Python 併發程式設計 - 快速指南
Python 併發程式設計 - 簡介
本章我們將瞭解 Python 中併發的概念,並學習不同的執行緒和程序。
什麼是併發?
簡單來說,併發是指兩個或多個事件同時發生。併發是一種自然現象,因為在任何給定時間,許多事件會同時發生。
在程式設計方面,併發是指兩個任務在執行上重疊。透過併發程式設計,可以提高應用程式和軟體系統的效能,因為我們可以併發處理請求,而不是等待上一個請求完成。
併發的歷史回顧
以下幾點將簡要回顧併發的歷史:
從鐵路的概念出發
併發與鐵路的概念密切相關。有了鐵路,就需要以一種方式處理同一鐵路系統上的多列火車,確保每列火車都能安全到達目的地。
學術界中的併發計算
對計算機科學併發的興趣始於 Edsger W. Dijkstra 在 1965 年發表的研究論文。在這篇論文中,他識別並解決了互斥問題,這是併發控制的一個特性。
高階併發原語
近年來,由於引入了高階併發原語,程式設計師們獲得了改進的併發解決方案。
程式語言改進的併發性
諸如 Google 的 Golang、Rust 和 Python 等程式語言在幫助我們獲得更好的併發解決方案的領域取得了令人難以置信的發展。
什麼是執行緒和多執行緒?
執行緒是作業系統中可以執行的最小執行單元。它本身不是一個程式,而是在程式中執行。換句話說,執行緒彼此不獨立。每個執行緒與其他執行緒共享程式碼段、資料段等。它們也被稱為輕量級程序。
執行緒包含以下元件:
程式計數器,包含下一個可執行指令的地址
堆疊
暫存器集
一個唯一的 ID
另一方面,多執行緒是指 CPU 管理作業系統使用情況的能力,透過併發執行多個執行緒來實現。多執行緒的主要思想是透過將一個程序分成多個執行緒來實現並行性。可以透過以下示例理解多執行緒的概念。
示例
假設我們正在執行一個特定的程序,其中我們開啟 MS Word 在其中鍵入內容。一個執行緒將被分配來開啟 MS Word,另一個執行緒將需要在其中鍵入內容。現在,如果我們想編輯現有的內容,則需要另一個執行緒來執行編輯任務,依此類推。
什麼是程序和多程序?
程序被定義為一個實體,它表示要在系統中實現的基本工作單元。簡單來說,我們將計算機程式寫在文字檔案中,當我們執行此程式時,它就變成了一個執行程式中提到的所有任務的程序。在程序生命週期中,它會經歷不同的階段——開始、就緒、執行、等待和終止。
下圖顯示了程序的不同階段:
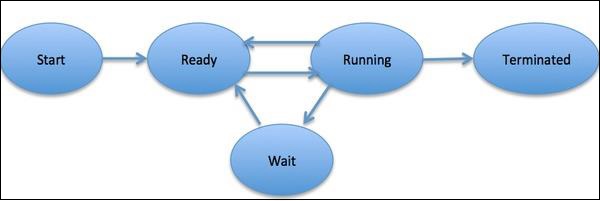
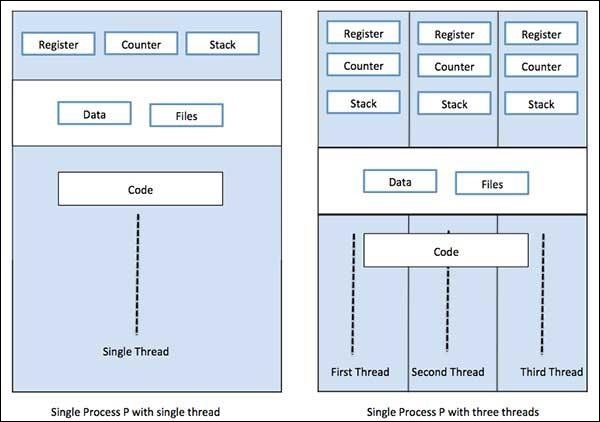
一個程序可以只有一個執行緒(稱為主執行緒),也可以有多個執行緒,每個執行緒都有自己的一組暫存器、程式計數器和堆疊。下圖將顯示它們的差異:
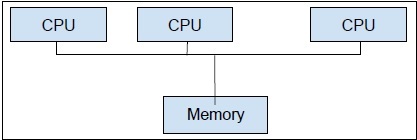
另一方面,多程序是在單個計算機系統中使用兩個或多個 CPU 單元。我們的主要目標是從我們的硬體中獲得全部潛力。為了實現這一點,我們需要利用計算機系統中可用的全部 CPU 核心數量。多程序是實現此目標的最佳方法。
Python是最流行的程式語言之一。以下是一些使其適合併發應用程式的原因:
語法糖
語法糖是在程式語言中設計的語法,旨在使程式碼更易於閱讀或表達。它使語言對人類使用更“友好”:可以更清晰、更簡潔地表達事物,或者根據偏好採用替代風格。Python 帶有魔術方法,可以定義為作用於物件。這些魔術方法用作語法糖,並繫結到更容易理解的關鍵字。
大型社群
Python 語言在人工智慧、機器學習、深度學習和定量分析領域工作的眾多資料科學家和數學家中獲得了廣泛的採用率。
用於併發程式設計的有用 API
Python 2 和 3 擁有大量專用於並行/併發程式設計的 API。其中最流行的是threading、concurrent.futures、multiprocessing、asyncio、gevent 和 greenlets等。
Python 在實現併發應用程式方面的侷限性
Python 在併發應用程式方面存在一個限制。這個限制被稱為GIL(全域性直譯器鎖)存在於 Python 中。GIL 從不允許我們利用 CPU 的多個核心,因此我們可以說 Python 中沒有真正的執行緒。我們可以如下理解 GIL 的概念:
GIL(全域性直譯器鎖)
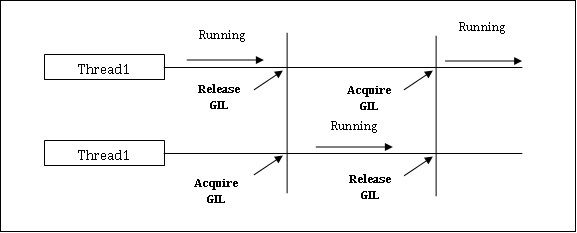
這是 Python 世界中備受爭議的話題之一。在 CPython 中,GIL 是互斥鎖——互斥鎖,它使事物執行緒安全。換句話說,我們可以說 GIL 阻止多個執行緒並行執行 Python 程式碼。一次只能由一個執行緒持有該鎖,如果我們想要執行一個執行緒,則它必須首先獲取該鎖。下圖將幫助你瞭解 GIL 的工作原理。
但是,Python 中有一些庫和實現,例如Numpy、Jpython和IronPytbhon。這些庫無需與 GIL 互動即可工作。
併發與並行
併發和並行都用於與多執行緒程式相關,但對它們之間相似性和差異的理解存在很多混淆。這方面的一個大問題是:併發是不是並行?雖然這兩個術語看起來非常相似,但上述問題的答案是否定的,併發和並行並不相同。現在,如果它們不相同,那麼它們之間有什麼根本區別呢?
簡單來說,併發處理的是從不同執行緒管理對共享狀態的訪問,而並行處理的是利用多個 CPU 或其核心來提高硬體效能。
併發詳解
併發是指兩個任務在執行上重疊。這可能是一種情況,即應用程式同時在多個任務上取得進展。我們可以用圖表來理解它;多個任務同時取得進展,如下所示:

併發級別
在本節中,我們將討論程式設計方面併發性的三個重要級別:
低階併發
在此併發級別中,顯式使用原子操作。我們不能將這種併發用於應用程式構建,因為它很容易出錯並且難以除錯。即使 Python 也不支援這種併發。
中級併發
在此併發中,不使用顯式原子操作。它使用顯式鎖。Python 和其他程式語言支援這種併發。大多數應用程式程式設計師都使用這種併發。
高階併發
在此併發中,既不使用顯式原子操作也不使用顯式鎖。Python 有concurrent.futures模組來支援這種併發。
併發系統的屬性
為了使程式或併發系統正確,它必須滿足某些屬性。與系統終止相關的屬性如下:
正確性屬性
正確性屬性意味著程式或系統必須提供所需的正確答案。為了簡單起見,我們可以說系統必須正確地將起始程式狀態對映到最終狀態。
安全性屬性
安全性屬性意味著程式或系統必須保持在“良好”或“安全”狀態,並且永遠不會做任何“壞”事。
活性屬性
此屬性意味著程式或系統必須“取得進展”並且它將達到某個理想狀態。
併發系統的參與者
這是併發系統的一個共同屬性,其中可以有多個程序和執行緒同時執行以在自己的任務上取得進展。這些程序和執行緒被稱為併發系統的參與者。
併發系統的資源
參與者必須利用記憶體、磁碟、印表機等資源才能執行其任務。
某些規則集
每個併發系統都必須擁有一組規則來定義參與者要執行的任務型別以及每個任務的時間安排。任務可能是獲取鎖、共享記憶體、修改狀態等。
併發系統的障礙
在實現併發系統時,程式設計師必須考慮以下兩個重要問題,它們可能是併發系統的障礙:資料共享
在實現併發系統時,一個重要的問題是在多個執行緒或程序之間共享資料。實際上,程式設計師必須確保鎖保護共享資料,以便對它的所有訪問都是序列的,並且一次只有一個執行緒或程序可以訪問共享資料。如果多個執行緒或程序都試圖訪問相同的共享資料,則並非所有執行緒或程序都會被阻塞並保持空閒狀態。換句話說,當鎖生效時,我們一次只能使用一個程序或執行緒。有一些簡單的解決方案可以消除上述障礙:
資料共享限制
最簡單的解決方案是不共享任何可變資料。在這種情況下,我們不需要使用顯式鎖,由於互斥資料造成的併發障礙也會得到解決。
資料結構輔助
很多時候,併發程序需要同時訪問相同的資料。除了使用顯式鎖之外,另一個解決方案是使用支援併發訪問的資料結構。例如,我們可以使用queue模組,它提供執行緒安全的佇列。我們還可以使用multiprocessing.JoinableQueue類進行基於多處理的併發。
不可變資料傳輸
有時,我們正在使用的資料結構(例如併發佇列)不合適,那麼我們可以傳遞不可變資料而無需鎖定它。
可變資料傳輸
延續上述解決方案,假設需要傳遞僅可變資料而不是不可變資料,那麼我們可以傳遞只讀的可變資料。
I/O資源共享
在實現併發系統時,另一個重要問題是執行緒或程序使用I/O資源。當一個執行緒或程序長時間使用I/O而其他程序處於空閒狀態時,就會出現問題。在處理I/O密集型應用程式時,我們可以看到這種型別的障礙。可以用一個例子來理解,例如從Web瀏覽器請求頁面。這是一個重量級應用程式。在這裡,如果請求資料的速率慢於消耗資料的速率,那麼我們的併發系統中就會出現I/O障礙。
以下Python指令碼用於請求網頁並獲取網路獲取請求頁面的時間:
import urllib.request
import time
ts = time.time()
req = urllib.request.urlopen('https://tutorialspoint.tw')
pageHtml = req.read()
te = time.time()
print("Page Fetching Time : {} Seconds".format (te-ts))
執行上述指令碼後,我們可以得到如下所示的頁面獲取時間。
輸出
Page Fetching Time: 1.0991398811340332 Seconds
我們可以看到獲取頁面的時間超過一秒。現在,如果我們要獲取數千個不同的網頁,您可以理解我們的網路將需要多少時間。
什麼是並行性?
