- Apache Storm 教程
- Apache Storm - 首頁
- Apache Storm - 簡介
- Apache Storm - 核心概念
- Apache Storm - 叢集架構
- Apache Storm - 工作流程
- Storm - 分散式訊息系統
- Apache Storm - 安裝
- Apache Storm - 工作示例
- Apache Storm - Trident
- Twitter 中的 Apache Storm
- 雅虎財經中的 Apache Storm
- Apache Storm - 應用
- Apache Storm 有用資源
- Apache Storm 快速指南
- Apache Storm - 有用資源
- Apache Storm - 討論
Apache Storm 快速指南
Apache Storm - 簡介
什麼是 Apache Storm?
Apache Storm 是一個分散式即時大資料處理系統。Storm 旨在以容錯且橫向擴充套件的方式處理海量資料。它是一個流資料框架,具有最高的攝取率能力。儘管 Storm 是無狀態的,但它透過 Apache ZooKeeper 管理分散式環境和叢集狀態。它很簡單,您可以在並行中對即時資料執行各種操作。
Apache Storm 繼續成為即時資料分析的領導者。Storm 易於設定和操作,並保證每個訊息至少會被拓撲處理一次。
Apache Storm 與 Hadoop
基本上,Hadoop 和 Storm 框架用於分析大資料。它們彼此互補,但在某些方面有所不同。Apache Storm 執行所有操作(永續性除外),而 Hadoop 擅長所有操作,但在即時計算方面卻有所欠缺。下表比較了 Storm 和 Hadoop 的屬性。
| Storm | Hadoop |
|---|---|
| 即時流處理 | 批處理 |
| 無狀態 | 有狀態 |
| 基於 ZooKeeper 的協調的主/從架構。主節點稱為 **nimbus**,從節點稱為 **supervisor**。 | 帶或不帶基於 ZooKeeper 的協調的主從架構。主節點是 **job tracker**,從節點是 **task tracker**。 |
| Storm 流處理可以在叢集上每秒訪問數萬條訊息。 | Hadoop 分散式檔案系統 (HDFS) 使用 MapReduce 框架處理需要數分鐘或數小時才能完成的海量資料。 |
| Storm 拓撲一直執行,直到使用者關閉或發生意外的不可恢復的故障。 | MapReduce 作業按順序執行並最終完成。 |
| 兩者都是分散式且容錯的 | |
| 如果 nimbus/supervisor 死亡,重新啟動使其從停止的地方繼續,因此不會受到任何影響。 | 如果 JobTracker 死亡,所有正在執行的作業都會丟失。 |
Apache Storm 的用例
Apache Storm 因其即時大資料流處理而聞名。因此,大多數公司都將 Storm 作為其系統不可或缺的一部分。一些值得注意的例子如下:
**Twitter** - Twitter 使用 Apache Storm 構建其一系列“釋出者分析產品”。“釋出者分析產品”處理 Twitter 平臺上的每一條推文和點選。Apache Storm 與 Twitter 基礎架構深度整合。
**NaviSite** - NaviSite 使用 Storm 構建事件日誌監控/審計系統。系統中生成的每個日誌都會透過 Storm。Storm 會根據配置的正則表示式集檢查訊息,如果匹配,則將該特定訊息儲存到資料庫中。
**Wego** - Wego 是一家位於新加坡的旅遊元搜尋引擎。旅遊相關資料來自世界各地的許多來源,時間也不同。Storm 幫助 Wego 搜尋即時資料,解決併發問題併為終端使用者找到最佳匹配。
Apache Storm 的優勢
以下是 Apache Storm 提供的優勢列表:
Storm 是開源的、健壯的且使用者友好的。它可以被小型公司和大型企業使用。
Storm 具有容錯性、靈活性和可靠性,並支援任何程式語言。
允許即時流處理。
Storm 非常快,因為它具有強大的資料處理能力。
Storm 透過線性增加資源,即使在負載增加的情況下也能保持效能。它具有高度的可擴充套件性。
Storm 在幾秒或幾分鐘內完成資料重新整理和端到端交付響應,具體取決於問題。它的延遲非常低。
Storm 具有運營智慧。
即使叢集中的任何連線節點死亡或訊息丟失,Storm 也可以保證資料處理。
Apache Storm - 核心概念
Apache Storm 從一端讀取原始的即時資料流,並將其透過一系列小的處理單元,並在另一端輸出處理後的/有用的資訊。
下圖描述了 Apache Storm 的核心概念。
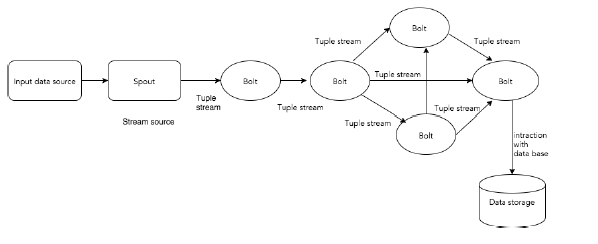
現在讓我們仔細看看 Apache Storm 的元件:
| 元件 | 描述 |
|---|---|
| Tuple | Tuple 是 Storm 中的主要資料結構。它是有序元素的列表。預設情況下,Tuple 支援所有資料型別。通常,它被建模為一組逗號分隔的值,並傳遞到 Storm 叢集。 |
| Stream | Stream 是 Tuple 的無序序列。 |
| Spouts | 流的來源。通常,Storm 從原始資料來源(如 Twitter Streaming API、Apache Kafka 佇列、Kestrel 佇列等)接受輸入資料。或者,您可以編寫 spout 從資料來源讀取資料。“ISpout”是實現 spout 的核心介面。一些具體的介面是 IRichSpout、BaseRichSpout、KafkaSpout 等。 |
| Bolts | Bolt 是邏輯處理單元。Spout 將資料傳遞給 bolt,bolt 處理並生成新的輸出流。Bolt 可以執行過濾、聚合、連線、與資料來源和資料庫互動等操作。Bolt 接收資料並向一個或多個 bolt 發射資料。“IBolt”是實現 bolt 的核心介面。一些常見的介面是 IRichBolt、IBasicBolt 等。 |
讓我們以“Twitter 分析”的即時示例為例,看看它如何在 Apache Storm 中建模。下圖描述了結構。
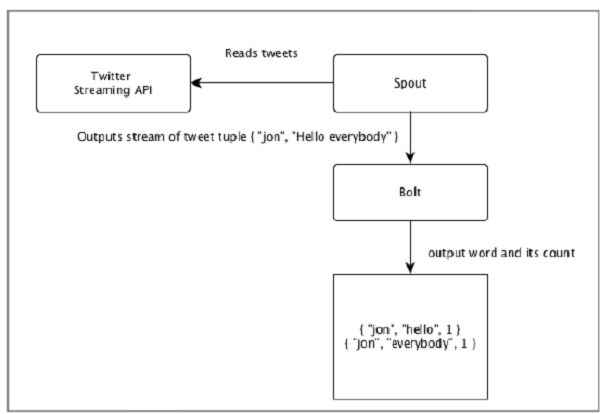
“Twitter 分析”的輸入來自 Twitter Streaming API。Spout 將使用 Twitter Streaming API 讀取使用者的推文,並將其輸出為 Tuple 流。來自 spout 的單個 Tuple 將包含 Twitter 使用者名稱和一條推文作為逗號分隔的值。然後,此 Tuple 流將轉發到 Bolt,Bolt 將推文拆分為單個單詞,計算單詞計數,並將資訊持久化到配置的資料來源。現在,我們可以透過查詢資料來源輕鬆獲取結果。
Topology
Spout 和 bolt 連線在一起,形成一個拓撲。即時應用程式邏輯在 Storm 拓撲中指定。簡單來說,拓撲是一個有向圖,其中頂點是計算,邊是資料流。
一個簡單的拓撲以 spout 開始。Spout 將資料發射到一個或多個 bolt。Bolt 代表拓撲中具有最小處理邏輯的節點,bolt 的輸出可以作為輸入發射到另一個 bolt。
