
 資料結構
資料結構 網路
網路 關係資料庫管理系統(RDBMS)
關係資料庫管理系統(RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPML中的DBSCAN聚類 | 基於密度的聚類
介紹
DBSCAN是Density-Based Spatial Clustering of Applications with Noise的縮寫。它是一種無監督聚類演算法。DBSCAN聚類可以處理來自海量資料中任意大小的叢集,並且可以處理包含大量噪聲的資料集。它基本上是基於一個區域內最小點數的標準。
什麼是DBSCAN演算法?
DBSCAN演算法可以有效地將密集分組的點聚類到一個叢集中。它可以識別大型資料集中資料點之間的區域性密度。DBSCAN可以非常有效地處理異常值。與K-means演算法相比,DBSCAN的一個優勢是,在DBSCAN的情況下,不需要預先知道質心的數量。
DBSCAN演算法依賴於兩個引數:epsilon和minPoints。
Epsilon定義為每個資料點周圍考慮密度的半徑。
minPoints是在半徑內需要的點數,以便資料點成為核心點。
該圓圈可以擴充套件到更高的維度。
DBSCAN演算法的工作原理
在DBSCAN演算法中,在每個資料點周圍繪製一個半徑為epsilon的圓,並將資料點分類為核心點、邊界點或噪聲點。如果資料點在epsilon半徑內有minPoints個數據點,則將其分類為核心點。如果它擁有的點少於minPoints,則稱為邊界點;如果epsilon半徑內沒有點,則將其視為噪聲點。
讓我們透過一個例子來理解其工作原理。
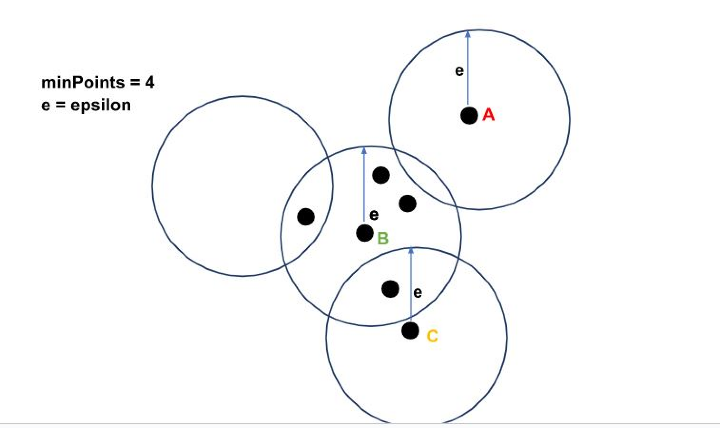
在上圖中,我們可以看到點A在epsilon(e)半徑內沒有點。因此,它是一個噪聲點。點B在epsilon e半徑內有minPoints(=4)個點,因此它是一個核心點。而該點只有1個(小於minPoints)點,因此它是一個邊界點。
DBSCAN演算法涉及的步驟。
首先,找到epsilon半徑內的所有點,並識別點數大於或等於minPoints的核心點。
接下來,對於每個核心點,如果未分配給特定叢集,則為其建立一個新叢集。
找到與核心點相關的所有密集連線的點,並將它們分配到同一個叢集。如果兩個點具有一個鄰居點,並且該鄰居點與這兩個點之間的距離都在epsilon距離之內,則這兩個點被稱為密集連線點。
然後迭代資料中的所有點,並將不屬於任何叢集的點標記為噪聲。
程式碼實現
## DBSCAN
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
import seaborn as sns
data = pd.read_csv('/content/customers.csv')
data.rename(columns={'CustomerID':'customer_id','Gender':'gender','Age':'age','Annual Income (k$)':'income','Spending Score (1-100)':'score'},inplace=True)
features = ['age', 'income', 'score']
train_x = data[features]
cls = DBSCAN(eps=12.5, min_samples=4).fit(train_x)
datasetDBSCAN = train_x.copy()
datasetDBSCAN.loc[:,'cluster'] = cls.labels_
datasetDBSCAN.cluster.value_counts().to_frame()
outliers = datasetDBSCAN[datasetDBSCAN['cluster']==-1]
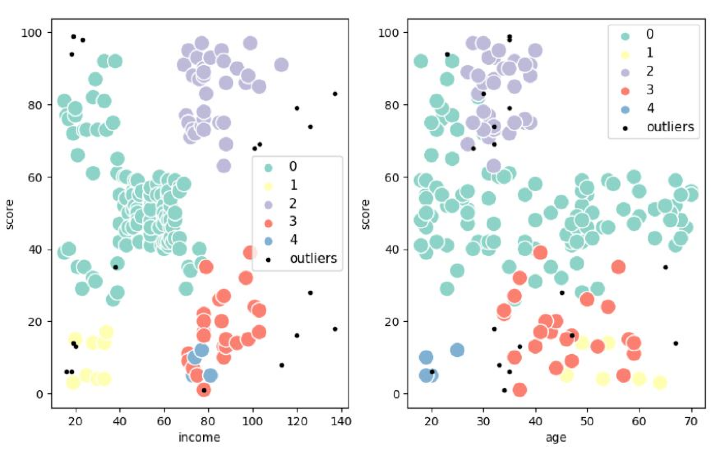
fig, (ax) = plt.subplots(1,2,figsize=(10,6))
sns.scatterplot(x='income', y='score',data=datasetDBSCAN[datasetDBSCAN['cluster']!=-1],hue='cluster', ax=ax[0], palette='Set3', legend='full', s=180)
sns.scatterplot(x='age', y='score',
data=datasetDBSCAN[datasetDBSCAN['cluster']!=-1],
hue='cluster', palette='Set3', ax=ax[1], legend='full', s=180)
ax[0].scatter(outliers['income'], outliers['score'], s=9, label='outliers', c="k")
ax[1].scatter(outliers['age'], outliers['score'], s=9, label='outliers', c="k")
ax[0].legend()
ax[1].legend()
plt.setp(ax[0].get_legend().get_texts(), fontsize='11')
plt.setp(ax[1].get_legend().get_texts(), fontsize='11')
plt.show()
輸出
DBSCAN演算法的優點
DBSCAN不需要像K-Means演算法那樣預先知道質心的數量。
它可以找到任何形狀的叢集。
它還可以找到與任何其他組或叢集不相連的叢集。它可以很好地處理噪聲叢集。
它對異常值具有魯棒性。
DBSCAN演算法的缺點
它不適用於密度不同的資料集。
由於它不能被分割,因此不能與多程序一起使用。
如果資料集稀疏,則無法找到正確的叢集。
它對引數epsilon和minPoints敏感
DBSCAN的應用
它用於衛星影像。
用於X射線晶體學
溫度異常檢測。
結論
DBSCAN是一種無監督聚類技術,在處理異常值和任意形狀的叢集時,其效能優於其他聚類演算法。DBSCAN根據距離測量將密集的區域聚類在一起。它是一種空間聚類演算法,也可以很好地處理噪聲資料。

7K+ 次瀏覽
