
 資料結構
資料結構 網路
網路 關係型資料庫管理系統
關係型資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何在 Python 中使用 Seaborn 視覺化具有多個變數的資料?
Seaborn 是一個有助於資料視覺化的庫。它帶有自定義主題和高階介面。在即時情況下,資料集包含許多變數。有時,可能需要分析資料集中每個變數與其他每個變數的關係。在這種情況下,雙變數分佈可能花費太多時間,並且也可能變得複雜。
這就是多對多雙變數分佈發揮作用的地方。可以使用“pairplot”函式獲取資料框中變數組合之間的關係。輸出將是單變數圖。
pairplot 函式的語法
seaborn.pairplot(data,…)
現在讓我們瞭解如何在圖形上繪製它 -
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
my_df = sb.load_dataset('iris')
sb.set_style("ticks")
sb.pairplot(my_df,hue = 'species',diag_kind = "kde",kind = "scatter",palette = "husl")
plt.show()輸出
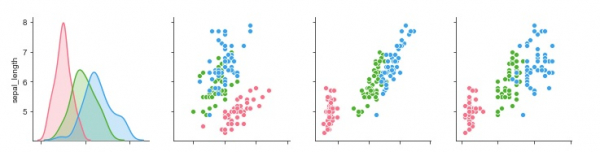
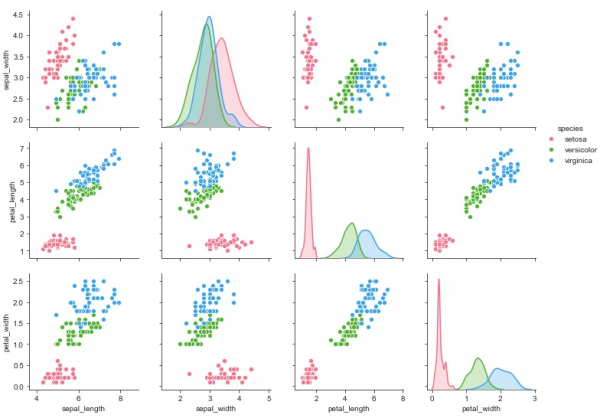
解釋
- 匯入所需的包。
- 輸入資料為“iris_data”,它從 scikit learn 庫載入。
- 此資料儲存在資料框中。
- “load_dataset”函式用於載入鳶尾花資料。
- 使用“pairplot”函式視覺化此資料。
- 這裡,資料框作為引數提供。
- 這裡,“kind”引數指定為“kde”,以便繪圖理解打印核密度估計。
- 圖的型別被提及為散點圖。
- 此資料顯示在控制檯上。

更新於:2020-12-11
248 次檢視

廣告