- Apache Flume 教程
- Apache Flume - 首頁
- Apache Flume - 簡介
- Hadoop 中的資料傳輸
- Apache Flume - 架構
- Apache Flume - 資料流
- Apache Flume - 環境
- Apache Flume - 配置
- Apache Flume - 獲取 Twitter 資料
- 序列生成器源
- Apache Flume - NetCat 源
- Apache Flume 資源
- Apache Flume 快速指南
- Apache Flume - 有用資源
- Apache Flume - 討論
Apache Flume 快速指南
Apache Flume - 簡介
什麼是 Flume?
Apache Flume 是一種用於收集、聚合和傳輸大量流式資料的工具/服務/資料攝取機制,例如日誌檔案、事件(等等)從各種來源到一個集中的資料儲存。
Flume 是一種高度可靠、分散式且可配置的工具。它主要設計用於將流式資料(日誌資料)從各種 Web 伺服器複製到 HDFS。
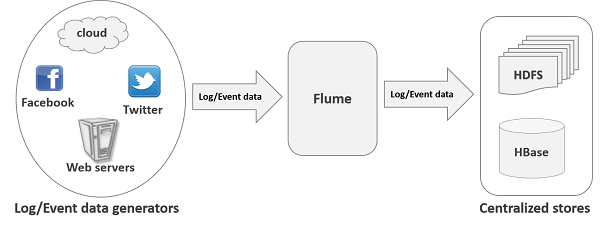
Flume 的應用
假設一個電子商務 Web 應用程式想要分析某個特定區域的客戶行為。為此,他們需要將可用的日誌資料移動到 Hadoop 中進行分析。在這裡,Apache Flume 就派上用場了。
Flume 用於以更高的速度將應用程式伺服器生成的日誌資料移動到 HDFS 中。
Flume 的優勢
以下是使用 Flume 的優勢:
使用 Apache Flume,我們可以將資料儲存到任何集中的儲存中(HBase、HDFS)。
當傳入資料的速率超過寫入目標資料的速率時,Flume 充當資料生產者和集中式儲存之間的中介,並在它們之間提供穩定的資料流。
Flume 提供了**上下文路由**的功能。
Flume 中的事務是基於通道的,其中為每條訊息維護兩個事務(一個傳送者和一個接收者)。它保證可靠的訊息傳遞。
Flume 可靠、容錯、可擴充套件、可管理且可定製。
Flume 的特性
Flume 的一些顯著特性如下:
Flume 有效地將來自多個 Web 伺服器的日誌資料攝取到集中式儲存(HDFS、HBase)中。
使用 Flume,我們可以立即將來自多個伺服器的資料獲取到 Hadoop 中。
除了日誌檔案外,Flume 還用於匯入社交網路網站(如 Facebook 和 Twitter)以及電子商務網站(如 Amazon 和 Flipkart)生成的巨量事件資料。
Flume 支援大量源和目標型別。
Flume 支援多跳流、扇入扇出流、上下文路由等。
Flume 可以水平擴充套件。
Apache Flume - Hadoop 中的資料傳輸
眾所周知,**大資料**是指無法使用傳統計算技術處理的大型資料集的集合。分析大資料可以得出有價值的結果。**Hadoop** 是一個開源框架,它允許使用簡單的程式設計模型在計算機叢集的分散式環境中儲存和處理大資料。
流式/日誌資料
通常,大部分要分析的資料將由各種資料來源生成,例如應用程式伺服器、社交網路站點、雲伺服器和企業伺服器。這些資料將以**日誌檔案**和**事件**的形式存在。
**日誌檔案** - 通常,日誌檔案是一個列出作業系統中發生的事件/操作的檔案。例如,Web 伺服器在日誌檔案中列出對伺服器發出的每個請求。
在收集此類日誌資料後,我們可以獲取有關以下方面的資訊:
- 應用程式效能並定位各種軟體和硬體故障。
- 使用者行為並獲得更好的業務洞察。
將資料傳輸到 HDFS 系統的傳統方法是使用**put**命令。讓我們看看如何使用**put**命令。
HDFS put 命令
處理日誌資料的主要挑戰在於將這些由多個伺服器生成的日誌移動到 Hadoop 環境中。
Hadoop**檔案系統 Shell**提供命令將資料插入 Hadoop 並從中讀取。您可以使用如下所示的**put**命令將資料插入 Hadoop。
$ Hadoop fs –put /path of the required file /path in HDFS where to save the file
put 命令的問題
我們可以使用 Hadoop 的**put**命令將資料從這些源傳輸到 HDFS。但是,它存在以下缺點:
使用**put**命令,我們**一次只能傳輸一個檔案**,而資料生成器生成資料的速度要快得多。由於對舊資料的分析準確性較低,因此我們需要找到一種解決方案來即時傳輸資料。
如果我們使用**put**命令,則需要打包資料並準備好上傳。由於 Web 伺服器持續生成資料,因此這是一項非常困難的任務。
我們需要的是一種解決方案,它可以克服**put**命令的缺點,並將“流式資料”從資料生成器傳輸到集中式儲存(尤其是 HDFS)中,延遲更小。
HDFS 的問題
在 HDFS 中,檔案以目錄條目形式存在,並且在關閉檔案之前,檔案的長度將被視為零。例如,如果源正在將資料寫入 HDFS 並且操作過程中網路中斷(在未關閉檔案的情況下),則寫入檔案中的資料將丟失。
因此,我們需要一個可靠、可配置且可維護的系統來將日誌資料傳輸到 HDFS 中。
**注意** - 在 POSIX 檔案系統中,每當我們訪問檔案(例如執行寫操作)時,其他程式仍然可以讀取此檔案(至少可以讀取檔案的已儲存部分)。這是因為檔案在關閉之前就存在於磁碟上。
可用的解決方案
為了將流式資料(日誌檔案、事件等)從各種來源傳送到 HDFS,我們可以使用以下工具:
Facebook 的 Scribe
Scribe 是一款非常流行的工具,用於聚合和流式傳輸日誌資料。它旨在擴充套件到大量節點,並對網路和節點故障具有魯棒性。
Apache Kafka
Kafka 由 Apache 軟體基金會開發。它是一個開源訊息代理。使用 Kafka,我們可以處理高吞吐量和低延遲的饋送。
Apache Flume
Apache Flume 是一種用於收集、聚合和傳輸大量流式資料的工具/服務/資料攝取機制,例如日誌資料、事件(等等)從各種 Web 伺服器到一個集中的資料儲存。
它是一個高度可靠、分散式且可配置的工具,主要設計用於將流式資料從各種來源傳輸到 HDFS。
在本教程中,我們將詳細討論如何使用 Flume 以及一些示例。
Apache Flume - 架構
下圖描述了 Flume 的基本架構。如圖所示,**資料生成器**(例如 Facebook、Twitter)生成資料,這些資料由在其上執行的各個 Flume**代理**收集。此後,**資料收集器**(它也是一個代理)從代理收集資料,這些資料會被聚合並推送到集中式儲存(例如 HDFS 或 HBase)中。

