
- JCL 教程
- JCL 首頁
- JCL - 概述
- JCL - 環境
- JCL - JOB 語句
- JCL - EXEC 語句
- JCL - DD 語句
- JCL - 基本庫
- JCL - 過程
- JCL - 條件處理
- JCL - 定義資料集
- JCL - 輸入/輸出方法
- JCL - 執行 COBOL 程式
- JCL - 實用程式
- JCL - 基本排序技巧
- JCL 有用資源
- JCL - 問題與解答
- JCL 快速指南
- JCL - 有用資源
- JCL - 討論
JCL 快速指南
JCL - 概述
何時使用 JCL
JCL 用於大型機環境中,作為程式(例如:COBOL、彙編程式或 PL/I)與作業系統之間的通訊手段。在大型機環境中,程式可以以批處理和聯機模式執行。批處理系統的示例可以透過 VSAM(虛擬儲存訪問方法)檔案處理銀行交易並將其應用於相應的賬戶。聯機系統的示例可以是銀行員工用來開戶的後端螢幕。在批處理模式下,程式作為作業透過 JCL 提交給作業系統。
批處理和聯機處理在輸入、輸出和程式執行請求方面有所不同。在批處理中,這些方面被輸入到 JCL 中,JCL 又被作業系統接收。
作業處理
作業是工作單元,可以由多個作業步驟組成。每個作業步驟都透過一組作業控制語句在作業控制語言 (JCL) 中指定。
作業系統使用作業輸入系統 (JES) 將作業接收進入作業系統、安排作業進行處理並控制輸出。
作業處理經歷以下一系列步驟
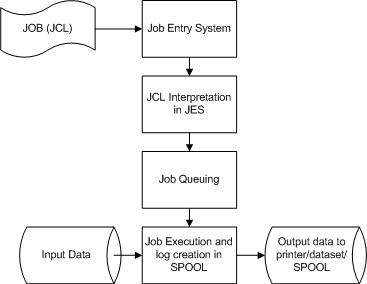
作業提交 - 將 JCL 提交給 JES。
作業轉換 - JCL 以及 PROC 被轉換為 JES 可以理解的解釋文字,並存儲到一個數據集(我們稱之為 SPOOL)中。
作業排隊 - JES 根據 JOB 語句中的 CLASS 和 PRTY 引數(在JCL - JOB 語句章節中解釋)確定作業的優先順序。檢查 JCL 錯誤,如果無錯誤,則將作業排程到作業佇列中。
作業執行 - 當作業達到最高優先順序時,它將從作業佇列中取出執行。從 SPOOL 中讀取 JCL,執行程式,並將輸出重定向到 JCL 中指定的相應輸出目標。
清除 - 作業完成後,釋放分配的資源和 JES SPOOL 空間。為了儲存作業日誌,我們需要在它從 SPOOL 中釋放之前將作業日誌複製到另一個數據集。
JCL - 環境設定
在 Windows/Linux 上安裝 JCL
有許多可用於 Windows 的免費大型機模擬器,可用於編寫和學習 JCL 示例。
其中一個模擬器是 Hercules,可以透過以下幾個簡單的步驟輕鬆安裝在 Windows 上
下載並安裝 Hercules 模擬器,可從 Hercules 的主頁獲取:www.hercules-390.eu
在 Windows 機器上安裝軟體包後,它將建立一個名為C:\Mainframes的資料夾。
執行命令提示符 (CMD) 並在 CMD 中到達 C:\Mainframes 目錄。
有關編寫和執行 JCL 的各種命令的完整指南可以在 URL www.jaymoseley.com/hercules/installmvs/instmvs2.htm 上找到。
Hercules 是大型機 System/370 和 ESA/390 架構以及最新的 64 位 z/Architecture 的開源軟體實現。Hercules 在 Linux、Windows、Solaris、FreeBSD 和 Mac OS X 上執行。
在大型機上執行 JCL
使用者可以透過多種方式連線到大型機伺服器,例如瘦客戶端、虛擬終端、虛擬客戶端系統 (VCS) 或虛擬桌面系統 (VDS)。
每個有效使用者都會獲得一個登入 ID,用於輸入 Z/OS 介面(TSO/E 或 ISPF)。在 Z/OS 介面中,可以對 JCL 進行編碼並將其儲存為分割槽資料集 (PDS) 中的一個成員。提交 JCL 後,它將被執行,並根據上一章的作業處理部分中所述接收輸出。
JCL 的結構
下面給出了包含常用語句的 JCL 的基本結構
//SAMPJCL JOB 1,CLASS=6,MSGCLASS=0,NOTIFY=&SYSUID (1) //* (2) //STEP010 EXEC PGM=SORT (3) //SORTIN DD DSN=JCL.SAMPLE.INPUT,DISP=SHR (4) //SORTOUT DD DSN=JCL.SAMPLE.OUTPUT, (5) // DISP=(NEW,CATLG,CATLG),DATACLAS=DSIZE50 //SYSOUT DD SYSOUT=* (6) //SYSUDUMP DD SYSOUT=C (6) //SYSPRINT DD SYSOUT=* (6) //SYSIN DD * (6) SORT FIELDS=COPY INCLUDE COND=(28,3,CH,EQ,C'XXX') /* (7)
程式描述
下面解釋了編號的 JCL 語句
(1) JOB 語句 - 指定 SPOOL 作業所需的資訊,例如作業 ID、執行優先順序、作業完成後要通知的使用者 ID。
(2) //* 語句 - 這是一個註釋語句。
(3) EXEC 語句 - 指定要執行的 PROC/程式。在上面的示例中,正在執行 SORT 程式(即,按特定順序對輸入資料進行排序)
(4) 輸入 DD 語句 - 指定要傳遞給 (3) 中提到的程式的輸入型別。在上面的示例中,物理順序 (PS) 檔案以共享模式 (DISP = SHR) 作為輸入傳遞。
(5) 輸出 DD 語句 - 指定程式執行後要產生的輸出型別。在上面的示例中,建立了一個 PS 檔案。如果語句超過一行中的第 70 個位置,則在下一行繼續,下一行應以“//”後跟一個或多個空格開頭。
(6) 可以有其他型別的 DD 語句來向程式指定其他資訊(在上面的示例中:SYSIN DD 語句中指定了排序條件)並指定錯誤/執行日誌的目標(示例:SYSUDUMP/SYSPRINT)。DD 語句可以包含在資料集(大型機檔案)中,也可以作為流資料(硬編碼在 JCL 中的資訊)包含在上面示例中。
(7) /* 標記流資料結束。
除流資料外,所有 JCL 語句都以 // 開頭。JOB、EXEC 和 DD 關鍵字前後至少應有一個空格,其餘語句中不應有空格。
JOB 引數型別
每個 JCL 語句都帶有一組引數,以幫助作業系統完成程式執行。引數可以分為兩種型別
位置引數
出現在語句中預定義的位置和順序。示例:會計資訊引數只能出現在JOB關鍵字之後,程式設計師名稱引數和關鍵字引數之前。如果省略位置引數,則必須用逗號替換。
位置引數存在於 JOB 和 EXEC 語句中。在上面的示例中,PGM 是在EXEC關鍵字之後編碼的位置引數。
關鍵字引數
它們編碼在位置引數之後,但可以按任何順序出現。如果不需要,可以省略關鍵字引數。通用語法為 KEYWORD= value。示例:MSGCLASS=X,即作業完成後作業日誌重定向到輸出 SPOOL。
在上面的示例中,CLASS、MSGCLASS 和 NOTIFY 是 JOB 語句的關鍵字引數。EXEC 語句中也可以有關鍵字引數。
這些引數將在後續章節中結合相應的示例進行詳細說明。
JCL - JOB 語句
JOB 語句是 JCL 中的第一個控制語句。它向作業系統 (OS)、SPOOL 和排程程式提供作業的標識。JOB 語句中的引數幫助作業系統分配正確的排程程式、所需的 CPU 時間並向用戶發出通知。
語法
以下是 JCL JOB 語句的基本語法
//Job-name JOB Positional-param, Keyword-param
描述
讓我們看看上面 JOB 語句語法中使用的術語的描述。
作業名
在將作業提交到 OS 時,這將為作業提供一個 ID。它的長度可以為 1 到 8 個字母數字字元,並且緊跟在 // 之後。
JOB
這是識別它為 JOB 語句的關鍵字。
位置引數
有位置引數,可以分為兩種型別
| 位置引數 | 描述 |
|---|---|
| 賬戶資訊 | 這指的是擁有 CPU 時間的人或組。它根據擁有大型機的公司的規則進行設定。如果將其指定為 (*),則它採用當前登入到大型機終端的使用者 ID。 |
| 程式設計師姓名 | 這標識負責 JCL 的人員或組。這不是必填引數,可以用逗號替換。 |
關鍵字引數
以下是可以在 JOB 語句中使用的各種關鍵字引數。您可以根據需要使用一個或多個引數,並且它們用逗號分隔
| 關鍵字引數 | 描述 |
|---|---|
