
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP探索資料分佈
介紹
在處理任何資料科學或機器學習用例時,資料分佈能讓我們對資料有有用的見解。資料分佈指的是資料的可用方式及其當前狀態、關於資料特定部分的資訊、資料中的任何異常值以及與資料相關的中心趨勢。
為了探索資料分佈,有一些常用的圖形方法在處理資料時非常有用。在本文中,讓我們探索這些方法。
瞭解您的資料:圖形化方法
直方圖和KDE密度圖
直方圖是在圖形方法中使用最廣泛且最常見的資料探索工具。在直方圖中,矩形條用於表示特定變數或類別(或箱)的頻率。當資料可以存在於不同的桶中時,會用到分箱。
讓我們使用以下關於房價資料集的程式碼示例來了解直方圖。
資料集連結 − https://drive.google.com/file/d/1XbyBcw6OfE_w3ZeqPM1s_6jT8XeTCeOT/view?usp=sharing
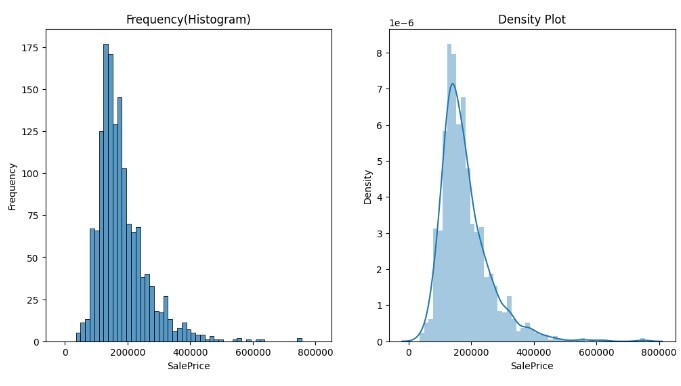
下面的程式碼幫助我們更有效地理解直方圖。在這個程式碼示例中,我們使用了房價資料集來繪製左側的銷售價格與頻率的頻率或直方圖。右側的圖是銷售價格與頻率分佈的KDE圖。密度圖是直方圖的機率密度函式。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
df = pd.read_csv("/content/house_price_data.csv")
figure, ax = plt.subplots(1, 2, sharex=True, figsize=(12, 6))
ax[0]= sns.histplot(data=df, x="SalePrice",ax=ax[0])
ax[0].set_ylabel("Frequency")
ax[0].set_xlabel("SalePrice")
ax[0].set_title("Frequency(Histogram)")
ax[1]= sns.distplot(df.SalePrice, kde = True,ax=ax[1])
ax[1].set_ylabel("Density")
ax[1].set_xlabel("SalePrice")
ax[1].set_title("Frequency(Histogram)")
輸出
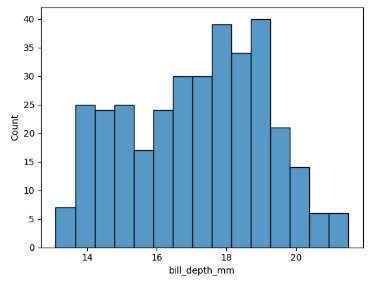
在下面的程式碼示例中,我們使用了不同類別的箱。我們使用了企鵝資料集來繪製喙深度與計數。這裡,喙深度被分成不同的區間,並在x軸上繪製,y軸上繪製計數或頻率。
# Using bins on penguins' dataset – seaborn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
data_pen = sns.load_dataset("penguins")
sns.histplot(data=data_pen, x="bill_depth_mm", bins=15)
輸出
箱線圖
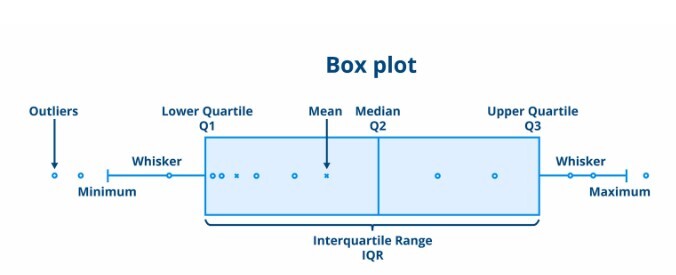
箱線圖也稱為盒須圖。箱線圖表示資料的百分位數。整個資料被分成不同的百分位數,其中主要分位數是第25、50和75百分位數。第50百分位數表示中位數。箱線圖顯示位於第25和75百分位數之間的資料,稱為IQR(四分位數間距)。
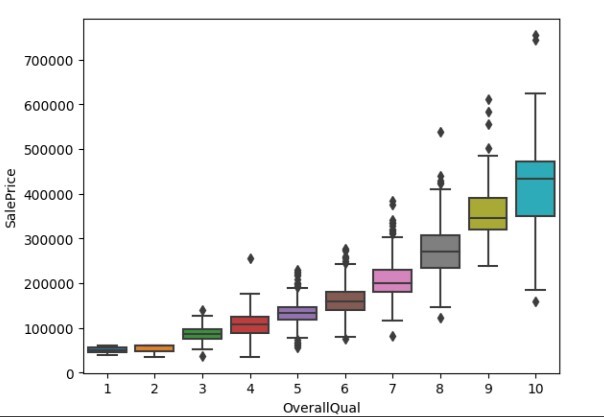
讓我們使用以下關於房價資料集的程式碼示例來了解箱線圖。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
df = pd.read_csv("/content/house_price_data.csv")
subset = pd.concat([df['SalePrice'], df['OverallQual']])
figure = sns.boxplot(x='OverallQual', y="SalePrice", data=df)
輸出
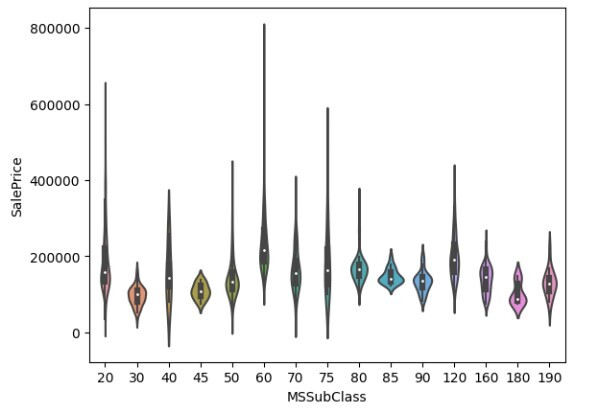
小提琴圖
它看起來類似於箱線圖,但是它還在圖中顯示了變數的機率分佈。它用於比較所觀察變數的機率分佈。
讓我們使用以下關於房價資料集的程式碼示例來了解小提琴圖。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
df = pd.read_csv("/content/house_price_data.csv")
subset = pd.concat([df['SalePrice'], df['MSSubClass']])
figure = sns.violinplot(x='MSSubClass', y="SalePrice", data=df)
輸出
結論
箱線圖、密度圖和小提琴圖是探索資料分佈最流行和最常用的方法。它們可靠且受到機器學習工程師和資料科學家的高度信賴。這些圖讓我們瞭解資料以及資料的分佈方式。此外,還可以從圖中確定關於偏度、稀疏性等的基本資訊。箱線圖和小提琴圖等圖還可以指示異常值點。

369 次瀏覽