並行性可以定義為將任務分解成可以同時處理的子任務的藝術。它與上面討論的併發性相反,併發性是指兩個或多個事件同時發生。我們可以透過圖表來理解它;一個任務被分解成許多可以並行處理的子任務,如下所示:
為了更好地理解併發和並行之間的區別,請考慮以下幾點:
併發但不併行
一個應用程式可以是併發但不併行的,這意味著它同時處理多個任務,但這些任務沒有被分解成子任務。
並行但不併發
一個應用程式可以是並行但不併發的,這意味著它一次只處理一個任務,並且可以並行處理將任務分解成的子任務。
既不併行也不併發
一個應用程式可以既不併行也不併發。這意味著它一次只處理一個任務,並且任務從未被分解成子任務。
既並行又併發
一個應用程式可以既並行又併發,這意味著它既可以同時處理多個任務,又可以將任務分解成子任務以並行執行它們。
並行性的必要性
我們可以透過將子任務分配到單個CPU的不同核心或連線到網路中的多臺計算機上來實現並行性。
請考慮以下要點,以瞭解為什麼需要實現並行性:
高效的程式碼執行
藉助並行性,我們可以高效地執行程式碼。這將節省我們的時間,因為程式碼的各個部分是並行執行的。
比順序計算快
順序計算受到物理和實際因素的約束,因此無法獲得更快的計算結果。另一方面,這個問題透過平行計算得到解決,並且比順序計算給我們更快的計算結果。
更短的執行時間
並行處理減少了程式程式碼的執行時間。
如果我們談論並行性的現例項子,我們計算機的顯示卡就是一個突顯並行處理真正能力的例子,因為它擁有數百個獨立工作的獨立處理核心,可以同時執行。由於這個原因,我們能夠執行高階應用程式和遊戲。
理解處理器以進行實現
我們瞭解併發、並行以及它們之間的區別,但是關於要在其上實現的系統呢?瞭解我們將要實現的系統非常必要,因為它使我們在設計軟體時能夠做出明智的決策。我們有以下兩種型別的處理器:
單核處理器
單核處理器能夠在任何給定時間執行一個執行緒。這些處理器使用上下文切換來儲存特定時間執行緒的所有必要資訊,然後稍後恢復資訊。上下文切換機制幫助我們在給定的一秒鐘內在許多執行緒上取得進展,看起來系統正在處理多件事情。
單核處理器有很多優點。這些處理器功耗更低,多個核心之間沒有複雜的通訊協議。另一方面,單核處理器的速度有限,不適合大型應用程式。
多核處理器
多核處理器具有多個獨立的處理單元,也稱為核心。
此類處理器不需要上下文切換機制,因為每個核心都包含執行一系列儲存指令所需的一切。
取指令-解碼-執行週期
多核處理器的核心遵循一個執行週期。這個週期稱為取指令-解碼-執行週期。它包括以下步驟:
取指令
這是週期的第一步,它涉及從程式記憶體中獲取指令。
解碼
最近獲取的指令將轉換為一系列訊號,這些訊號將觸發CPU的其他部分。
執行
這是最後一步,其中獲取和解碼的指令將被執行。執行結果將儲存在CPU暫存器中。
一個優點是多核處理器的執行速度比單核處理器快。它適合大型應用程式。另一方面,多個核心之間的複雜通訊協議是一個問題。多個核心比單核處理器需要更多的功耗。
系統和記憶體架構
在設計程式或併發系統時,需要考慮不同的系統和記憶體架構樣式。這是非常必要的,因為一種系統和記憶體樣式可能適合一項任務,但可能對另一項任務容易出錯。
支援併發的計算機系統架構
Michael Flynn在1972年提出了對不同型別的計算機系統架構進行分類的分類法。該分類法定義了四種不同的樣式,如下所示:
- 單指令流,單資料流 (SISD)
- 單指令流,多資料流 (SIMD)
- 多指令流,單資料流 (MISD)
- 多指令流,多資料流 (MIMD)。
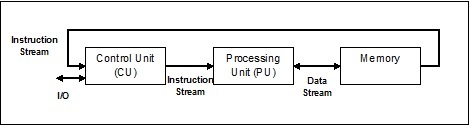
單指令流,單資料流 (SISD)
顧名思義,這種系統將擁有一個順序的輸入資料流和一個執行資料流的單個處理單元。它們就像具有平行計算架構的單處理器系統。以下是SISD的架構:
SISD的優點
SISD架構的優點如下:
- 功耗更低。
- 多個核心之間沒有複雜的通訊協議問題。
SISD的缺點
SISD架構的缺點如下:
- SISD架構的速度與單核處理器一樣有限。
- 它不適合大型應用程式。
單指令流,多資料流 (SIMD)
顧名思義,這種系統將擁有多個輸入資料流和多個處理單元,這些處理單元可以在任何給定時間對單個指令進行操作。它們就像具有平行計算架構的多處理器系統。以下是SIMD的架構:

SIMD的最佳示例是顯示卡。這些卡具有數百個獨立的處理單元。如果我們談論SISD和SIMD之間的計算差異,那麼對於新增陣列[5, 15, 20]和[15, 25, 10],SISD架構必須執行三個不同的加法運算。另一方面,使用SIMD架構,我們可以在單個加法運算中新增它們。
SIMD的優點
SIMD架構的優點如下:
只需一條指令即可對多個元素執行相同的操作。
透過增加處理器的核心數量,可以提高系統的吞吐量。
處理速度高於SISD架構。
SIMD的缺點
SIMD架構的缺點如下:
- 處理器核心之間存在複雜的通訊。
- 成本高於SISD架構。
多指令單資料 (MISD) 流
具有MISD流的系統具有多個處理單元,透過對相同資料集執行不同的指令來執行不同的操作。以下是MISD的架構:

MISD架構的代表尚未在商業上存在。
多指令多資料 (MIMD) 流
在使用MIMD架構的系統中,多處理器系統中的每個處理器都可以獨立地對不同資料集的不同指令集進行並行執行。它與SIMD架構相反,在SIMD架構中,對多個數據集執行單個操作。以下是MIMD的架構:
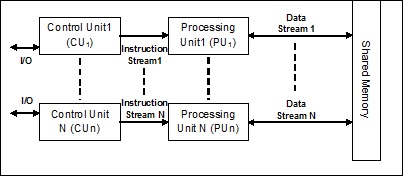
普通的多分處理器使用MIMD架構。這些架構基本上應用於許多領域,例如計算機輔助設計/計算機輔助製造、模擬、建模、通訊交換機等。
支援併發的記憶體架構
在處理併發和並行等概念時,總是需要加快程式速度。計算機設計師找到的一種解決方案是建立共享記憶體多計算機,即具有單個物理地址空間的計算機,該地址空間由處理器的所有核心訪問。在這種情況下,可能存在許多不同的架構風格,但以下三種架構風格非常重要:
UMA(統一記憶體訪問)
在這個模型中,所有處理器都統一共享物理記憶體。所有處理器對所有記憶體字的訪問時間相同。每個處理器可能都有一個私有快取記憶體。外圍裝置遵循一組規則。
當所有處理器都能平等地訪問所有外圍裝置時,系統被稱為對稱多處理器。當只有一個或少數處理器可以訪問外圍裝置時,系統被稱為非對稱多處理器。

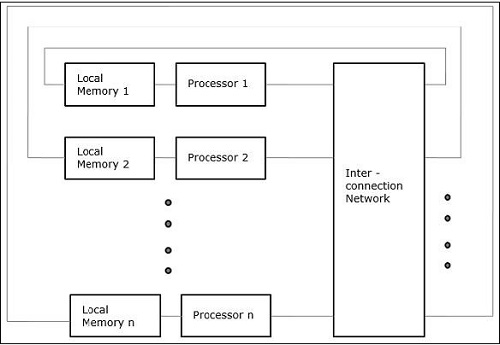
非統一記憶體訪問 (NUMA)
在 NUMA 多處理器模型中,訪問時間隨記憶體字的位置而變化。在這裡,共享記憶體物理上分佈在所有處理器之間,稱為本地記憶體。所有本地記憶體的集合構成一個全域性地址空間,所有處理器都可以訪問。
僅快取記憶體架構 (COMA)
COMA 模型是 NUMA 模型的一個特殊版本。在這裡,所有分散式主記憶體都被轉換為快取記憶體。
Python 中的併發 - 執行緒
一般來說,我們知道執行緒是一根非常細的扭曲的線,通常由棉或絲織物製成,用於縫製衣服等。術語“執行緒”也用於計算機程式設計領域。現在,我們如何將用於縫製衣服的執行緒與用於計算機程式設計的執行緒聯絡起來呢?兩者執行的角色在這裡是相似的。在衣服中,線將布料縫合在一起;在計算機程式設計中,執行緒將計算機程式連線在一起,並允許程式一次執行順序操作或許多操作。
執行緒是作業系統中最小的執行單元。它本身並不是一個程式,而是在程式內執行。換句話說,執行緒彼此不獨立,並與其他執行緒共享程式碼段、資料段等。這些執行緒也稱為輕量級程序。
執行緒的狀態
為了深入瞭解執行緒的功能,我們需要了解執行緒的生命週期或不同的執行緒狀態。通常,執行緒可以存在於五個不同的狀態。不同的狀態如下所示:
新建執行緒
一個新執行緒從新建狀態開始其生命週期。但是,在這個階段,它尚未啟動,也沒有分配任何資源。可以說它只是一個物件的例項。
可執行
當新建立的執行緒啟動時,執行緒變為可執行狀態,即等待執行。在此狀態下,它擁有所有資源,但任務排程程式尚未安排它執行。
執行
在此狀態下,執行緒取得進展並執行任務排程程式選擇執行的任務。現在,執行緒可以進入死亡狀態或不可執行/等待狀態。
不可執行/等待
在此狀態下,執行緒暫停,因為它正在等待某些 I/O 請求的響應或等待其他執行緒執行完成。
死亡
當可執行執行緒完成其任務或以其他方式終止時,它進入終止狀態。
下圖顯示了執行緒的完整生命週期:

執行緒的型別
在本節中,我們將瞭解不同型別的執行緒。這些型別描述如下:
使用者級執行緒
這些是使用者管理的執行緒。
在這種情況下,執行緒管理核心不知道執行緒的存在。執行緒庫包含用於建立和銷燬執行緒、線上程之間傳遞訊息和資料、排程執行緒執行以及儲存和恢復執行緒上下文的程式碼。應用程式從單個執行緒開始。
使用者級執行緒的示例包括:
- Java 執行緒
- POSIX 執行緒
使用者級執行緒的優點
以下是使用者級執行緒的不同優點:
- 執行緒切換不需要核心模式許可權。
- 使用者級執行緒可以在任何作業系統上執行。
- 使用者級執行緒的排程可以是特定於應用程式的。
- 使用者級執行緒建立和管理速度快。
使用者級執行緒的缺點
以下是使用者級執行緒的不同缺點:
- 在典型的作業系統中,大多數系統呼叫都是阻塞的。
- 多執行緒應用程式無法利用多處理。
核心級執行緒
作業系統管理的執行緒作用於核心,核心是作業系統核心。
在這種情況下,核心進行執行緒管理。應用程式區域中沒有執行緒管理程式碼。核心執行緒直接由作業系統支援。任何應用程式都可以程式設計為多執行緒的。應用程式中的所有執行緒都支援在一個程序中。
核心維護整個程序以及程序中各個執行緒的上下文資訊。核心按執行緒進行排程。核心在核心空間中執行執行緒建立、排程和管理。核心執行緒的建立和管理通常比使用者執行緒慢。核心級執行緒的示例包括 Windows 和 Solaris。

核心級執行緒的優點
以下是核心級執行緒的不同優點:
核心可以同時在多個程序上排程來自同一程序的多個執行緒。
如果程序中的一個執行緒被阻塞,核心可以排程同一程序的另一個執行緒。
核心例程本身可以是多執行緒的。
核心級執行緒的缺點
核心執行緒的建立和管理通常比使用者執行緒慢。
從同一程序中的一個執行緒到另一個執行緒的控制轉移需要模式切換到核心。
執行緒控制塊 - TCB
執行緒控制塊 (TCB) 可以定義為作業系統核心中的資料結構,該結構主要包含有關執行緒的資訊。儲存在 TCB 中的特定於執行緒的資訊將突出顯示有關每個程序的一些重要資訊。
考慮與 TCB 中包含的執行緒相關的以下幾點:
執行緒標識 - 這是分配給每個新執行緒的唯一執行緒 ID (tid)。
執行緒狀態 - 它包含與執行緒狀態(執行、可執行、不可執行、死亡)相關的資訊。
程式計數器 (PC) - 它指向執行緒的當前程式指令。
暫存器集 - 它包含分配給執行緒進行計算的暫存器值。
堆疊指標 - 它指向程序中執行緒的堆疊。它包含執行緒作用域內的區域性變數。
指向 PCB 的指標 - 它包含指向建立該執行緒的程序的指標。

程序與執行緒之間的關係
在多執行緒中,程序和執行緒是兩個非常密切相關的術語,它們具有相同的目標:使計算機能夠同時執行多項任務。一個程序可以包含一個或多個執行緒,但相反,執行緒不能包含一個程序。但是,它們仍然是兩個基本的執行單元。執行一系列指令的程式會同時啟動程序和執行緒。
下表顯示了程序和執行緒之間的比較:
| 程序 | 執行緒 |
|---|---|
| 程序是重量級的或資源密集型的。 | 執行緒是輕量級的,它比程序消耗更少的資源。 |
| 程序切換需要與作業系統互動。 | 執行緒切換不需要與作業系統互動。 |
| 在多處理環境中,每個程序執行相同的程式碼,但擁有自己的記憶體和檔案資源。 | 所有執行緒都可以共享同一組開啟的檔案、子程序。 |
| 如果一個程序被阻塞,則在第一個程序被解除阻塞之前,任何其他程序都不能執行。 | 當一個執行緒被阻塞並等待時,同一任務中的第二個執行緒可以執行。 |
| 不使用執行緒的多個程序使用更多資源。 | 多個執行緒程序使用更少的資源。 |
| 在多個程序中,每個程序獨立於其他程序執行。 | 一個執行緒可以讀取、寫入或更改另一個執行緒的資料。 |
| 如果父程序發生任何更改,則不會影響子程序。 | 如果主執行緒發生任何更改,則可能會影響該程序中其他執行緒的行為。 |
| 要與兄弟程序通訊,程序必須使用程序間通訊。 | 執行緒可以直接與該程序的其他執行緒通訊。 |
多執行緒的概念
正如我們前面討論的那樣,多執行緒是 CPU 管理作業系統使用方式的能力,透過同時執行多個執行緒來實現。多執行緒的主要思想是透過將程序劃分為多個執行緒來實現並行性。更簡單地說,多執行緒是使用執行緒概念實現多工處理的一種方式。
可以透過以下示例瞭解多執行緒的概念。
示例
假設我們正在執行一個程序。該程序可能是為了開啟 MS Word 來編寫一些內容。在此過程中,一個執行緒將被分配來開啟 MS Word,另一個執行緒將被要求進行編寫。現在,假設如果我們想編輯某些內容,則需要另一個執行緒來執行編輯任務,依此類推。
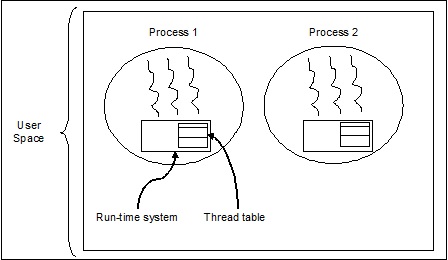
下圖有助於我們理解多個執行緒如何在記憶體中存在:

我們可以在上圖中看到,在一個程序中可以存在多個執行緒,其中每個執行緒都包含它自己的暫存器集和區域性變數。除此之外,程序中的所有執行緒共享全域性變數。
多執行緒的優點
現在讓我們看看多執行緒的一些優點。優點如下:
通訊速度 - 多執行緒提高了計算速度,因為每個核心或處理器同時處理單獨的執行緒。
程式保持響應 - 它允許程式保持響應,因為一個執行緒等待輸入,而另一個執行緒同時執行 GUI。
訪問全域性變數 - 在多執行緒中,特定程序的所有執行緒都可以訪問全域性變數,如果全域性變數發生任何更改,則其他執行緒也能看到。
資源利用率 - 在每個程式中執行多個執行緒可以更好地利用 CPU,並且 CPU 的空閒時間減少。
資料共享 - 每個執行緒不需要額外的空間,因為程式中的執行緒可以共享相同的資料。
多執行緒的缺點
現在讓我們看看多執行緒的一些缺點。缺點如下:
不適用於單處理器系統 − 與多處理器系統相比,多執行緒在單處理器系統上難以在計算速度方面實現效能提升。
安全問題 − 眾所周知,程式中的所有執行緒共享相同的資料,因此始終存在安全問題,因為任何未知執行緒都可能更改資料。
複雜性增加 − 多執行緒會增加程式的複雜性,從而使除錯變得困難。
導致死鎖狀態 − 多執行緒可能導致程式面臨達到死鎖狀態的潛在風險。
需要同步 − 需要同步來避免互斥。這會導致更多的記憶體和 CPU 利用率。
執行緒的實現
本章,我們將學習如何在 Python 中實現執行緒。
Python 執行緒實現模組
Python 執行緒有時被稱為輕量級程序,因為執行緒比程序佔用更少的記憶體。執行緒允許同時執行多個任務。在 Python 中,我們有以下兩個模組用於在程式中實現執行緒:
<_thread> 模組
<threading> 模組
這兩個模組的主要區別在於,<_thread> 模組將執行緒視為一個函式,而 <threading> 模組將每個執行緒視為一個物件並以面向物件的方式實現它。此外,<_thread> 模組在低階執行緒中有效,並且功能少於 <threading> 模組。
<_thread> 模組
在早期版本的 Python 中,我們有 <thread> 模組,但它已被認為是“已棄用”很長時間了。鼓勵使用者改用 <threading> 模組。因此,在 Python 3 中,“thread”模組不再可用。為了 Python 3 的向後相容性,它已被重新命名為“<_thread>”。
要藉助 <_thread> 模組生成新執行緒,我們需要呼叫其 start_new_thread 方法。可以透過以下語法瞭解此方法的工作原理:
_thread.start_new_thread ( function, args[, kwargs] )
這裡:
args 是一個引數元組
kwargs 是一個可選的關鍵字引數字典
如果我們想在不傳遞引數的情況下呼叫函式,則需要在 args 中使用空的引數元組。
此方法呼叫立即返回,子執行緒啟動,並使用傳遞的 args 列表(如果有)呼叫函式。執行緒在函式返回時終止。
示例
以下是使用 <_thread> 模組生成新執行緒的示例。我們在這裡使用 start_new_thread() 方法。
import _thread
import time
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: unable to start thread")
while 1:
pass
輸出
以下輸出將幫助我們理解藉助 <_thread> 模組生成新執行緒。
Thread-1: Mon Apr 23 10:03:33 2018 Thread-2: Mon Apr 23 10:03:35 2018 Thread-1: Mon Apr 23 10:03:35 2018 Thread-1: Mon Apr 23 10:03:37 2018 Thread-2: Mon Apr 23 10:03:39 2018 Thread-1: Mon Apr 23 10:03:39 2018 Thread-1: Mon Apr 23 10:03:41 2018 Thread-2: Mon Apr 23 10:03:43 2018 Thread-2: Mon Apr 23 10:03:47 2018 Thread-2: Mon Apr 23 10:03:51 2018
<threading> 模組
<threading> 模組以面向物件的方式實現,並將每個執行緒視為一個物件。因此,它比 <_thread> 模組提供了更強大、更高級別的執行緒支援。此模組包含在 Python 2.4 中。
<threading> 模組中的附加方法
<threading> 模組包含 <_thread> 模組的所有方法,但它也提供其他方法。附加方法如下:
threading.activeCount() − 此方法返回活動執行緒物件的數目
threading.currentThread() − 此方法返回呼叫方執行緒控制中的執行緒物件數目。
threading.enumerate() − 此方法返回當前活動的所有執行緒物件的列表。
run() − run() 方法是執行緒的入口點。
start() − start() 方法透過呼叫 run 方法啟動執行緒。
join([time]) − join() 等待執行緒終止。
isAlive() − isAlive() 方法檢查執行緒是否仍在執行。
getName() − getName() 方法返回執行緒的名稱。
setName() − setName() 方法設定執行緒的名稱。
為了實現執行緒,<threading> 模組具有 Thread 類,它提供以下方法:
如何使用 <threading> 模組建立執行緒?