Storm 使拓撲始終執行,直到您殺死拓撲。Apache Storm 的主要工作是執行拓撲,並在給定時間執行任意數量的拓撲。
Tasks
現在您對 spout 和 bolt 有了基本的瞭解。它們是拓撲的最小邏輯單元,拓撲是使用單個 spout 和一系列 bolt 構建的。為了使拓撲成功執行,它們應該按特定順序正確執行。Storm 執行每個 spout 和 bolt 的過程稱為“Tasks”。簡單來說,task 或者是 spout 的執行,或者是 bolt 的執行。在給定時間,每個 spout 和 bolt 都可以有多個例項在多個獨立執行緒中執行。
Workers
拓撲以分散式方式在多個工作節點上執行。Storm 將任務均勻地分佈在所有工作節點上。工作節點的作用是偵聽作業並在有新作業到達時啟動或停止程序。
Stream Grouping
資料流從 spout 流向 bolt 或從一個 bolt 流向另一個 bolt。Stream Grouping 控制 Tuple 如何在拓撲中路由,並幫助我們瞭解 Tuple 在拓撲中的流動。有四個內建的分組,如下所述。
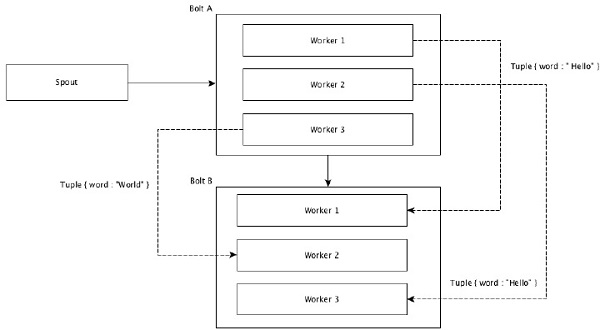
Shuffle Grouping
在 shuffle grouping 中,相同數量的 Tuple 會隨機分佈到執行 bolt 的所有工作節點。下圖描述了結構。
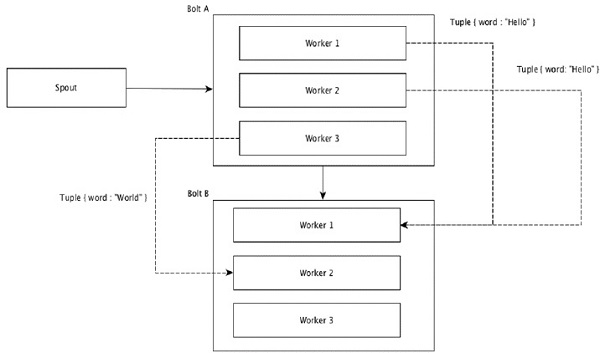
Field Grouping
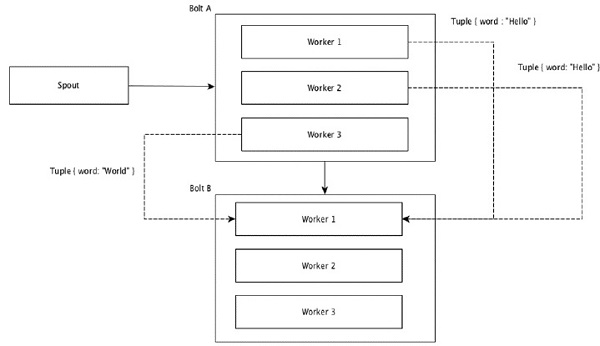
將 Tuple 中具有相同值的欄位組合在一起,並將其餘 Tuple 保留在外部。然後,將具有相同欄位值的 Tuple 傳送到執行 bolt 的同一工作節點。例如,如果流按欄位“word”分組,則具有相同字串“Hello”的 Tuple 將移動到同一工作節點。下圖顯示了 Field Grouping 的工作原理。
Global Grouping
所有流都可以分組並轉發到一個 bolt。此分組將所有源例項生成的 Tuple 傳送到單個目標例項(具體來說,選擇 ID 最低的 worker)。
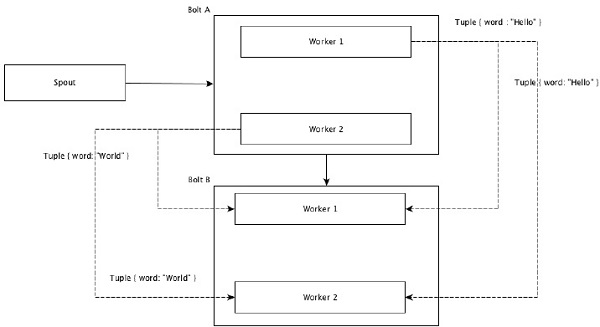
All Grouping
All Grouping 將每個 Tuple 的單個副本傳送到接收 bolt 的所有例項。這種分組用於向 bolt 傳送訊號。All Grouping 對於連線操作很有用。
Apache Storm - 叢集架構
Apache Storm 的主要亮點之一是它是一個容錯、快速且沒有“單點故障”(SPOF)的分散式應用程式。我們可以根據需要在儘可能多的系統中安裝 Apache Storm 以提高應用程式的容量。
讓我們看看 Apache Storm 叢集是如何設計的以及其內部架構。下圖描述了叢集設計。

Apache Storm 有兩種型別的節點,**Nimbus**(主節點)和 **Supervisor**(工作節點)。Nimbus 是 Apache Storm 的核心元件。Nimbus 的主要工作是執行 Storm 拓撲。Nimbus 分析拓撲並收集要執行的任務。然後,它將任務分發到可用的 supervisor。
supervisor 將擁有一個或多個工作程序。supervisor 將任務委託給工作程序。工作程序將根據需要生成執行器並執行任務。Apache Storm 使用內部分散式訊息系統來實現 nimbus 和 supervisor 之間的通訊。
| 元件 | 描述 |
|---|---|
| Nimbus | Nimbus 是 Storm 叢集的主節點。叢集中的所有其他節點都稱為**工作節點**。主節點負責在所有工作節點之間分發資料,將任務分配給工作節點並監控故障。 |
| Supervisor | 遵循 nimbus 給出的指令的節點稱為 Supervisor。**Supervisor** 具有多個工作程序,它管理工作程序以完成 nimbus 分配的任務。 |
| Worker process | 工作程序將執行與特定拓撲相關的任務。工作程序本身不會執行任務,而是建立**執行器**並要求它們執行特定任務。工作程序將有多個執行器。 |
| Executor | 執行器不過是工作程序生成的單個執行緒。執行器執行一個或多個任務,但僅針對特定的 spout 或 bolt。 |
| Task | 任務執行實際的資料處理。因此,它要麼是 spout,要麼是 bolt。 |
| ZooKeeper 框架 | Apache ZooKeeper 是一項由叢集(節點組)用於彼此之間協調並使用強大的同步技術維護共享資料的服務。Nimbus 是無狀態的,因此它依賴於 ZooKeeper 來監視工作節點狀態。 ZooKeeper 幫助主管與 Nimbus 進行互動。它負責維護 Nimbus 和主管的狀態。 |
Storm 本質上是無狀態的。儘管無狀態特性有其自身的缺點,但它實際上幫助 Storm 以最佳和最快的方式處理即時資料。
不過,Storm 並非完全無狀態。它將其狀態儲存在 Apache ZooKeeper 中。由於狀態在 Apache ZooKeeper 中可用,因此可以重新啟動失敗的 Nimbus 並使其從中斷的地方繼續工作。通常,服務監控工具(如 **monit**)會監視 Nimbus,並在發生任何故障時重新啟動它。
Apache Storm 還具有稱為 **Trident Topology** 的高階拓撲,它具有狀態維護功能,並且還提供類似 Pig 的高階 API。我們將在接下來的章節中討論所有這些功能。
Apache Storm - 工作流程
一個工作的 Storm 叢集應該有一個 Nimbus 和一個或多個主管。另一個重要的節點是 Apache ZooKeeper,它將用於 Nimbus 和主管之間的協調。
現在讓我們仔細看看 Apache Storm 的工作流程 -
最初,Nimbus 將等待“Storm Topology”提交給它。
一旦提交了拓撲,它將處理拓撲並收集所有要執行的任務以及任務執行的順序。
然後,Nimbus 將任務均勻地分配給所有可用的主管。
在特定時間間隔內,所有主管都將向 Nimbus 傳送心跳以通知它們仍然處於活動狀態。
當主管死亡並且沒有向 Nimbus 傳送心跳時,Nimbus 將任務分配給另一個主管。
當 Nimbus 本身死亡時,主管將毫無問題地繼續執行已分配的任務。
一旦所有任務都完成了,主管將等待新的任務進來。
同時,死掉的 Nimbus 將由服務監控工具自動重新啟動。
重新啟動的 Nimbus 將從停止的地方繼續。同樣,死掉的主管也可以自動重新啟動。由於 Nimbus 和主管都可以自動重新啟動,並且兩者都將像以前一樣繼續,因此可以保證 Storm 至少處理一次所有任務。
一旦所有拓撲都處理完畢,Nimbus 將等待新的拓撲到達,類似地,主管將等待新的任務。
預設情況下,Storm 叢集中有兩種模式 -
**本地模式** - 此模式用於開發、測試和除錯,因為它是檢視所有拓撲元件協同工作最簡單的方法。在此模式下,我們可以調整引數,使我們能夠檢視拓撲在不同的 Storm 配置環境中如何執行。在本地模式下,Storm 拓撲在單個 JVM 中的本地機器上執行。
**生產模式** - 在此模式下,我們將拓撲提交到正在工作的 Storm 叢集,該叢集由許多程序組成,通常執行在不同的機器上。如 Storm 工作流程中所述,正在工作的叢集將無限期執行,直到關閉。
Storm - 分散式訊息系統
