- Elixir 教程
- Elixir - 首頁
- Elixir - 概述
- Elixir - 環境配置
- Elixir - 基本語法
- Elixir - 資料型別
- Elixir - 變數
- Elixir - 運算子
- Elixir - 模式匹配
- Elixir - 決策語句
- Elixir - 字串
- Elixir - 字元列表
- Elixir - 列表和元組
- Elixir - 關鍵字列表
- Elixir - 對映
- Elixir - 模組
- Elixir - 別名
- Elixir - 函式
- Elixir - 遞迴
- Elixir - 迴圈
- Elixir - 可列舉
- Elixir - 流
- Elixir - 結構體
- Elixir - 協議
- Elixir - 檔案 I/O
- Elixir - 程序
- Elixir - 符號
- Elixir - 列表推導式
- Elixir - 型別宣告
- Elixir - 行為
- Elixir - 錯誤處理
- Elixir - 宏
- Elixir - 庫
- Elixir 有用資源
- Elixir 快速指南
- Elixir - 有用資源
- Elixir - 討論
Elixir 快速指南
Elixir - 概述
Elixir 是一種動態函式式語言,設計用於構建可擴充套件和易於維護的應用程式。它利用 Erlang VM,該虛擬機器以執行低延遲、分散式和容錯系統而聞名,同時也能成功應用於 Web 開發和嵌入式軟體領域。
Elixir 是一種基於 Erlang 和 Erlang VM 的函式式動態語言。Erlang 是一種最初由愛立信於 1986 年編寫的語言,用於解決諸如分散式、容錯和併發等電話問題。由 José Valim 編寫的 Elixir 擴充套件了 Erlang,並在 Erlang VM 中提供了更友好的語法。它在保持與 Erlang 相同效能水平的同時實現了這一點。
Elixir 的特性
現在讓我們討論 Elixir 的一些重要特性:
可擴充套件性 - 所有 Elixir 程式碼都在輕量級程序中執行,這些程序是隔離的,並透過訊息交換資訊。
容錯性 - Elixir 提供了主管程序,用於描述在出現問題時如何重啟系統部分,返回到已知的初始狀態,從而保證系統正常執行。這確保您的應用程式/平臺永不宕機。
函數語言程式設計 - 函數語言程式設計提倡一種程式設計風格,幫助開發人員編寫簡潔、快速且易於維護的程式碼。
構建工具 - Elixir 附帶一組開發工具。Mix 就是這樣一個工具,它簡化了專案建立、任務管理、執行測試等操作。它還有一個自己的包管理器 - Hex。
Erlang 相容性 - Elixir 執行在 Erlang VM 上,使開發人員可以完全訪問 Erlang 的生態系統。
Elixir - 環境配置
要執行 Elixir,您需要在本地系統上進行設定。
要安裝 Elixir,您首先需要 Erlang。在某些平臺上,Elixir 包中包含 Erlang。
安裝 Elixir
現在讓我們瞭解如何在不同的作業系統中安裝 Elixir。
Windows 設定
要在 Windows 上安裝 Elixir,請從此處下載安裝程式 https://elixir-lang.org/install.html#windows,然後只需單擊下一步即可完成所有步驟。您將在本地系統上安裝它。
如果您在安裝過程中遇到任何問題,可以檢視此頁面以獲取更多資訊。
Mac 設定
如果您已安裝 Homebrew,請確保它是最新版本。要更新,請使用以下命令:
brew update
現在,使用以下命令安裝 Elixir:
brew install elixir
Ubuntu/Debian 設定
在 Ubuntu/Debian 系統中安裝 Elixir 的步驟如下:
新增 Erlang Solutions 倉庫:
wget https://packages.erlang-solutions.com/erlang-solutions_1.0_all.deb && sudo dpkg -i erlang-solutions_1.0_all.deb sudo apt-get update
安裝 Erlang/OTP 平臺及其所有應用程式:
sudo apt-get install esl-erlang
安裝 Elixir:
sudo apt-get install elixir
其他 Linux 發行版
如果您使用的是其他 Linux 發行版,請訪問此頁面以在本地系統上設定 Elixir。
測試設定
要在您的系統上測試 Elixir 設定,請開啟終端並在其中輸入 iex。它將開啟互動式 Elixir shell,如下所示:
Erlang/OTP 19 [erts-8.0] [source-6dc93c1] [64-bit] [smp:4:4] [async-threads:10] [hipe] [kernel-poll:false] Interactive Elixir (1.3.1) - press Ctrl+C to exit (type h() ENTER for help) iex(1)>
Elixir 現在已成功安裝在您的系統上。
Elixir - 基本語法
我們將從慣例的“Hello World”程式開始。
要啟動 Elixir 互動式 shell,請輸入以下命令。
iex
shell 啟動後,使用IO.puts函式將字串“輸出”到控制檯。在您的 Elixir shell 中輸入以下內容:
IO.puts "Hello world"
在本教程中,我們將使用 Elixir 指令碼模式,即將 Elixir 程式碼儲存在副檔名為.ex的檔案中。現在讓我們將上述程式碼儲存在test.ex檔案中。在接下來的步驟中,我們將使用elixirc執行它:
IO.puts "Hello world"
現在讓我們嘗試執行上述程式,如下所示:
$elixirc test.ex
上述程式生成以下結果:
Hello World
在這裡,我們呼叫函式IO.puts以將字串作為輸出生成到我們的控制檯。此函式也可以像我們在 C、C++、Java 等中那樣呼叫,在函式名後面提供括號中的引數:
IO.puts("Hello world")
註釋
單行註釋以“#”符號開頭。沒有多行註釋,但是您可以堆疊多個註釋。例如:
#This is a comment in Elixir
行尾
Elixir 中不需要像“;”這樣的行尾。但是,我們可以使用“;”在同一行中包含多個語句。例如:
IO.puts("Hello"); IO.puts("World!")
上述程式生成以下結果:
Hello World!
識別符號
識別符號(例如變數、函式名)用於標識變數、函式等。在 Elixir 中,您可以使用以下方法命名識別符號:以小寫字母開頭,後跟數字、下劃線和大寫字母。此命名約定通常稱為 snake_case。例如,以下是 Elixir 中的一些有效識別符號:
var1 variable_2 one_M0r3_variable
請注意,變數也可以用下劃線開頭命名。不打算使用的值必須賦值給 _ 或賦值給以下劃線開頭的變數:
_some_random_value = 42
此外,Elixir 依靠下劃線來使函式對模組私有。如果您在模組中使用下劃線開頭的函式名,並匯入該模組,則此函式不會被匯入。
關於 Elixir 中的函式命名還有許多更復雜的細節,我們將在接下來的章節中討論。
保留字
以下詞語是保留字,不能用作變數、模組或函式名。
after and catch do inbits inlist nil else end not or false fn in rescue true when xor __MODULE__ __FILE__ __DIR__ __ENV__ __CALLER__
Elixir - 資料型別
要使用任何語言,您需要了解該語言支援的基本資料型別。在本章中,我們將討論 Elixir 語言支援的 7 種基本資料型別:整數、浮點數、布林值、原子、字串、列表和元組。
數值型別
Elixir 與任何其他程式語言一樣,都支援整數和浮點數。如果您開啟 Elixir shell 並輸入任何整數或浮點數作為輸入,它將返回其值。例如:
42
執行上述程式時,將產生以下結果:
42
您還可以使用八進位制、十六進位制和二進位制定義數字。
八進位制
要以八進位制定義數字,請在其前面加上“0o”。例如,八進位制中的 0o52 等於十進位制中的 42。
十六進位制
要以十進位制定義數字,請在其前面加上“0x”。例如,十六進位制中的 0xF1 等於十進位制中的 241。
二進位制
要以二進位制定義數字,請在其前面加上“0b”。例如,二進位制中的 0b1101 等於十進位制中的 13。
Elixir 支援 64 位雙精度浮點數。它們也可以使用指數樣式定義。例如,10145230000 可以寫成 1.014523e10
原子
原子的名稱就是其值。可以使用冒號 (:) 符號建立它們。例如:
:hello
布林值
Elixir 支援true和false作為布林值。這兩個值實際上分別附加到原子 :true 和 :false。
字串
Elixir 中的字串用雙引號括起來,並使用 UTF-8 編碼。它們可以跨多行幷包含插值。要定義字串,只需用雙引號將其括起來:
"Hello world"
要定義多行字串,我們使用類似於 python 的語法,使用三個雙引號:
""" Hello World! """
我們將在字串章節中深入學習字串、二進位制和字元列表(類似於字串)。
二進位制
二進位制是用<< >>括起來的位元組序列,用逗號分隔。例如:
<< 65, 68, 75>>
二進位制主要用於處理位和位元組相關資料。預設情況下,它們可以在每個值中儲存 0 到 255。可以使用 size 函式增加此大小限制,該函式說明儲存該值應占用多少位。例如:
<<65, 255, 289::size(15)>>
列表
Elixir 使用方括號指定值列表。值可以是任何型別。例如:
[1, "Hello", :an_atom, true]
列表具有名為 hd 和 tl 的內建函式,用於獲取列表的頭和尾,它們分別返回列表的頭和尾。有時,當您建立列表時,它將返回字元列表。這是因為當 Elixir 看到可列印的 ASCII 字元列表時,它會將其列印為字元列表。請注意,字串和字元列表並不相等。我們將在後面的章節中進一步討論列表。
元組
Elixir 使用花括號定義元組。與列表一樣,元組可以儲存任何值。
{ 1, "Hello", :an_atom, true
這裡出現一個問題:為什麼同時提供列表和元組,而它們的工作方式相同?這是因為它們具有不同的實現。
列表實際上儲存為連結串列,因此在列表中插入和刪除操作非常快。
另一方面,元組儲存在連續的記憶體塊中,這使得訪問它們的速度更快,但在插入和刪除操作上增加了額外的成本。
Elixir - 變數
變數為我們的程式提供了可操作的命名儲存空間。Elixir 中的每個變數都有一個特定的型別,該型別決定變數記憶體的大小和佈局;可在該記憶體中儲存的值的範圍;以及可應用於變數的操作集。
變數型別
Elixir 支援以下基本型別的變數。
整數 (Integer)
這些用於表示整數。在 32 位架構上大小為 32 位,在 64 位架構上大小為 64 位。Elixir 中的整數始終是有符號的。如果整數的大小超過其限制,Elixir 會將其轉換為大整數 (BigInteger),大整數的記憶體佔用範圍為 3 到 n 個字,取決於記憶體中可以容納的大小。
浮點數 (Float)
Elixir 中的浮點數具有 64 位精度。在記憶體方面也類似於整數。定義浮點數時,可以使用指數表示法。
布林值 (Boolean)
布林值可以取兩個值:true 或 false。
字串
字串在 Elixir 中使用 UTF-8 編碼。它們有一個字串模組,為程式設計師提供了許多操作字串的功能。
匿名函式/Lambda 表示式
這些是可以定義並賦值給變數的函式,然後可以用來呼叫此函式。
集合 (Collections)
Elixir 中提供了許多集合型別。其中一些包括列表、元組、對映、二進位制等。這些將在後續章節中討論。
變數宣告
變數宣告告訴直譯器在哪裡以及如何建立變數的儲存空間。Elixir 不允許我們只宣告變數。變數必須同時宣告和賦值。例如,要建立一個名為 life 的變數並將其賦值為 42,我們可以執行以下操作:
life = 42
這將把變數 life 繫結到值 42。如果要將此變數重新賦值為一個新值,可以使用與上述相同的語法,即:
life = "Hello world"
變數命名
Elixir 中的變數命名遵循 **snake_case** 約定,即所有變數必須以小寫字母開頭,後跟 0 個或多個字母(大小寫均可),最後可選地跟一個 '?' 或 '!'。
變數名也可以以下劃線開頭,但這隻能在忽略變數時使用,即該變數不會再次使用,但需要賦值。
列印變數
在互動式 shell 中,只需輸入變數名即可列印變數。例如,如果建立了一個變數:
life = 42
並在 shell 中輸入 'life',則輸出為:
42
但是,如果要將變數輸出到控制檯(從檔案執行外部指令碼時),需要將變數作為輸入提供給 **IO.puts** 函式:
life = 42 IO.puts life
或