在本節中,我們將學習如何使用 <threading> 模組建立執行緒。請按照以下步驟使用 <threading> 模組建立新執行緒:
步驟 1 − 在此步驟中,我們需要定義 Thread 類的新的子類。
步驟 2 − 然後為了新增附加引數,我們需要重寫 __init__(self [,args]) 方法。
步驟 3 − 在此步驟中,我們需要重寫 run(self [,args]) 方法來實現執行緒啟動時應執行的操作。
現在,在建立新的 Thread 子類之後,我們可以建立它的例項,然後透過呼叫 start() 啟動新執行緒,這反過來會呼叫 run() 方法。
示例
請考慮此示例以瞭解如何使用 <threading> 模組生成新執行緒。
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("Starting " + self.name)
print_time(self.name, self.counter, 5)
print ("Exiting " + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("Exiting Main Thread")
Starting Thread-1
Starting Thread-2
輸出
現在,請考慮以下輸出:
Thread-1: Mon Apr 23 10:52:09 2018 Thread-1: Mon Apr 23 10:52:10 2018 Thread-2: Mon Apr 23 10:52:10 2018 Thread-1: Mon Apr 23 10:52:11 2018 Thread-1: Mon Apr 23 10:52:12 2018 Thread-2: Mon Apr 23 10:52:12 2018 Thread-1: Mon Apr 23 10:52:13 2018 Exiting Thread-1 Thread-2: Mon Apr 23 10:52:14 2018 Thread-2: Mon Apr 23 10:52:16 2018 Thread-2: Mon Apr 23 10:52:18 2018 Exiting Thread-2 Exiting Main Thread
Python 程式用於各種執行緒狀態
執行緒有五種狀態——新建、可執行、執行、等待和死亡。在這五種狀態中,我們將主要關注三種狀態——執行、等待和死亡。執行緒在其執行狀態下獲取其資源,在其等待狀態下等待資源;如果執行並獲取,則在死亡狀態下最終釋放資源。
以下 Python 程式藉助 start()、sleep() 和 join() 方法將顯示執行緒如何分別進入執行、等待和死亡狀態。
步驟 1 − 匯入必要的模組,<threading> 和 <time>
import threading import time
步驟 2 − 定義一個函式,該函式將在建立執行緒時呼叫。
def thread_states():
print("Thread entered in running state")
步驟 3 − 我們使用 time 模組的 sleep() 方法使我們的執行緒等待例如 2 秒。
time.sleep(2)
步驟 4 − 現在,我們正在建立一個名為 T1 的執行緒,它接受上面定義的函式的引數。
T1 = threading.Thread(target=thread_states)
步驟 5 − 現在,藉助 start() 函式,我們可以啟動我們的執行緒。它將生成我們定義函式時設定的訊息。
T1.start() Thread entered in running state
步驟 6 − 現在,最後,我們可以線上程完成執行後使用 join() 方法終止執行緒。
T1.join()
在 Python 中啟動執行緒
在 Python 中,我們可以透過不同的方式啟動新執行緒,但其中最簡單的一種方法是將其定義為單個函式。定義函式後,我們可以將其作為新 threading.Thread 物件的目標,依此類推。執行以下 Python 程式碼以瞭解函式的工作原理:
import threading
import time
import random
def Thread_execution(i):
print("Execution of Thread {} started\n".format(i))
sleepTime = random.randint(1,4)
time.sleep(sleepTime)
print("Execution of Thread {} finished".format(i))
for i in range(4):
thread = threading.Thread(target=Thread_execution, args=(i,))
thread.start()
print("Active Threads:" , threading.enumerate())
輸出
Execution of Thread 0 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>]
Execution of Thread 1 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>]
Execution of Thread 2 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>,
<Thread(Thread-3578, started 2268)>]
Execution of Thread 3 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>,
<Thread(Thread-3578, started 2268)>,
<Thread(Thread-3579, started 4520)>]
Execution of Thread 0 finished
Execution of Thread 1 finished
Execution of Thread 2 finished
Execution of Thread 3 finished
Python 中的守護執行緒
在 Python 中實現守護執行緒之前,我們需要了解守護執行緒及其用途。在計算方面,守護程式是一個後臺程序,它處理各種服務的請求,例如資料傳送、檔案傳輸等。如果不再需要它,它將處於休眠狀態。也可以藉助非守護執行緒完成相同的任務。但是,在這種情況下,主執行緒必須手動跟蹤非守護執行緒。另一方面,如果我們使用守護執行緒,則主執行緒可以完全忘記這一點,並且在主執行緒退出時它將被終止。關於守護執行緒的另一個重要點是,我們可以選擇僅將它們用於非必需任務,如果這些任務未完成或中途被終止,則不會影響我們。以下是 Python 中守護執行緒的實現:
import threading
import time
def nondaemonThread():
print("starting my thread")
time.sleep(8)
print("ending my thread")
def daemonThread():
while True:
print("Hello")
time.sleep(2)
if __name__ == '__main__':
nondaemonThread = threading.Thread(target = nondaemonThread)
daemonThread = threading.Thread(target = daemonThread)
daemonThread.setDaemon(True)
daemonThread.start()
nondaemonThread.start()
在上面的程式碼中,有兩個函式,即 >nondaemonThread() 和 >daemonThread()。第一個函式列印其狀態並在 8 秒後休眠,而 deamonThread() 函式每 2 秒無限期地列印 Hello。我們可以藉助以下輸出瞭解非守護執行緒和守護執行緒之間的區別:
Hello starting my thread Hello Hello Hello Hello ending my thread Hello Hello Hello Hello Hello
執行緒同步
執行緒同步可以定義為一種方法,藉助該方法,我們可以確保兩個或多個併發執行緒不會同時訪問稱為臨界區的程式段。另一方面,眾所周知,臨界區是訪問共享資源的程式部分。因此,我們可以說同步是確保兩個或多個執行緒不會透過同時訪問資源來相互干擾的過程。下圖顯示了四個執行緒試圖同時訪問程式的臨界區。
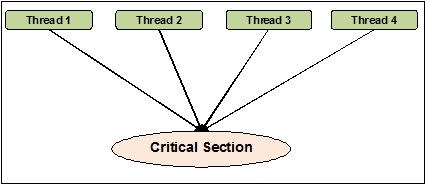
為了更清楚地說明,假設兩個或多個執行緒試圖同時在列表中新增物件。此操作無法成功結束,因為它要麼會丟棄一個或所有物件,要麼會完全破壞列表的狀態。這裡的同步作用是,一次只有一個執行緒可以訪問列表。
執行緒同步中的問題
在實現併發程式設計或應用同步原語時,我們可能會遇到問題。在本節中,我們將討論兩個主要問題。問題是:
- 死鎖
- 競爭條件
競爭條件
這是併發程式設計中的一個主要問題。對共享資源的併發訪問可能導致競爭條件。競爭條件可以定義為當兩個或多個執行緒可以訪問共享資料,然後嘗試同時更改其值時發生的條件。因此,變數的值可能不可預測,並且會根據程序上下文切換的時機而變化。
示例
請考慮此示例以瞭解競爭條件的概念:
步驟 1 − 在此步驟中,我們需要匯入 threading 模組:
import threading
步驟 2 − 現在,定義一個全域性變數,例如 x,其值為 0:
x = 0
步驟 3 − 現在,我們需要定義 increment_global() 函式,它將在這個全域性函式 x 中遞增 1:
def increment_global(): global x x += 1
步驟 4 − 在此步驟中,我們將定義 taskofThread() 函式,它將呼叫 increment_global() 函式指定次數;對於我們的示例,它是 50000 次:
def taskofThread():
for _ in range(50000):
increment_global()
步驟 5 − 現在,定義 main() 函式,其中建立執行緒 t1 和 t2。兩者都將藉助 start() 函式啟動,並藉助 join() 函式等待它們完成其工作。
def main(): global x x = 0 t1 = threading.Thread(target= taskofThread) t2 = threading.Thread(target= taskofThread) t1.start() t2.start() t1.join() t2.join()
步驟 6 − 現在,我們需要指定範圍,即我們希望呼叫 main() 函式的迭代次數。這裡,我們呼叫它 5 次。
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))
在下面顯示的輸出中,我們可以看到競爭條件的影響,因為每次迭代後 x 的值預期為 100000。但是,值存在很大的差異。這是由於執行緒併發訪問共享全域性變數 x 造成的。
輸出
x = 100000 after Iteration 0 x = 54034 after Iteration 1 x = 80230 after Iteration 2 x = 93602 after Iteration 3 x = 93289 after Iteration 4
使用鎖處理競爭條件
正如我們在上述程式中看到的競爭條件的影響一樣,我們需要一個同步工具來處理多個執行緒之間的競爭條件。在 Python 中,<threading> 模組提供 Lock 類來處理競爭條件。此外,Lock 類提供不同的方法,我們可以用這些方法來處理多個執行緒之間的競爭條件。這些方法描述如下:
acquire() 方法
此方法用於獲取,即阻塞鎖。鎖可以是阻塞的或非阻塞的,這取決於以下真或假值:
值為 True − 如果以 True 呼叫 acquire() 方法(這是預設引數),則執行緒執行將被阻塞,直到鎖被解鎖。
值為 False − 如果以 False 呼叫 acquire() 方法(這不是預設引數),則執行緒執行不會被阻塞,直到它被設定為 true,即直到它被鎖定。
release() 方法
此方法用於釋放鎖。以下是與此方法相關的幾個重要任務:
如果鎖已鎖定,則release() 方法將解鎖它。它的作用是允許恰好一個執行緒繼續執行,如果多個執行緒被阻塞並等待鎖被解鎖。
如果鎖已解鎖,它將引發ThreadError。
現在,我們可以使用 lock 類及其方法重寫上述程式以避免競爭條件。我們需要用 lock 引數定義 taskofThread() 方法,然後需要使用 acquire() 和 release() 方法來阻塞和非阻塞鎖,以避免競爭條件。
示例
以下是 Python 程式示例,用於理解用於處理競爭條件的鎖的概念:
import threading
x = 0
def increment_global():
global x
x += 1
def taskofThread(lock):
for _ in range(50000):
lock.acquire()
increment_global()
lock.release()
def main():
global x
x = 0
lock = threading.Lock()
t1 = threading.Thread(target = taskofThread, args = (lock,))
t2 = threading.Thread(target = taskofThread, args = (lock,))
t1.start()
t2.start()
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))
下面的輸出顯示競爭條件的影響被忽略了;因為每次迭代後 x 的值現在都是 100000,這符合該程式的預期。
輸出
x = 100000 after Iteration 0 x = 100000 after Iteration 1 x = 100000 after Iteration 2 x = 100000 after Iteration 3 x = 100000 after Iteration 4
死鎖 - 哲學家就餐問題
死鎖是設計併發系統時可能遇到的一個棘手問題。我們可以用哲學家就餐問題來說明這個問題,如下所示:
Edsger Dijkstra 最初提出了哲學家就餐問題,這是併發系統最大問題之一的著名例證,稱為死鎖。
在這個問題中,有五個著名的哲學家坐在圓桌旁,從他們的碗裡吃東西。有五把叉子可以被五個哲學家用來吃飯。但是,哲學家決定同時使用兩把叉子吃飯。
現在,哲學家有兩個主要條件。首先,每個哲學家都可以處於吃飯或思考狀態;其次,他們必須首先獲得兩把叉子,即左邊和右邊。當五個哲學家都設法同時拿起左邊的叉子時,問題就出現了。現在他們都在等待右邊的叉子空閒,但他們永遠不會放棄自己的叉子,直到他們吃完飯,而右邊的叉子永遠不會可用。因此,餐桌上會出現死鎖狀態。
併發系統中的死鎖
現在如果我們看到,同樣的問題也可能出現在我們的併發系統中。上面例子中的叉子將是系統資源,每個哲學家可以代表一個程序,該程序正在競爭獲取資源。
Python 程式的解決方案
這個問題的解決方案可以透過將哲學家分成兩種型別來找到——貪婪的哲學家和慷慨的哲學家。主要是一個貪婪的哲學家會試圖拿起左邊的叉子,並等待它出現。然後,他將等待右邊的叉子出現,拿起它,吃東西,然後放下它。另一方面,一個慷慨的哲學家會試圖拿起左邊的叉子,如果它不存在,他會等待一段時間後再嘗試。如果他們拿到左邊的叉子,他們就會試圖拿到右邊的叉子。如果他們也拿到右邊的叉子,他們就會吃東西並釋放兩個叉子。但是,如果他們沒有拿到右邊的叉子,他們就會釋放左邊的叉子。
示例
下面的 Python 程式將幫助我們找到哲學家就餐問題的解決方案:
import threading
import random
import time
class DiningPhilosopher(threading.Thread):
running = True
def __init__(self, xname, Leftfork, Rightfork):
threading.Thread.__init__(self)
self.name = xname
self.Leftfork = Leftfork
self.Rightfork = Rightfork
def run(self):
while(self.running):
time.sleep( random.uniform(3,13))
print ('%s is hungry.' % self.name)
self.dine()
def dine(self):
fork1, fork2 = self.Leftfork, self.Rightfork
while self.running:
fork1.acquire(True)
locked = fork2.acquire(False)
if locked: break
fork1.release()
print ('%s swaps forks' % self.name)
fork1, fork2 = fork2, fork1
else:
return
self.dining()
fork2.release()
fork1.release()
def dining(self):
print ('%s starts eating '% self.name)
time.sleep(random.uniform(1,10))
print ('%s finishes eating and now thinking.' % self.name)
def Dining_Philosophers():
forks = [threading.Lock() for n in range(5)]
philosopherNames = ('1st','2nd','3rd','4th', '5th')
philosophers= [DiningPhilosopher(philosopherNames[i], forks[i%5], forks[(i+1)%5]) \
for i in range(5)]
random.seed()
DiningPhilosopher.running = True
for p in philosophers: p.start()
time.sleep(30)
DiningPhilosopher.running = False
print (" It is finishing.")
