- AWK 教程
- AWK - 首頁
- AWK - 概述
- AWK - 環境
- AWK - 工作流程
- AWK - 基本語法
- AWK - 基本示例
- AWK - 內建變數
- AWK - 運算子
- AWK - 正則表示式
- AWK - 陣列
- AWK - 控制流
- AWK - 迴圈
- AWK - 內建函式
- AWK - 使用者自定義函式
- AWK - 輸出重定向
- AWK - 美化輸出
- AWK 有用資源
- AWK 快速指南
- AWK - 有用資源
- AWK - 討論
AWK 快速指南
AWK - 概述
AWK 是一種解釋型程式語言。它非常強大,專為文字處理而設計。它的名稱來源於其作者的姓氏——**Alfred Aho、Peter Weinberger 和 Brian Kernighan。**
GNU/Linux 發行的 AWK 版本由自由軟體基金會 (FSF) 編寫和維護;它通常被稱為**GNU AWK**。
AWK 的型別
以下是 AWK 的變體——
AWK - 來自 AT&T 實驗室的原始 AWK。
NAWK - 來自 AT&T 實驗室的更新和改進版本的 AWK。
GAWK - 它就是 GNU AWK。所有 GNU/Linux 發行版都附帶 GAWK。它與 AWK 和 NAWK 完全相容。
AWK 的典型用途
AWK 可以完成無數的任務。下面列出了一些——
- 文字處理,
- 生成格式化的文字報表,
- 執行算術運算,
- 執行字串操作,等等。
AWK - 環境
本章介紹如何在 GNU/Linux 系統上設定 AWK 環境。
使用包管理器安裝
通常,AWK 在大多數 GNU/Linux 發行版上預設可用。您可以使用which命令檢查它是否在您的系統上存在。如果您沒有 AWK,則可以使用高階軟體包工具(APT)包管理器在基於 Debian 的 GNU/Linux 上安裝它,如下所示——
[jeryy]$ sudo apt-get update [jeryy]$ sudo apt-get install gawk
類似地,要在基於 RPM 的 GNU/Linux 上安裝 AWK,請使用 Yellowdog Updator Modifier yum 包管理器,如下所示——
[root]# yum install gawk
安裝後,確保可以透過命令列訪問 AWK。
[jerry]$ which awk
執行上述程式碼後,您將獲得以下結果——
/usr/bin/awk
從原始碼安裝
由於 GNU AWK 是 GNU 專案的一部分,因此其原始碼可免費下載。我們已經瞭解瞭如何使用包管理器安裝 AWK。現在讓我們瞭解如何從其原始碼安裝 AWK。
以下安裝適用於任何 GNU/Linux 軟體,以及大多數其他免費提供的程式。以下是安裝步驟——
步驟 1 - 從可靠的地方下載原始碼。命令列實用程式wget用於此目的。
[jerry]$ wget http://ftp.gnu.org/gnu/gawk/gawk-4.1.1.tar.xz
步驟 2 - 解壓縮並提取下載的原始碼。
[jerry]$ tar xvf gawk-4.1.1.tar.xz
步驟 3 - 進入目錄並執行配置。
[jerry]$ ./configure
步驟 4 - 配置成功完成後,將生成 Makefile。要編譯原始碼,請發出make命令。
[jerry]$ make
步驟 5 - 您可以執行測試套件以確保構建是乾淨的。這是一個可選步驟。
[jerry]$ make check
步驟 6 - 最後,安裝 AWK。確保您具有超級使用者許可權。
[jerry]$ sudo make install
就是這樣!您已成功編譯並安裝了 AWK。透過執行awk命令來驗證它,如下所示——
[jerry]$ which awk
執行此程式碼後,您將獲得以下結果——
/usr/bin/awk
AWK - 工作流程
要成為一名專家級的 AWK 程式設計師,您需要了解其內部工作原理。AWK 遵循簡單的流程——讀取、執行和重複。下圖描述了 AWK 的工作流程——
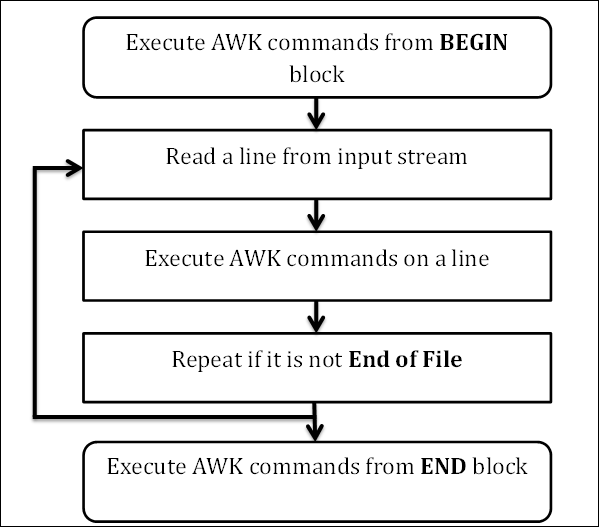
讀取
AWK 從輸入流(檔案、管道或 stdin)讀取一行並將其儲存在記憶體中。
執行
所有 AWK 命令都按順序應用於輸入。預設情況下,AWK 對每一行執行命令。我們可以透過提供模式來限制這一點。
重複
此過程重複,直到檔案到達其末尾。
程式結構
現在讓我們瞭解 AWK 的程式結構。
BEGIN 塊
BEGIN 塊的語法如下——
語法
BEGIN {awk-commands}
BEGIN 塊在程式啟動時執行。它只執行一次。這是初始化變數的好地方。BEGIN 是 AWK 關鍵字,因此它必須大寫。請注意,此塊是可選的。
主體塊
主體塊的語法如下——
語法
/pattern/ {awk-commands}
主體塊將 AWK 命令應用於每一行輸入。預設情況下,AWK 對每一行執行命令。我們可以透過提供模式來限制這一點。請注意,主體塊沒有關鍵字。
END 塊
END 塊的語法如下——
語法
END {awk-commands}
END 塊在程式結束時執行。END 是 AWK 關鍵字,因此它必須大寫。請注意,此塊是可選的。
讓我們建立一個名為marks.txt的檔案,其中包含學號、學生姓名、科目名稱和獲得的成績。
1) Amit Physics 80 2) Rahul Maths 90 3) Shyam Biology 87 4) Kedar English 85 5) Hari History 89
現在讓我們使用 AWK 指令碼顯示帶有標題的檔案內容。
示例
[jerry]$ awk 'BEGIN{printf "Sr No\tName\tSub\tMarks\n"} {print}' marks.txt
執行此程式碼時,它會生成以下結果——
輸出
Sr No Name Sub Marks 1) Amit Physics 80 2) Rahul Maths 90 3) Shyam Biology 87 4) Kedar English 85 5) Hari History 89
在開始時,AWK 從 BEGIN 塊列印標題。然後在主體塊中,它從檔案中讀取一行並執行 AWK 的 print 命令,該命令只是將內容列印到標準輸出流。此過程重複,直到檔案到達末尾。
AWK - 基本語法
AWK 使用簡單。我們可以直接從命令列或以包含 AWK 命令的文字檔案的形式提供 AWK 命令。
AWK 命令列
我們可以在命令列中使用單引號指定 AWK 命令,如下所示——
awk [options] file ...
