
 資料結構
資料結構 網路
網路 關係資料庫管理系統
關係資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPCNN影像分類入門指南(Python實現)
卷積神經網路(CNN)是一種專門設計用於處理具有網格拓撲結構的資料(例如影像)的神經網路。CNN由多個卷積層和池化層組成,這些層旨在從輸入資料中提取特徵,以及一個全連線層,用於對特徵進行分類。
CNN的主要優勢在於,它們能夠自動學習與手頭任務最相關的特徵,而不是依賴於手動特徵工程。這使得它們特別適合於影像分類任務,在這些任務中,用於分類的重要特徵可能事先未知。
在本文中,我們將詳細概述CNN,包括其架構和背後的關鍵概念。然後,我們將演示如何使用流行的Keras庫在Python中實現用於影像分類的CNN。
CNN架構
CNN由許多不同的層組成,每層執行特定的功能。CNN中最常見的層型別是卷積層、池化層和全連線層。
卷積層
卷積層是CNN的主要構建塊。它們將卷積運算應用於輸入資料,這涉及到在輸入資料上滑動一個小矩陣(稱為核或過濾器)並計算核中的條目與輸入資料之間的點積。這會產生一個新的、轉換後的特徵圖,該特徵圖捕獲輸入資料中條目之間的關係。
卷積層的引數包括核的大小、步長(即核每次移動的畫素數)和填充(即新增到輸入資料邊界處的畫素數,以確保核可以應用於輸入資料的每個部分)。
池化層
池化層用於透過對卷積層產生的特徵圖應用池化操作來對輸入資料進行下采樣。最常見的池化型別是最大池化和平均池化,它們分別獲取一組輸入的最大值和平均值。
池化層通常用於減少輸入資料的空間維度(即寬度和高度),這可以減少模型中的引數數量並提高其泛化效能。
全連線層
全連線層用於對卷積層和池化層提取的特徵進行分類。它們由多個神經元組成,每個神經元都連線到前一層中的每個神經元。全連線層的輸出是一組類別分數,可用於預測輸入資料的類別標籤。
卷積神經網路(CNN)的典型架構如下所示:
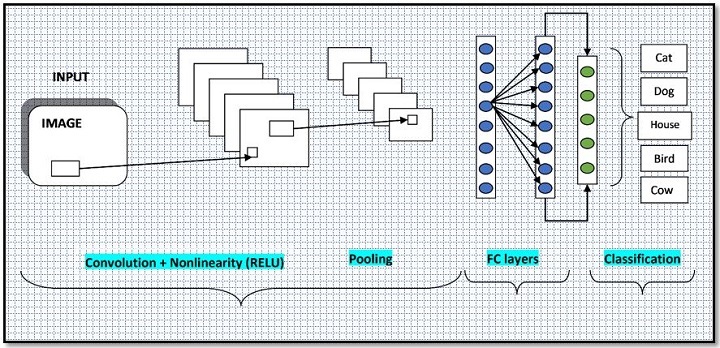
使用CNN進行影像分類
為了有效地使用CNN進行影像分類,有一些關鍵概念需要理解。
過濾器和核心
如上所述,卷積層將核心或過濾器應用於輸入資料以生成轉換後的特徵圖。核心的大小決定了在卷積運算的每個步驟中考慮的輸入資料區域的大小。例如,3x3核心在每個步驟中考慮輸入資料的3x3區域。
核心的權重在訓練過程中學習,並用於從輸入資料中提取特徵。不同的核心可用於提取不同型別的特徵,例如邊緣、角點或紋理。
步長
步長決定了核心應用於輸入資料的步長。較大的步長會導致較小的輸出特徵圖,因為核心應用於輸入資料中的較少位置。另一方面,較小的步長會導致較大的輸出特徵圖,因為核心應用於輸入資料中的更多位置。
填充
填充是在應用卷積運算之前新增到輸入資料邊界處的畫素數。填充通常用於確保輸出特徵圖與輸入資料具有相同的空間維度,這對於某些型別的下游處理非常有用。
池化
池化是對卷積層的輸出應用的下采樣操作。它減少了資料的空間維度,通常用於減少模型中的引數數量並提高其泛化效能。
在Python中實現用於影像分類的CNN
現在我們已經對CNN有了基本的瞭解,讓我們看看如何使用流行的Keras庫在Python中實現用於影像分類的CNN。
首先,我們需要安裝所需的庫。我們將使用以下庫:
NumPy - 用於處理陣列和矩陣的庫
Matplotlib - 用於建立繪圖和圖表
Keras - 用於構建和訓練神經網路的高階庫
您可以使用pip安裝這些庫:
pip install numpy matplotlib keras
接下來,我們需要匯入我們將要使用的庫:
import numpy as np import matplotlib.pyplot as plt from tensorflow import keras from tensorflow.keras.datasets import mnist from tensorflow.keras.utils import to_categorical from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
我們將在此示例中使用MNIST資料集,該資料集包含60,000個訓練影像和10,000個手寫數字的測試影像。這些影像為28×28畫素,每個畫素由0到255之間的灰度值表示。任務的目標是將影像分類為10個類別之一(即數字0-9)。
首先,我們需要載入資料集並預處理資料。我們可以使用以下程式碼:
# Load the dataset (X_train, y_train), (X_test, y_test) = mnist.load_data() # Pre-process the data X_train = X_train.astype(np.float32) / 255.0 X_test = X_test.astype(np.float32) / 255.0 # Reshape the data to add a channel dimension X_train = np.expand_dims(X_train, axis=-1) X_test = np.expand_dims(X_test, axis=-1) # One-hot encode the labels y_train = to_categorical(y_train, num_classes=10) y_test = to_categorical(y_test, num_classes=10)
接下來,我們需要定義模型。我們將使用Sequential模型,它允許我們將模型定義為一系列層。我們將首先新增一個具有32個大小為3x3的過濾器的卷積層,然後新增一個池大小為2×2的最大池化層。然後,我們將新增一個丟棄率為0.25的丟棄層,這將在訓練期間隨機丟棄25%的單元,以防止過擬合。
然後,我們將新增一個具有64個大小為3×3的過濾器的第二個卷積層,然後新增另一個池大小為2×2的最大池化層。我們還將新增一個丟棄率為0.25的丟棄層。
最後,我們將展平第二個池化層的輸出,並新增一個具有128個單元的全連線層,然後新增一個具有10個單元的輸出層(每個類別一個)。
我們可以使用以下程式碼定義模型:
# Define the model model = Sequential() model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(64, kernel_size=(3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dense(10, activation='softmax'))
接下來,我們需要透過指定要使用的損失函式、最佳化器和指標來編譯模型。對於此示例,我們將使用分類交叉熵損失、Adam最佳化器和準確率指標。
# Compile the model model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
最後,我們可以透過呼叫fit方法並指定訓練資料、時期數(即模型將看到資料的次數)和批大小(即每個梯度更新的樣本數)來訓練模型。
# Train the model history = model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))
執行以上程式碼片段後,輸出如下:
Epoch 1/10 1875/1875 [==============================] - 38s 20ms/step - loss: 0.1680 - accuracy: 0.9481 - val_loss: 0.0556 - val_accuracy: 0.9823 Epoch 2/10 1875/1875 [==============================] - 42s 22ms/step - loss: 0.0608 - accuracy: 0.9811 - val_loss: 0.0374 - val_accuracy: 0.9880 Epoch 3/10 1875/1875 [==============================] - 42s 22ms/step - loss: 0.0470 - accuracy: 0.9854 - val_loss: 0.0292 - val_accuracy: 0.9903 Epoch 4/10 1875/1875 [==============================] - 44s 24ms/step - loss: 0.0370 - accuracy: 0.9889 - val_loss: 0.0260 - val_accuracy: 0.9908 Epoch 5/10 1875/1875 [==============================] - 43s 23ms/step - loss: 0.0311 - accuracy: 0.9903 - val_loss: 0.0246 - val_accuracy: 0.9913 Epoch 6/10 1875/1875 [==============================] - 