Apache Storm 處理即時資料,輸入通常來自訊息佇列系統。外部分散式訊息系統將提供即時計算所需的輸入。Spout 將從訊息系統讀取資料並將其轉換為元組,並輸入到 Apache Storm 中。有趣的事實是,Apache Storm 在內部使用自己的分散式訊息系統來實現 Nimbus 和主管之間的通訊。
什麼是分散式訊息系統?
分散式訊息基於可靠訊息佇列的概念。訊息在客戶端應用程式和訊息系統之間非同步排隊。分散式訊息系統提供了可靠性、可擴充套件性和永續性的優勢。
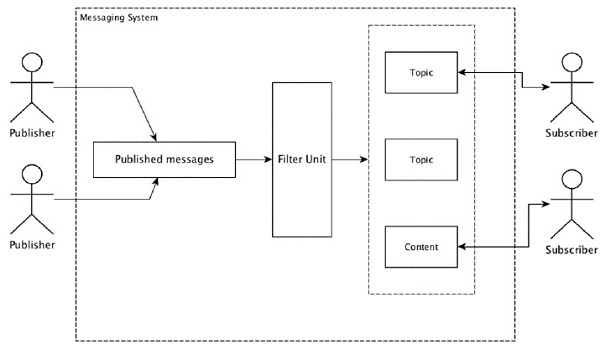
大多數訊息模式遵循 **釋出-訂閱** 模型(簡稱為 **Pub-Sub**),其中訊息的傳送者稱為 **釋出者**,而希望接收訊息的接收者稱為 **訂閱者**。
一旦傳送者釋出了訊息,訂閱者就可以在過濾選項的幫助下接收選定的訊息。通常我們有兩種型別的過濾,一種是 **基於主題的過濾**,另一種是 **基於內容的過濾**。
請注意,Pub-Sub 模型只能透過訊息進行通訊。它是一種非常鬆散耦合的架構;即使傳送者也不知道他們的訂閱者是誰。許多訊息模式使訊息代理能夠交換髮布的訊息,以便許多訂閱者及時訪問。一個現實生活中的例子是 Dish TV,它釋出不同的頻道,如體育、電影、音樂等,任何人都可以訂閱他們自己的一組頻道,並在其訂閱的頻道可用時獲得它們。
下表描述了一些流行的高吞吐量訊息系統 -
| 分散式訊息系統 | 描述 |
|---|---|
| Apache Kafka | Kafka 是在 LinkedIn 公司開發的,後來成為 Apache 的一個子專案。Apache Kafka 基於代理啟用、持久、分散式釋出-訂閱模型。Kafka 快速、可擴充套件且高效。 |
| RabbitMQ | RabbitMQ 是一種開源的分散式健壯訊息應用程式。它易於使用,並且可以在所有平臺上執行。 |
| JMS(Java 訊息服務) | JMS 是一種開源 API,支援在應用程式之間建立、讀取和傳送訊息。它提供保證的訊息傳遞並遵循釋出-訂閱模型。 |
| ActiveMQ | ActiveMQ 訊息系統是 JMS 的開源 API。 |
| ZeroMQ | ZeroMQ 是無代理的對等訊息處理。它提供推拉、路由器-經銷商訊息模式。 |
| Kestrel | Kestrel 是一種快速、可靠且簡單的分散式訊息佇列。 |
Thrift 協議
Thrift 是 Facebook 為跨語言服務開發和遠端過程呼叫 (RPC) 而構建的。後來,它成為了一個開源的 Apache 專案。Apache Thrift 是一種 **介面定義語言**,並允許以簡單的方式在定義的資料型別之上定義新的資料型別和服務實現。
Apache Thrift 也是一個通訊框架,支援嵌入式系統、移動應用程式、Web 應用程式和許多其他程式語言。與 Apache Thrift 相關的一些關鍵功能包括其模組化、靈活性以及高效能。此外,它可以在分散式應用程式中執行流、訊息傳遞和 RPC。
Storm 廣泛使用 Thrift 協議進行其內部通訊和資料定義。Storm 拓撲只是 **Thrift 結構**。在 Apache Storm 中執行拓撲的 Storm Nimbus 是一個 **Thrift 服務**。
Apache Storm - 安裝
現在讓我們看看如何在您的機器上安裝 Apache Storm 框架。這裡有三個主要步驟 -
- 如果您的系統上還沒有安裝 Java,請安裝它。
- 安裝 ZooKeeper 框架。
- 安裝 Apache Storm 框架。
步驟 1 - 驗證 Java 安裝
使用以下命令檢查您的系統上是否已安裝 Java。
$ java -version
如果 Java 已存在,則您將看到其版本號。否則,下載最新版本的 JDK。
步驟 1.1 - 下載 JDK
使用以下連結下載最新版本的 JDK - www.oracle.com
最新版本是 JDK 8u 60,檔案是 **“jdk-8u60-linux-x64.tar.gz”**。將檔案下載到您的機器上。
步驟 1.2 - 解壓縮檔案
通常檔案會下載到 **downloads** 資料夾中。使用以下命令解壓縮 tar 設定。
$ cd /go/to/download/path $ tar -zxf jdk-8u60-linux-x64.gz
步驟 1.3 - 移動到 opt 目錄
為了使所有使用者都能使用 Java,請將解壓縮的 Java 內容移動到“/usr/local/java”資料夾。
$ su password: (type password of root user) $ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/
步驟 1.4 - 設定路徑
要設定路徑和 JAVA_HOME 變數,請將以下命令新增到 ~/.bashrc 檔案中。
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60 export PATH=$PATH:$JAVA_HOME/bin
現在將所有更改應用到當前正在執行的系統中。
$ source ~/.bashrc
步驟 1.5 - Java 備選方案
使用以下命令更改 Java 備選方案。
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100
步驟 1.6
現在使用步驟 1 中說明的驗證命令 **(java -version)** 驗證 Java 安裝。
步驟 2 - ZooKeeper 框架安裝
步驟 2.1 - 下載 ZooKeeper
要在您的機器上安裝 ZooKeeper 框架,請訪問以下連結並下載最新版本的 ZooKeeper http://zookeeper.apache.org/releases.html
截至目前,ZooKeeper 的最新版本是 3.4.6 (ZooKeeper-3.4.6.tar.gz)。
步驟 2.2 - 解壓縮 tar 檔案
使用以下命令解壓縮 tar 檔案 -
$ cd opt/ $ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6 $ mkdir data
步驟 2.3 - 建立配置檔案
使用命令“vi conf/zoo.cfg”開啟名為“conf/zoo.cfg”的配置檔案,並將所有以下引數設定為起點。
$ vi conf/zoo.cfg tickTime=2000 dataDir=/path/to/zookeeper/data clientPort=2181 initLimit=5 syncLimit=2
成功儲存配置檔案後,您可以啟動 ZooKeeper 伺服器。
步驟 2.4 - 啟動 ZooKeeper 伺服器
使用以下命令啟動 ZooKeeper 伺服器。
$ bin/zkServer.sh start
執行此命令後,您將獲得如下響應 -
$ JMX enabled by default $ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTED
步驟 2.5 - 啟動 CLI
使用以下命令啟動 CLI。
$ bin/zkCli.sh
執行上述命令後,您將連線到 ZooKeeper 伺服器並獲得以下響應。
Connecting to localhost:2181 ................ ................ ................ Welcome to ZooKeeper! ................ ................ WATCHER:: WatchedEvent state:SyncConnected type: None path:null [zk: localhost:2181(CONNECTED) 0]
步驟 2.6 - 停止 ZooKeeper 伺服器
連線伺服器並執行所有操作後,您可以使用以下命令停止 ZooKeeper 伺服器。
bin/zkServer.sh stop
您已成功在您的機器上安裝了 Java 和 ZooKeeper。現在讓我們看看安裝 Apache Storm 框架的步驟。
步驟 3 - Apache Storm 框架安裝
步驟 3.1 下載 Storm
要在您的機器上安裝 Storm 框架,請訪問以下連結並下載最新版本的 Storm http://storm.apache.org/downloads.html
截至目前,Storm 的最新版本是“apache-storm-0.9.5.tar.gz”。
步驟 3.2 - 解壓縮 tar 檔案
使用以下命令解壓縮 tar 檔案 -
$ cd opt/ $ tar -zxf apache-storm-0.9.5.tar.gz $ cd apache-storm-0.9.5 $ mkdir data
步驟 3.3 - 開啟配置檔案
Storm 的當前版本包含一個位於“conf/storm.yaml”的檔案,該檔案配置 Storm 守護程式。將以下資訊新增到該檔案中。
$ vi conf/storm.yaml storm.zookeeper.servers: - "localhost" storm.local.dir: “/path/to/storm/data(any path)” nimbus.host: "localhost" supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703
應用所有更改後,儲存並返回終端。
步驟 3.4 - 啟動 Nimbus
$ bin/storm nimbus
步驟 3.5 - 啟動主管
$ bin/storm supervisor
步驟 3.6 啟動 UI
$ bin/storm ui
啟動 Storm 使用者介面應用程式後,在您喜歡的瀏覽器中鍵入 URL **https://:8080**,您就可以看到 Storm 叢集資訊及其正在執行的拓撲。該頁面應類似於以下螢幕截圖。
Apache Storm - 工作示例
我們已經瞭解了 Apache Storm 的核心技術細節,現在是時候編寫一些簡單的場景了。
場景 – 移動通話記錄分析器
移動通話及其時長將作為輸入提供給 Apache Storm,Storm 將處理並對同一呼叫者和接收者之間的呼叫進行分組,以及他們的總呼叫次數。
Spout 建立
Spout 是用於資料生成的元件。基本上,Spout 將實現 IRichSpout 介面。“IRichSpout”介面具有以下重要方法 -
**open** - 為 Spout 提供執行環境。執行程式將執行此方法來初始化 Spout。
**nextTuple** - 透過收集器發出生成的資料。
**close** - 當 Spout 將要關閉時呼叫此方法。
**declareOutputFields** - 宣告元組的輸出模式。
**ack** - 確認已處理特定元組
**fail** - 指定未處理特定元組,並且不應重新處理。
開啟
**open** 方法的簽名如下 -
open(Map conf, TopologyContext context, SpoutOutputCollector collector)
conf − 提供此 spout 的 Storm 配置。
context − 提供有關 spout 在拓撲中的位置、其任務 ID、輸入和輸出資訊的完整資訊。
collector − 使我們能夠發出將由 bolt 處理的元組。
nextTuple
nextTuple 方法的簽名如下所示:
nextTuple()
nextTuple() 從與 ack() 和 fail() 方法相同的迴圈中定期呼叫。當沒有工作要做時,它必須釋放執行緒的控制權,以便其他方法有機會被呼叫。因此,nextTuple 的第一行檢查處理是否已完成。如果是,它應該休眠至少 1 毫秒以減少處理器負載,然後再返回。
close
close 方法的簽名如下所示:
close()
declareOutputFields
declareOutputFields 方法的簽名如下所示:
declareOutputFields(OutputFieldsDeclarer declarer)
declarer − 用於宣告輸出流 ID、輸出欄位等。
此方法用於指定元組的輸出模式。
ack
ack 方法的簽名如下所示:
ack(Object msgId)
此方法確認已處理特定元組。
fail
nextTuple 方法的簽名如下所示:
ack(Object msgId)
此方法通知特定元組未完全處理。Storm 將重新處理該特定元組。
FakeCallLogReaderSpout
在我們的場景中,我們需要收集呼叫日誌詳細資訊。呼叫日誌的資訊包含。
- 主叫號碼
- 被叫號碼
- 持續時間
由於我們沒有呼叫日誌的即時資訊,我們將生成虛假的呼叫日誌。虛假資訊將使用 Random 類建立。完整的程式程式碼如下所示。
編碼 - FakeCallLogReaderSpout.java
import java.util.*;
//import storm tuple packages
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import Spout interface packages
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
//Create a class FakeLogReaderSpout which implement IRichSpout interface
to access functionalities
public class FakeCallLogReaderSpout implements IRichSpout {
//Create instance for SpoutOutputCollector which passes tuples to bolt.
private SpoutOutputCollector collector;
private boolean completed = false;
//Create instance for TopologyContext which contains topology data.
private TopologyContext context;
//Create instance for Random class.