life = 42 IO.puts(life)
這將給出以下輸出:
42
Elixir - 運算子
運算子是一個符號,它告訴編譯器執行特定的數學或邏輯操作。Elixir 提供了大量的運算子。它們分為以下幾類:
- 算術運算子
- 比較運算子
- 布林運算子
- 其他運算子
算術運算子
下表顯示了 Elixir 語言支援的所有算術運算子。假設變數 **A** 為 10,變數 **B** 為 20,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| + | 將兩個數字相加。 | A + B 將得到 30 |
| - | 從第一個數字中減去第二個數字。 | A - B 將得到 -10 |
| * | 將兩個數字相乘。 | A * B 將得到 200 |
| / | 將第一個數字除以第二個數字。這會將數字轉換為浮點數並返回浮點數結果。 | A / B 將得到 0.5。 |
| div | 此函式用於獲取除法的商。 | div(10, 20) 將得到 0 |
| rem | 此函式用於獲取除法的餘數。 | rem(A, B) 將得到 10 |
比較運算子
Elixir 中的比較運算子與大多數其他語言中提供的運算子基本相同。下表總結了 Elixir 中的比較運算子。假設變數 **A** 為 10,變數 **B** 為 20,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| == | 檢查左側的值是否等於右側的值(如果型別不同則轉換型別)。 | A == B 將得到 false |
| != | 檢查左側的值是否不等於右側的值。 | A != B 將得到 true |
| === | 檢查左側的值的型別是否等於右側的值的型別,如果是,則檢查值是否相同。 | A === B 將得到 false |
| !== | 與上面相同,但檢查的是不等式而不是等式。 | A !== B 將得到 true |
| > | 檢查左運算元的值是否大於右運算元的值;如果是,則條件為 true。 | A > B 將得到 false |
| < | 檢查左運算元的值是否小於右運算元的值;如果是,則條件為 true。 | A < B 將得到 true |
| >= | 檢查左運算元的值是否大於或等於右運算元的值;如果是,則條件為 true。 | A >= B 將得到 false |
| <= | 檢查左運算元的值是否小於或等於右運算元的值;如果是,則條件為 true。 | A <= B 將得到 true |
邏輯運算子
Elixir 提供 6 個邏輯運算子:and、or、not、&&、|| 和 !。前三個 **and or not** 是嚴格的布林運算子,這意味著它們期望它們的第一個引數是布林值。非布林引數將引發錯誤。而接下來的三個 **&&、|| 和 !** 不是嚴格的,不需要第一個值嚴格為布林值。它們的工作方式與其嚴格的對應部分相同。假設變數 **A** 為 true,變數 **B** 為 20,則:
| 運算子 | 描述 | 示例 |
|---|---|---|
| and | 檢查提供的兩個值是否都為真值,如果是,則返回第二個變數的值。(邏輯與)。 | A and B 將得到 20 |
| 或 | 檢查提供的任何一個值是否為真值。返回任何一個真值。否則返回 false。(邏輯或)。 | A or B 將得到 true |
| not | 一元運算子,反轉給定輸入的值。 | not A 將得到 false |
| && | 非嚴格 **and**。工作方式與 **and** 相同,但不期望第一個引數為布林值。 | B && A 將得到 20 |
| || | 非嚴格 **or**。工作方式與 **or** 相同,但不期望第一個引數為布林值。 | B || A 將得到 true |
| ! | 非嚴格 **not**。工作方式與 **not** 相同,但不期望引數為布林值。 | !A 將得到 false |
**注意 -** and、or、&& 和 || 是短路運算子。這意味著如果 **and** 的第一個引數為 false,則它不會進一步檢查第二個引數。如果 **or** 的第一個引數為 true,則它不會檢查第二個引數。例如:
false and raise("An error")
#This won't raise an error as raise function wont get executed because of short
#circuiting nature of and operator
位運算子
位運算子作用於位並執行逐位運算。Elixir 將位運算模組作為 **Bitwise** 包的一部分提供,因此要使用它們,需要 `use` 位運算模組。要使用它,請在 shell 中輸入以下命令:
use Bitwise
在以下示例中,假設 A 為 5,B 為 6:
| 運算子 | 描述 | 示例 |
|---|---|---|
| &&& | 按位與運算子僅當兩個運算元中都存在位時,才將該位複製到結果中。 | A &&& B 將得到 4 |
| ||| | 按位或運算子如果位在任何一個運算元中存在,則將其複製到結果中。 | A ||| B 將得到 7 |
| >>> | 按位右移運算子將第一個運算元的位向右移動第二個運算元中指定的位數。 | A >>> B 將得到 0 |
| <<< | 按位左移運算子將第一個運算元的位向左移動第二個運算元中指定的位數。 | A <<< B 將得到 320 |
| ^^^ | 按位異或運算子僅當位在兩個運算元中不同時,才將其複製到結果中。 | A ^^^ B 將得到 3 |
| ~~~ | 一元按位非運算子反轉給定數字的位。 | ~~~A 將得到 -6 |
其他運算子
除了上述運算子外,Elixir 還提供了一系列其他運算子,例如 **連線運算子、匹配運算子、固定運算子、管道運算子、字串匹配運算子、程式碼點運算子、捕獲運算子、三元運算子**,使其成為一種非常強大的語言。
Elixir - 模式匹配
模式匹配是 Elixir 從 Erlang 繼承的一種技術。這是一種非常強大的技術,允許我們從複雜的資料結構(如列表、元組、對映等)中提取更簡單的子結構。
匹配有兩個主要部分,**左邊**和**右邊**。右邊是任何型別的資料結構。左邊嘗試匹配右邊的資料結構,並將左邊的任何變數繫結到右邊的相應子結構。如果找不到匹配項,運算子將引發錯誤。
最簡單的匹配是左邊是一個單獨的變數,右邊是任何資料結構。**此變數將匹配任何內容**。例如:
x = 12 x = "Hello" IO.puts(x)
您可以將變數放在結構內,以便捕獲子結構。例如:
[var_1, _unused_var, var_2] = [{"First variable"}, 25, "Second variable" ]
IO.puts(var_1)
IO.puts(var_2)
這會將值 **{"First variable"}** 儲存在 var_1 中,並將值 **"Second variable"** 儲存在 var_2 中。還有一個特殊的 **_** 變數(或以 '_' 為字首的變數),它的作用與其他變數完全相同,但它告訴 Elixir,**“確保這裡有一些東西,但我並不關心它究竟是什麼。”**。在前面的示例中,_unused_var 就是這樣一個變數。
我們可以使用這種技術匹配更復雜的模式。**例如**,如果要解包並獲取列表中的元組中的數字,而該列表本身又在另一個列表中,可以使用以下命令:
[_, [_, {a}]] = ["Random string", [:an_atom, {24}]]
IO.puts(a)
上述程式生成以下結果:
24
這會將 **a** 繫結到 24。其他值被忽略,因為我們使用了 '_'。
在模式匹配中,如果我們在**右邊**使用變數,則使用其值。如果要使用左邊變數的值,則需要使用固定運算子。
例如,如果有一個值為 25 的變數 "a",並且要將其與另一個值為 25 的變數 "b" 匹配,則需要輸入:
a = 25 b = 25 ^a = b
最後一行匹配 **a** 的當前值,而不是將其賦值給 **b** 的值。如果左、右兩側的集合不匹配,匹配運算子將引發錯誤。例如,如果嘗試將元組與列表匹配,或者將大小為 2 的列表與大小為 3 的列表匹配,則會顯示錯誤。
Elixir - 決策語句
決策結構要求程式設計師指定一個或多個條件,由程式進行評估或測試,以及如果條件確定為 **true** 則要執行的語句,以及可選地,如果條件確定為 **false** 則要執行的其他語句。
以下是大多數程式語言中常見的典型決策結構的一般形式:
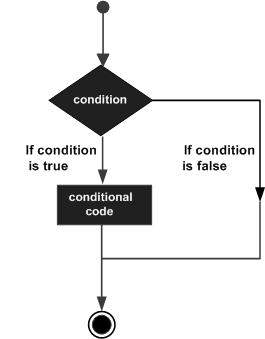
Elixir 提供了與許多其他程式語言類似的 if/else 條件結構。它還有一個 **cond** 語句,該語句呼叫它找到的第一個 true 值。case 是另一個控制流語句,它使用模式匹配來控制程式的流程。讓我們深入瞭解一下它們。
Elixir 提供以下幾種決策語句。點選以下連結檢視它們的詳細資訊。
| 序號 | 語句及描述 |
|---|---|
| 1 | if 語句
if 語句由一個布林表示式後跟do,一個或多個可執行語句,最後是一個end關鍵字組成。只有當布林條件計算結果為真時,if 語句中的程式碼才會執行。 |
| 2 | if..else 語句
if 語句後面可以跟一個可選的 else 語句(在 do..end 塊內),當布林表示式為假時,else 語句會執行。 |
| 3 | unless 語句
unless 語句與 if 語句具有相同的結構。只有當指定的條件為假時,unless 語句中的程式碼才會執行。 |
| 4 | unless..else 語句
unless..else 語句與 if..else 語句具有相同的結構。只有當指定的條件為假時,unless 語句中的程式碼才會執行。 |
| 5 | cond
cond 語句用於根據多個條件執行程式碼。它類似於其他多種程式語言中的 if...else if….else 結構。 |
| 6 | case
case 語句可以被認為是命令式語言中 switch 語句的替代品。case 接收一個變數/字面量,並用不同的 case 對其應用模式匹配。如果任何 case 匹配,Elixir 將執行與該 case 關聯的程式碼並退出 case 語句。 |
Elixir - 字串
Elixir 中的字串用雙引號括起來,並使用 UTF-8 編碼。與 C 和 C++ 中預設字串使用 ASCII 編碼且只有 256 個不同字元不同,UTF-8 包含 1,112,064 個碼位。這意味著 UTF-8 編碼包含這麼多不同的字元。由於字串使用 utf-8,我們也可以使用像 ö、ł 等符號。
建立字串
要建立一個字串變數,只需將一個字串賦值給一個變數:
str = "Hello world"
要將此列印到控制檯,只需呼叫IO.puts 函式並傳入變數 str:
str = str = "Hello world" IO.puts(str)
上述程式生成以下結果:
Hello World
空字串
可以使用字串字面量""建立一個空字串。例如:
a = ""
if String.length(a) === 0 do
IO.puts("a is an empty string")
end
以上程式產生以下結果。
a is an empty string
字串插值
字串插值是一種透過將常量、變數、字面量和表示式的值包含在字串字面量中來從它們的混合構建新字串值的方法。Elixir 支援字串插值,要在字串中使用變數,編寫時用大括號將其括起來,並在花括號前加上'#'符號。
例如:
x = "Apocalypse"
y = "X-men #{x}"
IO.puts(y)
這將取 x 的值並將其替換到 y 中。以上程式碼將產生以下結果:
X-men Apocalypse
字串連線
我們已經在前面的章節中看到了字串連線的使用。'<>' 運算子用於連線 Elixir 中的字串。要連線兩個字串,
x = "Dark" y = "Knight" z = x <> " " <> y IO.puts(z)
以上程式碼產生以下結果:
Dark Knight
字串長度
要獲取字串的長度,我們使用String.length函式。將字串作為引數傳遞,它將顯示其大小。例如:
IO.puts(String.length("Hello"))
執行以上程式時,會產生以下結果:
5
反轉字串
要反轉字串,將其傳遞給 String.reverse 函式。例如:
IO.puts(String.reverse("Elixir"))
上述程式生成以下結果:
rixilE
字串比較
要比較兩個字串,可以使用 == 或 === 運算子。例如:
var_1 = "Hello world"
var_2 = "Hello Elixir"
if var_1 === var_2 do
IO.puts("#{var_1} and #{var_2} are the same")
else
IO.puts("#{var_1} and #{var_2} are not the same")
end
上述程式生成以下結果:
Hello world and Hello elixir are not the same.
