
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPSeaborn 箱線圖中如何確定異常值?
什麼是異常值?
異常值是指資料集中的資料點或觀測值,它們遠離其他點。異常值可能是由測量誤差、資料輸入誤差或實驗誤差等原因造成的。異常值會歪曲資料集,從而影響統計分析,並可能增加資料集的標準差,進一步影響模型預測。
異常值可能是有效的資料點,也可能是噪聲。
為了更好地理解,讓我們來看一個示例場景。假設您正在收集學生身高資料(年齡在 9 到 12 歲之間)。大多數學生身高都在 4 英尺左右。但有一些學生輸入了錯誤的身高,例如 7 英尺。這個不尋常且不正確的數值就是異常值,因為它與其他數值有顯著差異。簡單來說,異常值就像“異類”,與組中其他成員不太相符。
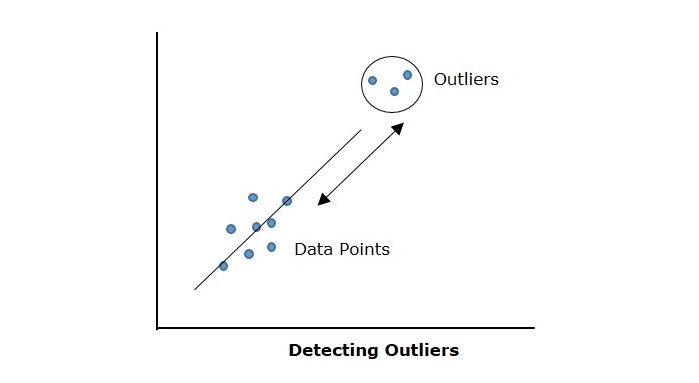
為什麼要移除異常值?
移除異常值是資料預處理的重要步驟。如果資料集包含異常值,如果不移除並在該資料集上訓練機器學習模型,則模型也會嘗試覆蓋異常值點,這會導致預測模型的泛化能力差。
在這種情況下,在覆蓋異常值時,模型變得複雜,從而導致過擬合併在新資料集上產生錯誤預測。移除異常值最簡單的方法之一是使用箱線圖,以下部分討論瞭如何藉助箱線圖識別異常值。
箱線圖的統計分析
箱線圖也稱為盒須圖,它是資料集分佈的圖形表示。它可以幫助我們解釋資料點是分散還是集中。它還解釋了資料集的偏度。
使用箱線圖,我們可以瞭解資料集的最小值、最大值和四分位數範圍(Q1、Q2、Q3)的統計資訊。
其中 -
最小值 - 最小值確定資料集中的最小資料點。
最大值 - 最大值確定資料集中的最大資料點。
第一四分位數 (Q1) - 當資料點分成兩半時,Q1 是資料點下半部分的中位數。它是資料點的第 25 個百分位數。
第二四分位數或中位數 (Q2) - Q2 是所有資料點的中位數。
第三四分位數 (Q3) - 當資料點分成兩半時,Q3 是資料點上半部分的中位數。它是資料點的第 75 個百分位數。
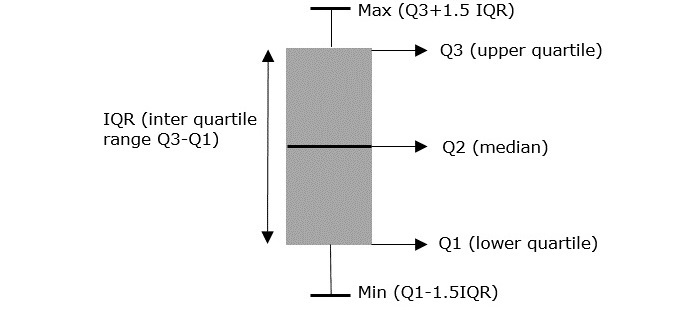
在任何資料集中,大於 Q3+1.5IQR 或小於 Q1-1.5IQR 的記錄都被認為是異常值。
盒子越長,資料越分散,盒子越短,資料越集中。
使用 Seaborn 檢測異常值
Seaborn 是一個基於 matplotlib 的資料視覺化庫,它可以建立複雜的視覺化繪圖,並提供預設調色盤,從而生成美觀的繪圖。
我們可以使用 Seaborn 中的 boxplot() 函式建立箱線圖。以下是 Seaborn 中 boxplot() 函式的語法:
seaborn.boxplot(x=, y=, heu=, data=)
其中,
x、y、hue - 資料集中特徵的名稱。
data - 用於繪圖的資料集。
示例
在以下示例中,我們將使用箱線圖繪製泰坦尼克號資料集,並嘗試確定其中的異常值。
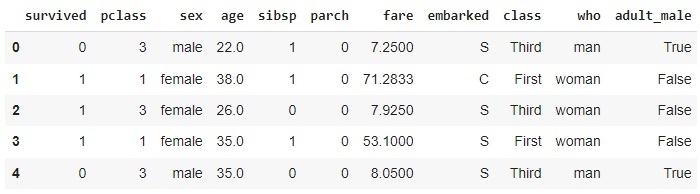
在這個泰坦尼克號資料集中,我們有 891 條記錄和 15 個特徵,描述了泰坦尼克號上乘客的生存狀況。
以下是資料集中的前五行。
當我們使用“sns.boxplot()”為“age”特徵繪製箱線圖時,高於最大值和低於最小值的資料點被認為是異常值。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