43s 23ms/step - loss: 0.0267 - accuracy: 0.9911 - val_loss: 0.0278 - val_accuracy: 0.9910 Epoch 7/10 1875/1875 [==============================] - 40s 21ms/step - loss: 0.0233 - accuracy: 0.9923 - val_loss: 0.0261 - val_accuracy: 0.9926 Epoch 8/10 1875/1875 [==============================] - 41s 22ms/step - loss: 0.0193 - accuracy: 0.9939 - val_loss: 0.0268 - val_accuracy: 0.9917 Epoch 9/10 1875/1875 [==============================] - 41s 22ms/step - loss: 0.0188 - accuracy: 0.9941 - val_loss: 0.0252 - val_accuracy: 0.9916 Epoch 10/10 1875/1875 [==============================] - 41s 22ms/step - loss: 0.0169 - accuracy: 0.9945 - val_loss: 0.0314 - val_accuracy: 0.9909
訓練完成後,我們可以透過呼叫evaluate方法在測試資料上評估模型:
# Evaluate the model
loss, accuracy = model.evaluate(X_test, y_test)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
執行以上程式碼片段後,輸出如下:
313/313 [==============================] - 1s 5ms/step - loss: 0.0314 - accuracy: 0.9909 Loss: 0.031392790377140045 Accuracy: 0.9908999800682068
我們還可以透過從history物件中提取準確率歷史記錄來繪製訓練和驗證準確率隨訓練過程的變化圖:
# Extract the accuracy history
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
# Plot the accuracy history
plt.plot(acc)
plt.plot(val_acc)
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
它將繪製訓練和驗證準確率如下所示:
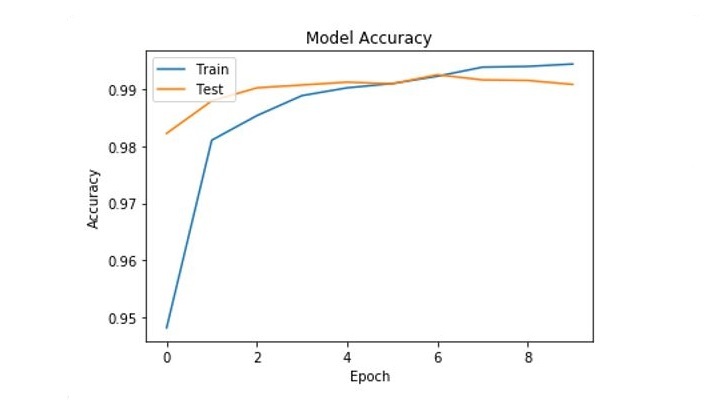
提高效能
為了進一步提高CNN的效能,您可以考慮以下提示:
微調架構 - 有許多不同的方法來設計CNN,最適合您的任務的架構將取決於資料的特定特徵。您可以嘗試使用不同的層數、核心大小、步長等,以檢視什麼最適合您的任務。
使用資料增強 - 資料增強是一種透過對現有資料應用轉換來生成額外訓練資料的技術。這對於提高泛化效能很有用,尤其是在訓練資料有限的情況下。
使用預訓練模型 - 預訓練模型是在大型資料集(如ImageNet)上訓練的CNN,可以作為您自己任務的起點。遷移學習,即在您自己的資料集上微調預訓練模型,是一種強大的技術,可以大大加快訓練速度並提高效能。
最佳化超引數 - CNN的效能還可以透過最佳化超引數來提高,例如學習率、批大小等。您可以使用網格搜尋或隨機搜尋等技術來找到最適合您任務的一組超引數。
透過遵循這些提示並將其應用於您自己的CNN,您應該能夠在各種影像分類任務中獲得良好的效能。
結論
本文詳細概述了卷積神經網路(CNN),並演示瞭如何使用Keras庫在Python中實現CNN進行影像分類。我們討論了CNN背後的關鍵概念,包括過濾器和核心、步長、填充和池化,並解釋瞭如何利用這些概念從輸入資料中提取特徵並對其進行分類。
我們還展示瞭如何微調CNN的架構和超引數,使用資料增強來提高泛化能力,以及使用預訓練模型來加快訓練速度和提高效能。
透過遵循本文中概述的技術,您應該能夠在各種影像分類任務中取得良好的效能。總的來說,CNN是分析和分類影像資料的強大工具,透過正確的方法,它們可以用來解決計算機視覺和機器學習中的各種問題。

1K+ 瀏覽量
