- Apache Kafka 教程
- Apache Kafka - 首頁
- Apache Kafka - 簡介
- Apache Kafka - 基礎知識
- Apache Kafka - 叢集架構
- Apache Kafka - 工作流程
- Apache Kafka - 安裝步驟
- Apache Kafka - 基本操作
- 簡單的生產者示例
- 消費者組示例
- 與Storm整合
- 與Spark整合
- 即時應用(Twitter)
- Apache Kafka - 工具
- Apache Kafka - 應用
- Apache Kafka 有用資源
- Apache Kafka 快速指南
- Apache Kafka - 有用資源
- Apache Kafka - 討論
Apache Kafka 快速指南
Apache Kafka - 簡介
在大資料中,使用了海量資料。關於資料,我們面臨兩個主要挑戰。第一個挑戰是如何收集大量資料,第二個挑戰是如何分析收集到的資料。為了克服這些挑戰,您需要一個訊息系統。
Kafka專為分散式高吞吐量系統而設計。Kafka往往可以很好地替代更傳統的訊息代理。與其他訊息系統相比,Kafka具有更高的吞吐量、內建分割槽、複製和固有的容錯性,這使其非常適合大規模訊息處理應用程式。
什麼是訊息系統?
訊息系統負責將資料從一個應用程式傳輸到另一個應用程式,這樣應用程式可以專注於資料,而不必擔心如何共享資料。分散式訊息傳遞基於可靠訊息排隊的概念。訊息在客戶端應用程式和訊息系統之間非同步排隊。兩種型別的訊息模式可用——一種是點對點,另一種是釋出-訂閱(pub-sub)訊息系統。大多數訊息模式遵循**pub-sub**。
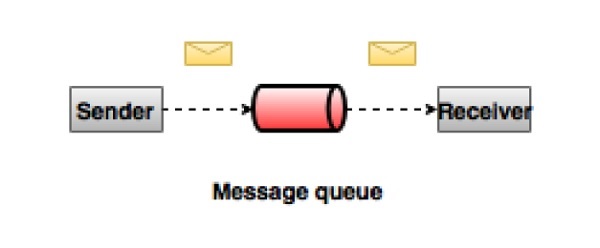
點對點訊息系統
在點對點系統中,訊息持久化在佇列中。一個或多個消費者可以消費佇列中的訊息,但特定訊息最多隻能被一個消費者消費。一旦消費者讀取佇列中的訊息,它就會從該佇列中消失。此係統的典型示例是訂單處理系統,其中每個訂單將由一個訂單處理器處理,但多個訂單處理器也可以同時工作。下圖描述了該結構。
釋出-訂閱訊息系統
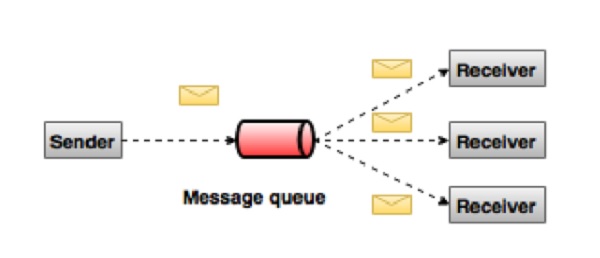
在釋出-訂閱系統中,訊息持久化在主題中。與點對點系統不同,消費者可以訂閱一個或多個主題並消費該主題中的所有訊息。在釋出-訂閱系統中,訊息生產者稱為釋出者,訊息消費者稱為訂閱者。一個現實世界的例子是衛星電視,它釋出不同的頻道,如體育、電影、音樂等,任何人都可以訂閱他們自己的一組頻道並在他們的訂閱頻道可用時接收它們。
什麼是Kafka?
Apache Kafka是一個分散式釋出-訂閱訊息系統和一個強大的佇列,它可以處理大量資料,並使您可以將訊息從一個端點傳遞到另一個端點。Kafka適用於離線和線上訊息消費。Kafka訊息持久化到磁碟,並在叢集內複製以防止資料丟失。Kafka構建在ZooKeeper同步服務之上。它與Apache Storm和Spark整合得很好,用於即時流資料分析。
優勢
以下是Kafka的一些優勢:
**可靠性** - Kafka是分散式的、分割槽的、複製的和容錯的。
**可擴充套件性** - Kafka訊息系統可以輕鬆擴充套件而無需停機。
**永續性** - Kafka使用“分散式提交日誌”,這意味著訊息儘可能快地持久化到磁碟,因此它是持久的。
**效能** - Kafka對釋出和訂閱訊息都具有高吞吐量。即使儲存了TB級訊息,它也能保持穩定的效能。
Kafka非常快,保證零停機時間和零資料丟失。
用例
Kafka可以用於許多用例。其中一些列在下面:
**指標** - Kafka通常用於操作監控資料。這涉及聚合來自分散式應用程式的統計資料,以生成集中的操作資料饋送。
**日誌聚合解決方案** - Kafka可用於跨組織收集來自多個服務的日誌,並以標準格式將其提供給多個消費者。
**流處理** - Storm和Spark Streaming等流行框架從主題讀取資料,處理它,並將處理後的資料寫入新主題,在那裡它可供使用者和應用程式使用。Kafka強大的永續性在流處理中也非常有用。
對Kafka的需求
Kafka是一個統一的平臺,用於處理所有即時資料饋送。Kafka支援低延遲訊息傳遞,並在機器故障情況下保證容錯性。它能夠處理大量不同的消費者。Kafka非常快,每秒執行200萬次寫入。Kafka將所有資料持久化到磁碟,這意味著所有寫入都進入作業系統的頁面快取(RAM)。這使得將資料從頁面快取傳輸到網路套接字非常高效。
Apache Kafka - 基礎知識
在深入研究Kafka之前,您必須瞭解主要術語,例如主題、代理、生產者和消費者。下圖說明了主要術語,表格詳細描述了圖表元件。
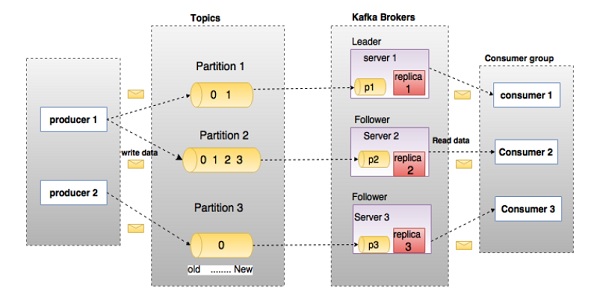
在上圖中,一個主題配置為三個分割槽。分割槽1有兩個偏移量因子0和1。分割槽2有四個偏移量因子0、1、2和3。分割槽3有一個偏移量因子0。副本的ID與其託管它的伺服器的ID相同。
假設,如果主題的複製因子設定為3,則Kafka將建立每個分割槽的3個相同副本並將它們放置在叢集中以使其可用於所有操作。為了平衡叢集中的負載,每個代理儲存一個或多個這些分割槽。多個生產者和消費者可以同時釋出和檢索訊息。
| 序號 | 元件和描述 |
|---|---|
| 1 | 主題 屬於特定類別的一系列訊息稱為主題。資料儲存在主題中。 主題被分成分割槽。對於每個主題,Kafka至少保留一個分割槽。每個這樣的分割槽都包含按不變順序排列的訊息。分割槽實現為一組大小相等的段檔案。 |
| 2 | 分割槽 主題可能有多個分割槽,因此它可以處理任意數量的資料。 |
| 3 |
分割槽偏移量 每個分割槽訊息都有一個唯一的序列ID,稱為“偏移量”。 |
| 4 |
分割槽的副本 副本只不過是分割槽的“備份”。副本永遠不會讀取或寫入資料。它們用於防止資料丟失。 |
| 5 |
代理
|
| 6 |
Kafka叢集 Kafka擁有多個代理被稱為Kafka叢集。Kafka叢集可以在不停機的情況下擴充套件。這些叢集用於管理訊息資料的永續性和複製。 |
| 7 |
生產者 生產者是向一個或多個Kafka主題釋出訊息的釋出者。生產者將資料傳送到Kafka代理。每次生產者向代理釋出訊息時,代理只是將訊息附加到最後一個段檔案。實際上,訊息將附加到分割槽。生產者也可以將訊息傳送到他們選擇的分割槽。 |
| 8 |
消費者 消費者從代理讀取資料。消費者訂閱一個或多個主題,並透過從代理拉取資料來使用已釋出的訊息。 |
| 9 |
領導者 “領導者”是負責給定分割槽的所有讀寫操作的節點。每個分割槽都有一個充當領導者的伺服器。 |
| 10 |
追隨者 遵循領導者指令的節點稱為追隨者。如果領導者失敗,一個追隨者將自動成為新的領導者。追隨者充當普通消費者,拉取訊息並更新其自己的資料儲存。 |
Apache Kafka - 叢集架構
請看下面的圖示。它顯示了Kafka的叢集圖。

下表描述了上圖中顯示的每個元件。
| 序號 | 元件和描述 |
|---|---|
| 1 |
代理 Kafka叢集通常包含多個代理以保持負載平衡。Kafka代理是無狀態的,因此它們使用ZooKeeper來維護其叢集狀態。一個Kafka代理例項每秒可以處理數十萬次讀寫操作,每個代理可以處理TB級訊息而不會影響效能。Kafka代理領導者選舉可以由ZooKeeper完成。 |
| 2 |
ZooKeeper ZooKeeper用於管理和協調Kafka代理。ZooKeeper服務主要用於通知生產者和消費者Kafka系統中任何新代理的存在或代理的故障。根據Zookeeper收到的關於代理存在或故障的通知,生產者和消費者做出決策,並開始與其他代理協調其任務。 |
| 3 |
生產者 生產者將資料推送到代理。當啟動新的代理時,所有生產者都會搜尋它並自動向該新代理傳送訊息。Kafka生產者不會等待代理的確認,並儘快傳送訊息,直到代理可以處理。 |
| 4 |
消費者 由於Kafka代理是無狀態的,這意味著消費者必須使用分割槽偏移量來維護已消費的訊息數量。如果消費者確認特定的訊息偏移量,則意味著消費者已消費所有先前訊息。消費者向代理發出非同步拉取請求,以準備要消費的位元組緩衝區。消費者只需提供偏移量值即可將分割槽中的任何點倒帶或跳過。消費者偏移量值由ZooKeeper通知。 |
Apache Kafka - 工作流程
目前為止,我們討論了Kafka的核心概念。現在讓我們來了解一下Kafka的工作流程。
Kafka簡單來說就是多個主題的集合,每個主題又可以分成一個或多個分割槽。Kafka分割槽是一個線性排序的訊息序列,每條訊息都由其索引(稱為偏移量)標識。Kafka叢集中的所有資料都是各個分割槽的無交集並集。傳入的訊息寫入分割槽的末尾,訊息由消費者順序讀取。透過將訊息複製到不同的代理來提供永續性。
Kafka以快速、可靠、持久、容錯和零停機的方式提供釋出-訂閱和基於佇列的訊息系統。在這兩種情況下,生產者只需將訊息傳送到主題,消費者可以根據需要選擇任何一種訊息系統。讓我們在下一節中按照步驟來了解消費者如何選擇他們想要的訊息系統。
釋出-訂閱訊息的工作流程
以下是釋出-訂閱訊息的逐步工作流程:
生產者定期向主題傳送訊息。
Kafka代理將所有訊息儲存在為該特定主題配置的分割槽中。它確保訊息在分割槽之間平均分配。如果生產者傳送兩條訊息,並且有兩個分割槽,Kafka將把一條訊息儲存在第一個分割槽中,另一條訊息儲存在第二個分割槽中。
消費者訂閱特定主題。
一旦消費者訂閱了主題,Kafka將向消費者提供該主題的當前偏移量,並將其儲存在ZooKeeper叢集中。
消費者將定期(例如100毫秒)向Kafka請求新訊息。
一旦Kafka從生產者接收到訊息,它就會將這些訊息轉發給消費者。
消費者將接收訊息並處理它。
訊息處理完畢後,消費者將向Kafka代理傳送確認。
Kafka收到確認後,它會將偏移量更改為新值並在ZooKeeper中更新它。由於偏移量儲存在ZooKeeper中,即使伺服器發生故障,消費者也可以正確讀取下一條訊息。
