
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP推薦系統中的稀疏性問題處理
引言
在推薦系統中,協同過濾是構建模型並尋找使用者之間相似性的方法之一。這一概念廣泛應用於電子商務網站、OTT平臺和影片共享平臺。此類系統在初始建模階段面臨的一個備受關注的問題是資料稀疏性,即只有少數使用者在平臺上給出評分或評論,並以任何方式參與互動。
在本文中,讓我們瞭解推薦系統中資料稀疏性的問題,並瞭解處理它的方法。
資料稀疏性
協同過濾的主要目標是聚合具有相似想法和共同選擇的使用者的評分或對產品/電影等的評論。透過收集基於使用者對產品/電影等的評分或評論的使用者級別資訊來實現這一點。因此,生成了一個使用者和專案評分矩陣。然而,大多數情況下,這個矩陣是高度稀疏的,可能高達99%。當出現新使用者時,另一個問題出現了,因為關於評分的資訊非常少。
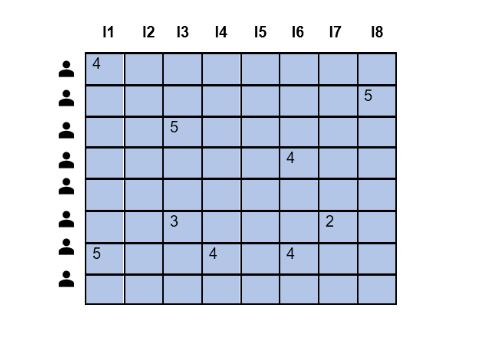
這在冷啟動問題中也很明顯。
如何處理資料稀疏性?
有一些方法可以處理資料稀疏性。
降維 − 採用降維演算法,將使用者和專案互動矩陣簡化為更密集的形式,同時保留已互動並提供評分的最相關的使用者。所有預測都基於此簡化後的密集矩陣。此方法可以提高許多推薦系統的效能,但是有一個缺點,即會導致寶貴資訊的丟失。
推斷使用者之間的信任 − 在這種方法中,我們試圖找到兩個可能沒有直接關聯的使用者之間的信任因素。但是,它們可以透過中間使用者(例如P)相關聯。
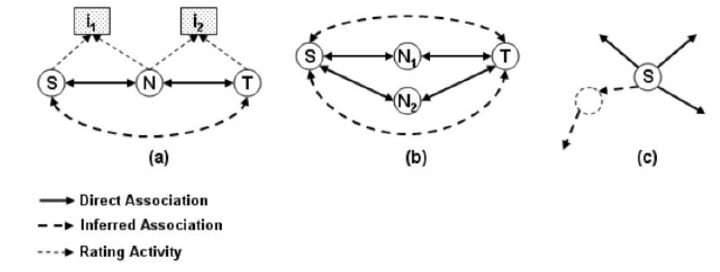
例如,如果使用者S和N對I1相關聯,並且使用者N和T對I2進行了評分,為了找到S和T之間的關係,我們可以使用透過使用者N的信任路徑,因為N是S和T之間的共同連結。
如此定義的信任路徑的長度(k)可能會有所不同,如果源使用者和目標使用者沒有共同的關係或信任使用者,則可能變得無限。
系統中的社交網路 − 透過對雙方共同評分的專案的使用者來推斷和建立關係。還有其他型別的互動,例如反饋、交易等。這是透過在推薦系統中構建社交網路來實現的。這種方法涉及兩個過程:成員資格和演變。在成員資格中,任何新使用者或現有使用者都必須至少對一個專案進行評分才能加入這樣的網路。
在演變階段,隨著越來越多的使用者與網路進行互動,互動和連結會增長和加強,並且會建立更多的關聯。
結論
稀疏性問題是推薦系統中非常常見的問題,主要與協同過濾方法有關。當資料稀疏且無法從中識別鄰居時,就會出現稀疏性。這可能會限制推薦演算法/系統推薦的質量,但是有一些方法,如降維、推斷使用者之間的信任以及社交網路,已被證明對解決此問題非常有用。

瀏覽量:205