| CLASS | 根據作業所需的時間長度和資源數量,公司分配不同的作業類別。這些可以被視為 OS 用於接收作業的單個排程程式。將作業放入正確的排程程式中將有助於輕鬆執行作業。一些公司在測試和生產環境中為作業設定不同的類別。 CLASS 引數的有效值為 A 到 Z 字元和 0 到 9 數字(長度為 1)。以下是語法 CLASS=0 到 9 | A 到 Z |
| PRTY | 指定作業在作業類別中的優先順序。如果未指定此引數,則作業將新增到指定 CLASS 中佇列的末尾。以下是語法 PRTY=N 其中 N 是 0 到 15 之間的數字,數字越大,優先順序越高。 |
| NOTIFY | 系統將成功或失敗訊息(最大條件程式碼)傳送到此引數中指定的使用者。以下是語法 NOTIFY="userid | &SYSUID" 在這裡,系統將訊息傳送到使用者“userid”,但如果我們使用 NOTIFY = &SYSUID,則訊息將傳送到提交 JCL 的使用者。 |
| MSGCLASS | 指定作業完成後系統和作業訊息的輸出目標。以下是語法 MSGCLASS=CLASS CLASS 的有效值可以是“A”到“Z”和“0”到“9”。可以將 MSGCLASS = Y 設定為一個類別,以將作業日誌傳送到 JMR(JOBLOG 管理和檢索:大型機內用於儲存作業統計資訊的儲存庫)。 |
| MSGLEVEL | 指定要寫入 MSGCLASS 中指定的輸出目標的訊息型別。以下是語法 MSGLEVEL=(ST, MSG) ST = 寫入輸出日誌的語句型別
MSG = 寫入輸出日誌的訊息型別。
|
| TYPRUN | 指定作業的特殊處理。以下是語法 TYPRUN = SCAN | HOLD 其中 SCAN 和 HOLD 具有以下描述
|
| TIME | 指定處理器執行作業所需的時間跨度。以下是語法 TIME=(mm, ss) 或 TIME=ss 其中 mm = 分鐘,ss = 秒 此引數在測試新編寫的程式時很有用。為了確保程式不會因迴圈錯誤而長時間執行,可以編寫時間引數,以便在達到指定的 CPU 時間時程式異常終止。 |
| REGION | 指定作業內作業步驟執行所需的地址空間。以下是語法 REGION=nK | nM 這裡,region 可以指定為 nK 或 nM,其中 n 是一個數字,K 是千位元組,M 是兆位元組。 當 REGION = 0K 或 0M 時,將提供最大的地址空間進行執行。在關鍵應用程式中,禁止編碼 0K 或 0M 以避免浪費地址空間。 |
示例
//URMISAMP JOB (*),"tutpoint",CLASS=6,PRTY=10,NOTIFY=&SYSUID, // MSGCLASS=X,MSGLEVEL=(1,1),TYPRUN=SCAN, // TIME=(3,0),REGION=10K
這裡,JOB 語句在一行中擴充套件到第 70 位之後,因此我們在下一行繼續,下一行應以“//”後跟一個或多個空格開頭。
其他引數
還有其他一些引數可以與 JOB 語句一起使用,但它們不常使用
| ADDRSPC | 使用的儲存型別:虛擬或真實 |
| BYTES | 要寫入輸出日誌的資料大小以及超過該大小時要採取的操作。 |
| LINES | 要列印到輸出日誌的最大行數。 |
| PAGES | 要列印到輸出日誌的最大頁數。 |
| USER | 用於提交作業的使用者 ID。 |
| PASSWORD | USER 引數中指定的使用者 ID 的密碼。 |
| COND 和 RESTART | 這些用於條件作業步驟處理,在討論條件處理時將詳細解釋。 |
JCL - EXEC 語句
每個 JCL 可以由許多作業步驟組成。每個作業步驟可以直接執行程式或呼叫過程,該過程依次執行一個或多個程式(作業步驟)。包含作業步驟程式/過程資訊的語句是EXEC 語句。
EXEC 語句的目的是為在作業步驟中執行的程式/過程提供必要的資訊。在此語句中編碼的引數可以將資料傳遞給正在執行的程式,可以覆蓋 JOB 語句的某些引數,並且如果 EXEC 語句呼叫過程而不是直接執行程式,則可以將引數傳遞給該過程。
語法
以下是 JCL EXEC 語句的基本語法
//Step-name EXEC Positional-param, Keyword-param
描述
讓我們看看上面 EXEC 語句語法中使用的術語的描述。
STEP-NAME
這標識 JCL 中的作業步驟。它可以是長度為 1 到 8 的字母數字字元。
EXEC
這是識別它是 EXEC 語句的關鍵字。
POSITIONAL-PARAM
這些是位置引數,可以分為兩種型別
| 位置引數 | 描述 |
|---|---|
| PGM | 這指的是要在作業步驟中執行的程式名稱。 |
| PROC | 這指的是要在作業步驟中執行的過程名稱。我們將在單獨的章節中討論它。 |
KEYWORD-PARAM
以下是 EXEC 語句的各種關鍵字引數。您可以根據需要使用一個或多個引數,並且它們用逗號分隔
| 關鍵字引數 | 描述 |
|---|---|
| PARM | 用於向作業步驟中正在執行的程式提供引數化資料。這是一個程式相關的欄位,沒有明確的規則,除非 PARM 值在包含特殊字元的情況下必須包含在引號中。 例如,以下給出的值“CUST1000”作為字母數字值傳遞給程式。如果程式在 COBOL 中,則透過 JCL 中的 PARM 引數傳遞的值將在程式的 LINKAGE SECTION 中接收。 |
| ADDRSPC | 這用於指定作業步驟是否需要虛擬或真實儲存來執行。虛擬儲存是可分頁的,而真實儲存不可分頁,並且放置在主記憶體中以供執行。需要更快執行的作業步驟可以放置在真實儲存中。以下是語法 ADDRSPC=VIRT | REAL 當未編碼 ADDRSPC 時,VIRT 是預設值。 |
| ACCT | 這指定作業步驟的會計資訊。以下是語法 ACCT=(userid) 這類似於 JOB 語句中的位置引數會計資訊。如果它在 JOB 和 EXEC 語句中都進行了編碼,則 JOB 語句中的會計資訊將應用於所有未編碼 ACCT 引數的作業步驟。EXEC 語句中的 ACCT 引數將僅覆蓋該作業步驟中存在的 JOB 語句中的引數。 |
EXEC 和 JOB 語句的常用關鍵字引數
| 關鍵字引數 | 描述 |
|---|---|
| ADDRSPC | JOB 語句中編碼的 ADDRSPC 覆蓋任何作業步驟的 EXEC 語句中編碼的 ADDRSPC。 |
| TIME | 如果在 EXEC 語句中編碼了 TIME,則它僅適用於該作業步驟。如果它在 JOB 和 EXEC 語句中都指定,則兩者都將生效,並且可能由於其中任何一個導致超時錯誤。不建議同時在 JOB 和 EXEC 語句中一起使用 TIME 引數。 |
| REGION | 如果在 EXEC 語句中編碼了 REGION,則它僅適用於該作業步驟。 JOB 語句中編碼的 REGION 覆蓋任何作業步驟的 EXEC 語句中編碼的 REGION。 |
| COND | 用於根據上一步的返回碼控制作業步驟的執行。 如果在作業步驟的 EXEC 語句中編碼了 COND 引數,則忽略 JOB 語句(如果存在)的 COND 引數。可以使用 COND 引數執行的各種測試將在條件處理中解釋。 |
示例
以下是一個簡單的 JCL 指令碼示例,以及 JOB 和 EXEC 語句
//TTYYSAMP JOB 'TUTO',CLASS=6,MSGCLASS=X,REGION=8K, // NOTIFY=&SYSUID //* //STEP010 EXEC PGM=MYCOBOL,PARAM=CUST1000, // ACCT=(XXXX),REGION=8K,ADDRSPC=REAL,TIME=1440
JCL - DD 語句
資料集是具有以特定格式組織的記錄的主機檔案。資料集儲存在主機系統的直接訪問儲存裝置 (DASD) 或磁帶上,並且是基本的資料儲存區域。如果需要在批處理程式中使用/建立這些資料,則檔案(即資料集)物理名稱以及檔案格式和組織將在 JCL 中進行編碼。
使用DD 語句給出 JCL 中使用的每個資料集的定義。作業步驟所需的輸入和輸出資源需要在 DD 語句中進行描述,其中包含資料集組織、儲存需求和記錄長度等資訊。
語法
以下是 JCL DD 語句的基本語法
//DD-name DD Parameters
描述
讓我們看看上面 DD 語句語法中使用的術語的描述。
DD-NAME
DD-NAME 標識資料集或輸入/輸出資源。如果這是 COBOL/彙編程式使用的輸入/輸出檔案,則程式在程式中引用該檔案。
DD
這是識別它是 DD 語句的關鍵字。
PARAMETERS
以下是 DD 語句的各種引數。您可以根據需要使用一個或多個引數,並且它們用逗號分隔
| 引數 | 描述 |
|---|---|
