- 組合語言教程
- 組合語言 - 首頁
- 組合語言 - 簡介
- 組合語言 - 環境搭建
- 組合語言 - 基本語法
- 組合語言 - 記憶體段
- 組合語言 - 暫存器
- 組合語言 - 系統呼叫
- 組合語言 -定址方式
- 組合語言 - 變數
- 組合語言 - 常量
- 組合語言 - 算術指令
- 組合語言 - 邏輯指令
- 組合語言 - 條件語句
- 組合語言 - 迴圈語句
- 組合語言 - 數字
- 組合語言 - 字串
- 組合語言 - 陣列
- 組合語言 - 過程
- 組合語言 - 遞迴
- 組合語言 - 宏
- 組合語言 - 檔案管理
- 組合語言 - 記憶體管理
- 組合語言有用資源
- 組合語言 - 快速指南
- 組合語言 - 有用資源
- 組合語言 - 討論
組合語言 - 快速指南
組合語言 - 簡介
什麼是組合語言?
每臺個人電腦都有一顆微處理器,它管理計算機的算術、邏輯和控制活動。
每個處理器系列都有自己的一套指令,用於處理各種操作,例如從鍵盤獲取輸入、在螢幕上顯示資訊以及執行其他各種任務。這些指令集稱為“機器語言指令”。
處理器只理解機器語言指令,它們是一串1和0。然而,機器語言對於軟體開發來說過於晦澀和複雜。因此,為特定處理器系列設計的低階組合語言,它以符號程式碼和更易理解的形式表示各種指令。
組合語言的優點
瞭解組合語言使人能夠了解:
- 程式如何與作業系統、處理器和BIOS互動;
- 資料如何在記憶體和其他外部裝置中表示;
- 處理器如何訪問和執行指令;
- 指令如何訪問和處理資料;
- 程式如何訪問外部裝置。
使用匯編語言的其他優點包括:
它需要的記憶體和執行時間更少;
它允許以更簡單的方式執行硬體特定的複雜任務;
它適用於時間關鍵型任務;
它最適合編寫中斷服務程式和其他記憶體駐留程式。
PC硬體的基本特徵
PC的主要內部硬體包括處理器、記憶體和暫存器。暫存器是處理器元件,用於儲存資料和地址。要執行程式,系統會將其從外部裝置複製到內部記憶體。處理器執行程式指令。
計算機儲存的基本單位是位;它可以是開(1)或關(0),在大多數現代計算機上,8個相關的位構成一個位元組。
因此,奇偶校驗位用於使位元組中的位數為奇數。如果奇偶校驗為偶數,則系統假設發生了奇偶校驗錯誤(儘管很少見),這可能是由於硬體故障或電氣干擾造成的。
處理器支援以下資料大小:
- 字:2位元組資料項
- 雙字:4位元組(32位)資料項
- 四字:8位元組(64位)資料項
- 段:16位元組(128位)區域
- 千位元組:1024位元組
- 兆位元組:1,048,576位元組
二進位制數系統
每個數制都使用位置計數法,即寫入數字的每個位置都有不同的位置值。每個位置都是基數的冪,對於二進位制數系統來說,基數是2,這些冪從0開始,每次增加1。
下表顯示了8位二進位制數的位置值,其中所有位都設定為ON。
| 位值 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|---|---|---|---|---|---|---|---|---|
| 以2為底的冪的位置值 | 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
| 位數 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
二進位制數的值基於1位的出現及其位置值。因此,給定二進位制數的值為:
1 + 2 + 4 + 8 +16 + 32 + 64 + 128 = 255
這與28 - 1相同。
十六進位制數系統
十六進位制數系統使用基數16。該系統中的數字範圍從0到15。按照約定,字母A到F用於表示對應於十進位制值10到15的十六進位制數字。
在計算中,十六進位制數用於縮寫冗長的二進位制表示。基本上,十六進位制數系統透過將每個位元組分成兩半並表達每半位元組的值來表示二進位制資料。下表提供了十進位制、二進位制和十六進位制的等效值:
| 十進位制數 | 二進位制表示 | 十六進位制表示 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 2 | 10 | 2 |
| 3 | 11 | 3 |
| 4 | 100 | 4 |
| 5 | 101 | 5 |
| 6 | 110 | 6 |
| 7 | 111 | 7 |
| 8 | 1000 | 8 |
| 9 | 1001 | 9 |
| 10 | 1010 | A |
| 11 | 1011 | B |
| 12 | 1100 | C |
| 13 | 1101 | D |
| 14 | 1110 | E |
| 15 | 1111 | F |
要將二進位制數轉換為其十六進位制等效值,請將其分成每組4個連續的組,從右邊開始,並將這些組寫在十六進位制數的相應數字之上。
示例 - 二進位制數1000 1100 1101 0001 等效於十六進位制 - 8CD1
要將十六進位制數轉換為二進位制數,只需將每個十六進位制數字寫入其4位二進位制等效值即可。
示例 - 十六進位制數FAD8 等效於二進位制 - 1111 1010 1101 1000
二進位制算術
下表說明了二進位制加法的四個簡單規則:
| (i) | (ii) | (iii) | (iv) |
|---|---|---|---|
| 1 | |||
| 0 | 1 | 1 | 1 |
| +0 | +0 | +1 | +1 |
| =0 | =1 | =10 | =11 |
規則(iii)和(iv)顯示將1位進位到下一個左邊的位置。
示例
| 十進位制 | 二進位制 |
|---|---|
| 60 | 00111100 |
| +42 | 00101010 |
| 102 | 01100110 |
負二進位制值以二進位制補碼錶示法表示。根據此規則,要將二進位制數轉換為其負值,需要反轉其位值並加1。
示例
| 數字53 | 00110101 |
| 反轉位 | 11001010 |
| 加1 | 00000001 |
| 數字-53 | 11001011 |
要從另一個值中減去一個值,將被減數轉換為二進位制補碼格式並相加。
示例
從53中減去42
| 數字53 | 00110101 |
| 數字42 | 00101010 |
| 反轉42的位 | 11010101 |
| 加1 | 00000001 |
| 數字-42 | 11010110 |
| 53 - 42 = 11 | 00001011 |
最後一位的溢位將丟失。
記憶體中資料的定址
處理器控制指令執行的過程稱為取指-譯碼-執行週期或執行週期。它包含三個連續的步驟:
- 從記憶體中取指令
- 解碼或識別指令
- 執行指令
處理器可以一次訪問一個或多個位元組的記憶體。讓我們考慮一個十六進位制數0725H。這個數字需要兩個位元組的記憶體。高位位元組或最高有效位元組是07,低位位元組是25。
處理器以反向位元組順序儲存資料,即低位位元組儲存在低記憶體地址,高位位元組儲存在高記憶體地址。因此,如果處理器將值0725H從暫存器移到記憶體,它將首先將25傳輸到較低的記憶體地址,然後將07傳輸到下一個記憶體地址。
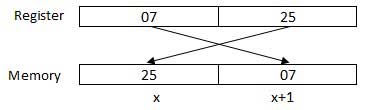
x:記憶體地址
當處理器從記憶體獲取數值資料到暫存器時,它會再次反轉位元組。有兩種記憶體地址:
絕對地址 - 對特定位置的直接引用。
段地址(或偏移量) - 記憶體段的起始地址以及偏移值。
組合語言 - 環境搭建
本地環境設定
組合語言依賴於處理器的指令集和體系結構。在本教程中,我們關注的是英特爾32位處理器,如奔騰。要學習本教程,您需要:
- 一臺IBM PC或任何等效的相容計算機
- 一個Linux作業系統副本
- 一個NASM彙編程式副本
有很多優秀的彙編程式,例如:
- Microsoft Assembler (MASM)
- Borland Turbo Assembler (TASM)
- GNU彙編器 (GAS)
我們將使用NASM彙編器,因為它:
- 免費。您可以從各種網路資源下載它。
- 文件齊全,您可以在網上找到大量資訊。
- 可以在Linux和Windows上使用。
安裝NASM
如果您在安裝Linux時選擇“開發工具”,則可能會與Linux作業系統一起安裝NASM,您無需單獨下載和安裝它。要檢查您是否已安裝NASM,請執行以下步驟:
開啟Linux終端。
鍵入whereis nasm並按ENTER鍵。
如果已安裝,則會出現類似nasm: /usr/bin/nasm的行。否則,您只會看到nasm:,則需要安裝NASM。
要安裝NASM,請執行以下步驟:
檢視The Netwide Assembler (NASM)網站以獲取最新版本。
下載Linux原始碼存檔
nasm-X.XX.ta.gz,其中X.XX是存檔中的NASM版本號。將存檔解壓到一個目錄中,該目錄會建立一個子目錄
nasm-X.XX。cd到
nasm-X.XX並鍵入./configure。此shell指令碼將找到最佳的C編譯器並相應地設定Makefile。鍵入make以構建nasm和ndisasm二進位制檔案。
鍵入make install以將nasm和ndisasm安裝到/usr/local/bin中,並安裝手冊頁。
這應該會在您的系統上安裝NASM。或者,您可以為Fedora Linux使用RPM發行版。此版本安裝起來更簡單,只需雙擊RPM檔案即可。
組合語言 - 基本語法
彙編程式可以分為三個部分:
資料部分、
bss部分和
文字部分。
資料部分
資料部分用於宣告已初始化的資料或常量。此資料在執行時不會更改。您可以在此部分宣告各種常數值、檔名或緩衝區大小等。
宣告資料部分的語法為:
section.data
bss部分
bss部分用於宣告變數。宣告bss部分的語法為:
section.bss
文字部分
文字部分用於儲存實際程式碼。此部分必須以宣告global _start開頭,這告訴核心程式執行從哪裡開始。
宣告文字部分的語法為:
section.text global _start _start:
註釋
組合語言註釋以分號 (;) 開頭。它可以包含任何可列印字元,包括空格。它可以單獨出現在一行上,例如:
; This program displays a message on screen
或者,與指令在同一行上,例如:
add eax, ebx ; adds ebx to eax
組合語言語句
組合語言程式由三種類型的語句組成:
- 可執行指令或指令、
- 彙編指令或偽操作和
- 宏。
可執行指令或簡稱指令告訴處理器做什麼。每個指令都包含一個操作碼 (opcode)。每個可執行指令都會生成一條機器語言指令。
彙編指令或偽操作告訴彙編器有關彙編過程的各個方面。這些指令不可執行,不會生成機器語言指令。
宏基本上是一種文字替換機制。
組合語言語句的語法
組合語言語句每行輸入一條語句。每個語句都遵循以下格式:
[label] mnemonic [operands] [;comment]
方括號中的欄位是可選的。基本指令有兩個部分,第一個是將要執行的指令的名稱(或助記符),第二個是命令的運算元或引數。
以下是一些典型的組合語言語句示例:
INC COUNT ; Increment the memory variable COUNT
MOV TOTAL, 48 ; Transfer the value 48 in the
; memory variable TOTAL
ADD AH, BH ; Add the content of the
; BH register into the AH register
AND MASK1, 128 ; Perform AND operation on the
; variable MASK1 and 128
ADD MARKS, 10 ; Add 10 to the variable MARKS
MOV AL, 10 ; Transfer the value 10 to the AL register
組合語言中的Hello World程式
以下組合語言程式碼在螢幕上顯示字串“Hello World”:
section .text global _start ;must be declared for linker (ld) _start: ;tells linker entry point mov edx,len ;message length mov ecx,msg ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel section .data msg db 'Hello, world!', 0xa ;string to be printed len equ $ - msg ;length of the string
編譯並執行上述程式碼後,將產生以下結果:
Hello, world!