字串匹配
我們已經看到了 =~ 字串匹配運算子的使用。要檢查字串是否與正則表示式匹配,我們也可以使用字串匹配運算子或 String.match? 函式。例如:
IO.puts(String.match?("foo", ~r/foo/))
IO.puts(String.match?("bar", ~r/foo/))
上述程式生成以下結果:
true false
這也可以透過使用 =~ 運算子來實現。例如:
IO.puts("foo" =~ ~r/foo/)
上述程式生成以下結果:
true
字串函式
Elixir 支援大量與字串相關的函式,一些最常用的函式列在下表中。
| 序號 | 函式及其用途 |
|---|---|
| 1 | at(string, position) 返回給定 utf8 字串中 position 位置的 grapheme。如果 position 大於字串長度,則返回 nil |
| 2 | capitalize(string) 將給定字串中的第一個字元轉換為大寫,其餘轉換為小寫 |
| 3 | contains?(string, contents) 檢查字串是否包含任何給定的內容 |
| 4 | downcase(string) 將給定字串中的所有字元轉換為小寫 |
| 5 | ends_with?(string, suffixes) 如果字串以任何給定的字尾結尾,則返回 true |
| 6 | first(string) 返回 utf8 字串中的第一個 grapheme,如果字串為空,則返回 nil |
| 7 |
last(string) 返回 utf8 字串中的最後一個 grapheme,如果字串為空,則返回 nil |
| 8 |
replace(subject, pattern, replacement, options \\ []) 返回一個新字串,該字串透過用 replacement 替換 subject 中 pattern 的出現來建立 |
| 9 |
slice(string, start, len) 返回從偏移量 start 開始,長度為 len 的子字串 |
| 10 |
split(string) 在每個 Unicode 空格出現的位置將字串劃分為子字串,忽略前導和尾隨空格。空格組被視為單個出現。分割不會發生在不間斷空格上 |
| 11 |
upcase(string) 將給定字串中的所有字元轉換為大寫 |
二進位制
二進位制只是一系列位元組。二進位制使用<< >>定義。例如
<< 0, 1, 2, 3 >>
當然,這些位元組可以以任何方式組織,甚至可以以不使它們成為有效字串的序列組織。例如:
<< 239, 191, 191 >>
字串也是二進位制的。而字串連線運算子<>實際上是二進位制連線運算子
IO.puts(<< 0, 1 >> <> << 2, 3 >>)
以上程式碼產生以下結果:
<< 0, 1, 2, 3 >>
注意 ł 字元。由於這是 utf-8 編碼的,這個字元表示佔用 2 個位元組。
由於二進位制中表示的每個數字都應該是一個位元組,當這個值超過 255 時,它會被截斷。為了防止這種情況,我們使用大小修飾符來指定我們希望該數字佔用多少位。例如:
IO.puts(<< 256 >>) # truncated, it'll print << 0 >> IO.puts(<< 256 :: size(16) >>) #Takes 16 bits/2 bytes, will print << 1, 0 >>
以上程式將產生以下結果:
<< 0 >> << 1, 0 >>
如果字元是碼位,我們也可以使用 utf8 修飾符,它將在輸出中產生;否則是位元組:
IO.puts(<< 256 :: utf8 >>)
上述程式生成以下結果:
Ā
我們還有一個名為is_binary的函式,它檢查給定的變數是否為二進位制。請注意,只有儲存為 8 位倍數的變數才是二進位制的。
位串
如果我們使用大小修飾符定義二進位制並傳遞一個不是 8 的倍數的值,則最終會得到一個位串而不是二進位制。例如:
bs = << 1 :: size(1) >> IO.puts(bs) IO.puts(is_binary(bs)) IO.puts(is_bitstring(bs))
上述程式生成以下結果:
<< 1::size(1) >> false true
這意味著變數bs不是二進位制的,而是一個位串。我們也可以說二進位制是一個位數是 8 的倍數的位串。模式匹配同樣適用於二進位制和位串。
Elixir - 字元列表
字元列表只不過是字元列表。考慮以下程式以瞭解相同的內容。
IO.puts('Hello')
IO.puts(is_list('Hello'))
上述程式生成以下結果:
Hello true
字元列表包含字元的程式碼點,而不是位元組,這些字元位於單引號之間。因此,雙引號表示字串(即二進位制),單引號表示字元列表(即列表)。請注意,如果任何字元超出 ASCII 範圍,IEx 將僅生成程式碼點作為輸出。
字元列表主要用於與 Erlang 互動,特別是那些不接受二進位制作為引數的舊庫。您可以使用 to_string(char_list) 和 to_char_list(string) 函式將字元列表轉換為字串並轉換回來:
IO.puts(is_list(to_char_list("hełło")))
IO.puts(is_binary(to_string ('hełło')))
上述程式生成以下結果:
true true
注意 - 函式to_string和to_char_list是多型的,即它們可以接受多種型別的輸入,例如原子、整數,並將它們分別轉換為字串和字元列表。
Elixir - 列表和元組
(連結串列)列表
連結串列是在記憶體中不同位置儲存的元素的異構列表,並使用引用進行跟蹤。連結串列是在函數語言程式設計中特別使用的的資料結構。
Elixir 使用方括號指定值列表。值可以是任何型別:
[1, 2, true, 3]
當 Elixir 看到可列印的 ASCII 數字列表時,Elixir 將將其列印為字元列表(實際上是字元列表)。每當您在 IEx 中看到一個值並且不確定它是什麼時,您可以使用i函式來檢索有關它的資訊。
IO.puts([104, 101, 108, 108, 111])
列表中的上述字元都是可列印的。執行以上程式時,會產生以下結果:
hello
您也可以使用單引號反向定義列表:
IO.puts(is_list('Hello'))
執行上述程式時,將產生以下結果:
true
請記住,在 Elixir 中,單引號和雙引號表示法並不等效,因為它們由不同的型別表示。
列表的長度
要查詢列表的長度,我們使用 length 函式,如下面的程式所示:
IO.puts(length([1, 2, :true, "str"]))
上述程式生成以下結果:
4
連線和減法
可以使用++和--運算子連線和減去兩個列表。考慮以下示例以瞭解這些函式。
IO.puts([1, 2, 3] ++ [4, 5, 6]) IO.puts([1, true, 2, false, 3, true] -- [true, false])
這將分別在第一種情況下為您提供連線的字串,在第二種情況下提供減去的字串。以上程式產生以下結果:
[1, 2, 3, 4, 5, 6] [1, 2, 3, true]
列表的頭和尾
頭是列表的第一個元素,尾是列表的其餘部分。它們可以使用hd和tl函式檢索。讓我們將列表分配給變數並檢索其頭和尾。
list = [1, 2, 3] IO.puts(hd(list)) IO.puts(tl(list))
這將為我們提供列表的頭和尾作為輸出。以上程式產生以下結果:
1 [2, 3]
注意 - 獲取空列表的頭或尾是錯誤的。
其他列表函式
Elixir 標準庫提供了許多處理列表的函式。我們將在此處檢視其中一些。
| 序號 | 函式名稱和描述 |
|---|---|
| 1 |
delete(list, item) 從列表中刪除給定的項。返回一個不包含該項的列表。如果該項在列表中出現多次,則只刪除第一次出現的項。 |
| 2 |
delete_at(list, index) 透過刪除指定索引處的值來生成一個新列表。負索引表示從列表末尾的偏移量。如果索引超出範圍,則返回原始列表。 |
| 3 |
first(list) 返回列表中的第一個元素,如果列表為空則返回 nil。 |
| 4 |
flatten(list) 展平給定的巢狀列表。 |
| 5 |
insert_at(list, index, value) 返回一個在指定索引處插入 value 的列表。注意,索引值的上限為列表長度。負索引表示從列表末尾的偏移量。 |
| 6 |
last(list) 返回列表中的最後一個元素,如果列表為空則返回 nil。 |
元組
元組也是一種資料結構,可以在其中儲存多個其他結構。與列表不同,它們將元素儲存在連續的記憶體塊中。這意味著按索引訪問元組元素或獲取元組大小是一個快速操作。索引從零開始。
Elixir 使用花括號定義元組。與列表一樣,元組可以容納任何值:
{:ok, "hello"}
元組的長度
要獲取元組的長度,請使用 **tuple_size** 函式,如下面的程式所示:
IO.puts(tuple_size({:ok, "hello"}))
上述程式生成以下結果:
2
追加值
要向元組追加值,請使用 Tuple.append 函式:
tuple = {:ok, "Hello"}
Tuple.append(tuple, :world)
這將建立一個新的元組並返回它:{:ok, "Hello", :world}
插入值
要在給定位置插入值,我們可以使用 **Tuple.insert_at** 函式或 **put_elem** 函式。請考慮以下示例以瞭解相同內容:
tuple = {:bar, :baz}
new_tuple_1 = Tuple.insert_at(tuple, 0, :foo)
new_tuple_2 = put_elem(tuple, 1, :foobar)
請注意,**put_elem** 和 **insert_at** 返回了新的元組。儲存在 tuple 變數中的原始元組沒有被修改,因為 Elixir 資料型別是不可變的。由於不可變性,Elixir 程式碼更容易推理,因為您永遠不必擔心特定程式碼是否正在就地更改您的資料結構。
元組與列表
列表和元組有什麼區別?