private Random randomGenerator = new Random();
private Integer idx = 0;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
if(this.idx <= 1000) {
List<String> mobileNumbers = new ArrayList<String>();
mobileNumbers.add("1234123401");
mobileNumbers.add("1234123402");
mobileNumbers.add("1234123403");
mobileNumbers.add("1234123404");
Integer localIdx = 0;
while(localIdx++ < 100 && this.idx++ < 1000) {
String fromMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
String toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
while(fromMobileNumber == toMobileNumber) {
toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
}
Integer duration = randomGenerator.nextInt(60);
this.collector.emit(new Values(fromMobileNumber, toMobileNumber, duration));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("from", "to", "duration"));
}
//Override all the interface methods
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
Bolt 建立
Bolt 是一種元件,它以元組作為輸入,處理元組,併產生新的元組作為輸出。Bolt 將實現IRichBolt介面。在此程式中,使用兩個 bolt 類CallLogCreatorBolt和CallLogCounterBolt來執行操作。
IRichBolt 介面具有以下方法:
prepare − 為 bolt 提供執行環境。執行器將執行此方法來初始化 spout。
execute − 處理單個輸入元組。
cleanup − 當 bolt 將要關閉時呼叫。
**declareOutputFields** - 宣告元組的輸出模式。
Prepare
prepare 方法的簽名如下所示:
prepare(Map conf, TopologyContext context, OutputCollector collector)
conf − 提供此 bolt 的 Storm 配置。
context − 提供有關 bolt 在拓撲中的位置、其任務 ID、輸入和輸出資訊等的完整資訊。
collector − 使我們能夠發出已處理的元組。
execute
execute 方法的簽名如下所示:
execute(Tuple tuple)
這裡tuple是要處理的輸入元組。
execute方法一次處理一個元組。可以透過 Tuple 類的 getValue 方法訪問元組資料。不需要立即處理輸入元組。可以處理多個元組並將其輸出為單個輸出元組。可以使用 OutputCollector 類發出已處理的元組。
cleanup
cleanup 方法的簽名如下所示:
cleanup()
declareOutputFields
declareOutputFields 方法的簽名如下所示:
declareOutputFields(OutputFieldsDeclarer declarer)
這裡引數declarer用於宣告輸出流 ID、輸出欄位等。
此方法用於指定元組的輸出模式
呼叫日誌建立器 Bolt
呼叫日誌建立器 bolt 接收呼叫日誌元組。呼叫日誌元組包含主叫號碼、被叫號碼和呼叫持續時間。此 bolt 僅透過組合主叫號碼和被叫號碼來建立一個新值。新值的格式為“主叫號碼 - 被叫號碼”,並將其命名為新欄位“call”。完整的程式碼如下所示。
編碼 - CallLogCreatorBolt.java
//import util packages
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
//import Storm IRichBolt package
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
//Create a class CallLogCreatorBolt which implement IRichBolt interface
public class CallLogCreatorBolt implements IRichBolt {
//Create instance for OutputCollector which collects and emits tuples to produce output
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String from = tuple.getString(0);
String to = tuple.getString(1);
Integer duration = tuple.getInteger(2);
collector.emit(new Values(from + " - " + to, duration));
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call", "duration"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
呼叫日誌計數器 Bolt
呼叫日誌計數器 bolt 接收呼叫及其持續時間作為元組。此 bolt 在 prepare 方法中初始化一個字典 (Map) 物件。在execute方法中,它檢查元組併為元組中的每個新的“call”值在字典物件中建立一個新條目,並在字典物件中設定值 1。對於字典中已有的條目,它只是將其值遞增。簡單來說,此 bolt 將呼叫及其計數儲存在字典物件中。除了將呼叫及其計數儲存在字典中,我們還可以將其儲存到資料來源中。完整的程式程式碼如下所示:
編碼 - CallLogCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class CallLogCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String call = tuple.getString(0);
Integer duration = tuple.getInteger(1);
if(!counterMap.containsKey(call)){
counterMap.put(call, 1);
}else{
Integer c = counterMap.get(call) + 1;
counterMap.put(call, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
建立拓撲
Storm 拓撲基本上是一個 Thrift 結構。TopologyBuilder 類提供簡單易用的方法來建立複雜的拓撲。TopologyBuilder 類具有設定 spout (setSpout) 和設定 bolt (setBolt) 的方法。最後,TopologyBuilder 具有 createTopology 以建立拓撲。使用以下程式碼片段建立拓撲:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));
shuffleGrouping 和 fieldsGrouping 方法有助於為 spout 和 bolt 設定流分組。
本地叢集
出於開發目的,我們可以使用“LocalCluster”物件建立本地叢集,然後使用“LocalCluster”類的“submitTopology”方法提交拓撲。 “submitTopology”的引數之一是“Config”類的例項。“Config”類用於在提交拓撲之前設定配置選項。此配置選項將在執行時與叢集配置合併,並透過 prepare 方法傳送到所有任務(spout 和 bolt)。拓撲提交到集群后,我們將等待 10 秒鐘,讓叢集計算提交的拓撲,然後使用“LocalCluster”的“shutdown”方法關閉叢集。完整的程式程式碼如下所示:
編碼 - LogAnalyserStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import storm configuration packages
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
//Create main class LogAnalyserStorm submit topology.
public class LogAnalyserStorm {
public static void main(String[] args) throws Exception{
//Create Config instance for cluster configuration
Config config = new Config();
config.setDebug(true);
//
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LogAnalyserStorm", config, builder.createTopology());
Thread.sleep(10000);
//Stop the topology
cluster.shutdown();
}
}
構建和執行應用程式
完整的應用程式有四個 Java 程式碼。它們是:
- FakeCallLogReaderSpout.java
- CallLogCreaterBolt.java
- CallLogCounterBolt.java
- LogAnalyerStorm.java
可以使用以下命令構建應用程式:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.java
可以使用以下命令執行應用程式:
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserStorm
輸出
應用程式啟動後,它將輸出有關叢集啟動過程、spout 和 bolt 處理以及最終叢集關閉過程的完整詳細資訊。在“CallLogCounterBolt”中,我們列印了呼叫及其計數詳細資訊。此資訊將顯示在控制檯上,如下所示:
1234123402 - 1234123401 : 78 1234123402 - 1234123404 : 88 1234123402 - 1234123403 : 105 1234123401 - 1234123404 : 74 1234123401 - 1234123403 : 81 1234123401 - 1234123402 : 81 1234123403 - 1234123404 : 86 1234123404 - 1234123401 : 63 1234123404 - 1234123402 : 82 1234123403 - 1234123402 : 83 1234123404 - 1234123403 : 86 1234123403 - 1234123401 : 93
非 JVM 語言
Storm 拓撲由 Thrift 介面實現,這使得在任何語言中提交拓撲變得容易。Storm 支援 Ruby、Python 和許多其他語言。讓我們看看 python 繫結。
Python 繫結
Python 是一種通用的解釋型、互動式、面向物件的高階程式語言。Storm 支援 Python 來實現其拓撲。Python 支援發出、錨定、確認和記錄操作。
