
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPScikit Learn 中的聚類效能評估
聚類是一種基本的無監督學習技術,旨在發現未標記資料中的模式或分組。它在資料探勘、模式識別和客戶細分等各個領域都發揮著至關重要的作用。但是,一旦應用了聚類演算法,就必須評估其效能並評估所得聚類的質量。
聚類效能評估是理解聚類演算法的有效性和可靠性的關鍵步驟。它包括量化獲得的聚類的質量,並提供對其一致性和可分離性的見解。透過評估聚類結果,從業人員可以就演算法選擇、引數調整和發現的聚類的可解釋性做出明智的決策。
在本文中,我們將探討使用 Python 中的 Scikit-Learn 庫進行聚類效能評估的概念。
為了說明聚類效能評估的概念,讓我們考慮一個我們對資料集執行聚類的示例。
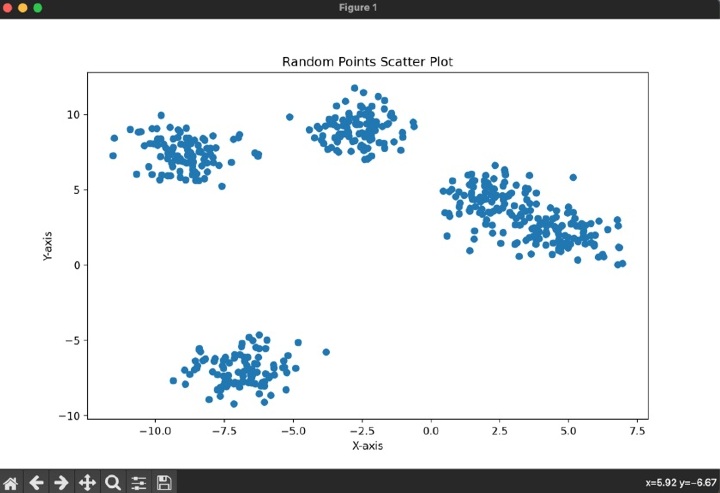
考慮以下所示的程式碼。
示例
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# Generate random points
features, targets = make_blobs(n_samples=500, centers=5, random_state=42, shuffle=False)
# Create the scatter plot
plt.scatter(features[:, 0], features[:, 1])
# Customize plot appearance
plt.title("Random Points Scatter Plot")
plt.xlabel("X-axis")
plt.ylabel("Y-axis")
# Display the plot
plt.show()
輸出
K均值
在下面的示例中,我們將使用 k 均值演算法。
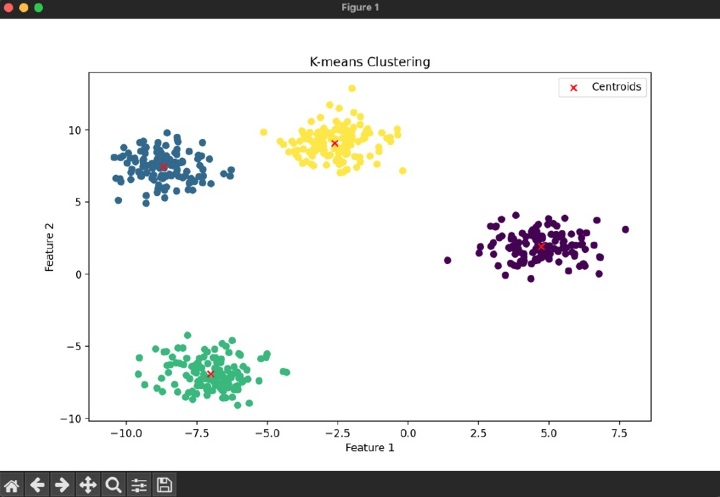
考慮以下所示的程式碼。
示例
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
# Generate sample data
X, y_true = make_blobs(n_samples=500, centers=4, random_state=42)
# Perform clustering using k-means algorithm
kmeans = KMeans(n_clusters=4, random_state=42)
y_pred = kmeans.fit_predict(X)
# Evaluate clustering performance using metrics
silhouette = silhouette_score(X, y_pred)
calinski_harabasz = calinski_harabasz_score(X, y_pred)
davies_bouldin = davies_bouldin_score(X, y_pred)
# Plot the clustering results
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], marker='x', c='red', label='Centroids')
plt.title('K-means Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()
# Print the evaluation scores
print(f"Silhouette Score: {silhouette:.3f}")
print(f"Calinski-Harabasz Index: {calinski_harabasz:.3f}")
print(f"Davies-Bouldin Index: {davies_bouldin:.3f}")
輸出
效能評估指標
輪廓係數
輪廓係數是廣泛用於評估聚類結果質量的指標。它衡量資料點與其自身叢集相比與其他叢集的相似程度。該分數範圍為 -1 到 1,其中較高的值表示更好的聚類效能。接近 1 的值表明資料點已很好地聚類並被正確分離,而接近 -1 的值表明資料點可能已被分配到錯誤的叢集。在程式碼中,輪廓係數是使用 silhouette_score() 函式計算的。
考慮以下所示的程式碼。
示例
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# Generate sample data
X, _ = make_blobs(n_samples=500, centers=4, random_state=42)
# Perform clustering using K-means algorithm
kmeans = KMeans(n_clusters=4, random_state=42)
y_pred = kmeans.fit_predict(X)
# Calculate the Silhouette Score
silhouette = silhouette_score(X, y_pred)
# Print the Silhouette Score
print("Silhouette Score:", silhouette)
輸出
Silhouette Score: 0.7911042588289479
Calinski-Harabasz 指數
Calinski-Harabasz 指數,也稱為方差比率準則,是聚類的另一個性能評估指標。它衡量叢集間離散度與叢集內離散度的比率。較高的 Calinski-Harabasz 指數值表示更好的聚類效能,叢集之間具有更高的分離度,而叢集內的方差較低。在程式碼中,Calinski-Harabasz 指數是使用 calinski_harabasz_score() 函式計算的。
考慮以下所示的程式碼。
示例
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import calinski_harabasz_score
# Generate sample data
X, _ = make_blobs(n_samples=500, centers=4, random_state=42)
# Perform clustering using K-means algorithm
kmeans = KMeans(n_clusters=4, random_state=42)
y_pred = kmeans.fit_predict(X)
# Calculate the Calinski-Harabasz Index
calinski_harabasz = calinski_harabasz_score(X, y_pred)
# Print the Calinski-Harabasz Index
print("Calinski-Harabasz Index:", calinski_harabasz)
輸出
Calinski-Harabasz Index: 5742.035759058726
結論
總之,評估聚類演算法的效能對於評估其對資料點分組的有效性至關重要。在本文中,我們探討了兩個常用的效能評估指標:輪廓係數和 Calinski-Harabasz 指數。
輪廓係數透過考慮同一叢集中樣本之間的平均距離以及其他叢集中樣本的平均距離來衡量叢集的質量和分離度。較高的輪廓係數表示更好的聚類效能,具有良好的分離和不同的叢集。
Calinski-Harabasz 指數透過考慮叢集間離散度與叢集內離散度的比率來評估聚類效能。較高的 Calinski-Harabasz 指數表明更好的聚類效能,叢集之間具有更高的分離度,而叢集內的方差較低。
透過利用這些評估指標,我們可以定量地評估聚類結果的質量,並就聚類演算法和引數設定的選擇做出明智的決策。

356 次瀏覽