Flume 事件
**事件**是**Flume**內部傳輸的資料的基本單位。它包含一個要從源傳輸到目標的位元組陣列有效負載,並附帶可選的標頭。典型的 Flume 事件將具有以下結構:

Flume 代理
**代理**是 Flume 中一個獨立的守護程序(JVM)。它接收來自客戶端或其他代理的資料(事件),並將其轉發到其下一個目標(接收器或代理)。Flume 可能有多個代理。下圖表示一個**Flume 代理**

如圖所示,Flume 代理包含三個主要元件,即**源**、**通道**和**接收器**。
源
**源**是代理的一個元件,它接收來自資料生成器的資料,並以 Flume 事件的形式將其傳輸到一個或多個通道。
Apache Flume 支援多種型別的源,每個源都接收來自指定資料生成器的事件。
**示例** - Avro 源、Thrift 源、Twitter 1% 源等。
通道
**通道**是一個瞬態儲存,它接收來自源的事件,並在接收器使用它們之前緩衝它們。它充當源和接收器之間的橋樑。
這些通道是完全事務性的,它們可以與任意數量的源和接收器一起工作。
**示例** - JDBC 通道、檔案系統通道、記憶體通道等。
接收器
**接收器**將資料儲存到集中式儲存(如 HBase 和 HDFS)中。它使用通道中的資料(事件),並將其傳遞到目標。接收器的目標可能是另一個代理或中央儲存。
**示例** - HDFS 接收器
**注意** - Flume 代理可以有多個源、接收器和通道。我們在本教程的 Flume 配置章節中列出了所有支援的源、接收器和通道。
Flume 代理的其他元件
我們上面討論的是代理的基本元件。除此之外,我們還有幾個元件在將事件從資料生成器傳輸到集中式儲存中發揮著至關重要的作用。
攔截器
攔截器用於更改/檢查在源和通道之間傳輸的 Flume 事件。
通道選擇器
這些用於確定在有多個通道的情況下選擇哪個通道來傳輸資料。通道選擇器有兩種型別:
**預設通道選擇器** - 這些也稱為複製通道選擇器,它們會複製每個通道中的所有事件。
**多路複用通道選擇器** - 這些根據該事件標頭中的地址決定要傳送事件的通道。
接收器處理器
這些用於從選定的接收器組中呼叫特定接收器。這些用於為接收器建立故障轉移路徑或跨多個接收器從通道中負載均衡事件。
Apache Flume - 資料流
Flume是一個用於將日誌資料移動到HDFS的框架。通常,日誌事件和日誌資料由日誌伺服器生成,這些伺服器上執行著Flume代理。這些代理從資料生成器接收資料。
這些代理中的資料將由一個稱為**收集器**(Collector)的中間節點收集。與代理類似,Flume中可以有多個收集器。
最後,來自所有這些收集器的資料將被聚合並推送到一個集中式儲存中,例如HBase或HDFS。下圖解釋了Flume中的資料流。