| DSN | DSN 引數指的是新建立或現有資料集的物理資料集名稱。DSN 值可以由每個長度為 1 到 8 個字元的子名稱組成,用句點分隔,總長度為 44 個字元(字母數字)。以下是語法 DSN=物理資料集名稱 臨時資料集僅在作業持續時間內需要儲存,並在作業完成時刪除。此類資料集表示為DSN=&name或根本不指定 DSN。 如果作業步驟建立的臨時資料集要在下一個作業步驟中使用,則將其引用為DSN=*.stepname.ddname。這稱為後向引用。 |
| DISP | DISP 引數用於描述資料集的狀態,以及在作業步驟正常和異常完成時結束時的處理方式。僅當資料集在同一作業步驟中建立和刪除(如臨時資料集)時,DD 語句中不需要 DISP。以下是語法 DISP=(status, normal-disposition, abnormal-disposition) 以下是status的有效值
normal-disposition引數可以取以下值之一
abnormal-disposition引數可以取以下值之一
以下是 CATLG、UNCATLG、DELETE、PASS 和 KEEP 引數的描述
當 DISP 的任何子引數未指定時,預設值如下所示
|
| DCB | 資料控制塊 (DCB) 引數詳細說明了資料集的物理特徵。此引數對於在作業步驟中新建立的資料集是必需的。 LRECL 是資料集內每個記錄的長度。 RECFM 是資料集的記錄格式。RECFM 可以儲存 FB、V 或 VB 值。FB 是固定塊組織,其中一個或多個邏輯記錄分組在一個塊內。V 是可變組織,其中一個可變長度的邏輯記錄放置在一個物理塊內。VB 是可變塊組織,其中一個或多個可變長度的邏輯記錄放置在一個物理塊內。 BLKSIZE 是物理塊的大小。塊越大,FB 或 VB 檔案的記錄數量就越多。 DSORG 是資料集組織的型別。DSORG 可以儲存 PS(物理順序)、PO(分割槽組織)和 DA(直接組織)值。 當需要將一個數據集的 DCB 值複製到同一作業步驟或 JCL 中的另一個數據集時,則將其指定為 DCB=*.stepname.ddname,其中 stepname 是作業步驟的名稱,ddname 是複製 DCB 的資料集。 請檢視以下示例,其中 RECFM=FB、LRECL=80 構成資料集 OUTPUT1 的 DCB。 |
| SPACE | SPACE 引數指定資料集在 DASD(直接訪問儲存磁碟)中所需的儲存空間。以下是語法 SPACE=(spcunits, (pri, sec, dir), RLSE) 以下是所有使用引數的說明
|
| UNIT | UNIT 和 VOL 引數列在系統目錄中以供編目資料集使用,因此只需使用物理 DSN 名稱即可訪問它們。但是對於未編目的資料集,DD 語句應包含這些引數。對於要建立的新資料集,可以指定 UNIT/VOL 引數,或者 Z/OS 分配合適的裝置和卷。 UNIT 引數指定儲存資料集的裝置型別。可以使用硬體地址或裝置型別組識別裝置型別。以下是語法 UNIT=DASD | SYSDA 其中 DASD 代表直接訪問儲存裝置,SYSDA 代表系統直接訪問,並指下一個可用的磁碟儲存裝置。 |
| VOL | VOL 引數指定由 UNIT 引數標識的裝置上的卷號。以下是語法 VOL=SER=(v1,v2) 其中 v1、v2 是卷序列號。您也可以使用以下語法 VOL=REF=*.DDNAME 其中 REF 是對 JCL 中任何先前作業步驟中的資料集的卷序列號的反向引用。 |
| SYSOUT | 到目前為止討論的 DD 語句引數對應於儲存在資料集中的資料。SYSOUT 引數根據指定的類將資料定向到輸出裝置。以下是語法 SYSOUT=class 其中,如果 class 為 A,則將其輸出定向到印表機,如果 class 為 *,則將其輸出定向到與 JOB 語句中的 MSGCLASS 引數相同的目標。 |
示例
以下是一個示例,它使用 DD 語句以及上面解釋的各種引數
//TTYYSAMP JOB 'TUTO',CLASS=6,MSGCLASS=X,REGION=8K, // NOTIFY=&SYSUID //* //STEP010 EXEC PGM=ICETOOL,ADDRSPC=REAL //* //INPUT1 DD DSN=TUTO.SORT.INPUT1,DISP=SHR //INPUT2 DD DSN=TUTO.SORT.INPUT2,DISP=SHR,UNIT=SYSDA, // VOL=SER=(1243,1244) //OUTPUT1 DD DSN=MYFILES.SAMPLE.OUTPUT1,DISP=(,CATLG,DELETE), // RECFM=FB,LRECL=80,SPACE=(CYL,(10,20)) //OUTPUT2 DD SYSOUT=*
JCL - 基本庫
基本庫是分割槽資料集 (PDS),它儲存要在 JCL 中執行的程式的載入模組或在程式中呼叫的編目過程。基本庫可以在整個 JCL 中的 JOBLIB 庫中指定,或者在特定作業步驟的 STEPLIB 語句中指定。
JOBLIB 語句
JOBLIB 語句用於識別要在 JCL 中執行的程式的位置。JOBLIB 語句在 JOB 語句之後和 EXEC 語句之前指定。這隻能用於流內過程和程式。
語法
以下是 JCL JOBLIB 語句的基本語法
//JOBLIB DD DSN=dsnname,DISP=SHR
JOBLIB 語句適用於 JCL 中的所有 EXEC 語句。EXEC 語句中指定的程式將在 JOBLIB 庫中搜索,然後在系統庫中搜索。
例如,如果 EXEC 語句正在執行 COBOL 程式,則 COBOL 程式的載入模組應放置在 JOBLIB 庫中。
STEPLIB 語句
STEPLIB 語句用於識別要在作業步驟內執行的程式的位置。STEPLIB 語句在 EXEC 語句之後和作業步驟的 DD 語句之前指定。
語法
以下是 JCL STEPLIB 語句的基本語法
//STEPLIB DD DSN=dsnname,DISP=SHR
EXEC 語句中指定的程式將在 STEPLIB 庫中搜索,然後在系統庫中搜索。在作業步驟中編碼的 STEPLIB 覆蓋 JOBLIB 語句。
示例
以下示例顯示了 JOBLIB 和 STEPLIB 語句的用法
//MYJCL JOB ,,CLASS=6,NOTIFY=&SYSUID //* //JOBLIB DD DSN=MYPROC.BASE.LIB1,DISP=SHR //* //STEP1 EXEC PGM=MYPROG1 //INPUT1 DD DSN=MYFILE.SAMPLE.INPUT1,DISP=SHR //OUTPUT1 DD DSN=MYFILES.SAMPLE.OUTPUT1,DISP=(,CATLG,DELETE), // RECFM=FB,LRECL=80 //* //STEP2 EXEC PGM=MYPROG2 //STEPLIB DD DSN=MYPROC.BASE.LIB2,DISP=SHR //INPUT2 DD DSN=MYFILE.SAMPLE.INPUT2,DISP=SHR //OUTPUT2 DD DSN=MYFILES.SAMPLE.OUTPUT2,DISP=(,CATLG,DELETE), // RECFM=FB,LRECL=80
此處,程式 MYPROG1(在 STEP1 中)的載入模組在 MYPROC.SAMPLE.LIB1 中搜索。如果未找到,則在系統庫中搜索。在 STEP2 中,STEPLIB 覆蓋 JOBLIB,程式 MYPROG2 的載入模組在 MYPROC.SAMPLE.LIB2 中搜索,然後在系統庫中搜索。
INCLUDE 語句
使用 INCLUDE 語句可以將編碼在 PDS 成員中的 JCL 語句集包含到 JCL 中。當 JES 解釋 JCL 時,INCLUDE 成員中的 JCL 語句集將替換 INCLUDE 語句。
語法
以下是 JCL INCLUDE 語句的基本語法
//name INCLUDE MEMBER=member-name
INCLUDE 語句的主要目的是可重用性。例如,要在許多 JCL 中使用的公共檔案可以作為 DD 語句編碼在 INCLUDE 成員中,並在 JCL 中使用。
虛擬 DD 語句、資料卡規範、PROC、JOB、PROC 語句不能編碼在 INCLUDE 成員中。INCLUDE 語句可以編碼在 INCLUDE 成員中,並且可以進一步巢狀最多 15 層。
JCLLIB 語句
JCLLIB 語句用於識別作業中使用的私有庫。它可以與流內過程和編目過程一起使用。
語法
以下是 JCL JCLLIB 語句的基本語法
//name JCLLIB ORDER=(library1, library2....)
