
 資料結構
資料結構 網路
網路 關係資料庫管理系統
關係資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何根據列名或行索引對 Pandas DataFrame 進行排序?
許多應用程式都受益於根據列名或行索引對 Pandas DataFrame 進行排序。例如,為了展示銷售額隨時間的變化情況,我們可以按日期對銷售資料 DataFrame 進行排序。在 Python 中,我們有一些內建函式——DataFrame()、sort_index() 和 sort_values(),可用於根據列名或行索引對 Pandas DataFrame 進行排序。
語法
以下語法在示例中使用:
DataFrame(var_name, colums= ['col1', 'col2', and so on], index= ['1', '2', and so on])
DataFrame 是 Pandas 模組的一個庫,它定義了不同行和列的二維結構。
sort_index()
sort_index 用於根據索引標籤對序列進行排序。此方法對 Pandas DataFrame 進行排序
升序和降序。
sort_index(axis = 1)
此 sort_index 接受名為 axis = 1 的引數,用於排序列順序。換句話說,我們可以說 axis = 1 指定列。[示例 3]
sort_values(by=["col1","col2","col3"])
sort_value 方法透過按升序對專案或序列進行排序來定義。以上表示形式接受三個列作為引數來排序其專案或序列。
sort_values(by=["row1","row2","row2"])
以上表示形式接受三行,透過使用列表資料型別的技術對其專案或序列進行排序。
示例 1
在以下示例中,我們將透過匯入名為 pandas 的模組來啟動程式。將 pd 作為其物件引用。然後使用列表推導式建立員工資料並將其儲存在變數 Emp 中。然後使用列和行從元組列表建立 DataFrame 物件並將其儲存在變數 info 中。接下來,提及變數 info 並獲取資料的表格結構。
import pandas as pd
# List of Tuples
Emp = [('Arun', 24, 'Uttrakhand', 'Tester', 'Male'),
('Shyam', 23, 'West Bengal', 'SDE-1', 'Male'),
('Raghav', 37, 'Maharastra', 'SDE-3', 'Male'),
('Jayanti', 29, 'Kerala', 'Customer Support','Female')]
# Dataframe object from list of tuples using column and index
info = pd.DataFrame(Emp, columns =['Name', 'Age',
'Place', 'Designation','Gender'],
index =[ '105', '109', '110', '104'])
# Show the dataframe
info
輸出
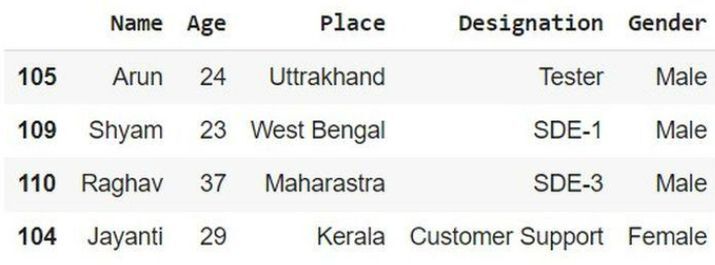
示例 2
在以下示例中,以下程式碼使用下一個終端遵循程式碼的順序。然後使用內建方法 sort_index(),它將按升序對行進行排序並將其儲存在變數 sort_idx 中。最後,使用變數 sort_idx 根據給定的程式碼獲取處理後的資料。
# sort the index row sort_idx = info.sort_index() sort_idx
輸出