多跳流
在Flume中,可以有多個代理,並且在到達最終目的地之前,事件可能會經過多個代理。這被稱為**多跳流**(multi-hop flow)。
扇出流
從一個源到多個通道的資料流稱為**扇出流**(fan-out flow)。它分為兩種型別:
**複製**(Replicating) - 資料流將資料複製到所有配置的通道中。
**多路複用**(Multiplexing) - 資料流將資料傳送到事件頭中指定的選定通道。
扇入流
資料流從多個源傳輸到一個通道稱為**扇入流**(fan-in flow)。
故障處理
在Flume中,對於每個事件,都會發生兩個事務:一個在傳送方,一個在接收方。傳送方將事件傳送到接收方。接收方在收到資料後立即提交其自身的事務,並向傳送方傳送“已收到”訊號。傳送方在收到訊號後提交其事務。(傳送方在收到接收方的訊號之前不會提交其事務。)
Apache Flume - 環境
我們在上一章中已經討論了Flume的架構。在本章中,讓我們看看如何下載和設定Apache Flume。
在繼續操作之前,您需要在系統中擁有Java環境。因此,首先,請確保您的系統中已安裝Java。在本教程中的一些示例中,我們使用了Hadoop HDFS(作為接收器)。因此,我們建議您安裝Hadoop以及Java。要收集更多資訊,請訪問以下連結:https://tutorialspoint.tw/hadoop/hadoop_enviornment_setup.htm
安裝Flume
首先,從網站 https://flume.apache.org/下載最新版本的Apache Flume軟體。
步驟1
開啟網站。點選主頁左側的**下載**連結。它將帶您到Apache Flume的下載頁面。
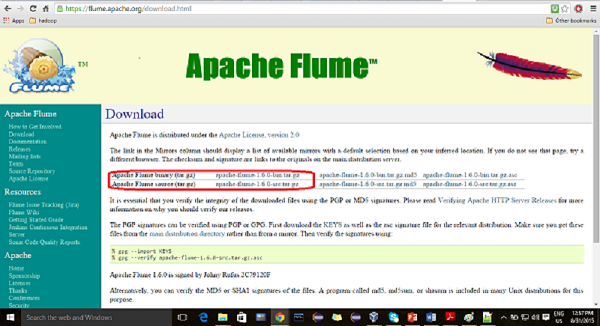
步驟2
在下載頁面中,您可以看到Apache Flume的二進位制檔案和原始檔的連結。點選連結apache-flume-1.6.0-bin.tar.gz
您將被重定向到一個映象列表,您可以在其中點選任意一個映象開始下載。同樣,您可以透過點選apache-flume-1.6.0-src.tar.gz下載Apache Flume的原始碼。
步驟3
在與Hadoop、HBase和其他軟體的安裝目錄相同的目錄中建立一個名為Flume的目錄(如果您已安裝任何軟體),如下所示。
$ mkdir Flume
步驟4
解壓縮下載的tar檔案,如下所示。
$ cd Downloads/ $ tar zxvf apache-flume-1.6.0-bin.tar.gz $ tar zxvf apache-flume-1.6.0-src.tar.gz
步驟5
將apache-flume-1.6.0-bin.tar檔案的內容移動到之前建立的Flume目錄中,如下所示。(假設我們在名為Hadoop的本地使用者中建立了Flume目錄。)
$ mv apache-flume-1.6.0-bin.tar/* /home/Hadoop/Flume/
配置Flume
要配置Flume,我們必須修改三個檔案,即flume-env.sh、flumeconf.properties和bash.rc。
設定路徑/類路徑
在.bashrc檔案中,設定Flume的主資料夾、路徑和類路徑,如下所示。
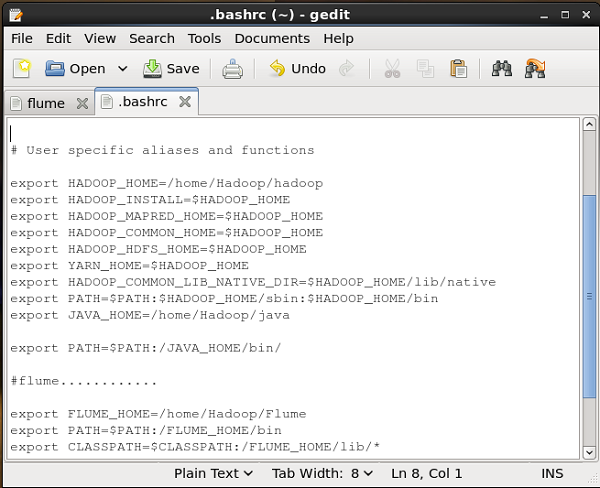
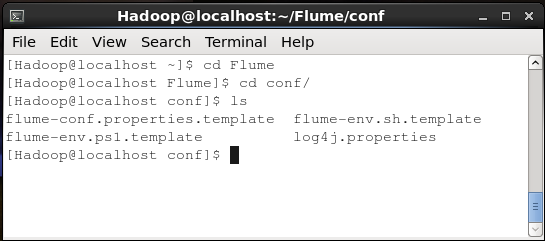
conf資料夾
如果您開啟Apache Flume的conf資料夾,您將看到以下四個檔案:
- flume-conf.properties.template,
- flume-env.sh.template,
- flume-env.ps1.template, 和
- log4j.properties.
現在重新命名
flume-conf.properties.template檔案為flume-conf.properties,以及
flume-env.sh.template為flume-env.sh
flume-env.sh
開啟flume-env.sh檔案並將JAVA_Home設定為Java在系統中安裝的資料夾。
驗證安裝
透過瀏覽bin資料夾並鍵入以下命令來驗證Apache Flume的安裝。
$ ./flume-ng
如果成功安裝了Flume,您將獲得Flume的幫助提示,如下所示。
Apache Flume - 配置
安裝Flume後,我們需要使用配置檔案對其進行配置,該配置檔案是一個包含**鍵值對**的Java屬性檔案。我們需要將值傳遞給檔案中的鍵。
在Flume配置檔案中,我們需要:
- 命名當前代理的元件。
- 描述/配置源。
- 描述/配置接收器。
- 描述/配置通道。
- 將源和接收器繫結到通道。
通常,我們可以在Flume中有多個代理。我們可以使用唯一的名稱來區分每個代理。並使用此名稱,我們必須配置每個代理。
命名元件
首先,您需要命名/列出代理的元件,例如源、接收器和通道,如下所示。
agent_name.sources = source_name agent_name.sinks = sink_name agent_name.channels = channel_name
Flume支援各種源、接收器和通道。它們列在下表中。
| 源 | 通道 | 接收器 |
|---|---|---|
|
|
|
