
 資料結構
資料結構 網路
網路 關係型資料庫管理系統 (RDBMS)
關係型資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何使用Python獲取每日新聞?
每日新聞指的是每天釋出的、關注全球事件和主題的新聞。每日新聞的使命是讓讀者瞭解並及時掌握世界各地的事件。政治、體育、娛樂、科學和技術只是每日新聞涵蓋的眾多領域中的一小部分。
Python程式語言在資料分析和Web開發領域都有廣泛的應用。它可以用來建立一個程式,從多個來源收集新聞文章,並將它們編譯成每日新聞摘要。可以使用Python包,如Requests和Beautiful Soup來實現此功能。
注意 − 由於每日新聞不斷更新,輸出可能會有所變化
使用Python獲取每日新聞的演算法
以下是使用Python獲取每日新聞的一些演算法方法。
步驟1 − 確定可靠的新聞來源 查詢提供各種主題資訊(例如政治、體育、娛樂、科學和技術)的可信新聞網站。這可能包括著名的新聞機構,如CNN、BBC和《紐約時報》,以及更專業、規模較小的期刊,這些期刊專注於特定地區或問題。
步驟2 − 設定你的Python環境 在第二步中,你必須在你的計算機上設定一個Python環境,以便使用Python來抓取新聞文章。安裝任何必要的庫的最新版本,包括Beautiful Soup和Requests,以及Python。
步驟3 − 編寫程式碼來抓取新聞文章 編寫Python程式碼,使用Requests庫向你已識別的新聞來源網站發出HTTP請求。使用Beautiful Soup解析HTML內容並提取相關資訊,例如標題、文章文字、作者和釋出時間。將此資訊儲存在資料庫或資料檔案中,以及原始文章的URL。
步驟4 − 檢查文章的文字。對每篇文章的文字分析應用自然語言處理工具,以查詢可能表明剽竊或改寫的模式或相似之處。可以使用像NLTK(自然語言工具包)這樣的工具將每篇文章的文字與其他抓取的文章進行比較。任何似乎是重複使用或剽竊的文章都應從每日新聞摘要中排除。
步驟5 − 製作每日新聞摘要。將抓取的新聞文章彙編成每日新聞摘要,其中應包含全球事件和主題。為了確保摘要公平和有幫助,請包含各種主題和觀點。
步驟6 − 公開每日新聞摘要。將每日新聞摘要釋出到網上或社交媒體平臺上。Beautiful Soup (bs4)是一個用於從HTML和XML檔案中提取資料的Python包。Python預設不包含此模組。在終端輸入以下命令進行安裝。以便任何人都可以訪問它。包含對源文章的引用,以便讀者可以訪問更多細節和上下文。
你可以按照以下步驟使用Python獲取每日新聞。
所需的模組
安裝Beautiful Soup(bs4)的命令
bs4 − Beautiful Soup(bs4) 是一個用於從HTML和XML檔案中提取資料的Python庫。此模組並非Python內建。要安裝它,請在終端中輸入以下命令。
pip install bs4
安裝Request的命令
Requests − Request 使傳送HTTP/1.1請求變得非常簡單。此外,Python預設不包含此模組。在終端輸入以下命令進行安裝。
pip install requests
使用Python獲取每日新聞的方法
方法1
在這種方法中,我們首先匯入模組 −
import requests from bs4 import BeautifulSoup