JCLLIB 語句中指定的庫將按給定順序搜尋,以找到作業中使用的程式、過程和 INCLUDE 成員。JCL 中只能有一個 JCLLIB 語句;在 JOB 語句之後和 EXEC 和 INCLUDE 語句之前指定,但不能在 INCLUDE 成員中編碼。
示例
在以下示例中,程式 MYPROG3 和 INCLUDE 成員 MYINCL 按 MYPROC.BASE.LIB1、MYPROC.BASE.LIB2、系統庫的順序搜尋。
//MYJCL JOB ,,CLASS=6,NOTIFY=&SYSUID //* //MYLIB JCLLIB ORDER=(MYPROC.BASE.LIB1,MYPROC.BASE.LIB2) //* //STEP1 EXEC PGM=MYPROG3 //INC INCLUDE MEMBER=MYINCL //OUTPUT1 DD DSN=MYFILES.SAMPLE.OUTPUT1,DISP=(,CATLG,DELETE), // RECFM=FB,LRECL=80 //*
JCL - 過程
JCL 過程是 JCL 內的一組語句,它們組合在一起以執行特定功能。通常,JCL 的固定部分編碼在過程中。作業的可變部分編碼在 JCL 中。
您可以使用過程來實現使用多個輸入檔案的程式的並行執行。可以為每個輸入檔案建立一個 JCL,並且可以透過將輸入檔名作為符號引數傳遞來同時呼叫單個過程。
語法
以下是 JCL 過程定義的基本語法
//* //Step-name EXEC procedure name
對於流內過程,過程的內容儲存在 JCL 中。對於編目過程,內容儲存在基本庫的不同成員中。本章將解釋 JCL 中可用的兩種過程型別,然後我們將瞭解如何巢狀各種過程。
流內過程
當過程編碼在同一 JCL 成員中時,稱為流內過程。它應以 PROC 語句開頭,以 PEND 語句結尾。
//SAMPINST JOB 1,CLASS=6,MSGCLASS=Y,NOTIFY=&SYSUID //* //INSTPROC PROC //*START OF PROCEDURE //PROC1 EXEC PGM=SORT //SORTIN DD DSN=&DSNAME,DISP=SHR //SORTOUT DD SYSOUT=*MYINCL //SYSOUT DD SYSOUT=* //SYSIN DD DSN=&DATAC LRECL=80 // PEND //*END OF PROCEDURE //* //STEP1 EXEC INSTPROC,DSNME=MYDATA.URMI.INPUT1, // DATAC=MYDATA.BASE.LIB1(DATA1) //* //STEP2 EXEC INSTPROC,DSNME=MYDATA.URMI.INPUT2 // DATAC=MYDATA.BASE.LIB1(DATA1) //*
在上面的示例中,過程 INSTPROC 在 STEP1 和 STEP2 中使用不同的輸入檔案呼叫。引數 DSNAME 和 DATAC 可以使用不同的值進行編碼,並在呼叫過程時使用,這些稱為 符號引數。JCL 的可變輸入(如檔名、資料卡、PARM 值等)作為符號引數傳遞給過程。
在編碼符號引數時,不要使用 KEYWORDS、PARAMETERS 或 SUB-PARAMETERS 作為符號名稱。例如:不要使用 TIME=&TIME,但可以使用 TIME=&TM,並且假定這是正確的符號編碼方式。
使用者定義的符號引數稱為 JCL 符號。有一些稱為 系統符號的符號,用於登入作業執行。普通使用者在批處理作業中使用的唯一系統符號是 &SYSUID,它用於 JOB 語句中的 NOTIFY 引數。
編目過程
當過程與 JCL 分開並編碼在不同的資料儲存中時,稱為 編目過程。編目過程中不需要強制編碼 PROC 語句。以下是在 JCL 中呼叫 CATLPROC 過程的示例
//SAMPINST JOB 1,CLASS=6,MSGCLASS=Y,NOTIFY=&SYSUID //* //STEP EXEC CATLPROC,PROG=CATPRC1,DSNME=MYDATA.URMI.INPUT // DATAC=MYDATA.BASE.LIB1(DATA1)
此處,過程 CATLPROC 編目在 MYCOBOL.BASE.LIB1 中。PROG、DATAC 和 DSNAME 作為符號引數傳遞給過程 CATLPROC。
//CATLPROC PROC PROG=,BASELB=MYCOBOL.BASE.LIB1 //* //PROC1 EXEC PGM=&PROG //STEPLIB DD DSN=&BASELB,DISP=SHR //IN1 DD DSN=&DSNAME,DISP=SHR //OUT1 DD SYSOUT=* //SYSOUT DD SYSOUT=* //SYSIN DD DSN=&DATAC //*
在過程中,編碼了符號引數 PROG 和 BASELB。請注意,過程中的 PROG 引數被 JCL 中的值覆蓋,因此 PGM 在執行期間取值為 CATPRC1。
巢狀過程
從過程內部呼叫過程稱為 巢狀過程。過程可以巢狀最多 15 層。巢狀可以完全是流內的或編目的。我們不能在編目過程中編碼流內過程。
//SAMPINST JOB 1,CLASS=6,MSGCLASS=Y,NOTIFY=&SYSUID //* //SETNM SET DSNM1=INPUT1,DSNM2=OUTPUT1 //INSTPRC1 PROC //* START OF PROCEDURE 1 //STEP1 EXEC PGM=SORT,DISP=SHR //SORTIN DD DSN=&DSNM1,DISP=SHR //SORTOUT DD DSN=&DSNM2,DISP=(,PASS) //SYSOUT DD SYSOUT=* //SYSIN DD DSN=&DATAC //* //STEP2 EXEC PROC=INSTPRC2,DSNM2=MYDATA.URMI.OUTPUT2 // PEND //* END OF PROCEDURE 1 //* //INSTPRC2 PROC //* START OF PROCEDURE 2 //STEP1 EXEC PGM=SORT //SORTIN DD DSN=*.INSTPRC1.STEP1.SORTOUT //SORTOUT DD DSN=&DSNM2,DISP=OLD //SYSOUT DD SYSOUT=* //SYSIN DD DSN=&DATAC // PEND //* END OF PROCEDURE 2 //* //JSTEP1 EXEC INSTPRC1,DSNM1=MYDATA.URMI.INPUT1, // DATAC=MYDATA.BASE.LIB1(DATA1) //*
在上面的示例中,JCL 在 JSTEP1 中呼叫過程 INSTPRC1,過程 INSTPRC2 在過程 INSTPRC1 中被呼叫。此處,INSTPRC1 的輸出 (SORTOUT) 作為輸入 (SORTIN) 傳遞給 INSTPRC2。
SET 語句用於在作業步驟或過程之間定義常用符號。它初始化符號名稱中的先前值。它必須在 JCL 中首次使用符號名稱之前定義。
讓我們看一下下面的描述,以便更多地瞭解上述程式。
SET 引數初始化 DSNM1=INPUT1 和 DSNM2=OUTPUT1。
當在 JCL 的 JSTEP1 中呼叫 INSTPRC1 時,DSNM1=MYDATA.URMI.INPUT1 且 DSNM2=OUTPUT1.,即 SET 語句中初始化的值將重置為在任何作業步驟/過程中設定的值。
當在 INSTPRC1 的 STEP2 中呼叫 INSTPRC2 時,DSNM1=MYDATA.URMI.INPUT1 且 DSNM2=MYDATA.URMI.OUTPUT2。
JCL - 條件處理
作業輸入系統使用兩種方法在 JCL 中執行條件處理。作業完成後,會根據執行狀態設定返回碼。返回碼可以是 0(執行成功)到 4095(非零表示錯誤條件)之間的數字。最常見的常規值是
0 = 正常 - 一切正常
4 = 警告 - 次要錯誤或問題。
8 = 錯誤 - 嚴重錯誤或問題。
12 = 嚴重錯誤 - 重大錯誤或問題,結果不可信。
16 = 終止錯誤 - 非常嚴重的問題,請勿使用結果。
可以使用COND引數和IF-THEN-ELSE結構控制作業步驟的執行,該結構基於前一步/步驟的返回碼,本教程已對此進行了說明。
COND 引數
COND引數可以在 JCL 的 JOB 或 EXEC 語句中編碼。它對前面作業步驟的返回碼進行測試。如果測試結果為真,則當前作業步驟的執行將被繞過。繞過只是省略作業步驟,而不是異常終止。單個測試中最多可以組合八個條件。
語法
以下是 JCL COND 引數的基本語法
COND=(rc,logical-operator) or COND=(rc,logical-operator,stepname) or COND=EVEN or COND=ONLY
以下是所用引數的描述
rc:這是返回碼
邏輯運算子:可以是 GT(大於)、GE(大於或等於)、EQ(等於)、LT(小於)、LE(小於或等於)或 NE(不等於)。
stepname:這是用於測試的作業步驟的返回碼。
最後兩個條件 (a) COND=EVEN 和 (b) COND=ONLY 已在本教程後面進行了說明。
COND 可以編碼在 JOB 語句或 EXEC 語句中,並且在這兩種情況下,其行為都不同,如下所述
JOB 語句中的 COND
當 COND 編碼在 JOB 語句中時,會對每個作業步驟進行條件測試。當在任何特定作業步驟中條件為真時,它將被繞過,以及隨後的作業步驟。以下是一個示例
//CNDSAMP JOB CLASS=6,NOTIFY=&SYSUID,COND=(5,LE) //* //STEP10 EXEC PGM=FIRSTP //* STEP10 executes without any test being performed. //STEP20 EXEC PGM=SECONDP //* STEP20 is bypassed, if RC of STEP10 is 5 or above. //* Say STEP10 ends with RC4 and hence test is false. //* So STEP20 executes and lets say it ends with RC16. //STEP30 EXEC PGM=SORT //* STEP30 is bypassed since 5 <= 16.