您可以使用其中任何一個。例如,如果您使用Twitter源透過記憶體通道將Twitter資料傳輸到HDFS接收器,並且代理名稱為TwitterAgent,則
TwitterAgent.sources = Twitter TwitterAgent.channels = MemChannel TwitterAgent.sinks = HDFS
列出代理的元件後,您必須透過為其屬性提供值來描述源、接收器和通道。
描述源
每個源將具有單獨的屬性列表。名為“type”的屬性對每個源都是通用的,它用於指定我們正在使用的源的型別。
除了屬性“type”之外,還需要提供特定源所有**必需**屬性的值來對其進行配置,如下所示。
agent_name.sources. source_name.type = value agent_name.sources. source_name.property2 = value agent_name.sources. source_name.property3 = value
例如,如果我們考慮twitter源,以下是我們必須提供值才能對其進行配置的屬性。
TwitterAgent.sources.Twitter.type = Twitter (type name) TwitterAgent.sources.Twitter.consumerKey = TwitterAgent.sources.Twitter.consumerSecret = TwitterAgent.sources.Twitter.accessToken = TwitterAgent.sources.Twitter.accessTokenSecret =
描述接收器
與源一樣,每個接收器將具有單獨的屬性列表。名為“type”的屬性對每個接收器都是通用的,它用於指定我們正在使用的接收器的型別。除了屬性“type”之外,還需要提供特定接收器所有**必需**屬性的值來對其進行配置,如下所示。
agent_name.sinks. sink_name.type = value agent_name.sinks. sink_name.property2 = value agent_name.sinks. sink_name.property3 = value
例如,如果我們考慮HDFS接收器,以下是我們必須提供值才能對其進行配置的屬性。
TwitterAgent.sinks.HDFS.type = hdfs (type name) TwitterAgent.sinks.HDFS.hdfs.path = HDFS directory’s Path to store the data
描述通道
Flume提供各種通道來在源和接收器之間傳輸資料。因此,除了源和通道之外,還需要描述代理中使用的通道。
要描述每個通道,您需要設定所需的屬性,如下所示。
agent_name.channels.channel_name.type = value agent_name.channels.channel_name. property2 = value agent_name.channels.channel_name. property3 = value
例如,如果我們考慮記憶體通道,以下是我們必須提供值才能對其進行配置的屬性。
TwitterAgent.channels.MemChannel.type = memory (type name)
將源和接收器繫結到通道
由於通道連線源和接收器,因此需要將兩者都繫結到通道,如下所示。
agent_name.sources.source_name.channels = channel_name agent_name.sinks.sink_name.channels = channel_name
以下示例顯示瞭如何將源和接收器繫結到通道。這裡,我們考慮twitter源、記憶體通道和HDFS接收器。
TwitterAgent.sources.Twitter.channels = MemChannel TwitterAgent.sinks.HDFS.channels = MemChannel
啟動Flume代理
配置完成後,我們必須啟動Flume代理。操作如下:
$ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf Dflume.root.logger=DEBUG,console -n TwitterAgent
其中:
agent - 啟動Flume代理的命令
--conf ,-c<conf> - 使用conf目錄中的配置檔案
-f<file> - 指定配置檔案路徑,如果缺少
--name, -n <name> - twitter代理的名稱
-D property =value - 設定Java系統屬性值。
Apache Flume - 獲取 Twitter 資料
使用Flume,我們可以從各種服務中獲取資料並將其傳輸到集中式儲存(HDFS和HBase)。本章說明如何使用Apache Flume從Twitter服務獲取資料並將其儲存在HDFS中。
如Flume架構中所述,Web伺服器生成日誌資料,並且Flume中的代理收集此資料。通道將此資料緩衝到接收器,接收器最終將其推送到集中式儲存。
在本例中提供的示例中,我們將建立一個應用程式並使用Apache Flume提供的實驗性Twitter源獲取其中的推文。我們將使用記憶體通道緩衝這些推文,並使用HDFS接收器將這些推文推送到HDFS中。