在NASM中編譯和連結彙編程式
確保你已將nasm和ld二進位制檔案的路徑設定到你的PATH環境變數中。現在,按照以下步驟編譯和連結上述程式:
使用文字編輯器輸入上述程式碼,並將其儲存為hello.asm。
確保你當前目錄與儲存hello.asm檔案的目錄相同。
要彙編程式,請鍵入nasm -f elf hello.asm
如果存在任何錯誤,在此階段將提示你。否則,將建立名為hello.o的程式目標檔案。
要連結目標檔案並建立名為hello的可執行檔案,請鍵入ld -m elf_i386 -s -o hello hello.o
鍵入./hello執行程式
如果一切正確,它將在螢幕上顯示“Hello, world!”。
組合語言 - 記憶體段
我們已經討論了彙編程式的三個部分。這些部分也代表不同的記憶體段。
有趣的是,如果你用segment替換section關鍵字,你將得到相同的結果。請嘗試以下程式碼:
segment .text ;code segment global _start ;must be declared for linker _start: ;tell linker entry point mov edx,len ;message length mov ecx,msg ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel segment .data ;data segment msg db 'Hello, world!',0xa ;our dear string len equ $ - msg ;length of our dear string
編譯並執行上述程式碼後,將產生以下結果:
Hello, world!
記憶體段
分段記憶體模型將系統記憶體劃分為獨立的段組,這些段組由段暫存器中位於的指標引用。每個段用於包含特定型別的資料。一個段用於包含指令程式碼,另一個段儲存資料元素,第三個段儲存程式堆疊。
根據上述討論,我們可以指定各種記憶體段:
資料段 - 它由.data段和.bss段表示。.data段用於宣告記憶體區域,程式的資料元素儲存在該區域。宣告資料元素後,此段不能擴充套件,並且在整個程式中保持靜態。
.bss段也是一個靜態記憶體段,它包含以後在程式中宣告資料的緩衝區。此緩衝區記憶體將被清零。
程式碼段 - 它由.text段表示。這定義了一個儲存指令程式碼的記憶體區域。這也是一個固定區域。
堆疊 - 此段包含傳遞給程式中函式和過程的資料值。
組合語言 - 暫存器
處理器操作主要涉及處理資料。這些資料可以儲存在記憶體中並從中訪問。但是,從記憶體讀取資料和將資料儲存到記憶體會降低處理器的速度,因為它涉及透過控制匯流排和到記憶體儲存單元傳送資料請求以及透過同一通道獲取資料的複雜過程。
為了加快處理器操作速度,處理器包含一些內部記憶體儲存位置,稱為暫存器。
暫存器儲存資料元素以進行處理,而無需訪問記憶體。處理器晶片中內建數量有限的暫存器。
處理器暫存器
IA-32架構中有十個32位和六個16位處理器暫存器。這些暫存器分為三類:
- 通用暫存器;
- 控制暫存器;以及
- 段暫存器。
通用暫存器進一步細分為以下幾組:
- 資料暫存器;
- 指標暫存器;以及
- 索引暫存器。
資料暫存器
四個32位資料暫存器用於算術、邏輯和其他運算。這四個32位暫存器可以使用三種方式:
作為完整的32位資料暫存器:EAX、EBX、ECX、EDX。
32位暫存器的低半部分可以用作四個16位資料暫存器:AX、BX、CX和DX。
上述四個16位暫存器的低半部分和高半部分可以用作八個8位資料暫存器:AH、AL、BH、BL、CH、CL、DH和DL。

其中一些資料暫存器在算術運算中具有特定用途。
AX是主累加器;它用於輸入/輸出和大多數算術指令。例如,在乘法運算中,根據運算元的大小,一個運算元儲存在EAX或AX或AL暫存器中。
BX稱為基址暫存器,因為它可用於索引定址。
CX稱為計數暫存器,因為ECX、CX暫存器在迭代運算中儲存迴圈計數。
DX稱為資料暫存器。它也用於輸入/輸出操作。它也與AX暫存器一起用於涉及大值的乘法和除法運算。
指標暫存器
指標暫存器是32位EIP、ESP和EBP暫存器以及相應的16位右半部分IP、SP和BP。指標暫存器分為三類:
指令指標(IP) - 16位IP暫存器儲存要執行的下一條指令的偏移地址。IP與CS暫存器(作為CS:IP)一起提供程式碼段中當前指令的完整地址。
堆疊指標(SP) - 16位SP暫存器提供程式堆疊內的偏移值。SP與SS暫存器(SS:SP)一起引用程式堆疊中資料的當前位置或地址。
基址指標(BP) - 16位BP暫存器主要幫助引用傳遞給子例程的引數變數。SS暫存器中的地址與BP中的偏移量組合以獲取引數的位置。BP也可以與DI和SI組合用作特殊定址的基址暫存器。
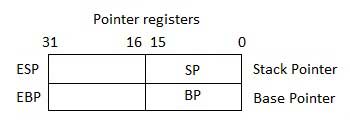
索引暫存器
32位索引暫存器ESI和EDI及其16位最右半部分SI和DI用於索引定址,有時也用於加法和減法。有兩組索引指標:
源索引(SI) - 它用作字串操作的源索引。
目標索引(DI) - 它用作字串操作的目標索引。

控制暫存器
32位指令指標暫存器和32位標誌暫存器組合在一起被認為是控制暫存器。
許多指令涉及比較和數學計算,並更改標誌的狀態,一些其他條件指令測試這些狀態標誌的值以將控制流轉移到其他位置。
常見的標誌位是
溢位標誌(OF) - 它指示帶符號算術運算後資料的高位位(最左位)溢位。
方向標誌(DF) - 它確定移動或比較字串資料的左右方向。當DF值為0時,字串操作採用從左到右的方向;當值為1時,字串操作採用從右到左的方向。
中斷標誌(IF) - 它確定是否要忽略或處理外部中斷(如鍵盤輸入等)。當值為0時,它停用外部中斷;當設定為1時,它啟用中斷。
陷阱標誌(TF) - 它允許將處理器的操作設定為單步模式。我們使用的DEBUG程式設定了陷阱標誌,因此我們可以一次一步地執行指令。
符號標誌(SF) - 它顯示算術運算結果的符號。此標誌根據算術運算後資料項的符號設定。符號由最左邊的最高位指示。正結果將SF的值清除為0,負結果將其設定為1。
零標誌(ZF) - 它指示算術或比較運算的結果。非零結果將零標誌清除為0,零結果將其設定為1。
輔助進位標誌(AF) - 它包含算術運算後從位3到位4的進位;用於專門的算術運算。當1位元組算術運算導致從位3到位4的進位時,AF被設定。
奇偶標誌(PF) - 它指示從算術運算獲得的結果中1位的總數。偶數個1位將奇偶標誌清除為0,奇數個1位將奇偶標誌設定為1。
進位標誌(CF) - 它包含算術運算後高位位(最左位)的進位0或1。它還儲存移位或旋轉操作的最後一位的內容。
下表指示標誌位在16位標誌暫存器中的位置
| 標誌 | O | D | I | T | S | Z | A | P | C | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 位號 | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
段暫存器
段是在程式中定義的特定區域,用於包含資料、程式碼和堆疊。主要有三個段:
程式碼段 - 它包含所有要執行的指令。16位程式碼段暫存器或CS暫存器儲存程式碼段的起始地址。
資料段 - 它包含資料、常量和工作區。16位資料段暫存器或DS暫存器儲存資料段的起始地址。
堆疊段 - 它包含資料和過程或子例程的返回地址。它實現為“堆疊”資料結構。堆疊段暫存器或SS暫存器儲存堆疊的起始地址。
除了DS、CS和SS暫存器之外,還有其他額外的段暫存器——ES(額外段)、FS和GS,它們提供用於儲存資料的額外段。
在彙編程式設計中,程式需要訪問記憶體位置。段內的所有記憶體位置都相對於段的起始地址。段以可被16或十六進位制10整除的地址開始。因此,所有此類記憶體地址中最右邊的十六進位制數字都是0,通常不儲存在段暫存器中。
段暫存器儲存段的起始地址。要獲得段內資料或指令的確切位置,需要一個偏移值(或位移)。要引用段中的任何記憶體位置,處理器將段暫存器中的段地址與位置的偏移值組合。
示例
檢視以下簡單的程式,以瞭解暫存器在彙編程式設計中的用途。此程式在螢幕上顯示9個星號以及一條簡單的訊息:
section .text global _start ;must be declared for linker (gcc) _start: ;tell linker entry point mov edx,len ;message length mov ecx,msg ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov edx,9 ;message length mov ecx,s2 ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel section .data msg db 'Displaying 9 stars',0xa ;a message len equ $ - msg ;length of message s2 times 9 db '*'
編譯並執行上述程式碼後,將產生以下結果:
Displaying 9 stars *********
組合語言 - 系統呼叫
系統呼叫是使用者空間和核心空間之間介面的API。我們已經使用了系統呼叫sys_write和sys_exit,分別用於寫入螢幕和退出程式。
Linux系統呼叫
你可以在彙編程式中使用Linux系統呼叫。要在程式中使用Linux系統呼叫,需要執行以下步驟:
- 將系統呼叫號放入EAX暫存器。
- 將系統呼叫的引數儲存在EBX、ECX等暫存器中。
- 呼叫相關的中斷 (80h)。
- 結果通常返回在EAX暫存器中。
有六個暫存器用於儲存系統呼叫的引數。它們是EBX、ECX、EDX、ESI、EDI和EBP。這些暫存器依次儲存引數,從EBX暫存器開始。如果引數超過六個,則第一個引數的記憶體地址儲存在EBX暫存器中。
以下程式碼片段顯示了系統呼叫sys_exit的使用:
mov eax,1 ; system call number (sys_exit) int 0x80 ; call kernel
以下程式碼片段顯示了系統呼叫sys_write的使用:
mov edx,4 ; message length mov ecx,msg ; message to write mov ebx,1 ; file descriptor (stdout) mov eax,4 ; system call number (sys_write) int 0x80 ; call kernel
