- H2O 教程
- H2O - 首頁
- H2O - 簡介
- H2O - 安裝
- H2O - 流程
- H2O - 執行示例應用程式
- H2O - 自動機器學習 (AutoML)
- H2O 有用資源
- H2O - 快速指南
- H2O - 有用資源
- H2O - 討論
H2O - 安裝
H2O 可以透過以下五個選項進行配置和使用:
在 Python 中安裝
在 R 中安裝
基於 Web 的 Flow GUI
Hadoop
Anaconda Cloud
在接下來的章節中,您將看到基於可用選項的 H2O 安裝說明。您可能會使用其中一個選項。
在 Python 中安裝
要使用 Python 執行 H2O,安裝需要幾個依賴項。因此,讓我們開始安裝執行 H2O 的最小依賴項集。
安裝依賴項
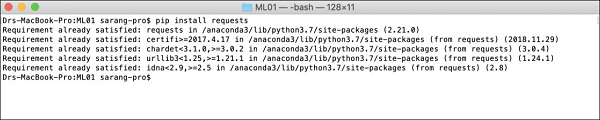
要安裝依賴項,請執行以下 pip 命令:
$ pip install requests
開啟您的控制檯視窗並輸入上述命令以安裝 requests 包。以下螢幕截圖顯示了在我們的 Mac 機器上執行上述命令的情況:
安裝 requests 後,您需要安裝另外三個包,如下所示:
$ pip install tabulate $ pip install "colorama >= 0.3.8" $ pip install future
H2O GitHub 頁面上提供了最新的依賴項列表。在撰寫本文時,頁面上列出了以下依賴項。
python 2. H2O — Installation pip >= 9.0.1 setuptools colorama >= 0.3.7 future >= 0.15.2
刪除舊版本
安裝上述依賴項後,您需要刪除任何現有的 H2O 安裝。為此,請執行以下命令:
$ pip uninstall h2o
安裝最新版本
現在,讓我們使用以下命令安裝最新版本的 H2O:
$ pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2o
安裝成功後,您應該會看到以下訊息顯示在螢幕上:
Installing collected packages: h2o Successfully installed h2o-3.26.0.1
測試安裝
為了測試安裝,我們將執行 H2O 安裝中提供的示例應用程式之一。首先透過鍵入以下命令啟動 Python 提示符:
$ Python3
啟動 Python 直譯器後,在 Python 命令提示符下鍵入以下 Python 語句:
>>>import h2o
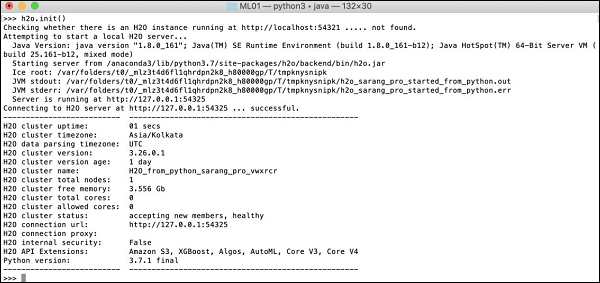
上述命令將 H2O 包匯入您的程式。接下來,使用以下命令初始化 H2O 系統:
>>>h2o.init()
您的螢幕將顯示叢集資訊,在此階段應如下所示:
現在,您可以執行示例程式碼了。在 Python 提示符下鍵入以下命令並執行它。
>>>h2o.demo("glm")
該演示包含一個包含一系列命令的 Python 筆記本。執行每個命令後,其輸出會立即顯示在螢幕上,並且系統會提示您按回車鍵繼續執行下一步。此處顯示執行筆記本中最後一條語句時的部分螢幕截圖:
在此階段,您的 Python 安裝已完成,您可以進行自己的實驗了。
在 R 中安裝
安裝用於 R 開發的 H2O 與為 Python 安裝它非常相似,只是您將使用 R 提示符進行安裝。
啟動 R 控制檯
透過點選您機器上的 R 應用程式圖示來啟動 R 控制檯。控制檯螢幕將如下面的螢幕截圖所示:
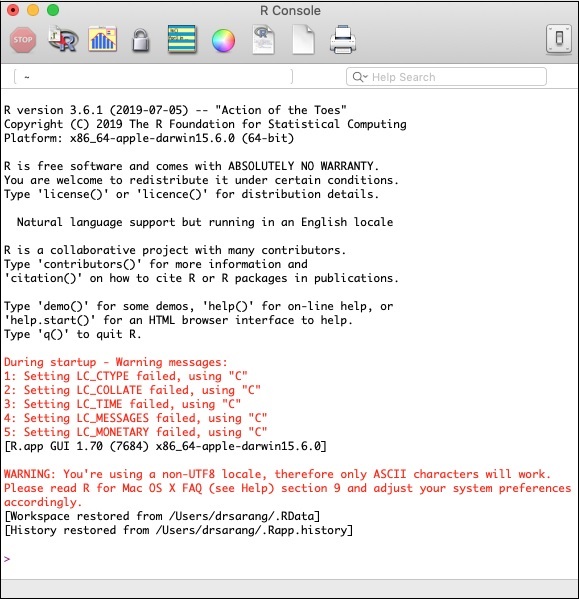
您的 H2O 安裝將在上述 R 提示符下完成。如果您更喜歡使用 RStudio,請在 R 控制檯子視窗中鍵入命令。
刪除舊版本
首先,使用以下命令在 R 提示符下刪除舊版本:
> if ("package:h2o" %in% search()) { detach("package:h2o", unload=TRUE) }
> if ("h2o" %in% rownames(installed.packages())) { remove.packages("h2o") }
下載依賴項
