
 資料結構
資料結構 網路
網路 關係型資料庫管理系統
關係型資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP編譯器設計中的輸入緩衝是什麼?
詞法分析 必須每次都訪問 輔助儲存器 來識別標記。這既耗時又昂貴。因此,輸入字串被儲存到緩衝區中,然後由詞法分析器進行掃描。
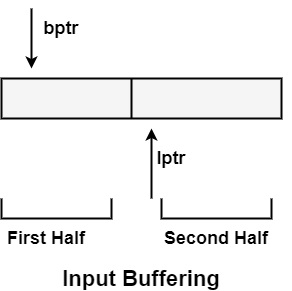
詞法分析器從左到右逐個字元掃描輸入字串以識別標記。它使用兩個指標來掃描標記:
起始指標 (bptr) - 它指向要讀取的字串的開頭。
前瞻指標 (lptr) - 它向前移動以搜尋標記的結尾。
示例 - 對於語句 int a, b;
兩個指標都從儲存在緩衝區中的字串的開頭開始。
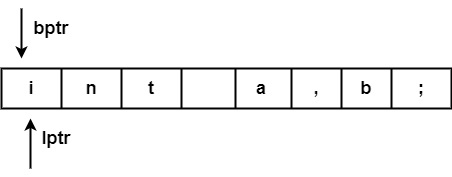
前瞻指標掃描緩衝區直到找到標記。
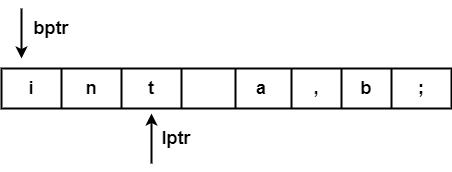
在確定標記 ("int") 之前,必須檢查標記 ("int") 後面的字元 ("空格")。
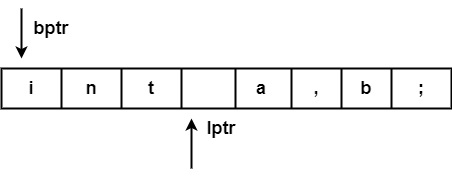
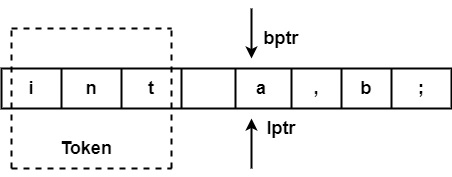
處理完標記 ("int") 後,兩個指標將設定為下一個標記 ('a'),並且此過程將對整個程式重複。
緩衝區可以分成兩半。如果前瞻指標向第一半的中間移動,則第二半將填充要讀取的新字元。如果前瞻指標移動到第二半緩衝區的右端,則第一半將填充新字元,然後繼續此過程。
哨兵 - 哨兵用於進行檢查,每次向前指標移動時,都會進行檢查以確保緩衝區的一半沒有移出範圍。如果移出範圍,則應重新載入另一半。
緩衝區對 - 一種專門的緩衝技術可以減少處理輸入字元時在傳輸字元所需的開銷。它包括兩個緩衝區,每個緩衝區包含 N 個字元大小,並交替重新載入。
有兩個指標,例如詞素開始和向前指標得到支援。詞素開始指向當前發現的詞素的開頭。向前指標掃描前方,直到發現模式匹配。在詞素開始之前,詞素開始設定為僅構造的詞素之後的字元,而向前指標設定為其右側的字元。
初步掃描 - 一些過程最好在將字元從原始檔移動到緩衝區時執行。例如,它可以刪除註釋。像 FORTRAN 這樣的語言忽略空格,可以將它們從字元流中刪除。它還可以將多個空格的字串壓縮成一個空格。對要進行詞法分析的字元流進行預處理可以避免在空格字串上來回移動前瞻指標的麻煩。

46K+ 瀏覽量