要獲取Twitter資料,我們將必須按照以下步驟操作:
- 建立Twitter應用程式
- 安裝/啟動HDFS
- 配置Flume
建立Twitter應用程式
為了從Twitter獲取推文,需要建立一個Twitter應用程式。按照以下步驟建立Twitter應用程式。
步驟1
要建立一個 Twitter 應用程式,請點選以下連結 https://apps.twitter.com/。登入您的 Twitter 賬戶。您將看到一個 Twitter 應用程式管理視窗,您可以在其中建立、刪除和管理 Twitter 應用程式。

步驟2
點選建立新的應用按鈕。您將被重定向到一個視窗,其中包含一個應用程式表單,您需要填寫您的詳細資訊以建立應用程式。填寫網站地址時,請提供完整的 URL 模式,例如,http://example.com。

步驟3
填寫詳細資訊,完成後接受開發者協議,點選頁面底部的建立您的 Twitter 應用程式按鈕。如果一切順利,將根據提供的詳細資訊建立一個應用程式,如下所示。

步驟4
在頁面底部的金鑰和訪問令牌選項卡下,您可以看到一個名為建立我的訪問令牌的按鈕。點選它以生成訪問令牌。

步驟5
最後,點選頁面右上角的測試 OAuth按鈕。這將導致跳轉到一個頁面,該頁面顯示您的消費者金鑰、消費者金鑰秘密、訪問令牌和訪問令牌金鑰。複製這些詳細資訊。這些資訊用於在 Flume 中配置代理。