所有系統呼叫都列在/usr/include/asm/unistd.h中,以及它們的編號(在呼叫int 80h之前放入EAX中的值)。
下表顯示了本教程中使用的一些系統呼叫:
| %eax | 名稱 | %ebx | %ecx | %edx | %esx | %edi |
|---|---|---|---|---|---|---|
| 1 | sys_exit | int | - | - | - | - |
| 2 | sys_fork | struct pt_regs | - | - | - | - |
| 3 | sys_read | unsigned int | char * | size_t | - | - |
| 4 | sys_write | unsigned int | const char * | size_t | - | - |
| 5 | sys_open | const char * | int | int | - | - |
| 6 | sys_close | unsigned int | - | - | - | - |
示例
以下示例從鍵盤讀取一個數字並將其顯示在螢幕上:
section .data ;Data segment
userMsg db 'Please enter a number: ' ;Ask the user to enter a number
lenUserMsg equ $-userMsg ;The length of the message
dispMsg db 'You have entered: '
lenDispMsg equ $-dispMsg
section .bss ;Uninitialized data
num resb 5
section .text ;Code Segment
global _start
_start: ;User prompt
mov eax, 4
mov ebx, 1
mov ecx, userMsg
mov edx, lenUserMsg
int 80h
;Read and store the user input
mov eax, 3
mov ebx, 2
mov ecx, num
mov edx, 5 ;5 bytes (numeric, 1 for sign) of that information
int 80h
;Output the message 'The entered number is: '
mov eax, 4
mov ebx, 1
mov ecx, dispMsg
mov edx, lenDispMsg
int 80h
;Output the number entered
mov eax, 4
mov ebx, 1
mov ecx, num
mov edx, 5
int 80h
; Exit code
mov eax, 1
mov ebx, 0
int 80h
編譯並執行上述程式碼後,將產生以下結果:
Please enter a number: 1234 You have entered:1234
組合語言 -定址方式
大多數組合語言指令都需要處理運算元。運算元地址提供要處理的資料儲存位置。有些指令不需要運算元,而有些指令可能需要一個、兩個或三個運算元。
當指令需要兩個運算元時,第一個運算元通常是目標運算元,它包含暫存器或記憶體位置中的資料;第二個運算元是源運算元。源運算元包含要傳送的資料(立即定址)或資料的地址(在暫存器或記憶體中)。通常,操作後源資料保持不變。
三種基本的定址方式是:
- 暫存器定址
- 立即定址
- 記憶體定址
暫存器定址
在這種定址方式下,暫存器包含運算元。根據指令的不同,暫存器可以是第一個運算元、第二個運算元或兩者都是。
例如:
MOV DX, TAX_RATE ; Register in first operand MOV COUNT, CX ; Register in second operand MOV EAX, EBX ; Both the operands are in registers
由於暫存器之間的資料處理不涉及記憶體,因此它提供了最快的資料處理速度。
立即定址
立即運算元具有常數值或表示式。當具有兩個運算元的指令使用立即定址時,第一個運算元可以是暫存器或記憶體位置,第二個運算元是立即常數。第一個運算元定義資料的長度。
例如:
BYTE_VALUE DB 150 ; A byte value is defined WORD_VALUE DW 300 ; A word value is defined ADD BYTE_VALUE, 65 ; An immediate operand 65 is added MOV AX, 45H ; Immediate constant 45H is transferred to AX
直接記憶體定址
當運算元以記憶體定址模式指定時,需要直接訪問主記憶體(通常是資料段)。這種定址方式導致資料處理速度較慢。為了找到記憶體中資料的精確位置,我們需要段起始地址(通常在DS暫存器中找到)和偏移值。此偏移值也稱為有效地址。
在直接定址模式下,偏移值直接作為指令的一部分指定,通常由變數名指示。彙編器計算偏移值並維護一個符號表,該符號表儲存程式中使用的所有變數的偏移值。
在直接記憶體定址中,一個運算元引用記憶體位置,另一個運算元引用暫存器。
例如:
ADD BYTE_VALUE, DL ; Adds the register in the memory location MOV BX, WORD_VALUE ; Operand from the memory is added to register
直接偏移定址
這種定址方式使用算術運算子來修改地址。例如,檢視以下定義資料表的定義:
BYTE_TABLE DB 14, 15, 22, 45 ; Tables of bytes WORD_TABLE DW 134, 345, 564, 123 ; Tables of words
以下操作訪問記憶體中表中的資料到暫存器:
MOV CL, BYTE_TABLE[2] ; Gets the 3rd element of the BYTE_TABLE MOV CL, BYTE_TABLE + 2 ; Gets the 3rd element of the BYTE_TABLE MOV CX, WORD_TABLE[3] ; Gets the 4th element of the WORD_TABLE MOV CX, WORD_TABLE + 3 ; Gets the 4th element of the WORD_TABLE
間接記憶體定址
這種定址方式利用計算機的段:偏移定址能力。通常,基址暫存器EBX、EBP(或BX、BP)和索引暫存器(DI、SI)(在記憶體引用中用方括號編碼)用於此目的。
間接定址通常用於包含多個元素的變數,例如陣列。陣列的起始地址儲存在例如EBX暫存器中。
以下程式碼片段顯示瞭如何訪問變數的不同元素。
MY_TABLE TIMES 10 DW 0 ; Allocates 10 words (2 bytes) each initialized to 0 MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX MOV [EBX], 110 ; MY_TABLE[0] = 110 ADD EBX, 2 ; EBX = EBX +2 MOV [EBX], 123 ; MY_TABLE[1] = 123
MOV指令
我們已經使用了MOV指令,它用於將資料從一個儲存空間移動到另一個儲存空間。MOV指令有兩個運算元。
語法
MOV指令的語法如下:
MOV destination, source
MOV指令可能有以下五種形式之一:
MOV register, register MOV register, immediate MOV memory, immediate MOV register, memory MOV memory, register
請注意:
- MOV操作中的兩個運算元大小應相同。
- 源運算元的值保持不變。
MOV指令有時會造成歧義。例如,檢視以下語句:
MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX MOV [EBX], 110 ; MY_TABLE[0] = 110
不清楚您是想移動位元組等效值還是字等效值110。在這種情況下,最好使用型別說明符。
下表顯示了一些常見的型別說明符:
| 型別說明符 | 定址的位元組數 |
|---|---|
| BYTE | 1 |
| WORD | 2 |
| DWORD | 4 |
| QWORD | 8 |
| TBYTE | 10 |
示例
以下程式說明了上面討論的一些概念。它將名稱“Zara Ali”儲存在記憶體的資料段中,然後以程式設計方式將其值更改為另一個名稱“Nuha Ali”,並顯示兩個名稱。
section .text global _start ;must be declared for linker (ld) _start: ;tell linker entry point ;writing the name 'Zara Ali' mov edx,9 ;message length mov ecx, name ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov [name], dword 'Nuha' ; Changed the name to Nuha Ali ;writing the name 'Nuha Ali' mov edx,8 ;message length mov ecx,name ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel section .data name db 'Zara Ali '
編譯並執行上述程式碼後,將產生以下結果:
Zara Ali Nuha Ali
組合語言 - 變數
NASM提供各種定義指令來為變數保留儲存空間。define彙編指令用於分配儲存空間。它可以用於保留和初始化一個或多個位元組。
為已初始化資料分配儲存空間
已初始化資料的儲存分配語句的語法如下:
[variable-name] define-directive initial-value [,initial-value]...