EXEC 語句中的 COND
當 COND 編碼在作業步驟的 EXEC 語句中並發現為真時,只會繞過該作業步驟,並且從下一個作業步驟繼續執行。
//CNDSAMP JOB CLASS=6,NOTIFY=&SYSUID //* //STP01 EXEC PGM=SORT //* Assuming STP01 ends with RC0. //STP02 EXEC PGM=MYCOBB,COND=(0,EQ,STP01) //* In STP02, condition evaluates to TRUE and step bypassed. //STP03 EXEC PGM=IEBGENER,COND=((10,LT,STP01),(10,GT,STP02)) //* In STP03, first condition fails and hence STP03 executes. //* Since STP02 is bypassed, the condition (10,GT,STP02) in //* STP03 is not tested.
COND=EVEN
當編碼 COND=EVEN 時,即使任何先前的步驟異常終止,當前作業步驟也會執行。如果與 COND=EVEN 一起編碼了任何其他 RC 條件,則如果沒有任何 RC 條件為真,則作業步驟將執行。
//CNDSAMP JOB CLASS=6,NOTIFY=&SYSUID //* //STP01 EXEC PGM=SORT //* Assuming STP01 ends with RC0. //STP02 EXEC PGM=MYCOBB,COND=(0,EQ,STP01) //* In STP02, condition evaluates to TRUE and step bypassed. //STP03 EXEC PGM=IEBGENER,COND=((10,LT,STP01),EVEN) //* In STP03, condition (10,LT,STP01) evaluates to true, //* hence the step is bypassed.
COND=ONLY
當編碼 COND=ONLY 時,只有當任何先前的步驟異常終止時,才會執行當前作業步驟。如果與 COND=ONLY 一起編碼了任何其他 RC 條件,則如果沒有任何 RC 條件為真並且任何先前的作業步驟異常失敗,則作業步驟將執行。
//CNDSAMP JOB CLASS=6,NOTIFY=&SYSUID //* //STP01 EXEC PGM=SORT //* Assuming STP01 ends with RC0. //STP02 EXEC PGM=MYCOBB,COND=(4,EQ,STP01) //* In STP02, condition evaluates to FALSE, step is executed //* and assume the step abends. //STP03 EXEC PGM=IEBGENER,COND=((0,EQ,STP01),ONLY) //* In STP03, though the STP02 abends, the condition //* (0,EQ,STP01) is met. Hence STP03 is bypassed.
IF-THEN-ELSE 結構
控制作業處理的另一種方法是使用 IF-THEN-ELSE 結構。這提供了更靈活且使用者友好的條件處理方式。
語法
以下是 JCL IF-THEN-ELSE 結構的基本語法
//name IF condition THEN list of statements //* action to be taken when condition is true //name ELSE list of statements //* action to be taken when condition is false //name ENDIF
以下是上述 IF-THEN-ELSE 結構中所用術語的描述
name:這是可選的,名稱可以有 1 到 8 個字母數字字元,以字母、#、$ 或 @ 開頭。
Condition:條件將具有以下格式:KEYWORD OPERATOR VALUE,其中KEYWORDS可以是 RC(返回碼)、ABENDCC(系統或使用者完成碼)、ABEND、RUN(步驟已開始執行)。OPERATOR可以是邏輯運算子(AND(&)、OR(|))或關係運算符(<、<=、>、>=、<>)。
示例
以下是一個簡單的示例,顯示了 IF-THEN-ELSE 的用法
//CNDSAMP JOB CLASS=6,NOTIFY=&SYSUID //* //PRC1 PROC //PST1 EXEC PGM=SORT //PST2 EXEC PGM=IEBGENER // PEND //STP01 EXEC PGM=SORT //IF1 IF STP01.RC = 0 THEN //STP02 EXEC PGM=MYCOBB1,PARM=123 // ENDIF //IF2 IF STP01.RUN THEN //STP03a EXEC PGM=IEBGENER //STP03b EXEC PGM=SORT // ENDIF //IF3 IF STP03b.!ABEND THEN //STP04 EXEC PGM=MYCOBB1,PARM=456 // ELSE // ENDIF //IF4 IF (STP01.RC = 0 & STP02.RC <= 4) THEN //STP05 EXEC PROC=PRC1 // ENDIF //IF5 IF STP05.PRC1.PST1.ABEND THEN //STP06 EXEC PGM=MYABD // ELSE //STP07 EXEC PGM=SORT // ENDIF
讓我們嘗試深入研究上述程式,以便更詳細地瞭解它。
在 IF1 中測試 STP01 的返回碼。如果為 0,則執行 STP02。否則,處理轉到下一個 IF 語句 (IF2)。
在 IF2 中,如果 STP01 已開始執行,則執行 STP03a 和 STP03b。
在 IF3 中,如果 STP03b 沒有 ABEND,則執行 STP04。在 ELSE 中,沒有語句。這稱為 NULL ELSE 語句。
在 IF4 中,如果 STP01.RC = 0 且 STP02.RC <=4 為真,則執行 STP05。
在 IF5 中,如果作業步驟 STP05 中 PRC1 中的 proc-step PST1 ABEND,則執行 STP06。否則執行 STP07。
如果 IF4 評估為假,則不會執行 STP05。在這種情況下,不會測試 IF5,並且不會執行步驟 STP06、STP07。
在作業異常終止的情況下(例如使用者取消作業、作業時間到期或資料集向後引用被繞過的步驟),IF-THEN-ELSE 不會執行。
設定檢查點
您可以使用SYSCKEOV(這是一個 DD 語句)在 JCL 程式中設定檢查點資料集。
CHKPT是在 DD 語句中為多卷 QSAM 資料集編碼的引數。當 CHKPT 編碼為 CHKPT=EOV 時,在每個輸入/輸出多卷資料集卷的末尾將檢查點寫入 SYSCKEOV 語句中指定的資料集中。
//CHKSAMP JOB CLASS=6,NOTIFY=&SYSUID //* //STP01 EXEC PGM=MYCOBB //SYSCKEOV DD DSNAME=SAMPLE.CHK,DISP=MOD //IN1 DD DSN=SAMPLE.IN,DISP=SHR //OUT1 DD DSN=SAMPLE.OUT,DISP=(,CATLG,CATLG) // CHKPT=EOV,LRECL=80,RECFM=FB
在上面的示例中,在輸出資料集 SAMPLE.OUT 的每個卷的末尾,都會在資料集 SAMPLE.CHK 中寫入一個檢查點。
重新啟動處理
您可以使用RD 引數透過自動方式或使用RESTART 引數透過手動方式重新啟動處理。
RD 引數編碼在 JOB 或 EXEC 語句中,它有助於自動重新啟動 JOB/STEP,並且可以儲存四個值之一:R、RNC、NR 或 NC。
RD=R允許自動重新啟動,並考慮 DD 語句的 CHKPT 引數中編碼的檢查點。
RD=RNC允許自動重新啟動,但會覆蓋(忽略)CHKPT 引數。
RD=NR指定作業/步驟不能自動重新啟動。但是,當使用 RESTART 引數手動重新啟動時,將考慮 CHKPT 引數(如果有)。
RD=NC不允許自動重新啟動和檢查點處理。
如果需要僅針對特定異常結束程式碼執行自動重新啟動,則可以在 IBM 系統 parmlib 庫的SCHEDxx成員中指定。
RESTART 引數編碼在 JOB 或 EXEC 語句中,它有助於在作業失敗後手動重新啟動 JOB/STEP。RESTART 可以與檢查 ID 結合使用,檢查 ID 是在 SYSCKEOV DD 語句中編碼的資料集中寫入的檢查點。當編碼檢查 ID 時,應編碼 SYSCHK DD 語句以引用 JOBLIB 語句(如果有)之後的檢查點資料集,否則在 JOB 語句之後引用。
//CHKSAMP JOB CLASS=6,NOTIFY=&SYSUID,RESTART=(STP01,chk5) //* //SYSCHK DD DSN=SAMPLE.CHK,DISP=OLD //STP01 EXEC PGM=MYCOBB //*SYSCKEOV DD DSNAME=SAMPLE.CHK,DISP=MOD //IN1 DD DSN=SAMPLE.IN,DISP=SHR //OUT1 DD DSN=SAMPLE.OUT,DISP=(,CATLG,CATLG) // CHKPT=EOV,LRECL=80,RECFM=FB