示例
考慮一個名為marks.txt的文字檔案,其內容如下——
1) Amit Physics 80 2) Rahul Maths 90 3) Shyam Biology 87 4) Kedar English 85 5) Hari History 89
讓我們使用 AWK 顯示檔案的完整內容,如下所示——
示例
[jerry]$ awk '{print}' marks.txt
執行此程式碼後,您將獲得以下結果——
輸出
1) Amit Physics 80 2) Rahul Maths 90 3) Shyam Biology 87 4) Kedar English 85 5) Hari History 89
AWK 程式檔案
我們可以在指令碼檔案中提供 AWK 命令,如下所示——
awk [options] -f file ....
首先,建立一個名為command.awk的文字檔案,其中包含以下 AWK 命令——
{print}
現在我們可以指示 AWK 從文字檔案讀取命令並執行操作。在這裡,我們實現了與上述示例相同的結果。
示例
[jerry]$ awk -f command.awk marks.txt
執行此程式碼後,您將獲得以下結果——
輸出
1) Amit Physics 80 2) Rahul Maths 90 3) Shyam Biology 87 4) Kedar English 85 5) Hari History 89
AWK 標準選項
AWK 支援以下標準選項,這些選項可以從命令列提供。
-v 選項
此選項將值賦給變數。它允許在程式執行之前進行賦值。以下示例描述了 -v 選項的用法。
示例
[jerry]$ awk -v name=Jerry 'BEGIN{printf "Name = %s\n", name}'
執行此程式碼後,您將獲得以下結果——
輸出
Name = Jerry
--dump-variables[=file] 選項
它將全域性變數及其最終值的排序列表列印到檔案中。預設檔案為awkvars.out。
示例
[jerry]$ awk --dump-variables '' [jerry]$ cat awkvars.out
執行上述程式碼後,您將獲得以下結果——
輸出
ARGC: 1 ARGIND: 0 ARGV: array, 1 elements BINMODE: 0 CONVFMT: "%.6g" ERRNO: "" FIELDWIDTHS: "" FILENAME: "" FNR: 0 FPAT: "[^[:space:]]+" FS: " " IGNORECASE: 0 LINT: 0 NF: 0 NR: 0 OFMT: "%.6g" OFS: " " ORS: "\n" RLENGTH: 0 RS: "\n" RSTART: 0 RT: "" SUBSEP: "\034" TEXTDOMAIN: "messages"
--help 選項
此選項在標準輸出上列印幫助訊息。
示例
[jerry]$ awk --help
執行此程式碼後,您將獲得以下結果——
輸出
Usage: awk [POSIX or GNU style options] -f progfile [--] file ... Usage: awk [POSIX or GNU style options] [--] 'program' file ... POSIX options : GNU long options: (standard) -f progfile --file=progfile -F fs --field-separator=fs -v var=val --assign=var=val Short options : GNU long options: (extensions) -b --characters-as-bytes -c --traditional -C --copyright -d[file] --dump-variables[=file] -e 'program-text' --source='program-text' -E file --exec=file -g --gen-pot -h --help -L [fatal] --lint[=fatal] -n --non-decimal-data -N --use-lc-numeric -O --optimize -p[file] --profile[=file] -P --posix -r --re-interval -S --sandbox -t --lint-old -V --version
--lint[=fatal] 選項
此選項啟用對不可移植或可疑結構的檢查。當提供引數fatal時,它將警告訊息視為錯誤。以下示例演示了這一點——
示例
[jerry]$ awk --lint '' /bin/ls
執行此程式碼後,您將獲得以下結果——
輸出
awk: cmd. line:1: warning: empty program text on command line awk: cmd. line:1: warning: source file does not end in newline awk: warning: no program text at all!
--posix 選項
此選項開啟嚴格的 POSIX 相容性,其中所有通用和 gawk 特定的擴充套件都被停用。
--profile[=file] 選項
此選項在檔案中生成程式的漂亮列印版本。預設檔案為awkprof.out。以下簡單示例說明了這一點——
示例
[jerry]$ awk --profile 'BEGIN{printf"---|Header|--\n"} {print}
END{printf"---|Footer|---\n"}' marks.txt > /dev/null
[jerry]$ cat awkprof.out
執行此程式碼後,您將獲得以下結果——
輸出
# gawk profile, created Sun Oct 26 19:50:48 2014
# BEGIN block(s)
BEGIN {
printf "---|Header|--\n"
}
# Rule(s) {
print $0
}
# END block(s)
END {
printf "---|Footer|---\n"
}
--traditional 選項
此選項停用所有 gawk 特定的擴充套件。
--version 選項
此選項顯示 AWK 程式的版本資訊。
示例
[jerry]$ awk --version
執行此程式碼時,它會生成以下結果——
輸出
GNU Awk 4.0.1 Copyright (C) 1989, 1991-2012 Free Software Foundation.