其中,變數名是每個儲存空間的識別符號。彙編器為資料段中定義的每個變數名關聯一個偏移值。
define指令有五種基本形式:
| 指令 | 用途 | 儲存空間 |
|---|---|---|
| DB | 定義位元組 | 分配1個位元組 |
| DW | 定義字 | 分配2個位元組 |
| DD | 定義雙字 | 分配4個位元組 |
| DQ | 定義四字 | 分配8個位元組 |
| DT | 定義十位元組 | 分配10個位元組 |
以下是一些使用define指令的示例:
choice DB 'y' number DW 12345 neg_number DW -12345 big_number DQ 123456789 real_number1 DD 1.234 real_number2 DQ 123.456
請注意:
每個字元的位元組都以十六進位制的ASCII值儲存。
每個十進位制值都自動轉換為其16位二進位制等效值並存儲為十六進位制數。
處理器使用小端位元組序。
負數轉換為其二進位制補碼錶示。
短浮點數和長浮點數分別使用32位或64位表示。
以下程式顯示了define指令的使用:
section .text global _start ;must be declared for linker (gcc) _start: ;tell linker entry point mov edx,1 ;message length mov ecx,choice ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel section .data choice DB 'y'
編譯並執行上述程式碼後,將產生以下結果:
y
為未初始化資料分配儲存空間
reserve指令用於為未初始化資料保留空間。reserve指令接受一個運算元,該運算元指定要保留的空間單位數。每個define指令都有一個相關的reserve指令。
reserve指令有五種基本形式:
| 指令 | 用途 |
|---|---|
| RESB | 保留一個位元組 |
| RESW | 保留一個字 |
| RESD | 保留一個雙字 |
| RESQ | 保留一個四字 |
| REST | 保留十個位元組 |
多個定義
程式中可以有多個數據定義語句。例如:
choice DB 'Y' ;ASCII of y = 79H number1 DW 12345 ;12345D = 3039H number2 DD 12345679 ;123456789D = 75BCD15H
彙編器為多個變數定義分配連續記憶體。
多個初始化
TIMES指令允許對相同值進行多次初始化。例如,可以使用以下語句定義大小為9的名為marks的陣列並將其初始化為零:
marks TIMES 9 DW 0
TIMES指令在定義陣列和表時很有用。以下程式在螢幕上顯示9個星號:
section .text global _start ;must be declared for linker (ld) _start: ;tell linker entry point mov edx,9 ;message length mov ecx, stars ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel section .data stars times 9 db '*'
編譯並執行上述程式碼後,將產生以下結果:
*********
組合語言 - 常量
NASM提供了一些指令來定義常量。我們已經在前面的章節中使用了EQU指令。我們將特別討論三個指令:
- EQU
- %assign
- %define
EQU指令
EQU指令用於定義常量。EQU指令的語法如下:
CONSTANT_NAME EQU expression
例如:
TOTAL_STUDENTS equ 50
然後,您可以在程式碼中使用此常量值,例如:
mov ecx, TOTAL_STUDENTS cmp eax, TOTAL_STUDENTS
EQU語句的運算元可以是表示式:
LENGTH equ 20 WIDTH equ 10 AREA equ length * width
上面的程式碼段將AREA定義為200。
示例
以下示例說明了EQU指令的使用:
SYS_EXIT equ 1 SYS_WRITE equ 4 STDIN equ 0 STDOUT equ 1 section .text global _start ;must be declared for using gcc _start: ;tell linker entry point mov eax, SYS_WRITE mov ebx, STDOUT mov ecx, msg1 mov edx, len1 int 0x80 mov eax, SYS_WRITE mov ebx, STDOUT mov ecx, msg2 mov edx, len2 int 0x80 mov eax, SYS_WRITE mov ebx, STDOUT mov ecx, msg3 mov edx, len3 int 0x80 mov eax,SYS_EXIT ;system call number (sys_exit) int 0x80 ;call kernel section .data msg1 db 'Hello, programmers!',0xA,0xD len1 equ $ - msg1 msg2 db 'Welcome to the world of,', 0xA,0xD len2 equ $ - msg2 msg3 db 'Linux assembly programming! ' len3 equ $- msg3
編譯並執行上述程式碼後,將產生以下結果:
Hello, programmers! Welcome to the world of, Linux assembly programming!
%assign指令
%assign指令可用於定義類似於EQU指令的數字常量。此指令允許重新定義。例如,您可以將常量TOTAL定義為:
%assign TOTAL 10
稍後在程式碼中,您可以將其重新定義為:
%assign TOTAL 20
此指令區分大小寫。
%define指令
%define指令允許定義數字和字串常量。此指令類似於C語言中的#define。例如,您可以將常量PTR定義為:
%define PTR [EBP+4]
上面的程式碼將PTR替換為[EBP+4]。
此指令也允許重新定義,並且區分大小寫。
組合語言 - 算術指令
INC指令
INC指令用於將運算元遞增一。它作用於單個運算元,該運算元可以位於暫存器中或記憶體中。
語法
INC指令具有以下語法:
INC destination
運算元destination可以是8位、16位或32位運算元。
示例
INC EBX ; Increments 32-bit register INC DL ; Increments 8-bit register INC [count] ; Increments the count variable
DEC指令
DEC指令用於將運算元遞減一。它作用於單個運算元,該運算元可以位於暫存器中或記憶體中。
語法
DEC指令具有以下語法:
DEC destination
運算元destination可以是8位、16位或32位運算元。
示例
segment .data count dw 0 value db 15 segment .text inc [count] dec [value] mov ebx, count inc word [ebx] mov esi, value dec byte [esi]
ADD和SUB指令
ADD和SUB指令用於對位元組、字和雙字大小的二進位制資料執行簡單的加/減運算,即分別對8位、16位或32位運算元進行加法或減法運算。
語法
ADD和SUB指令具有以下語法:
ADD/SUB destination, source
ADD/SUB指令可以在以下之間進行:
- 暫存器到暫存器
- 記憶體到暫存器
- 暫存器到記憶體
- 暫存器到常量資料
- 記憶體到常量資料
然而,與其他指令一樣,ADD/SUB指令無法執行記憶體到記憶體的操作。ADD或SUB操作會設定或清除溢位和進位標誌。
示例
下面的例子將向用戶詢問兩個數字,分別將這些數字儲存在EAX和EBX暫存器中,將這些值相加,將結果儲存在記憶體位置“res”中,最後顯示結果。
SYS_EXIT equ 1 SYS_READ equ 3 SYS_WRITE equ 4 STDIN equ 0 STDOUT equ 1 segment .data msg1 db "Enter a digit ", 0xA,0xD len1 equ $- msg1 msg2 db "Please enter a second digit", 0xA,0xD len2 equ $- msg2 msg3 db "The sum is: " len3 equ $- msg3 segment .bss num1 resb 2 num2 resb 2 res resb 1 section .text global _start ;must be declared for using gcc _start: ;tell linker entry point mov eax, SYS_WRITE mov ebx, STDOUT mov ecx, msg1 mov edx, len1 int 0x80 mov eax, SYS_READ mov ebx, STDIN mov ecx, num1 mov edx, 2 int 0x80 mov eax, SYS_WRITE mov ebx, STDOUT mov ecx, msg2 mov edx, len2 int 0x80 mov eax, SYS_READ mov ebx, STDIN mov ecx, num2 mov edx, 2 int 0x80 mov eax, SYS_WRITE mov ebx, STDOUT mov ecx, msg3 mov edx, len3 int 0x80 ; moving the first number to eax register and second number to ebx ; and subtracting ascii '0' to convert it into a decimal number mov eax, [num1] sub eax, '0' mov ebx, [num2] sub ebx, '0' ; add eax and ebx add eax, ebx ; add '0' to to convert the sum from decimal to ASCII add eax, '0' ; storing the sum in memory location res mov [res], eax ; print the sum mov eax, SYS_WRITE mov ebx, STDOUT mov ecx, res mov edx, 1 int 0x80 exit: mov eax, SYS_EXIT xor ebx, ebx int 0x80
編譯並執行上述程式碼後,將產生以下結果:
Enter a digit: 3 Please enter a second digit: 4 The sum is: 7
使用硬編碼變數的程式:
section .text global _start ;must be declared for using gcc _start: ;tell linker entry point mov eax,'3' sub eax, '0' mov ebx, '4' sub ebx, '0' add eax, ebx add eax, '0' mov [sum], eax mov ecx,msg mov edx, len mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov ecx,sum mov edx, 1 mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel section .data msg db "The sum is:", 0xA,0xD len equ $ - msg segment .bss sum resb 1
編譯並執行上述程式碼後,將產生以下結果:
The sum is: 7
MUL/IMUL指令
有兩條指令用於乘法二進位制資料。MUL(乘法)指令處理無符號資料,而IMUL(整數乘法)指令處理有符號資料。這兩條指令都會影響進位和溢位標誌。
語法
MUL/IMUL指令的語法如下:
MUL/IMUL multiplier