列表在記憶體中以連結串列的形式儲存,這意味著列表中的每個元素都儲存其值並指向下一個元素,直到到達列表的末尾。我們將值和指標的每一對稱為 cons 單元。這意味著訪問列表的長度是一個線性操作:我們需要遍歷整個列表才能確定其大小。只要我們預先新增元素,更新列表就很快。
另一方面,元組在記憶體中連續儲存。這意味著透過索引獲取元組大小或訪問元素速度很快。但是,更新或向元組新增元素代價很高,因為它需要複製記憶體中的整個元組。
Elixir - 關鍵字列表
到目前為止,我們還沒有討論任何關聯資料結構,即可以將某個值(或多個值)與鍵關聯的資料結構。不同的語言使用不同的名稱來稱呼這些特性,例如字典、雜湊、關聯陣列等。
在 Elixir 中,我們有兩個主要的關聯資料結構:關鍵字列表和對映。在本章中,我們將重點介紹關鍵字列表。
在許多函數語言程式設計語言中,使用 2 個專案的元組列表作為關聯資料結構的表示是很常見的。在 Elixir 中,當我們有一個元組列表並且元組的第一個專案(即鍵)是一個原子時,我們稱之為關鍵字列表。請考慮以下示例以瞭解相同內容:
list = [{:a, 1}, {:b, 2}]
Elixir 支援定義此類列表的特殊語法。我們可以將冒號放在每個原子的末尾,並完全刪除元組。例如,
list_1 = [{:a, 1}, {:b, 2}]
list_2 = [a: 1, b: 2]
IO.puts(list_1 == list_2)
以上程式將產生以下結果:
true
這兩個都表示關鍵字列表。由於關鍵字列表也是列表,因此我們可以對它們使用我們對列表使用過的所有操作。
要檢索與關鍵字列表中原子關聯的值,請將原子作為 [] 傳遞到列表名稱之後:
list = [a: 1, b: 2] IO.puts(list[:a])
上述程式生成以下結果:
1
關鍵字列表具有三個特殊特性:
- 鍵必須是原子。
- 鍵是有序的,由開發者指定。
- 鍵可以多次給出。
為了操作關鍵字列表,Elixir 提供了 Keyword 模組。但是請記住,關鍵字列表只是列表,因此它們提供了與列表相同的線性效能特徵。列表越長,查詢鍵、計算專案數量等所需的時間就越長。因此,關鍵字列表主要在 Elixir 中用作選項。如果您需要儲存許多專案或保證一個鍵最多與一個值關聯,則應改用對映。
訪問鍵
要訪問與給定鍵關聯的值,我們使用 **Keyword.get** 函式。它返回與給定鍵關聯的第一個值。要獲取所有值,我們使用 Keyword.get_values 函式。例如:
kl = [a: 1, a: 2, b: 3] IO.puts(Keyword.get(kl, :a)) IO.puts(Keyword.get_values(kl))
以上程式將產生以下結果:
1 [1, 2]
插入鍵
要新增新值,請使用 **Keyword.put_new**。如果鍵已存在,則其值保持不變:
kl = [a: 1, a: 2, b: 3] kl_new = Keyword.put_new(kl, :c, 5) IO.puts(Keyword.get(kl_new, :c))
執行上述程式時,它將建立一個具有附加鍵 c 的新關鍵字列表,並生成以下結果:
5
刪除鍵
如果要刪除鍵的所有條目,請使用 **Keyword.delete**;要僅刪除鍵的第一個條目,請使用 **Keyword.delete_first**。
kl = [a: 1, a: 2, b: 3, c: 0] kl = Keyword.delete_first(kl, :b) kl = Keyword.delete(kl, :a) IO.puts(Keyword.get(kl, :a)) IO.puts(Keyword.get(kl, :b)) IO.puts(Keyword.get(kl, :c))
這將刪除列表中的第一個 **b** 和列表中的所有 **a**。執行上述程式時,它將生成以下結果:
0
Elixir - 對映
關鍵字列表是透過鍵處理儲存在列表中的內容的一種便捷方式,但在底層,Elixir 仍在遍歷列表。如果您對該列表還有其他計劃需要遍歷所有內容,這可能很合適,但如果您計劃僅使用鍵作為資料的方法,這可能會造成不必要的開銷。
這就是對映可以幫上忙的地方。每當您需要鍵值儲存時,對映都是 Elixir 中的“首選”資料結構。
建立對映
使用 %{} 語法建立對映:
map = %{:a => 1, 2 => :b}
與關鍵字列表相比,我們已經可以看到兩個區別:
- 對映允許任何值作為鍵。
- 對映的鍵不遵循任何順序。
訪問鍵
為了訪問與鍵關聯的值,對映使用與關鍵字列表相同的語法:
map = %{:a => 1, 2 => :b}
IO.puts(map[:a])
IO.puts(map[2])
執行上述程式時,它將生成以下結果:
1 b
插入鍵
要在對映中插入鍵,我們使用 **Dict.put_new** 函式,該函式將對映、新鍵和新值作為引數:
map = %{:a => 1, 2 => :b}
new_map = Dict.put_new(map, :new_val, "value")
IO.puts(new_map[:new_val])
這將在新對映中插入鍵值對 **:new_val - "value"**。執行上述程式時,它將生成以下結果:
"value"
更新值
要更新對映中已存在的值,可以使用以下語法:
map = %{:a => 1, 2 => :b}
new_map = %{ map | a: 25}
IO.puts(new_map[:a])
執行上述程式時,它將生成以下結果:
25
模式匹配
與關鍵字列表相比,對映在模式匹配中非常有用。當在模式中使用對映時,它將始終匹配給定值的子集:
%{:a => a} = %{:a => 1, 2 => :b}
IO.puts(a)
上述程式生成以下結果:
1
這將匹配 **a** 與 **1**。因此,它將生成輸出 **1**。
如上所示,只要模式中的鍵存在於給定對映中,對映就會匹配。因此,空對映匹配所有對映。
在訪問、匹配和新增對映鍵時可以使用變數:
n = 1
map = %{n => :one}
%{^n => :one} = %{1 => :one, 2 => :two, 3 => :three}
Map 模組 提供了與 Keyword 模組非常相似的 API,以及用於操作對映的便利函式。您可以使用 **Map.get、Map.delete** 等函式來操作對映。
具有原子鍵的對映
對映具有一些有趣的屬性。當對映中的所有鍵都是原子時,您可以使用關鍵字語法以方便起見:
map = %{:a => 1, 2 => :b}
IO.puts(map.a)
對映的另一個有趣的屬性是它們提供了自己的語法來更新和訪問原子鍵:
map = %{:a => 1, 2 => :b}
IO.puts(map.a)
上述程式生成以下結果:
1
請注意,要以這種方式訪問原子鍵,它必須存在,否則程式將無法工作。
Elixir - 模組
在 Elixir 中,我們將多個函式分組到模組中。我們已經在前面的章節中使用了不同的模組,例如 String 模組、Bitwise 模組、Tuple 模組等。
為了在 Elixir 中建立我們自己的模組,我們使用 **defmodule** 宏。我們使用 **def** 宏在該模組中定義函式:
defmodule Math do
def sum(a, b) do
a + b
end
end
在以下部分中,我們的示例大小將越來越大,在 shell 中鍵入所有這些示例可能會很棘手。我們需要學習如何編譯 Elixir 程式碼以及如何執行 Elixir 指令碼。
編譯
將模組寫入檔案以便編譯和重用總是很方便的。假設我們有一個名為 math.ex 的檔案,其內容如下:
defmodule Math do
def sum(a, b) do
a + b
end
end
我們可以使用命令編譯檔案:**elixirc**
$ elixirc math.ex
這將生成一個名為 **Elixir.Math.beam** 的檔案,其中包含已定義模組的位元組碼。如果我們再次啟動 **iex**,我們的模組定義將可用(前提是 iex 在位元組碼檔案所在的同一目錄中啟動)。例如,
IO.puts(Math.sum(1, 2))
以上程式將產生以下結果:
3
指令碼模式
除了 Elixir 副檔名 **.ex** 之外,Elixir 還支援 **.exs** 檔案進行指令碼編寫。Elixir 對這兩個檔案的處理方式完全相同,唯一的區別在於目標。**.ex** 檔案旨在進行編譯,而 .exs 檔案用於 **指令碼編寫**。執行時,這兩個副檔名都會編譯並將它們的模組載入到記憶體中,儘管只有 **.ex** 檔案將其位元組碼寫入磁碟,格式為 .beam 檔案。
例如,如果我們想在同一個檔案中執行 **Math.sum**,我們可以使用以下方式使用 .exs:
Math.exs
defmodule Math do
def sum(a, b) do
a + b
end
end
IO.puts(Math.sum(1, 2))
我們可以使用 Elixir 命令執行它:
$ elixir math.exs
以上程式將產生以下結果:
3
該檔案將在記憶體中編譯並執行,列印“3”作為結果。不會建立位元組碼檔案。
模組巢狀
模組可以在 Elixir 中巢狀。語言的此特性有助於我們更好地組織程式碼。要建立巢狀模組,我們使用以下語法:
defmodule Foo do
#Foo module code here
defmodule Bar do
#Bar module code here
end
end
上面給出的示例將定義兩個模組:**Foo** 和 **Foo.Bar**。只要它們在相同的詞法作用域中,第二個模組可以在 **Foo** 中作為 **Bar** 訪問。如果稍後將 **Bar** 模組移到 Foo 模組定義之外,則必須透過其全名 (Foo.Bar) 引用它,或者必須使用別名章節中討論的 alias 指令設定別名。
**注意**:在 Elixir 中,無需定義 Foo 模組即可定義 Foo.Bar 模組,因為該語言將所有模組名稱轉換為原子。您可以定義任意巢狀的模組,而無需定義鏈中的任何模組。例如,您可以定義 **Foo.Bar.Baz** 而無需定義 **Foo** 或 **Foo.Bar**。
Elixir - 別名
為了促進軟體重用,Elixir 提供了三個指令 – **alias、require** 和 **import**。它還提供了一個名為 use 的宏,總結如下:
# Alias the module so it can be called as Bar instead of Foo.Bar alias Foo.Bar, as: Bar # Ensure the module is compiled and available (usually for macros) require Foo # Import functions from Foo so they can be called without the `Foo.` prefix import Foo # Invokes the custom code defined in Foo as an extension point use Foo
現在讓我們詳細瞭解每個指令。
alias
alias 指令允許您為任何給定的模組名稱設定別名。例如,如果您想為 String 模組提供別名 **'Str'**,您可以簡單地編寫:
alias String, as: Str
IO.puts(Str.length("Hello"))
上述程式生成以下結果:
5
將String模組命名為Str別名。現在,當我們使用Str字面量呼叫任何函式時,它實際上都引用了String模組。當我們使用非常長的模組名並希望在當前作用域內用較短的名稱替換它們時,這非常有用。
注意 − 別名必須以大寫字母開頭。
別名僅在其呼叫的詞法作用域內有效。例如,如果在一個檔案中包含2個模組,並在其中一個模組內建立別名,則該別名在第二個模組中不可訪問。
如果將內建模組(如String或Tuple)的名稱作為其他模組的別名,則要訪問內建模組,需要在前面加上“Elixir.”。例如:
alias List, as: String
#Now when we use String we are actually using List.
#To use the string module:
IO.puts(Elixir.String.length("Hello"))
執行上述程式時,它將生成以下結果:
5
require
Elixir提供宏作為超程式設計(編寫生成程式碼的程式碼)的機制。
宏是在編譯時執行和擴充套件的程式碼塊。這意味著,為了使用宏,我們需要保證其模組和實現可在編譯期間使用。這是透過require指令完成的。
Integer.is_odd(3)
執行上述程式時,將生成以下結果:
** (CompileError) iex:1: you must require Integer before invoking the macro Integer.is_odd/1
在Elixir中,Integer.is_odd被定義為宏。此宏可用作保護條件。這意味著,為了呼叫Integer.is_odd,我們需要Integer模組。
使用require Integer函式並按如下所示執行程式。
require Integer Integer.is_odd(3)
這次程式將執行併產生輸出:true。
通常,除非我們要使用該模組中可用的宏,否則在使用之前不需要模組。嘗試呼叫未載入的宏將引發錯誤。請注意,與alias指令一樣,require也具有詞法作用域。我們將在後面的章節中詳細討論宏。
import
我們使用import指令輕鬆訪問其他模組中的函式或宏,而無需使用完全限定名。例如,如果我們想多次使用List模組中的duplicate函式,我們可以簡單地匯入它。
import List, only: [duplicate: 2]
在這種情況下,我們只從List中匯入函式duplicate(引數列表長度為2)。雖然:only是可選的,但建議使用它,以避免將給定模組的所有函式匯入名稱空間。也可以使用:except選項,以便匯入模組中的所有內容,除了函式列表。
import指令還支援將:macros和:functions提供給:only。例如,要匯入所有宏,使用者可以編寫:
import Integer, only: :macros
請注意,import也與require和alias指令一樣具有詞法作用域。還要注意,“匯入”模組也會“需要”它。
use
雖然不是指令,但use是一個與require緊密相關的宏,允許您在當前上下文中使用模組。use宏經常被開發人員用來將外部功能引入當前詞法作用域,通常是模組。讓我們透過一個例子來理解use指令:
defmodule Example do use Feature, option: :value end
Use是一個宏,它將上述內容轉換為:
defmodule Example do require Feature Feature.__using__(option: :value) end
use Module首先需要該模組,然後在Module上呼叫__using__宏。Elixir具有強大的超程式設計功能,它具有在編譯時生成程式碼的宏。在上述例項中呼叫了__using__宏,並將程式碼注入到我們的區域性上下文中。區域性上下文是在編譯時呼叫use宏的地方。
Elixir - 函式
函式是一組組織在一起以執行特定任務的語句。程式設計中的函式大多類似於數學中的函式。您向函式提供一些輸入,它們根據提供的輸入生成輸出。
Elixir中有兩種型別的函式:
匿名函式
使用fn..end結構定義的函式是匿名函式。這些函式有時也稱為lambda函式。它們透過將它們賦值給變數名來使用。
命名函式
使用def關鍵字定義的函式是命名函式。這些是Elixir中提供的原生函式。
匿名函式
顧名思義,匿名函式沒有名稱。這些函式經常傳遞給其他函式。要在Elixir中定義匿名函式,我們需要fn和end關鍵字。在這些關鍵字中,我們可以定義任意數量的引數和函式體,它們由->分隔。例如:
sum = fn (a, b) -> a + b end IO.puts(sum.(1, 5))
執行上述程式時,將生成以下結果:
6
請注意,這些函式的呼叫方式與命名函式不同。函式名及其引數之間有一個'.'。
使用捕獲運算子
我們也可以使用捕獲運算子定義這些函式。這是一種建立函式的更簡單的方法。我們現在將使用捕獲運算子定義上述sum函式:
sum = &(&1 + &2) IO.puts(sum.(1, 2))
執行上述程式時,它將生成以下結果:
3
在簡寫版本中,我們的引數沒有命名,但我們可以將其作為&1,&2,&3等等使用。
模式匹配函式
模式匹配不僅限於變數和資料結構。我們可以使用模式匹配使我們的函式多型。例如,我們將宣告一個函式,它可以接受1個或2個輸入(在一個元組中),並將它們列印到控制檯:
handle_result = fn
{var1} -> IO.puts("#{var1} found in a tuple!")