AWK - 基本示例
本章介紹了一些有用的 AWK 命令及其相應的示例。考慮一個名為marks.txt的文字檔案,其內容如下——
1) Amit Physics 80 2) Rahul Maths 90 3) Shyam Biology 87 4) Kedar English 85 5) Hari History 89
列印列或欄位
您可以指示 AWK 僅列印輸入欄位中的某些列。以下示例演示了這一點——
示例
[jerry]$ awk '{print $3 "\t" $4}' marks.txt
執行此程式碼後,您將獲得以下結果——
輸出
Physics 80 Maths 90 Biology 87 English 85 History 89
在marks.txt檔案中,第三列包含科目名稱,第四列包含特定科目中獲得的成績。讓我們使用 AWK print 命令列印這兩列。在上面的示例中,$3 和 $4分別表示輸入記錄中的第三和第四個欄位。
列印所有行
預設情況下,AWK 列印與模式匹配的所有行。
示例
[jerry]$ awk '/a/ {print $0}' marks.txt
執行此程式碼後,您將獲得以下結果——
輸出
2) Rahul Maths 90 3) Shyam Biology 87 4) Kedar English 85 5) Hari History 89
在上面的示例中,我們正在搜尋模式a。當模式匹配成功時,它會執行主體塊中的命令。在沒有主體塊的情況下——將採取預設操作,即列印記錄。因此,以下命令產生相同的結果——
示例
[jerry]$ awk '/a/' marks.txt
按模式列印列
當模式匹配成功時,AWK 預設列印整個記錄。但是您可以指示 AWK 僅列印某些欄位。例如,以下示例在模式匹配成功時列印第三和第四個欄位。
示例
[jerry]$ awk '/a/ {print $3 "\t" $4}' marks.txt
執行此程式碼後,您將獲得以下結果——
輸出
Maths 90 Biology 87 English 85 History 89
按任意順序列印列
您可以按任意順序列印列。例如,以下示例列印第四列,然後列印第三列。
示例
[jerry]$ awk '/a/ {print $4 "\t" $3}' marks.txt
執行上述程式碼後,您將獲得以下結果——
輸出
90 Maths 87 Biology 85 English 89 History
計算和列印匹配的模式
讓我們看一個可以計算和列印模式匹配成功行數的示例。
示例
[jerry]$ awk '/a/{++cnt} END {print "Count = ", cnt}' marks.txt
執行此程式碼後,您將獲得以下結果——
輸出
Count = 4
在此示例中,當模式匹配成功時,我們遞增計數器的值,並在 END 塊中列印此值。請注意,與其他程式語言不同,在使用變數之前不需要宣告它。
列印超過 18 個字元的行
讓我們只打印包含超過 18 個字元的行。
示例
[jerry]$ awk 'length($0) > 18' marks.txt
執行此程式碼後,您將獲得以下結果——
輸出
3) Shyam Biology 87 4) Kedar English 85
AWK 提供了一個內建的length函式,該函式返回字串的長度。$0變數儲存整行,在沒有主體塊的情況下,將採取預設操作,即列印操作。因此,如果一行超過 18 個字元,則比較結果為真,並且該行將被列印。
AWK - 內建變數
AWK 提供了一些內建變數。它們在編寫 AWK 指令碼時起著重要作用。本章演示了內建變數的用法。
標準 AWK 變數
下面討論標準 AWK 變數。
ARGC
它表示在命令列中提供的引數數量。
示例
[jerry]$ awk 'BEGIN {print "Arguments =", ARGC}' One Two Three Four
執行此程式碼後,您將獲得以下結果——
輸出
Arguments = 5
但是為什麼 AWK 顯示 5 而您只傳遞了 4 個引數呢?只需檢查以下示例即可消除您的疑問。
ARGV
它是一個儲存命令列引數的陣列。陣列的有效索引範圍從 0 到 ARGC-1。
示例
[jerry]$ awk 'BEGIN {
for (i = 0; i < ARGC - 1; ++i) {
printf "ARGV[%d] = %s\n", i, ARGV[i]
}
}' one two three four
執行此程式碼後,您將獲得以下結果——
輸出
ARGV[0] = awk ARGV[1] = one ARGV[2] = two ARGV[3] = three
CONVFMT
它表示數字的轉換格式。其預設值為%.6g。
示例
[jerry]$ awk 'BEGIN { print "Conversion Format =", CONVFMT }'
執行此程式碼後,您將獲得以下結果——
輸出
Conversion Format = %.6g
ENVIRON
它是一個環境變數的關聯陣列。
示例
[jerry]$ awk 'BEGIN { print ENVIRON["USER"] }'
執行此程式碼後,您將獲得以下結果——
輸出
jerry
要查詢其他環境變數的名稱,請使用env命令。
FILENAME
它表示當前檔名。
示例
[jerry]$ awk 'END {print FILENAME}' marks.txt
執行此程式碼後,您將獲得以下結果——
輸出
marks.txt
請注意,FILENAME 在 BEGIN 塊中未定義。
FS
它表示(輸入)欄位分隔符,其預設值為空格。您也可以使用-F命令列選項更改它。
示例
[jerry]$ awk 'BEGIN {print "FS = " FS}' | cat -vte
執行此程式碼後,您將獲得以下結果——
輸出
FS = $
NF
它表示當前記錄中的欄位數。例如,以下示例僅列印包含兩個以上欄位的行。
示例
[jerry]$ echo -e "One Two\nOne Two Three\nOne Two Three Four" | awk 'NF > 2'
執行此程式碼後,您將獲得以下結果——
輸出
One Two Three One Two Three Four
NR
它表示當前記錄的編號。例如,以下示例如果當前記錄編號小於 3,則列印該記錄。
示例
[jerry]$ echo -e "One Two\nOne Two Three\nOne Two Three Four" | awk 'NR < 3'
執行此程式碼後,您將獲得以下結果——
輸出
One Two One Two Three
FNR
它類似於 NR,但相對於當前檔案。當 AWK 操作多個檔案時,它很有用。FNR 的值在新的檔案中重置。
OFMT
它表示輸出格式數字,其預設值為%.6g。
示例
[jerry]$ awk 'BEGIN {print "OFMT = " OFMT}'
執行此程式碼後,您將獲得以下結果——
輸出
OFMT = %.6g
OFS
它表示輸出欄位分隔符,其預設值為空格。
示例
[jerry]$ awk 'BEGIN {print "OFS = " OFS}' | cat -vte