Dining_Philosophers()
上面的程式使用了貪婪和慷慨的哲學家的概念。該程式還使用了<threading> 模組的Lock 類的acquire() 和release() 方法。我們可以在下面的輸出中看到解決方案:
輸出
4th is hungry. 4th starts eating 1st is hungry. 1st starts eating 2nd is hungry. 5th is hungry. 3rd is hungry. 1st finishes eating and now thinking.3rd swaps forks 2nd starts eating 4th finishes eating and now thinking. 3rd swaps forks5th starts eating 5th finishes eating and now thinking. 4th is hungry. 4th starts eating 2nd finishes eating and now thinking. 3rd swaps forks 1st is hungry. 1st starts eating 4th finishes eating and now thinking. 3rd starts eating 5th is hungry. 5th swaps forks 1st finishes eating and now thinking. 5th starts eating 2nd is hungry. 2nd swaps forks 4th is hungry. 5th finishes eating and now thinking. 3rd finishes eating and now thinking. 2nd starts eating 4th starts eating It is finishing.
執行緒間通訊
在現實生活中,如果一個團隊的人正在從事一項共同的任務,那麼他們之間應該進行溝通才能正確完成任務。同樣的類比也適用於執行緒。在程式設計中,為了減少處理器的空閒時間,我們建立多個執行緒並將不同的子任務分配給每個執行緒。因此,必須有一個通訊機制,並且它們應該相互互動以同步的方式完成工作。
考慮與執行緒間通訊相關的以下重要事項:
沒有效能提升 − 如果我們無法實現執行緒和程序之間的正確通訊,那麼併發和並行帶來的效能提升就毫無用處。
正確完成任務 − 如果沒有執行緒之間的正確通訊機制,則無法正確完成分配的任務。
比程序間通訊更高效 − 執行緒間通訊比程序間通訊更高效且更容易使用,因為一個程序中的所有執行緒共享相同的地址空間,它們不需要使用共享記憶體。
用於執行緒安全通訊的 Python 資料結構
多執行緒程式碼帶來了一個問題,即從一個執行緒傳遞資訊到另一個執行緒。標準通訊原語無法解決此問題。因此,我們需要實現我們自己的複合物件,以便線上程之間共享物件以使通訊執行緒安全。以下是一些資料結構,它們在進行一些更改後提供執行緒安全通訊:
集合
為了以執行緒安全的方式使用集合資料結構,我們需要擴充套件集合類以實現我們自己的鎖定機制。
示例
這是一個擴充套件類的 Python 示例:
class extend_class(set):
def __init__(self, *args, **kwargs):
self._lock = Lock()
super(extend_class, self).__init__(*args, **kwargs)
def add(self, elem):
self._lock.acquire()
try:
super(extend_class, self).add(elem)
finally:
self._lock.release()
def delete(self, elem):
self._lock.acquire()
try:
super(extend_class, self).delete(elem)
finally:
self._lock.release()
在上面的例子中,定義了一個名為extend_class的類物件,它進一步繼承自 Python 的set 類。在這個類的建構函式中建立了一個鎖物件。現在,有兩個函式 - add() 和 delete()。這些函式已定義且是執行緒安全的。它們都依賴於super類的功能,但有一個關鍵例外。
裝飾器
這是另一種用於執行緒安全通訊的關鍵方法,即使用裝飾器。
示例
考慮一個 Python 示例,它展示瞭如何使用裝飾器:
def lock_decorator(method):
def new_deco_method(self, *args, **kwargs):
with self._lock:
return method(self, *args, **kwargs)
return new_deco_method
class Decorator_class(set):
def __init__(self, *args, **kwargs):
self._lock = Lock()
super(Decorator_class, self).__init__(*args, **kwargs)
@lock_decorator
def add(self, *args, **kwargs):
return super(Decorator_class, self).add(elem)
@lock_decorator
def delete(self, *args, **kwargs):
return super(Decorator_class, self).delete(elem)
在上面的例子中,定義了一個名為 lock_decorator 的裝飾器方法,它進一步繼承自 Python 方法類。然後在這個類的建構函式中建立了一個鎖物件。現在,有兩個函式 - add() 和 delete()。這些函式已定義且是執行緒安全的。它們都依賴於super類的功能,但有一個關鍵例外。
列表
列表資料結構是執行緒安全的,對於臨時記憶體儲存來說既快速又容易。在 CPython 中,GIL 可以防止併發訪問它們。正如我們所知,列表是執行緒安全的,但是它們中的資料呢?實際上,列表的資料不受保護。例如,L.append(x) 不能保證在另一個執行緒嘗試執行相同操作時返回預期結果。這是因為,雖然append()是一個原子操作且執行緒安全,但另一個執行緒正在嘗試併發地修改列表的資料,因此我們可以在輸出中看到競爭條件的副作用。
為了解決這類問題並安全地修改資料,我們必須實現一個適當的鎖定機制,這進一步確保多個執行緒不會潛在遇到競爭條件。為了實現適當的鎖定機制,我們可以像在前面的示例中那樣擴充套件類。
列表上的一些其他原子操作如下:
L.append(x) L1.extend(L2) x = L[i] x = L.pop() L1[i:j] = L2 L.sort() x = y x.field = y D[x] = y D1.update(D2) D.keys()
這裡:
- L、L1、L2 都是列表
- D、D1、D2 是字典
- x、y 是物件
- i、j 是整數
佇列
如果列表的資料不受保護,我們可能不得不面對後果。我們可能會獲取或刪除錯誤的資料項,或者出現競爭條件。這就是建議使用佇列資料結構的原因。佇列的現實世界例子可以是一個單車道單行道,車輛先進入,先退出。在售票視窗和公交車站可以看到更多現實世界的例子。
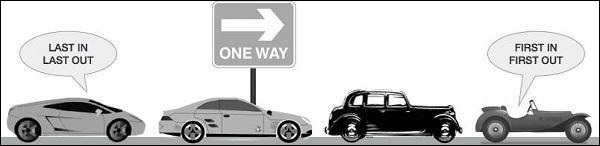
佇列預設是執行緒安全的的資料結構,我們不必擔心實現複雜的鎖定機制。Python 為我們提供了
佇列型別
在本節中,我們將瞭解不同型別的佇列。Python 提供了三個佇列選項,可從<queue> 模組中使用:
- 普通佇列 (FIFO,先進先出)
- LIFO,後進先出
- 優先順序
我們將在後續章節中學習不同的佇列。
普通佇列 (FIFO,先進先出)
這是 Python 提供的最常用的佇列實現。在這種排隊機制中,誰先來,誰先得到服務。FIFO 也稱為普通佇列。FIFO 佇列可以表示如下:

FIFO 佇列的 Python 實現
在 Python 中,FIFO 佇列可以使用單執行緒和多執行緒實現。
單執行緒 FIFO 佇列
為了使用單執行緒實現 FIFO 佇列,Queue 類將實現一個基本的先進先出容器。將使用put()將元素新增到序列的“一端”,並使用get()從另一端移除元素。
示例
以下是使用單執行緒實現 FIFO 佇列的 Python 程式:
import queue
q = queue.Queue()
for i in range(8):
q.put("item-" + str(i))
while not q.empty():
print (q.get(), end = " ")
輸出
item-0 item-1 item-2 item-3 item-4 item-5 item-6 item-7
輸出顯示上面的程式使用單個執行緒來說明元素以插入它們的相同順序從佇列中移除。
多執行緒 FIFO 佇列
為了實現多執行緒FIFO佇列,我們需要定義myqueue()函式,該函式擴充套件自queue模組。get()和put()方法的工作原理與上面討論的單執行緒FIFO佇列實現相同。然後,為了使其支援多執行緒,我們需要宣告和例項化執行緒。這些執行緒將以FIFO方式消費佇列。
示例
下面是一個使用多執行緒實現FIFO佇列的Python程式
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(2)
q = queue.Queue()
for i in range(5):
q.put(i)
threads = []
for i in range(4):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
輸出
<Thread(Thread-3654, started 5044)> removed 0 from the queue <Thread(Thread-3655, started 3144)> removed 1 from the queue <Thread(Thread-3656, started 6996)> removed 2 from the queue <Thread(Thread-3657, started 2672)> removed 3 from the queue <Thread(Thread-3654, started 5044)> removed 4 from the queue
LIFO佇列(後進先出佇列)
此佇列與FIFO(先進先出)佇列的邏輯完全相反。在此排隊機制中,最後到達的將最先獲得服務。這類似於實現棧資料結構。LIFO佇列在實現人工智慧的深度優先搜尋等演算法時非常有用。
LIFO佇列的Python實現
在Python中,LIFO佇列可以使用單執行緒和多執行緒實現。
單執行緒LIFO佇列
為了實現單執行緒LIFO佇列,**Queue**類將使用**Queue.LifoQueue**結構實現一個基本的先進後出容器。現在,呼叫**put()**時,元素新增到容器的頭部,使用**get()**時也從頭部移除。
示例
下面是一個使用單執行緒實現LIFO佇列的Python程式:
import queue
q = queue.LifoQueue()
for i in range(8):
q.put("item-" + str(i))
while not q.empty():
print (q.get(), end=" ")
Output:
item-7 item-6 item-5 item-4 item-3 item-2 item-1 item-0
輸出顯示上述程式使用單執行緒來說明元素以與插入順序相反的順序從佇列中移除。
多執行緒LIFO佇列
實現方法與我們使用多執行緒實現FIFO佇列的方法類似。唯一的區別是我們需要使用**Queue**類,它將使用**Queue.LifoQueue**結構實現一個基本的先進後出容器。
示例
下面是一個使用多執行緒實現LIFO佇列的Python程式:
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(2)
q = queue.LifoQueue()
for i in range(5):
q.put(i)
threads = []
for i in range(4):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
輸出
<Thread(Thread-3882, started 4928)> removed 4 from the queue <Thread(Thread-3883, started 4364)> removed 3 from the queue <Thread(Thread-3884, started 6908)> removed 2 from the queue <Thread(Thread-3885, started 3584)> removed 1 from the queue <Thread(Thread-3882, started 4928)> removed 0 from the queue
優先順序佇列
在FIFO和LIFO佇列中,專案的順序與插入順序相關。但是,在許多情況下,優先順序比插入順序更重要。讓我們考慮一個現實世界的例子。假設機場安檢正在檢查不同類別的乘客。VVIP、航空公司員工、海關官員等類別的乘客可能會優先檢查,而不是像普通乘客那樣按到達順序檢查。
優先順序佇列需要考慮的另一個重要方面是如何開發任務排程程式。一種常見的方案是基於優先順序服務佇列中最緊急的任務。此資料結構可用於根據專案的優先順序值從佇列中提取專案。
優先順序佇列的Python實現
在Python中,優先順序佇列可以使用單執行緒和多執行緒實現。
單執行緒優先順序佇列
為了實現單執行緒優先順序佇列,**Queue**類將使用**Queue.PriorityQueue**結構實現一個基於優先順序的任務容器。現在,呼叫**put()**時,元素將新增一個值,其中值越小優先順序越高,因此將首先使用**get()**檢索。
示例
考慮以下使用單執行緒實現優先順序佇列的Python程式:
import queue as Q
p_queue = Q.PriorityQueue()
p_queue.put((2, 'Urgent'))
p_queue.put((1, 'Most Urgent'))
p_queue.put((10, 'Nothing important'))
prio_queue.put((5, 'Important'))
while not p_queue.empty():
item = p_queue.get()
print('%s - %s' % item)
輸出
1 – Most Urgent 2 - Urgent 5 - Important 10 – Nothing important
在上面的輸出中,我們可以看到佇列根據優先順序儲存了專案——值越小,優先順序越高。
多執行緒優先順序佇列
實現方法與使用多執行緒實現FIFO和LIFO佇列的方法類似。唯一的區別是我們需要使用**Queue**類來使用**Queue.PriorityQueue**結構初始化優先順序。另一個區別在於佇列的生成方式。在下面給出的示例中,它將使用兩個相同的資料集生成。
示例
下面的Python程式有助於使用多執行緒實現優先順序佇列:
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(1)
q = queue.PriorityQueue()
for i in range(5):
q.put(i,1)
for i in range(5):
q.put(i,1)
threads = []
for i in range(2):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
輸出
<Thread(Thread-4939, started 2420)> removed 0 from the queue <Thread(Thread-4940, started 3284)> removed 0 from the queue <Thread(Thread-4939, started 2420)> removed 1 from the queue <Thread(Thread-4940, started 3284)> removed 1 from the queue <Thread(Thread-4939, started 2420)> removed 2 from the queue <Thread(Thread-4940, started 3284)> removed 2 from the queue <Thread(Thread-4939, started 2420)> removed 3 from the queue <Thread(Thread-4940, started 3284)> removed 3 from the queue <Thread(Thread-4939, started 2420)> removed 4 from the queue <Thread(Thread-4940, started 3284)> removed 4 from the queue
執行緒應用測試
在本章中,我們將學習執行緒應用程式的測試。我們還將學習測試的重要性。
為什麼要測試?