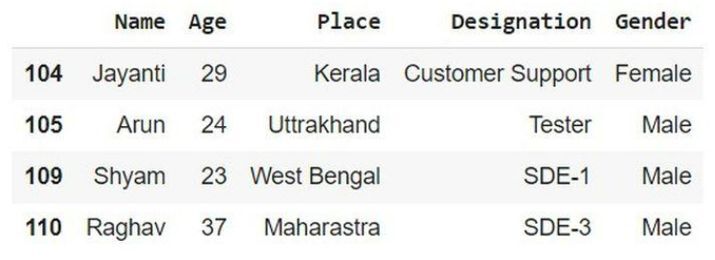
示例 3
在以下示例中,以下程式碼使用下一個終端遵循上述程式碼的順序。這裡我們將根據列排序實現程式。然後匯入 pandas 以啟動程式(不一定需要)。接下來,使用內建方法 sort_index(),它將按升序對列進行排序。然後只需編寫名為 sort_col 的變數即可以另一種形式獲取結果。
# sort the column import pandas as pd sort_col = info.sort_index(axis = 1) sort_col
輸出
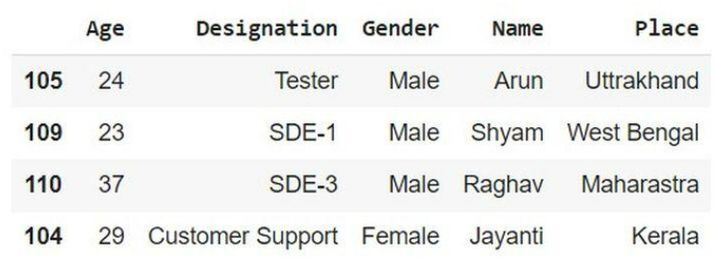
示例 4
在以下示例中,透過匯入名為 pandas 的模組開始程式,該模組將物件引用設定為 pd。然後使用字典資料型別設定三個列,即 X、Y 和 Z,並將其儲存在變數 col 中。接下來,使用 pandas 模組的 DataFrame 並將其儲存在一個名為 df 的新變數中。現在使用內建方法 sort_values 按升序對行進行排序,該方法遵循序列或專案,並將其儲存在變數 sorted_df 中。然後只需編寫 sorted_df 即可獲得表格輸出作為結果。
# Sort DataFrame rows based on multiple columns
import pandas as pd
# create the dictionary
col = {"X" : [40, 10, 60, 20], "Y":[11, 48, 92, 16], "Z":[32,1,26,5]}
df = pd.DataFrame(col)
#Mention the row for sorting
sorted_df=df.sort_values(by=["X","Y","Z"])
sorted_df
輸出
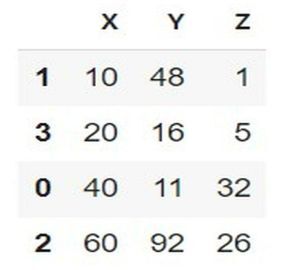
示例 5
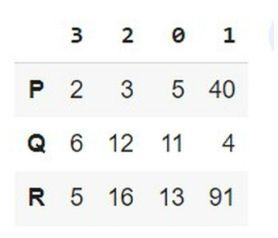
在以下示例中,透過匯入名為 pandas 的模組開始程式。獲取名為 pd 的物件引用,稍後將在內建方法 sort_values 中使用它。然後建立列表,該列表建立三行不同專案的行資料(即 P、Q 和 R),並將其儲存在變數 list1 中。接下來,使用 pandas 模組的 DataFrame,它接受兩個引數——list1(用於使用資料的先前變數名稱)和 index(此引數使用內建方法列表設定所有列的值)。繼續使用名為 sort_values 的內建方法,它接受以下引數:
by=['P','Q','R']:關鍵字 by 設定行數,即 P、Q 和 R。
axis = 1:標識列。
最後,我們藉助變數 sorted_row 列印結果。
# Sort Dataframe based on multiple rows
import pandas as pd
list1 = [(5,40,3,2),(11,4,12,6),(13,91,16,5)]
df = pd.DataFrame(list1, index=list('PQR'))
sorted_row = df.sort_values(by=['P','Q','R'],axis=1)
sorted_row
輸出
結論
我們討論了使用 Pandas DataFrame 對列名或行索引進行排序的不同方法。第一個示例解釋了行和列的簡單表格結構,而第二個和第三個示例遵循順序以完成資料集的有意義表示。第四個示例使用字典技術為多列建立資料,而第五個示例使用列表資料型別為多行建立資料,並生成了不同的輸出作為結果。

3K+ 瀏覽量
