
 資料結構
資料結構 網路
網路 關係型資料庫管理系統 (RDBMS)
關係型資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用 Seaborn Clustermap 在 Python 中建立分層聚類熱圖
在資料分析和視覺化中,分層聚類熱圖提供了一個強大的工具來揭示覆雜資料集中的模式和關係。本文探討了如何使用 Python 中的 Seaborn Clustermap 建立分層聚類熱圖。
為了幫助您理解這個過程,我們將使用程式碼示例逐步引導您完成該過程。我們將指導您如何對資料進行聚類和視覺化,這將為您提供有關每個變數之間關係的重要資訊。
什麼是使用 Seaborn Clustermap 在 Python 中建立的分層聚類熱圖?
分層聚類熱圖是一種視覺化技術,用於以熱圖格式顯示資料矩陣,同時還結合了分層聚類。在 Python 中,Seaborn 庫提供了一個名為 Clustermap 的實用工具,可以建立分層聚類熱圖。
您是否曾經處理過大型複雜資料集,並發現難以識別資料中的模式或連線?如果是這樣,您並不孤單。這可能是一項艱鉅的任務,需要花費大量時間和精力。這就是分層聚類發揮作用的地方。此方法有助於根據其相似性組織熱圖的行和列,從而使我們能夠更好地理解資料不同部分之間的關係。
結果是一個不僅外觀吸引人,而且對資料的底層結構具有重要影響的熱圖。透過將行和列組合在一起,我們可以推斷它們如何聚類成相似物件的組或族。這有助於識別從原始資料中無法立即看到的趨勢和連線。
使用 Seaborn Clustermap 在 Python 中繪製分層聚類熱圖
以下是我們將遵循的步驟,以便使用 Seaborn Clustermap 在 Python 中繪製分層聚類熱圖:
匯入必要的庫:
使用 `import seaborn as sns` 匯入 Seaborn 庫。
可選地,使用 `import matplotlib.pyplot as plt` 匯入 Matplotlib 庫以進行其他自定義。
載入或準備資料集:
使用 `sns.load_dataset()` 載入要視覺化的資料集,或以合適的格式準備您自己的資料集。
預處理資料(如果需要):
執行任何必要的資料預處理步驟,例如重塑或聚合資料,以建立適合熱圖視覺化的矩陣。
建立聚類熱圖:
使用 `sns.clustermap()` 函式,將預處理的資料矩陣作為輸入傳遞。
指定任何其他引數以自定義外觀,例如顏色對映(`cmap` 引數)或聚類方法(`method` 引數)。
顯示熱圖:
如果您在步驟 1 中匯入了 Matplotlib 庫,則使用 `plt.show()` 顯示熱圖。
示例
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# Load the inbuilt dataset
data = sns.load_dataset("flights")
# Data preprocessing
data_pivot = data.pivot("month", "year", "passengers")
# Data analysis
monthly_totals = data.groupby("month")["passengers"].sum()
yearly_totals = data.groupby("year")["passengers"].sum()
# Data processing
processed_data = data_pivot.div(monthly_totals, axis=0)
# Create the clustered heatmap using seaborn clustermap
sns.clustermap(processed_data, cmap="YlGnBu")
# Display the heatmap
plt.show()
輸出
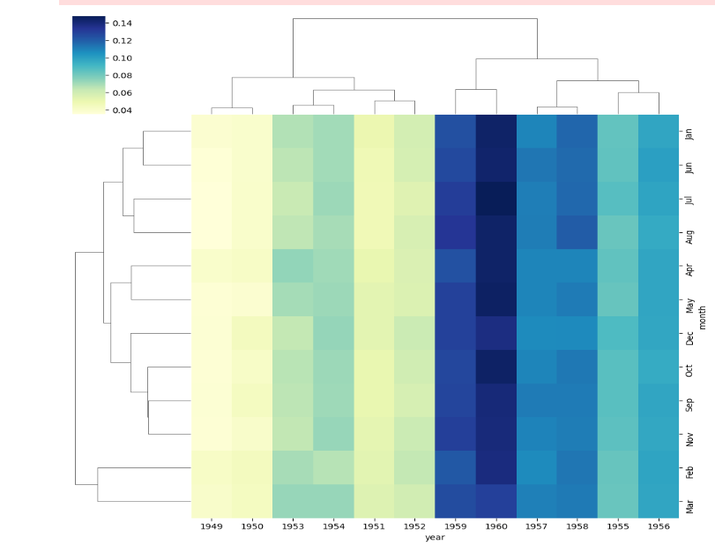
使用 Seaborn Clustermap 在 Python 中自定義分層聚類熱圖
我們使用 Seaborn 的 clustermap() 函式建立分層聚類熱圖,並將 pivot_data 矩陣作為輸入傳遞。
我們使用 cmap 引數將顏色對映指定為“YlGnBu”。
提供了其他自定義選項
linewidths=0.5:設定樹狀圖中線條的寬度。
figsize=(8, 6):設定生成的熱圖圖形的大小。
dendrogram_ratio=(0.1, 0.2):調整樹狀圖高度的比例。
自定義熱圖
我們使用標準的 Matplotlib 函式進一步自定義熱圖。在此示例中,我們使用 plt.title() 設定標題,並分別使用 plt.xlabel() 和 plt.ylabel() 為 x 軸和 y 軸新增標籤。
示例
import seaborn as sns
# Load the inbuilt dataset
data = sns.load_dataset("flights")
# Pivot the data to create a matrix for the heatmap
pivot_data = data.pivot("month", "year", "passengers")
# Create the clustered heatmap using seaborn clustermap
sns.clustermap(pivot_data, cmap="YlGnBu", linewidths=0.5, figsize=(8, 6), dendrogram_ratio=(0.1, 0.2))
# Customize the heatmap
plt.title("Hierarchically-clustered Heatmap - Flights Data")
plt.xlabel("Year")
plt.ylabel("Month")
# Display the heatmap
plt.show()
輸出

結論
總之,本文探討了使用 Seaborn Clustermap 在 Python 中建立分層聚類熱圖。透過遵循概述的步驟,可以輕鬆地視覺化複雜資料集並發現資料中的模式和關係。
Seaborn 庫的 clustermap 函式提供了靈活性和自定義選項,允許使用者根據自己的喜好調整顏色方案、線寬、圖形大小和樹狀圖比例。

979 次瀏覽