在上面的示例中,chk5 是檢查 ID,即 STP01 從檢查點 5 重新啟動。請注意,已新增 SYSCHK 語句,並且在“設定檢查點”部分中解釋的先前程式中已註釋掉 SYSCKEOV 語句。
JCL - 定義資料集
資料集名稱指定檔名稱,並在 JCL 中用 DSN 表示。DSN 引數指的是新建立或現有資料集的物理資料集名稱。DSN 值可以由每個長度為 1 到 8 個字元的子名稱組成,用句點分隔,總長度為 44 個字元(字母數字)。以下是語法
DSN=&name | *.stepname.ddname
臨時資料集僅在作業持續時間內需要儲存空間,並在作業完成後刪除。此類資料集表示為DSN=&name或根本沒有指定 DSN。
如果作業步驟建立的臨時資料集要在下一個作業步驟中使用,則將其引用為DSN=*.stepname.ddname。這稱為向後引用。
連線資料集
如果有多個相同格式的資料集,則可以將它們連線起來,並作為單個 DD 名稱傳遞給程式作為輸入。
//CONCATEX JOB CLASS=6,NOTIFY=&SYSUID //* //STEP10 EXEC PGM=SORT //SORTIN DD DSN=SAMPLE.INPUT1,DISP=SHR // DD DSN=SAMPLE.INPUT2,DISP=SHR // DD DSN=SAMPLE.INPUT3,DISP=SHR //SORTOUT DD DSN=SAMPLE.OUTPUT,DISP=(,CATLG,DELETE), // LRECL=50,RECFM=FB
在上面的示例中,將三個資料集連線起來,並作為輸入傳遞給 SORTIN DD 名稱中的 SORT 程式。檔案將被合併,根據指定的鍵欄位排序,然後寫入 SORTOUT DD 名稱中的單個輸出檔案 SAMPLE.OUTPUT。
覆蓋資料集
在標準化的 JCL 中,要執行的程式及其相關資料集將放置在已編目過程中,該過程在 JCL 中被呼叫。通常,出於測試目的或為了解決事件修復,可能需要使用與已編目過程中指定的資料集不同的資料集。在這種情況下,可以在 JCL 中覆蓋過程中的資料集。
//SAMPINST JOB 1,CLASS=6,MSGCLASS=Y,NOTIFY=&SYSUID //* //JSTEP1 EXEC CATLPROC,PROG=CATPRC1,DSNME=MYDATA.URMI.INPUT // DATAC=MYDATA.BASE.LIB1(DATA1) //STEP1.IN1 DD DSN=MYDATA.OVER.INPUT,DISP=SHR //* //* The cataloged procedure is as below: //* //CATLPROC PROC PROG=,BASELB=MYCOBOL.BASE.LIB1 //* //STEP1 EXEC PGM=&PROG //STEPLIB DD DSN=&BASELB,DISP=SHR //IN1 DD DSN=MYDATA.URMI.INPUT,DISP=SHR //OUT1 DD SYSOUT=* //SYSOUT DD SYSOUT=* //SYSIN DD MYDATA.BASE.LIB1(DATA1),DISP=SHR //* //STEP2 EXEC PGM=SORT
在上面的示例中,資料集 IN1 在 PROC 中使用檔案 MYDATA.URMI.INPUT,該檔案在 JCL 中被覆蓋。因此,執行中使用的輸入檔案為 MYDATA.OVER.INPUT。請注意,資料集稱為 STEP1.IN1。如果 JCL/PROC 中只有一個步驟,則可以使用 DD 名稱引用資料集。類似地,如果 JCL 中有多個步驟,則資料集需要覆蓋為 JSTEP1.STEP1.IN1。
//SAMPINST JOB 1,CLASS=6,MSGCLASS=Y,NOTIFY=&SYSUID //* //STEP EXEC CATLPROC,PROG=CATPRC1,DSNME=MYDATA.URMI.INPUT // DATAC=MYDATA.BASE.LIB1(DATA1) //STEP1.IN1 DD DSN=MYDATA.OVER.INPUT,DISP=SHR // DD DUMMY // DD DUMMY //*
在上面的示例中,在 IN1 中連線的三個資料集中,第一個在 JCL 中被覆蓋,其餘保留為 PROC 中存在的資料集。
在 JCL 中定義 GDG
生成資料組 (GDG) 是由一個通用名稱關聯的一組資料集。通用名稱稱為 GDG 基名稱,與基名稱關聯的每個資料集稱為 GDG 版本。
例如,MYDATA.URMI.SAMPLE.GDG 是 GDG 基名稱。資料集的名稱為 MYDATA.URMI.SAMPLE.GDG.G0001V00、MYDATA.URMI.SAMPLE.GDG.G0002V00 等。GDG 的最新版本稱為 MYDATA.URMI.SAMPLE.GDG(0),先前版本稱為 (-1)、(-2) 等。在程式中要建立的下一個版本在 JCL 中稱為 MYDATA.URMI.SAMPLE.GDG(+1)。
在 JCL 中建立/更改 GDG
GDG 版本可以具有相同或不同的 DCB 引數。可以定義一個初始模型 DCB 供所有版本使用,但在建立新版本時可以覆蓋它。
//GDGSTEP1 EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
DEFINE GDG(NAME(MYDATA.URMI.SAMPLE.GDG) -
LIMIT(7) -
NOEMPTY -
SCRATCH)
/*
//GDGSTEP2 EXEC PGM=IEFBR14
//GDGMODLD DD DSN=MYDATA.URMI.SAMPLE.GDG,
// DISP=(NEW,CATLG,DELETE),
// UNIT=SYSDA,
// SPACE=(CYL,10,20),
// DCB=(LRECL=50,RECFM=FB)
//
在上面的示例中,IDCAMS 實用程式在 GDGSTEP1 中定義了 GDG 基名稱,並在 SYSIN DD 語句中傳遞了以下引數
NAME指定 GDG 基名稱的物理資料集名稱。
LIMIT指定 GDG 基名稱可以儲存的最大版本數。
EMPTY在達到 LIMIT 時取消編目所有世代。
NOEMPTY取消編目最近的世代。
SCRATCH在取消編目時物理刪除世代。
NOSCRATCH不刪除資料集,即可以使用 UNIT 和 VOL 引數引用它。
在 GDGSTEP2 中,IEFBR14 實用程式指定所有版本要使用的模型 DD 引數。
可以使用 IDCAMS 更改 GDG 的定義引數,例如增加 LIMIT、將 EMPTY 更改為 NOEMPTY 等,以及使用 SYSIN 命令更改其相關版本,例如 **ALTER MYDATA.URMI.SAMPLE.GDG LIMIT(15) EMPTY**。
在 JCL 中刪除 GDG
使用 IEFBR14 實用程式,我們可以刪除 GDG 的單個版本。
//GDGSTEP3 EXEC PGM=IEFBR14 //GDGDEL DD DSN=MYDATA.URMI.SAMPLE.GDG(0), // DISP=(OLD,DELETE,DELETE)
在上面的示例中,刪除了 MYDATA.URMI.SAMPLE.GDG 的最新版本。請注意,正常作業完成時的 DISP 引數編碼為 DELETE。因此,作業執行完成後將刪除資料集。
可以使用 IDCAMS 刪除 GDG 及其相關版本,使用 SYSIN 命令 **DELETE(MYDATA.URMI.SAMPLE.GDG) GDG FORCE/PURGE**。
**FORCE** 刪除 GDG 版本和 GDG 基座。如果任何 GDG 版本設定了尚未過期的失效日期,則不會刪除這些版本,因此將保留 GDG 基座。
**PURGE** 刪除 GDG 版本和 GDG 基座,無論失效日期如何。
在 JCL 中使用 GDG
在以下示例中,將 MYDATA.URMI.SAMPLE.GDG 的最新版本用作程式的輸入,並建立一個 MYDATA.URMI.SAMPLE.GDG 的新版本作為輸出。
//CNDSAMP JOB CLASS=6,NOTIFY=&SYSUID //* //STP01 EXEC PGM=MYCOBB //IN1 DD DSN=MYDATA.URMI.SAMPLE.GDG(0),DISP=SHR //OUT1 DD DSN=MYDATA.URMI.SAMPLE.GDG(+1),DISP=(,CALTG,DELETE) // LRECL=100,RECFM=FB
這裡,如果 GDG 透過實際名稱(如 MYDATA.URMI.SAMPLE.GDG.G0001V00)引用,則每次執行前都需要更改 JCL。使用 (0) 和 (+1) 使其動態替換 GDG 版本以進行執行。
輸入/輸出方法
任何透過 JCL 執行的批處理程式都需要資料輸入,對其進行處理並建立輸出。有多種方法可以將輸入提供給程式並寫入從 JCL 收到的輸出。在批處理模式下,不需要使用者互動,但在 JCL 中定義了輸入和輸出裝置以及所需的組織並提交。
JCL 中的資料輸入
有多種方法可以使用 JCL 將資料提供給程式,下面將解釋這些方法。
內聯資料
可以使用 SYSIN DD 語句為程式指定內聯資料。
//CONCATEX JOB CLASS=6,NOTIFY=&SYSUID //* Example 1: //STEP10 EXEC PGM=MYPROG //IN1 DD DSN=SAMPLE.INPUT1,DISP=SHR //OUT1 DD DSN=SAMPLE.OUTPUT1,DISP=(,CATLG,DELETE), // LRECL=50,RECFM=FB //SYSIN DD * //CUST1 1000 //CUST2 1001 /* //* //* Example 2: //STEP20 EXEC PGM=MYPROG //OUT1 DD DSN=SAMPLE.OUTPUT2,DISP=(,CATLG,DELETE), // LRECL=50,RECFM=FB //SYSIN DD DSN=SAMPLE.SYSIN.DATA,DISP=SHR //*