{var_2, var_3} -> IO.puts("#{var_2} and #{var_3} found!")
end
handle_result.({"Hey people"})
handle_result.({"Hello", "World"})
執行上述程式時,將產生以下結果:
Hey people found in a tuple! Hello and World found!
命名函式
我們可以定義帶有名稱的函式,以便以後可以輕鬆引用它們。命名函式使用def關鍵字在模組中定義。命名函式始終在模組中定義。要呼叫命名函式,我們需要使用它們的模組名來引用它們。
以下是命名函式的語法:
def function_name(argument_1, argument_2) do #code to be executed when function is called end
現在讓我們在Math模組中定義我們的命名函式sum。
defmodule Math do
def sum(a, b) do
a + b
end
end
IO.puts(Math.sum(5, 6))
執行以上程式時,會產生以下結果:
11
對於單行函式,可以使用do:定義這些函式的簡寫符號。例如:
defmodule Math do def sum(a, b), do: a + b end IO.puts(Math.sum(5, 6))
執行以上程式時,會產生以下結果:
11
私有函式
Elixir使我們能夠定義私有函式,這些函式可以在定義它們的模組內訪問。要定義私有函式,請使用defp而不是def。例如:
defmodule Greeter do
def hello(name), do: phrase <> name
defp phrase, do: "Hello "
end
Greeter.hello("world")
執行上述程式時,將產生以下結果:
Hello world
但是,如果我們只是嘗試使用Greeter.phrase()函式顯式呼叫phrase函式,它將引發錯誤。
預設引數
如果我們想要引數的預設值,我們使用引數 \\ 值語法:
defmodule Greeter do
def hello(name, country \\ "en") do
phrase(country) <> name
end
defp phrase("en"), do: "Hello, "
defp phrase("es"), do: "Hola, "
end
Greeter.hello("Ayush", "en")
Greeter.hello("Ayush")
Greeter.hello("Ayush", "es")
執行上述程式時,將產生以下結果:
Hello, Ayush Hello, Ayush Hola, Ayush
Elixir - 遞迴
遞迴是一種方法,其中問題的解決方案取決於對同一問題的較小例項的解決方案。大多數計算機程式語言都支援遞迴,允許函式在程式文字中呼叫自身。
理想情況下,遞迴函式具有結束條件。這個結束條件,也稱為基本情況,會停止重新進入函式並將函式呼叫新增到堆疊中。這就是遞迴函式呼叫停止的地方。讓我們考慮以下示例來進一步理解遞迴函式。
defmodule Math do
def fact(res, num) do
if num === 1 do
res
else
new_res = res * num
fact(new_res, num-1)
end
end
end
IO.puts(Math.fact(1,5))
執行上述程式時,它將生成以下結果:
120
因此,在上面的函式Math.fact中,我們正在計算數字的階乘。請注意,我們正在函式自身內部呼叫該函式。現在讓我們瞭解一下它是如何工作的。
我們向它提供了1和我們要計算階乘的數字。該函式檢查數字是否為1,如果不是1則返回res(結束條件)。如果不是,則它建立一個變數new_res,併為其賦值previous res * current num的值。它返回我們的函式呼叫fact(new_res, num-1)返回的值。這將重複進行,直到我們得到num為1。一旦發生這種情況,我們就會得到結果。
讓我們考慮另一個示例,逐個列印列表中的每個元素。為此,我們將利用列表的hd和tl函式以及函式中的模式匹配:
a = ["Hey", 100, 452, :true, "People"]
defmodule ListPrint do
def print([]) do
end
def print([head | tail]) do
IO.puts(head)
print(tail)
end
end
ListPrint.print(a)
當我們有一個空列表時,將呼叫第一個print函式(結束條件)。如果不是,則將呼叫第二個print函式,它將列表分成兩部分,並將列表的第一個元素賦值給head,並將列表的其餘部分賦值給tail。然後列印head,我們再次使用列表的其餘部分(即tail)呼叫print函式。執行上述程式時,將產生以下結果:
Hey 100 452 true People
Elixir - 迴圈
由於不變性,Elixir中的迴圈(與任何函數語言程式設計語言一樣)與命令式語言中的寫法不同。例如,在像C這樣的命令式語言中,你會這樣寫:
for(i = 0; i < 10; i++) {
printf("%d", array[i]);
}
在上例中,我們正在修改陣列和變數i。在Elixir中不可能進行修改。相反,函式式語言依賴於遞迴:遞迴呼叫函式,直到達到停止遞迴操作繼續的條件。在此過程中不會修改任何資料。
現在讓我們使用遞迴編寫一個簡單的迴圈,列印n次hello。
defmodule Loop do
def print_multiple_times(msg, n) when n <= 1 do
IO.puts msg
end
def print_multiple_times(msg, n) do
IO.puts msg
print_multiple_times(msg, n - 1)
end
end
Loop.print_multiple_times("Hello", 10)
執行上述程式時,將產生以下結果:
Hello Hello Hello Hello Hello Hello Hello Hello Hello Hello
我們利用了函式的模式匹配技術和遞迴成功地實現了一個迴圈。遞迴定義很難理解,但是將迴圈轉換為遞迴很容易。
Elixir為我們提供了Enum模組。此模組用於大多數迭代迴圈呼叫,因為它比嘗試為相同內容找出遞迴定義要容易得多。我們將在下一章討論這些內容。只有當您找不到使用該模組的解決方案時,才應使用您自己的遞迴定義。這些函式經過尾呼叫最佳化,速度相當快。
Elixir - 可列舉
列舉是可列舉的物件。“列舉”意味著逐個(通常按順序,通常按名稱)計算集合/集合/類別的成員。
Elixir提供了列舉的概念和Enum模組來處理它們。Enum模組中的函式僅限於(顧名思義)列舉資料結構中的值。列舉資料結構的示例是列表、元組、對映等。Enum模組為我們提供了超過100個處理列舉的函式。我們將在本章討論一些重要的函式。
所有這些函式都將列舉作為第一個元素,並將函式作為第二個元素,並在其上工作。這些函式描述如下。
all?
當我們使用all?函式時,整個集合必須計算為true,否則將返回false。例如,要檢查列表中的所有元素是否都是奇數,則:
res = Enum.all?([1, 2, 3, 4], fn(s) -> rem(s,2) == 1 end) IO.puts(res)
執行上述程式時,將產生以下結果:
false
這是因為此列表並非所有元素都是奇數。
any?
顧名思義,如果集合的任何元素計算為true,此函式將返回true。例如:
res = Enum.any?([1, 2, 3, 4], fn(s) -> rem(s,2) == 1 end) IO.puts(res)
執行上述程式時,將產生以下結果:
true
chunk
此函式將我們的集合分成大小為第二個引數的小塊。例如:
res = Enum.chunk([1, 2, 3, 4, 5, 6], 2) IO.puts(res)
執行上述程式時,將產生以下結果:
[[1, 2], [3, 4], [5, 6]]
each
可能需要迭代集合而不產生新值,在這種情況下,我們使用each函式:
Enum.each(["Hello", "Every", "one"], fn(s) -> IO.puts(s) end)
執行上述程式時,將產生以下結果:
Hello Every one
map
要將我們的函式應用於每個專案併產生新的集合,我們使用map函式。它是函數語言程式設計中最有用的構造之一,因為它非常簡潔和簡短。讓我們考慮一個例子來理解這一點。我們將把列表中儲存的值加倍,並將其儲存在新列表res中:
res = Enum.map([2, 5, 3, 6], fn(a) -> a*2 end) IO.puts(res)
執行上述程式時,將產生以下結果:
[4, 10, 6, 12]
reduce
reduce函式幫助我們將列舉減少到單個值。為此,我們提供一個可選的累加器(在此示例中為5)傳遞到我們的函式中;如果沒有提供累加器,則使用第一個值:
res = Enum.reduce([1, 2, 3, 4], 5, fn(x, accum) -> x + accum end) IO.puts(res)
執行上述程式時,將產生以下結果:
15
累加器是傳遞給fn的初始值。從第二次呼叫開始,前一次呼叫的返回值將作為累加器傳遞。我們也可以在沒有累加器的情況下使用reduce:
res = Enum.reduce([1, 2, 3, 4], fn(x, accum) -> x + accum end) IO.puts(res)
執行上述程式時,將產生以下結果:
10
uniq
uniq 函式會移除集合中的重複元素,只返回集合中唯一元素的集合。例如:
res = Enum.uniq([1, 2, 2, 3, 3, 3, 4, 4, 4, 4]) IO.puts(res)
執行上述程式,會產生以下結果:
[1, 2, 3, 4]
及早求值
Enum 模組中的所有函式都是及早求值的。許多函式都接收一個可列舉物件並返回一個列表。這意味著當使用 Enum 執行多個操作時,每個操作都會生成一箇中間列表,直到得到最終結果。讓我們來看下面的例子來理解這一點:
odd? = &(odd? = &(rem(&1, 2) != 0) res = 1..100_000 |> Enum.map(&(&1 * 3)) |> Enum.filter(odd?) |> Enum.sum IO.puts(res)
執行上述程式時,將產生以下結果:
7500000000
上面的例子有一系列的操作。我們從一個範圍開始,然後將範圍中的每個元素乘以 3。這個第一個操作現在將建立一個包含 100,000 個元素的列表並返回。然後我們保留列表中所有奇數元素,生成一個新的列表,現在包含 50,000 個元素,然後我們對所有元素求和。
上面程式碼片段中使用的 |> 符號是 管道運算子:它簡單地將左側表示式的輸出作為第一個引數傳遞給右側的函式呼叫。它類似於 Unix 的 | 運算子。它的目的是突出顯示一系列函式轉換資料流。
如果沒有 管道運算子,程式碼看起來會很複雜:
Enum.sum(Enum.filter(Enum.map(1..100_000, &(&1 * 3)), odd?))