在這兩種情況下,被乘數都在累加器中,取決於被乘數和乘數的大小,生成的乘積也儲存在兩個暫存器中,取決於運算元的大小。下一節將解釋三種不同情況下的MUL指令:
| 序號 | 場景 |
|---|---|
| 1 | 當兩個位元組相乘時: 被乘數在AL暫存器中,乘數是記憶體或另一個暫存器中的一個位元組。乘積在AX中。乘積的高8位儲存在AH中,低8位儲存在AL中。
|
| 2 | 當兩個字值相乘時: 被乘數應在AX暫存器中,乘數是記憶體或另一個暫存器中的一個字。例如,對於像MUL DX這樣的指令,必須將乘數儲存在DX中,將被乘數儲存在AX中。 結果乘積是一個雙字,需要兩個暫存器。高位(最左邊)部分儲存在DX中,低位(最右邊)部分儲存在AX中。
|
| 3 | 當兩個雙字值相乘時: 當兩個雙字值相乘時,被乘數應在EAX中,乘數是儲存在記憶體或另一個暫存器中的一個雙字值。生成的乘積儲存在EDX:EAX暫存器中,即高32位儲存在EDX暫存器中,低32位儲存在EAX暫存器中。
|



示例
MOV AL, 10 MOV DL, 25 MUL DL ... MOV DL, 0FFH ; DL= -1 MOV AL, 0BEH ; AL = -66 IMUL DL
示例
下面的例子將3乘以2,並顯示結果:
section .text global _start ;must be declared for using gcc _start: ;tell linker entry point mov al,'3' sub al, '0' mov bl, '2' sub bl, '0' mul bl add al, '0' mov [res], al mov ecx,msg mov edx, len mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov ecx,res mov edx, 1 mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel section .data msg db "The result is:", 0xA,0xD len equ $- msg segment .bss res resb 1
編譯並執行上述程式碼後,將產生以下結果:
The result is: 6
DIV/IDIV指令
除法運算生成兩個元素——**商**和**餘數**。在乘法情況下,不會發生溢位,因為使用雙長度暫存器來儲存乘積。但是,在除法情況下,可能會發生溢位。如果發生溢位,處理器將生成中斷。
DIV(除法)指令用於無符號資料,而IDIV(整數除法)指令用於有符號資料。
語法
DIV/IDIV指令的格式:
DIV/IDIV divisor
被除數在累加器中。這兩個指令都可以處理8位、16位或32位運算元。該操作影響所有六個狀態標誌。下一節將解釋三種不同運算元大小的除法情況:
| 序號 | 場景 |
|---|---|
| 1 | 當除數為1位元組時: 假定被除數在AX暫存器(16位)中。除法後,商進入AL暫存器,餘數進入AH暫存器。
|
| 2 | 當除數為1字時: 假定被除數為32位長,位於DX:AX暫存器中。高16位在DX中,低16位在AX中。除法後,16位商進入AX暫存器,16位餘數進入DX暫存器。
|
| 3 | 當除數為雙字時: 假定被除數為64位長,位於EDX:EAX暫存器中。高32位在EDX中,低32位在EAX中。除法後,32位商進入EAX暫存器,32位餘數進入EDX暫存器。
|



示例
下面的例子將8除以2。**被除數8**儲存在**16位AX暫存器**中,**除數2**儲存在**8位BL暫存器**中。
section .text global _start ;must be declared for using gcc _start: ;tell linker entry point mov ax,'8' sub ax, '0' mov bl, '2' sub bl, '0' div bl add ax, '0' mov [res], ax mov ecx,msg mov edx, len mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov ecx,res mov edx, 1 mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel section .data msg db "The result is:", 0xA,0xD len equ $- msg segment .bss res resb 1
編譯並執行上述程式碼後,將產生以下結果:
The result is: 4
組合語言 - 邏輯指令
處理器指令集提供了AND、OR、XOR、TEST和NOT布林邏輯指令,這些指令根據程式的需要測試、設定和清除位。
這些指令的格式:
| 序號 | 指令 | 格式 |
|---|---|---|
| 1 | AND | AND operand1, operand2 |
| 2 | OR | OR operand1, operand2 |
| 3 | XOR | XOR operand1, operand2 |
| 4 | TEST | TEST operand1, operand2 |
| 5 | NOT | NOT operand1 |
在所有情況下,第一個運算元都可以位於暫存器或記憶體中。第二個運算元可以位於暫存器/記憶體中,也可以是立即數(常量)值。但是,記憶體到記憶體的操作是不可能的。這些指令比較或匹配運算元的位,並設定CF、OF、PF、SF和ZF標誌。
AND指令
AND指令用於透過執行按位AND運算來支援邏輯表示式。如果來自兩個運算元的匹配位都是1,則按位AND運算返回1,否則返回0。例如:
Operand1: 0101
Operand2: 0011
----------------------------
After AND -> Operand1: 0001
AND運算可用於清除一個或多個位。例如,假設BL暫存器包含0011 1010。如果需要將高位清零,則將其與0FH進行AND運算。
AND BL, 0FH ; This sets BL to 0000 1010
讓我們來看另一個例子。如果要檢查給定的數字是奇數還是偶數,一個簡單的測試是檢查數字的最低有效位。如果它是1,則該數字是奇數,否則是偶數。
假設該數字在AL暫存器中,我們可以編寫:
AND AL, 01H ; ANDing with 0000 0001 JZ EVEN_NUMBER
下面的程式演示了這一點:
示例
section .text global _start ;must be declared for using gcc _start: ;tell linker entry point mov ax, 8h ;getting 8 in the ax and ax, 1 ;and ax with 1 jz evnn mov eax, 4 ;system call number (sys_write) mov ebx, 1 ;file descriptor (stdout) mov ecx, odd_msg ;message to write mov edx, len2 ;length of message int 0x80 ;call kernel jmp outprog evnn: mov ah, 09h mov eax, 4 ;system call number (sys_write) mov ebx, 1 ;file descriptor (stdout) mov ecx, even_msg ;message to write mov edx, len1 ;length of message int 0x80 ;call kernel outprog: mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel section .data even_msg db 'Even Number!' ;message showing even number len1 equ $ - even_msg odd_msg db 'Odd Number!' ;message showing odd number len2 equ $ - odd_msg
編譯並執行上述程式碼後,將產生以下結果:
Even Number!
將ax暫存器中的值更改為奇數,例如:
mov ax, 9h ; getting 9 in the ax
程式將顯示
Odd Number!
同樣,要清除整個暫存器,可以將其與00H進行AND運算。
OR指令
OR指令用於透過執行按位OR運算來支援邏輯表示式。如果來自一個或兩個運算元的匹配位為一,則按位OR運算子返回1。如果兩個位都是零,則返回0。
例如:
Operand1: 0101
Operand2: 0011
----------------------------
After OR -> Operand1: 0111
OR運算可用於設定一個或多個位。例如,假設AL暫存器包含0011 1010,需要設定四個低位,可以將其與值0000 1111,即FH進行OR運算。
OR BL, 0FH ; This sets BL to 0011 1111
示例
下面的例子演示了OR指令。讓我們分別在AL和BL暫存器中儲存值5和3,然後指令:
OR AL, BL
應在AL暫存器中儲存7:
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov al, 5 ;getting 5 in the al
mov bl, 3 ;getting 3 in the bl
or al, bl ;or al and bl registers, result should be 7
add al, byte '0' ;converting decimal to ascii
mov [result], al
mov eax, 4
mov ebx, 1
mov ecx, result
mov edx, 1
int 0x80
outprog:
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .bss
result resb 1
編譯並執行上述程式碼後,將產生以下結果:
7
XOR指令
XOR指令實現按位XOR運算。XOR運算僅當運算元的位不同時,才將結果位設定為1。如果運算元的位相同(都是0或都是1),則結果位將被清除為0。
例如:
Operand1: 0101
Operand2: 0011
----------------------------
After XOR -> Operand1: 0110
將運算元與自身進行**XOR**運算會將運算元更改為**0**。這用於清除暫存器。
XOR EAX, EAX
TEST指令
TEST指令的工作方式與AND運算相同,但與AND指令不同,它不會更改第一個運算元。因此,如果需要檢查暫存器中的數字是偶數還是奇數,也可以使用TEST指令而不更改原始數字。
TEST AL, 01H JZ EVEN_NUMBER
NOT指令
NOT指令實現按位NOT運算。NOT運算反轉運算元中的位。運算元可以位於暫存器或記憶體中。
例如:
Operand1: 0101 0011 After NOT -> Operand1: 1010 1100
組合語言 - 條件語句
組合語言中的條件執行是通過幾個迴圈和分支指令完成的。這些指令可以改變程式的控制流程。條件執行在兩種情況下觀察到:
| 序號 | 條件指令 |
|---|---|
| 1 | 無條件跳轉 這是由JMP指令執行的。條件執行通常涉及將控制轉移到當前正在執行的指令之後不跟隨的指令的地址。控制轉移可以是向前的,以執行一組新的指令,也可以是向後的,以重新執行相同的步驟。 |
| 2 | 條件跳轉 這是由一組跳轉指令j<condition>根據條件執行的。條件指令透過中斷順序流來轉移控制,它們透過更改IP中的偏移值來實現。 |
在討論條件指令之前,讓我們先討論CMP指令。
CMP指令
CMP指令比較兩個運算元。它通常用於條件執行。這條指令基本上是從另一個運算元中減去一個運算元,以比較運算元是否相等。它不會干擾目標運算元或源運算元。它與條件跳轉指令一起用於決策。
語法
CMP destination, source
CMP比較兩個數值資料欄位。目標運算元可以位於暫存器或記憶體中。源運算元可以是常量(立即數)資料、暫存器或記憶體。
示例
CMP DX, 00 ; Compare the DX value with zero JE L7 ; If yes, then jump to label L7 . . L7: ...