dataset= sns.load_dataset('titanic')
sns.boxplot(y=dataset['age'])
plt.show()
輸出
執行上述程式後,您將獲得以下輸出:
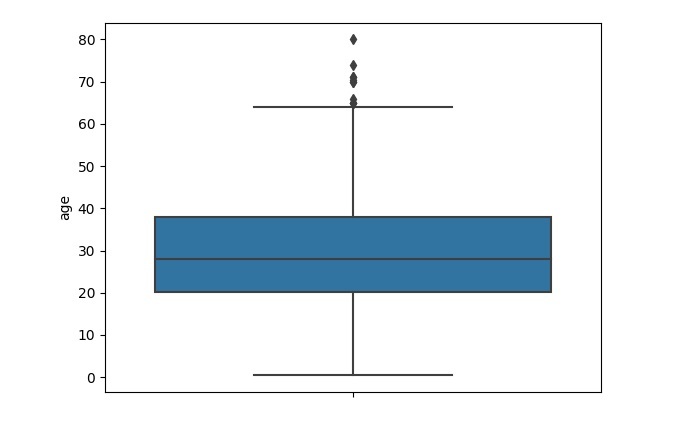
考慮到輸出,可以看出,Age>65 是異常值點。
示例
由於我們在上述示例中使用了單個數值特徵,因此我們在此考慮了 x 軸上的一個分類特徵(alive)和 y 軸上的一個數值特徵(age)。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
dataset= sns.load_dataset('titanic')
sns.boxplot(data=dataset, x="alive", y="age")
plt.show()
輸出
執行上述程式後,您將獲得以下輸出:
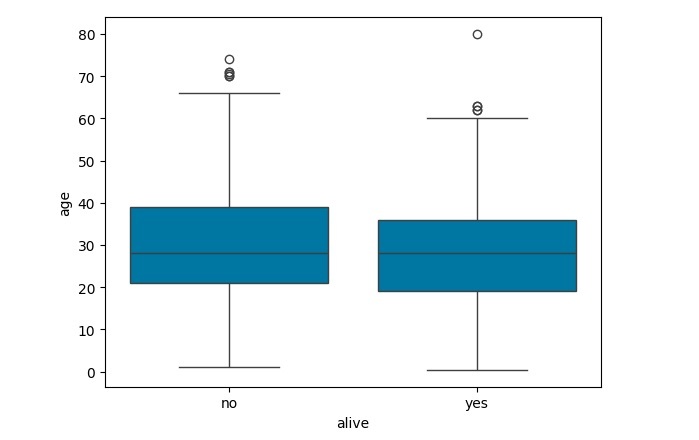
示例
在這裡,我們考慮了一個分類特徵(class)並確定了相對於年齡特徵的異常值,將圖與另一個分類特徵(sex)進行比較。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
dataset= sns.load_dataset('titanic')
sns.boxplot(x="class",y="age",hue="sex",data=dataset)
plt.show()
輸出
執行上述程式後,您將獲得以下輸出:

刪除異常值
刪除異常值的一種方法是識別最小值和最大值,並丟棄超出此範圍的資料點(將其設為空值並刪除它們)。
示例
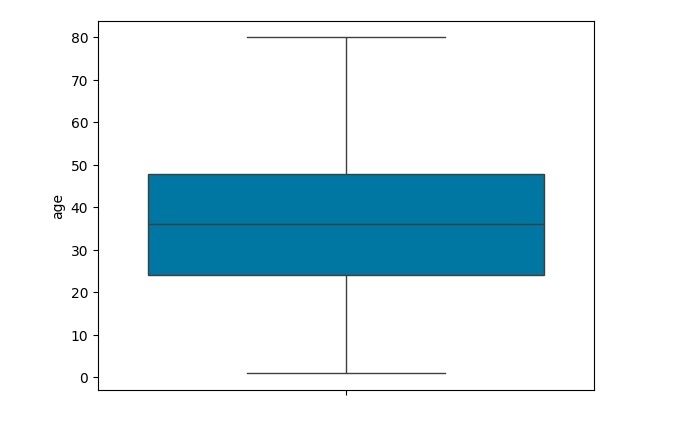
在以下示例中,我們選擇年齡特徵並移除識別的異常值:
我們首先必須計算 Q1 和 Q3 值,然後計算四分位數範圍 (Q3-Q1)。
計算完四分位數範圍後,計算 Q3+1.5IQR 和 Q1-1.5IQR 的值,如指定的那樣,如果資料點大於 Q3+1.5IQR 且小於 Q1-1.5IQR,則認為這些資料點是異常值。
最後,將這些異常值替換為空值,然後使用 .dropna 刪除這些空值。再次繪製箱線圖檢查是否已移除異常值。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
dataset= sns.load_dataset('titanic')
for i in ['age']:
q75,q25=np.percentile(dataset.loc[:,i],[75,25])
intr_qr= q75-q25
max = q75+(1.5*intr_qr)
min = q25-(1.5*intr_qr)
dataset.loc[dataset[i]<min,i]=np.nan
dataset.loc[dataset[i]>max,i]=np.nan
dataset=dataset.dropna(axis=0)
sns.boxplot(y=dataset['age'])
plt.show()
輸出
執行上述程式後,您將獲得以下輸出:

924 次檢視