在示例 1 中,透過 SYSIN 將輸入傳遞給 MYPROG。資料在 JCL 中提供。兩條資料記錄傳遞給程式。請注意,/* 標記內聯 SYSIN 資料的結束。
"CUST1 1000" 是記錄 1,"CUST2 1001" 是記錄 2。當讀取資料時遇到符號 /* 時,將滿足資料結束條件。
在示例 2 中,SYSIN 資料儲存在資料集內,其中 SAMPLE.SYSIN.DATA 是一個 PS 檔案,可以儲存一條或多條資料記錄。
透過檔案輸入資料
如前幾章的大多數示例中所述,可以透過 PS、VSAM 或 GDG 檔案將資料輸入提供給程式,並使用相關的 DSN 名稱和 DISP 引數以及 DD 語句。
在示例 1 中,SAMPLE.INPUT1 是透過其將資料傳遞給 MYPROG 的輸入檔案。它在程式中被引用為 IN1。
JCL 中的資料輸出
JCL 中的輸出可以編目到資料集中或傳遞到 SYSOUT。如 DD 語句章節中所述,**SYSOUT=*** 將輸出重定向到與 JOB 語句的 MSGCLASS 引數中指定的類相同的類。
儲存作業日誌
指定 **MSGCLASS=Y** 將作業日誌儲存在 JMR(作業日誌管理和檢索)中。整個作業日誌可以重定向到 SPOOL,並可以透過在 SPOOL 中針對作業名稱發出 XDC 命令將其儲存到資料集中。當在 SPOOL 中發出 XDC 命令時,將開啟一個數據集建立螢幕。然後,可以透過提供適當的 PS 或 PDS 定義來儲存作業日誌。
作業日誌也可以透過為 SYSOUT 和 SYSPRINT 指定一個已建立的資料集來儲存到資料集中。但無法透過這種方式捕獲整個作業日誌(即 JESMSG 將不會被編目),如在 JMR 或 XDC 中所做的那樣。
//SAMPINST JOB 1,CLASS=6,MSGCLASS=Y,NOTIFY=&SYSUID //* //STEP1 EXEC PGM=MYPROG //IN1 DD DSN=MYDATA.URMI.INPUT,DISP=SHR //OUT1 DD SYSOUT=* //SYSOUT DD DSN=MYDATA.URMI.SYSOUT,DISP=SHR //SYSPRINT DD DSN=MYDATA.URMI.SYSPRINT,DISP=SHR //SYSIN DD MYDATA.BASE.LIB1(DATA1),DISP=SHR //* //STEP2 EXEC PGM=SORT
在上面的示例中,SYSOUT 編目在 MYDATA.URMI.SYSOUT 中,SYSPRINT 編目在 MYDATA.URMI.SYSPRINT 中。
使用 JCL 執行 COBOL 程式
編譯 COBOL 程式
為了使用 JCL 在批處理模式下執行 COBOL 程式,需要編譯程式並建立一個包含所有子程式的載入模組。JCL 在執行時使用載入模組而不是實際程式。載入庫被連線起來,並在執行時使用 **JCLLIB** 或 **STEPLIB** 提供給 JCL。
有許多可用的主機編譯器實用程式可以編譯 COBOL 程式。一些公司使用 Change Management 工具(如 **Endevor**),它編譯並存儲程式的每個版本。這有助於跟蹤對程式所做的更改。
//COMPILE JOB ,CLASS=6,MSGCLASS=X,NOTIFY=&SYSUID //* //STEP1 EXEC IGYCRCTL,PARM=RMODE,DYNAM,SSRANGE //SYSIN DD DSN=MYDATA.URMI.SOURCES(MYCOBB),DISP=SHR //SYSLIB DD DSN=MYDATA.URMI.COPYBOOK(MYCOPY),DISP=SHR //SYSLMOD DD DSN=MYDATA.URMI.LOAD(MYCOBB),DISP=SHR //SYSPRINT DD SYSOUT=* //*
IGYCRCTL 是一個 IBM COBOL 編譯器實用程式。編譯器選項透過 PARM 引數傳遞。在上面的示例中,RMODE 指示編譯器在程式中使用相對定址模式。COBOL 程式透過 SYSIN 引數傳遞,副本庫是程式在 SYSLIB 中使用的庫。
此 JCL 生成程式的載入模組作為輸出,該輸出用作執行 JCL 的輸入。
執行 COBOL 程式
下面是一個 JCL 示例,其中使用輸入檔案 MYDATA.URMI.INPUT 執行程式 MYPROG,並生成兩個寫入卷軸的輸出檔案。
//COBBSTEP JOB CLASS=6,NOTIFY=&SYSUID // //STEP10 EXEC PGM=MYPROG,PARM=ACCT5000 //STEPLIB DD DSN=MYDATA.URMI.LOADLIB,DISP=SHR //INPUT1 DD DSN=MYDATA.URMI.INPUT,DISP=SHR //OUT1 DD SYSOUT=* //OUT2 DD SYSOUT=* //SYSIN DD * //CUST1 1000 //CUST2 1001 /*
MYPROG 的載入模組位於 MYDATA.URMI.LOADLIB 中。需要注意的是,上述 JCL 只能用於非 DB2 COBOL 模組。
將資料傳遞給 COBOL 程式
COBOL 批處理程式的資料輸入可以透過檔案、PARAM 引數和 SYSIN DD 語句進行。在上面的例子中
資料記錄透過檔案 MYDATA.URMI.INPUT 傳遞給 MYPROG。此檔案將在程式中使用 DD 名稱 INPUT1 引用。可以在程式中開啟、讀取和關閉該檔案。
程式 MYPROG 的 LINKAGE 部分接收 PARM 引數資料 ACCT5000,該資料在該部分內定義的變數中。
SYSIN 語句中的資料透過程式的 PROCEDURE 部分中的 ACCEPT 語句接收。每個 ACCEPT 語句將一條完整記錄(即 CUST1 1000)讀入程式中定義的工作儲存變數。
執行 COBOL-DB2 程式
為了執行 COBOL DB2 程式,JCL 和程式中使用了專門的 IBM 實用程式;DB2 區域和所需引數作為輸入傳遞給實用程式。
執行 COBOL-DB2 程式遵循以下步驟
當編譯 COBOL-DB2 程式時,除了載入模組之外,還會建立一個 DBRM(資料庫請求模組)。DBRM 包含 COBOL 程式的 SQL 語句,並對其語法進行了檢查以確保其正確性。
DBRM 繫結到 COBOL 將在其中執行的 DB2 區域(環境)。這可以透過 JCL 中的 IKJEFT01 實用程式來完成。
繫結步驟完成後,使用 IKJEFT01(再次)執行 COBOL-DB2 程式,並將載入庫和 DBRM 庫作為輸入提供給 JCL。
//STEP001 EXEC PGM=IKJEFT01
//*
//STEPLIB DD DSN=MYDATA.URMI.DBRMLIB,DISP=SHR
//*
//input files
//output files
//SYSPRINT DD SYSOUT=*
//SYSABOUT DD SYSOUT=*
//SYSDBOUT DD SYSOUT=*
//SYSUDUMP DD SYSOUT=*
//DISPLAY DD SYSOUT=*
//SYSOUT DD SYSOUT=*
//SYSTSPRT DD SYSOUT=*
//SYSTSIN DD *
DSN SYSTEM(SSID)
RUN PROGRAM(MYCOBB) PLAN(PLANNAME) PARM(parameters to cobol program) -
LIB('MYDATA.URMI.LOADLIB')
END
/*
在上面的示例中,MYCOBB 是使用 IKJEFT01 執行的 COBOL-DB2 程式。請注意,程式名稱、DB2 子系統 ID (SSID) 和 DB2 計劃名稱都傳遞在 SYSTSIN DD 語句中。DBRM 庫在 STEPLIB 中指定。
JCL - 實用程式
IBM 資料集實用程式
實用程式是預先編寫的程式,系統程式設計師和應用程式開發人員廣泛用於主機中,以實現日常需求、組織和維護資料。下面列出了一些及其功能。
| 實用程式名稱 | 功能 |
|---|---|
| IEHMOVE | 移動或複製順序資料集。 |
| IEHPROGM | 刪除和重新命名資料集;編目或取消編目除 VSAM 之外的其他資料集。 |
| IEHCOMPR | 比較順序資料集中資料。 |
| IEBCOPY | 複製、合併、壓縮、備份或恢復 PDS。 |
| IEFBR14 | 無操作實用程式。用於將控制權返回給使用者並終止。它通常用於建立空資料集或刪除現有資料集。 例如,如果將資料集作為輸入傳遞給具有 DISP=(OLD,DELETE,DELETE) 的 IEFBR14 程式,則在作業完成後將刪除該資料集。 |
| IEBEDIT | 用於複製 JCL 的選定部分。例如,如果 JCL 有 5 個步驟,而我們只需要執行步驟 1 和 3,則可以使用包含要執行的實際 JCL 的資料集編碼 IEBEDIT JCL。在 IEBEDIT 的 SYSIN 中,我們可以指定 STEP1 和 STEP3 作為引數。當執行此 JCL 時,它將執行實際 JCL 的 STEP1 和 STEP3。 |
| IDCAMS | 建立、刪除、重新命名、編目、取消編目資料集(除 PDS 之外)。通常用於管理 VSAM 資料集。 |
為了實現指定的功能,這些實用程式需要與 JCL 中的適當 DD 語句一起使用。
DFSORT 概述