上述流程將重複,直到消費者停止請求。
消費者可以選擇隨時回溯/跳過到主題的所需偏移量並讀取所有後續訊息。
佇列訊息/消費者組的工作流程
在佇列訊息系統中,不是單個消費者,而是一組具有相同“組ID”的消費者將訂閱主題。簡單來說,使用相同“組ID”訂閱主題的消費者被視為一個組,訊息在它們之間共享。讓我們檢查一下這個系統的實際工作流程。
生產者定期向主題傳送訊息。
Kafka將所有訊息儲存在為該特定主題配置的分割槽中,類似於之前的場景。
單個消費者訂閱特定主題,假設為“Topic-01”,其“組ID”為“Group-1”。
Kafka與消費者的互動方式與釋出-訂閱訊息相同,直到新的消費者使用相同的“組ID”(“Group-1”)訂閱相同的主題“Topic-01”。
一旦新的消費者加入,Kafka就會切換到共享模式,並在兩個消費者之間共享資料。這種共享將持續到消費者的數量達到為該特定主題配置的分割槽數量。
一旦消費者的數量超過了分割槽的數量,新的消費者將不會收到任何進一步的訊息,直到任何一個現有的消費者取消訂閱。這種情況的出現是因為Kafka中的每個消費者至少會被分配一個分割槽,一旦所有分割槽都被分配給現有的消費者,新的消費者就必須等待。
此功能也稱為“消費者組”。同樣,Kafka將以非常簡單和高效的方式提供這兩個系統的優點。
ZooKeeper的作用
Apache Kafka的一個關鍵依賴項是Apache ZooKeeper,它是一個分散式配置和同步服務。ZooKeeper充當Kafka代理和消費者之間的協調介面。Kafka伺服器透過ZooKeeper叢集共享資訊。Kafka在ZooKeeper中儲存基本元資料,例如關於主題、代理、消費者偏移量(佇列讀取器)等資訊。
由於所有關鍵資訊都儲存在ZooKeeper中,並且它通常在其叢集中複製此資料,因此Kafka代理/ZooKeeper的故障不會影響Kafka叢集的狀態。Kafka將在ZooKeeper重啟後恢復狀態。這為Kafka提供了零停機時間。Kafka代理之間的領導者選舉也是在領導者故障時使用ZooKeeper完成的。
要了解更多關於ZooKeeper的資訊,請參考 zookeeper
讓我們在下一章繼續學習如何在你的機器上安裝Java、ZooKeeper和Kafka。
Apache Kafka - 安裝步驟
以下是安裝Java的步驟:
步驟1 - 驗證Java安裝
希望你現在已經在你機器上安裝了Java,所以你只需要使用以下命令驗證它。
$ java -version
如果Java已成功安裝在你的機器上,你將看到已安裝Java的版本。
步驟1.1 - 下載JDK
如果Java未下載,請訪問以下連結下載最新版本的JDK並下載最新版本。
http://www.oracle.com/technetwork/java/javase/downloads/index.html現在最新版本是JDK 8u 60,檔名為“jdk-8u60-linux-x64.tar.gz”。請將檔案下載到你的機器上。
步驟1.2 - 解壓檔案
通常情況下,下載的檔案儲存在downloads資料夾中,請驗證並使用以下命令解壓tar安裝包。
$ cd /go/to/download/path $ tar -zxf jdk-8u60-linux-x64.gz
步驟1.3 - 移動到Opt目錄
為了使所有使用者都可以使用Java,請將解壓後的Java內容移動到“usr/local/java”資料夾。
$ su password: (type password of root user) $ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/
步驟1.4 - 設定路徑
要設定路徑和JAVA_HOME變數,請將以下命令新增到~/.bashrc檔案中。
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60 export PATH=$PATH:$JAVA_HOME/bin
現在將所有更改應用到當前執行的系統。
$ source ~/.bashrc
步驟1.5 - Java Alternatives
使用以下命令更改Java Alternatives。
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100
步驟1.6 − 現在使用步驟1中解釋的驗證命令(java -version)驗證java。
步驟2 - ZooKeeper框架安裝
步驟2.1 - 下載ZooKeeper
要在你的機器上安裝ZooKeeper框架,請訪問以下連結並下載最新版本的ZooKeeper。
http://zookeeper.apache.org/releases.html目前,ZooKeeper的最新版本是3.4.6(ZooKeeper-3.4.6.tar.gz)。
步驟2.2 - 解壓tar檔案
使用以下命令解壓tar檔案
$ cd opt/ $ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6 $ mkdir data
步驟2.3 - 建立配置檔案
使用命令vi “conf/zoo.cfg”開啟名為“conf/zoo.cfg”的配置檔案,並將所有以下引數設定為起始點。
$ vi conf/zoo.cfg tickTime=2000 dataDir=/path/to/zookeeper/data clientPort=2181 initLimit=5 syncLimit=2
配置檔案儲存成功並返回終端後,您可以啟動ZooKeeper伺服器。
步驟2.4 - 啟動ZooKeeper伺服器
$ bin/zkServer.sh start
執行此命令後,您將獲得如下所示的響應:
$ JMX enabled by default $ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTED
步驟2.5 - 啟動CLI
$ bin/zkCli.sh
輸入上述命令後,您將連線到ZooKeeper伺服器,並將獲得以下響應。
Connecting to localhost:2181 ................ ................ ................ Welcome to ZooKeeper! ................ ................ WATCHER:: WatchedEvent state:SyncConnected type: None path:null [zk: localhost:2181(CONNECTED) 0]
步驟2.6 - 停止ZooKeeper伺服器
連線伺服器並執行所有操作後,您可以使用以下命令停止ZooKeeper伺服器:
$ bin/zkServer.sh stop
現在你已經成功地在你的機器上安裝了Java和ZooKeeper。讓我們看看安裝Apache Kafka的步驟。
步驟3 - Apache Kafka安裝
讓我們繼續按照以下步驟在你的機器上安裝Kafka。
步驟3.1 - 下載Kafka
要在你的機器上安裝Kafka,請點選以下連結:
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgz現在,最新版本,即kafka_2.11_0.9.0.0.tgz將下載到你的機器上。
步驟3.2 - 解壓tar檔案
使用以下命令解壓tar檔案:
$ cd opt/ $ tar -zxf kafka_2.11.0.9.0.0 tar.gz $ cd kafka_2.11.0.9.0.0
現在你已經將Kafka的最新版本下載到你的機器上了。
步驟3.3 - 啟動伺服器
您可以透過執行以下命令啟動伺服器:
$ bin/kafka-server-start.sh config/server.properties
伺服器啟動後,您將在螢幕上看到以下響應:
$ bin/kafka-server-start.sh config/server.properties [2016-01-02 15:37:30,410] INFO KafkaConfig values: request.timeout.ms = 30000 log.roll.hours = 168 inter.broker.protocol.version = 0.9.0.X log.preallocate = false security.inter.broker.protocol = PLAINTEXT ……………………………………………. …………………………………………….
步驟4 - 停止伺服器
執行所有操作後,您可以使用以下命令停止伺服器:
$ bin/kafka-server-stop.sh config/server.properties
既然我們已經討論了Kafka的安裝,我們可以在下一章學習如何在Kafka上執行基本操作。
Apache Kafka - 基本操作
首先讓我們開始實現“單節點-單個代理”配置,然後我們將把我們的設定遷移到單節點-多個代理配置。
希望你現在已經在你的機器上安裝了Java、ZooKeeper和Kafka。在遷移到Kafka叢集設定之前,你需要先啟動ZooKeeper,因為Kafka叢集使用ZooKeeper。
啟動ZooKeeper
開啟一個新的終端並輸入以下命令:
bin/zookeeper-server-start.sh config/zookeeper.properties
要啟動Kafka代理,請鍵入以下命令:
bin/kafka-server-start.sh config/server.properties
啟動Kafka代理後,在ZooKeeper終端上鍵入命令“jps”,你將看到以下響應:
821 QuorumPeerMain 928 Kafka 931 Jps