我們還有許多其他函式,但是這裡只描述了其中一些重要的函式。
Elixir - 流
許多函式都接收一個可列舉物件並返回一個 列表。這意味著,在使用 Enum 執行多個操作時,每個操作都會生成一箇中間列表,直到得到最終結果。
與 Enum 的及早求值操作相反,Stream 支援惰性操作。簡而言之,Stream 是惰性的、可組合的可列舉物件。這意味著 Stream 只有在絕對需要時才會執行操作。讓我們來看一個例子來理解這一點:
odd? = &(rem(&1, 2) != 0) res = 1..100_000 |> Stream.map(&(&1 * 3)) |> Stream.filter(odd?) |> Enum.sum IO.puts(res)
執行上述程式時,將產生以下結果:
7500000000
在上面的例子中,1..100_000 |> Stream.map(&(&1 * 3)) 返回一個數據型別,一個實際的流,它表示對範圍 1..100_000 的對映計算。它還沒有計算這個表示。Stream 不會生成中間列表,而是構建一系列計算,只有當我們將底層 Stream 傳遞給 Enum 模組時才會呼叫這些計算。在處理大型的、可能是無限的集合時,Stream 非常有用。
Stream 和 Enum 具有許多共同的函式。Stream 主要提供與 Enum 模組提供的函式相同的函式,這些函式在對輸入可列舉物件執行計算後將列表作為返回值。其中一些列在下面的表中:
| 序號 | 函式及其描述 |
|---|---|
| 1 |
chunk(enum, n, step, leftover \\ nil) 將可列舉物件分成塊,每個塊包含 n 個元素,每個新塊從可列舉物件的 step 個元素開始。 |
| 2 |
concat(enumerables) 建立一個流,列舉可列舉物件中的每個可列舉物件。 |
| 3 |
each(enum, fun) 為每個元素執行給定的函式。 |
| 4 |
filter(enum, fun) 建立一個流,根據列舉時給定的函式過濾元素。 |
| 5 |
map(enum, fun) 建立一個流,將在列舉時應用給定的函式。 |
| 6 |
drop(enum, n) 惰性地丟棄可列舉物件的接下來的 n 個元素。 |
Elixir - 結構體
結構體是在 map 之上構建的擴充套件,提供編譯時檢查和預設值。
定義結構體
要定義一個結構體,使用 defstruct 結構:
defmodule User do defstruct name: "John", age: 27 end
與 defstruct 一起使用的關鍵字列表定義了結構體將具有的欄位及其預設值。結構體採用定義它們的模組的名稱。在上面的例子中,我們定義了一個名為 User 的結構體。我們現在可以使用類似於建立 map 的語法來建立 User 結構體:
new_john = %User{})
ayush = %User{name: "Ayush", age: 20}
megan = %User{name: "Megan"})
以上程式碼將生成三個具有不同值的結構體:
%User{age: 27, name: "John"}
%User{age: 20, name: "Ayush"}
%User{age: 27, name: "Megan"}
結構體提供編譯時保證,只有透過 defstruct 定義的欄位(以及所有欄位)才能存在於結構體中。因此,一旦在模組中建立了結構體,就不能定義自己的欄位。
訪問和更新結構體
當我們討論 map 時,我們展示瞭如何訪問和更新 map 的欄位。同樣的技術(和相同的語法)也適用於結構體。例如,如果我們想更新我們在前面示例中建立的使用者,那麼:
defmodule User do
defstruct name: "John", age: 27
end
john = %User{}
#john right now is: %User{age: 27, name: "John"}
#To access name and age of John,
IO.puts(john.name)
IO.puts(john.age)
執行上述程式時,將產生以下結果:
John 27
要更新結構體中的值,我們將再次使用我們在 map 章節中使用的相同過程:
meg = %{john | name: "Meg"}
結構體也可以用於模式匹配,既可以匹配特定鍵的值,也可以確保匹配的值與匹配值具有相同的型別。
Elixir - 協議
協議是在 Elixir 中實現多型性的機制。只要資料型別實現了協議,就可以對該協議進行分派。
讓我們考慮一個使用協議的例子。我們在前面的章節中使用了名為 to_string 的函式將其他型別轉換為字串型別。這實際上是一個協議。它根據給定的輸入進行操作,而不會產生錯誤。這看起來像是我們正在討論模式匹配函式,但隨著我們的進一步討論,事實證明情況並非如此。
考慮下面的例子來進一步理解協議機制。
讓我們建立一個協議來顯示給定的輸入是否為空。我們將這個協議稱為 blank?。
定義協議
我們可以在 Elixir 中以以下方式定義協議:
defprotocol Blank do def blank?(data) end
正如你所看到的,我們不需要為函式定義一個函式體。如果你熟悉其他程式語言中的介面,你可以認為協議基本上是相同的東西。
所以這個協議說的是,任何實現它的東西都必須有一個 empty? 函式,儘管實現者如何響應該函式取決於實現者。在定義了協議之後,讓我們瞭解如何新增幾個實現。
實現協議
由於我們已經定義了一個協議,我們現在需要告訴它如何處理它可能接收的不同輸入。讓我們基於我們之前使用的例子。我們將為列表、map 和字串實現 blank 協議。這將顯示我們傳遞的內容是否為空。
#Defining the protocol
defprotocol Blank do
def blank?(data)
end
#Implementing the protocol for lists
defimpl Blank, for: List do
def blank?([]), do: true
def blank?(_), do: false
end
#Implementing the protocol for strings
defimpl Blank, for: BitString do
def blank?(""), do: true
def blank?(_), do: false
end
#Implementing the protocol for maps
defimpl Blank, for: Map do
def blank?(map), do: map_size(map) == 0
end
IO.puts(Blank.blank? [])
IO.puts(Blank.blank? [:true, "Hello"])
IO.puts(Blank.blank? "")
IO.puts(Blank.blank? "Hi")
你可以為任意數量的型別實現你的協議,只要對你的協議的使用有意義即可。這是一個關於協議相當基本的用例。執行上述程式時,會產生以下結果:
true false true false
注意 - 如果你將其用於除你為其定義協議的型別以外的任何型別,它將產生錯誤。
Elixir - 檔案 I/O
檔案 I/O 是任何程式語言不可或缺的一部分,因為它允許語言與檔案系統上的檔案互動。在本節中,我們將討論兩個模組:Path 和 File。
Path 模組
path 模組是一個非常小的模組,可以被認為是檔案系統操作的輔助模組。File 模組中的大多數函式都期望路徑作為引數。最常見的是,這些路徑將是常規二進位制資料。Path 模組提供處理此類路徑的功能。建議使用 Path 模組中的函式,而不是僅僅操作二進位制資料,因為 Path 模組透明地處理不同的作業系統。需要注意的是,Elixir 在執行檔案操作時會自動將斜槓 (/) 轉換為反斜槓 (\)(在 Windows 上)。
讓我們考慮下面的例子來進一步理解 Path 模組:
IO.puts(Path.join("foo", "bar"))
執行上述程式時,將產生以下結果:
foo/bar
path 模組提供了很多方法。你可以檢視不同的方法 這裡。如果你正在執行許多檔案操作,這些方法經常被使用。
File 模組
file 模組包含允許我們將檔案開啟為 I/O 裝置的函式。預設情況下,檔案以二進位制模式開啟,這要求開發人員使用 IO 模組中的特定 IO.binread 和 IO.binwrite 函式。讓我們建立一個名為 newfile 的檔案並向其中寫入一些資料。
{:ok, file} = File.read("newfile", [:write])
# Pattern matching to store returned stream
IO.binwrite(file, "This will be written to the file")
如果你去開啟我們剛才寫入的檔案,內容將以以下方式顯示:
This will be written to the file
現在讓我們瞭解如何使用 file 模組。
開啟檔案
要開啟檔案,我們可以使用以下兩個函式中的任何一個:
{:ok, file} = File.open("newfile")
file = File.open!("newfile")
現在讓我們瞭解 File.open 函式和 File.open!() 函式之間的區別。
File.open 函式總是返回一個元組。如果檔案成功開啟,它將元組中的第一個值返回為 :ok,第二個值是 io_device 型別的字面量。如果發生錯誤,它將返回一個元組,第一個值為 :error,第二個值為原因。
另一方面,File.open!() 函式如果檔案成功開啟將返回一個 io_device,否則將引發錯誤。注意:這是我們將要討論的所有 file 模組函式中遵循的模式。
我們還可以指定要開啟此檔案的模式。要以只讀模式和 utf-8 編碼模式開啟檔案,我們使用以下程式碼:
file = File.open!("newfile", [:read, :utf8])
寫入檔案
我們有兩種方法可以寫入檔案。讓我們看看第一種方法,使用 File 模組的 write 函式。
File.write("newfile", "Hello")
但是,如果要對同一個檔案進行多次寫入,則不應使用此方法。每次呼叫此函式時,都會開啟一個檔案描述符併產生一個新程序來寫入檔案。如果在迴圈中進行多次寫入,請透過 File.open 開啟檔案,並使用 IO 模組中的方法寫入檔案。讓我們考慮一個例子來理解這一點:
#Open the file in read, write and utf8 modes.
file = File.open!("newfile_2", [:read, :utf8, :write])
#Write to this "io_device" using standard IO functions
IO.puts(file, "Random text")
你可以使用其他 IO 模組方法,如 IO.write 和 IO.binwrite,寫入以 io_device 開啟的檔案。
從檔案讀取
我們有兩種方法可以從檔案讀取。讓我們看看第一種方法,使用 File 模組的 read 函式。
IO.puts(File.read("newfile"))
執行此程式碼時,你應該得到一個元組,其第一個元素為 :ok,第二個元素為 newfile 的內容。
我們還可以使用 File.read! 函式來獲取返回給我們的檔案內容。
關閉開啟的檔案
每當你使用 File.open 函式開啟檔案後,在完成使用後,都應使用 File.close 函式關閉它:
File.close(file)
Elixir - 程序
在Elixir中,所有程式碼都在程序內執行。程序彼此隔離,併發執行,並透過訊息傳遞進行通訊。Elixir的程序不應與作業系統程序混淆。Elixir中的程序在記憶體和CPU方面都非常輕量級(不像許多其他程式語言中的執行緒)。因此,同時執行成千上萬甚至數十萬個程序並不少見。
在本章中,我們將學習生成新程序以及在不同程序之間傳送和接收訊息的基本結構。
spawn函式
建立新程序最簡單的方法是使用spawn函式。spawn接受一個將在新程序中執行的函式。例如:
pid = spawn(fn -> 2 * 2 end) Process.alive?(pid)
執行上述程式時,將產生以下結果:
false
spawn函式的返回值是PID。這是程序的唯一識別符號,因此如果您執行上面的程式碼,您的PID將不同。正如您在這個例子中看到的,當我們檢查程序是否存活時,程序已經死亡。這是因為程序一旦完成給定函式的執行就會退出。
如前所述,所有Elixir程式碼都在程序內執行。如果您執行self函式,您將看到當前會話的PID:
pid = self Process.alive?(pid)
執行上述程式時,會產生以下結果:
true
訊息傳遞
我們可以使用send向程序傳送訊息,並使用receive接收訊息。讓我們向當前程序傳遞一條訊息並在同一程序中接收它。
send(self(), {:hello, "Hi people"})
receive do
{:hello, msg} -> IO.puts(msg)
{:another_case, msg} -> IO.puts("This one won't match!")