在我們深入討論測試的重要性之前,我們需要知道什麼是測試。一般來說,測試是一種找出某事物工作情況有多好的技術。另一方面,如果我們具體談論計算機程式或軟體,那麼測試就是訪問軟體程式功能的技術。
在本節中,我們將討論軟體測試的重要性。在軟體開發中,在向客戶釋出軟體之前必須進行二次檢查。這就是為什麼由經驗豐富的測試團隊測試軟體非常重要的原因。請考慮以下幾點,以瞭解軟體測試的重要性:
提高軟體質量
當然,沒有公司想交付低質量的軟體,也沒有客戶想購買低質量的軟體。測試透過查詢和修復其中的錯誤來提高軟體質量。
客戶滿意度
任何業務最重要的部分是客戶的滿意度。透過提供無錯誤且高質量的軟體,公司可以實現客戶滿意度。
減少新功能的影響
假設我們已經制作了一個10000行的軟體系統,我們需要新增一個新功能,那麼開發團隊會擔心這個新功能對整個軟體的影響。在這裡,測試也起著至關重要的作用,因為如果測試團隊建立了一套良好的測試,那麼它可以使我們免受任何潛在的災難性故障。
使用者體驗
任何業務的另一個最重要的部分是該產品使用者的體驗。只有測試才能確保終端使用者發現該產品簡單易用。
降低成本
測試可以透過在開發階段查詢和修復錯誤來降低軟體的總成本,而不是在交付後修復它。如果軟體交付後存在重大錯誤,則會增加其有形成本(例如支出)和無形成本(例如客戶不滿、公司負面聲譽等)。
測試什麼?
始終建議對要測試的內容有適當的瞭解。在本節中,我們首先將瞭解測試任何軟體時測試人員的首要動機。在測試時,應避免程式碼覆蓋率,即我們的測試套件命中了多少行程式碼。這是因為,在測試時,只關注程式碼行數不會為我們的系統增加任何實際價值。即使在部署後,也可能仍然存在一些錯誤,這些錯誤會在稍後的階段反映出來。
考慮以下與測試內容相關的要點:
我們需要關注測試程式碼的功能,而不是程式碼覆蓋率。
我們需要首先測試程式碼中最重要的部分,然後轉向程式碼中不太重要的部分。這肯定會節省時間。
測試人員必須進行多種不同的測試,這些測試可以將軟體推到其極限。
併發軟體程式的測試方法
由於能夠利用多核架構的真正能力,併發軟體系統正在取代順序系統。近年來,併發系統程式已用於從手機到洗衣機,從汽車到飛機等一切事物。我們需要更加小心地測試併發軟體程式,因為如果我們向已經存在錯誤的單執行緒應用程式添加了多個執行緒,那麼最終會產生多個錯誤。
併發軟體程式的測試技術主要集中在選擇交錯,以揭示潛在的有害模式,例如競爭條件、死鎖和原子性違規。以下是兩種併發軟體程式測試方法:
系統探索
這種方法旨在儘可能廣泛地探索交錯空間。此類方法可以採用蠻力技術,其他方法採用部分順序約簡技術或啟發式技術來探索交錯空間。
屬性驅動
屬性驅動的方法依賴於這樣的觀察:併發錯誤更有可能發生在揭示特定屬性(例如可疑記憶體訪問模式)的交錯下。不同的屬性驅動方法針對不同的錯誤,例如競爭條件、死鎖和原子性違規,這進一步取決於一個或另一個特定屬性。
測試策略
測試策略也稱為測試方法。該策略定義瞭如何進行測試。測試方法有兩種技術:
主動式
一種方法,其中測試設計過程儘早啟動,以便在建立構建之前查詢和修復缺陷。
被動式
一種方法,其中測試直到開發過程完成後才開始。
在將任何測試策略或方法應用於Python程式之前,我們必須對軟體程式可能存在的錯誤型別有一個基本的瞭解。錯誤如下:
語法錯誤
在程式開發過程中,可能會出現許多小錯誤。這些錯誤大多是由於打字錯誤造成的。例如,缺少冒號或關鍵字拼寫錯誤等。此類錯誤是由於程式語法中的錯誤造成的,而不是邏輯錯誤。因此,這些錯誤稱為語法錯誤。
語義錯誤
語義錯誤也稱為邏輯錯誤。如果軟體程式中存在邏輯或語義錯誤,則該語句將正確編譯和執行,但它不會給出預期的輸出,因為邏輯不正確。
單元測試
這是用於測試Python程式最常用的測試策略之一。此策略用於測試程式碼的單元或元件。就單元或元件而言,我們的意思是程式碼的類或函式。單元測試透過測試“小型”單元來簡化大型程式設計系統的測試。藉助上述概念,單元測試可以定義為一種方法,其中測試單個原始碼單元以確定它們是否返回所需的輸出。
在我們接下來的章節中,我們將學習用於單元測試的不同Python模組。
unittest模組
第一個用於單元測試的模組是unittest模組。它受JUnit啟發,預設包含在Python 3.6中。它支援測試自動化、共享測試的設定和拆卸程式碼、將測試聚合到集合中以及測試與報告框架的獨立性。
以下是unittest模組支援的一些重要概念
測試裝置
它用於設定測試,以便在開始測試之前執行它,並在測試結束後拆除。這可能包括在開始測試之前建立所需的臨時資料庫、目錄等。
測試用例
測試用例檢查特定輸入集是否產生所需響應。unittest模組包含一個名為TestCase的基類,可用於建立新的測試用例。它預設包含兩種方法:
**setUp()** - 一個掛鉤方法,用於在執行測試裝置之前設定它。這在呼叫已實現的測試方法之前呼叫。
**tearDown()** - 一個掛鉤方法,用於在執行類中所有測試後解構類測試裝置。
測試套件
它是測試套件、測試用例或兩者的集合。
測試執行器
它控制測試用例或套件的執行,並將結果提供給使用者。它可以使用GUI或簡單的文字介面來提供結果。
示例
下面的Python程式使用unittest模組來測試名為Fibonacci的模組。該程式有助於計算數字的斐波那契數列。在這個例子中,我們建立了一個名為Fibo_test的類,使用不同的方法定義測試用例。這些方法繼承自unittest.TestCase。我們預設使用了兩個方法——setUp()和tearDown()。我們還定義了testfibocal方法。測試名稱必須以字母test開頭。在最後的塊中,unittest.main()為測試指令碼提供了一個命令列介面。
import unittest
def fibonacci(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return a
class Fibo_Test(unittest.TestCase):
def setUp(self):
print("This is run before our tests would be executed")
def tearDown(self):
print("This is run after the completion of execution of our tests")
def testfibocal(self):
self.assertEqual(fib(0), 0)
self.assertEqual(fib(1), 1)
self.assertEqual(fib(5), 5)
self.assertEqual(fib(10), 55)
self.assertEqual(fib(20), 6765)
if __name__ == "__main__":
unittest.main()
從命令列執行時,上述指令碼生成的輸出如下所示:
輸出
This runs before our tests would be executed. This runs after the completion of execution of our tests. . ---------------------------------------------------------------------- Ran 1 test in 0.006s OK
現在,為了更清晰起見,我們修改了幫助定義Fibonacci模組的程式碼。
以下程式碼塊為例:
def fibonacci(n): a, b = 0, 1 for i in range(n): a, b = b, a + b return a
對程式碼塊進行了一些更改,如下所示:
def fibonacci(n): a, b = 1, 1 for i in range(n): a, b = b, a + b return a
現在,使用修改後的程式碼執行指令碼後,我們將得到以下輸出:
This runs before our tests would be executed. This runs after the completion of execution of our tests. F ====================================================================== FAIL: testCalculation (__main__.Fibo_Test) ---------------------------------------------------------------------- Traceback (most recent call last): File "unitg.py", line 15, in testCalculation self.assertEqual(fib(0), 0) AssertionError: 1 != 0 ---------------------------------------------------------------------- Ran 1 test in 0.007s FAILED (failures = 1)
上述輸出表明該模組未能給出期望的輸出。
doctest模組
doctest模組也有助於單元測試。它也預先打包在python中。它比unittest模組更容易使用。unittest模組更適合複雜的測試。要使用doctest模組,我們需要匯入它。相應函式的文件字串必須包含互動式python會話及其輸出。
如果我們的程式碼一切正常,那麼doctest模組將不會輸出任何內容;否則,它將提供輸出。
示例
以下Python示例使用doctest模組測試名為Fibonacci的模組,該模組有助於計算數字的斐波那契數列。
import doctest
def fibonacci(n):
"""
Calculates the Fibonacci number
>>> fibonacci(0)
0
>>> fibonacci(1)
1
>>> fibonacci(10)
55
>>> fibonacci(20)
6765
>>>
"""
a, b = 1, 1
for i in range(n):
a, b = b, a + b
return a
if __name__ == "__main__":
doctest.testmod()
我們可以看到,名為fib的相應函式的文件字串包含互動式python會話及其輸出。如果我們的程式碼正常,則doctest模組不會輸出任何內容。但是為了瞭解其工作原理,我們可以使用-v選項執行它。
(base) D:\ProgramData>python dock_test.py -v Trying: fibonacci(0) Expecting: 0 ok Trying: fibonacci(1) Expecting: 1 ok Trying: fibonacci(10) Expecting: 55 ok Trying: fibonacci(20) Expecting: 6765 ok 1 items had no tests: __main__ 1 items passed all tests: 4 tests in __main__.fibonacci 4 tests in 2 items. 4 passed and 0 failed. Test passed.
現在,我們將更改幫助定義Fibonacci模組的程式碼
以下程式碼塊為例:
def fibonacci(n): a, b = 0, 1 for i in range(n): a, b = b, a + b return a
以下程式碼塊有助於進行更改:
def fibonacci(n): a, b = 1, 1 for i in range(n): a, b = b, a + b return a
即使沒有使用-v選項,使用更改後的程式碼執行指令碼後,我們將得到如下所示的輸出。
輸出
(base) D:\ProgramData>python dock_test.py ********************************************************************** File "unitg.py", line 6, in __main__.fibonacci Failed example: fibonacci(0) Expected: 0 Got: 1 ********************************************************************** File "unitg.py", line 10, in __main__.fibonacci Failed example: fibonacci(10) Expected: 55 Got: 89 ********************************************************************** File "unitg.py", line 12, in __main__.fibonacci Failed example: fibonacci(20) Expected: 6765 Got: 10946 ********************************************************************** 1 items had failures: 3 of 4 in __main__.fibonacci ***Test Failed*** 3 failures.
我們可以看到上面的輸出顯示三個測試失敗了。
執行緒應用除錯
在本章中,我們將學習如何除錯執行緒應用程式。我們還將學習除錯的重要性。
什麼是除錯?