DFSORT 是一個功能強大的 IBM 實用程式,用於複製、排序或合併資料集。SORTIN 和 SORTINnn DD 語句用於指定輸入資料集。SORTOUT 和 OUTFIL 語句用於指定輸出資料。
SYSIN DD 語句用於指定排序和合並條件。DFSORT 通常用於實現以下功能
按檔案中指定欄位位置的順序對輸入檔案進行排序。
根據指定的條件包含或省略輸入檔案中的記錄。
按檔案中指定欄位位置的順序對輸入檔案進行排序合併。
根據指定的 JOIN KEY(每個輸入檔案中的欄位)對兩個或多個輸入檔案進行排序連線。
當需要對輸入檔案進行額外處理時,可以從 SORT 程式中呼叫 USER EXIT 程式。例如,如果需要在輸出檔案中新增標題/尾部,則可以從 SORT 程式中呼叫使用者編寫的 COBOL 程式來執行此功能。可以使用控制卡將資料傳遞給 COBOL 程式。
反過來,可以從 COBOL 程式內部呼叫 SORT 以在處理前按特定順序排列輸入檔案。通常,對於大型檔案,不建議這樣做,因為這會影響效能。
ICETOOL 概述
ICETOOL 是一個多功能 DFSORT 實用程式,用於對資料集執行各種操作。可以使用使用者定義的 DD 名稱定義輸入和輸出資料集。檔案操作在 TOOLIN DD 語句中指定。可以在使用者定義的“CTL”DD 語句中指定其他條件。
下面列出了一些 ICETOOL 的實用程式
ICETOOL 可以在一項或多項條件下實現 DFSORT 的所有功能。
SPLICE 是 ICETOOL 的一個強大操作,類似於 SORT JOIN,但具有其他功能。它可以根據指定的欄位比較兩個或多個檔案,並建立一或多個輸出檔案,例如包含匹配記錄的檔案、包含不匹配記錄的檔案等。
可以將一個檔案中特定位置的資料覆蓋到同一檔案或不同檔案中另一個位置。
一個檔案可以根據指定條件拆分為n個檔案。例如,包含員工姓名列表的檔案可以拆分為26個檔案,每個檔案包含以A、B、C等字母開頭的姓名。
透過對ICETOOL進行一些探索,可以實現多種檔案操作的組合。
SYNCSORT概述
SYNCSORT用於以高效能複製、合併或排序資料集。它能夠最佳利用系統資源,並在31位和64位地址空間中高效執行。
它可以在與DFSORT相同的行中使用,並且可以實現相同的功能。它可以透過JCL呼叫,也可以從用COBOL、PL/1或組合語言編寫的程式中呼叫。它還支援從SYNCSORT程式中呼叫的使用者出口程式。
下一章將解釋使用這些實用程式的常用排序技巧。複雜的需要在COBOL/ASSEMBLER中進行大量程式設計才能實現的需求,可以使用上述實用程式以簡單的步驟實現。
JCL - 基本排序技巧
下面說明了企業界中可以使用實用程式實現的日常應用程式需求
1. 一個檔案有100條記錄。需要將前10條記錄寫入輸出檔案。
//JSTEP020 EXEC PGM=ICETOOL //TOOLMSG DD SYSOUT=* //DFSMSG DD SYSOUT=* //IN1 DD DSN=MYDATA.URMI.STOPAFT,DISP=SHR //OUT1 DD SYSOUT=* //TOOLIN DD * COPY FROM(IN1) TO(OUT1) USING(CTL1) /* //CTL1CNTL DD * OPTION STOPAFT=10 /*
STOPAFT選項將在讀取第10條記錄後停止讀取輸入檔案並終止程式。因此,10條記錄被寫入輸出。
2. 輸入檔案對同一個員工號有一條或多條記錄。將唯一記錄寫入輸出。
//STEP010 EXEC PGM=SORT //SYSOUT DD SYSOUT=* //SORTIN DD DSN=MYDATA.URMI.DUPIN,DISP=SHR //SORTOUT DD SYSOUT=* //SYSIN DD * SORT FIELDS=(1,15,ZD,A) SUM FIELDS=NONE /*
SUM FIELDS=NONE刪除在SORT FIELDS中指定的欄位中的重複項。在上面的示例中,員工號位於欄位位置1,15。輸出檔案將包含按升序排序的唯一員工號。
3. 覆蓋輸入記錄內容。
//JSTEP010 EXEC PGM=SORT //SORTIN DD DSN= MYDATA.URMI.SAMPLE.MAIN,DISP=SHR //SORTOUT DD SYSOUT=* //SYSPRINT DD SYSOUT=* //SYSOUT DD SYSOUT=* //SYSIN DD * OPTION COPY INREC OVERLAY=(47:1,6) /*
在輸入檔案中,位置1,6中的內容被覆蓋到位置47,6,然後複製到輸出檔案。為了在複製到輸出之前重寫輸入檔案中的資料,使用了INREC OVERLAY操作。
4. 向輸出檔案新增序列號。
//JSTEP010 EXEC PGM=SORT //SORTIN DD * data1 data2 data3 /* //SORTOUT DD SYSOUT=* //SYSPRINT DD SYSOUT=* //SYSOUT DD SYSOUT=* //SYSIN DD * OPTION COPY BUILD=(1:1,5,10:SEQNUM,4,ZD,START=1000,INCR=2) /*
輸出將是
data1 1000 data2 1002 data3 1004
在輸出的第10個位置新增4位序列號,從1000開始,每條記錄遞增2。
5. 向輸出檔案新增報頭/報尾。
//JSTEP010 EXEC PGM=SORT //SORTIN DD * data1 data2 data3 /* //SORTOUT DD SYSOUT=* //SYSPRINT DD SYSOUT=* //SYSOUT DD SYSOUT=* //SYSIN DD * SORT FIELDS=COPY OUTFIL REMOVECC, HEADER1=(1:C'HDR',10:X'020110131C'), TRAILER1=(1:C'TRL',TOT=(10,9,PD,TO=PD,LENGTH=9)) /*
輸出將是
HDR 20110131 data1 data2 data3 TRL 000000003
TOT計算輸入檔案中的記錄數。HDR和TRL作為報頭/報尾的識別符號新增,它們是使用者定義的,可以根據使用者的需求自定義。
6. 條件處理
//JSTEP010 EXEC PGM=SORT
//SORTIN DD *
data1select
data2
data3select
/*
//SORTOUT DD SYSOUT=*
//SYSPRINT DD SYSOUT=*
//SYSOUT DD SYSOUT=*
//SYSIN DD *
INREC IFTHEN=(WHEN=(6,1,CH,NE,C' '),BUILD=(1:1,15),
IFTHEN=(WHEN=(6,1,CH,EQ,C' '),BUILD=(1:1,5,7:C'EMPTY ')
OPTION COPY
/*
輸出將是
data1select data2 EMPTY data3select
根據檔案的第6個位置,輸出檔案的BUILD會發生變化。如果第6個位置為空格,則將文字“EMPTY”附加到輸入記錄。否則,按原樣將輸入記錄寫入輸出。
7. 備份檔案
//JSTEP001 EXEC PGM=IEBGENER //SYSPRINT DD SYSOUT=* //SYSIN DD * //SYSOUT DD SYSOUT=* //SORTOUT DD DUMMY //SYSUT1 DD DSN=MYDATA.URMI.ORIG,DISP=SHR //SYSUT2 DD DSN=MYDATA.URMI.BACKUP,DISP=(NEW,CATLG,DELETE), // DCB=*.SYSUT1,SPACE=(CYL,(50,1),RLSE)
IEBGENER將SYSUT1中的檔案複製到SYSUT2中的檔案。請注意,在上面的示例中,SYSUT2中的檔案採用與SYSUT1相同的DCB。
8. 檔案比較
//STEP010 EXEC PGM=SORT //MAIN DD * 1000 1001 1003 1005 //LOOKUP DD * 1000 1002 1003 //MATCH DD DSN=MYDATA.URMI.SAMPLE.MATCH,DISP=OLD //NOMATCH1 DD DSN=MYDATA.URMI.SAMPLE.NOMATCH1,DISP=OLD //NOMATCH2 DD DSN=MYDATA.URMI.SAMPLE.NOMATCH2,DISP=OLD //SYSOUT DD SYSOUT=* //SYSIN DD * JOINKEYS F1=MAIN,FIELDS=(1,4,A) JOINKEYS F2=LOOKUP,FIELDS=(1,4,A) JOIN UNPAIRED,F1,F2 REFORMAT FIELDS=(?,F1:1,4,F2:1,4) OPTION COPY OUTFIL FNAMES=MATCH,INCLUDE=(1,1,CH,EQ,C'B'),BUILD=(1:2,4) OUTFIL FNAMES=NOMATCH1,INCLUDE=(1,1,CH,EQ,C'1'),BUILD=(1:2,4) OUTFIL FNAMES=NOMATCH2,INCLUDE=(1,1,CH,EQ,C'2'),BUILD=(1:2,4) /*
JOINKEYS指定比較兩個檔案的欄位。
REFORMAT FIELDS=?將'B'(匹配的記錄)、'1'(存在於檔案1中,但不存在於檔案2中)或'2'(存在於檔案2中,但不存在於檔案1中)放置在輸出BUILD的第1個位置。
JOIN UNPAIRED對兩個檔案進行全外部聯接。
輸出將是
MATCH File 1000 1003 NOMATCH1 File 1001 1005 NOMATCH2 File 1002
使用ICETOOL也可以實現相同的功能。