end
執行上述程式時,將產生以下結果:
Hi people
我們使用send函式向當前程序傳送了一條訊息,並將其傳遞給了self的PID。然後我們使用receive函式處理傳入的訊息。
當向程序傳送訊息時,訊息將儲存在程序郵箱中。receive塊遍歷當前程序郵箱,搜尋與任何給定模式匹配的訊息。receive塊支援守衛和許多子句,例如case。
如果郵箱中沒有與任何模式匹配的訊息,則當前程序將等待直到有匹配的訊息到達。也可以指定超時時間。例如:
receive do
{:hello, msg} -> msg
after
1_000 -> "nothing after 1s"
end
執行上述程式時,將產生以下結果:
nothing after 1s
注意 - 當您已經預期郵箱中存在訊息時,可以指定0超時。
連結
Elixir中最常見的spawn方式實際上是透過spawn_link函式。在檢視spawn_link的示例之前,讓我們瞭解一下程序失敗時會發生什麼。
spawn fn -> raise "oops" end
執行上述程式時,會產生以下錯誤:
[error] Process #PID<0.58.00> raised an exception ** (RuntimeError) oops :erlang.apply/2
它記錄了一個錯誤,但生成程序仍在執行。這是因為程序是隔離的。如果我們希望一個程序中的失敗傳播到另一個程序,我們需要將它們連結起來。這可以透過spawn_link函式完成。讓我們考慮一個例子來理解這一點:
spawn_link fn -> raise "oops" end
執行上述程式時,會產生以下錯誤:
** (EXIT from #PID<0.41.0>) an exception was raised:
** (RuntimeError) oops
:erlang.apply/2
如果您在iex shell中執行此程式碼,則shell會處理此錯誤而不會退出。但是,如果您首先建立一個指令碼檔案,然後使用elixir <file-name>.exs執行,則父程序也會因這個失敗而被終止。
程序和連結在構建容錯系統中起著重要作用。在Elixir應用程式中,我們經常將程序連結到監督器,監督器將檢測程序何時死亡並在其位置啟動一個新程序。這隻有在程序被隔離並且預設情況下不共享任何內容時才有可能。由於程序是隔離的,因此一個程序中的故障不可能崩潰或破壞另一個程序的狀態。雖然其他語言需要我們捕獲/處理異常;在Elixir中,我們實際上可以放任程序失敗,因為我們期望監督器能夠正確地重新啟動我們的系統。
狀態
如果您正在構建一個需要狀態的應用程式,例如,為了保留您的應用程式配置,或者您需要解析一個檔案並將其儲存在記憶體中,您將把它儲存在哪裡?Elixir的程序功能在執行此類操作時非常有用。
我們可以編寫無限迴圈、維護狀態以及傳送和接收訊息的程序。例如,讓我們編寫一個模組,該模組啟動充當鍵值儲存的新程序,儲存在一個名為kv.exs的檔案中。
defmodule KV do
def start_link do
Task.start_link(fn -> loop(%{}) end)
end
defp loop(map) do
receive do
{:get, key, caller} ->
send caller, Map.get(map, key)
loop(map)
{:put, key, value} ->
loop(Map.put(map, key, value))
end
end
end
請注意,start_link函式啟動一個執行loop函式的新程序,從空對映開始。然後,loop函式等待訊息並對每條訊息執行相應的操作。對於:get訊息,它將訊息傳送回撥用方並再次呼叫loop,以等待新訊息。而:put訊息實際上使用新的對映版本呼叫loop,其中儲存了給定的鍵和值。
現在讓我們執行以下程式碼:
iex kv.exs
現在您應該在iex shell中。要測試我們的模組,請嘗試以下操作:
{:ok, pid} = KV.start_link
# pid now has the pid of our new process that is being
# used to get and store key value pairs
# Send a KV pair :hello, "Hello" to the process
send pid, {:put, :hello, "Hello"}
# Ask for the key :hello
send pid, {:get, :hello, self()}
# Print all the received messages on the current process.
flush()
執行上述程式時,將產生以下結果:
"Hello"
Elixir - 符號
在本章中,我們將探索sigil,這是語言提供的用於處理文字表示的機制。Sigil以波浪號 (~) 字元開頭,後跟一個字母(標識sigil),然後是一個分隔符;可選地,可以在最終分隔符之後新增修飾符。
正則表示式
Elixir中的正則表示式是sigil。我們在String章節中已經看到它們的用法。讓我們再舉一個例子來看看如何在Elixir中使用正則表示式。
# A regular expression that matches strings which contain "foo" or
# "bar":
regex = ~r/foo|bar/
IO.puts("foo" =~ regex)
IO.puts("baz" =~ regex)
執行上述程式時,將產生以下結果:
true false
Sigil支援8個不同的分隔符:
~r/hello/
~r|hello|
~r"hello"
~r'hello'
~r(hello)
~r[hello]
~r{hello}
~r<hello>
支援不同分隔符的原因是,不同的分隔符可能更適合不同的sigil。例如,對正則表示式使用括號可能是一個令人困惑的選擇,因為它們可能會與正則表示式中的括號混淆。但是,括號對於其他sigil可能非常有用,正如我們將在下一節中看到的。
Elixir支援與Perl相容的正則表示式,也支援修飾符。您可以在這裡瞭解更多關於正則表示式用法的知識here。
字串、字元列表和單詞列表
除了正則表示式外,Elixir還有3個內建sigil。讓我們來看看這些sigil。
字串
~s sigil用於生成字串,就像雙引號一樣。例如,當字元串同時包含雙引號和單引號時,~s sigil非常有用:
new_string = ~s(this is a string with "double" quotes, not 'single' ones) IO.puts(new_string)
此sigil生成字串。執行上述程式時,會產生以下結果:
"this is a string with \"double\" quotes, not 'single' ones"
字元列表
~c sigil用於生成字元列表:
new_char_list = ~c(this is a char list containing 'single quotes') IO.puts(new_char_list)
執行上述程式時,將產生以下結果:
this is a char list containing 'single quotes'
單詞列表
~w sigil用於生成單詞列表(單詞只是普通的字串)。在~w sigil中,單詞由空格分隔。
new_word_list = ~w(foo bar bat) IO.puts(new_word_list)
執行上述程式時,將產生以下結果:
foobarbat
~w sigil還接受c、s和a修飾符(分別用於字元列表、字串和原子),這些修飾符指定結果列表元素的資料型別:
new_atom_list = ~w(foo bar bat)a IO.puts(new_atom_list)
執行上述程式時,將產生以下結果:
[:foo, :bar, :bat]
Sigil中的插值和轉義
除了小寫sigil外,Elixir還支援大寫sigil來處理跳脫字元和插值。雖然~s和~S都會返回字串,但前者允許轉義碼和插值,而後者則不允許。讓我們考慮一個例子來理解這一點:
~s(String with escape codes \x26 #{"inter" <> "polation"})
# "String with escape codes & interpolation"
~S(String without escape codes \x26 without #{interpolation})
# "String without escape codes \\x26 without \#{interpolation}"
自定義Sigil
我們可以輕鬆建立自己的自定義sigil。在這個例子中,我們將建立一個sigil來將字串轉換為大寫。
defmodule CustomSigil do def sigil_u(string, []), do: String.upcase(string) end import CustomSigil IO.puts(~u/tutorials point/)
執行上述程式碼時,會產生以下結果:
TUTORIALS POINT
首先,我們定義一個名為CustomSigil的模組,在這個模組中,我們建立了一個名為sigil_u的函式。由於現有sigil空間中不存在~u sigil,我們將使用它。_u表示我們希望使用u作為波浪號後的字元。函式定義必須接受兩個引數:一個輸入和一個列表。
Elixir - 列表推導式
列表推導式是Elixir中迴圈遍歷可列舉物件的語法糖。在本章中,我們將使用推導式進行迭代和生成。
基礎知識
當我們在可列舉章節中檢視Enum模組時,我們遇到了map函式。
Enum.map(1..3, &(&1 * 2))
在這個例子中,我們將傳遞一個函式作為第二個引數。範圍中的每個專案都將傳遞到函式中,然後將返回一個包含新值的新列表。
對映、過濾和轉換在Elixir中非常常見,因此與之前的示例相比,實現相同結果的方法略有不同:
for n <- 1..3, do: n * 2
執行上述程式碼時,會產生以下結果:
[2, 4, 6]
第二個例子是一個推導式,正如您可能看到的,它只是您可以使用Enum.map函式實現的語法糖。但是,就效能而言,使用推導式與Enum模組中的函式相比,並沒有真正的優勢。
推導式不限於列表,可以與所有可列舉物件一起使用。
過濾
您可以將過濾器視為推導式的一種守衛。當過濾後的值返回false或nil時,它將從最終列表中排除。讓我們遍歷一個範圍,只關注偶數。我們將使用Integer模組中的is_even函式來檢查一個值是偶數還是奇數。
import Integer IO.puts(for x <- 1..10, is_even(x), do: x)
執行上述程式碼時,會產生以下結果:
[2, 4, 6, 8, 10]
我們也可以在同一個推導式中使用多個過濾器。在is_even過濾器之後新增另一個您想要的過濾器,用逗號隔開。
:into選項
在上面的例子中,所有推導式都將其結果作為列表返回。但是,可以透過將:into選項傳遞給推導式,將推導式的結果插入到不同的資料結構中。
例如,可以使用:into選項與bitstring生成器一起使用,以便輕鬆地刪除字串中的所有空格:
IO.puts(for <<c <- " hello world ">>, c != ?\s, into: "", do: <<c>>)
執行上述程式碼時,會產生以下結果:
helloworld
上述程式碼使用c != ?\s過濾器刪除字串中的所有空格,然後使用:into選項,它將所有返回的字元放入一個字串中。
Elixir - 型別宣告
Elixir是一種動態型別語言,因此Elixir中的所有型別都是由執行時推斷的。儘管如此,Elixir仍然帶有typespec,這是一種用於宣告自定義資料型別和宣告型別化函式簽名(規範)的符號。
函式規範(specs)
預設情況下,Elixir 提供了一些基本型別,例如整數或 pid,以及複雜型別:例如,**round** 函式,它將浮點數四捨五入到最接近的整數,它接受一個數字作為引數(整數或浮點數)並返回一個整數。在相關的文件中,round 的型別簽名寫為:
round(number) :: integer
上述描述意味著左側的函式以括號中指定的引數作為輸入,並返回 :: 右側的內容,即 Integer。函式規範使用**@spec** 指令編寫,放置在函式定義的正前方。round 函式可以寫成:
@spec round(number) :: integer def round(number), do: # Function implementation ...