在計算機程式設計中,除錯是查詢並刪除計算機程式中錯誤、異常和異常的過程。這個過程從程式碼編寫之初就開始,並在後續階段持續進行,因為程式碼與其他程式設計單元組合在一起形成軟體產品。除錯是軟體測試過程的一部分,也是整個軟體開發生命週期中不可或缺的一部分。
Python偵錯程式
Python偵錯程式或pdb是Python標準庫的一部分。它是一個很好的後備工具,用於追蹤難以查詢的錯誤,並允許我們快速可靠地修復有故障的程式碼。以下是pdp偵錯程式的兩個最重要的任務:
- 它允許我們在執行時檢查變數的值。
- 我們還可以逐步執行程式碼並設定斷點。
我們可以透過以下兩種方式使用pdb:
- 透過命令列;這也被稱為事後除錯。
- 透過互動式執行pdb。
使用pdb
要使用Python偵錯程式,我們需要在想要進入偵錯程式的 位置使用以下程式碼:
import pdb; pdb.set_trace()
考慮使用以下命令透過命令列使用pdb。
- h(help)
- d(down)
- u(up)
- b(break)
- cl(clear)
- l(list)
- n(next)
- c(continue)
- s(step)
- r(return)
- b(break)
以下是Python偵錯程式h(help)命令的演示:
import pdb pdb.set_trace() --Call-- >d:\programdata\lib\site-packages\ipython\core\displayhook.py(247)__call__() -> def __call__(self, result = None): (Pdb) h Documented commands (type help <topic>): ======================================== EOF c d h list q rv undisplay a cl debug help ll quit s unt alias clear disable ignore longlist r source until args commands display interact n restart step up b condition down j next return tbreak w break cont enable jump p retval u whatis bt continue exit l pp run unalias where Miscellaneous help topics: ========================== exec pdb
示例
在使用Python偵錯程式時,我們可以使用以下幾行程式碼在指令碼中的任何位置設定斷點:
import pdb; pdb.set_trace()
設定斷點後,我們可以正常執行指令碼。指令碼將執行到某個點;直到設定了斷點的行。以下示例中,我們將使用上述幾行程式碼在指令碼中的各個位置執行指令碼:
import pdb; a = "aaa" pdb.set_trace() b = "bbb" c = "ccc" final = a + b + c print (final)
執行上述指令碼時,它將執行程式直到a = “aaa”,我們可以在以下輸出中檢查這一點。
輸出
--Return-- > <ipython-input-7-8a7d1b5cc854>(3)<module>()->None -> pdb.set_trace() (Pdb) p a 'aaa' (Pdb) p b *** NameError: name 'b' is not defined (Pdb) p c *** NameError: name 'c' is not defined
在pdb中使用命令‘p(print)’後,此指令碼只打印‘aaa’。之後出現錯誤,因為我們已將斷點設定到a = "aaa"。
同樣,我們可以透過更改斷點來執行指令碼並檢視輸出差異:
import pdb a = "aaa" b = "bbb" c = "ccc" pdb.set_trace() final = a + b + c print (final)
輸出
--Return-- > <ipython-input-9-a59ef5caf723>(5)<module>()->None -> pdb.set_trace() (Pdb) p a 'aaa' (Pdb) p b 'bbb' (Pdb) p c 'ccc' (Pdb) p final *** NameError: name 'final' is not defined (Pdb) exit
在以下指令碼中,我們在程式的最後一行設定斷點:
import pdb a = "aaa" b = "bbb" c = "ccc" final = a + b + c pdb.set_trace() print (final)
輸出如下:
--Return-- > <ipython-input-11-8019b029997d>(6)<module>()->None -> pdb.set_trace() (Pdb) p a 'aaa' (Pdb) p b 'bbb' (Pdb) p c 'ccc' (Pdb) p final 'aaabbbccc' (Pdb)
基準測試和效能分析
在本章中,我們將學習基準測試和效能分析如何幫助解決效能問題。
假設我們編寫了一個程式碼,它也給出了期望的結果,但是如果我們想讓這個程式碼執行得更快一些,因為需求發生了變化呢?在這種情況下,我們需要找出程式碼的哪些部分正在減慢整個程式的執行速度。在這種情況下,基準測試和效能分析可能會有用。
什麼是基準測試?
基準測試旨在透過與標準進行比較來評估某些東西。但是,這裡出現的問題是基準測試是什麼,以及在軟體程式設計的情況下為什麼需要它。對程式碼進行基準測試意味著程式碼的執行速度以及瓶頸在哪裡。基準測試的一個主要原因是它可以最佳化程式碼。
基準測試是如何工作的?
如果我們談論基準測試的工作原理,我們需要從將整個程式作為一個當前狀態進行基準測試開始,然後我們可以組合微基準測試,然後將程式分解成更小的程式。為了找到程式中的瓶頸並對其進行最佳化。換句話說,我們可以將其理解為將大型難題分解成一系列較小且更容易解決的問題,以便對其進行最佳化。
Python基準測試模組
在Python中,我們有一個預設的基準測試模組,稱為timeit。藉助timeit模組,我們可以在主程式中測量一小段Python程式碼的效能。
示例
在下面的Python指令碼中,我們匯入了timeit模組,該模組進一步測量執行兩個函式——functionA和functionB——所需的時間:
import timeit
import time
def functionA():
print("Function A starts the execution:")
print("Function A completes the execution:")
def functionB():
print("Function B starts the execution")
print("Function B completes the execution")
start_time = timeit.default_timer()
functionA()
print(timeit.default_timer() - start_time)
start_time = timeit.default_timer()
functionB()
print(timeit.default_timer() - start_time)
執行上述指令碼後,我們將得到兩個函式的執行時間,如下所示。
輸出
Function A starts the execution: Function A completes the execution: 0.0014599495514175942 Function B starts the execution Function B completes the execution 0.0017024724827479076
使用裝飾器函式編寫我們自己的計時器
在Python中,我們可以建立我們自己的計時器,它的作用就像timeit模組一樣。這可以透過裝飾器函式來實現。以下是一個自定義計時器的示例:
import random
import time
def timer_func(func):
def function_timer(*args, **kwargs):
start = time.time()
value = func(*args, **kwargs)
end = time.time()
runtime = end - start
msg = "{func} took {time} seconds to complete its execution."
print(msg.format(func = func.__name__,time = runtime))
return value
return function_timer
@timer_func
def Myfunction():
for x in range(5):
sleep_time = random.choice(range(1,3))
time.sleep(sleep_time)
if __name__ == '__main__':
Myfunction()
上面的python指令碼有助於匯入隨機時間模組。我們建立了timer_func()裝飾器函式。它內部包含function_timer()函式。現在,巢狀函式將在呼叫傳入的函式之前獲取時間。然後它等待函式返回並獲取結束時間。透過這種方式,我們最終可以使python指令碼列印執行時間。指令碼將生成如下所示的輸出。
輸出
Myfunction took 8.000457763671875 seconds to complete its execution.
什麼是效能分析?
有時程式設計師希望測量程式的一些屬性,例如記憶體使用情況、時間複雜度或特定指令的使用情況,以衡量該程式的實際能力。對程式進行這種測量稱為效能分析。效能分析使用動態程式分析進行這種測量。
在接下來的部分中,我們將學習關於不同Python效能分析模組的內容。
cProfile – 內建模組
cProfile是Python內建的效能分析模組。該模組是一個C擴充套件,開銷合理,使其適合於分析長時間執行的程式。執行後,它會記錄所有函式和執行時間。它非常強大,但有時有點難以解釋和處理。在下面的示例中,我們對下面的程式碼使用cProfile:
示例
def increment_global():
global x
x += 1
def taskofThread(lock):
for _ in range(50000):
lock.acquire()
increment_global()
lock.release()
def main():
global x
x = 0
lock = threading.Lock()
t1 = threading.Thread(target=taskofThread, args=(lock,))
t2 = threading.Thread(target= taskofThread, args=(lock,))
t1.start()
t2.start()
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))
上述程式碼儲存在thread_increment.py檔案中。現在,在命令列上使用cProfile執行程式碼,如下所示:
(base) D:\ProgramData>python -m cProfile thread_increment.py
x = 100000 after Iteration 0
x = 100000 after Iteration 1
x = 100000 after Iteration 2
x = 100000 after Iteration 3
x = 100000 after Iteration 4
3577 function calls (3522 primitive calls) in 1.688 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:103(release)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:143(__init__)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:147(__enter__)
… … … …
從上面的輸出可以看出,cProfile打印出所有呼叫的3577個函式,以及每個函式花費的時間以及它們被呼叫的次數。以下是我們在輸出中獲得的列:
ncalls – 這是呼叫的次數。
tottime – 這是在給定函式中花費的總時間。
percall – 它指的是tottime除以ncalls的商。
cumtime – 這是在此函式和所有子函式中花費的累積時間。對於遞迴函式來說,它甚至更準確。
percall – 它是cumtime除以原始呼叫的商。
filename:lineno(function) – 它基本上提供了每個函式的相應資料。
Python中的併發 - 執行緒池
假設我們必須為我們的多執行緒任務建立大量執行緒。由於可能存在許多效能問題,因此在計算上將是最昂貴的,因為過多的執行緒可能會導致吞吐量受限。我們可以透過建立執行緒池來解決這個問題。執行緒池可以定義為一組預例項化和空閒的執行緒,它們隨時準備接收工作。當我們需要執行大量任務時,建立執行緒池比為每個任務例項化新執行緒更可取。執行緒池可以管理大量執行緒的併發執行,如下所示:
如果執行緒池中的一個執行緒完成了執行,則可以重用該執行緒。
如果執行緒終止,將建立另一個執行緒來替換該執行緒。
Python模組 – concurrent.futures
Python標準庫包含concurrent.futures模組。此模組新增到Python 3.2中,為開發人員提供了一個高階介面來啟動非同步任務。它是在Python的threading和multiprocessing模組頂部的抽象層,用於提供使用執行緒池或程序執行任務的介面。
在接下來的部分中,我們將學習關於concurrent.futures模組的不同類的內容。
Executor類
Executor是concurrent.futures Python模組的抽象類。不能直接使用它,我們需要使用以下具體子類之一:
- ThreadPoolExecutor
- ProcessPoolExecutor
ThreadPoolExecutor – 一個具體的子類
它是Executor類的具體子類之一。該子類使用多執行緒,我們得到一個執行緒池來提交任務。此池將任務分配給可用的執行緒並安排它們執行。
如何建立一個ThreadPoolExecutor?
藉助於**concurrent.futures**模組及其具體的子類**Executor**,我們可以輕鬆地建立一個執行緒池。為此,我們需要用想要在池中建立的執行緒數來構造一個**ThreadPoolExecutor**。預設情況下,執行緒數為5。然後我們可以向執行緒池提交任務。當我們**submit()**一個任務時,我們會得到一個**Future**物件。Future物件有一個名為**done()**的方法,它指示future是否已完成。這意味著為該特定的future物件設定了一個值。當任務完成後,執行緒池執行器會將值設定到future物件。
示例
from concurrent.futures import ThreadPoolExecutor
from time import sleep
def task(message):
sleep(2)
return message
def main():
executor = ThreadPoolExecutor(5)
future = executor.submit(task, ("Completed"))
print(future.done())
sleep(2)
print(future.done())
print(future.result())
if __name__ == '__main__':
main()
輸出
False True Completed
在上面的例子中,已經構造了一個包含5個執行緒的**ThreadPoolExecutor**。然後將一個任務提交到執行緒池執行器,該任務將在發出訊息之前等待2秒。從輸出中可以看到,任務直到2秒後才完成,因此第一次呼叫**done()**將返回False。2秒後,任務完成,我們透過呼叫其上的**result()**方法獲得future的結果。
例項化ThreadPoolExecutor – 上下文管理器
例項化**ThreadPoolExecutor**的另一種方法是藉助上下文管理器。它的工作方式類似於上面示例中使用的方法。使用上下文管理器的主要優點是它在語法上看起來更好。可以使用以下程式碼進行例項化:
with ThreadPoolExecutor(max_workers = 5) as executor
示例
下面的例子取自Python文件。在這個例子中,首先需要匯入**concurrent.futures**模組。然後建立一個名為**load_url()**的函式,該函式將載入請求的URL。然後該函式建立**ThreadPoolExecutor**,池中有5個執行緒。**ThreadPoolExecutor**被用作上下文管理器。我們可以透過呼叫其上的**result()**方法獲得future的結果。
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout = timeout) as conn:
return conn.read()
with concurrent.futures.ThreadPoolExecutor(max_workers = 5) as executor:
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
輸出
以下是上面Python指令碼的輸出:
'http://some-made-up-domain.com/' generated an exception: <urlopen error [Errno 11004] getaddrinfo failed> 'http://www.foxnews.com/' page is 229313 bytes 'http://www.cnn.com/' page is 168933 bytes 'http://www.bbc.co.uk/' page is 283893 bytes 'http://europe.wsj.com/' page is 938109 bytes
Executor.map()函式的使用
Python的**map()**函式廣泛用於許多工中。其中一項任務是將某個函式應用於迭代物件中的每個元素。類似地,我們可以將迭代器的所有元素對映到一個函式,並將這些元素作為獨立的作業提交到我們的**ThreadPoolExecutor**。考慮以下Python指令碼示例,以瞭解該函式的工作原理。
示例
在下面的例子中,map函式用於將**square()**函式應用於values陣列中的每個值。
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import as_completed
values = [2,3,4,5]
def square(n):
return n * n
def main():
with ThreadPoolExecutor(max_workers = 3) as executor:
results = executor.map(square, values)
for result in results:
print(result)
if __name__ == '__main__':
main()
輸出
上面的Python指令碼生成以下輸出:
4 9 16 25
Python中的併發 - 程序池
程序池的建立和使用方式與我們建立和使用執行緒池的方式相同。程序池可以定義為一組預先例項化且處於空閒狀態的程序,它們隨時準備接收工作。當我們需要執行大量任務時,建立程序池比為每個任務例項化新程序更可取。
Python模組 – concurrent.futures
Python標準庫有一個名為**concurrent.futures**的模組。此模組是在Python 3.2中新增的,為開發人員提供了一個用於啟動非同步任務的高階介面。它是Python的threading和multiprocessing模組之上的一個抽象層,用於提供使用執行緒池或程序池執行任務的介面。
在接下來的章節中,我們將瞭解concurrent.futures模組的不同子類。
Executor類
**Executor**是**concurrent.futures** Python模組的抽象類。它不能直接使用,我們需要使用以下具體的子類之一:
- ThreadPoolExecutor
- ProcessPoolExecutor
ProcessPoolExecutor – 一個具體的子類
它是Executor類的具體子類之一。它使用多程序,我們得到一個用於提交任務的程序池。該池將任務分配給可用的程序並安排它們執行。
如何建立一個ProcessPoolExecutor?