使用以下程式碼下載 H2O 的依賴項:
> pkgs <- c("RCurl","jsonlite")
for (pkg in pkgs) {
if (! (pkg %in% rownames(installed.packages()))) { install.packages(pkg) }
}
安裝 H2O
在 R 提示符下鍵入以下命令安裝 H2O:
> install.packages("h2o", type = "source", repos = (c("http://h2o-release.s3.amazonaws.com/h2o/latest_stable_R")))
以下螢幕截圖顯示了預期的輸出:
還有另一種在 R 中安裝 H2O 的方法。
從 CRAN 安裝 R
要從 CRAN 安裝 R,請在 R 提示符下使用以下命令:
> install.packages("h2o")
系統將要求您選擇映象:
--- Please select a CRAN mirror for use in this session ---
螢幕上將顯示一個顯示映象站點列表的對話方塊。選擇最近的位置或您選擇的映象。
測試安裝
在 R 提示符下,鍵入並執行以下程式碼:
> library(h2o) > localH2O = h2o.init() > demo(h2o.kmeans)
生成的輸出將如下面的螢幕截圖所示:
您在 R 中的 H2O 安裝現已完成。
安裝 Web GUI Flow
要安裝 GUI Flow,請從 H20 網站下載安裝檔案。將下載的檔案解壓縮到您首選的資料夾中。請注意安裝中存在 h2o.jar 檔案。使用以下命令在命令視窗中執行此檔案:
$ java -jar h2o.jar
一段時間後,您的控制檯視窗將顯示以下內容。
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: H2O started in 7725ms 07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: 07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO: Open H2O Flow in your web browser: http://192.168.1.18:54321 07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO:
要啟動 Flow,請在您的瀏覽器中開啟給定的 URL **https://:54321**。將出現以下螢幕:
在此階段,您的 Flow 安裝已完成。
在 Hadoop/Anaconda Cloud 上安裝
除非您是經驗豐富的開發者,否則您不會考慮在大型資料上使用 H2O。在此只需說明,H2O 模型可以在數 TB 的大型資料庫上高效執行。如果您的資料位於您的 Hadoop 安裝或雲中,請按照 H2O 網站上提供的步驟為您的資料庫安裝它。
現在您已成功在您的機器上安裝並測試了 H2O,您可以進行實際開發了。首先,我們將看到從命令提示符進行的開發。在我們接下來的課程中,我們將學習如何在 H2O Flow 中進行模型測試。
在命令提示符下進行開發
現在讓我們考慮使用 H2O 對眾所周知的 iris 資料集的植物進行分類,該資料集可免費用於開發機器學習應用程式。
透過在 shell 視窗中鍵入以下命令來啟動 Python 直譯器:
$ Python3
這將啟動 Python 直譯器。使用以下命令匯入 h2o 平臺:
>>> import h2o
我們將使用隨機森林演算法進行分類。這在 H2ORandomForestEstimator 包中提供。我們使用 import 語句如下匯入此包:
>>> from h2o.estimators import H2ORandomForestEstimator
我們透過呼叫其 init 方法來初始化 H2o 環境。
>>> h2o.init()
初始化成功後,您應該會在控制檯上看到以下訊息以及叢集資訊。
Checking whether there is an H2O instance running at https://:54321 . connected.