啟動 HDFS
由於我們將資料儲存在 HDFS 中,因此我們需要安裝/驗證 Hadoop。啟動 Hadoop 並在其中建立一個資料夾來儲存 Flume 資料。在配置 Flume 之前,請按照以下步驟操作。
步驟 1:安裝/驗證 Hadoop
安裝 Hadoop。如果您的系統中已經安裝了 Hadoop,請使用 Hadoop 版本命令驗證安裝,如下所示。
$ hadoop version
如果您的系統包含 Hadoop,並且您已設定路徑變數,則您將獲得以下輸出:
Hadoop 2.6.0 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1 Compiled by jenkins on 2014-11-13T21:10Z Compiled with protoc 2.5.0 From source with checksum 18e43357c8f927c0695f1e9522859d6a This command was run using /home/Hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jar
步驟 2:啟動 Hadoop
瀏覽 Hadoop 的sbin目錄並啟動 yarn 和 Hadoop dfs(分散式檔案系統),如下所示。
cd /$Hadoop_Home/sbin/ $ start-dfs.sh localhost: starting namenode, logging to /home/Hadoop/hadoop/logs/hadoop-Hadoop-namenode-localhost.localdomain.out localhost: starting datanode, logging to /home/Hadoop/hadoop/logs/hadoop-Hadoop-datanode-localhost.localdomain.out Starting secondary namenodes [0.0.0.0] starting secondarynamenode, logging to /home/Hadoop/hadoop/logs/hadoop-Hadoop-secondarynamenode-localhost.localdomain.out $ start-yarn.sh starting yarn daemons starting resourcemanager, logging to /home/Hadoop/hadoop/logs/yarn-Hadoop-resourcemanager-localhost.localdomain.out localhost: starting nodemanager, logging to /home/Hadoop/hadoop/logs/yarn-Hadoop-nodemanager-localhost.localdomain.out
步驟 3:在 HDFS 中建立目錄
在 Hadoop DFS 中,您可以使用mkdir命令建立目錄。瀏覽它並在所需的路徑中建立一個名為twitter_data的目錄,如下所示。
$cd /$Hadoop_Home/bin/ $ hdfs dfs -mkdir hdfs://:9000/user/Hadoop/twitter_data
配置Flume
我們必須使用conf資料夾中的配置檔案配置源、通道和接收器。本章提供的示例使用 Apache Flume 提供的一個實驗性源,名為Twitter 1% Firehose記憶體通道和 HDFS 接收器。
Twitter 1% Firehose 源
此源處於高度實驗階段。它使用流式 API 連線到 Twitter 1% 樣本 Firehose,並持續下載推文,將其轉換為 Avro 格式,並將 Avro 事件傳送到下游 Flume 接收器。
安裝 Flume 後,我們將預設獲得此源。與該源對應的jar檔案位於lib資料夾中,如下所示。

設定類路徑
將classpath變數設定為Flume-env.sh檔案中的 Flume 的lib資料夾,如下所示。
export CLASSPATH=$CLASSPATH:/FLUME_HOME/lib/*
此源需要 Twitter 應用程式的詳細資訊,例如消費者金鑰、消費者金鑰秘密、訪問令牌和訪問令牌金鑰。配置此源時,您必須為以下屬性提供值:
通道
源型別:org.apache.flume.source.twitter.TwitterSource
consumerKey - OAuth 消費者金鑰
consumerSecret - OAuth 消費者金鑰秘密
accessToken - OAuth 訪問令牌
accessTokenSecret - OAuth 令牌金鑰
maxBatchSize - Twitter 批處理中應包含的最大 Twitter 訊息數。預設值為 1000(可選)。
maxBatchDurationMillis - 關閉批處理之前要等待的最大毫秒數。預設值為 1000(可選)。
通道
我們正在使用記憶體通道。要配置記憶體通道,您必須為通道的型別提供值。
type - 它儲存通道的型別。在我們的示例中,型別為MemChannel。
Capacity - 它是通道中儲存的事件的最大數量。其預設值為 100(可選)。
TransactionCapacity - 它是通道接受或傳送的事件的最大數量。其預設值為 100(可選)。
HDFS接收器
此接收器將資料寫入 HDFS。要配置此接收器,您必須提供以下詳細資訊。
通道
type - hdfs
hdfs.path - HDFS 中要儲存資料的目錄的路徑。
並且我們可以根據場景提供一些可選值。以下是我們在應用程式中配置的 HDFS 接收器的可選屬性。
fileType - 這是我們 HDFS 檔案所需的格式。SequenceFile、DataStream和CompressedStream是此流可用的三種類型。在我們的示例中,我們使用DataStream。
writeFormat - 可以是文字或可寫。
batchSize - 它是寫入檔案中的事件數,然後將其重新整理到 HDFS 中。其預設值為 100。
rollsize - 它是觸發滾動操作的檔案大小。其預設值為 100。
rollCount - 它是寫入檔案中的事件數,然後將其滾動。其預設值為 10。
示例 - 配置檔案
以下是配置檔案的一個示例。複製此內容並將其儲存為 Flume 的 conf 資料夾中的twitter.conf。
# Naming the components on the current agent. TwitterAgent.sources = Twitter TwitterAgent.channels = MemChannel TwitterAgent.sinks = HDFS # Describing/Configuring the source TwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource TwitterAgent.sources.Twitter.consumerKey = Your OAuth consumer key TwitterAgent.sources.Twitter.consumerSecret = Your OAuth consumer secret TwitterAgent.sources.Twitter.accessToken = Your OAuth consumer key access token TwitterAgent.sources.Twitter.accessTokenSecret = Your OAuth consumer key access token secret TwitterAgent.sources.Twitter.keywords = tutorials point,java, bigdata, mapreduce, mahout, hbase, nosql # Describing/Configuring the sink TwitterAgent.sinks.HDFS.type = hdfs TwitterAgent.sinks.HDFS.hdfs.path = hdfs://:9000/user/Hadoop/twitter_data/ TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000 TwitterAgent.sinks.HDFS.hdfs.rollSize = 0 TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000 # Describing/Configuring the channel TwitterAgent.channels.MemChannel.type = memory TwitterAgent.channels.MemChannel.capacity = 10000 TwitterAgent.channels.MemChannel.transactionCapacity = 100 # Binding the source and sink to the channel TwitterAgent.sources.Twitter.channels = MemChannel TwitterAgent.sinks.HDFS.channel = MemChannel
執行
瀏覽 Flume 主目錄並執行應用程式,如下所示。
$ cd $FLUME_HOME $ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf Dflume.root.logger=DEBUG,console -n TwitterAgent
如果一切順利,推文流式傳輸到 HDFS 將開始。以下是在獲取推文時命令提示符視窗的快照。