執行此程式碼後,您將獲得以下結果——
輸出
OFS = $
ORS
它表示輸出記錄分隔符,其預設值為換行符。
示例
[jerry]$ awk 'BEGIN {print "ORS = " ORS}' | cat -vte
執行上述程式碼後,您將獲得以下結果——
輸出
ORS = $ $
RLENGTH
它表示由match函式匹配的字串的長度。AWK 的 match 函式在輸入字串中搜索給定的字串。
示例
[jerry]$ awk 'BEGIN { if (match("One Two Three", "re")) { print RLENGTH } }'
執行此程式碼後,您將獲得以下結果——
輸出
2
RS
它表示(輸入)記錄分隔符,其預設值為換行符。
示例
[jerry]$ awk 'BEGIN {print "RS = " RS}' | cat -vte
執行此程式碼後,您將獲得以下結果——
輸出
RS = $ $
RSTART
它表示由match函式匹配的字串中的第一個位置。
示例
[jerry]$ awk 'BEGIN { if (match("One Two Three", "Thre")) { print RSTART } }'
執行此程式碼後,您將獲得以下結果——
輸出
9
SUBSEP
它表示陣列下標的分隔符字元,其預設值為\034。
示例
[jerry]$ awk 'BEGIN { print "SUBSEP = " SUBSEP }' | cat -vte
執行此程式碼後,您將獲得以下結果——
輸出
SUBSEP = ^\$
$0
它表示整個輸入記錄。
示例
[jerry]$ awk '{print $0}' marks.txt
執行此程式碼後,您將獲得以下結果——
輸出
1) Amit Physics 80 2) Rahul Maths 90 3) Shyam Biology 87 4) Kedar English 85 5) Hari History 89
$n
它表示當前記錄中的第n個欄位,其中欄位由FS分隔。
示例
[jerry]$ awk '{print $3 "\t" $4}' marks.txt
執行此程式碼後,您將獲得以下結果——
輸出
Physics 80 Maths 90 Biology 87 English 85 History 89
GNU AWK 特定變數
GNU AWK 特定變數如下所示:
ARGIND
它表示當前正在處理的檔案在ARGV中的索引。
示例
[jerry]$ awk '{
print "ARGIND = ", ARGIND; print "Filename = ", ARGV[ARGIND]
}' junk1 junk2 junk3
執行此程式碼後,您將獲得以下結果——
輸出
ARGIND = 1 Filename = junk1 ARGIND = 2 Filename = junk2 ARGIND = 3 Filename = junk3
BINMODE
它用於在非POSIX系統上為所有檔案I/O指定二進位制模式。數值1、2或3分別指定輸入檔案、輸出檔案或所有檔案應使用二進位制I/O。字串值r或w分別指定輸入檔案或輸出檔案應使用二進位制I/O。字串值rw或wr指定所有檔案應使用二進位制I/O。
ERRNO
當重定向對於getline失敗或close呼叫失敗時,一個字串指示錯誤。
示例
[jerry]$ awk 'BEGIN { ret = getline < "junk.txt"; if (ret == -1) print "Error:", ERRNO }'
執行此程式碼後,您將獲得以下結果——
輸出
Error: No such file or directory
FIELDWIDTHS
當設定了空格分隔的欄位寬度變數時,GAWK會將輸入解析為固定寬度的欄位,而不是使用FS變數的值作為欄位分隔符。
IGNORECASE
當設定此變數時,GAWK將不區分大小寫。以下示例演示了這一點:
示例
[jerry]$ awk 'BEGIN{IGNORECASE = 1} /amit/' marks.txt
執行此程式碼後,您將獲得以下結果——
輸出
1) Amit Physics 80
LINT
它提供對GAWK程式中--lint選項的動態控制。當設定此變數時,GAWK會列印lint警告。當賦值為字串值fatal時,lint警告將變為致命錯誤,就像--lint=fatal一樣。
示例
[jerry]$ awk 'BEGIN {LINT = 1; a}'
執行此程式碼後,您將獲得以下結果——
輸出
awk: cmd. line:1: warning: reference to uninitialized variable `a' awk: cmd. line:1: warning: statement has no effect
PROCINFO
這是一個關聯陣列,包含有關程序的資訊,例如真實和有效UID編號、程序ID編號等。
示例
[jerry]$ awk 'BEGIN { print PROCINFO["pid"] }'
執行此程式碼後,您將獲得以下結果——
輸出
4316
TEXTDOMAIN
它表示AWK程式的文字域。它用於查詢程式字串的本地化翻譯。
示例
[jerry]$ awk 'BEGIN { print TEXTDOMAIN }'
執行此程式碼後,您將獲得以下結果——
輸出
messages
由於en_IN區域設定,以上輸出顯示英文文字
AWK - 運算子
像其他程式語言一樣,AWK也提供大量運算子。本章將結合示例解釋AWK運算子。
| 序號 | 運算子及描述 |
|---|---|
| 1 | 算術運算子
AWK支援以下算術運算子。 |
| 2 | 自增和自減運算子
AWK支援以下自增和自減運算子。 |
| 3 | 賦值運算子
AWK支援以下賦值運算子。 |
| 4 | 關係運算符
AWK支援以下關係運算符。 |
| 5 | 邏輯運算子
AWK支援以下邏輯運算子。 |
| 6 | 三元運算子
我們可以使用三元運算子輕鬆實現條件表示式。 |
| 7 | 一元運算子
AWK支援以下一元運算子。 |
| 8 | 指數運算子
指數運算子有兩種格式。 |
| 9 | 字串連線運算子
空格是一個字串連線運算子,用於合併兩個字串。 |
| 10 | 陣列成員運算子
它由in表示。它用於訪問陣列元素。 |
| 11 | 正則表示式運算子
此示例說明了正則表示式運算子的兩種形式。 |
AWK - 正則表示式
AWK在處理正則表示式方面非常強大和高效。許多複雜的任務可以透過簡單的正則表示式解決。任何命令列專家都知道正則表示式的強大功能。
本章將結合示例介紹標準正則表示式。
點
它匹配任何單個字元,除了換行符。例如,以下示例匹配fin、fun、fan等。
示例
[jerry]$ echo -e "cat\nbat\nfun\nfin\nfan" | awk '/f.n/'
執行上述程式碼後,您將獲得以下結果——
輸出
fun fin fan
行首
它匹配行首。例如,以下示例列印所有以模式The開頭的行。
示例
[jerry]$ echo -e "This\nThat\nThere\nTheir\nthese" | awk '/^The/'