藉助於**concurrent.futures**模組及其具體的子類**Executor**,我們可以輕鬆地建立一個程序池。為此,我們需要用想要在池中建立的程序數來構造一個**ProcessPoolExecutor**。預設情況下,程序數為5。之後將任務提交到程序池。
示例
我們現在考慮與建立執行緒池時使用的相同示例,唯一的區別是現在我們將使用**ProcessPoolExecutor**而不是**ThreadPoolExecutor**。
from concurrent.futures import ProcessPoolExecutor
from time import sleep
def task(message):
sleep(2)
return message
def main():
executor = ProcessPoolExecutor(5)
future = executor.submit(task, ("Completed"))
print(future.done())
sleep(2)
print(future.done())
print(future.result())
if __name__ == '__main__':
main()
輸出
False False Completed
在上面的例子中,已經構造了一個包含5個程序的Process**PoolExecutor**。然後將一個任務提交到程序池執行器,該任務將在發出訊息之前等待2秒。從輸出中可以看到,任務直到2秒後才完成,因此第一次呼叫**done()**將返回False。2秒後,任務完成,我們透過呼叫其上的**result()**方法獲得future的結果。
例項化ProcessPoolExecutor – 上下文管理器
例項化ProcessPoolExecutor的另一種方法是藉助上下文管理器。它的工作方式類似於上面示例中使用的方法。使用上下文管理器的主要優點是它在語法上看起來更好。可以使用以下程式碼進行例項化:
with ProcessPoolExecutor(max_workers = 5) as executor
示例
為了更好地理解,我們使用與建立執行緒池時相同的示例。在這個例子中,我們需要首先匯入**concurrent.futures**模組。然後建立一個名為**load_url()**的函式,該函式將載入請求的URL。然後建立**ProcessPoolExecutor**,池中有5個執行緒。Process**PoolExecutor**被用作上下文管理器。我們可以透過呼叫其上的**result()**方法獲得future的結果。
import concurrent.futures
from concurrent.futures import ProcessPoolExecutor
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout = timeout) as conn:
return conn.read()
def main():
with concurrent.futures.ProcessPoolExecutor(max_workers=5) as executor:
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
if __name__ == '__main__':
main()
輸出
上面的Python指令碼將生成以下輸出:
'http://some-made-up-domain.com/' generated an exception: <urlopen error [Errno 11004] getaddrinfo failed> 'http://www.foxnews.com/' page is 229476 bytes 'http://www.cnn.com/' page is 165323 bytes 'http://www.bbc.co.uk/' page is 284981 bytes 'http://europe.wsj.com/' page is 967575 bytes
Executor.map()函式的使用
Python的**map()**函式廣泛用於執行許多工。其中一項任務是將某個函式應用於迭代物件中的每個元素。類似地,我們可以將迭代器的所有元素對映到一個函式,並將這些元素作為獨立的作業提交到**ProcessPoolExecutor**。考慮以下Python指令碼示例以瞭解這一點。
示例
我們將考慮與使用**Executor.map()**函式建立執行緒池時相同的示例。在下面的示例中,map函式用於將**square()**函式應用於values陣列中的每個值。
from concurrent.futures import ProcessPoolExecutor
from concurrent.futures import as_completed
values = [2,3,4,5]
def square(n):
return n * n
def main():
with ProcessPoolExecutor(max_workers = 3) as executor:
results = executor.map(square, values)
for result in results:
print(result)
if __name__ == '__main__':
main()
輸出
上面的Python指令碼將生成以下輸出
4 9 16 25
何時使用ProcessPoolExecutor和ThreadPoolExecutor?
現在我們已經學習了兩個Executor類——ThreadPoolExecutor和ProcessPoolExecutor,我們需要知道何時使用哪個執行器。對於CPU密集型工作負載,我們需要選擇ProcessPoolExecutor;對於I/O密集型工作負載,我們需要選擇ThreadPoolExecutor。
如果我們使用**ProcessPoolExecutor**,那麼我們不需要擔心GIL,因為它使用多程序。此外,與**ThreadPoolExecution**相比,執行時間將更短。考慮以下Python指令碼示例以瞭解這一點。
示例
import time
import concurrent.futures
value = [8000000, 7000000]
def counting(n):
start = time.time()
while n > 0:
n -= 1
return time.time() - start
def main():
start = time.time()
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, time_taken in zip(value, executor.map(counting, value)):
print('Start: {} Time taken: {}'.format(number, time_taken))
print('Total time taken: {}'.format(time.time() - start))
if __name__ == '__main__':
main()
輸出
Start: 8000000 Time taken: 1.5509998798370361
Start: 7000000 Time taken: 1.3259999752044678
Total time taken: 2.0840001106262207
Example- Python script with ThreadPoolExecutor:
import time
import concurrent.futures
value = [8000000, 7000000]
def counting(n):
start = time.time()
while n > 0:
n -= 1
return time.time() - start
def main():
start = time.time()
with concurrent.futures.ThreadPoolExecutor() as executor:
for number, time_taken in zip(value, executor.map(counting, value)):
print('Start: {} Time taken: {}'.format(number, time_taken))
print('Total time taken: {}'.format(time.time() - start))
if __name__ == '__main__':
main()
輸出
Start: 8000000 Time taken: 3.8420000076293945 Start: 7000000 Time taken: 3.6010000705718994 Total time taken: 3.8480000495910645
從上面兩個程式的輸出中,我們可以看到使用**ProcessPoolExecutor**和**ThreadPoolExecutor**時的執行時間差異。
Python中的併發 - 多程序
在本章中,我們將更側重於多程序和多執行緒之間的比較。
多程序
它是在單個計算機系統中使用兩個或多個CPU單元。這是充分發揮硬體潛力的最佳方法,因為它可以利用計算機系統中可用的所有CPU核心。
多執行緒
它指的是CPU能夠透過併發執行多個執行緒來管理作業系統的使用。多執行緒的主要思想是透過將程序分成多個執行緒來實現並行性。
下表顯示了它們之間的一些重要區別:
| 多程序 | 多程式設計 |
|---|---|
| 多程序是指多個CPU同時處理多個程序。 | 多程式設計同時將多個程式保留在主記憶體中,並利用單個CPU併發執行它們。 |
| 它利用多個CPU。 | 它利用單個CPU。 |
| 它允許並行處理。 | 發生上下文切換。 |
| 處理作業所需時間更少。 | 處理作業所需時間更多。 |
| 它有助於更有效地利用計算機系統的裝置。 | 效率低於多程序。 |
| 通常更昂貴。 | 此類系統成本較低。 |
消除全域性直譯器鎖 (GIL) 的影響
在使用併發應用程式時,Python中存在一個名為**GIL(全域性直譯器鎖)**的限制。GIL不允許我們利用CPU的多個核心,因此我們可以說Python中沒有真正的執行緒。GIL是互斥鎖,它使事物執行緒安全。換句話說,我們可以說GIL阻止多個執行緒並行執行Python程式碼。一次只能由一個執行緒持有鎖,如果我們想要執行一個執行緒,則它必須首先獲取鎖。
透過使用多程序,我們可以有效地繞過GIL造成的限制:
透過使用多程序,我們正在利用多個程序的能力,因此我們正在利用GIL的多個例項。
因此,在任何時候都沒有限制在一個程式中執行一個執行緒的位元組碼。
在Python中啟動程序
可以使用以下三種方法在multiprocessing模組中啟動Python中的程序:
- fork
- spawn
- forkserver
使用fork建立程序
fork命令是UNIX中找到的標準命令。它用於建立稱為子程序的新程序。此子程序與稱為父程序的程序併發執行。這些子程序與其父程序也相同,並繼承父程序可用的所有資源。在使用fork建立程序時,使用以下系統呼叫:
**fork()** – 它通常在核心中實現的系統呼叫。它用於建立程序的副本。
**getpid()** – 此係統呼叫返回呼叫程序的程序ID (PID)。
示例
以下Python指令碼示例將幫助您瞭解如何建立新的子程序並獲取子程序和父程序的PID:
import os
def child():
n = os.fork()
if n > 0:
print("PID of Parent process is : ", os.getpid())
else:
print("PID of Child process is : ", os.getpid())
child()
輸出
PID of Parent process is : 25989 PID of Child process is : 25990
使用spawn建立程序
spawn意為啟動新的事物。因此,生成程序意味著父程序建立新的程序。父程序繼續非同步執行或等待子程序結束執行。按照以下步驟生成程序:
匯入multiprocessing模組。
建立程序物件。
透過呼叫**start()**方法啟動程序活動。
等待程序完成其工作並透過呼叫**join()**方法退出。
示例
以下Python指令碼示例有助於生成三個程序
import multiprocessing
def spawn_process(i):
print ('This is process: %s' %i)
return
if __name__ == '__main__':
Process_jobs = []
for i in range(3):
p = multiprocessing.Process(target = spawn_process, args = (i,))
Process_jobs.append(p)
p.start()
p.join()
輸出
This is process: 0 This is process: 1 This is process: 2
使用forkserver建立程序
forkserver機制僅適用於支援透過Unix管道傳遞檔案描述符的某些選定的UNIX平臺。考慮以下幾點,以瞭解forkserver機制的工作原理:
使用forkserver機制啟動新程序時,會例項化一個伺服器。
然後,伺服器接收命令並處理所有建立新程序的請求。
為了建立新程序,我們的Python程式將向Forkserver傳送請求,它將為我們建立一個程序。
最後,我們可以在程式中使用這個新建立的程序。
Python中的守護程序
Python的multiprocessing模組允許我們透過其daemonic選項擁有守護程序。守護程序或在後臺執行的程序遵循與守護執行緒類似的概念。要在後臺執行程序,我們需要將daemonic標誌設定為true。守護程序將在主程序執行期間繼續執行,並在完成其執行或主程式被終止後終止。
示例
這裡,我們使用與守護執行緒中相同的示例。唯一的區別是將模組從multithreading更改為multiprocessing並將daemonic標誌設定為true。但是,輸出會有所不同,如下所示:
import multiprocessing
import time
def nondaemonProcess():
print("starting my Process")
time.sleep(8)
print("ending my Process")
def daemonProcess():
while True:
print("Hello")
time.sleep(2)
if __name__ == '__main__':
nondaemonProcess = multiprocessing.Process(target = nondaemonProcess)
daemonProcess = multiprocessing.Process(target = daemonProcess)
daemonProcess.daemon = True
nondaemonProcess.daemon = False
daemonProcess.start()
nondaemonProcess.start()
輸出
starting my Process ending my Process
與守護執行緒生成的輸出相比,輸出有所不同,因為非守護模式下的程序有輸出。因此,守護程序在主程式結束後會自動結束,以避免執行程序的永續性。
終止Python中的程序
我們可以使用terminate()方法立即終止程序。我們將使用此方法立即終止在函式幫助下建立的子程序,該子程序在完成其執行之前。
示例
import multiprocessing
import time
def Child_process():
print ('Starting function')
time.sleep(5)
print ('Finished function')
P = multiprocessing.Process(target = Child_process)
P.start()
print("My Process has terminated, terminating main thread")
print("Terminating Child Process")
P.terminate()
print("Child Process successfully terminated")
輸出
My Process has terminated, terminating main thread Terminating Child Process Child Process successfully terminated
輸出顯示程式在建立子程序(藉助Child_process()函式建立)執行之前終止。這意味著子程序已成功終止。
識別Python中的當前程序
作業系統中的每個程序都有一個稱為PID的程序標識。在Python中,我們可以藉助以下命令找出當前程序的PID:
import multiprocessing print(multiprocessing.current_process().pid)
示例
以下Python指令碼示例有助於找出主程序的PID以及子程序的PID:
import multiprocessing
import time
def Child_process():
print("PID of Child Process is: {}".format(multiprocessing.current_process().pid))
print("PID of Main process is: {}".format(multiprocessing.current_process().pid))
P = multiprocessing.Process(target=Child_process)
P.start()
P.join()
輸出
PID of Main process is: 9401 PID of Child Process is: 9402
在子類中使用程序
我們可以透過子類化threading.Thread類來建立執行緒。此外,我們還可以透過子類化multiprocessing.Process類來建立程序。要在子類中使用程序,我們需要考慮以下幾點:
我們需要定義Process類的新子類。
我們需要重寫_init_(self [,args] )類。
我們需要重寫run(self [,args] )方法來實現Process的功能。
我們需要透過呼叫start()方法來啟動程序。
示例
import multiprocessing
class MyProcess(multiprocessing.Process):
def run(self):
print ('called run method in process: %s' %self.name)
return
if __name__ == '__main__':
jobs = []
for i in range(5):
P = MyProcess()
jobs.append(P)
P.start()
P.join()
輸出
called run method in process: MyProcess-1 called run method in process: MyProcess-2 called run method in process: MyProcess-3 called run method in process: MyProcess-4 called run method in process: MyProcess-5
Python多程序模組 – Pool類
如果我們在Python應用程式中討論簡單的並行處理任務,那麼multiprocessing模組為我們提供了Pool類。Pool類的以下方法可用於在我們主程式中啟動多個子程序。
apply()方法
此方法類似於.ThreadPoolExecutor的.submit()方法。它會阻塞,直到結果準備好。
apply_async()方法
當我們需要並行執行任務時,我們需要使用apply_async()方法將任務提交到池中。這是一個非同步操作,在所有子程序執行完畢之前不會鎖定主執行緒。
map()方法
與apply()方法一樣,它也會阻塞,直到結果準備好。它等效於內建的map()函式,該函式將可迭代資料分成多個塊,並將其作為單獨的任務提交給程序池。
map_async()方法
它是map()方法的變體,就像apply_async()之於apply()方法一樣。它返回一個結果物件。當結果準備好時,會將一個可呼叫物件應用於它。可呼叫物件必須立即完成;否則,處理結果的執行緒將被阻塞。
示例
以下示例將幫助您實現一個程序池來執行並行執行。透過multiprocessing.Pool方法應用square()函式,已經執行了簡單的數字平方計算。然後使用pool.map()提交了5個數字(輸入是從0到4的整數列表)。結果將儲存在p_outputs中並打印出來。
def square(n):
result = n*n
return result
if __name__ == '__main__':
inputs = list(range(5))
