
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP關於FLAIR:一個NLP框架的全部內容
FLAIR,代表前瞻性人工智慧推理 (Forward-Looking AI Reasoning),是一個近年來在自然語言處理 (NLP) 領域日益受到關注的複雜框架。FLAIR憑藉其強大的功能和前沿方法,改變了我們處理NLP任務的方式,提高了準確性、效率和多樣性。
在這篇詳細的文章中,我們將深入探討FLAIR的複雜性,探索其基本元件和功能,並透過真實的例子展示其優異的效能。
什麼是FLAIR?
FLAIR是由Zalando Research開發的一個全面的NLP框架。它旨在為研究人員和開發人員提供一個靈活且高效的工具集,用於各種文字分析任務。FLAIR的特點在於其對前沿序列標註、文字分類和語言建模的重視。它融合了深度學習和經典機器學習技術的最佳特性,以提供準確高效的結果。
FLAIR主要由兩部分組成:FLAIR庫和FLAIR嵌入。FLAIR庫包含各種預配置的模型和實用程式,用於常見的NLP任務。另一方面,FLAIR嵌入提供了一個詞嵌入和上下文字串嵌入庫,這些庫是在大型資料集上訓練的。
FLAIR模型
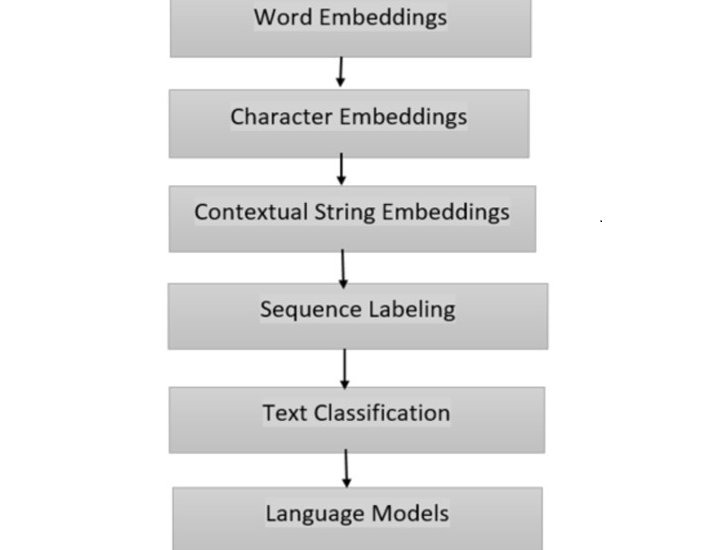
FLAIR模型圖示了資訊流經FLAIR不同元件的過程,直觀地展現了文字如何被處理和分析。該圖顯示了以下元件:
詞嵌入 − 這些嵌入捕獲給定文字中單個單詞的語義和句法資訊。它們是使用Word2Vec和GloVe等技術生成的。
字元嵌入 − FLAIR還結合了字元級嵌入來捕獲單詞的形態資訊。這有助於模型處理詞彙表外的單詞,並提高其魯棒性。
上下文字串嵌入 − FLAIR利用上下文字串嵌入根據單詞的周圍上下文來編碼單詞的含義。這使得模型能夠有效地捕獲詞義消歧和上下文資訊。
序列標註 − FLAIR使用序列標註模型(例如雙向LSTM(長短期記憶))為文字中的單個標記分配標籤。此元件對於命名實體識別和詞性標註等任務至關重要。
文字分類 − FLAIR使用卷積神經網路 (CNN) 和自注意力機制等方法支援文字分類任務。此元件使模型能夠將文件分類到不同的類別或預測情感。
語言模型 − FLAIR結合了捕獲文字全域性上下文的語言模型。這些模型(例如轉換器)是在大型語料庫上預訓練的,可以生成上下文化詞表示。
用於序列標註的上下文字串嵌入
FLAIR中的上下文字串嵌入是文字中單詞或標記的表示,它們根據周圍上下文捕獲其含義。這些嵌入透過考慮它們出現的整個句子或標記序列來編碼單個單詞的語義和句法資訊。此上下文資訊對於NLP中的序列標註任務(例如命名實體識別 (NER) 和詞性 (POS) 標註)至關重要。
示例
讓我們來看一個上下文字串嵌入實際應用的例子:“貓坐在墊子上”。一個詞在句子中出現的上下文會影響其解釋和含義。例如,“墊子”可以指地毯,“貓”可以指貓科動物。
在FLAIR中,上下文字串嵌入模型(通常基於BERT或RoBERTa等轉換器架構)一次處理整個句子。它考慮句子中每個單詞的上下文,併為該單詞生成密集向量表示或嵌入。
以下是上下文字串嵌入如何用於序列標註的圖示:
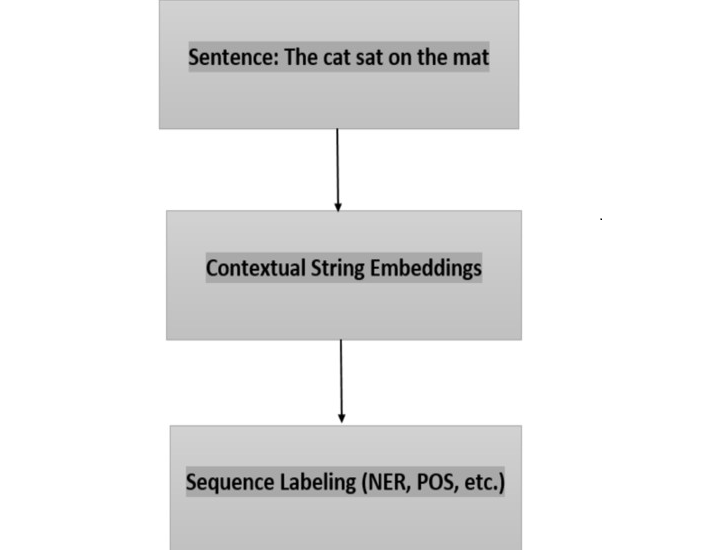
在圖中,輸入句子“貓坐在墊子上”被送入上下文字串嵌入元件,該元件整體處理句子。上下文字串嵌入模型為句子中的每個單詞生成密集向量表示,捕獲其上下文含義。
然後,這些上下文字串嵌入用作序列標註任務(如命名實體識別 (NER)或詞性 (POS)標註)的輸入。序列標註元件根據上下文和手頭的任務為句子中的每個單詞應用特定標籤。