型別規範也支援複雜型別,例如,如果要返回一個整數列表,則可以使用**[Integer]**
自定義型別
雖然 Elixir 提供了許多有用的內建型別,但在適當情況下定義自定義型別也很方便。這可以在定義模組時透過 @type 指令完成。讓我們考慮一個例子來理解這一點:
defmodule FunnyCalculator do
@type number_with_joke :: {number, String.t}
@spec add(number, number) :: number_with_joke
def add(x, y), do: {x + y, "You need a calculator to do that?"}
@spec multiply(number, number) :: number_with_joke
def multiply(x, y), do: {x * y, "It is like addition on steroids."}
end
{result, comment} = FunnyCalculator.add(10, 20)
IO.puts(result)
IO.puts(comment)
執行上述程式時,將產生以下結果:
30 You need a calculator to do that?
**注意** — 透過 @type 定義的自定義型別會被匯出,並在定義它們的模組之外可用。如果要將自定義型別保持為私有,可以使用**@typep** 指令代替**@type**。
Elixir - 行為
Elixir(和 Erlang)中的行為是一種將元件的通用部分(成為行為模組)與特定部分(成為回撥模組)分離和抽象的方法。行為提供了一種方法:
- 定義一組必須由模組實現的函式。
- 確保模組實現該集合中的所有函式。
如果需要,可以將行為視為 Java 等面嚮物件語言中的介面:模組必須實現的一組函式簽名。
定義行為
讓我們考慮一個例子來建立我們自己的行為,然後使用這個通用行為來建立一個模組。我們將定義一個行為,它可以用不同的語言向人們問好和道別。
defmodule GreetBehaviour do @callback say_hello(name :: string) :: nil @callback say_bye(name :: string) :: nil end
**@callback** 指令用於列出採用模組需要定義的函式。它還指定引數的數量、型別和返回值。
採用行為
我們已經成功定義了一個行為。現在,我們將把它應用並實現到多個模組中。讓我們建立兩個模組,分別用英語和西班牙語實現此行為。
defmodule GreetBehaviour do
@callback say_hello(name :: string) :: nil
@callback say_bye(name :: string) :: nil
end
defmodule EnglishGreet do
@behaviour GreetBehaviour
def say_hello(name), do: IO.puts("Hello " <> name)
def say_bye(name), do: IO.puts("Goodbye, " <> name)
end
defmodule SpanishGreet do
@behaviour GreetBehaviour
def say_hello(name), do: IO.puts("Hola " <> name)
def say_bye(name), do: IO.puts("Adios " <> name)
end
EnglishGreet.say_hello("Ayush")
EnglishGreet.say_bye("Ayush")
SpanishGreet.say_hello("Ayush")
SpanishGreet.say_bye("Ayush")
執行上述程式時,將產生以下結果:
Hello Ayush Goodbye, Ayush Hola Ayush Adios Ayush
正如您已經看到的,我們使用模組中的**@behaviour** 指令採用行為。我們必須為所有 *子* 模組定義行為中實現的所有函式。這大致可以認為等同於 OOP 語言中的介面。
Elixir - 錯誤處理
Elixir 有三種錯誤機制:錯誤、丟擲和退出。讓我們詳細探討每種機制。
錯誤
當代碼中發生異常情況時,使用錯誤(或異常)。可以透過嘗試將數字新增到字串中來檢索示例錯誤:
IO.puts(1 + "Hello")
執行上述程式時,會產生以下錯誤:
** (ArithmeticError) bad argument in arithmetic expression :erlang.+(1, "Hello")
這是一個內建錯誤示例。
引發錯誤
我們可以使用 raise 函式**引發** 錯誤。讓我們考慮一個例子來理解這一點:
#Runtime Error with just a message raise "oops" # ** (RuntimeError) oops
可以使用 raise/2 傳遞錯誤名稱和關鍵字引數列表來引發其他錯誤。
#Other error type with a message raise ArgumentError, message: "invalid argument foo"
您還可以定義自己的錯誤並引發它們。考慮以下示例:
defmodule MyError do defexception message: "default message" end raise MyError # Raises error with default message raise MyError, message: "custom message" # Raises error with custom message
處理錯誤
我們不希望程式突然退出,而是需要仔細處理錯誤。為此,我們使用錯誤處理。我們使用**try/rescue** 結構**處理** 錯誤。讓我們考慮以下示例來理解這一點:
err = try do raise "oops" rescue e in RuntimeError -> e end IO.puts(err.message)
執行上述程式時,將產生以下結果:
oops
我們使用模式匹配在 rescue 語句中處理了錯誤。如果我們沒有使用錯誤,只是想將其用於識別目的,我們也可以使用以下形式:
err = try do 1 + "Hello" rescue RuntimeError -> "You've got a runtime error!" ArithmeticError -> "You've got a Argument error!" end IO.puts(err)
執行上述程式,會產生以下結果:
You've got a Argument error!
**注意** — Elixir 標準庫中的大多數函式都實現了兩次,一次返回元組,另一次引發錯誤。例如,**File.read** 和**File.read!** 函式。如果檔案讀取成功,第一個函式返回一個元組;如果遇到錯誤,則使用此元組給出錯誤原因。第二個函式如果遇到錯誤則引發錯誤。
如果我們使用第一個函式方法,那麼我們需要使用 case 來匹配模式錯誤並根據該錯誤採取行動。在第二種情況下,我們對易出錯的程式碼使用 try rescue 方法並相應地處理錯誤。
丟擲
在 Elixir 中,可以丟擲一個值,然後稍後捕獲它。Throw 和 Catch 保留用於無法檢索值的情況,除非使用 throw 和 catch。
實際上,除了與庫互動之外,這些例項很少見。例如,現在讓我們假設 Enum 模組沒有提供任何查詢值的 API,我們需要在數字列表中找到第一個 13 的倍數:
val = try do
Enum.each 20..100, fn(x) ->
if rem(x, 13) == 0, do: throw(x)
end
"Got nothing"
catch
x -> "Got #{x}"
end
IO.puts(val)
執行上述程式時,將產生以下結果:
Got 26
退出
當程序因“自然原因”(例如,未處理的異常)死亡時,它會發送退出訊號。程序也可以透過顯式傳送退出訊號而死亡。讓我們考慮以下示例:
spawn_link fn -> exit(1) end
在上面的示例中,連結的程序透過傳送值為 1 的退出訊號而死亡。請注意,exit 也可以使用 try/catch“捕獲”。例如:
val = try do exit "I am exiting" catch :exit, _ -> "not really" end IO.puts(val)
執行上述程式時,將產生以下結果:
not really
之後
有時需要確保在可能引發錯誤的一些操作之後清理資源。try/after 結構允許您這樣做。例如,我們可以開啟一個檔案,並在發生錯誤時使用 after 子句關閉它。
{:ok, file} = File.open "sample", [:utf8, :write]
try do
IO.write file, "olá"
raise "oops, something went wrong"
after
File.close(file)
end
當我們執行此程式時,它會給我們一個錯誤。但是**after** 語句將確保在任何此類事件發生時關閉檔案描述符。
Elixir - 宏
宏是 Elixir 最高階和最強大的功能之一。與任何語言的所有高階功能一樣,應謹慎使用宏。它們使得能夠在編譯時執行強大的程式碼轉換。我們現在將簡要了解宏是什麼以及如何在簡要說明中使用它們。
引用
在我們開始討論宏之前,讓我們首先看看 Elixir 的內部機制。Elixir 程式可以用它自己的資料結構來表示。Elixir 程式的構建塊是一個包含三個元素的元組。例如,函式呼叫 sum(1, 2, 3) 在內部表示為:
{:sum, [], [1, 2, 3]}
第一個元素是函式名稱,第二個是包含元資料的關鍵字列表,第三個是引數列表。如果您編寫以下內容,則可以在 iex shell 中將其作為輸出獲得:
quote do: sum(1, 2, 3)
運算子也表示為這樣的元組。變數也使用這樣的三元組表示,只是最後一個元素是原子,而不是列表。當引用更復雜的表示式時,我們可以看到程式碼是用這樣的元組表示的,這些元組通常彼此巢狀在一個類似樹的結構中。許多語言會將這種表示稱為**抽象語法樹 (AST)**。Elixir 將這些引用的表示式稱為 quoted expressions。
取消引用
既然我們可以檢索程式碼的內部結構,我們如何修改它呢?要注入新的程式碼或值,我們使用**unquote**。當我們取消引用表示式時,它將被計算並注入到 AST 中。讓我們考慮一個例子(在 iex shell 中)來理解這個概念:
num = 25 quote do: sum(15, num) quote do: sum(15, unquote(num))
執行上述程式時,將產生以下結果:
{:sum, [], [15, {:num, [], Elixir}]}
{:sum, [], [15, 25]}
在 quote 表示式的示例中,它沒有自動將 num 替換為 25。如果要修改 AST,則需要取消引用此變數。
宏
所以現在我們熟悉了 quote 和 unquote,我們可以使用宏來探索 Elixir 中的超程式設計。
簡單來說,宏是專門設計的函式,用於返回將插入到我們的應用程式程式碼中的引用表示式。想象一下,宏被替換為引用的表示式,而不是像函式一樣被呼叫。使用宏,我們擁有擴充套件 Elixir 並動態地向我們的應用程式新增程式碼所需的一切。
讓我們實現 unless 作為宏。我們將首先使用**defmacro** 宏來定義宏。請記住,我們的宏需要返回一個引用的表示式。
defmodule OurMacro do
defmacro unless(expr, do: block) do
quote do
if !unquote(expr), do: unquote(block)
end
end
end
require OurMacro
OurMacro.unless true, do: IO.puts "True Expression"
OurMacro.unless false, do: IO.puts "False expression"
執行上述程式時,將產生以下結果:
False expression
這裡發生的事情是我們的程式碼被 unless 宏返回的引用程式碼替換。我們取消引用表示式以在當前上下文中對其進行計算,並取消引用 do 塊以在其上下文中執行它。此示例向我們展示了使用宏在 elixir 中進行超程式設計。
宏可用於更復雜的任務,但應謹慎使用。這是因為超程式設計通常被認為是不好的做法,只有在必要時才應使用。
Elixir - 庫
Elixir 提供了與 Erlang 庫的出色互操作性。讓我們簡要討論一些庫。
Binary 模組
內建的 Elixir String 模組處理 UTF-8 編碼的二進位制資料。當處理並非 UTF-8 編碼的二進位制資料時,binary 模組非常有用。讓我們考慮一個例子來進一步理解 Binary 模組:
# UTF-8
IO.puts(String.to_char_list("Ø"))
# binary
IO.puts(:binary.bin_to_list "Ø")
執行上述程式時,將產生以下結果:
[216] [195, 152]
上面的例子顯示了區別;String 模組返回 UTF-8 程式碼點,而 :binary 處理原始資料位元組。
Crypto 模組
crypto 模組包含雜湊函式、數字簽名、加密等等。此模組不是 Erlang 標準庫的一部分,而是包含在 Erlang 發行版中。這意味著每當使用它時,都必須在專案的應用程式列表中列出 :crypto。讓我們看一個使用 crypto 模組的例子:
IO.puts(Base.encode16(:crypto.hash(:sha256, "Elixir")))
執行上述程式時,將產生以下結果:
3315715A7A3AD57428298676C5AE465DADA38D951BDFAC9348A8A31E9C7401CB
Digraph 模組
digraph 模組包含用於處理由頂點和邊構成的有向圖的函式。構造圖後,其中的演算法將有助於查詢例如兩個頂點之間的最短路徑或圖中的迴圈。請注意,:digraph 中的函式會間接地作為副作用來更改圖的結構,同時返回新增的頂點或邊。
digraph = :digraph.new()
coords = [{0.0, 0.0}, {1.0, 0.0}, {1.0, 1.0}]
[v0, v1, v2] = (for c <- coords, do: :digraph.add_vertex(digraph, c))
:digraph.add_edge(digraph, v0, v1)
:digraph.add_edge(digraph, v1, v2)
for point <- :digraph.get_short_path(digraph, v0, v2) do
{x, y} = point
IO.puts("#{x}, #{y}")
end
執行上述程式時,將產生以下結果:
0.0, 0.0 1.0, 0.0 1.0, 1.0
Math 模組
math 模組包含常見的數學運算,涵蓋三角函式、指數函式和對數函式。讓我們來看下面的例子,瞭解 Math 模組是如何工作的:
# Value of pi IO.puts(:math.pi()) # Logarithm IO.puts(:math.log(7.694785265142018e23)) # Exponentiation IO.puts(:math.exp(55.0)) #...
執行上述程式時,將產生以下結果:
3.141592653589793 55.0 7.694785265142018e23
佇列模組
佇列是一種資料結構,它高效地實現了 (雙端) FIFO (先進先出) 佇列。下面的例子展示了佇列模組是如何工作的:
q = :queue.new
q = :queue.in("A", q)
q = :queue.in("B", q)
{{:value, val}, q} = :queue.out(q)
IO.puts(val)
{{:value, val}, q} = :queue.out(q)
IO.puts(val)
執行上述程式時,將產生以下結果:
A B