
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用Python在Selenium WebDriver中獲取WebElement的HTML原始碼。
我們可以使用Selenium webdriver獲取webelement的html原始碼。我們可以獲取**innerHTML**屬性來獲取web元素的原始碼。
innerHTML是webelement的一個屬性,它等於起始標籤和結束標籤之間存在的文字。**get_attribute**方法用於此目的,並將innerHTML作為引數傳遞給該方法。
語法
s = element.get_attribute('innerHTML')我們可以藉助Javascript Executor獲取webelement的html原始碼。我們將使用**execute_script**方法,並將**arguments index.innerHTML**和要檢索其html原始碼的**webelement**傳遞給該方法。
語法
s = driver.find_element_by_id("txt-search")
driver.execute_script("return arguments[0].innerHTML;",s)讓我們看看下面元素的html程式碼。該元素的innerHTML將是 - **您正在瀏覽最佳的<b>線上教育</b>資源。**
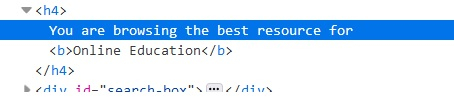
示例
使用get_attribute的程式碼實現。
from selenium import webdriver
driver = webdriver.Chrome(executable_path="C:\chromedriver.exe"
# implicit wait applied
driver.implicitly_wait(0.5)
driver.get("https://tutorialspoint.tw/index.htm")
# to identify element and obtain innerHTML with get_attribute
l = driver.find_element_by_css_selector("h4")
print("HTML code of element: " + l.get_attribute('innerHTML'))使用Javascript Executor的程式碼實現。
from selenium import webdriver
driver = webdriver.Chrome(executable_path="C:\chromedriver.exe"
# implicit wait applied
driver.implicitly_wait(0.5)
driver.get("https://tutorialspoint.tw/index.htm")
# to identify element and obtain innerHTML with execute_script
l = driver.find_element_by_css_selector("h4")
h= driver.execute_script("return arguments[0].innerHTML;",l)
print("HTML code of element: " + h)輸出


更新於:2020年10月26日
12K+ 次瀏覽

廣告