
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP自然語言處理中訓練一元語法標註器
簡介
單個詞語稱為一元語法。一元語法標註器是一種僅需要一個詞語就能推斷出該詞語詞性的標註器。它只有一個詞語的上下文。NLTK 庫為我們提供了 UnigramTagger,它繼承自 NgramTagger。
在本文中,讓我們瞭解自然語言處理中一元語法標註器的訓練過程。
一元語法標註器及其使用 NLTK 進行的訓練
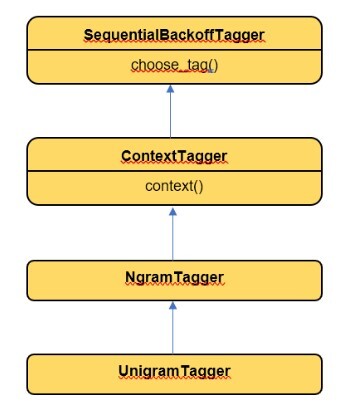
工作原理
UnigramTagger 繼承自 ContextTagger。實現了 context() 方法。context 方法與 choose_tag() 具有相同的引數。
從 context() 方法中,將使用一個詞語標記來建立模型。此詞語用於查詢最佳標籤。
UnigramTagger 將使用上下文建立一個模型。
Python 實現
import nltk
nltk.download('treebank')
from nltk.tag import UnigramTagger
from nltk.corpus import treebank as tb
sentences_trained = treebank.tagged_sents()[:4000]
uni_tagger = UnigramTagger(sentences_trained)
print("Sample Sentence : ",tb.sents()[1])
print("Tag sample sentence : ", uni_tagger.tag(tb.sents()[1]))
輸出
Sample Sentence : ['Mr.', 'Vinken', 'is', 'chairman', 'of', 'Elsevier', 'N.V.', ',', 'the', 'Dutch', 'publishing', 'group', '.']
Tag sample sentence : [('Mr.', 'NNP'), ('Vinken', 'NNP'), ('is', 'VBZ'), ('chairman', 'NN'), ('of', 'IN'), ('Elsevier', 'NNP'), ('N.V.', 'NNP'), (',', ','), ('the', 'DT'), ('Dutch', 'JJ'), ('publishing', 'NN'), ('group', 'NN'), ('.', '.')]
在以上程式碼示例中,第一個 Unigram Tagger 在 Treebank 中的前 4000 個句子上進行訓練。一旦句子訓練完成,它們就會使用相同的標註器對任何句子進行標註。在以上程式碼示例中,使用了句子 1。
以下程式碼示例可用於測試和評估 Unigram Tagger。
from nltk.corpus import treebank as tb
sentences_trained = treebank.tagged_sents()[:4000]
uni_tagger = UnigramTagger(sentences_trained)
sent_tested = treebank.tagged_sents()[3000:]
print("Test score : ",uni_tagger.evaluate(sent_tested))
輸出
Test score : 0.96
在以上程式碼示例中,一元語法標註器在 4000 個句子上進行訓練,然後在最後 1000 個句子上進行評估。
平滑技術
在許多情況下,我們需要在自然語言處理中構建統計模型,例如,可以根據訓練資料預測下一個詞語或自動完成句子。在如此多的詞語組合或可能性中,獲得最準確的預測詞語是必不可少的。在這種情況下,可以使用平滑技術。平滑是一種調整訓練模型中機率的方法,以便它能夠更準確地預測詞語,甚至預測訓練語料庫中不存在的適當詞語。
平滑技術的型別
拉普拉斯平滑
它也稱為加 1 平滑,其中我們在分母中詞語的計數中加 1,這樣我們就不會出現 0 值或除以 0 的情況。
例如:
Problaplace (wi | w(i-1)) = (count(wi w(i-1)) +1 ) / (count(w(i-1)) + N)
N = total words in the training corpus
Prob("He likes coffee")
= Prob( I | <S>)* Prob( likes | I)* Prob( coffee | likes)* Prob(<E> | coffee)
= ((1+1) / (4+6)) * ((1+1) / (1+8)) * ((0+1) / (1+5)) * ((1+1) / (4+8))
= 0.00123
回退和插值
它包含兩個步驟
回退過程
我們從 n-gram 開始,
如果觀測值不足,則檢查 n-1 gram。
如果我們有足夠的觀測值,則使用 n-2 gram。
插值過程
我們使用不同 n-gram 模型的混合。
例如,考慮句子“他去了 xxx”,我們可以說三元語法“他去了到”出現過一次,如果詞語是“到”,則詞語“他去了”的機率為 1,對於所有其他詞語,機率為 0。
結論
UnigramTagger 是一個有用的 NLTK 工具,用於訓練一個標註器,該標註器可以使用單個詞語作為上下文來確定句子的詞性。UnigramTagger 在 NLTK 工具包中可用,該工具包使用 Ngram Tagger 作為其父類。

128 次瀏覽