現在你可以看到終端上執行著兩個守護程序,其中QuorumPeerMain是ZooKeeper守護程序,另一個是Kafka守護程序。
單節點-單個代理配置
在此配置中,你只有一個ZooKeeper和代理ID例項。以下是配置步驟:
建立Kafka主題 − Kafka提供了一個名為“kafka-topics.sh”的命令列實用程式來在伺服器上建立主題。開啟新的終端並鍵入以下示例。
語法
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic-name
示例
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic Hello-Kafka
我們剛剛建立了一個名為“Hello-Kafka”的主題,它只有一個分割槽和一個副本因子。上面建立的輸出將類似於以下輸出:
輸出 − 建立主題“Hello-Kafka”
主題建立後,你可以在Kafka代理終端視窗中收到通知,並在config/server.properties檔案中指定的“/tmp/kafka-logs/”中看到已建立主題的日誌。
主題列表
要獲取Kafka伺服器中的主題列表,可以使用以下命令:
語法
bin/kafka-topics.sh --list --zookeeper localhost:2181
輸出
Hello-Kafka
由於我們已經建立了一個主題,它將只列出“Hello-Kafka”。假設你建立了多個主題,你將在輸出中看到主題名稱。
啟動生產者傳送訊息
語法
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-name
從上面的語法中,生產者命令列客戶端需要兩個主要引數:
代理列表 (Broker-list) − 我們要向其傳送訊息的代理列表。在本例中,我們只有一個代理。Config/server.properties 檔案包含代理埠 ID,由於我們知道我們的代理正在 9092 埠監聽,因此可以直接指定它。
主題名稱 − 這是一個主題名稱的示例。
示例
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-Kafka
生產者將等待來自標準輸入 (stdin) 的輸入,併發布到 Kafka 叢集。預設情況下,每行新內容都會作為一條新訊息釋出,然後在 config/producer.properties
檔案中指定預設生產者屬性。現在,您可以在終端中輸入幾行訊息,如下所示。
輸出
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-Kafka[2016-01-16 13:50:45,931] WARN property topic is not valid (kafka.utils.Verifia-bleProperties) Hello My first message
My second message
啟動消費者接收訊息
與生產者類似,預設消費者屬性在 config/consumer.properties
檔案中指定。開啟一個新的終端,並鍵入以下語法來消費訊息。
語法
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic topic-name --from-beginning
示例
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Hello-Kafka --from-beginning
輸出
Hello My first message My second message
最後,您可以從生產者的終端輸入訊息,並看到它們出現在消費者的終端中。目前為止,您已經對具有單個代理的單節點叢集有了很好的理解。現在讓我們繼續討論多個代理的配置。
單節點-多個代理配置
在繼續進行多個代理叢集設定之前,首先啟動您的 ZooKeeper 伺服器。
建立多個 Kafka 代理 − 我們已經在 config/server.properties 中已經有了一個 Kafka 代理例項。現在我們需要多個代理例項,因此將現有的 server.properties 檔案複製到兩個新的配置檔案中,並將其重新命名為 server-one.properties 和 server-two.properties。然後編輯這兩個新檔案並進行以下更改 −
config/server-one.properties
# The id of the broker. This must be set to a unique integer for each broker. broker.id=1 # The port the socket server listens on port=9093 # A comma seperated list of directories under which to store log files log.dirs=/tmp/kafka-logs-1
config/server-two.properties
# The id of the broker. This must be set to a unique integer for each broker. broker.id=2 # The port the socket server listens on port=9094 # A comma seperated list of directories under which to store log files log.dirs=/tmp/kafka-logs-2
啟動多個代理 − 對三個伺服器進行所有更改後,開啟三個新的終端,一次啟動一個代理。
Broker1 bin/kafka-server-start.sh config/server.properties Broker2 bin/kafka-server-start.sh config/server-one.properties Broker3 bin/kafka-server-start.sh config/server-two.properties
現在我們有三臺不同的代理在機器上執行。您可以自己嘗試一下,透過在 ZooKeeper 終端鍵入 jps 來檢查所有守護程序,然後您將看到響應。
建立主題
讓我們為這個主題分配複製因子值為 3,因為我們有三個不同的代理正在執行。如果您有兩個代理,則分配的副本值將為 2。
語法
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 -partitions 1 --topic topic-name
示例
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 -partitions 1 --topic Multibrokerapplication
輸出
created topic “Multibrokerapplication”
Describe
命令用於檢查哪個代理正在監聽當前建立的主題,如下所示 −
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic Multibrokerappli-cation
輸出
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic Multibrokerappli-cation Topic:Multibrokerapplication PartitionCount:1 ReplicationFactor:3 Configs: Topic:Multibrokerapplication Partition:0 Leader:0 Replicas:0,2,1 Isr:0,2,1
從以上輸出中,我們可以得出結論,第一行總結了所有分割槽,顯示主題名稱、分割槽計數和我們已經選擇的複製因子。在第二行中,每個節點都將成為隨機選擇的一部分分割槽的領導者。
在我們的例子中,我們看到我們的第一個代理(broker.id 為 0)是領導者。然後 Replicas:0,2,1 表示所有代理最終都會複製主題,Isr
是同步
副本的集合。好吧,這是當前處於活動狀態並與領導者同步的副本的子集。
啟動生產者傳送訊息
此過程與單代理設定中的過程相同。
示例
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Multibrokerapplication
輸出
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Multibrokerapplication [2016-01-20 19:27:21,045] WARN Property topic is not valid (kafka.utils.Verifia-bleProperties) This is single node-multi broker demo This is the second message
啟動消費者接收訊息
此過程與單代理設定中所示的過程相同。
示例
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Multibrokerapplica-tion --from-beginning
輸出
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Multibrokerapplica-tion —from-beginning This is single node-multi broker demo This is the second message
基本主題操作
本章將討論各種基本主題操作。
修改主題