驗證 HDFS
您可以使用以下 URL 訪問 Hadoop 管理 Web UI。
https://:50070/
點選頁面右側名為實用程式的下拉選單。您可以看到兩個選項,如下面的快照所示。

點選瀏覽檔案系統並輸入您儲存推文的 HDFS 目錄的路徑。在我們的示例中,路徑將為/user/Hadoop/twitter_data/。然後,您可以看到儲存在 HDFS 中的 Twitter 日誌檔案列表,如下所示。

Apache Flume - 序列生成器源
在上一章中,我們已經瞭解瞭如何將資料從 Twitter 源獲取到 HDFS。本章介紹如何從序列生成器獲取資料。
先決條件
要執行本章提供的示例,您需要安裝HDFS以及Flume。因此,在繼續之前,請驗證 Hadoop 安裝並啟動 HDFS。(請參閱上一章以瞭解如何啟動 HDFS)。
配置Flume
我們必須使用conf資料夾中的配置檔案配置源、通道和接收器。本章提供的示例使用序列生成器源、記憶體通道和HDFS 接收器。
序列生成器源
它是持續生成事件的源。它維護一個從 0 開始並遞增 1 的計數器。它用於測試目的。配置此源時,您必須為以下屬性提供值:
通道
源型別 - seq
通道
我們正在使用記憶體通道。要配置記憶體通道,您必須為通道的型別提供值。以下是配置記憶體通道時需要提供的屬性列表:
type - 它儲存通道的型別。在我們的示例中,型別為 MemChannel。
Capacity - 它是通道中儲存的事件的最大數量。其預設值為 100。(可選)
TransactionCapacity - 它是通道接受或傳送的事件的最大數量。其預設值為 100。(可選)
HDFS接收器
此接收器將資料寫入 HDFS。要配置此接收器,您必須提供以下詳細資訊。
通道
type - hdfs
hdfs.path - HDFS 中要儲存資料的目錄的路徑。
並且我們可以根據場景提供一些可選值。以下是我們在應用程式中配置的 HDFS 接收器的可選屬性。
fileType - 這是我們 HDFS 檔案所需的格式。SequenceFile、DataStream和CompressedStream是此流可用的三種類型。在我們的示例中,我們使用DataStream。
writeFormat - 可以是文字或可寫。
batchSize - 它是寫入檔案中的事件數,然後將其重新整理到 HDFS 中。其預設值為 100。
rollsize - 它是觸發滾動操作的檔案大小。其預設值為 100。
rollCount - 它是寫入檔案中的事件數,然後將其滾動。其預設值為 10。
示例 - 配置檔案
以下是配置檔案的一個示例。複製此內容並將其儲存為 Flume 的 conf 資料夾中的seq_gen .conf。
# Naming the components on the current agent SeqGenAgent.sources = SeqSource SeqGenAgent.channels = MemChannel SeqGenAgent.sinks = HDFS # Describing/Configuring the source SeqGenAgent.sources.SeqSource.type = seq # Describing/Configuring the sink SeqGenAgent.sinks.HDFS.type = hdfs SeqGenAgent.sinks.HDFS.hdfs.path = hdfs://:9000/user/Hadoop/seqgen_data/ SeqGenAgent.sinks.HDFS.hdfs.filePrefix = log SeqGenAgent.sinks.HDFS.hdfs.rollInterval = 0 SeqGenAgent.sinks.HDFS.hdfs.rollCount = 10000 SeqGenAgent.sinks.HDFS.hdfs.fileType = DataStream # Describing/Configuring the channel SeqGenAgent.channels.MemChannel.type = memory SeqGenAgent.channels.MemChannel.capacity = 1000 SeqGenAgent.channels.MemChannel.transactionCapacity = 100 # Binding the source and sink to the channel SeqGenAgent.sources.SeqSource.channels = MemChannel SeqGenAgent.sinks.HDFS.channel = MemChannel
執行
瀏覽 Flume 主目錄並執行應用程式,如下所示。
$ cd $FLUME_HOME $./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/seq_gen.conf --name SeqGenAgent
如果一切順利,源將開始生成序列號,這些序列號將以日誌檔案形式推送到 HDFS 中。
以下是命令提示符視窗的快照,該視窗將序列生成器生成的資料獲取到 HDFS 中。