如您所知,bolt 可以用任何語言定義。用另一種語言編寫的 bolt 作為子程序執行,Storm 透過 stdin/stdout 上的 JSON 訊息與這些子程序通訊。首先獲取一個支援 python 繫結的示例 bolt WordCount。
public static class WordCount implements IRichBolt {
public WordSplit() {
super("python", "splitword.py");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
這裡類WordCount實現IRichBolt介面並使用指定的 python 實現執行超級方法引數“splitword.py”。現在建立一個名為“splitword.py”的 python 實現。
import storm
class WordCountBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
for word in words:
storm.emit([word])
WordCountBolt().run()
這是 Python 的示例實現,用於計算給定句子中的單詞數。類似地,您也可以繫結其他支援的語言。
Apache Storm - Trident
Trident 是 Storm 的擴充套件。與 Storm 一樣,Trident 也由 Twitter 開發。開發 Trident 的主要原因是在 Storm 之上提供高階抽象,以及有狀態流處理和低延遲分散式查詢。
Trident 使用 spout 和 bolt,但這些低階元件在執行之前由 Trident 自動生成。Trident 具有函式、過濾器、聯接、分組和聚合。
Trident 將流處理為一系列批次,這些批次稱為事務。通常,這些小批次的大小將以數千或數百萬個元組為單位,具體取決於輸入流。這樣,Trident 就不同於 Storm,後者執行逐個元組的處理。
批處理概念與資料庫事務非常相似。每個事務都分配一個事務 ID。一旦所有處理完成,則認為事務成功。但是,處理事務的其中一個元組失敗將導致整個事務被重新傳輸。對於每個批次,Trident 將在事務開始時呼叫 beginCommit,並在事務結束時呼叫 commit。
Trident 拓撲
Trident API 公開了一個簡單的選項,可以使用“TridentTopology”類建立 Trident 拓撲。基本上,Trident 拓撲從 spout 接收輸入流,並在流上執行有序的序列操作(過濾器、聚合、分組等)。Storm 元組被 Trident 元組替換,Bolt 被操作替換。可以如下建立簡單的 Trident 拓撲:
TridentTopology topology = new TridentTopology();
Trident 元組
Trident 元組是命名的值列表。TridentTuple 介面是 Trident 拓撲的資料模型。TridentTuple 介面是 Trident 拓撲可以處理的基本資料單元。
Trident Spout
Trident spout 類似於 Storm spout,但增加了使用 Trident 功能的選項。實際上,我們仍然可以使用我們在 Storm 拓撲中使用的 IRichSpout,但它本質上是非事務性的,我們無法使用 Trident 提供的優勢。
具有使用 Trident 功能的所有功能的基本 spout 是“ITridentSpout”。它支援事務性和不透明事務性語義。其他 spout 是 IBatchSpout、IPartitionedTridentSpout 和 IOpaquePartitionedTridentSpout。
除了這些通用 spout 之外,Trident 還有許多 trident spout 的示例實現。其中之一是 FeederBatchSpout spout,我們可以使用它輕鬆傳送命名的 trident 元組列表,而無需擔心批處理、並行性等。
FeederBatchSpout 建立和資料饋送可以如下所示完成:
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(
ImmutableList.of("fromMobileNumber", "toMobileNumber", “duration”));
topology.newStream("fixed-batch-spout", testSpout)
testSpout.feed(ImmutableList.of(new Values("1234123401", "1234123402", 20)));
Trident 操作
Trident 依賴於“Trident 操作”來處理 trident 元組的輸入流。Trident API 有許多內建操作來處理從簡單到複雜的流處理。這些操作範圍從簡單的驗證到 trident 元組的複雜分組和聚合。讓我們瞭解一下最重要和最常用的操作。
過濾器
過濾器是一個用於執行輸入驗證任務的物件。Trident 過濾器獲取 trident 元組欄位的子集作為輸入,並根據是否滿足某些條件返回 true 或 false。如果返回 true,則元組保留在輸出流中;否則,元組將從流中刪除。過濾器基本上將繼承自BaseFilter類並實現isKeep方法。以下是對過濾器操作的示例實現:
public class MyFilter extends BaseFilter {
public boolean isKeep(TridentTuple tuple) {
return tuple.getInteger(1) % 2 == 0;
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2]
[1, 4]
可以在拓撲中使用“each”方法呼叫過濾器函式。“Fields”類可用於指定輸入(trident 元組的子集)。示例程式碼如下所示:
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields("a", "b"), new MyFilter())
函式
函式是一個用於對單個 trident 元組執行簡單操作的物件。它獲取 trident 元組欄位的子集併發出零個或多個新的 trident 元組欄位。
函式基本上繼承自BaseFunction類並實現execute方法。下面給出了一個示例實現:
public class MyFunction extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
int a = tuple.getInteger(0);
int b = tuple.getInteger(1);
collector.emit(new Values(a + b));
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2, 3]
[1, 3, 4]
[1, 4, 5]
就像 Filter 操作一樣,可以在拓撲中使用each方法呼叫 Function 操作。示例程式碼如下所示:
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d")));
聚合
聚合是一個用於對輸入批次或分割槽或流執行聚合操作的物件。Trident 有三種類型的聚合。它們如下所示:
aggregate − 對每個 Trident 元組批次獨立進行聚合。在聚合過程中,元組最初使用全域性分組重新分割槽,將同一批次的所有分割槽合併到單個分割槽中。
partitionAggregate − 對每個分割槽進行聚合,而不是對整個 Trident 元組批次進行聚合。分割槽聚合的輸出完全替換輸入元組。分割槽聚合的輸出包含單個欄位元組。
persistentaggregate − 對所有批次中的所有 Trident 元組進行聚合,並將結果儲存在記憶體或資料庫中。
TridentTopology topology = new TridentTopology();
// aggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.aggregate(new Count(), new Fields(“count”))
// partitionAggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.partitionAggregate(new Count(), new Fields(“count"))
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));
聚合操作可以使用 CombinerAggregator、ReducerAggregator 或通用 Aggregator 介面建立。“count” 聚合器在以上示例中使用,是內建聚合器之一。它使用“CombinerAggregator”實現。實現如下:
public class Count implements CombinerAggregator<Long> {
@Override
public Long init(TridentTuple tuple) {
return 1L;
}
@Override
public Long combine(Long val1, Long val2) {
return val1 + val2;
}
@Override
public Long zero() {
return 0L;
}
}
分組
分組操作是內建操作,可以透過groupBy方法呼叫。groupBy 方法透過對指定欄位執行 partitionBy 來重新分割槽流,然後在每個分割槽內,將組欄位相等的元組組合在一起。通常,我們會將“groupBy”與“persistentAggregate”一起使用以獲取分組聚合。示例程式碼如下:
TridentTopology topology = new TridentTopology();
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.groupBy(new Fields(“d”)
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));
合併和連線
合併和連線可以透過分別使用“merge”和“join”方法來完成。合併組合一個或多個流。連線類似於合併,但連線使用來自兩側的 Trident 元組欄位來檢查和連線兩個流。此外,連線僅在批次級別工作。示例程式碼如下:
TridentTopology topology = new TridentTopology();
topology.merge(stream1, stream2, stream3);
topology.join(stream1, new Fields("key"), stream2, new Fields("x"),
new Fields("key", "a", "b", "c"));
狀態維護
Trident 提供了一種狀態維護機制。狀態資訊可以儲存在拓撲本身中,也可以儲存在單獨的資料庫中。原因是為了維護一個狀態,如果任何元組在處理過程中失敗,則重試失敗的元組。這在更新狀態時會產生問題,因為您不確定此元組的狀態是否已更新過。如果元組在更新狀態之前失敗,則重試元組將使狀態穩定。但是,如果元組在更新狀態後失敗,則重試相同的元組將再次增加資料庫中的計數,使狀態不穩定。需要執行以下步驟以確保訊息僅處理一次:
將元組分成小批次處理。
為每個批次分配一個唯一的 ID。如果批次重試,則賦予相同的唯一 ID。
狀態更新在批次之間是有序的。例如,第二個批次的狀態更新只有在第一個批次的狀態更新完成後才可能進行。
分散式 RPC
分散式 RPC 用於查詢和檢索 Trident 拓撲中的結果。Storm 有一個內建的分散式 RPC 伺服器。分散式 RPC 伺服器接收來自客戶端的 RPC 請求,並將其傳遞給拓撲。拓撲處理請求並將結果傳送到分散式 RPC 伺服器,然後由分散式 RPC 伺服器重定向到客戶端。Trident 的分散式 RPC 查詢執行方式類似於普通的 RPC 查詢,但這些查詢是並行執行的。
何時使用 Trident?