您已經瞭解瞭如何在 Kafka 叢集中建立主題。現在讓我們使用以下命令修改已建立的主題
語法
bin/kafka-topics.sh —zookeeper localhost:2181 --alter --topic topic_name --parti-tions count
示例
We have already created a topic “Hello-Kafka” with single partition count and one replica factor. Now using “alter” command we have changed the partition count. bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic Hello-kafka --parti-tions 2
輸出
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected Adding partitions succeeded!
刪除主題
要刪除主題,可以使用以下語法。
語法
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic topic_name
示例
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic Hello-kafka
輸出
> Topic Hello-kafka marked for deletion
注意 −如果 delete.topic.enable 未設定為 true,則此操作將不會產生任何影響。
Apache Kafka - 簡單生產者示例
讓我們建立一個應用程式,使用 Java 客戶端釋出和消費訊息。Kafka 生產者客戶端包含以下 API。
KafkaProducer API
讓我們在本節中瞭解 Kafka 生產者 API 中最重要的一組 API。KafkaProducer API 的核心部分是 KafkaProducer
類。KafkaProducer 類提供了一個選項,可以在其建構函式中連線 Kafka 代理,並使用以下方法。
KafkaProducer 類提供 send 方法以非同步方式將訊息傳送到主題。send() 的簽名如下所示
producer.send(new ProducerRecord<byte[],byte[]>(topic, partition, key1, value1) , callback);
ProducerRecord − 生產者管理一個等待發送的記錄緩衝區。
回撥 (Callback) − 使用者提供的回撥函式,在伺服器確認記錄後執行(null 表示沒有回撥)。
KafkaProducer 類提供 flush 方法來確保所有先前傳送的訊息都已實際完成。flush 方法的語法如下 −
public void flush()
KafkaProducer 類提供 partitionFor 方法,該方法有助於獲取給定主題的分割槽元資料。這可用於自定義分割槽。此方法的簽名如下 −
public Map metrics()
它返回生產者維護的內部指標對映。
public void close() − KafkaProducer 類提供 close 方法,該方法會阻塞直到所有先前傳送的請求都已完成。
生產者 API
生產者 API 的核心部分是 Producer
類。生產者類提供了一個選項,可以透過以下方法在其建構函式中連線 Kafka 代理。
生產者類
生產者類提供 send 方法來傳送訊息到單個或多個主題,使用以下簽名。
public void send(KeyedMessaget<k,v> message) - sends the data to a single topic,par-titioned by key using either sync or async producer. public void send(List<KeyedMessage<k,v>>messages) - sends data to multiple topics. Properties prop = new Properties(); prop.put(producer.type,”async”) ProducerConfig config = new ProducerConfig(prop);
生產者有兩種型別:同步 (Sync) 和非同步 (Async)。
相同的 API 配置也適用於 Sync
生產者。它們之間的區別在於同步生產者直接傳送訊息,而非同步生產者在後臺傳送訊息。當您需要更高的吞吐量時,首選非同步生產者。在之前的版本(如 0.8)中,非同步生產者沒有 send() 的回撥來註冊錯誤處理程式。這僅在當前的 0.9 版本中可用。
public void close()
生產者類提供close方法來關閉生產者池與所有 Kafka 代理的連線。
配置設定
為了更好地理解,生產者 API 的主要配置設定列在下表中 −
| 序號 | 配置設定和說明 |
|---|---|
| 1 |
client.id 標識生產者應用程式 |
| 2 |
producer.type 同步或非同步 |
| 3 |
acks acks 配置控制生產者請求被認為完成的標準。 |
| 4 |
retries 如果生產者請求失敗,則會使用特定值自動重試。 |
| 5 |
bootstrap.servers 代理的引導列表。 |
| 6 |
linger.ms 如果要減少請求數量,可以將 linger.ms 設定為大於某個值。 |
| 7 |
key.serializer 序列化器介面的鍵。 |
| 8 |
value.serializer 序列化器介面的值。 |
| 9 |
batch.size 緩衝區大小。 |
| 10 |
buffer.memory 控制生產者可用於緩衝的總記憶體量。 |
ProducerRecord API
ProducerRecord 是傳送到 Kafka 叢集的鍵值對。ProducerRecord 類建構函式用於使用以下簽名建立帶有分割槽、鍵和值對的記錄。
public ProducerRecord (string topic, int partition, k key, v value)
主題 (Topic) − 將附加到記錄的使用者定義主題名稱。
分割槽 (Partition) − 分割槽計數
鍵 (Key) − 將包含在記錄中的鍵。
- 值 (Value) − 記錄內容
public ProducerRecord (string topic, k key, v value)
ProducerRecord 類建構函式用於建立具有鍵值對且沒有分割槽的記錄。
主題 (Topic) − 建立一個主題來分配記錄。
鍵 (Key) − 記錄的鍵。
值 (Value) − 記錄內容。
public ProducerRecord (string topic, v value)
ProducerRecord 類建立沒有分割槽和鍵的記錄。
主題 (Topic) − 建立一個主題。
值 (Value) − 記錄內容。
ProducerRecord 類的函式列在下表中 −
| 序號 | 類方法和說明 |
|---|---|
| 1 |
public string topic() 將附加到記錄的主題。 |
| 2 |
public K key() 將包含在記錄中的鍵。如果沒有此類鍵,則此處將返回 null。 |
| 3 |
public V value() 記錄內容。 |
| 4 |
partition() 記錄的分割槽計數 |
SimpleProducer 應用程式
在建立應用程式之前,首先啟動 ZooKeeper 和 Kafka 代理,然後使用 create topic 命令在 Kafka 代理中建立您自己的主題。之後,建立一個名為 SimpleProducer.java
的 Java 類,並輸入以下程式碼。
//import util.properties packages
import java.util.Properties;
//import simple producer packages
import org.apache.kafka.clients.producer.Producer;
//import KafkaProducer packages
import org.apache.kafka.clients.producer.KafkaProducer;
//import ProducerRecord packages
import org.apache.kafka.clients.producer.ProducerRecord;
//Create java class named “SimpleProducer”
public class SimpleProducer {
public static void main(String[] args) throws Exception{
// Check arguments length value
if(args.length == 0){
System.out.println("Enter topic name");
return;
}
//Assign topicName to string variable
String topicName = args[0].toString();
// create instance for properties to access producer configs
Properties props = new Properties();
//Assign localhost id
props.put("bootstrap.servers", “localhost:9092");
//Set acknowledgements for producer requests.