驗證 HDFS
您可以使用以下 URL 訪問 Hadoop 管理 Web UI:
https://:50070/
點選頁面右側名為實用程式的下拉選單。您可以看到兩個選項,如下面的圖表所示。
點選瀏覽檔案系統並輸入您儲存序列生成器生成資料的 HDFS 目錄的路徑。
在我們的示例中,路徑將為/user/Hadoop/ seqgen_data /。然後,您可以看到序列生成器生成的日誌檔案列表,儲存在 HDFS 中,如下所示。
驗證檔案內容
所有這些日誌檔案都包含按順序排列的數字。您可以使用cat命令在檔案系統中驗證這些檔案的內容,如下所示。

Apache Flume - NetCat 源
本章以一個示例來說明如何生成事件並隨後將其記錄到控制檯。為此,我們使用NetCat源和logger接收器。
先決條件
要執行本章提供的示例,您需要安裝Flume。
配置Flume
我們必須使用conf資料夾中的配置檔案配置源、通道和接收器。本章提供的示例使用NetCat 源、記憶體通道和logger 接收器。
NetCat源
配置 NetCat 源時,我們必須在配置源時指定埠。現在源(NetCat 源)偵聽給定埠,並將我們在該埠中輸入的每一行作為單個事件接收,並透過指定的通道將其傳輸到接收器。
配置此源時,您必須為以下屬性提供值:
通道
源型別 - netcat
bind - 要繫結的主機名或 IP 地址。
port - 我們希望源偵聽的埠號。
通道
我們正在使用記憶體通道。要配置記憶體通道,您必須為通道的型別提供值。以下是配置記憶體通道時需要提供的屬性列表:
type - 它儲存通道的型別。在我們的示例中,型別為MemChannel。
Capacity - 它是通道中儲存的事件的最大數量。其預設值為 100。(可選)
TransactionCapacity − 它表示通道接受或傳送事件的最大數量。其預設值為 100。(可選)。
日誌接收器
此接收器會記錄傳遞給它的所有事件。通常,它用於測試或除錯目的。要配置此接收器,您必須提供以下詳細資訊。
通道
type − logger
示例配置檔案
下面給出一個配置檔案示例。複製此內容並將其另存為 Flume 的 conf 資料夾中的 netcat.conf。
# Naming the components on the current agent NetcatAgent.sources = Netcat NetcatAgent.channels = MemChannel NetcatAgent.sinks = LoggerSink # Describing/Configuring the source NetcatAgent.sources.Netcat.type = netcat NetcatAgent.sources.Netcat.bind = localhost NetcatAgent.sources.Netcat.port = 56565 # Describing/Configuring the sink NetcatAgent.sinks.LoggerSink.type = logger # Describing/Configuring the channel NetcatAgent.channels.MemChannel.type = memory NetcatAgent.channels.MemChannel.capacity = 1000 NetcatAgent.channels.MemChannel.transactionCapacity = 100 # Bind the source and sink to the channel NetcatAgent.sources.Netcat.channels = MemChannel NetcatAgent.sinks. LoggerSink.channel = MemChannel
執行
瀏覽 Flume 主目錄並執行應用程式,如下所示。
$ cd $FLUME_HOME $ ./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/netcat.conf --name NetcatAgent -Dflume.root.logger=INFO,console
如果一切正常,源將開始監聽給定的埠。在本例中,它是 56565。下面是已啟動並監聽埠 56565 的 NetCat 源的命令提示符視窗的快照。

將資料傳遞到源
要將資料傳遞到 NetCat 源,您必須開啟配置檔案中給出的埠。開啟一個單獨的終端並使用 curl 命令連線到源 (56565)。連線成功後,您將收到一條“connected”訊息,如下所示。
$ curl telnet://:56565 connected
現在您可以逐行輸入您的資料(每行之後,您必須按 Enter 鍵)。NetCat 源將每一行作為單個事件接收,您將收到一條“OK”的訊息。
完成資料傳遞後,您可以按 (Ctrl+C) 退出控制檯。下面是使用 curl 命令連線到源的控制檯快照。

在上述控制檯中輸入的每一行都將被源作為單個事件接收。由於我們使用了 Logger 接收器,因此這些事件將透過指定的通道(在本例中為記憶體通道)記錄到控制檯(源控制檯)。
以下快照顯示了記錄事件的 NetCat 控制檯。
