我們使用嵌入層作為輸入層,然後新增 LSTM 層。最後,使用密集層作為輸出層。
步驟 5:編譯模型
讓我們使用選擇的損失函式、最佳化器和指標來編譯模型。
model.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
步驟 6:訓練模型
讓我們使用fit()方法訓練模型。
model.fit( x_train, y_train, batch_size = 32, epochs = 15, validation_data = (x_test, y_test) )
執行應用程式將輸出以下資訊:
Epoch 1/15 2019-09-24 01:19:01.151247: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not co mpiled to use: AVX2 25000/25000 [==============================] - 101s 4ms/step - loss: 0.4707 - acc: 0.7716 - val_loss: 0.3769 - val_acc: 0.8349 Epoch 2/15 25000/25000 [==============================] - 95s 4ms/step - loss: 0.3058 - acc: 0.8756 - val_loss: 0.3763 - val_acc: 0.8350 Epoch 3/15 25000/25000 [==============================] - 91s 4ms/step - loss: 0.2100 - acc: 0.9178 - val_loss: 0.5065 - val_acc: 0.8110 Epoch 4/15 25000/25000 [==============================] - 90s 4ms/step - loss: 0.1394 - acc: 0.9495 - val_loss: 0.6046 - val_acc: 0.8146 Epoch 5/15 25000/25000 [==============================] - 90s 4ms/step - loss: 0.0973 - acc: 0.9652 - val_loss: 0.5969 - val_acc: 0.8147 Epoch 6/15 25000/25000 [==============================] - 98s 4ms/step - loss: 0.0759 - acc: 0.9730 - val_loss: 0.6368 - val_acc: 0.8208 Epoch 7/15 25000/25000 [==============================] - 95s 4ms/step - loss: 0.0578 - acc: 0.9811 - val_loss: 0.6657 - val_acc: 0.8184 Epoch 8/15 25000/25000 [==============================] - 97s 4ms/step - loss: 0.0448 - acc: 0.9850 - val_loss: 0.7452 - val_acc: 0.8136 Epoch 9/15 25000/25000 [==============================] - 95s 4ms/step - loss: 0.0324 - acc: 0.9894 - val_loss: 0.7616 - val_acc: 0.8162Epoch 10/15 25000/25000 [==============================] - 100s 4ms/step - loss: 0.0247 - acc: 0.9922 - val_loss: 0.9654 - val_acc: 0.8148 Epoch 11/15 25000/25000 [==============================] - 99s 4ms/step - loss: 0.0169 - acc: 0.9946 - val_loss: 1.0013 - val_acc: 0.8104 Epoch 12/15 25000/25000 [==============================] - 90s 4ms/step - loss: 0.0154 - acc: 0.9948 - val_loss: 1.0316 - val_acc: 0.8100 Epoch 13/15 25000/25000 [==============================] - 89s 4ms/step - loss: 0.0113 - acc: 0.9963 - val_loss: 1.1138 - val_acc: 0.8108 Epoch 14/15 25000/25000 [==============================] - 89s 4ms/step - loss: 0.0106 - acc: 0.9971 - val_loss: 1.0538 - val_acc: 0.8102 Epoch 15/15 25000/25000 [==============================] - 89s 4ms/step - loss: 0.0090 - acc: 0.9972 - val_loss: 1.1453 - val_acc: 0.8129 25000/25000 [==============================] - 10s 390us/step
步驟 7 - 評估模型
讓我們使用測試資料評估模型。
score, acc = model.evaluate(x_test, y_test, batch_size = 32)
print('Test score:', score)
print('Test accuracy:', acc)
執行上述程式碼將輸出以下資訊:
Test score: 1.145306069601178 Test accuracy: 0.81292