props.put("acks", “all");
//If the request fails, the producer can automatically retry,
props.put("retries", 0);
//Specify buffer size in config
props.put("batch.size", 16384);
//Reduce the no of requests less than 0
props.put("linger.ms", 1);
//The buffer.memory controls the total amount of memory available to the producer for buffering.
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer
<String, String>(props);
for(int i = 0; i < 10; i++)
producer.send(new ProducerRecord<String, String>(topicName,
Integer.toString(i), Integer.toString(i)));
System.out.println(“Message sent successfully”);
producer.close();
}
}
編譯 − 可以使用以下命令編譯應用程式。
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.java
執行 − 可以使用以下命令執行應用程式。
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleProducer <topic-name>
輸出
Message sent successfully To check the above output open new terminal and type Consumer CLI command to receive messages. >> bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic <topic-name> —from-beginning 1 2 3 4 5 6 7 8 9 10
簡單消費者示例
現在我們已經建立了一個生產者來向 Kafka 叢集傳送訊息。現在讓我們建立一個消費者來從 Kafka 叢集消費訊息。KafkaConsumer API 用於從 Kafka 叢集消費訊息。KafkaConsumer 類建構函式定義如下。
public KafkaConsumer(java.util.Map<java.lang.String,java.lang.Object> configs)
configs − 返回消費者配置的對映。
KafkaConsumer 類具有以下重要的函式,列在下表中。
| 序號 | 方法和說明 |
|---|---|
| 1 |
public java.util.Set<TopicPartition> assignment() 獲取消費者當前分配的分割槽集合。 |
| 2 |
public string subscription() 訂閱給定的主題列表以動態獲取分配的分割槽。 |
| 3 |
public void subscribe(java.util.List<java.lang.String> topics, ConsumerRebalanceListener listener) 訂閱給定的主題列表以動態獲取分配的分割槽。 |
| 4 |
public void unsubscribe() 取消訂閱給定分割槽列表中的主題。 |
| 5 |
public void subscribe(java.util.List<java.lang.String> topics) 訂閱給定的主題列表以動態獲取分配的分割槽。如果給定的主題列表為空,則其處理方式與 unsubscribe() 相同。 |
| 6 |
public void subscribe(java.util.regex.Pattern pattern, ConsumerRebalanceListener listener) 引數 pattern 指的是正則表示式格式的訂閱模式,引數 listener 獲取來自訂閱模式的通知。 |
| 7 |
public void assign(java.util.List<TopicPartition> partitions) 手動將分割槽列表分配給消費者。 |
| 8 |
poll() 獲取使用 subscribe/assign API 之一指定主題或分割槽的資料。如果在輪詢資料之前沒有訂閱主題,則將返回錯誤。 |
| 9 |
public void commitSync() 為所有已訂閱的主題和分割槽提交上次 poll() 返回的偏移量。相同的操作應用於 commitAsync()。 |
| 10 |
public void seek(TopicPartition partition, long offset) 獲取消費者將在下一個 poll() 方法中使用的當前偏移量值。 |
| 11 |
public void resume() 恢復已暫停的分割槽。 |
| 12 |
public void wakeup() 喚醒消費者。 |
ConsumerRecord API
ConsumerRecord API 用於接收來自 Kafka 叢集的記錄。此 API 包含主題名稱、分割槽編號(從中接收記錄)以及指向 Kafka 分割槽中記錄的偏移量。ConsumerRecord 類用於建立具有特定主題名稱、分割槽計數和
public ConsumerRecord(string topic,int partition, long offset,K key, V value)
主題 (Topic) − 從 Kafka 叢集接收到的消費者記錄的主題名稱。
分割槽 (Partition) − 主題的分割槽。
鍵 (Key) − 記錄的鍵,如果不存在鍵,則返回 null。
值 (Value) − 記錄內容。
ConsumerRecords API
ConsumerRecords API 充當 ConsumerRecord 的容器。此 API 用於儲存特定主題每個分割槽的 ConsumerRecord 列表。其建構函式定義如下。
public ConsumerRecords(java.util.Map<TopicPartition,java.util.List <Consumer-Record>K,V>>> records)
TopicPartition − 返回特定主題的分割槽對映。
Records − 返回 ConsumerRecord 列表。
ConsumerRecords 類定義了以下方法。
| 序號 | 方法和描述 |
|---|---|
| 1 |
public int count() 所有主題的記錄數量。 |
| 2 |
public Set partitions() 此記錄集中包含資料的分割槽集(如果未返回資料,則該集為空)。 |
| 3 |
public Iterator iterator() 迭代器使您可以迴圈遍歷集合,獲取或移除元素。 |
| 4 |
public List records() 獲取給定分割槽的記錄列表。 |
配置設定
Consumer 客戶端 API 的配置設定,主要的配置設定如下所示:
| 序號 | 設定和描述 |
|---|---|
| 1 |
bootstrap.servers 載入程式代理列表。 |
| 2 |
group.id 將單個消費者分配給一個組。 |
| 3 |
enable.auto.commit 如果值為 true,則啟用偏移量的自動提交,否則不提交。 |
| 4 |
auto.commit.interval.ms 返回多久將更新的已消費偏移量寫入 ZooKeeper。 |
| 5 |
session.timeout.ms 指示 Kafka 在放棄並繼續消費訊息之前,將等待 ZooKeeper 多久才能響應請求(讀取或寫入)。 |
SimpleConsumer 應用
生產者應用程式的步驟在這裡保持不變。首先,啟動您的 ZooKeeper 和 Kafka 代理。然後建立一個名為 “SimpleConsumer.java” 的 java 類,並輸入以下程式碼,建立 SimpleConsumer
應用程式。
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class SimpleConsumer {
public static void main(String[] args) throws Exception {
if(args.length == 0){
System.out.println("Enter topic name");
return;
}
//Kafka consumer configuration settings
String topicName = args[0].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer
<String, String>(props);
//Kafka Consumer subscribes list of topics here.