p = multiprocessing.Pool(processes = 4)
p_outputs = pool.map(function_square, inputs)
p.close()
p.join()
print ('Pool :', p_outputs)
輸出
Pool : [0, 1, 4, 9, 16]
程序間通訊
程序間通訊是指程序之間的資料交換。為了開發並行應用程式,需要在程序之間交換資料。下圖顯示了多個子程序之間同步的各種通訊機制:
各種通訊機制
在本節中,我們將學習各種通訊機制。這些機制描述如下:
佇列
佇列可以與多程序程式一起使用。multiprocessing模組的Queue類類似於Queue.Queue類。因此,可以使用相同的API。Multiprocessing.Queue為我們在程序之間提供了一種執行緒和程序安全的FIFO(先進先出)通訊機制。
示例
以下是從python官方文件中獲取的一個關於multiprocessing的簡單示例,用於理解multiprocessing的Queue類的概念。
from multiprocessing import Process, Queue import queue import random def f(q): q.put([42, None, 'hello']) def main(): q = Queue() p = Process(target = f, args = (q,)) p.start() print (q.get()) if __name__ == '__main__': main()
輸出
[42, None, 'hello']
管道
它是一種資料結構,用於在多程序程式中的程序之間進行通訊。Pipe()函式返回一對由管道連線的連線物件,預設情況下是雙工(雙向)的。它的工作方式如下:
它返回一對連線物件,它們表示管道的兩端。
每個物件都有兩個方法——send()和recv(),用於程序間通訊。
示例
以下是從python官方文件中獲取的一個關於multiprocessing的簡單示例,用於理解multiprocessing的Pipe()函式的概念。
from multiprocessing import Process, Pipe def f(conn): conn.send([42, None, 'hello']) conn.close() if __name__ == '__main__': parent_conn, child_conn = Pipe() p = Process(target = f, args = (child_conn,)) p.start() print (parent_conn.recv()) p.join()
輸出
[42, None, 'hello']
管理器
Manager是multiprocessing模組的一個類,它提供了一種協調所有使用者之間共享資訊的方法。管理器物件控制一個伺服器程序,該程序管理共享物件並允許其他程序操作它們。換句話說,管理器提供了一種建立可以在不同程序之間共享的資料的方法。以下是管理器物件的不同的屬性:
管理器的主要屬性是控制一個伺服器程序,該程序管理共享物件。
另一個重要的屬性是在任何程序修改共享物件時更新所有共享物件。
示例
以下是一個示例,它使用管理器物件在伺服器程序中建立列表記錄,然後在該列表中新增新記錄。
import multiprocessing
def print_records(records):
for record in records:
print("Name: {0}\nScore: {1}\n".format(record[0], record[1]))
def insert_record(record, records):
records.append(record)
print("A New record is added\n")
if __name__ == '__main__':
with multiprocessing.Manager() as manager:
records = manager.list([('Computers', 1), ('Histoty', 5), ('Hindi',9)])
new_record = ('English', 3)
p1 = multiprocessing.Process(target = insert_record, args = (new_record, records))
p2 = multiprocessing.Process(target = print_records, args = (records,))
p1.start()
p1.join()
p2.start()
p2.join()
輸出
A New record is added Name: Computers Score: 1 Name: Histoty Score: 5 Name: Hindi Score: 9 Name: English Score: 3
管理器中的名稱空間概念
Manager類帶有名稱空間的概念,這是一種在多個程序之間共享多個屬性的快速方法。名稱空間沒有任何可以呼叫的公共方法,但它們具有可寫屬性。
示例
以下Python指令碼示例幫助我們利用名稱空間在主程序和子程序之間共享資料:
import multiprocessing
def Mng_NaSp(using_ns):
using_ns.x +=5
using_ns.y *= 10
if __name__ == '__main__':
manager = multiprocessing.Manager()
using_ns = manager.Namespace()
using_ns.x = 1
using_ns.y = 1
print ('before', using_ns)
p = multiprocessing.Process(target = Mng_NaSp, args = (using_ns,))
p.start()
p.join()
print ('after', using_ns)
輸出
before Namespace(x = 1, y = 1) after Namespace(x = 6, y = 10)
Ctypes-Array和Value
Multiprocessing模組提供Array和Value物件用於在共享記憶體對映中儲存資料。Array是從共享記憶體分配的ctypes陣列,Value是從共享記憶體分配的ctypes物件。
首先,從multiprocessing匯入Process、Value、Array。
示例
以下Python指令碼是從python文件中獲取的一個示例,用於利用Ctypes Array和Value在程序之間共享一些資料。
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
if __name__ == '__main__':
num = Value('d', 0.0)
arr = Array('i', range(10))
p = Process(target = f, args = (num, arr))
p.start()
p.join()
print (num.value)
print (arr[:])
輸出
3.1415927 [0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
通訊順序程序 (CSP)
CSP用於說明系統與具有併發模型的其他系統的互動。CSP是一個編寫併發程式或透過訊息傳遞進行程式設計的框架,因此它對於描述併發性非常有效。
Python庫 – PyCSP
為了實現CSP中發現的核心原語,Python有一個名為PyCSP的庫。它使實現非常簡短易讀,因此很容易理解。以下是PyCSP的基本程序網路:

在上面的PyCSP程序網路中,有兩個程序——Process1和Process 2。這些程序透過兩個通道——通道1和通道2——傳遞訊息進行通訊。
安裝PyCSP
藉助以下命令,我們可以安裝Python庫PyCSP:
pip install PyCSP
示例
以下Python指令碼是一個簡單的示例,用於並行執行兩個程序。這是藉助PyCSP python庫完成的:
from pycsp.parallel import *
import time
@process
def P1():
time.sleep(1)
print('P1 exiting')
@process
def P2():
time.sleep(1)
print('P2 exiting')
def main():
Parallel(P1(), P2())
print('Terminating')
if __name__ == '__main__':
main()
在上面的指令碼中,建立了兩個函式,即P1和P2,然後用@process裝飾器將它們轉換為程序。
輸出
P2 exiting P1 exiting Terminating
事件驅動程式設計
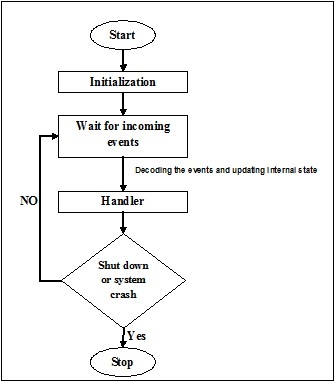
事件驅動程式設計關注事件。最終,程式的流程取決於事件。到目前為止,我們一直在處理順序或並行執行模型,但是具有事件驅動程式設計概念的模型稱為非同步模型。事件驅動程式設計依賴於一個始終在監聽新傳入事件的事件迴圈。事件驅動程式設計的工作取決於事件。一旦事件迴圈執行,事件就決定執行什麼以及按什麼順序執行。以下流程圖將幫助您理解其工作原理:
Python模組 – Asyncio
Asyncio模組新增到Python 3.4中,它提供編寫使用協程的單執行緒併發程式碼的基礎設施。以下是Asyncio模組使用的不同概念:
事件迴圈
事件迴圈是一種處理計算程式碼中所有事件的功能。在整個程式執行期間,它以迴圈方式執行,並跟蹤傳入事件和事件的執行。Asyncio模組允許每個程序只有一個事件迴圈。以下是Asyncio模組提供的一些用於管理事件迴圈的方法:
loop = get_event_loop() − 此方法將提供當前上下文的事件迴圈。
loop.call_later(time_delay,callback,argument) − 此方法安排在給定的time_delay秒後呼叫的回撥。
loop.call_soon(callback,argument) − 此方法安排儘快呼叫的回撥。回撥在call_soon()返回並且控制返回到事件迴圈後呼叫。
loop.time() − 此方法用於根據事件迴圈的內部時鐘返回當前時間。
asyncio.set_event_loop() − 此方法將當前上下文的事件迴圈設定為loop。
asyncio.new_event_loop() − 此方法將建立並返回一個新的事件迴圈物件。
loop.run_forever() − 此方法將執行,直到呼叫stop()方法。
示例
以下事件迴圈示例使用get_event_loop()方法列印hello world。此示例取自Python官方文件。
import asyncio
def hello_world(loop):
print('Hello World')
loop.stop()
loop = asyncio.get_event_loop()
loop.call_soon(hello_world, loop)
loop.run_forever()
loop.close()
輸出
Hello World
期物 (Futures)
這與concurrent.futures.Future類相容,該類表示尚未完成的計算。asyncio.futures.Future和concurrent.futures.Future之間存在以下區別:
result()和exception()方法不帶超時引數,並在期物尚未完成時引發異常。
使用add_done_callback()註冊的回撥始終透過事件迴圈的call_soon()呼叫。
asyncio.futures.Future類與concurrent.futures包中的wait()和as_completed()函式不相容。
示例
以下是一個示例,將幫助您瞭解如何使用asyncio.futures.future類。
import asyncio
async def Myoperation(future):
await asyncio.sleep(2)
future.set_result('Future Completed')
loop = asyncio.get_event_loop()
future = asyncio.Future()
asyncio.ensure_future(Myoperation(future))
try:
loop.run_until_complete(future)
print(future.result())
finally:
loop.close()
輸出
Future Completed
協程
Asyncio 中的協程概念類似於 threading 模組下標準 Thread 物件的概念。這是子例程概念的泛化。協程可以在執行期間暫停,以便等待外部處理,並在外部處理完成時從其停止的位置返回。以下兩種方法可以幫助我們實現協程:
async def function()
這是在 Asyncio 模組下實現協程的一種方法。下面是一個 Python 指令碼:
import asyncio
async def Myoperation():
print("First Coroutine")
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(Myoperation())
finally:
loop.close()
輸出
First Coroutine
@asyncio.coroutine 裝飾器
實現協程的另一種方法是使用帶有 @asyncio.coroutine 裝飾器的生成器。下面是一個 Python 指令碼:
import asyncio
@asyncio.coroutine
def Myoperation():
print("First Coroutine")
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(Myoperation())
finally:
loop.close()
輸出
First Coroutine
任務 (Tasks)
Asyncio 模組的這個子類負責以並行方式在事件迴圈中執行協程。下面的 Python 指令碼是一個並行處理一些任務的示例。
import asyncio
import time
async def Task_ex(n):
time.sleep(1)
print("Processing {}".format(n))
async def Generator_task():
for i in range(10):
asyncio.ensure_future(Task_ex(i))
int("Tasks Completed")
asyncio.sleep(2)
loop = asyncio.get_event_loop()
loop.run_until_complete(Generator_task())
loop.close()
輸出
Tasks Completed Processing 0 Processing 1 Processing 2 Processing 3 Processing 4 Processing 5 Processing 6 Processing 7 Processing 8 Processing 9
傳輸 (Transports)
Asyncio 模組提供傳輸類來實現各種型別的通訊。這些類不是執行緒安全的,並且在建立通訊通道後始終與協議例項配對。
以下是繼承自 BaseTransport 的不同型別的傳輸:
ReadTransport - 這是一個只讀傳輸的介面。
WriteTransport - 這是一個只寫傳輸的介面。
DatagramTransport - 這是一個用於傳送資料的介面。
BaseSubprocessTransport - 類似於 BaseTransport 類。
以下是 BaseTransport 類的五個不同的方法,這些方法隨後在四種傳輸型別中都是瞬態的:
close() - 它關閉傳輸。
is_closing() - 如果傳輸正在關閉或已經關閉,此方法將返回 true。
get_extra_info(name, default = none) - 這將給我們一些關於傳輸的額外資訊。
get_protocol() - 此方法將返回當前協議。
協議 (Protocols)
Asyncio 模組提供基類,您可以對其進行子類化以實現您的網路協議。這些類與傳輸一起使用;協議解析傳入資料並請求寫入傳出資料,而傳輸負責實際的 I/O 和緩衝。以下是協議的三個類:
Protocol - 這是用於實現與 TCP 和 SSL 傳輸一起使用的流協議的基類。
DatagramProtocol - 這是用於實現與 UDP 傳輸一起使用的資料報協議的基類。
SubprocessProtocol - 這是用於實現透過一組單向管道與子程序通訊的協議的基類。
響應式程式設計
響應式程式設計是一種處理資料流和更改傳播的程式設計範例。這意味著當一個元件發出資料流時,更改將透過響應式程式設計庫傳播到其他元件。更改的傳播將持續到到達最終接收器為止。事件驅動程式設計和響應式程式設計的區別在於,事件驅動程式設計圍繞事件展開,而響應式程式設計圍繞資料展開。
ReactiveX 或 RX 用於響應式程式設計
ReactiveX 或 Reactive Extension 是響應式程式設計最著名的實現。ReactiveX 的工作依賴於以下兩個類:
Observable 類
此類是資料流或事件的來源,它打包傳入資料,以便資料可以從一個執行緒傳遞到另一個執行緒。在某些觀察者訂閱它之前,它不會提供資料。
Observer 類
此類使用Observable發出的資料流。可以有多個觀察者使用 Observable,每個觀察者將接收發出的每個資料項。觀察者可以透過訂閱 Observable 來接收三種類型的事件:
on_next() 事件 - 這意味著資料流中有一個元素。
on_completed() 事件 - 這意味著發射結束,不再有專案。
on_error() 事件 - 這也意味著發射結束,但在Observable丟擲錯誤的情況下。
RxPY – 用於響應式程式設計的 Python 模組
RxPY 是一個可用於響應式程式設計的 Python 模組。我們需要確保安裝了該模組。可以使用以下命令安裝 RxPY 模組:
pip install RxPY
示例
下面是一個 Python 指令碼,它使用RxPY模組及其類Observable和Observe進行響應式程式設計。基本上有兩個類:
get_strings() - 用於從觀察者獲取字串。
PrintObserver() - 用於從觀察者列印字串。它使用觀察者類的所有三個事件。它還使用 subscribe() 類。
from rx import Observable, Observer
def get_strings(observer):
observer.on_next("Ram")
observer.on_next("Mohan")
observer.on_next("Shyam")
observer.on_completed()
class PrintObserver(Observer):
def on_next(self, value):
print("Received {0}".format(value))
def on_completed(self):
print("Finished")
def on_error(self, error):
print("Error: {0}".format(error))
source = Observable.create(get_strings)
source.subscribe(PrintObserver())
輸出
Received Ram Received Mohan Received Shyam Finished
用於響應式程式設計的 PyFunctional 庫
PyFunctional是另一個可用於響應式程式設計的 Python 庫。它使我們能夠使用 Python 程式語言建立函式式程式。它很有用,因為它允許我們使用鏈式函式運算子建立資料管道。
RxPY 和 PyFunctional 之間的區別
這兩個庫都用於響應式程式設計,並以類似的方式處理流,但它們之間的主要區別取決於資料的處理方式。RxPY處理系統中的資料和事件,而PyFunctional專注於使用函數語言程式設計範例轉換資料。
安裝 PyFunctional 模組
在使用此模組之前,我們需要安裝它。可以使用 pip 命令安裝它,如下所示:
pip install pyfunctional
示例
以下示例使用PyFunctional模組及其seq類,該類充當流物件,我們可以使用它來迭代和操作。在這個程式中,它使用 lambda 函式將序列對映為每個值的雙倍,然後過濾 x 大於 4 的值,最後將序列簡化為所有剩餘值的總和。
from functional import seq
result = seq(1,2,3).map(lambda x: x*2).filter(lambda x: x > 4).reduce(lambda x, y: x + y)
print ("Result: {}".format(result))
輸出
Result: 6