現在,我們將使用 H2O 中的 import_file 方法匯入 iris 資料。
>>> data = h2o.import_file('iris.csv')
進度將如下面的螢幕截圖所示:

將檔案載入到記憶體後,您可以透過顯示載入的表的前 10 行來驗證這一點。您可以使用 **head** 方法來做到這一點:
>>> data.head()
您將在表格格式中看到以下輸出。
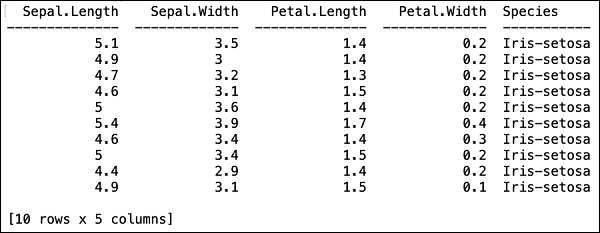
該表還顯示列名。我們將使用前四列作為我們 ML 演算法的特徵,並將最後一列 class 作為預測輸出。我們首先建立以下兩個變數,在呼叫我們的 ML 演算法時指定這一點。
>>> features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] >>> output = 'class'
接下來,我們透過呼叫 split_frame 方法將資料分成訓練集和測試集。
>>> train, test = data.split_frame(ratios = [0.8])
資料按 80:20 的比例分割。我們使用 80% 的資料進行訓練,20% 的資料進行測試。
現在,我們將內建的隨機森林模型載入到系統中。
>>> model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
在上一次呼叫中,我們將樹的數量設定為 50,樹的最大深度設定為 20,交叉驗證的摺疊數設定為 10。現在我們需要訓練模型。我們透過呼叫 train 方法如下進行:
>>> model.train(x = features, y = output, training_frame = train)
train 方法接收我們之前建立的特徵和輸出作為前兩個引數。訓練資料集設定為 train,這是我們完整資料集的 80%。在訓練期間,您將看到如下所示的進度:
現在,模型構建過程完成後,是時候測試模型了。我們透過對訓練好的模型物件呼叫 model_performance 方法來做到這一點。
>>> performance = model.model_performance(test_data=test)
在上一次方法呼叫中,我們將測試資料作為引數傳送。
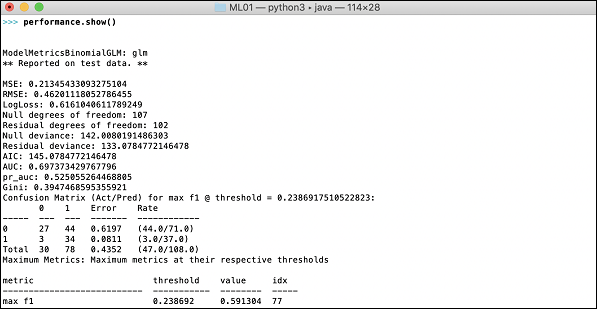
現在是時候檢視輸出了,這是我們模型的效能。您可以透過簡單地列印效能來做到這一點。
>>> print (performance)
這將為您提供以下輸出:
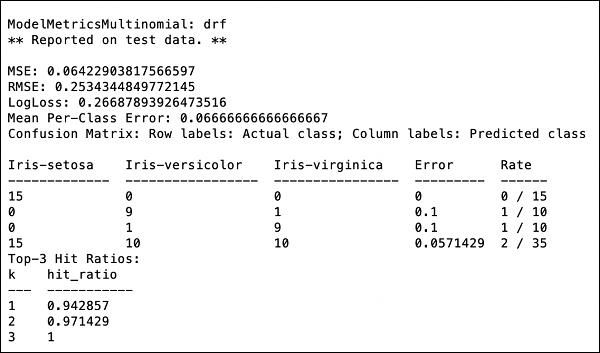
輸出顯示均方誤差 (MSE)、均方根誤差 (RMSE)、LogLoss,甚至混淆矩陣。
在 Jupyter 中執行
我們已經看到了從命令列執行的情況,也瞭解了每一行程式碼的目的。您可以在 Jupyter 環境中逐行或一次執行整個程式。完整的列表如下所示:
import h2o
from h2o.estimators import H2ORandomForestEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios=[0.8])
model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data=test)
print (performance)
執行程式碼並觀察輸出。現在您可以欣賞到在您的資料集上應用和測試隨機森林演算法是多麼容易了。H20 的強大功能遠不止於此。如果您想在同一資料集上嘗試另一個模型以檢視是否可以獲得更好的效能,該怎麼辦?這將在我們接下來的章節中解釋。
應用不同的演算法
現在,我們將學習如何將梯度提升演算法應用於我們之前的 dataset,以檢視它的效能如何。在上面的完整列表中,您只需要進行兩個小的更改,如下面的程式碼中突出顯示的那樣:
import h2o
from h2o.estimators import H2OGradientBoostingEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios = [0.8])
model = H2OGradientBoostingEstimator
(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data = test)
print (performance)
執行程式碼,您將獲得以下輸出:
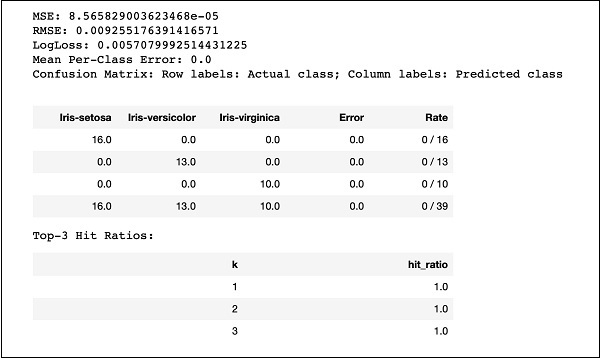
只需將 MSE、RMSE、混淆矩陣等結果與之前的輸出進行比較,然後決定使用哪個結果進行生產部署。事實上,您可以應用幾種不同的演算法來決定最符合您目的的那個。