CMP經常用於比較計數器值是否已達到迴圈需要執行的次數。考慮以下典型條件:
INC EDX CMP EDX, 10 ; Compares whether the counter has reached 10 JLE LP1 ; If it is less than or equal to 10, then jump to LP1
無條件跳轉
如前所述,這是由JMP指令執行的。條件執行通常涉及將控制轉移到當前正在執行的指令之後不跟隨的指令的地址。控制轉移可以是向前的,以執行一組新的指令,也可以是向後的,以重新執行相同的步驟。
語法
JMP指令提供一個標籤名稱,控制流將立即轉移到該標籤名稱。JMP指令的語法是:
JMP label
示例
下面的程式碼片段演示了JMP指令:
MOV AX, 00 ; Initializing AX to 0 MOV BX, 00 ; Initializing BX to 0 MOV CX, 01 ; Initializing CX to 1 L20: ADD AX, 01 ; Increment AX ADD BX, AX ; Add AX to BX SHL CX, 1 ; shift left CX, this in turn doubles the CX value JMP L20 ; repeats the statements
條件跳轉
如果在條件跳轉中滿足某些指定的條件,則控制流將轉移到目標指令。根據條件和資料,存在許多條件跳轉指令。
以下是用於算術運算的有符號資料中使用的條件跳轉指令:
| 指令 | 描述 | 測試的標誌 |
|---|---|---|
| JE/JZ | 跳轉相等或跳轉零 | ZF |
| JNE/JNZ | 跳轉不相等或跳轉非零 | ZF |
| JG/JNLE | 跳轉大於或跳轉非小於/等於 | OF, SF, ZF |
| JGE/JNL | 跳轉大於/等於或跳轉非小於 | OF, SF |
| JL/JNGE | 跳轉小於或跳轉非大於/等於 | OF, SF |
| JLE/JNG | 跳轉小於/等於或跳轉非大於 | OF, SF, ZF |
以下是用於邏輯運算的無符號資料中使用的條件跳轉指令:
| 指令 | 描述 | 測試的標誌 |
|---|---|---|
| JE/JZ | 跳轉相等或跳轉零 | ZF |
| JNE/JNZ | 跳轉不相等或跳轉非零 | ZF |
| JA/JNBE | 跳轉高於或跳轉非低於/等於 | CF, ZF |
| JAE/JNB | 跳轉高於/等於或跳轉非低於 | CF |
| JB/JNAE | 跳轉低於或跳轉非高於/等於 | CF |
| JBE/JNA | 跳轉低於/等於或跳轉非高於 | AF, CF |
以下條件跳轉指令具有特殊用途,並檢查標誌的值:
| 指令 | 描述 | 測試的標誌 |
|---|---|---|
| JXCZ | 如果CX為零則跳轉 | 無 |
| JC | 如果進位則跳轉 | CF |
| JNC | 如果沒有進位則跳轉 | CF |
| JO | 如果溢位則跳轉 | OF |
| JNO | 如果沒有溢位則跳轉 | OF |
| JP/JPE | 跳轉奇偶校驗或跳轉奇偶校驗偶數 | PF |
| JNP/JPO | 跳轉非奇偶校驗或跳轉奇偶校驗奇數 | PF |
| JS | 跳轉符號(負值) | SF |
| JNS | 跳轉無符號(正值) | SF |
J<condition>指令集的語法:
示例:
CMP AL, BL JE EQUAL CMP AL, BH JE EQUAL CMP AL, CL JE EQUAL NON_EQUAL: ... EQUAL: ...
示例
下面的程式顯示三個變數中最大的一個。這些變數是兩位數變數。三個變數num1、num2和num3的值分別為47、22和31:
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx, [num1]
cmp ecx, [num2]
jg check_third_num
mov ecx, [num2]
check_third_num:
cmp ecx, [num3]
jg _exit
mov ecx, [num3]
_exit:
mov [largest], ecx
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,largest
mov edx, 2
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax, 1
int 80h
section .data
msg db "The largest digit is: ", 0xA,0xD
len equ $- msg
num1 dd '47'
num2 dd '22'
num3 dd '31'
segment .bss
largest resb 2
編譯並執行上述程式碼後,將產生以下結果:
The largest digit is: 47
組合語言 - 迴圈語句
JMP指令可用於實現迴圈。例如,下面的程式碼片段可用於執行迴圈體10次。
MOV CL, 10 L1: <LOOP-BODY> DEC CL JNZ L1
但是,處理器指令集包含一組迴圈指令來實現迭代。基本的LOOP指令具有以下語法:
LOOP label
其中,label是標識目標指令的目標標籤,如跳轉指令中所示。LOOP指令假定**ECX暫存器包含迴圈計數**。當執行迴圈指令時,ECX暫存器將遞減,並且控制跳轉到目標標籤,直到ECX暫存器值(即計數器)達到零。
上面的程式碼片段可以寫成:
mov ECX,10 l1: <loop body> loop l1
示例
下面的程式在螢幕上列印數字1到9:
section .text global _start ;must be declared for using gcc _start: ;tell linker entry point mov ecx,10 mov eax, '1' l1: mov [num], eax mov eax, 4 mov ebx, 1 push ecx mov ecx, num mov edx, 1 int 0x80 mov eax, [num] sub eax, '0' inc eax add eax, '0' pop ecx loop l1 mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel section .bss num resb 1
編譯並執行上述程式碼後,將產生以下結果:
123456789:
組合語言 - 數字
數值資料通常以二進位制形式表示。算術指令對二進位制資料進行操作。當數字顯示在螢幕上或從鍵盤輸入時,它們採用ASCII碼形式。
到目前為止,我們已經將ASCII碼形式的輸入資料轉換為二進位制形式進行算術運算,並將結果轉換回ASCII碼形式。以下程式碼顯示了這一點:
section .text global _start ;must be declared for using gcc _start: ;tell linker entry point mov eax,'3' sub eax, '0' mov ebx, '4' sub ebx, '0' add eax, ebx add eax, '0' mov [sum], eax mov ecx,msg mov edx, len mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov ecx,sum mov edx, 1 mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel section .data msg db "The sum is:", 0xA,0xD len equ $ - msg segment .bss sum resb 1
編譯並執行上述程式碼後,將產生以下結果:
The sum is: 7
然而,這種轉換有一定的開銷,組合語言程式設計允許以更有效的方式(二進位制形式)處理數字。十進位制數可以表示為兩種形式:
- ASCII碼形式
- BCD碼(二進位制編碼的十進位制)形式
ASCII碼錶示
在ASCII碼錶示中,十進位制數儲存為ASCII字元的字串。例如,十進位制值1234儲存為:
31 32 33 34H
其中,31H是1的ASCII碼值,32H是2的ASCII碼值,依此類推。有四條指令用於處理ASCII碼錶示的數字:
AAA - 加法後ASCII碼調整
AAS - 減法後ASCII碼調整
AAM - 乘法後ASCII碼調整
AAD - 除法前ASCII碼調整
這些指令不接受任何運算元,並假設所需的運算元位於AL暫存器中。
以下示例使用AAS指令演示此概念:
section .text global _start ;must be declared for using gcc _start: ;tell linker entry point sub ah, ah mov al, '9' sub al, '3' aas or al, 30h mov [res], ax mov edx,len ;message length mov ecx,msg ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov edx,1 ;message length mov ecx,res ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel section .data msg db 'The Result is:',0xa len equ $ - msg section .bss res resb 1
編譯並執行上述程式碼後,將產生以下結果:
The Result is: 6
BCD碼錶示
BCD碼錶示有兩種型別:
- 非壓縮BCD碼錶示
- 壓縮BCD碼錶示
在非壓縮BCD碼錶示中,每個位元組儲存一個十進位制數字的二進位制等效值。例如,數字1234儲存為:
01 02 03 04H
有兩種指令用於處理這些數字:
AAM - 乘法後ASCII碼調整
AAD - 除法前ASCII碼調整
四條ASCII碼調整指令AAA、AAS、AAM和AAD也可以用於非壓縮BCD碼錶示。在壓縮BCD碼錶示中,每個數字使用四位儲存。兩個十進位制數字打包到一個位元組中。例如,數字1234儲存為:
12 34H
有兩種指令用於處理這些數字:
DAA - 加法後十進位制調整
DAS - 減法後十進位制調整
壓縮BCD碼錶示不支援乘法和除法。
示例
以下程式將兩個5位十進位制數相加並顯示和。它使用了上述概念:
section .text global _start ;must be declared for using gcc _start: ;tell linker entry point mov esi, 4 ;pointing to the rightmost digit mov ecx, 5 ;num of digits clc add_loop: mov al, [num1 + esi] adc al, [num2 + esi] aaa pushf or al, 30h popf mov [sum + esi], al dec esi loop add_loop mov edx,len ;message length mov ecx,msg ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov edx,5 ;message length mov ecx,sum ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel section .data msg db 'The Sum is:',0xa len equ $ - msg num1 db '12345' num2 db '23456' sum db ' '