consumer.subscribe(Arrays.asList(topicName))
//print the topic name
System.out.println("Subscribed to topic " + topicName);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = con-sumer.poll(100);
for (ConsumerRecord<String, String> record : records)
// print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}
編譯 − 可以使用以下命令編譯應用程式。
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.java
執行 − 可以使用以下命令執行應用程式
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleConsumer <topic-name>
輸入 − 開啟生產者 CLI 並向主題傳送一些訊息。您可以將示例輸入設定為“Hello Consumer”。
輸出 − 輸出如下所示。
Subscribed to topic Hello-Kafka offset = 3, key = null, value = Hello Consumer
Apache Kafka - 消費者組示例
消費者組是從 Kafka 主題進行多執行緒或多機器消費。
消費者組
消費者可以使用相同的
group.id
加入組。組的最大並行度是組中消費者的數量 ← 分割槽的數量。
Kafka 將主題的分割槽分配給組中的消費者,以便組中的每個消費者只消費一個分割槽。
Kafka 保證一條訊息只會被組中的一個消費者讀取。
消費者可以按他們在日誌中儲存的順序檢視訊息。
消費者的重新平衡
新增更多程序/執行緒將導致 Kafka 重新平衡。如果任何消費者或代理未能向 ZooKeeper 傳送心跳,則可以透過 Kafka 叢集重新配置它。在此重新平衡期間,Kafka 將把可用的分割槽分配給可用的執行緒,可能會將分割槽移動到另一個程序。
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class ConsumerGroup {
public static void main(String[] args) throws Exception {
if(args.length < 2){
System.out.println("Usage: consumer <topic> <groupname>");
return;
}
String topic = args[0].toString();
String group = args[1].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", group);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.ByteArraySerializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topic));
System.out.println("Subscribed to topic " + topic);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}
編譯
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*" ConsumerGroup.java
執行
>>java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*":. ConsumerGroup <topic-name> my-group >>java -cp "/home/bala/Workspace/kafka/kafka_2.11-0.9.0.0/libs/*":. ConsumerGroup <topic-name> my-group
在這裡,我們建立了一個名為 my-group
的示例組,其中包含兩個消費者。類似地,您可以建立您的組和組中的消費者數量。
輸入
開啟生產者 CLI 併發送一些訊息,例如:
Test consumer group 01 Test consumer group 02
第一個程序的輸出
Subscribed to topic Hello-kafka offset = 3, key = null, value = Test consumer group 01
第二個程序的輸出
Subscribed to topic Hello-kafka offset = 3, key = null, value = Test consumer group 02
現在,希望您已經瞭解瞭如何使用 Java 客戶端演示來使用 SimpleConsumer 和 ConsumeGroup。現在您瞭解瞭如何使用 Java 客戶端傳送和接收訊息。讓我們在下一章繼續 Kafka 與大資料技術的整合。
Apache Kafka - 與 Storm 整合
在本章中,我們將學習如何將 Kafka 與 Apache Storm 整合。
關於 Storm
Storm 最初由 BackType 的 Nathan Marz 和團隊建立。在很短的時間內,Apache Storm 成為分散式即時處理系統的標準,允許您處理海量資料。Storm 非常快,基準測試顯示其每個節點每秒處理超過一百萬個元組。Apache Storm 持續執行,從配置的源(Spout)中消費資料,並將資料傳遞到處理管道(Bolt)。Spout 和 Bolt 組合構成一個 Topology。
與 Storm 整合
Kafka 和 Storm 自然地相互補充,它們強大的合作使您可以對快速移動的大資料進行即時流分析。Kafka 和 Storm 整合是為了使開發人員更容易地從 Storm topology 中提取和釋出資料流。
概念流程
Spout 是流的來源。例如,Spout 可以從 Kafka 主題讀取元組並將其作為流發出。Bolt 消費輸入流,處理並可能發出新的流。Bolt 可以執行任何操作,從執行函式、過濾元組、進行流聚合、流連線、與資料庫通訊等等。Storm topology 中的每個節點都並行執行。topology 會無限期執行,直到您終止它。Storm 將自動重新分配任何失敗的任務。此外,Storm 保證不會丟失資料,即使機器出現故障並且訊息丟失。
讓我們詳細瞭解 Kafka-Storm 整合 API。將 Kafka 與 Storm 整合的三個主要類如下:
BrokerHosts - ZkHosts & StaticHosts
BrokerHosts 是一個介面,ZkHosts 和 StaticHosts 是其兩個主要實現。ZkHosts 用於透過維護 ZooKeeper 中的詳細資訊來動態跟蹤 Kafka 代理,而 StaticHosts 用於手動/靜態設定 Kafka 代理及其詳細資訊。ZkHosts 是訪問 Kafka 代理的簡單快捷方法。
ZkHosts 的簽名如下:
public ZkHosts(String brokerZkStr, String brokerZkPath) public ZkHosts(String brokerZkStr)
其中 brokerZkStr 是 ZooKeeper 主機,brokerZkPath 是維護 Kafka 代理詳細資訊的 ZooKeeper 路徑。
KafkaConfig API
此 API 用於定義 Kafka 叢集的配置設定。Kafka Config 的簽名定義如下
public KafkaConfig(BrokerHosts hosts, string topic)
Hosts − BrokerHosts 可以是 ZkHosts/StaticHosts。
Topic − 主題名稱。
SpoutConfig API
Spoutconfig 是 KafkaConfig 的擴充套件,支援其他 ZooKeeper 資訊。
public SpoutConfig(BrokerHosts hosts, string topic, string zkRoot, string id)
Hosts − BrokerHosts 可以是 BrokerHosts 介面的任何實現
Topic − 主題名稱。
zkRoot − ZooKeeper 根路徑。
id − Spout 將其消費的偏移量的狀態儲存在 Zookeeper 中。id 應唯一標識您的 spout。
SchemeAsMultiScheme
SchemeAsMultiScheme 是一個介面,它決定了從 Kafka 消費的 ByteBuffer 如何轉換為 storm 元組。它派生自 MultiScheme 並接受 Scheme 類的實現。Scheme 類有很多實現,其中一種實現是 StringScheme,它將位元組解析為簡單的字串。它還控制輸出欄位的命名。簽名定義如下。
public SchemeAsMultiScheme(Scheme scheme)
Scheme − 從 kafka 消費的位元組緩衝區。
KafkaSpout API
KafkaSpout 是我們的 spout 實現,它將與 Storm 整合。它從 kafka 主題中獲取訊息,並將其作為元組發出到 Storm 生態系統中。KafkaSpout 從 SpoutConfig 獲取其配置詳細資訊。
下面是建立簡單的 Kafka spout 的示例程式碼。
// ZooKeeper connection string BrokerHosts hosts = new ZkHosts(zkConnString); //Creating SpoutConfig Object SpoutConfig spoutConfig = new SpoutConfig(hosts, topicName, "/" + topicName UUID.randomUUID().toString()); //convert the ByteBuffer to String. spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme()); //Assign SpoutConfig to KafkaSpout. KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
Bolt 建立
Bolt 是一個元件,它接收元組作為輸入,處理元組,併產生新的元組作為輸出。Bolt 將實現 IRichBolt 介面。在這個程式中,使用了兩個 bolt 類 WordSplitter-Bolt 和 WordCounterBolt 來執行操作。
IRichBolt 介面具有以下方法:
Prepare − 為 bolt 提供執行環境。執行器將執行此方法來初始化 spout。
Execute − 處理單個輸入元組。
Cleanup − 當 bolt 將要關閉時呼叫。
declareOutputFields − 宣告元組的輸出模式。
讓我們建立 SplitBolt.java,它實現將句子拆分成單詞的邏輯,以及 CountBolt.java,它實現分離唯一單詞並計算其出現次數的邏輯。
SplitBolt.java
import java.util.Map;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class SplitBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for(String word: words) {
word = word.trim();
if(!word.isEmpty()) {
word = word.toLowerCase();
collector.emit(new Values(word));
}
}
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public void cleanup() {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
CountBolt.java
import java.util.Map;
import java.util.HashMap;
import backtype.storm.tuple.Tuple;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class CountBolt implements IRichBolt{
Map<String, Integer> counters;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.counters = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String str = input.getString(0);
if(!counters.containsKey(str)){
counters.put(str, 1);
}else {
Integer c = counters.get(str) +1;