在許多用例中,如果要求僅處理一次查詢,我們可以透過在 Trident 中編寫拓撲來實現。另一方面,在 Storm 的情況下,很難實現完全一次處理。因此,對於需要完全一次處理的用例,Trident 將很有用。Trident 並非適用於所有用例,特別是高效能用例,因為它增加了 Storm 的複雜性並管理狀態。
Trident 的工作示例
我們將把上一節中完成的呼叫日誌分析器應用程式轉換為 Trident 框架。由於 Trident 的高階 API,Trident 應用程式將比普通的 Storm 應用程式相對容易。Storm 將基本上需要在 Trident 中執行任何一個 Function、Filter、Aggregate、GroupBy、Join 和 Merge 操作。最後,我們將使用LocalDRPC類啟動 DRPC 伺服器,並使用LocalDRPC類的execute方法搜尋一些關鍵字。
格式化呼叫資訊
FormatCall 類的目的是格式化包含“呼叫者號碼”和“接收者號碼”的呼叫資訊。完整的程式程式碼如下:
編碼:FormatCall.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class FormatCall extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String fromMobileNumber = tuple.getString(0);
String toMobileNumber = tuple.getString(1);
collector.emit(new Values(fromMobileNumber + " - " + toMobileNumber));
}
}
CSVSplit
CSVSplit 類的目的是根據“逗號 (,)”分割輸入字串,併發出字串中的每個單詞。此函式用於解析分散式查詢的輸入引數。完整的程式碼如下:
編碼:CSVSplit.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class CSVSplit extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
for(String word: tuple.getString(0).split(",")) {
if(word.length() > 0) {
collector.emit(new Values(word));
}
}
}
}
日誌分析器
這是主應用程式。最初,應用程式將初始化 TridentTopology 並使用FeederBatchSpout提供呼叫者資訊。可以使用 TridentTopology 類的newStream方法建立 Trident 拓撲流。類似地,可以使用 TridentTopology 類的newDRCPStream方法建立 Trident 拓撲 DRPC 流。可以使用 LocalDRPC 類建立一個簡單的 DRCP 伺服器。LocalDRPC具有 execute 方法來搜尋一些關鍵字。完整的程式碼如下所示。
編碼:LogAnalyserTrident.java
import java.util.*;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.utils.DRPCClient;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import storm.trident.TridentState;
import storm.trident.TridentTopology;
import storm.trident.tuple.TridentTuple;
import storm.trident.operation.builtin.FilterNull;
import storm.trident.operation.builtin.Count;
import storm.trident.operation.builtin.Sum;
import storm.trident.operation.builtin.MapGet;
import storm.trident.operation.builtin.Debug;
import storm.trident.operation.BaseFilter;
import storm.trident.testing.FixedBatchSpout;
import storm.trident.testing.FeederBatchSpout;
import storm.trident.testing.Split;
import storm.trident.testing.MemoryMapState;
import com.google.common.collect.ImmutableList;
public class LogAnalyserTrident {
public static void main(String[] args) throws Exception {
System.out.println("Log Analyser Trident");
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(ImmutableList.of("fromMobileNumber",
"toMobileNumber", "duration"));
TridentState callCounts = topology
.newStream("fixed-batch-spout", testSpout)
.each(new Fields("fromMobileNumber", "toMobileNumber"),
new FormatCall(), new Fields("call"))
.groupBy(new Fields("call"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(),
new Fields("count"));
LocalDRPC drpc = new LocalDRPC();
topology.newDRPCStream("call_count", drpc)
.stateQuery(callCounts, new Fields("args"), new MapGet(), new Fields("count"));
topology.newDRPCStream("multiple_call_count", drpc)
.each(new Fields("args"), new CSVSplit(), new Fields("call"))
.groupBy(new Fields("call"))
.stateQuery(callCounts, new Fields("call"), new MapGet(),
new Fields("count"))
.each(new Fields("call", "count"), new Debug())
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
Config conf = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("trident", conf, topology.build());
Random randomGenerator = new Random();
int idx = 0;
while(idx < 10) {
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123402", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123403", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123404", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123402",
"1234123403", randomGenerator.nextInt(60))));
idx = idx + 1;
}
System.out.println("DRPC : Query starts");
System.out.println(drpc.execute("call_count","1234123401 - 1234123402"));
System.out.println(drpc.execute("multiple_call_count", "1234123401 -
1234123402,1234123401 - 1234123403"));
System.out.println("DRPC : Query ends");
cluster.shutdown();
drpc.shutdown();
// DRPCClient client = new DRPCClient("drpc.server.location", 3772);
}
}
構建和執行應用程式
完整的應用程式包含三個 Java 程式碼。它們如下:
- FormatCall.java
- CSVSplit.java
- LogAnalyerTrident.java
可以使用以下命令構建應用程式:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.java
可以使用以下命令執行應用程式:
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserTrident
輸出
應用程式啟動後,將輸出有關叢集啟動過程、操作處理、DRPC 伺服器和客戶端資訊以及最終叢集關閉過程的完整詳細資訊。此輸出將顯示在控制檯上,如下所示。
DRPC : Query starts [["1234123401 - 1234123402",10]] DEBUG: [1234123401 - 1234123402, 10] DEBUG: [1234123401 - 1234123403, 10] [[20]] DRPC : Query ends
Twitter 中的 Apache Storm
在本章中,我們將討論 Apache Storm 的一個即時應用程式。我們將瞭解 Storm 如何在 Twitter 中使用。
Twitter 是一種線上社交網路服務,提供了一個傳送和接收使用者推文的平臺。註冊使用者可以閱讀和釋出推文,但未註冊使用者只能閱讀推文。主題標籤用於透過在相關關鍵字前新增 # 來按關鍵字對推文進行分類。現在讓我們以查詢每個主題使用最多的主題標籤的即時場景為例。
Spout 建立
Spout 的目的是儘快獲取人們提交的推文。Twitter 提供“Twitter 流式 API”,這是一個基於 Web 服務的工具,用於即時檢索人們提交的推文。Twitter 流式 API 可以透過任何程式語言訪問。
twitter4j 是一個開源的非官方 Java 庫,它提供了一個基於 Java 的模組來輕鬆訪問 Twitter 流式 API。twitter4j 提供了一個基於監聽器的框架來訪問推文。要訪問 Twitter 流式 API,我們需要註冊 Twitter 開發者帳戶,並獲取以下 OAuth 身份驗證詳細資訊。
- 客戶金鑰
- 客戶金鑰秘鑰
- 訪問令牌
- 訪問令牌秘鑰
Storm 在其入門工具包中提供了一個 Twitter Spout,TwitterSampleSpout。我們將使用它來檢索推文。Spout 需要 OAuth 身份驗證詳細資訊和至少一個關鍵字。Spout 將根據關鍵字發出即時推文。完整的程式程式碼如下所示。
編碼:TwitterSampleSpout.java
import java.util.Map;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.FilterQuery;
import twitter4j.StallWarning;
import twitter4j.Status;
import twitter4j.StatusDeletionNotice;
import twitter4j.StatusListener;
import twitter4j.TwitterStream;
import twitter4j.TwitterStreamFactory;
import twitter4j.auth.AccessToken;
import twitter4j.conf.ConfigurationBuilder;
import backtype.storm.Config;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
@SuppressWarnings("serial")
public class TwitterSampleSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
LinkedBlockingQueue<Status> queue = null;
TwitterStream _twitterStream;
String consumerKey;
String consumerSecret;
String accessToken;
String accessTokenSecret;
String[] keyWords;
public TwitterSampleSpout(String consumerKey, String consumerSecret,
String accessToken, String accessTokenSecret, String[] keyWords) {
this.consumerKey = consumerKey;
this.consumerSecret = consumerSecret;
this.accessToken = accessToken;
this.accessTokenSecret = accessTokenSecret;
this.keyWords = keyWords;
}
public TwitterSampleSpout() {
// TODO Auto-generated constructor stub
}
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
queue = new LinkedBlockingQueue<Status>(1000);
_collector = collector;
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
}
@Override
public void onDeletionNotice(StatusDeletionNotice sdn) {}
@Override
public void onTrackLimitationNotice(int i) {}
@Override
public void onScrubGeo(long l, long l1) {}
@Override
public void onException(Exception ex) {}
@Override
public void onStallWarning(StallWarning arg0) {
// TODO Auto-generated method stub
}
};
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
_twitterStream = new TwitterStreamFactory(cb.build()).getInstance();
_twitterStream.addListener(listener);
if (keyWords.length == 0) {
_twitterStream.sample();
}else {
FilterQuery query = new FilterQuery().track(keyWords);
_twitterStream.filter(query);
}
}
@Override
public void nextTuple() {
Status ret = queue.poll();
if (ret == null) {
Utils.sleep(50);
} else {
_collector.emit(new Values(ret));