執行此程式碼後,您將獲得以下結果——
輸出
There Their
行尾
它匹配行尾。例如,以下示例列印以字母n結尾的行。
示例
[jerry]$ echo -e "knife\nknow\nfun\nfin\nfan\nnine" | awk '/n$/'
輸出
執行此程式碼後,您將獲得以下結果——
fun fin fan
匹配字元集
它用於匹配幾個字元中的一個。例如,以下示例匹配模式Call和Tall,但不匹配Ball。
示例
[jerry]$ echo -e "Call\nTall\nBall" | awk '/[CT]all/'
輸出
執行此程式碼後,您將獲得以下結果——
Call Tall
排他集
在排他集中,脫字元號否定方括號中字元的集合。例如,以下示例僅列印Ball。
示例
[jerry]$ echo -e "Call\nTall\nBall" | awk '/[^CT]all/'
執行此程式碼後,您將獲得以下結果——
輸出
Ball
替換
垂直條允許正則表示式進行邏輯或運算。例如,以下示例列印Ball和Call。
示例
[jerry]$ echo -e "Call\nTall\nBall\nSmall\nShall" | awk '/Call|Ball/'
執行此程式碼後,您將獲得以下結果——
輸出
Call Ball
零次或一次出現
它匹配前一個字元的零次或一次出現。例如,以下示例匹配Colour以及Color。我們使用?將u作為可選字元。
示例
[jerry]$ echo -e "Colour\nColor" | awk '/Colou?r/'
執行此程式碼後,您將獲得以下結果——
輸出
Colour Color
零次或多次出現
它匹配前一個字元的零次或多次出現。例如,以下示例匹配ca、cat、catt等。
示例
[jerry]$ echo -e "ca\ncat\ncatt" | awk '/cat*/'
執行此程式碼後,您將獲得以下結果——
輸出
ca cat catt
一次或多次出現
它匹配前一個字元的一次或多次出現。例如,以下示例匹配2的一次或多次出現。
示例
[jerry]$ echo -e "111\n22\n123\n234\n456\n222" | awk '/2+/'
執行上述程式碼後,您將獲得以下結果——
輸出
22 123 234 222
分組
圓括號()用於分組,字元|用於備選。例如,以下正則表示式匹配包含Apple Juice或Apple Cake的行。
示例
[jerry]$ echo -e "Apple Juice\nApple Pie\nApple Tart\nApple Cake" | awk '/Apple (Juice|Cake)/'
執行此程式碼後,您將獲得以下結果——
輸出
Apple Juice Apple Cake
AWK - 陣列
AWK具有關聯陣列,它最好的一個特性是——索引不必是連續的數字集;您可以使用字串或數字作為陣列索引。此外,無需預先宣告陣列的大小——陣列可以在執行時擴充套件/縮小。
其語法如下:
語法
array_name[index] = value
其中array_name是陣列的名稱,index是陣列索引,value是分配給陣列元素的任何值。
建立陣列
為了更深入地瞭解陣列,讓我們建立並訪問陣列的元素。
示例
[jerry]$ awk 'BEGIN {
fruits["mango"] = "yellow";
fruits["orange"] = "orange"
print fruits["orange"] "\n" fruits["mango"]
}'
執行此程式碼後,您將獲得以下結果——
輸出
orange yellow
在上面的示例中,我們將陣列宣告為fruits,其索引是水果名稱,值是水果的顏色。要訪問陣列元素,我們使用array_name[index]格式。
刪除陣列元素
對於插入,我們使用了賦值運算子。類似地,我們可以使用delete語句從陣列中刪除元素。delete語句的語法如下:
語法
delete array_name[index]
以下示例刪除元素orange。因此,該命令不顯示任何輸出。
示例
[jerry]$ awk 'BEGIN {
fruits["mango"] = "yellow";
fruits["orange"] = "orange";
delete fruits["orange"];
print fruits["orange"]
}'
多維陣列
AWK僅支援一維陣列。但是,您可以使用一維陣列本身輕鬆模擬多維陣列。
例如,下面是一個3x3的二維陣列:
100 200 300 400 500 600 700 800 900
在上面的示例中,array[0][0]儲存100,array[0][1]儲存200,依此類推。要將100儲存在陣列位置[0][0],我們可以使用以下語法:
語法
array["0,0"] = 100
雖然我們使用了0,0作為索引,但它們不是兩個索引。實際上,它只是一個索引,字串為0,0。
以下示例模擬了一個二維陣列:
示例
[jerry]$ awk 'BEGIN {
array["0,0"] = 100;
array["0,1"] = 200;
array["0,2"] = 300;
array["1,0"] = 400;
array["1,1"] = 500;
array["1,2"] = 600;
# print array elements
print "array[0,0] = " array["0,0"];
print "array[0,1] = " array["0,1"];
print "array[0,2] = " array["0,2"];
print "array[1,0] = " array["1,0"];
print "array[1,1] = " array["1,1"];
print "array[1,2] = " array["1,2"];
}'
執行此程式碼後,您將獲得以下結果——
輸出
array[0,0] = 100 array[0,1] = 200 array[0,2] = 300 array[1,0] = 400 array[1,1] = 500 array[1,2] = 600
您還可以對陣列執行各種操作,例如對元素/索引進行排序。為此,您可以使用asort和asorti函式
AWK - 控制流
像其他程式語言一樣,AWK提供條件語句來控制程式的流程。本章將結合示例解釋AWK的控制語句。
If語句
它只是測試條件,並根據條件執行某些操作。以下是if語句的語法:
語法
if (condition) action
我們也可以使用一對花括號,如下所示,來執行多個操作:
語法
if (condition) {
action-1
action-1
.
.
action-n
}
例如,以下示例檢查一個數字是否為偶數:
示例
[jerry]$ awk 'BEGIN {num = 10; if (num % 2 == 0) printf "%d is even number.\n", num }'
執行上述程式碼後,您將獲得以下結果——
輸出
10 is even number.