之後,為了輕鬆獲取任何特定新聞的每日新聞,我們將新增 https://www.bbc.com/news的HTML內容,新增這兩行程式碼 −
url='https://www.bbc.com/news' response = requests.get(url)
訪問 https://www.bbc.com/news,並透過右鍵單擊新聞標題並選擇“檢查”來檢查新聞標題,以查詢構成新聞標題的HTML標籤 −
首先,我們將“soup”定義為BBC新聞網站的HTML。下一步是將“headlines”定義為網站上所有“
”標籤的陣列。最後,使用“text.strip()”方法去除每個元素的outerHTML,只顯示其文字內容,指令碼迭代地遍歷“headlines”陣列並依次顯示每個專案。
第一種方法的程式碼實現
import requests
from bs4 import BeautifulSoup
url = 'https://www.bbc.com/news'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
headlines = soup.find('body').find_all('h3')
for x in headlines:
print(x.text.strip())
第一種方法的輸出
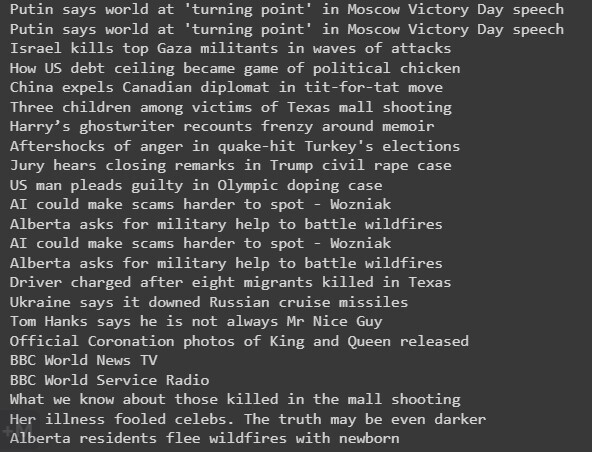
方法2
你可能已經看到你的輸出包含重複的新聞標題和不是新聞標題的文字內容,在這種方法中,我們將從每日新聞資料中刪除不需要的資料。
語法
unwanted = ['BBC World News TV', 'BBC World Service Radio', 'News daily newsletter', 'Mobile app', 'Get in touch']
然後,透過新增以下內容,僅在文字元素不在此列表中時列印文字元素:
第二種方法的程式碼實現
import requests
from bs4 import BeautifulSoup
url = 'https://www.bbc.com/news'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
headlines = soup.find('body').find_all('h3')
unwanted = ['BBC World News TV', 'BBC World Service Radio', 'News daily newsletter', 'Mobile app', 'Get in touch']
for x in headlines:
headline_text = x.text.strip()
if headline_text not in unwanted:
print(headline_text)
第二種方法的輸出
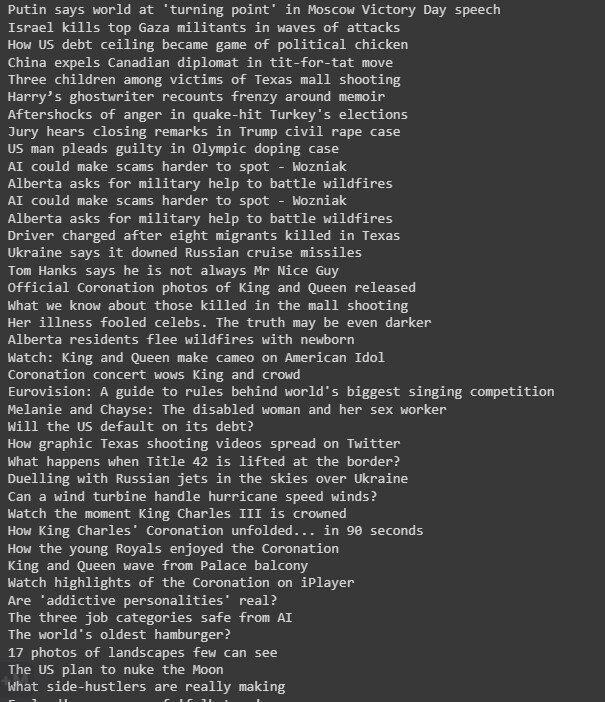
結論
Python程式設計師可以使用網路抓取方法和新聞機構的API來獲取當天的新聞。但是,網路抓取必須符合所抓取網站的條款和條件,並且不應向其伺服器發出過多的查詢。使用網路抓取技術從網站收集新聞文章是另一種方法。開發人員可以使用Python的BeautifulSoup包解析HTML和XML文件來實現這一點。但是,務必注意網站的條款和條件,並避免過度佔用其系統。

686 次瀏覽