}
}
@Override
public void close() {
_twitterStream.shutdown();
}
@Override
public Map<String, Object> getComponentConfiguration() {
Config ret = new Config();
ret.setMaxTaskParallelism(1);
return ret;
}
@Override
public void ack(Object id) {}
@Override
public void fail(Object id) {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("tweet"));
}
}
主題標籤讀取 Bolt
Spout 發出的推文將轉發到HashtagReaderBolt,它將處理推文併發出所有可用的主題標籤。HashtagReaderBolt 使用 twitter4j 提供的getHashTagEntities方法。getHashTagEntities 讀取推文並返回主題標籤列表。完整的程式程式碼如下:
編碼:HashtagReaderBolt.java
import java.util.HashMap;
import java.util.Map;
import twitter4j.*;
import twitter4j.conf.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagReaderBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
Status tweet = (Status) tuple.getValueByField("tweet");
for(HashtagEntity hashtage : tweet.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
this.collector.emit(new Values(hashtage.getText()));
}
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
主題標籤計數 Bolt
發出的主題標籤將轉發到HashtagCounterBolt。此 Bolt 將處理所有主題標籤,並使用 Java Map 物件將每個主題標籤及其計數儲存在記憶體中。完整的程式程式碼如下所示。
編碼:HashtagCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String key = tuple.getString(0);
if(!counterMap.containsKey(key)){
counterMap.put(key, 1);
}else{
Integer c = counterMap.get(key) + 1;
counterMap.put(key, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println("Result: " + entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
提交拓撲
提交拓撲是主應用程式。Twitter 拓撲包含TwitterSampleSpout、HashtagReaderBolt和HashtagCounterBolt。以下程式程式碼顯示瞭如何提交拓撲。
編碼:TwitterHashtagStorm.java
import java.util.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class TwitterHashtagStorm {
public static void main(String[] args) throws Exception{
String consumerKey = args[0];
String consumerSecret = args[1];
String accessToken = args[2];
String accessTokenSecret = args[3];
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 4, arguments.length);
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("twitter-spout", new TwitterSampleSpout(consumerKey,
consumerSecret, accessToken, accessTokenSecret, keyWords));
builder.setBolt("twitter-hashtag-reader-bolt", new HashtagReaderBolt())
.shuffleGrouping("twitter-spout");
builder.setBolt("twitter-hashtag-counter-bolt", new HashtagCounterBolt())
.fieldsGrouping("twitter-hashtag-reader-bolt", new Fields("hashtag"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("TwitterHashtagStorm", config,
builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}
構建和執行應用程式
完整的應用程式包含四個 Java 程式碼。它們如下:
- TwitterSampleSpout.java
- HashtagReaderBolt.java
- HashtagCounterBolt.java
- TwitterHashtagStorm.java
您可以使用以下命令編譯應用程式:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*” *.java
使用以下命令執行應用程式:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*”:. TwitterHashtagStorm <customerkey> <customersecret> <accesstoken> <accesstokensecret> <keyword1> <keyword2> … <keywordN>
輸出
應用程式將列印當前可用的主題標籤及其計數。輸出應類似於以下內容:
Result: jazztastic : 1 Result: foodie : 1 Result: Redskins : 1 Result: Recipe : 1 Result: cook : 1 Result: android : 1 Result: food : 2 Result: NoToxicHorseMeat : 1 Result: Purrs4Peace : 1 Result: livemusic : 1 Result: VIPremium : 1 Result: Frome : 1 Result: SundayRoast : 1 Result: Millennials : 1 Result: HealthWithKier : 1 Result: LPs30DaysofGratitude : 1 Result: cooking : 1 Result: gameinsight : 1 Result: Countryfile : 1 Result: androidgames : 1
雅虎財經中的 Apache Storm
雅虎財經是網際網路領先的商業新聞和金融資料網站。它是雅虎的一部分,提供有關金融新聞、市場統計、國際市場資料以及任何人都可以訪問的其他金融資源資訊。
如果您是註冊的雅虎使用者,則可以自定義雅虎財經以利用其某些產品。雅虎財經 API 用於從雅虎查詢財務資料。
此 API 顯示的資料比即時資料延遲 15 分鐘,並且每 1 分鐘更新一次其資料庫,以訪問當前的股票相關資訊。現在讓我們以一家公司的即時場景為例,看看如何在股票價值跌破 100 時發出警報。
Spout 建立
Spout 的目的是獲取公司詳細資訊並將價格發出到 Bolt。您可以使用以下程式程式碼建立 Spout。
編碼:YahooFinanceSpout.java
import java.util.*;
import java.io.*;
import java.math.BigDecimal;
//import yahoofinace packages
import yahoofinance.YahooFinance;
import yahoofinance.Stock;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
public class YahooFinanceSpout implements IRichSpout {
private SpoutOutputCollector collector;
private boolean completed = false;
private TopologyContext context;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector){
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
try {
Stock stock = YahooFinance.get("INTC");
BigDecimal price = stock.getQuote().getPrice();
this.collector.emit(new Values("INTC", price.doubleValue()));
stock = YahooFinance.get("GOOGL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("GOOGL", price.doubleValue()));
stock = YahooFinance.get("AAPL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("AAPL", price.doubleValue()));
} catch(Exception e) {}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("company", "price"));
}
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
Bolt 建立
此處,Bolt 的目的是在價格跌破 100 時處理給定公司的價格。它使用 Java Map 物件在股票價格跌破 100 時將截止價格限制警報設定為true;否則為 false。完整的程式程式碼如下:
編碼:PriceCutOffBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class PriceCutOffBolt implements IRichBolt {
Map<String, Integer> cutOffMap;
Map<String, Boolean> resultMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.cutOffMap = new HashMap <String, Integer>();
this.cutOffMap.put("INTC", 100);
this.cutOffMap.put("AAPL", 100);
this.cutOffMap.put("GOOGL", 100);
this.resultMap = new HashMap<String, Boolean>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String company = tuple.getString(0);
Double price = tuple.getDouble(1);
if(this.cutOffMap.containsKey(company)){
Integer cutOffPrice = this.cutOffMap.get(company);
if(price < cutOffPrice) {
this.resultMap.put(company, true);
} else {
this.resultMap.put(company, false);
}
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Boolean> entry:resultMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("cut_off_price"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
提交拓撲
這是主應用程式,其中 YahooFinanceSpout.java 和 PriceCutOffBolt.java 連線在一起並生成拓撲。以下程式程式碼顯示瞭如何提交拓撲。
編碼:YahooFinanceStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class YahooFinanceStorm {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("yahoo-finance-spout", new YahooFinanceSpout());
builder.setBolt("price-cutoff-bolt", new PriceCutOffBolt())
.fieldsGrouping("yahoo-finance-spout", new Fields("company"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("YahooFinanceStorm", config, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}
構建和執行應用程式
完整的應用程式包含三個 Java 程式碼。它們如下:
- YahooFinanceSpout.java
- PriceCutOffBolt.java
- YahooFinanceStorm.java
可以使用以下命令構建應用程式:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*” *.java
可以使用以下命令執行應用程式:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*”:. YahooFinanceStorm
輸出
輸出將類似於以下內容:
GOOGL : false AAPL : false INTC : true
Apache Storm - 應用
Apache Storm 框架支援當今許多最佳的工業應用。在本章中,我們將簡要概述 Storm 的一些最著名的應用。
Klout
Klout 是一款使用社交媒體分析根據線上社交影響力對使用者進行排名的應用程式,透過Klout 分數,這是一個介於 1 和 100 之間的數值。Klout 使用 Apache Storm 的內建 Trident 抽象來建立流式傳輸資料的複雜拓撲。
天氣頻道
天氣頻道使用 Storm 拓撲來攝取天氣資料。它已與 Twitter 合作,以便在 Twitter 和移動應用程式上啟用天氣資訊廣告。OpenSignal 是一家專門從事無線覆蓋範圍測繪的公司。StormTag 和WeatherSignal 是 OpenSignal 建立的天氣相關專案。StormTag 是一款藍牙氣象站,可連線到鑰匙扣上。裝置收集的天氣資料會發送到 WeatherSignal 應用程式和 OpenSignal 伺服器。
電信行業
電信提供商每秒處理數百萬個電話呼叫。他們對掉話和聲音質量差進行取證分析。呼叫詳細資訊記錄以每秒數百萬的速度流入,Apache Storm 即時處理這些記錄並識別任何令人擔憂的模式。Storm 分析可用於持續改進通話質量。