If Else語句
在if-else語法中,我們可以提供一個操作列表,當條件變為假時執行。
if-else語句的語法如下:
語法
if (condition) action-1 else action-2
在上述語法中,當條件計算結果為真時執行action-1,當條件計算結果為假時執行action-2。例如,以下示例檢查一個數字是否為偶數:
示例
[jerry]$ awk 'BEGIN {
num = 11; if (num % 2 == 0) printf "%d is even number.\n", num;
else printf "%d is odd number.\n", num
}'
執行此程式碼後,您將獲得以下結果——
輸出
11 is odd number.
If-Else-If階梯
我們可以透過使用多個if-else語句輕鬆建立if-else-if階梯。以下示例演示了這一點:
示例
[jerry]$ awk 'BEGIN {
a = 30;
if (a==10)
print "a = 10";
else if (a == 20)
print "a = 20";
else if (a == 30)
print "a = 30";
}'
執行此程式碼後,您將獲得以下結果——
輸出
a = 30
AWK - 迴圈
本章結合示例解釋AWK的迴圈。迴圈用於重複執行一組操作。只要迴圈條件為真,迴圈執行就會繼續。
For迴圈
for迴圈的語法為:
語法
for (initialization; condition; increment/decrement) action
最初,for語句執行初始化操作,然後檢查條件。如果條件為真,則執行操作,然後執行增量或減量操作。只要條件為真,迴圈執行就會繼續。例如,以下示例使用for迴圈列印1到5:
示例
[jerry]$ awk 'BEGIN { for (i = 1; i <= 5; ++i) print i }'
執行此程式碼後,您將獲得以下結果——
輸出
1 2 3 4 5
While迴圈
while迴圈會一直執行操作,直到特定的邏輯條件計算結果為真。以下是while迴圈的語法:
語法
while (condition) action
AWK首先檢查條件;如果條件為真,則執行操作。只要迴圈條件計算結果為真,此過程就會重複。例如,以下示例使用while迴圈列印1到5:
示例
[jerry]$ awk 'BEGIN {i = 1; while (i < 6) { print i; ++i } }'
執行此程式碼後,您將獲得以下結果——
輸出
1 2 3 4 5
Do-While迴圈
do-while迴圈類似於while迴圈,只是在迴圈結束時評估測試條件。以下是do-while迴圈的語法:
語法
do action while (condition)
在do-while迴圈中,即使條件語句計算結果為假,操作語句至少也會執行一次。例如,以下示例使用do-while迴圈列印1到5個數字:
示例
[jerry]$ awk 'BEGIN {i = 1; do { print i; ++i } while (i < 6) }'
執行此程式碼後,您將獲得以下結果——
輸出
1 2 3 4 5
Break語句
顧名思義,它用於結束迴圈執行。這是一個示例,當總和大於50時結束迴圈。
示例
[jerry]$ awk 'BEGIN {
sum = 0; for (i = 0; i < 20; ++i) {
sum += i; if (sum > 50) break; else print "Sum =", sum
}
}'
執行此程式碼後,您將獲得以下結果——
輸出
Sum = 0 Sum = 1 Sum = 3 Sum = 6 Sum = 10 Sum = 15 Sum = 21 Sum = 28 Sum = 36 Sum = 45
Continue語句
continue語句用於迴圈內部,以跳到迴圈的下一個迭代。當您希望跳過迴圈內部某些資料的處理時,它很有用。例如,以下示例使用continue語句列印1到20之間的偶數。
示例
[jerry]$ awk 'BEGIN {
for (i = 1; i <= 20; ++i) {
if (i % 2 == 0) print i ; else continue
}
}'
執行此程式碼後,您將獲得以下結果——
輸出
2 4 6 8 10 12 14 16 18 20
Exit語句
它用於停止指令碼的執行。它接受一個整數作為引數,該引數是AWK程序的退出狀態程式碼。如果沒有提供引數,exit將返回狀態零。這是一個在總和大於50時停止執行的示例。
示例
[jerry]$ awk 'BEGIN {
sum = 0; for (i = 0; i < 20; ++i) {
sum += i; if (sum > 50) exit(10); else print "Sum =", sum
}
}'
輸出
執行此程式碼後,您將獲得以下結果——
Sum = 0 Sum = 1 Sum = 3 Sum = 6 Sum = 10 Sum = 15 Sum = 21 Sum = 28 Sum = 36 Sum = 45
讓我們檢查指令碼的返回狀態。
示例
[jerry]$ echo $?
執行此程式碼後,您將獲得以下結果——
輸出
10
AWK - 內建函式
AWK 內建了許多函式,程式設計師始終可以使用這些函式。本章將結合示例介紹算術函式、字串函式、時間函式、位操作函式和其他雜項函式。
| 序號 | 內建函式及描述 |
|---|---|
| 1 | 算術函式
AWK 包含以下內建算術函式。 |
| 2 | 字串函式
AWK 包含以下內建字串函式。 |
| 3 | 時間函式
AWK 包含以下內建時間函式。 |
| 4 | 位操作函式
AWK 包含以下內建位操作函式。 |
| 5 | 雜項函式
AWK 包含以下雜項函式。 |
AWK - 使用者自定義函式
函式是程式的基本構建塊。AWK 允許我們定義自己的函式。一個大型程式可以被分解成多個函式,每個函式可以獨立編寫/測試。它提供了程式碼的可重用性。
以下是使用者自定義函式的一般格式:
語法
function function_name(argument1, argument2, ...) {
function body
}
在此語法中,function_name 是使用者自定義函式的名稱。函式名應以字母開頭,其餘字元可以是數字、字母字元或下劃線的任意組合。AWK 的保留字不能用作函式名。
函式可以接受多個以逗號分隔的引數。引數不是必須的。您還可以建立一個沒有任何引數的使用者自定義函式。
function body 包含一個或多個 AWK 語句。
讓我們編寫兩個分別計算最小值和最大值的函式,並從另一個名為main的函式中呼叫這些函式。functions.awk 檔案包含:
示例
# Returns minimum number
function find_min(num1, num2){
if (num1 < num2)
return num1
return num2
}
# Returns maximum number
function find_max(num1, num2){
if (num1 > num2)
return num1
return num2
}
# Main function
function main(num1, num2){
# Find minimum number
result = find_min(10, 20)
print "Minimum =", result
# Find maximum number
result = find_max(10, 20)
print "Maximum =", result
}
# Script execution starts here
BEGIN {
main(10, 20)
}
執行此程式碼後,您將獲得以下結果——
輸出
Minimum = 10 Maximum = 20
AWK - 輸出重定向
到目前為止,我們已將資料顯示在標準輸出流上。我們還可以將資料重定向到檔案。重定向出現在print或printf語句之後。AWK 中的重定向與 shell 命令中的重定向寫法相同,只是它們寫在 AWK 程式內部。本章將結合示例介紹重定向。
重定向運算子
重定向運算子的語法如下:
語法
print DATA > output-file
它將資料寫入output-file。如果 output-file 不存在,則建立一個。使用這種型別的重定向時,output-file 會在寫入第一個輸出之前被清空。隨後對同一 output-file 的寫入操作不會清空 output-file,而是追加到其末尾。例如,以下示例將Hello, World !!!寫入檔案。
讓我們建立一個包含一些文字資料的檔案。
示例
[jerry]$ echo "Old data" > /tmp/message.txt [jerry]$ cat /tmp/message.txt
執行此程式碼後,您將獲得以下結果——
輸出
Old data
現在讓我們使用 AWK 的重定向運算子將一些內容重定向到其中。
示例
[jerry]$ awk 'BEGIN { print "Hello, World !!!" > "/tmp/message.txt" }'
[jerry]$ cat /tmp/message.txt
執行此程式碼後,您將獲得以下結果——
輸出
Hello, World !!!