例如,在命名實體識別任務中,序列標註元件可以識別並將諸如“貓”之類的詞分類為“動物”型別的實體,並將“墊子”分類為“物體”型別的實體。
上下文字串嵌入透過利用句子中單詞的上下文資訊,在提高序列標註任務的效能方面發揮著至關重要的作用。它們使模型能夠根據周圍的單詞做出更準確的預測,從而提高文字的準確性和理解能力。
FLAIR的訓練過程
訓練FLAIR模型涉及一系列最佳化效能的步驟。該過程通常從資料預處理和標註開始。這包括清理文字,將其標記為單個單詞,並標記特定的實體或類別。
資料準備就緒後,FLAIR採用深度學習技術來訓練模型。這包括將標記資料輸入模型並迭代更新其引數。反向傳播和梯度下降等技術用於最佳化模型在給定任務上的效能。
FLAIR的應用領域
FLAIR在各種NLP領域都有應用。FLAIR擅長的一些關鍵應用領域包括:
情感分析
情感分析包括確定文字中表達的情感,無論是正面、負面還是中性。FLAIR的模型可以準確地分析社交媒體帖子、客戶評論和線上討論中的情感。
命名實體識別
命名實體識別 (NER) 旨在識別和分類文字中的命名實體,例如人名、組織名、地名和日期。FLAIR的序列標註模型在NER任務中表現出色,可提供準確的資訊提取結果。
文字分類
文字分類包括將文件分類到預定義的類別或主題中。FLAIR提供了強大的文字分類模型,可以執行垃圾郵件檢測、主題建模和文件組織等任務。
FLAIR與其他NLP框架的比較
由於其獨特的特性和優勢,FLAIR在SpaCy和NLTK等其他NLP框架中脫穎而出。以下是關於一些關鍵比較:
靈活性− 與其他框架相比,FLAIR提供了更靈活和模組化的方法,允許研究人員和開發人員試驗各種元件和配置。
最先進的結果− 由於其對先進深度學習技術和預訓練模型的關注,FLAIR在各種NLP任務上始終取得最先進的結果。
易用性− FLAIR提供使用者友好的介面和全面的API文件,使該領域的初學者和專家都能使用它。
但是,需要注意的是,每個框架都有其優缺點。雖然FLAIR在序列標註和語言建模方面表現出色,但SpaCy和NLTK在其他NLP任務中也具有其獨特的特性。
FLAIR實戰:真實案例
為了說明FLAIR的卓越能力,讓我們探索一些它表現出色的實際應用:
命名實體識別 (NER)
命名實體識別是一項基本的NLP任務,它涉及識別和分類文字中的命名實體。FLAIR的上下文嵌入使其能夠透過捕獲單詞與其周圍上下文之間細微的關係來勝任NER。即使在複雜和模糊的上下文中,該框架也能準確識別諸如人名、組織名、地名等命名實體。
考慮以下示例句子:
"Apple Inc. is planning to open a new store in downtown San Francisco."
FLAIR能夠正確地識別“Apple Inc.”為組織,“舊金山”為地點,展現了其在命名實體識別(NER)任務中的熟練程度。
情感分析
情感分析涉及確定文字中表達的情感,無論是積極的、消極的還是中性的。FLAIR的上下文嵌入與文件池化技術相結合,使其能夠透過考慮整體上下文和詞語之間的依賴關係來捕捉情感的細微之處。
讓我們以以下句子為例:
"The movie was absolutely fantastic; I loved every minute of it!"
FLAIR將準確識別此句中表達的積極情感,展現其在情感分析任務中的有效性。
結論
總而言之,FLAIR是一個全面的NLP框架,為文字分析任務提供了強大的解決方案。憑藉其先進的模型、靈活的架構和最先進的效能,FLAIR已成為NLP社群研究人員和開發人員的首選工具。無論您從事情感分析、命名實體識別還是文字分類工作,FLAIR都能提供實現準確高效結果所需的工具和資源。

瀏覽量:372
