
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP在 Python 的 Seaborn 庫中使用 stripplot 建立分類散點圖時,如何避免資料點重疊?
資料視覺化是一個重要步驟,因為它有助於理解資料中的情況,而無需檢視數字並執行復雜的計算。Seaborn 是一個有助於資料視覺化的庫。它帶有自定義主題和高階介面。
當需要處理的變數本質上是分類變數時,不能使用一般的散點圖、直方圖等。這時需要使用分類散點圖。
諸如“stripplot”、“swarmplot”之類的繪圖用於處理分類變數。“stripplot”函式用於至少一個變數是分類變數的情況。資料沿一個軸以排序的方式表示。但缺點是某些點會重疊。這就是需要使用“jitter”引數來避免變數之間重疊的地方。
它向資料集新增一些隨機噪聲,並調整分類軸上值的位。
stripplot 函式的語法
seaborn.stripplot(x, y,data, jitter = …)
讓我們看看如何使用“jitter”引數在資料集中繪製分類變數:
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
my_df = sb.load_dataset('iris')
sb.stripplot(x = "species", y = "petal_length", data = my_df, jitter = True)
plt.show()輸出
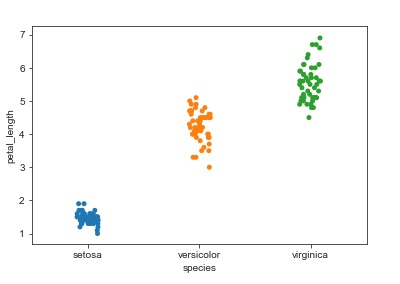
解釋
- 匯入所需的包。
- 輸入資料是“iris_data”,它從 scikit-learn 庫載入。
- 此資料儲存在資料框中。
- “load_dataset”函式用於載入 iris 資料。
- 使用“stripplot”函式視覺化此資料。
- 傳遞一個名為“jitter”的附加引數以避免資料框值的重疊。
- 此處,資料框作為引數提供。
- 此外,還指定了 x 和 y 值。
- 此資料顯示在控制檯中。

更新於:2020年12月11日
1K+ 次檢視

廣告