追加運算子
追加運算子的語法如下:
語法
print DATA >> output-file
它將資料追加到output-file。如果 output-file 不存在,則建立一個。使用這種型別的重定向時,新內容將追加到檔案的末尾。例如,以下示例將Hello, World !!!追加到檔案。
讓我們建立一個包含一些文字資料的檔案。
示例
[jerry]$ echo "Old data" > /tmp/message.txt [jerry]$ cat /tmp/message.txt
執行此程式碼後,您將獲得以下結果——
輸出
Old data
現在讓我們使用 AWK 的追加運算子向其中追加一些內容。
示例
[jerry]$ awk 'BEGIN { print "Hello, World !!!" >> "/tmp/message.txt" }'
[jerry]$ cat /tmp/message.txt
執行此程式碼後,您將獲得以下結果——
輸出
Old data Hello, World !!!
管道
可以透過管道將輸出傳送到另一個程式,而不是使用檔案。此重定向會開啟一個指向 command 的管道,並透過此管道將專案的 value 寫入另一個程序以執行 command。重定向引數 command 實際上是一個 AWK 表示式。以下是管道的語法:
語法
print items | command
讓我們使用tr命令將小寫字母轉換為大寫字母。
示例
[jerry]$ awk 'BEGIN { print "hello, world !!!" | "tr [a-z] [A-Z]" }'
執行此程式碼後,您將獲得以下結果——
輸出
HELLO, WORLD !!!
雙向通訊
AWK 可以使用|&與外部程序通訊,這是雙向通訊。例如,以下示例使用tr命令將小寫字母轉換為大寫字母。我們的command.awk檔案包含:
示例
BEGIN {
cmd = "tr [a-z] [A-Z]"
print "hello, world !!!" |& cmd
close(cmd, "to")
cmd |& getline out
print out;
close(cmd);
}
執行此程式碼後,您將獲得以下結果——
輸出
HELLO, WORLD !!!
指令碼看起來很神秘嗎?讓我們揭開它的神秘面紗。
第一條語句cmd = "tr [a-z] [A-Z]"是我們要與 AWK 建立雙向通訊的命令。
下一條語句,即 print 命令,為tr命令提供輸入。這裡&|表示雙向通訊。
第三條語句,即close(cmd, "to"),在完成執行後關閉to程序。
下一條語句cmd |& getline out藉助 getline 函式將output儲存到 out 變數中。
下一個 print 語句列印輸出,最後close函式關閉命令。
AWK - 美化輸出
到目前為止,我們已使用 AWK 的print和printf函式在標準輸出上顯示資料。但是 printf 比我們之前看到的要強大得多。此函數借鑑自 C 語言,在生成格式化輸出時非常有用。以下是 printf 語句的語法:
語法
printf fmt, expr-list
在上述語法中,fmt是格式規範和常量的字串。expr-list是與格式說明符對應的引數列表。
轉義序列
與任何字串類似,格式可以包含嵌入的轉義序列。下面討論 AWK 支援的轉義序列:
換行符
以下示例使用換行符在單獨的行中列印Hello和World:
示例
[jerry]$ awk 'BEGIN { printf "Hello\nWorld\n" }'
執行此程式碼後,您將獲得以下結果——
輸出
Hello World
水平製表符
以下示例使用水平製表符顯示不同的欄位:
示例
[jerry]$ awk 'BEGIN { printf "Sr No\tName\tSub\tMarks\n" }'
執行上述程式碼後,您將獲得以下結果——
輸出
Sr No Name Sub Marks
垂直製表符
以下示例在每個欄位後使用垂直製表符:
示例
[jerry]$ awk 'BEGIN { printf "Sr No\vName\vSub\vMarks\n" }'
執行此程式碼後,您將獲得以下結果——
輸出
Sr No
Name
Sub
Marks
退格符
以下示例在除最後一個欄位外的每個欄位後列印一個退格符。它從前三個欄位的最後一個數字中刪除。例如,Field 1顯示為Field,因為最後一個字元用退格符刪除了。但是,最後一個欄位Field 4按原樣顯示,因為我們在Field 4之後沒有\b。
示例
[jerry]$ awk 'BEGIN { printf "Field 1\bField 2\bField 3\bField 4\n" }'
執行此程式碼後,您將獲得以下結果——
輸出
Field Field Field Field 4
在以下示例中,在列印每個欄位後,我們執行回車並在當前列印值的頂部列印下一個值。這意味著,在最終輸出中,您只能看到Field 4,因為它是在所有先前欄位頂部列印的最後一個值。
回車符
示例
[jerry]$ awk 'BEGIN { printf "Field 1\rField 2\rField 3\rField 4\n" }'
執行此程式碼後,您將獲得以下結果——
輸出
Field 4
換頁符
以下示例在列印每個欄位後使用換頁符。
示例
[jerry]$ awk 'BEGIN { printf "Sr No\fName\fSub\fMarks\n" }'
執行此程式碼後,您將獲得以下結果——
輸出
Sr No
Name
Sub
Marks
格式說明符
與 C 語言一樣,AWK 也具有格式說明符。printf 語句的 AWK 版本接受以下轉換規範格式:
%c
它列印單個字元。如果用於%c的引數是數字,則將其視為字元並列印。否則,假定引數為字串,並且僅列印該字串的第一個字元。
示例
[jerry]$ awk 'BEGIN { printf "ASCII value 65 = character %c\n", 65 }'
輸出
執行此程式碼後,您將獲得以下結果——
ASCII value 65 = character A
%d 和 %i
它僅列印十進位制數的整數部分。
示例
[jerry]$ awk 'BEGIN { printf "Percentags = %d\n", 80.66 }'