counters.put(str, c);
}
collector.ack(input);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counters.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
提交到 Topology
Storm topology 基本上是一個 Thrift 結構。TopologyBuilder 類提供簡單易用的方法來建立複雜的 topology。TopologyBuilder 類具有設定 spout (setSpout) 和設定 bolt (setBolt) 的方法。最後,TopologyBuilder 有 createTopology 來建立 topology。shuffleGrouping 和 fieldsGrouping 方法有助於為 spout 和 bolt 設定流分組。
本地叢集 − 出於開發目的,我們可以使用 LocalCluster
物件建立一個本地叢集,然後使用 LocalCluster
類的 submitTopology
方法提交 topology。
KafkaStormSample.java
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import backtype.storm.spout.SchemeAsMultiScheme;
import storm.kafka.trident.GlobalPartitionInformation;
import storm.kafka.ZkHosts;
import storm.kafka.Broker;
import storm.kafka.StaticHosts;
import storm.kafka.BrokerHosts;
import storm.kafka.SpoutConfig;
import storm.kafka.KafkaConfig;
import storm.kafka.KafkaSpout;
import storm.kafka.StringScheme;
public class KafkaStormSample {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
config.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
String zkConnString = "localhost:2181";
String topic = "my-first-topic";
BrokerHosts hosts = new ZkHosts(zkConnString);
SpoutConfig kafkaSpoutConfig = new SpoutConfig (hosts, topic, "/" + topic,
UUID.randomUUID().toString());
kafkaSpoutConfig.bufferSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.fetchSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.forceFromStart = true;
kafkaSpoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka-spout", new KafkaSpout(kafkaSpoutCon-fig));
builder.setBolt("word-spitter", new SplitBolt()).shuffleGroup-ing("kafka-spout");
builder.setBolt("word-counter", new CountBolt()).shuffleGroup-ing("word-spitter");
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("KafkaStormSample", config, builder.create-Topology());
Thread.sleep(10000);
cluster.shutdown();
}
}
在進行編譯之前,Kakfa-Storm 整合需要 curator ZooKeeper 客戶端 Java 庫。Curator 2.9.1 版本支援 Apache Storm 0.9.5 版本(我們在本教程中使用)。下載下面指定的 jar 檔案並將其放在 Java 類路徑中。
- curator-client-2.9.1.jar
- curator-framework-2.9.1.jar
包含依賴檔案後,使用以下命令編譯程式:
javac -cp "/path/to/Kafka/apache-storm-0.9.5/lib/*" *.java
執行
啟動 Kafka Producer CLI(在上一章中解釋),建立一個名為 my-first-topic
的新主題,並提供一些示例訊息,如下所示:
hello kafka storm spark test message another test message
現在使用以下命令執行應用程式:
java -cp “/path/to/Kafka/apache-storm-0.9.5/lib/*”:. KafkaStormSample
此應用程式的示例輸出如下所示:
storm : 1 test : 2 spark : 1 another : 1 kafka : 1 hello : 1 message : 2
Apache Kafka - 與 Spark 整合
在本章中,我們將討論如何將 Apache Kafka 與 Spark Streaming API 整合。
關於 Spark
Spark Streaming API 能夠對即時資料流進行可擴充套件、高吞吐量、容錯的流處理。資料可以從許多來源(如 Kafka、Flume、Twitter 等)提取,並可以使用複雜的演算法(例如 map、reduce、join 和 window 等高階函式)進行處理。最後,處理後的資料可以推送到檔案系統、資料庫和即時儀表板。彈性分散式資料集 (RDD) 是 Spark 的基本資料結構。它是一個不可變的分散式物件集合。RDD 中的每個資料集都細分為邏輯分割槽,這些分割槽可以在叢集的不同節點上計算。
與 Spark 整合
Kafka 是 Spark 流式處理的潛在訊息傳遞和整合平臺。Kafka 充當即時資料流的中心樞紐,並使用 Spark Streaming 中的複雜演算法進行處理。一旦資料被處理,Spark Streaming 就可以將結果釋出到另一個 Kafka 主題,或者儲存在 HDFS、資料庫或儀表板中。下圖描述了概念流程。

現在,讓我們詳細瞭解 Kafka-Spark API。
SparkConf API
它表示 Spark 應用程式的配置。用於將各種 Spark 引數設定為鍵值對。
SparkConf
類具有以下方法:
set(string key, string value) − 設定配置變數。
remove(string key) − 從配置中刪除鍵。
setAppName(string name) − 為您的應用程式設定應用程式名稱。
get(string key) − 獲取鍵
StreamingContext API
這是 Spark 功能的主要入口點。SparkContext 表示與 Spark 叢集的連線,可用於在叢集上建立 RDD、累加器和廣播變數。簽名定義如下所示。
public StreamingContext(String master, String appName, Duration batchDuration, String sparkHome, scala.collection.Seq<String> jars, scala.collection.Map<String,String> environment)
master − 要連線到的叢集 URL(例如 mesos://host:port、spark://host:port、local[4])。
appName − 作業的名稱,顯示在叢集 Web UI 上
batchDuration − 流資料將被劃分為批次的 時間間隔
public StreamingContext(SparkConf conf, Duration batchDuration)
透過提供新的 SparkContext 所需的配置來建立 StreamingContext。
conf − Spark 引數
batchDuration − 流資料將被劃分為批次的 時間間隔
KafkaUtils API
KafkaUtils API 用於將 Kafka 叢集連線到 Spark Streaming。此 API 包含一個重要的名為 createStream
的方法,其簽名如下所示。
public static ReceiverInputDStream<scala.Tuple2<String,String>> createStream( StreamingContext ssc, String zkQuorum, String groupId, scala.collection.immutable.Map<String,Object> topics, StorageLevel storageLevel)
上述方法用於建立一個輸入流,該流從 Kafka Broker 拉取訊息。
ssc − StreamingContext 物件。
zkQuorum − ZooKeeper 叢集地址。
groupId − 此消費者的組 ID。
topics − 返回要消費的主題對映。
storageLevel − 用於儲存接收到的物件的儲存級別。
KafkaUtils API 還有另一個方法 createDirectStream,用於建立一個輸入流,該流直接從 Kafka Broker 拉取訊息,無需使用任何接收器。此流可以保證 Kafka 中的每條訊息都只在轉換中包含一次。
示例應用程式是用 Scala 編寫的。要編譯該應用程式,請下載並安裝 sbt
,這是一個 Scala 構建工具(類似於 Maven)。主要的應用程式程式碼如下所示。
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, Produc-erRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
object KafkaWordCount {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <zkQuorum><group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
ssc.checkpoint("checkpoint")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
構建指令碼
spark-kafka 整合依賴於 spark、spark streaming 和 spark Kafka 整合 jar 包。建立一個名為 build.sbt
的新檔案,並指定應用程式的詳細資訊及其依賴項。sbt
將在編譯和打包應用程式時下載必要的 jar 包。
name := "Spark Kafka Project" version := "1.0" scalaVersion := "2.10.5" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.0" libraryDependencies += "org.apache.spark" %% "spark-streaming" % "1.6.0" libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka" % "1.6.0"
編譯/打包
執行以下命令來編譯和打包應用程式的 jar 檔案。我們需要將 jar 檔案提交到 Spark 控制檯才能執行應用程式。
sbt package
提交到 Spark
啟動 Kafka Producer CLI(在上一章中解釋),建立一個名為 my-first-topic
的新主題,並提供一些示例訊息,如下所示。
Another spark test message
執行以下命令將應用程式提交到 Spark 控制檯。
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-streaming -kafka_2.10:1.6.0 --class "KafkaWordCount" --master local[4] target/scala-2.10/spark -kafka-project_2.10-1.0.jar localhost:2181 <group name> <topic name> <number of threads>
此應用程式的示例輸出如下所示。
spark console messages .. (Test,1) (spark,1) (another,1) (message,1) spark console message ..