編譯並執行上述程式碼後,將產生以下結果:
The Sum is: 35801
組合語言 - 字串
在我們之前的示例中,我們已經使用了變長字串。變長字串可以包含任意數量的字元。通常,我們透過以下兩種方式之一指定字串的長度:
- 顯式儲存字串長度
- 使用哨兵字元
我們可以使用表示位置計數器當前值的$位置計數器符號來顯式儲存字串長度。在下面的示例中:
msg db 'Hello, world!',0xa ;our dear string len equ $ - msg ;length of our dear string
$指向字串變數msg最後一個字元後面的位元組。因此,$-msg給出字串的長度。我們也可以寫
msg db 'Hello, world!',0xa ;our dear string len equ 13 ;length of our dear string
或者,您可以使用尾隨哨兵字元來分隔字串,而不是顯式儲存字串長度。哨兵字元應為字串中不會出現的特殊字元。
例如:
message DB 'I am loving it!', 0
字串指令
每個字串指令可能需要一個源運算元、一個目標運算元或兩者兼有。對於32位段,字串指令使用ESI和EDI暫存器分別指向源運算元和目標運算元。
但是,對於16位段,使用SI和DI暫存器分別指向源和目標。
有五條基本的字串處理指令。它們是:
MOVS - 此指令將1位元組、字或雙字的資料從一個記憶體位置移動到另一個記憶體位置。
LODS - 此指令從記憶體載入資料。如果運算元為一個位元組,則將其載入到AL暫存器中;如果運算元為一個字,則將其載入到AX暫存器中;如果運算元為雙字,則將其載入到EAX暫存器中。
STOS - 此指令將資料從暫存器(AL、AX或EAX)儲存到記憶體。
CMPS - 此指令比較記憶體中的兩個資料項。資料可以是位元組大小、字或雙字。
SCAS - 此指令將暫存器(AL、AX或EAX)的內容與記憶體中一項的內容進行比較。
上述每條指令都有位元組、字和雙字版本,並且可以透過使用重複字首來重複字串指令。
這些指令使用ES:DI和DS:SI暫存器對,其中DI和SI暫存器包含有效的偏移地址,這些地址指向儲存在記憶體中的位元組。SI通常與DS(資料段)相關聯,DI始終與ES(附加段)相關聯。
DS:SI(或ESI)和ES:DI(或EDI)暫存器分別指向源運算元和目標運算元。源運算元假定位於記憶體中的DS:SI(或ESI),目標運算元位於ES:DI(或EDI)。
對於16位地址,使用SI和DI暫存器;對於32位地址,使用ESI和EDI暫存器。
下表提供了字串指令的各種版本以及運算元的假定空間。
| 基本指令 | 運算元位於 | 位元組操作 | 字操作 | 雙字操作 |
|---|---|---|---|---|
| MOVS | ES:DI, DS:SI | MOVSB | MOVSW | MOVSD |
| LODS | AX, DS:SI | LODSB | LODSW | LODSD |
| STOS | ES:DI, AX | STOSB | STOSW | STOSD |
| CMPS | DS:SI, ES: DI | CMPSB | CMPSW | CMPSD |
| SCAS | ES:DI, AX | SCASB | SCASW | SCASD |
重複字首
當在字串指令之前設定REP字首時,例如REP MOVSB,會導致根據放置在CX暫存器中的計數器重複指令。REP執行指令,將CX減1,並檢查CX是否為零。它重複指令處理,直到CX為零。
方向標誌(DF)決定操作的方向。
- 使用CLD(清除方向標誌,DF = 0)使操作從左到右。
- 使用STD(設定方向標誌,DF = 1)使操作從右到左。
REP字首也有以下變體:
REP:它是無條件重複。它重複操作,直到CX為零。
REPE或REPZ:它是條件重複。當零標誌指示相等/零時,它重複操作。當ZF指示不相等/零或CX為零時,它停止。
REPNE或REPNZ:它也是條件重複。當零標誌指示不相等/零時,它重複操作。當ZF指示相等/零或CX遞減到零時,它停止。
組合語言 - 陣列
我們已經討論過,資料定義指令用於為變數分配儲存空間。變數也可以用一些特定值初始化。初始化值可以以十六進位制、十進位制或二進位制形式指定。
例如,我們可以透過以下任一方式定義一個字變數'months':
MONTHS DW 12 MONTHS DW 0CH MONTHS DW 0110B
資料定義指令也可以用於定義一維陣列。讓我們定義一個一維數字陣列。
NUMBERS DW 34, 45, 56, 67, 75, 89
上述定義聲明瞭一個包含六個字的陣列,每個字都初始化為34、45、56、67、75、89。這分配了2x6 = 12個連續的記憶體空間位元組。第一個數字的符號地址將為NUMBERS,第二個數字的符號地址將為NUMBERS + 2,依此類推。
讓我們來看另一個例子。您可以定義一個名為inventory大小為8的陣列,並將所有值初始化為零,如下所示:
INVENTORY DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
可以簡寫為:
INVENTORY DW 0, 0 , 0 , 0 , 0 , 0 , 0 , 0
TIMES指令也可以用於對相同值進行多次初始化。使用TIMES,INVENTORY陣列可以定義為
INVENTORY TIMES 8 DW 0
示例
以下示例透過定義一個包含三個值的3元素陣列x(儲存三個值:2、3和4)來演示上述概念。它將陣列中的值相加並顯示和9:
section .text global _start ;must be declared for linker (ld) _start: mov eax,3 ;number bytes to be summed mov ebx,0 ;EBX will store the sum mov ecx, x ;ECX will point to the current element to be summed top: add ebx, [ecx] add ecx,1 ;move pointer to next element dec eax ;decrement counter jnz top ;if counter not 0, then loop again done: add ebx, '0' mov [sum], ebx ;done, store result in "sum" display: mov edx,1 ;message length mov ecx, sum ;message to write mov ebx, 1 ;file descriptor (stdout) mov eax, 4 ;system call number (sys_write) int 0x80 ;call kernel mov eax, 1 ;system call number (sys_exit) int 0x80 ;call kernel section .data global x x: db 2 db 4 db 3 sum: db 0
編譯並執行上述程式碼後,將產生以下結果:
9
組合語言 - 過程
過程或子程式在組合語言中非常重要,因為組合語言程式往往很大。過程由名稱標識。在該名稱之後,描述執行明確定義的任務的過程體。過程的結束由return語句指示。
語法
以下是定義過程的語法:
proc_name: procedure body ... ret
透過使用CALL指令從另一個函式呼叫過程。CALL指令應將被呼叫過程的名稱作為引數,如下所示:
CALL proc_name
被呼叫過程使用RET指令將控制權返回給呼叫過程。
示例
讓我們編寫一個名為sum的非常簡單的過程,它將儲存在ECX和EDX暫存器中的變數相加,並將和返回到EAX暫存器:
section .text global _start ;must be declared for using gcc _start: ;tell linker entry point mov ecx,'4' sub ecx, '0' mov edx, '5' sub edx, '0' call sum ;call sum procedure mov [res], eax mov ecx, msg mov edx, len mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel mov ecx, res mov edx, 1 mov ebx, 1 ;file descriptor (stdout) mov eax, 4 ;system call number (sys_write) int 0x80 ;call kernel mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel sum: mov eax, ecx add eax, edx add eax, '0' ret section .data msg db "The sum is:", 0xA,0xD len equ $- msg segment .bss res resb 1
編譯並執行上述程式碼後,將產生以下結果:
The sum is: 9
堆疊資料結構
堆疊是記憶體中類似陣列的資料結構,可以在其中儲存資料並從稱為堆疊“頂部”的位置刪除資料。需要儲存的資料被“壓入”堆疊,需要檢索的資料被從堆疊“彈出”。堆疊是後進先出(LIFO)資料結構,即首先儲存的資料最後檢索。
組合語言提供兩個堆疊操作指令:PUSH和POP。這些指令的語法如下:
PUSH operand POP address/register
堆疊段中保留的記憶體空間用於實現堆疊。SS和ESP(或SP)暫存器用於實現堆疊。堆疊頂部指向插入堆疊的最後一個數據項,由SS:ESP暫存器指向,其中SS暫存器指向堆疊段的開頭,SP(或ESP)給出堆疊段中的偏移量。
堆疊實現具有以下特性:
只能將字或雙字儲存到堆疊中,不能儲存位元組。
堆疊按反方向增長,即朝向較低的記憶體地址。
堆疊頂部指向插入堆疊的最後一項;它指向插入的最後一個字的低位位元組。
正如我們討論的,在使用暫存器進行某些用途之前,可以將暫存器的值儲存在堆疊中;這可以透過以下方式完成:
; Save the AX and BX registers in the stack PUSH AX PUSH BX ; Use the registers for other purpose MOV AX, VALUE1 MOV BX, VALUE2 ... MOV VALUE1, AX MOV VALUE2, BX ; Restore the original values POP BX POP AX
示例
以下程式顯示整個ASCII字元集。主程式呼叫一個名為display的過程,該過程顯示ASCII字元集。
section .text global _start ;must be declared for using gcc _start: ;tell linker entry point call display mov eax,1 ;system call number (sys_exit) int 0x80 ;call kernel display: mov ecx, 256 next: push ecx mov eax, 4 mov ebx, 1 mov ecx, achar mov edx, 1 int 80h pop ecx mov dx, [achar] cmp byte [achar], 0dh inc byte [achar] loop next ret section .data achar db '0'
編譯並執行上述程式碼後,將產生以下結果:
0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}
...
...