執行此程式碼後,您將獲得以下結果——
輸出
Percentags = 80
%e 和 %E
它列印形式為[-]d.dddddde[+-]dd的浮點數。
示例
[jerry]$ awk 'BEGIN { printf "Percentags = %E\n", 80.66 }'
執行此程式碼後,您將獲得以下結果——
輸出
Percentags = 8.066000e+01
%E格式使用E代替 e。
示例
[jerry]$ awk 'BEGIN { printf "Percentags = %e\n", 80.66 }'
執行此程式碼後,您將獲得以下結果——
輸出
Percentags = 8.066000E+01
%f
它列印形式為[-]ddd.dddddd的浮點數。
示例
[jerry]$ awk 'BEGIN { printf "Percentags = %f\n", 80.66 }'
執行此程式碼後,您將獲得以下結果——
輸出
Percentags = 80.660000
%g 和 %G
使用%e或%f轉換,以較短者為準,並抑制不重要的零。
示例
[jerry]$ awk 'BEGIN { printf "Percentags = %g\n", 80.66 }'
輸出
執行此程式碼後,您將獲得以下結果——
Percentags = 80.66
%G格式使用%E代替%e。
示例
[jerry]$ awk 'BEGIN { printf "Percentags = %G\n", 80.66 }'
執行此程式碼後,您將獲得以下結果——
輸出
Percentags = 80.66
%o
它列印一個無符號八進位制數。
示例
[jerry]$ awk 'BEGIN { printf "Octal representation of decimal number 10 = %o\n", 10}'
執行此程式碼後,您將獲得以下結果——
輸出
Octal representation of decimal number 10 = 12
%u
它列印一個無符號十進位制數。
示例
[jerry]$ awk 'BEGIN { printf "Unsigned 10 = %u\n", 10 }'
執行此程式碼後,您將獲得以下結果——
輸出
Unsigned 10 = 10
%s
它列印一個字元字串。
示例
[jerry]$ awk 'BEGIN { printf "Name = %s\n", "Sherlock Holmes" }'
執行此程式碼後,您將獲得以下結果——
輸出
Name = Sherlock Holmes
%x 和 %X
它列印一個無符號十六進位制數。%X格式使用大寫字母代替小寫字母。
示例
[jerry]$ awk 'BEGIN {
printf "Hexadecimal representation of decimal number 15 = %x\n", 15
}'
執行此程式碼後,您將獲得以下結果——
輸出
Hexadecimal representation of decimal number 15 = f
現在讓我們使用%X並觀察結果:
示例
[jerry]$ awk 'BEGIN {
printf "Hexadecimal representation of decimal number 15 = %X\n", 15
}'
執行此程式碼後,您將獲得以下結果——
輸出
Hexadecimal representation of decimal number 15 = F
%%
它列印單個%字元,並且不轉換任何引數。
示例
[jerry]$ awk 'BEGIN { printf "Percentags = %d%%\n", 80.66 }'
執行此程式碼後,您將獲得以下結果——
輸出
Percentags = 80%
帶有%的可選引數
使用%,我們可以使用以下可選引數:
寬度
欄位將填充到width。預設情況下,欄位用空格填充,但當使用 0 標誌時,則用零填充。
示例
[jerry]$ awk 'BEGIN {
num1 = 10; num2 = 20; printf "Num1 = %10d\nNum2 = %10d\n", num1, num2
}'
執行此程式碼後,您將獲得以下結果——
輸出
Num1 = 10 Num2 = 20
前導零
前導零充當標誌,表示輸出應使用零而不是空格填充。請注意,此標誌僅在欄位寬度大於要列印的值時才會生效。以下示例說明了這一點:
示例
[jerry]$ awk 'BEGIN {
num1 = -10; num2 = 20; printf "Num1 = %05d\nNum2 = %05d\n", num1, num2
}'
執行此程式碼後,您將獲得以下結果——
輸出
Num1 = -0010 Num2 = 00020
左對齊
表示式應在其欄位內左對齊。當輸入字串小於指定的字元數,並且您希望將其左對齊,即透過在右側新增空格,請在%之後和數字之前立即使用減號(–)。
在以下示例中,AWK 命令的輸出透過管道傳輸到 cat 命令以顯示行尾($)字元。
示例
[jerry]$ awk 'BEGIN { num = 10; printf "Num = %-5d\n", num }' | cat -vte
執行此程式碼後,您將獲得以下結果——
輸出
Num = 10 $
字首符號
它始終為數值新增字首符號,即使該值為正數。
示例
[jerry]$ awk 'BEGIN {
num1 = -10; num2 = 20; printf "Num1 = %+d\nNum2 = %+d\n", num1, num2
}'
執行此程式碼後,您將獲得以下結果——
輸出
Num1 = -10 Num2 = +20
井號
對於%o,它提供一個前導零。對於%x和%X,它分別提供前導0x或0X,僅當結果非零時。對於%e、%E、%f和%F,結果始終包含小數點。對於%g和%G,不會從結果中刪除尾隨零。以下示例說明了這一點:
示例
[jerry]$ awk 'BEGIN {
printf "Octal representation = %#o\nHexadecimal representaion = %#X\n", 10, 10
}'
執行此程式碼後,您將獲得以下結果——
輸出
Octal representation = 012 Hexadecimal representation = 0XA