即時應用(Twitter)
讓我們分析一個即時應用程式,以獲取最新的 Twitter 饋送及其主題標籤。前面,我們已經看到了 Storm 和 Spark 與 Kafka 的整合。在這兩種情況下,我們都建立了一個 Kafka Producer(使用 cli)來向 Kafka 生態系統傳送訊息。然後,Storm 和 Spark 整合使用 Kafka Consumer 讀取訊息,並分別將其注入到 Storm 和 Spark 生態系統中。因此,實際上我們需要建立一個 Kafka Producer,它應該:
- 使用“Twitter Streaming API”讀取 Twitter 饋送,
- 處理饋送,
- 提取主題標籤,以及
- 將其傳送到 Kafka。
一旦 Kafka 接收到 主題標籤
,Storm/Spark 整合就會接收資訊並將其傳送到 Storm/Spark 生態系統。
Twitter Streaming API
可以使用任何程式語言訪問“Twitter Streaming API”。“twitter4j”是一個開源的、非官方的 Java 庫,它提供了一個基於 Java 的模組,可以輕鬆訪問“Twitter Streaming API”。“twitter4j”提供了一個基於監聽器的框架來訪問推文。要訪問“Twitter Streaming API”,我們需要註冊 Twitter 開發者帳戶,並獲取以下OAuth身份驗證詳細資訊。
- 客戶金鑰 (Customer key)
- 客戶金鑰密碼 (Customer secret)
- 訪問令牌 (Access token)
- 訪問令牌密碼 (Access token secret)
建立開發者帳戶後,下載“twitter4j”jar 檔案並將其放入 Java 類路徑。
完整的 Twitter Kafka Producer 程式碼 (KafkaTwitterProducer.java) 如下所示:
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.*;
import twitter4j.conf.*;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class KafkaTwitterProducer {
public static void main(String[] args) throws Exception {
LinkedBlockingQueue<Status> queue = new LinkedBlockingQueue<Sta-tus>(1000);
if(args.length < 5){
System.out.println(
"Usage: KafkaTwitterProducer <twitter-consumer-key>
<twitter-consumer-secret> <twitter-access-token>
<twitter-access-token-secret>
<topic-name> <twitter-search-keywords>");
return;
}
String consumerKey = args[0].toString();
String consumerSecret = args[1].toString();
String accessToken = args[2].toString();
String accessTokenSecret = args[3].toString();
String topicName = args[4].toString();
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 5, arguments.length);
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
TwitterStream twitterStream = new TwitterStreamFactory(cb.build()).get-Instance();
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
// System.out.println("@" + status.getUser().getScreenName()
+ " - " + status.getText());
// System.out.println("@" + status.getUser().getScreen-Name());
/*for(URLEntity urle : status.getURLEntities()) {
System.out.println(urle.getDisplayURL());
}*/
/*for(HashtagEntity hashtage : status.getHashtagEntities()) {
System.out.println(hashtage.getText());
}*/
}
@Override
public void onDeletionNotice(StatusDeletionNotice statusDeletion-Notice) {
// System.out.println("Got a status deletion notice id:"
+ statusDeletionNotice.getStatusId());
}
@Override
public void onTrackLimitationNotice(int numberOfLimitedStatuses) {
// System.out.println("Got track limitation notice:" +
num-berOfLimitedStatuses);
}
@Override
public void onScrubGeo(long userId, long upToStatusId) {
// System.out.println("Got scrub_geo event userId:" + userId +
"upToStatusId:" + upToStatusId);
}
@Override
public void onStallWarning(StallWarning warning) {
// System.out.println("Got stall warning:" + warning);
}
@Override
public void onException(Exception ex) {
ex.printStackTrace();
}
};
twitterStream.addListener(listener);
FilterQuery query = new FilterQuery().track(keyWords);
twitterStream.filter(query);
Thread.sleep(5000);
//Add Kafka producer config settings
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
int i = 0;
int j = 0;
while(i < 10) {
Status ret = queue.poll();
if (ret == null) {
Thread.sleep(100);
i++;
}else {
for(HashtagEntity hashtage : ret.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
producer.send(new ProducerRecord<String, String>(
top-icName, Integer.toString(j++), hashtage.getText()));
}
}
}
producer.close();
Thread.sleep(5000);
twitterStream.shutdown();
}
}
編譯
使用以下命令編譯應用程式:
javac -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”:. KafkaTwitterProducer.java
執行
開啟兩個控制檯。在一個控制檯中,執行上面編譯的應用程式,如下所示。
java -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”: . KafkaTwitterProducer <twitter-consumer-key> <twitter-consumer-secret> <twitter-access-token> <twitter-ac-cess-token-secret> my-first-topic food
在另一個視窗中執行上一章中解釋的任何一個 Spark/Storm 應用程式。需要注意的主要一點是,在這兩種情況下使用的主題應該相同。在這裡,我們使用“my-first-topic”作為主題名稱。
輸出
此應用程式的輸出將取決於關鍵字和 Twitter 的當前饋送。下面是一個示例輸出(Storm 整合)。
. . . food : 1 foodie : 2 burger : 1 . . .
Apache Kafka - 工具
打包在“org.apache.kafka.tools.*”下的 Kafka 工具。工具分為系統工具和複製工具。
系統工具
可以使用 run class 指令碼從命令列執行系統工具。語法如下:
bin/kafka-run-class.sh package.class - - options
下面提到一些系統工具:
Kafka 遷移工具 − 此工具用於將代理從一個版本遷移到另一個版本。
映象製作器 (Mirror Maker) − 此工具用於將一個 Kafka 叢集映象到另一個叢集。
消費者偏移量檢查器 (Consumer Offset Checker) − 此工具顯示指定主題和消費者組的消費者組、主題、分割槽、偏移量、日誌大小和所有者。
複製工具
Kafka 複製是一個高階設計工具。新增複製工具的目的是為了更強的永續性和更高的可用性。下面提到一些複製工具:
建立主題工具 (Create Topic Tool) − 這將建立一個具有預設分割槽數、複製因子並使用 Kafka 的預設方案進行副本分配的主題。
列出主題工具 (List Topic Tool) − 此工具列出給定主題列表的資訊。如果命令列中未提供任何主題,則該工具將查詢 ZooKeeper 以獲取所有主題並列出它們的資訊。該工具顯示的欄位是主題名稱、分割槽、領導者、副本和 ISR。
新增分割槽工具 (Add Partition Tool) − 建立主題時,必須指定主題的分割槽數。之後,當主題的容量增加時,可能需要為主題新增更多分割槽。此工具有助於為特定主題新增更多分割槽,並允許手動分配新增的分割槽的副本。
Apache Kafka - 應用
Kafka 支援當今許多最佳的工業應用。本章將簡要概述 Kafka 在一些最值得注意的應用中的應用。
Twitter 是一種線上社交網路服務,提供了一個傳送和接收使用者推文的平臺。註冊使用者可以閱讀和釋出推文,但未註冊使用者只能閱讀推文。Twitter 使用 Storm-Kafka 作為其流處理基礎架構的一部分。
LinkedIn 使用 Apache Kafka 來處理活動流資料和運營指標。Kafka 訊息系統幫助 LinkedIn 提供各種產品,例如 LinkedIn 資訊流、LinkedIn 今日新聞(用於線上訊息消費)以及離線分析系統(例如 Hadoop)。Kafka 的強大永續性也是與 LinkedIn 連線的關鍵因素之一。
Netflix
Netflix 是一家美國跨國公司,提供按需網際網路流媒體服務。Netflix 使用 Kafka 進行即時監控和事件處理。
Mozilla
Mozilla 是一個自由軟體社群,由 Netscape 成員於 1998 年建立。Kafka 將很快取代 Mozilla 當前生產系統的一部分,用於從終端使用者的瀏覽器收集效能和使用資料,用於遙測、測試飛行員等專案。
Oracle
Oracle 從其名為 OSB(Oracle Service Bus)的企業服務匯流排產品中提供對 Kafka 的原生連線,這允許開發人員利用 OSB 內建的調解功能來實現分階段資料管道。