組合語言 - 遞迴
遞迴過程是一個呼叫自身的程式。遞迴有兩種:直接遞迴和間接遞迴。在直接遞迴中,過程呼叫自身;在間接遞迴中,第一個過程呼叫第二個過程,而第二個過程又呼叫第一個過程。
遞迴可以在許多數學演算法中觀察到。例如,考慮計算一個數字的階乘的情況。一個數字的階乘由以下等式給出:
Fact (n) = n * fact (n-1) for n > 0
例如:5的階乘是1 x 2 x 3 x 4 x 5 = 5 x 4的階乘,這可以很好地作為顯示遞迴過程的例子。每個遞迴演算法都必須有一個結束條件,即當滿足某個條件時,程式的遞迴呼叫應該停止。在階乘演算法的情況下,當n為0時達到結束條件。
以下程式顯示瞭如何在組合語言中實現n的階乘。為了使程式簡單,我們將計算3的階乘。
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov bx, 3 ;for calculating factorial 3
call proc_fact
add ax, 30h
mov [fact], ax
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,1 ;message length
mov ecx,fact ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
proc_fact:
cmp bl, 1
jg do_calculation
mov ax, 1
ret
do_calculation:
dec bl
call proc_fact
inc bl
mul bl ;ax = al * bl
ret
section .data
msg db 'Factorial 3 is:',0xa
len equ $ - msg
section .bss
fact resb 1
編譯並執行上述程式碼後,將產生以下結果:
Factorial 3 is: 6
組合語言 - 宏
編寫宏是確保組合語言中模組化程式設計的另一種方法。
宏是一系列指令,由名稱分配,可以在程式的任何位置使用。
在NASM中,宏使用%macro和%endmacro指令定義。
宏以%macro指令開頭,以%endmacro指令結尾。
宏定義的語法:
%macro macro_name number_of_params <macro body> %endmacro
其中,number_of_params指定引數數量,macro_name指定宏的名稱。
宏的呼叫方法是使用宏名稱以及必要的引數。當您需要在程式中多次使用某一串指令時,可以將這些指令放入宏中,然後使用宏,而無需每次都編寫這些指令。
例如,程式的一個非常常見的需求是在螢幕上寫入一串字元。要顯示一串字元,需要以下指令序列:
mov edx,len ;message length mov ecx,msg ;message to write mov ebx,1 ;file descriptor (stdout) mov eax,4 ;system call number (sys_write) int 0x80 ;call kernel
在上例顯示字元字串中,INT 80H 函式呼叫使用了暫存器 EAX、EBX、ECX 和 EDX。因此,每次需要在螢幕上顯示內容時,都需要將這些暫存器儲存在堆疊中,呼叫 INT 80H,然後從堆疊中恢復暫存器的原始值。因此,編寫兩個用於儲存和恢復資料的宏可能很有用。
我們觀察到,一些指令(如 IMUL、IDIV、INT 等)需要將某些資訊儲存在某些特定的暫存器中,甚至在某些特定暫存器中返回結果。如果程式已經在使用這些暫存器來儲存重要資料,則應將這些暫存器中的現有資料儲存到堆疊中,並在指令執行後恢復。
示例
以下示例顯示了宏的定義和使用方法:
; A macro with two parameters
; Implements the write system call
%macro write_string 2
mov eax, 4
mov ebx, 1
mov ecx, %1
mov edx, %2
int 80h
%endmacro
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
write_string msg1, len1
write_string msg2, len2
write_string msg3, len3
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg1 db 'Hello, programmers!',0xA,0xD
len1 equ $ - msg1
msg2 db 'Welcome to the world of,', 0xA,0xD
len2 equ $- msg2
msg3 db 'Linux assembly programming! '
len3 equ $- msg3
編譯並執行上述程式碼後,將產生以下結果:
Hello, programmers! Welcome to the world of, Linux assembly programming!
組合語言 - 檔案管理
系統將任何輸入或輸出資料視為位元組流。有三個標準檔案流:
- 標準輸入 (stdin),
- 標準輸出 (stdout),以及
- 標準錯誤 (stderr)。
檔案描述符
檔案描述符是一個分配給檔案的 16 位整數,用作檔案 ID。建立新檔案或開啟現有檔案時,檔案描述符用於訪問檔案。
標準檔案流stdin、stdout 和stderr 的檔案描述符分別為 0、1 和 2。
檔案指標
檔案指標以位元組為單位指定檔案中後續讀/寫操作的位置。每個檔案都被視為一系列位元組。每個開啟的檔案都與一個檔案指標相關聯,該指標指定相對於檔案開頭的位元組偏移量。開啟檔案時,檔案指標設定為零。
檔案處理系統呼叫
下表簡要描述了與檔案處理相關的系統呼叫:
| %eax | 名稱 | %ebx | %ecx | %edx |
|---|---|---|---|---|
| 2 | sys_fork | struct pt_regs | - | - |
| 3 | sys_read | unsigned int | char * | size_t |
| 4 | sys_write | unsigned int | const char * | size_t |
| 5 | sys_open | const char * | int | int |
| 6 | sys_close | unsigned int | - | - |
| 8 | sys_creat | const char * | int | - |
| 19 | sys_lseek | unsigned int | off_t | unsigned int |
使用系統呼叫的步驟與我們前面討論的一樣:
- 將系統呼叫號放入EAX暫存器。
- 將系統呼叫的引數儲存在EBX、ECX等暫存器中。
- 呼叫相關的中斷 (80h)。
- 結果通常返回在EAX暫存器中。
建立和開啟檔案
要建立和開啟檔案,請執行以下任務:
- 將系統呼叫 sys_creat() 編號 8 放入 EAX 暫存器中。
- 將檔名放入 EBX 暫存器中。
- 將檔案許可權放入 ECX 暫存器中。
系統呼叫在 EAX 暫存器中返回已建立檔案的描述符;如果出錯,則 EAX 暫存器中包含錯誤程式碼。
開啟現有檔案
要開啟現有檔案,請執行以下任務:
- 將系統呼叫 sys_open() 編號 5 放入 EAX 暫存器中。
- 將檔名放入 EBX 暫存器中。
- 將檔案訪問模式放入 ECX 暫存器中。
- 將檔案許可權放入 EDX 暫存器中。
系統呼叫在 EAX 暫存器中返回已建立檔案的描述符;如果出錯,則 EAX 暫存器中包含錯誤程式碼。
在檔案訪問模式中,最常用的是:只讀 (0)、只寫 (1) 和讀寫 (2)。
從檔案讀取
要從檔案讀取,請執行以下任務:
將系統呼叫 sys_read() 編號 3 放入 EAX 暫存器中。
將檔案描述符放入 EBX 暫存器中。
將指向輸入緩衝區的指標放入 ECX 暫存器中。
將緩衝區大小(即要讀取的位元組數)放入 EDX 暫存器中。
系統呼叫在 EAX 暫存器中返回讀取的位元組數;如果出錯,則 EAX 暫存器中包含錯誤程式碼。
寫入檔案
要寫入檔案,請執行以下任務:
將系統呼叫 sys_write() 編號 4 放入 EAX 暫存器中。
將檔案描述符放入 EBX 暫存器中。
將指向輸出緩衝區的指標放入 ECX 暫存器中。
將緩衝區大小(即要寫入的位元組數)放入 EDX 暫存器中。
系統呼叫在 EAX 暫存器中返回實際寫入的位元組數;如果出錯,則 EAX 暫存器中包含錯誤程式碼。
關閉檔案
要關閉檔案,請執行以下任務:
- 將系統呼叫 sys_close() 編號 6 放入 EAX 暫存器中。
- 將檔案描述符放入 EBX 暫存器中。
系統呼叫返回;如果出錯,則 EAX 暫存器中包含錯誤程式碼。
更新檔案
要更新檔案,請執行以下任務:
- 將系統呼叫 sys_lseek() 編號 19 放入 EAX 暫存器中。
- 將檔案描述符放入 EBX 暫存器中。
- 將偏移值放入 ECX 暫存器中。
- 將偏移量的參考位置放入 EDX 暫存器中。
參考位置可以是:
- 檔案開頭 - 值 0
- 當前位置 - 值 1
- 檔案結尾 - 值 2
系統呼叫返回;如果出錯,則 EAX 暫存器中包含錯誤程式碼。
示例
下面的程式建立一個名為 *myfile.txt* 的檔案並開啟它,然後在這個檔案中寫入文字“Welcome to Tutorials Point”。接下來,程式從檔案中讀取資料並將資料儲存到名為 *info* 的緩衝區中。最後,它顯示儲存在 *info* 中的文字。
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
;create the file
mov eax, 8
mov ebx, file_name
mov ecx, 0777 ;read, write and execute by all
int 0x80 ;call kernel
mov [fd_out], eax
; write into the file
mov edx,len ;number of bytes
mov ecx, msg ;message to write
mov ebx, [fd_out] ;file descriptor
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
; close the file
mov eax, 6
mov ebx, [fd_out]
; write the message indicating end of file write
mov eax, 4
mov ebx, 1
mov ecx, msg_done
mov edx, len_done
int 0x80
;open the file for reading
mov eax, 5
mov ebx, file_name
mov ecx, 0 ;for read only access
mov edx, 0777 ;read, write and execute by all
int 0x80
mov [fd_in], eax
;read from file
mov eax, 3
mov ebx, [fd_in]
mov ecx, info
mov edx, 26
int 0x80
; close the file
mov eax, 6
mov ebx, [fd_in]
int 0x80
; print the info
mov eax, 4
mov ebx, 1
mov ecx, info
mov edx, 26
int 0x80
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
file_name db 'myfile.txt'
msg db 'Welcome to Tutorials Point'
len equ $-msg
msg_done db 'Written to file', 0xa
len_done equ $-msg_done
section .bss
fd_out resb 1
fd_in resb 1
info resb 26
編譯並執行上述程式碼後,將產生以下結果:
Written to file Welcome to Tutorials Point
組合語言 - 記憶體管理
核心提供sys_brk() 系統呼叫,以便無需稍後移動即可分配記憶體。此呼叫在記憶體中的應用程式映像後面分配記憶體。此係統函式允許您設定資料段中最高可用的地址。
此係統呼叫接受一個引數,即需要設定的最高記憶體地址。此值儲存在 EBX 暫存器中。
如果出錯,sys_brk() 返回 -1 或返回負的錯誤程式碼本身。以下示例演示動態記憶體分配。
示例
下面的程式使用 sys_brk() 系統呼叫分配 16kb 的記憶體:
section .text global _start ;must be declared for using gcc _start: ;tell linker entry point mov eax, 45 ;sys_brk xor ebx, ebx int 80h add eax, 16384 ;number of bytes to be reserved mov ebx, eax mov eax, 45 ;sys_brk int 80h cmp eax, 0 jl exit ;exit, if error mov edi, eax ;EDI = highest available address sub edi, 4 ;pointing to the last DWORD mov ecx, 4096 ;number of DWORDs allocated xor eax, eax ;clear eax std ;backward rep stosd ;repete for entire allocated area cld ;put DF flag to normal state mov eax, 4 mov ebx, 1 mov ecx, msg mov edx, len int 80h ;print a message exit: mov eax, 1 xor ebx, ebx int 80h section .data msg db "Allocated 16 kb of memory!", 10 len equ $ - msg
編譯並執行上述程式碼後,將產生以下結果:
Allocated 16 kb of memory!